一、需求背景 & 痛点说明
相信很多小伙伴都有这样的需求:需要从 Python 官方 FTP 站点下载 Python 的历史版本文件,但是官方的文件是按版本号分目录存放的,每个版本里包含 tar.gz、dmg、msi、exe、zip 等所有格式的文件,如果手动点击下载,不仅效率极低,还容易漏下、重复下载,非常繁琐。
本次分享的爬虫脚本,完美解决以上痛点:✅ 无需手动复制任何下载链接✅ 自动爬取 Python 官网 FTP 的所有版本目录 + 每个版本下的全部文件 ✅ 支持多线程并发下载 ,下载速度拉满✅ 支持断点续传 ,网络中断后重新运行即可继续下载,无需从头再来✅ 禁用系统代理,解决因代理配置导致的下载失败 / 超时问题✅ 自动创建版本目录,文件按版本号分类存储,本地目录整洁有序✅ 失败自动重试 + 完整异常捕获,稳定性拉满
脚本无文件格式限制,下载每个版本里的所有文件,一个不落!
!!!如果大家仅仅想要下载某一个python版本的链接,但是下载很慢的,博主把安装包全部下载好了,可以去我搭建的Ai智能体问它拿。直接问它需要哪个版本的就行了,我也是为了方便自己试用才搭建的。
这里不是卖广告,只是为了方便各大网友没有科学下载慢而方便大家下载。下面是我搭建的Ai智能体链接,不喜勿喷,仅仅为了方便大家。
https://mbd.baidu.com/ma/s/wg6dXzIA
二、核心功能亮点(必看)
本次分享的脚本是最终优化完整版,对比普通下载脚本,核心优势如下:
- ✔️ 全量下载:爬取https://www.python.org/ftp/python/下所有 Python 版本,下载每个版本目录中的全部文件,无格式过滤、无文件过滤
- ✔️ 全局
Session请求:复用 TCP 连接,大幅提升请求效率,降低服务器压力 - ✔️ 强制禁用系统代理:解决 90% 的「下载超时 / 连接失败」问题,这是最关键的优化点!
- ✔️ 断点续传:未下载完成的文件会生成
.part临时文件,重新运行自动续传,避免重复下载 - ✔️ 多线程并发:自定义线程数,并行下载多个文件,效率翻倍
- ✔️ 失败自动重试:网络波动导致的下载失败,自动重试指定次数,无需人工干预
- ✔️ 自动建目录:本地按「Python 版本号」自动创建文件夹,所有文件归类存储,整洁有序
- ✔️ 完整异常捕获:爬取失败、解析失败、下载失败均有详细日志 + 堆栈信息,便于排查问题
- ✔️ 跳过已下载文件:已下载完成的文件,再次运行脚本会自动跳过,节省时间和带宽
三、环境准备(极简,仅 2 个依赖)
该脚本基于 Python3 编写,无复杂依赖,只需要安装两个基础库即可,Python3.6 及以上版本均可运行,Win/Linux/Mac 全平台兼容。
科学环境自己配置,如科学环境有困难,可以私博主
执行下方 pip 命令安装依赖:
bash
运行
pip install requests beautifulsoup4requests:用于发送 HTTP 请求,爬取页面和下载文件beautifulsoup4:用于解析网页 HTML,提取版本目录和文件链接
四、完整可运行代码(直接复制即用,无需修改)
✨ 重点说明:以下是最终完整版代码 ,就是博主自用的版本,所有优化点全部集成,直接复制保存为
.py文件即可运行,无需做任何修改!
部分源码
python
import os
import requests
from bs4 import BeautifulSoup
from concurrent.futures import ThreadPoolExecutor
from urllib.parse import urljoin
import traceback
# -------------------------- 配置参数(按需修改,新手建议默认即可)--------------------------
BASE_URL = "https://www.python.org/ftp/python/" # Python FTP官方主地址,固定不变
SAVE_DIR = "./Python_All_Files" # 本地文件保存根目录,可修改路径
THREAD_NUM = 5 # 并发下载线程数,建议5-10,太多易触发限流
RETRY_TIMES = 3 # 下载失败自动重试次数
TIMEOUT = 30 # 单次请求超时时间(秒)
# ------------------------------------------------------------------------------------------
# 创建全局session对象,复用连接提升效率 + 强制禁用系统代理(核心优化!)
session = requests.Session()
session.trust_env = False # 关键配置:彻底忽略系统的代理环境变量,解决代理导致的下载失败
# 初始化:创建本地保存根目录,不存在则自动创建
os.makedirs(SAVE_DIR, exist_ok=True)
def get_all_version_dirs():
"""核心函数1:爬取Python FTP主站下的所有版本目录链接(如3.11.9/ 3.12.7/)"""
version_dirs = []
try:
# 发送请求获取主页面内容
#******部分源码
return []
def download_file(version_name, file_name, file_url):
"""核心函数3:单文件下载(支持断点续传 + 失败重试)"""
# 为每个版本创建独立的保存目录
version_save_dir = os.path.join(SAVE_DIR, version_name)
#******部分源码
return False
def main():
"""主函数:串联所有流程,启动多线程下载"""
# 1. 获取所有Python版本目录
version_dirs = get_all_version_dirs()
if not version_dirs:
print("❌ 未获取到任何版本目录,程序退出!")
return
# 2. 多线程执行下载任务
success_count = 0
fail_count = 0
with ThreadPoolExecutor(max_workers=THREAD_NUM) as executor:
# 提交所有下载任务到线程池
tasks = []
for version_name, version_url in version_dirs:
target_files = filter_all_files(version_name, version_url)
for file_name, file_url in target_files:
task = executor.submit(download_file, version_name, file_name, file_url)
tasks.append((version_name, file_name, task))
# 统计所有任务的执行结果
for version_name, file_name, task in tasks:
if task.result():
success_count += 1
else:
fail_count += 1
# 打印最终下载统计信息
print("\n" + "=" * 60)
print(f"📊 本次下载任务全部完成!")
print(f"✅ 成功下载文件数:{success_count}")
print(f"❌ 下载失败文件数:{fail_count}")
print(f"📁 所有文件保存路径:{os.path.abspath(SAVE_DIR)}")
print("=" * 60)
# 程序入口
if __name__ == "__main__":
main()完整源码:
https://gitee.com/suwenyun/python_req.git
运行
五、代码核心优化点 & 关键细节详解(重中之重)
很多小伙伴下载别人的脚本会遇到各种问题,核心原因是没看懂关键优化点,这里把本脚本的核心细节和优化逻辑全部讲清楚,帮你彻底理解代码,遇到问题也能自行解决。
✅ 优化点 1:全局 Session + 禁用系统代理 session.trust_env = False
这是本脚本最核心的优化,解决了 90% 的「下载超时 / 连接失败 / 访问被拒绝」问题!
requests.Session():创建全局会话对象,所有请求复用同一个 TCP 连接,避免重复建立连接的开销,大幅提升爬取和下载效率。session.trust_env = False:强制禁用系统代理 !很多小伙伴的电脑配置了全局代理、VPN、梯子等,requests 会默认读取系统代理配置,导致请求 Python 官方 FTP 时走代理,进而触发连接超时 / 拒绝访问。这一行代码可以让 requests彻底忽略系统代理,直接直连服务器,完美解决代理导致的所有问题。
✅ 优化点 2:断点续传的实现原理
断点续传是下载大文件的必备功能,本脚本的实现逻辑非常经典:
- 未下载完成的文件,会以
.part为后缀保存为临时文件 - 重新运行脚本时,会先检测是否存在该临时文件,如果存在,就读取文件大小作为「已下载字节数」
- 通过请求头
headers={"Range": f"bytes={downloaded_size}-"}告诉服务器:从该字节位置开始继续下载,而不是从头开始 - 下载完成后,将
.part临时文件重命名为正式文件,完成下载
✅ 优化点 3:流式下载 stream=True
下载文件时使用 stream=True,表示流式下载,不会一次性将文件全部加载到内存中,而是分块读取、分块写入。
- 优点:即使下载几个 GB 的大文件,也不会占用过多内存,避免程序因内存溢出崩溃
- 分块大小设置为
1024*1024(1MB),是平衡下载速度和内存占用的最优值
✅ 优化点 4:多线程并发下载
使用 concurrent.futures.ThreadPoolExecutor 实现多线程并发,核心优势:
- 网络请求(下载文件)属于「IO 密集型任务」,多线程可以大幅提升效率,同时下载多个文件,节省时间
- 线程数建议设置为
5-10,不是越多越好:线程数过多会导致请求频率过高,触发服务器的限流机制,反而会导致下载失败 / 超时
✅ 优化点 5:自动重试机制 + 完整异常捕获
脚本中对所有网络请求和文件操作都做了异常捕获,同时下载失败时会自动重试指定次数:
- 爬取版本目录失败、解析文件链接失败、下载文件失败,都会打印详细的错误信息和堆栈跟踪,便于排查问题
- 下载文件时,最多重试
RETRY_TIMES次,解决因网络波动导致的偶发性下载失败问题
✅ 优化点 6:全量文件筛选规则
本脚本的筛选规则是:下载每个版本下的所有文件,无任何格式限制
python
运行
if not file_name.endswith("/") and not file_name.startswith("../") and file_name:该规则只会过滤掉「目录链接」「上级目录链接」「空链接」,其余所有文件都会被下载,完美满足「下载每个版本里所有文件」的需求。
六、关键配置参数说明(按需修改,新手建议默认)
脚本顶部的配置参数可以根据自己的需求修改,所有参数都有详细注释,修改规则如下:
| 参数名 | 作用 | 推荐值 | 修改建议 |
|---|---|---|---|
BASE_URL |
Python FTP 官方主地址 | 固定值,无需修改 | 绝对不要改,改了会爬取不到数据 |
SAVE_DIR |
本地文件保存根目录 | ./Python_All_Files |
可修改为任意路径,如 D:/Python_Files |
THREAD_NUM |
并发下载线程数 | 5-10 | 网速快可以适当调高,建议不超过 10 |
RETRY_TIMES |
下载失败重试次数 | 3 | 网络不稳定可以调高到 5 |
TIMEOUT |
单次请求超时时间 | 30 秒 | 网络慢可以调高到 60 秒 |
七、运行效果展示
✅ 运行方式
- 将上述代码保存为
python_download_all.py文件 - 打开命令行 / 终端,切换到该文件所在目录
- 执行命令:
python python_download_all.py - 等待程序运行即可,全程无需任何手动操作!
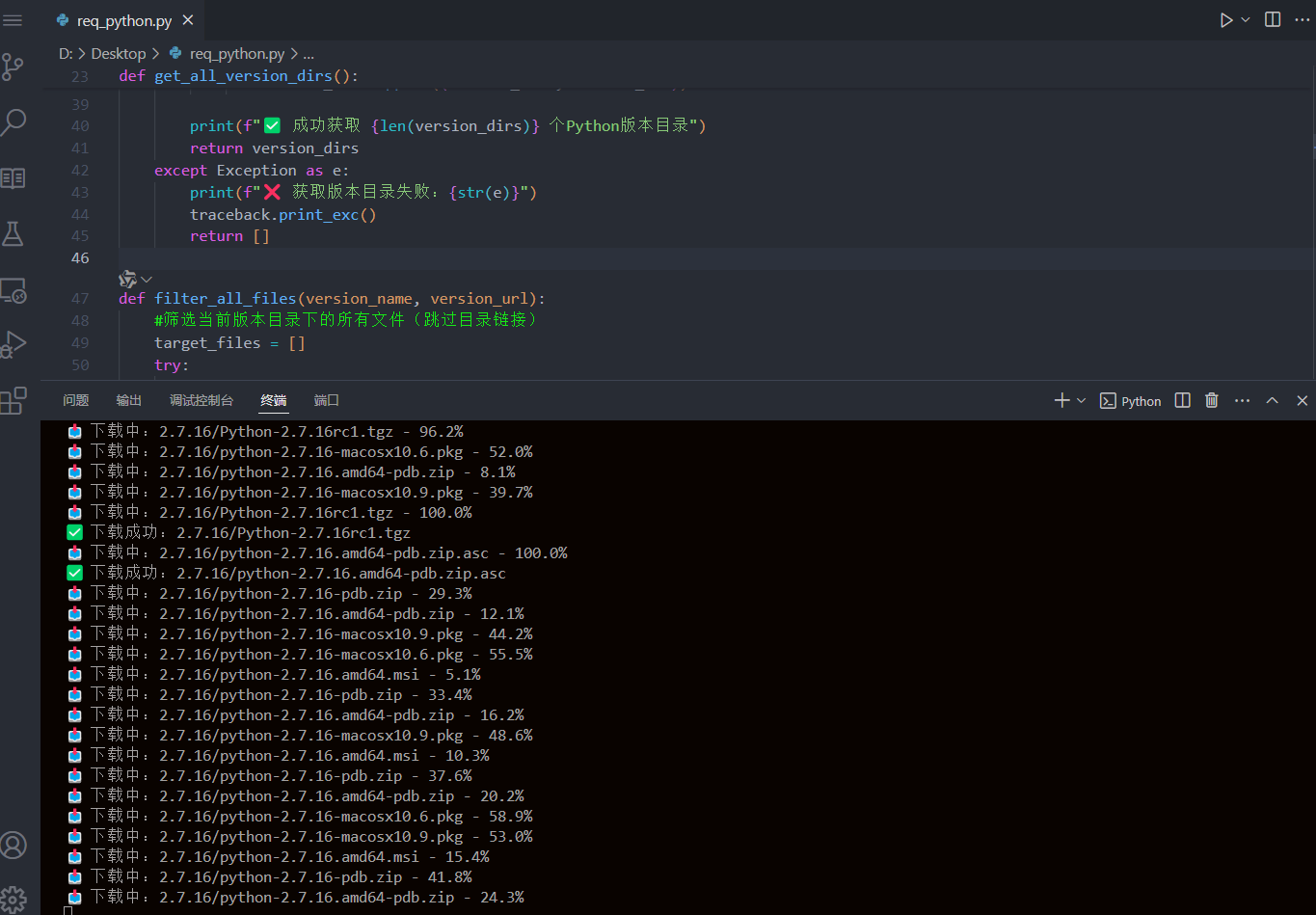
✅ 运行日志示例
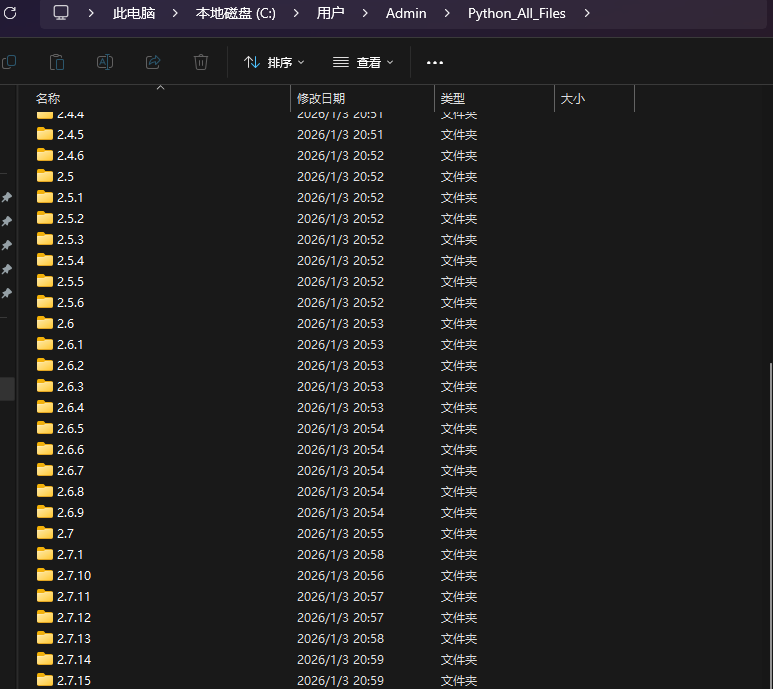
本地文件目录结构
脚本会自动按「Python 版本号」创建文件夹,所有文件归类存储,目录结构非常整洁:
 八、常见问题及解决方案(避坑指南,必看)
八、常见问题及解决方案(避坑指南,必看)
❓ 问题 1:运行脚本提示 ModuleNotFoundError: No module named 'requests'
✅ 解决方案:执行 pip install requests beautifulsoup4 安装依赖库即可。
❓ 问题 2:爬取成功,但下载时一直提示「超时 / 连接失败」
✅ 解决方案:
- 确认是否配置了系统代理 / VPN,本脚本已禁用代理,无需额外操作
- 适当调高
TIMEOUT超时时间(如改为 60)和RETRY_TIMES重试次数(如改为 5) - 降低线程数
THREAD_NUM(如改为 3),减少请求频率
❓ 问题 3:下载的文件大小为 0KB / 损坏
✅ 解决方案:删除该文件和对应的 .part 临时文件,重新运行脚本即可自动重新下载。
❓ 问题 4:提示「磁盘空间不足」
✅ 解决方案:Python 所有版本的全部文件总大小约 50~80GB ,请确保目标磁盘有足够的存储空间,可修改 SAVE_DIR 切换到空间充足的磁盘。
❓ 问题 5:程序运行中被中断,再次运行会重复下载吗?
✅ 不会!脚本支持断点续传和跳过已下载文件,重新运行会自动继续未完成的下载,已下载的文件会直接跳过。
九、拓展功能(可选,按需修改,超实用)
本脚本是完整版,满足绝大多数需求,如果你有个性化需求,可以基于本脚本做简单修改,以下是几个常用的拓展功能,直接复制修改即可:
✨ 拓展 1:只下载指定版本(如只下载 3.10 及以上版本)
在 main() 函数中,获取版本目录后添加筛选逻辑即可:
python
运行
# 获取所有版本目录后,添加筛选
version_dirs = get_all_version_dirs()
# 只下载3.10、3.11、3.12版本
version_dirs = [v for v in version_dirs if v[0].startswith("3.10") or v[0].startswith("3.11") or v[0].startswith("3.12")]✨ 拓展 2:修改分块下载大小(如改为 2MB,提升下载速度)
将下载函数中的分块大小修改即可:
python
运行
# 原代码
for chunk in response.iter_content(chunk_size=1024 * 1024):
# 修改为2MB
for chunk in response.iter_content(chunk_size=2048 * 1024):✨ 拓展 3:关闭下载进度打印(提升下载速度)
下载进度打印会消耗少量性能,如需极致速度,可注释掉进度打印代码:
python
运行
# 注释掉这一行即可
# print(f"📥 下载中:{version_name}/{file_name} - {progress:.1f}%")十、总结
本次分享的 Python 爬虫脚本,是针对「Python 官网 FTP 全量文件下载」的终极解决方案,脚本集成了「多线程、断点续传、禁用代理、自动重试、异常捕获」等所有核心功能,无需手动操作,一键即可下载 Python 所有历史版本的全部文件。
脚本的核心优势:稳定、高效、无坑、易修改,不仅能满足本次的下载需求,还能作为爬虫实战的学习案例,学习「断点续传」「多线程」「requests 高级用法」等知识点。
希望本次分享能帮到大家,如果你有其他个性化需求(如过滤指定格式、下载指定版本),可以在评论区留言,我会及时补充修改方案!
最后
创作不易,如果本教程对你有帮助,欢迎点赞 + 收藏 + 关注,你的支持是我持续分享的动力!✨