㊙️本期内容已收录至专栏《Python爬虫实战》,持续完善知识体系与项目实战,建议先订阅收藏,后续查阅更方便~持续更新中!
㊗️爬虫难度指数:⭐
🚫声明:本数据&代码仅供学习交流,严禁用于商业用途、倒卖数据或违反目标站点的服务条款等,一切后果皆由使用者本人承担。公开榜单数据一般允许访问,但请务必遵守"君子协议",技术无罪,责任在人。

全文目录:
-
-
- [🌟 开篇语](#🌟 开篇语)
- [1️⃣ 标题 && 摘要(Abstract)](#1️⃣ 标题 && 摘要(Abstract))
- [2️⃣ 背景与需求(Why)](#2️⃣ 背景与需求(Why))
- [3️⃣ 合规与注意事项(必写)](#3️⃣ 合规与注意事项(必写))
- [4️⃣ 技术选型与整体流程(What/How)](#4️⃣ 技术选型与整体流程(What/How))
- [5️⃣ 环境准备与依赖安装(可复现)](#5️⃣ 环境准备与依赖安装(可复现))
- [6️⃣ 核心实现:请求层(Fetcher)](#6️⃣ 核心实现:请求层(Fetcher))
- [7️⃣ 核心实现:解析层(Parser)](#7️⃣ 核心实现:解析层(Parser))
- [8️⃣ 数据存储与导出(Storage)](#8️⃣ 数据存储与导出(Storage))
- [9️⃣ 运行方式与结果展示(必写)](#9️⃣ 运行方式与结果展示(必写))
- [🔟 常见问题与排错(老司机的血泪史)](#🔟 常见问题与排错(老司机的血泪史))
- [1️⃣1️⃣ 进阶优化(可选但加分)](#1️⃣1️⃣ 进阶优化(可选但加分))
- [1️⃣2️⃣ 总结与延伸阅读](#1️⃣2️⃣ 总结与延伸阅读)
- [🌟 文末](#🌟 文末)
-
- [📌 专栏持续更新中|建议收藏 + 订阅](#📌 专栏持续更新中|建议收藏 + 订阅)
- [✅ 互动征集](#✅ 互动征集)
-
🌟 开篇语
哈喽,各位小伙伴们你们好呀~我是【喵手】。
运营社区: C站 / 掘金 / 腾讯云 / 阿里云 / 华为云 / 51CTO
欢迎大家常来逛逛,一起学习,一起进步~🌟
我长期专注 Python 爬虫工程化实战 ,主理专栏 👉 《Python爬虫实战》:从采集策略 到反爬对抗 ,从数据清洗 到分布式调度 ,持续输出可复用的方法论与可落地案例。内容主打一个"能跑、能用、能扩展 ",让数据价值真正做到------抓得到、洗得净、用得上。
📌 专栏食用指南(建议收藏)
- ✅ 入门基础:环境搭建 / 请求与解析 / 数据落库
- ✅ 进阶提升:登录鉴权 / 动态渲染 / 反爬对抗
- ✅ 工程实战:异步并发 / 分布式调度 / 监控与容错
- ✅ 项目落地:数据治理 / 可视化分析 / 场景化应用
📣 专栏推广时间 :如果你想系统学爬虫,而不是碎片化东拼西凑,欢迎订阅/关注专栏《Python爬虫实战》
订阅后更新会优先推送,按目录学习更高效~
1️⃣ 标题 && 摘要(Abstract)
摘要 :本文将跳过传统的 HTML 解析(XPath/CSS),带你解锁更高效的 API 抓包策略 。我们将利用浏览器开发者工具(F12)定位目标站点的隐蔽 API,使用 requests 模拟数据请求,直接获取干净的 JSON 格式数据。我们将抓取数据集的 名称 、所属主题 以及 最后更新时间,并自动生成一份 Excel 报表。
读完能获得什么?
- ⚡️ 学会使用浏览器"网络(Network)"面板抓包,找到隐藏的数据接口。
- 🔓 掌握处理
application/json类型 POST 请求的技巧。 - 📊 获得一套通用的zf/企业数据门户采集脚本模板。
2️⃣ 背景与需求(Why)
为什么要爬?
zf开放数据(Open Government Data)涵盖了交通、气象、经济、民生等高价值领域。对于数据分析师来说,我们需要一个"目录"来监控哪些数据更新了,或者通过聚合不同城市的"主题分布",来分析数字化建设的侧重点。
目标站点 :以某典型"市级开放数据平台"为例(通用架构)。
目标数据:
| 字段名 | 字段说明 | 目标价值 |
|---|---|---|
dataset_name |
数据集名称 | 核心标识,如"全市停车场信息" |
subject |
所属主题 | 分类标签,如"交通出行"、"城市建设" |
update_time |
更新时间 | 判断数据鲜活度,过滤僵尸数据 |
3️⃣ 合规与注意事项(必写)
⚠️ 高压线预警:
爬取zf网站,合规性是第一生命线。
- Robots.txt:务必检查。如果明确禁止爬取 API 路径,请立刻停止。
- 频率控制(QPS) :zf服务器通常还需要服务公众查询,带宽有限。绝对禁止多线程高并发!我们将严格限制在单线程,且每次请求间隔 2 秒以上。
- 敏感信息:虽然是"开放数据",但我们只采集"元数据(目录信息)",不涉及任何个人隐私或未公开的涉密数据。
- 态度:我们是数据的"利用者"而非"破坏者"。如果在 Header 里留下了你的联系方式,会显得更专业且友善。
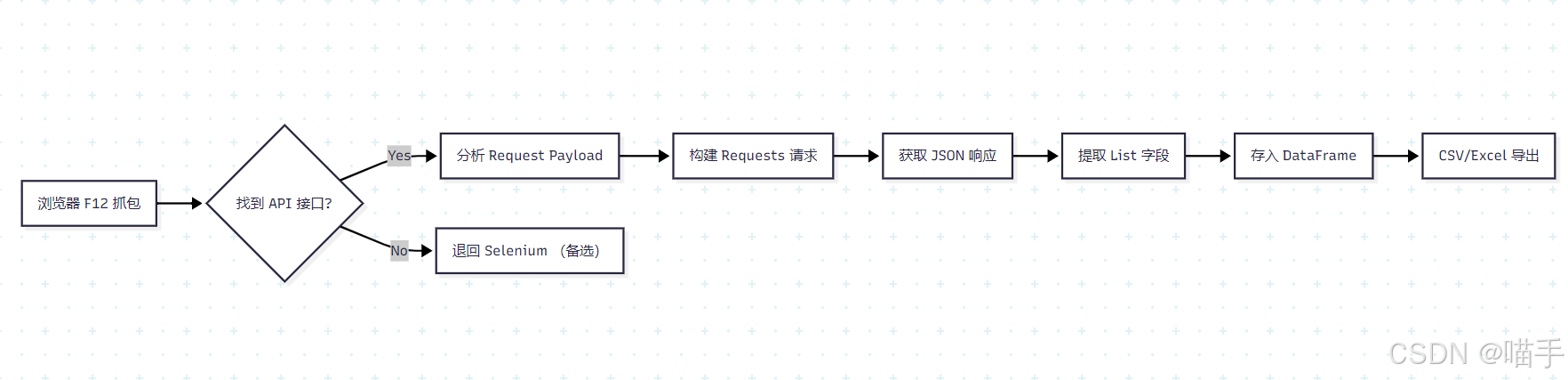
4️⃣ 技术选型与整体流程(What/How)
技术选型:Requests (JSON模式) + Pandas
-
为什么不用 BeautifulSoup? 因为现代数据门户大多是动态渲染(Vue/React/Angular)。你右键"查看源代码"可能只能看到一个空的
<div id="app"></div>。pp">`。数据都在 JSON 接口里!- 流程图:
5️⃣ 环境准备与依赖安装(可复现)
Python 版本:3.8+
依赖安装:
bash
pip install requests pandas openpyxlrequests: 处理 HTTP 交互。pandas+openpyl: 处理数据表格,支持导出为 Excel (.xlsx),比 CSV 对中文支持更友好。
项目结构:
text
gov_data_miner/
├── output/ # 结果保存
├── spider.py # 核心代码
└── config.py # 存放 URL 和 Headers 配置6️⃣ 核心实现:请求层(Fetcher)
这一步是成败关键。我们需要模拟浏览器的 **POST 请求。
🔍 侦探时间(How to find the API):
- 打开目标数据门户的"数据集列表"页。
- 按
F12打开开发者工具,切到 Network (网络) -> Fetch/XHR。- 点击网页上的"下一页"或刷新。
- 观察列表里出现的请求,通常叫
list,search, `query 之类的。- 点击该请求,查看 Payload (载荷) 和 Preview (响应预览)。
python
# spider.py
import requests
import time
import random
import json
class DataPortalFetcher:
def __init__(self):
# 伪装成浏览器,Headers 越全越好
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Content-Type': 'application/json;charset=UTF-8',
'Referer': 'https://data.example-city.gov.cn/data/', # 必填!很多接口校验 Referer
'Origin': 'https://data.example-city.gov.cn'
}
# 假设我们抓到了这个 API 地址 (示例地址)
self.api_url = "https://data.example-city.gov.cn/api/v1/dataset/list"
def fetch_page(self, page_num, page_size=10):
"""抓取单页数据"""
# 根据 F12 抓包看到的 Payload 结构来构造
payload = {
"page": page_num,
"size": page_size,
"order": "updateTime", # 按更新时间排序
"keywords": "" # 搜索关键词为空,即全量
}
try:
# ✅ 随机休眠,模拟真人阅读,防封核心!
time.sleep(random.uniform(1.5, 3.5))
# 注意:大多数现代 API 需要用 json=payload,而不是 data=payload
response = requests.post(self.api_url, headers=self.headers, json=payload, timeout=10)
if response.status_code == 200:
return response.json() # 直接转为字典
else:
print(f"❌ 状态码异常: {response.status_code}")
return None
except Exception as e:
print(f"❌ 请求报错: {e}")
return None7️⃣ 核心实现:解析层(Parser)
既然拿到的是 JSON,那就不用正则也不用 XPath 了,直接按 字典键值对(Key-Value) 取值,爽滑无比。
python
class DataParser:
def parse_json(self, json_data):
"""解析 JSON 响应,提取核心字段"""
cleaned_list = []
# 1. 防御性编程:检查 JSON 结构是否符合预期
# 假设结构是: {'code': 200, 'data': {'list': [...], 'total': 100}}
if not json_data or json_data.get('code') != 200:
print("⚠️ 接口返回 Code 非 200 或数据为空")
return []
raw_list = json_data.get('data', {}).get('list', [])
for item in raw_list:
# 2. 字段提取与容错
# 不同的网站字段名不同,需要根据 Preview 里的内容调整
dataset_name = item.get('name') or item.get('title', '未知名称')
# 主题有时候是个对象 {'id':1, 'name':'交通'},有时候直接是字符串
subject = item.get('subjectName') or item.get('topic', '未分类')
# 时间戳处理:有些返回 1678888888 (毫秒),有些返回 "2023-01-01"
update_time = item.get('updateTime') or item.get('gmtModified')
cleaned_list.append({
"名称": dataset_name,
"主题": subject,
"更新时间": update_time,
"来源API": "example-city-api"
})
return cleaned_list8️⃣ 数据存储与导出(Storage)
这次我们用 Excel 格式(.xlsx),因为它对业务人员查看更友好,且不用担心 CSV 在 Excel 打开时的乱码问题。
python
import pandas as pd
import os
from datetime import datetime
class ExcelStorage:
def save(self, data_list, filename="dataset_report.xlsx"):
if not data_list:
print("⚠️ 没有数据需要保存")
return
df = pd.DataFrame(data_list)
# 简单清洗:转换一下时间格式(如果拿到的是毫秒时间戳)
# df['更新时间'] = pd.to_datetime(df['更新时间'], unit='ms')
output_dir = "output"
os.makedirs(output_dir, exist_ok=True)
file_path = os.path.join(output_dir, filename)
# 导出 Excel
df.to_excel(file_path, index=False)
print(f"✅ 报表已生成: {file_path} (共 {len(df)} 条)")9️⃣ 运行方式与结果展示(必写)
python
# main.py (入口)
# 假设我们要抓前 3 页
def main():
print("🚀 开放数据门户爬虫启动...")
fetcher = DataPortalFetcher()
parser = DataParser()
storage = ExcelStorage()
all_data = []
# 循环抓取前 3 页
for page in range(1, 4):
print(f"📡 正在抓取第 {page} 页...")
json_data = fetcher.fetch_page(page)
if json_data:
batch_data = parser.parse_json(json_data)
print(f" ↳ 本页提取到 {len(batch_data)} 条数据")
all_data.extend(batch_data)
else:
print(" ↳ 本页抓取失败,停止后续任务。")
break
# 统一保存
print(f"💾 正在保存全量数据 ({len(all_data)} 条)...")
storage.save(all_data)
print("🎉 任务完成!")
if __name__ == "__main__":
main()示例运行结果:
text
🚀 开放数据门户爬虫启动...
📡 正在抓取第 1 页...
↳ 本页提取到 10 条数据
📡 正在抓取第 2 页...
↳ 本页提取到 10 条数据
📡 正在抓取第 3 页...
↳ 本页提取到 10 条数据
💾 正在保存全量数据 (30 条)...
✅ 报表已生成: output/dataset_report.xlsx (共 30 条)
🎉 任务完成!Image of Excel spreadsheet showing columns: Name, Subject, Update Time
🔟 常见问题与排错(老司机的血泪史)
-
JSON 解析报错 (JSONDecodeError)
- 现象 :
requests.exceptionsJSONDecodeError - 原因:你以为返回的是 JSON,其实服务器报错返回了 HTML(比如 500 错误页面),或者触发了 WAF 防火墙验证页。
- *解 :先打印
response.text看看内容到底是啥,不要盲目.json()。。
- 现象 :
-
缺少字段
- 现象:有的行有"主题",有的行是 `None。
- 原因:zf数据录入质量参差不齐。
- 解法 :使用
.get('key', '默认值')是必须的!千万别用data'key']直接取,会报错崩掉整个程序。
-
时间戳坑
-
- 现象 :
1672531200000这种数字。
- 现象 :
- 解法 :这是毫秒级 Unix 时间戳。用
datetime.fromtimestamp(ts/1000)转成人话。
-
-
Header 里的加密参数
- 现象 :请求头里有个
X-Sign: a8f9c2...,没有这个参数请求就 403。 - 解法 :这就触及到 JS 逆向 的深水区了。如果遇到这种情况,新手建议换个没加密的门户练手,或者改用 Selenium/Playwright 这种"所见即所得"的工具来绕过签名生成。
- 现象 :请求头里有个
1️⃣1️⃣ 进阶优化(可选但加分)
- 全量翻页自动化 :目前的 demo 只写了前 3 页。进阶版应该先读取第一页返回的
total(总数) 字段,计算出总页数total_pages = total // page_size + 1,然后用for循环跑完所有页。 - 增量爬取 :记录上一次爬取到的最新
update_time。下次运行通过 API 的排序功能,只抓取时间晚于该节点的数据,实现"每日更新"。 - 数据清洗管道 :把"主题"字段里的乱七八糟的分隔符(如
交通; 出行或交通_出行)统一清洗为标准列表。
1️⃣2️⃣ 总结与延伸阅读
复盘 :
这篇教程带你走出了"HTML 解析"的舒适区,迈向了更底层的 API 交互。对于开放数据平台这类现代化网站,这才是最正统、最高效的打法。你不仅学会了爬虫,还顺便复习了 HTTP 协议和 JSON 结构,一举两得!
下一步:
-
- 可视化:拿到数据后,试试用 ECharts 或 Tableau 做一个"各领域数据开放热度图"。
- 深挖 :既然拿到了列表,能不能根据列表里的
dataset_id,再发起请求去下载具体的 CSV/XLS 文件?(提示:是个下载链接的 URL 拼接问题)。
感觉如何?这种"直接调接口"的感觉是不是比用正则去匹配 HTML 代码爽多了?
如果你想针对具体的某个城市(比如北京或上海)进行实战调整,或者对如何查看 Network 面板有疑问,告诉我,我来给你做 1 对 1 辅导!
🌟 文末
好啦~以上就是本期 《Python爬虫实战》的全部内容啦!如果你在实践过程中遇到任何疑问,欢迎在评论区留言交流,我看到都会尽量回复~咱们下期见!
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦~
三连就是对我写作道路上最好的鼓励与支持! ❤️🔥
📌 专栏持续更新中|建议收藏 + 订阅
专栏 👉 《Python爬虫实战》,我会按照"入门 → 进阶 → 工程化 → 项目落地"的路线持续更新,争取让每一篇都做到:
✅ 讲得清楚(原理)|✅ 跑得起来(代码)|✅ 用得上(场景)|✅ 扛得住(工程化)
📣 想系统提升的小伙伴:强烈建议先订阅专栏,再按目录顺序学习,效率会高很多~

✅ 互动征集
想让我把【某站点/某反爬/某验证码/某分布式方案】写成专栏实战?
评论区留言告诉我你的需求,我会优先安排更新 ✅
⭐️ 若喜欢我,就请关注我叭~(更新不迷路)
⭐️ 若对你有用,就请点赞支持一下叭~(给我一点点动力)
⭐️ 若有疑问,就请评论留言告诉我叭~(我会补坑 & 更新迭代)
免责声明:本文仅用于学习与技术研究,请在合法合规、遵守站点规则与 Robots 协议的前提下使用相关技术。严禁将技术用于任何非法用途或侵害他人权益的行为。