
论文链接:https://arxiv.org/pdf/2512.25075
项目链接:https://zheninghuang.github.io/Space-Time-Pilot/
亮点直击
-
首次实现了联合空间和时间控制的视频扩散模型: SpaceTimePilot 是首个能够从单个单目视频实现对动态场景进行联合空间(摄像机视角)和时间(运动序列)控制的视频扩散模型。
-
引入动画时间嵌入机制: 提出了一种有效的动画时间嵌入机制,能够显式控制输出视频的运动序列,实现对时间进程的精细操控,例如慢动作、反向播放和子弹时间。
-
提出时间扭曲训练方案: 针对缺乏具有连续时间变化的配对视频数据集的问题,本文设计了一种简单有效的时间扭曲训练方案,通过增强现有多视角数据集来模拟多样化的时间差异,从而帮助模型学习时间控制并实现时空解耦。
-
构建 Cam×Time 合成数据集: 构建了第一个合成的时空全覆盖渲染数据集 Cam×Time,该数据集提供了场景中完全自由的时空视频轨迹,通过密集的时空采样为模型学习解耦的 4D 表示提供了关键监督。
-
改进摄像机条件机制: 提出了一种改进的摄像机条件机制,允许从第一帧开始改变摄像机,并引入源感知摄像机控制,将源视频和目标视频的摄像机姿态联合注入扩散模型,显著提高了摄像机控制的精度和鲁棒性。
-
支持更长的视频生成: 通过采用简单的自回归视频生成策略,SpaceTimePilot 能够生成任意长的连续视频片段,实现灵活的多轮生成,并支持跨越扩展时空轨迹的探索。

总结速览
解决的问题
-
缺乏对动态场景中空间变化(摄像机视角)和时间演变(场景运动)的完全解耦控制。
-
在 novel viewpoints 下进行 4D 重建通常会出现伪影,且渲染质量受限。
-
当前的视频扩散模型尽管在空间视点控制方面有所进展,但无法在空间和时间上自由导航场景,即缺乏完整的 4D 探索能力。
-
训练能够同时处理多种时间播放形式和摄像机运动的模型,在现有数据集上是困难的,因为它们缺乏足够的时间变化覆盖或无法提供具有连续时间变化的相同动态场景的配对视频。
提出的方案
本文提出了 SpaceTimePilot,一个视频扩散模型,旨在通过以下方式解决上述问题:
-
引入一种新的"动画时间"概念,将场景动态的时间状态独立于摄像机控制,从而实现空间和时间控制的自然解耦。
-
设计了一种有效的动画时间嵌入机制,用于在扩散过程中显式控制输出视频的运动序列。
-
提出了一种简单而有效的时间扭曲训练方案,通过重新利用现有的多视角数据集来模拟时间差异,以解决缺乏合适训练数据的问题。
-
引入了一个名为 Cam×Time 的合成时空全覆盖渲染数据集,它在一个场景中提供了完全自由的时空视频轨迹,以增强控制的精确性。
-
改进了摄像机条件机制,允许从第一帧开始改变摄像机,并使用源感知摄像机条件化,将源视频和目标视频的摄像机姿态联合注入扩散模型,以提供明确的几何上下文。
-
采用自回归视频生成策略,通过以先前生成的片段和源视频为条件,生成更长的视频片段,从而支持更长的视频序列。
应用的技术
-
潜在视频扩散骨干:采用类似于现代文本到视频基础模型的架构,包含用于潜在压缩的 3D 变分自编码器(VAE)和在多模态令牌上操作的基于 Transformer 的去噪模型(DiT)。
-
动画时间嵌入机制:通过正弦时间嵌入和 1D 卷积层将时间控制参数 编码并注入到扩散模型中,从而实现对视频运动序列的显式控制。
-
改进的摄像机条件化 :借鉴 ReCamMaster,并在此基础上进行改进,通过
E_cam(c)编码摄像机轨迹,并进一步结合源感知摄像机条件化,将源视频 和目标视频 的摄像机姿态联合注入模型。 -
时间扭曲训练方案:通过对现有多视角视频数据集应用反向、加速、冻结、分段慢动作和之字形运动等时间扭曲操作,来模拟多样化的时间变化。
-
合成数据集 Cam×Time:在 Blender 中渲染,通过详尽采样摄像机-时间网格来提供密集且系统覆盖的训练数据。
达到的效果
-
统一的时空控制:在单个扩散模型中对摄像机和时间进行统一控制,能够沿任意时空轨迹生成连续且连贯的视频。
-
解耦的空间和时间探索:能够独立改变摄像机视角和运动序列,实现对动态场景在空间和时间上的连续任意探索。
-
灵活的运动序列重定时:能够生成具有重新计时运动序列的新视频,包括慢动作、反向运动和子弹时间。
-
精确的摄像机轨迹控制:能够根据给定的摄像机轨迹精确控制摄像机运动。
-
强大的性能:在真实世界和合成数据上均表现出清晰的时空解耦,并与现有工作相比取得了强大的结果。
-
支持更长的视频生成:通过自回归推理方案,能够生成更长、更连贯的视频,实现超出输入视频的视点变化,例如旋转到物体后方或从低角度切换到高空鸟瞰视角,同时保持视觉和运动的连贯性。
架构方法
本文的方法 SpaceTimePilot 通过在生成过程中解耦空间和时间因素,实现了子弹时间(bullet-time)和从新视点重新计时播放等效果,如上图 1 所示。
解耦空间和时间
本文通过双重方法实现空间和时间解耦:专用的时间表示和专门的数据集。
时间表示
最近的视频扩散模型包括用于潜在帧索引 的位置嵌入,例如 RoPE(). 然而,本文发现使用 RoPE() 进行时间控制是无效的,因为它会干扰摄像机信号:RoPE() 通常同时限制时间和摄像机运动。为了解决空间和时间解耦问题,本文引入了一个专用的时间控制参数 。通过操纵 ,本文可以控制合成视频 的时间进程。例如,将 设置为常数会将 锁定到 中的特定时间戳,而反转帧索引会以反向播放 。
时间嵌入。 为了将时间控制注入扩散模型,本文分析了几种方法。首先,本文可以像使用帧索引一样编码时间,使用 RoPE 嵌入。然而,本文发现它不太适合时间控制。相反,本文采用应用于潜在帧 级别的正弦时间嵌入,它提供了每个帧时间位置的稳定连续表示,并在精度和稳定性之间提供了有利的权衡。本文进一步观察到每个潜在帧对应一个连续的时间块,并提出使用原始帧索引 的嵌入来支持更精细的时间控制粒度。为了实现这一点,本文引入了一种时间编码方法 ,其中 。本文首先计算正弦时间嵌入来表示时间序列,,,其中 。接下来,本文应用两个 1D 卷积层逐步将这些嵌入投影到潜在帧空间,。最后,本文将这些时间特征添加到摄像机特征和视频令牌嵌入中,更新等式 (1) 如下:
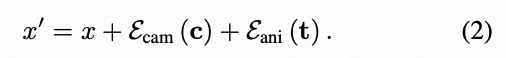
在下文中,本文将本文的方法与替代条件策略进行比较,例如使用正弦嵌入,其中 直接定义在 中,以及使用 MLP 而不是 1D 卷积进行压缩。本文定性和定量地展示了本文提出的方法的优势。
数据集
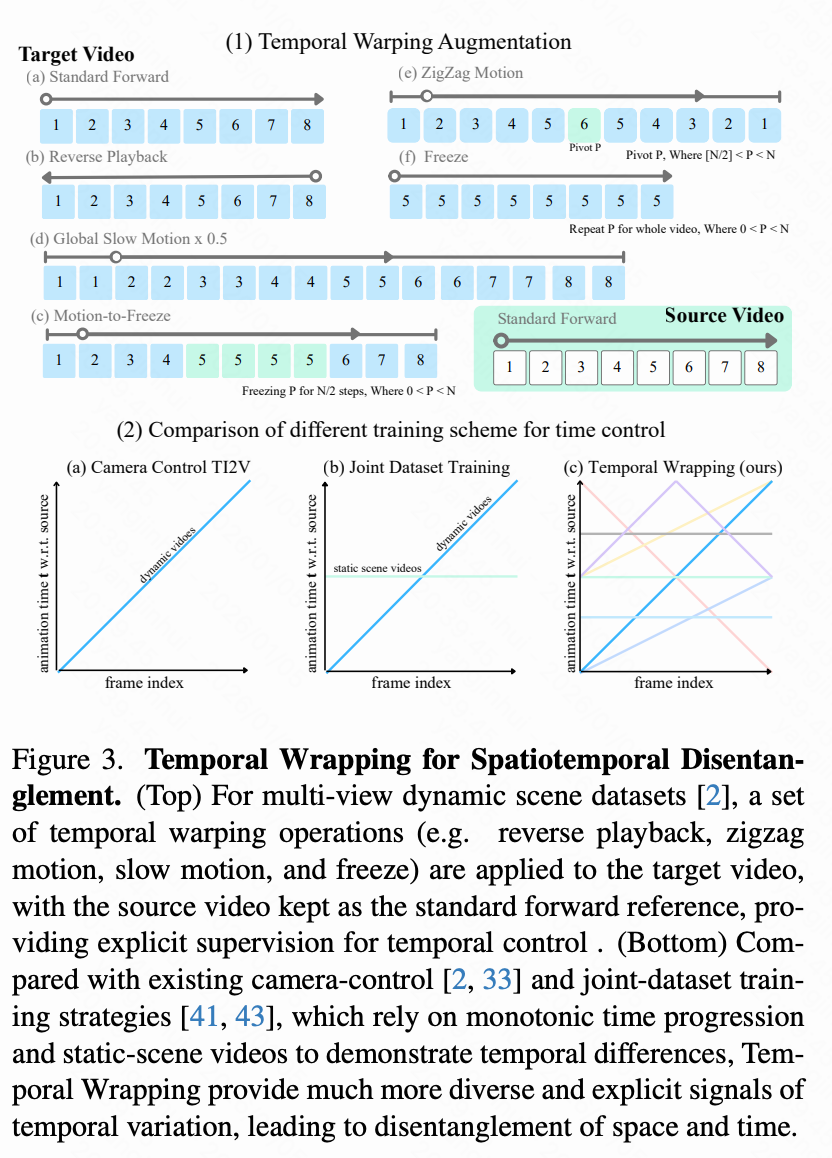
为了在本文的方法中实现时间操作,本文需要包含时间重映射示例的配对训练数据。实现时空解耦进一步需要包含摄像机和时间控制示例的数据。据本文所知,目前没有公开可用的数据集满足这些要求。只有少数先前的工作,例如 4DiM和 CAT4D,尝试解决时空解耦问题。一种常见的策略是在静态场景数据集和多视图视频数据集上联合训练。这些数据集中有限的控制可变性导致时间演变和空间运动之间的混淆,从而导致纠缠或不稳定的行为。本文通过使用时间扭曲增强现有多视图视频数据并提出新的合成数据集来解决这一限制。
时间扭曲增强。 本文引入了简单的增强功能,为多视图视频数据集添加可控的时间变化。在训练期间,给定源视频 和目标视频 ,本文将时间扭曲函数 应用于目标序列,生成扭曲视频 。源动画时间戳均匀采样,。扭曲时间戳 引入非线性时间效应(参见下图 3 顶部 b-e):(i) 反向,(ii) 加速,(iii) 冻结,(iv) 分段慢动作,和 (v) 之字形运动,其中动画重复反向。在这些增强之后,配对视频序列 在摄像机轨迹和时间动态方面都存在差异,为模型提供了学习解耦时空表示的清晰信号。
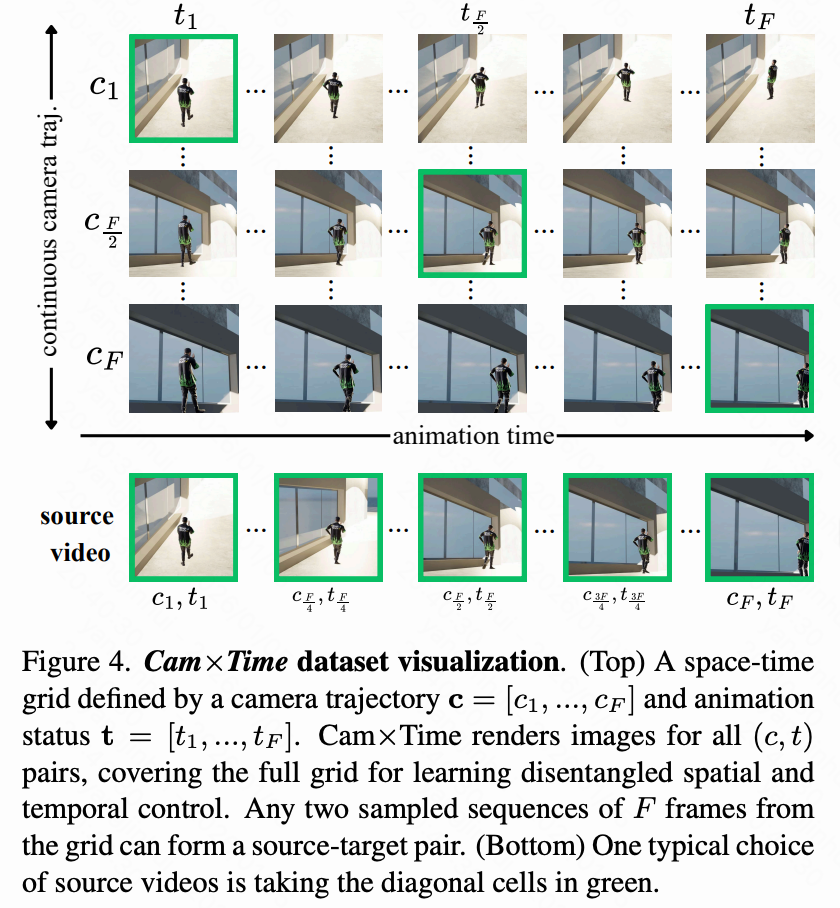
用于精确时空控制的合成 Cam×Time 数据集。虽然本文的时间扭曲增强鼓励空间和时间因素之间强烈的解耦,但实现细粒度和连续控制------即平滑精确地调整时间动态------受益于系统覆盖这两个维度的数据集。为此,本文构建了 Cam×Time,一个新的在 Blender 中渲染的合成时空数据集。给定摄像机轨迹和一个动画主题,Cam×Time 详尽地采样摄像机-时间网格,捕获跨越不同摄像机视角和时间状态组合 的每个动态场景,如下图 4 所示。源视频通过采样密集网格的对角线帧(下图 4(底部))获得,而目标视频通过更自由形式的连续序列采样获得。本文将 Cam×Time 与现有数据集进行比较,如下表 1 所示。虽然如23, 32, 53等是具有复杂摄像机路径注释的真实视频,但它们要么不提供时间同步的视频对,要么只提供静态场景对。合成多视图视频数据集提供动态视频对,但不允许训练时间控制。相比之下,Cam×Time 能够对摄像机运动和时间动态进行细粒度操作,从而实现子弹时间效果、运动稳定和灵活的控制组合。本文将 Cam×Time 的一部分指定为测试集,旨在将其用作可控视频生成的基准。本文将发布它以支持未来对细粒度时空建模的研究。

精确的摄像机条件化
本文的目标是实现目标视频中的完整摄像机轨迹控制。相比之下,先前的 Novel View Synthesis 方法假设源视频和目标视频的第一帧是相同的,并且目标摄像机轨迹是相对于它定义的。这源于两个限制。首先,现有方法忽略了源视频轨迹,导致使用目标轨迹计算的源特征不佳,以保持一致性:
其次,它在数据集上进行训练,其中源视频和目标视频的第一帧总是相同的。后一个限制在本文的训练数据集设计中得到了解决。为了克服前者,本文设计了一种源感知摄像机条件化。本文使用预训练的姿态估计器估计源视频和目标视频的摄像机姿态,并将它们联合注入扩散模型以提供明确的几何上下文。因此,等式 (2) 扩展为:
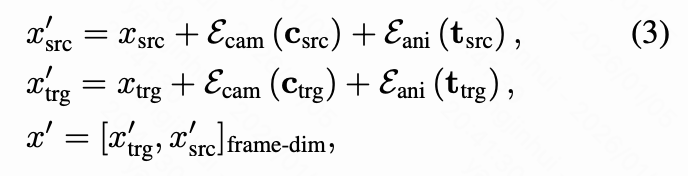
其中 表示 DiT 模型的输入,它是目标和源令牌沿帧维度的连接。这种公式化为模型提供了源和目标摄像机上下文,从而实现了空间一致的生成和对摄像机轨迹的精确控制。
支持更长的视频片段
最后,为了展示本文摄像机和时间控制的全部潜力,本文采用了一种简单的自回归视频生成策略,生成每个新片段 ,以先前生成的片段 和源视频 为条件,以生成更长的视频。
为了在推理过程中实现此功能,本文需要扩展本文的训练场景以支持以两个视频为条件,其中一个作为 ,另一个作为 。源视频 直接取自多视图数据集或本文的合成数据集,如前所述。 的构建方式与 类似------使用时间扭曲增强或从本文合成数据集的密集时空网格中采样。当应用时间扭曲时, 和 可能来自代表相同时间间隔的相同或不同的多视图序列。为了保持完全的控制灵活性,本文不强制 和 之间有任何其他明确的关联,除了指定相对于选定源视频帧的摄像机参数。
请注意,不约束源视频和目标视频共享相同的起始帧(如前文所述)对于在更长序列中实现灵活的摄像机控制至关重要。例如,这种设计可以实现扩展的子弹时间效果:本文可以首先围绕选定点生成高达 45° 的旋转(),然后从 45° 继续到 90°()。以两个连续的源片段为条件允许模型利用新生成视点的信息。在子弹时间示例中,以先前生成的视频为条件允许模型整合所有新合成视点的信息,而不是仅仅依赖于源视频中相应时刻的视点。
实验
与最先进基线的比较
时间控制评估
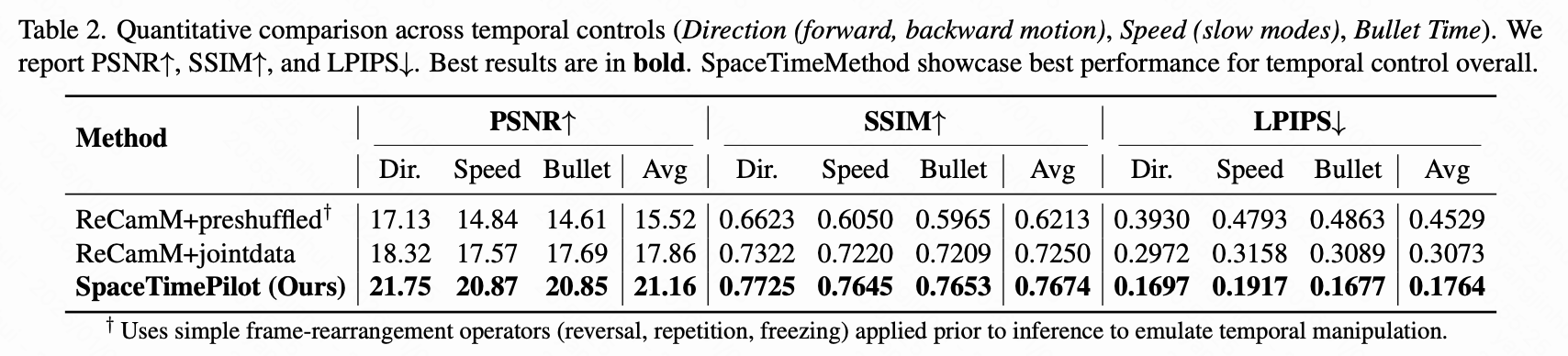
首先,本文评估了模型的时间重排能力。为了排除摄像机控制引起的误差,本文在固定摄像机姿态下对 SpaceTimePilot 进行条件化,仅改变时间控制信号。实验在未公开的 Cam×Time 测试集上进行,该测试集包含 50 个场景,这些场景以密集的全网格轨迹渲染,可以重新计时为任意时间序列。对于每个测试用例,本文使用一个移动摄像机的源视频,但将目标摄像机轨迹设置为第一帧姿态。然后,本文应用一系列时间控制信号,包括反向、子弹时间、之字形、慢动作和正常播放,以合成相应的重定时输出。由于本文拥有所有时间配置的地面真实帧,因此本文报告了感知损失:PSNR、SSIM 和 LPIPS。
本文考虑了两个基线:(1)ReCamM+preshuffled:原始 ReCamMaster 结合输入重新排序;(2)ReCamM+jointdata:遵循 41, 43,本文使用额外的静态场景数据集,如 18, 53 来训练 ReCamMaster,这些数据集仅提供单一的时间模式。
虽然帧混洗在简单场景中可能成功,但它无法解耦摄像机和时间控制。如下表 2 所示,这种方法表现出最弱的时间可控性。尽管结合静态场景数据集提高了性能,尤其是在子弹时间类别中,但依赖单一时间控制模式仍然不足以实现鲁棒的时间一致性。相比之下,SpaceTimePilot 在所有时间配置中始终优于所有基线。
视觉质量评估
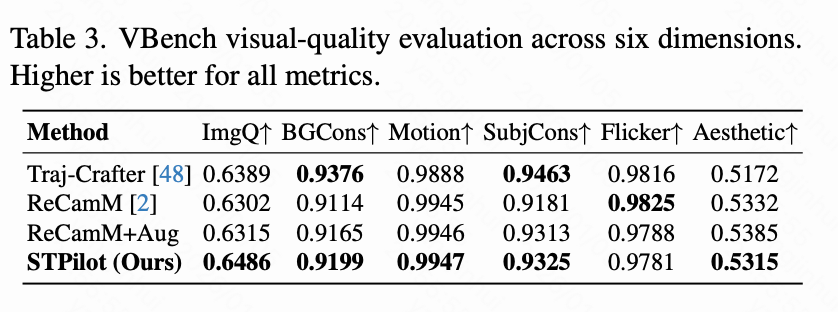
接下来,本文使用 VBench评估了本文 1800 个生成视频的感知真实感。本文报告了所有标准视觉质量指标,以提供对生成保真度的全面评估。如下表 3 所示,本文模型实现了与基线相当的视觉质量。
摄像机控制评估
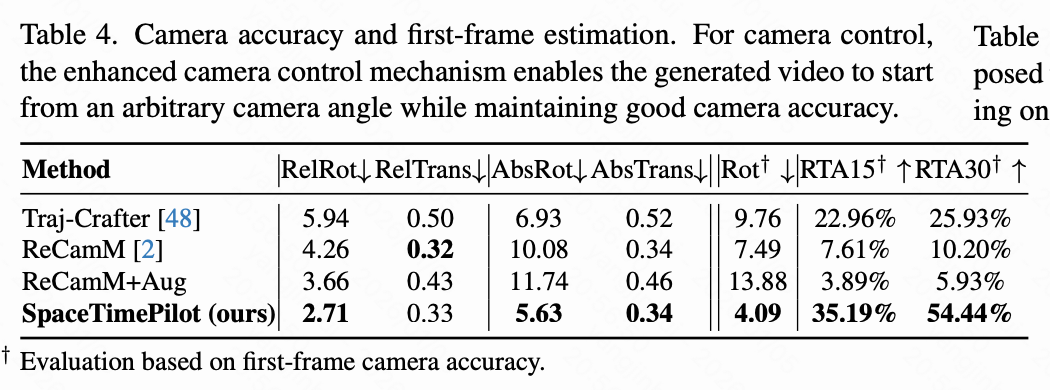
最后,本文评估了前文中详述的摄像机控制机制的有效性。与上述依赖合成地面真实视频的时间重排评估不同,本文构建了一个由 OpenVideoHD组成的真实世界 90 视频评估集,涵盖了各种动态人类和物体运动。每种方法在 20 种摄像机轨迹下进行评估:10 种从与源视频相同的初始姿态开始,10 种从不同的初始姿态开始,总共生成 1800 个视频。本文应用 SpatialTracker-v2从生成的视频中恢复摄像机姿态,并将其与相应的输入摄像机姿态进行比较。为了确保一致的比例,本文对齐了前两个摄像机位置的幅度。轨迹精度使用 RotErr 和 TransErr 根据 8 进行量化,采用两种协议:(1)评估相对于第一帧定义的原始轨迹(相对协议,RelRot,RelTrans),以及(2)在与第一帧的估计姿态对齐后进行评估(绝对协议,AbsRot,AbsTrans)。具体来说,本文通过乘以由 DUSt3R估计的生成帧和源第一帧之间的相对姿态来变换恢复的原始轨迹。本文还将此 DUSt3R 姿态与目标轨迹的初始姿态进行比较,并报告 RotErr、RTA@15 和 RTA@30,因为平移幅度是尺度模糊的。
为了仅测量源摄像机条件化的影响,本文考虑了原始 ReCamMaster(ReCamM) 和两种变体。由于 ReCamMaster 最初是在源视频和目标视频的第一帧相同的数据集上训练的,因此模型总是复制第一帧,而不管输入摄像机姿态如何。为了公平起见,本文使用更多数据增强功能重新训练 ReCamMaster,以包括不相同的起始帧,表示为 ReCamM+Aug。接下来,本文根据等式 3 额外使用源摄像机 对模型进行条件化,表示为 ReCamM+Aug+。最后,本文还报告了 TrajectoryCrafter的结果。
在下表 4 中,本文观察到绝对协议始终产生更高的误差,因为轨迹不仅必须匹配整体形状(相对协议),而且还必须在位置和方向上正确对齐。有趣的是,ReCamM+Aug 产生的误差高于原始 ReCamM,而结合源摄像机 产生了最佳的整体性能。这表明,如果没有明确参考 ,暴露于更多具有不同起始帧的增强视频反而会混淆模型。新引入的源视频轨迹 条件信号在所有指标上实现了显着更好的摄像机控制精度、更可靠的第一帧对齐,以及比所有基线更忠实地遵循完整轨迹。
定性结果
除了定量评估,本文还通过视觉示例展示了 SpaceTimePilot 的优势。如下图 6 所示,只有本文的方法正确合成摄像机运动(红色框)和动画时间状态(绿色框)。ReCamMaster 虽然能很好地处理摄像机控制,但无法修改时间状态,例如实现反向播放。相比之下,TrajectoryCrafter 被反向帧混洗所迷惑,导致最后一个源帧的摄像机姿态(蓝色框)错误地出现在生成视频的第一帧中。更多视觉结果可见下图 5。


消融研究
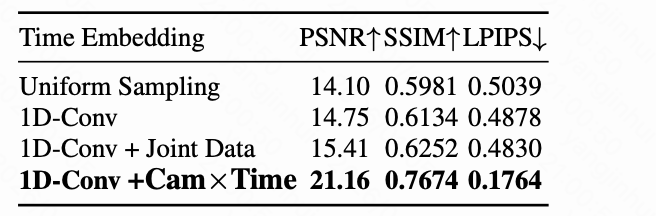
为了验证所提出的时间嵌入模块的有效性,如下表 5 所示,本文遵循上文中的时间控制评估设置,并将本文的 1D 卷积时间嵌入与上文中讨论的几种变体和替代方案进行比较:(1)均匀采样:将 81 帧嵌入均匀采样到 21 帧序列,这等效于在潜在帧 级别采用正弦嵌入;(2)1D-Conv:使用 1D 卷积层从 压缩到 ,并使用 ReCamMaster 和 SynCamMaster 数据集进行训练。(3)1D-Conv+jointdata:第 2 行,但额外包含静态场景数据集。(4)1D-Conv(本文):第 2 行,但包含所提出的 Cam×Time。本文观察到,通过将细粒度 维嵌入压缩到 维空间来学习紧凑表示的 1D 卷积方法明显优于直接在粗略 级别构建正弦嵌入。结合静态场景数据集仅带来了有限的改进,这可能是由于其有限的时间控制模式。相比之下,使用所提出的 Cam×Time 始终在所有三个指标上带来最大的收益,证实了本文新引入的数据集的有效性。此外,如下图 7 所示,本文展示了使用均匀采样和 MLP 代替 1D 卷积压缩时间控制信号的子弹时间结果的视觉比较。均匀采样产生了明显的伪影,MLP 压缩器导致摄像机运动突然,而 1D 卷积有效地锁定了动画时间并实现了平滑的摄像机运动。

结论
SpaceTimePilot,这是第一个提供完全解耦空间和时间控制的视频扩散模型,能够从单个单目视频进行 4D 时空探索。本文方法引入了一种新的"动画时间"表示,并结合了利用源姿态和目标姿态的源感知摄像机控制机制。这得到了合成 Cam×Time 和时间扭曲训练方案的支持,这些方案提供了密集的时空监督。这些组件允许精确的摄像机和时间操作、任意初始姿态以及灵活的多轮生成。在广泛的实验中,SpaceTimePilot 始终超越最先进的基线,显着提高了摄像机控制精度,并可靠地执行复杂的重新计时效果,例如反向播放、慢动作和子弹时间。
参考文献
1 SpaceTimePilot: Generative Rendering of Dynamic Scenes Across Space and Time