引言
自 CLIP 问世以来,它已经成为视觉-语言领域的重要基石,不仅在零样本分类与检索中表现优异,还被广泛用作多模态大模型的视觉编码器。然而,现有 CLIP 模型大多依赖英文数据训练,面对占全球网页内容 50.9% 的非英文数据(Wikipedia, 2025),却难以有效利用,即便有多语言版本(如 mSigLIP、SigLIP 2),也普遍存在一个问题------一旦引入非英语数据,英语性能反而下降,这种现象被称为 "多语言诅咒(curse of multilinguality)"。
Meta 团队提出了 Meta CLIP 2,它是首个基于全球网页级图像 - 文本对从头训练的 CLIP 模型,通过精心设计的元数据构建、筛选算法和训练框架,不仅打破了多语言诅咒,还实现了英文与非英文数据的互利共赢。
多语言挑战与研究思路
Meta CLIP 2 的核心突破始于对现有 CLIP 全球扩展两大痛点的针对性解决。
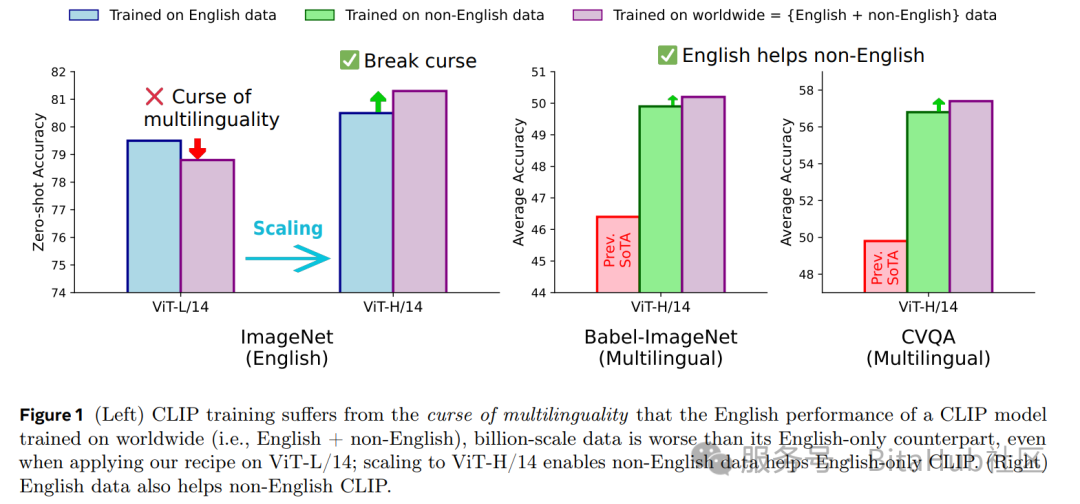
Fig. 1 :左图显示多语言诅咒现象------使用全球数据训练的 ViT-L/14 在英语 ImageNet 上表现不如仅英文模型;右图则展示了 ViT-H/14 打破诅咒的情况,英语与非英语任务均获提升。
阻碍 CLIP 全球化训练的两大核心问题是:
-
缺乏非英语数据的系统化策划方法------现有尝试要么不对原始数据进行处理,要么依赖私有数据或机器翻译,导致数据分布不可控或存在偏见,难以复现。
-
英语性能下降------多语言训练常导致英语表现劣化,使得研究者不得不为英语和非英语分别训练不同模型。
Meta CLIP 2 的核心假设是:多语言诅咒并非不可避免,而是由于缺乏适配全球数据的策划与训练策略导致的容量与规模不足。
Meta CLIP 2 训练策略
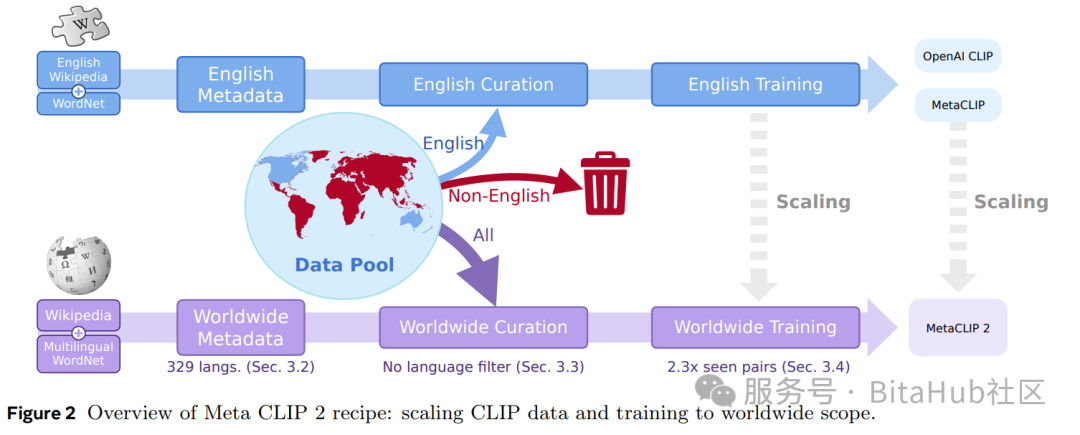
Fig. 2 :Meta CLIP 2 在原英文 Meta CLIP 框架上引入多语言元数据、全球化策划算法,以及适配全球数据的训练框架,实现从仅英文模型向全球范围扩展。
Meta CLIP 2 从源头出发,以英文 Meta CLIP 为基础,最小化改动,重点在三个方面做了全球化扩展:
1.元数据扩展(Metadata)
将原本的英语元数据扩展至 300+ 种语言,来源包括多语言WordNet、各语言的 Wikipedia 单词与词组、以及多时段的 Wikipedia 页面标题,并针对无空格语言(如中文、日文、泰语等)引入社区开发的开源分词器确保文本拆分的语义完整性。
2.全球化数据策划算法(Curation Algorithm)
首次针对每种语言独立匹配视觉概念,并根据语言数据量动态调整长尾/头部概念的采样阈值(t_lang),确保各语言的概念分布平衡。
3.训练框架调整(Training Framework)
训练阶段则将全局批次大小提升 2.3 倍,以匹配非英文数据带来的总量增长,确保英文数据的训练量不被稀释,同时验证出 ViT-H/14 是打破多语言诅咒的 "临界点"------ViT-L/14 即使采用相同框架仍受多语言诅咒影响,而 ViT-H/14 的容量足以同时吸收英文与非英文数据的价值。
关键实验结果
实验结果充分验证了 Meta CLIP 2 的性能优势。
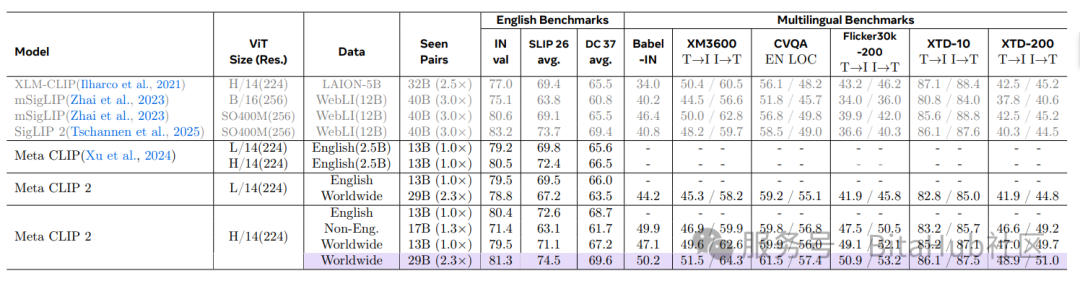
如上表所示在零样本 ImageNet 分类任务中,Meta CLIP 2 ViT-H/14 的准确率达到 81.3%,不仅比纯英文版本高 0.8%,还超过 mSigLIP 0.7%;更令人瞩目的是,它在多语言基准测试中创下多项新纪录:CVQA 准确率 57.4%、Babel-ImageNet 准确率 50.2%、XM3600 图像到文本检索准确率 64.3%,且这些成果未依赖翻译、定制架构等系统级干扰因素。Fig. 1 (右)进一步证明了英语与非英语数据实现了互相促进(英语数据提升多语言性能,非英语数据反哺英语性能),为模型持续扩展提供了新路径。
文化多样性与下游适配性
除了性能突破,Meta CLIP 2 还具备多项关键特性,推动视觉 - 语言模型向更公平、更多元的方向发展。它支持全语言覆盖,不因语言类型丢弃任何图像 - 文本对,且直接从母语者撰写的 alt-text 中学习,避免了机器翻译带来的语义偏差;同时保留了全球图像的完整分布,继承了文化和社会经济多样性,这使得模型在地理定位和区域特定识别任务中表现更优 。
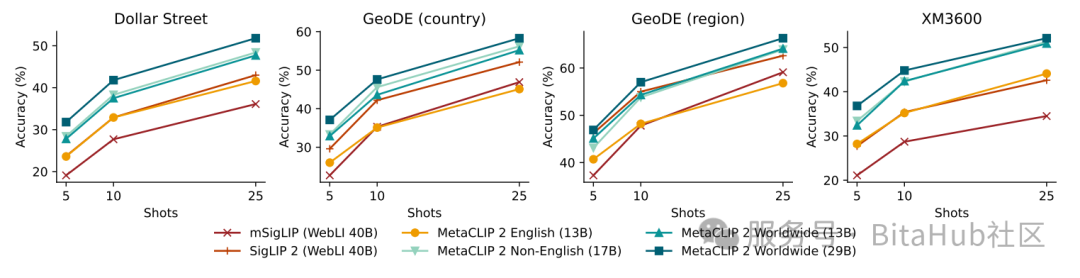
Fig. 3 :Meta CLIP 2 在 Dollar Street、GeoDE 等文化多样性基准的少样本地理定位任务中显著优于仅英文版本。
在 Dollar Street、GeoDE 等文化多样性基准测试中,使用 29B 全球数据的 Meta CLIP 2,其零样本分类准确率显著高于纯英文或纯非英文版本。此外,它移除了 "alt-text 是否为英文" 的筛选环节,减少了过滤带来的偏见,其开源的元数据、筛选算法和训练代码,也为社区突破英文中心主义 CLIP 模型提供了重要基础。
总结
Meta CLIP 2 的出现,不仅解决了 CLIP 模型全球扩展的核心难题,更重新定义了多语言视觉 - 语言模型的发展方向。它证明 "多语言诅咒" 并非不可突破,通过元数据、筛选算法与模型容量的协同扩展,英文与非英文数据能实现从 "互斥" 到 "互利" 的转变。未来,随着全球数据的持续应用,以及更多针对非英文、非欧美地区的基准测试完善,这类模型有望在跨文化交流、区域化 AI 应用等场景中发挥更大价值,推动 AI 技术真正走向全球化、多元化。