📖 前言
随着 NVIDIA Blackwell 架构的问世,DGX Spark (Personal AI Supercomputer) 将桌面级 AI 算力推向了新的巅峰。这台怪兽级设备搭载了 GB200/GB10 级别的 GPU 和 NVIDIA Grace CPU (ARM64) ,并运行在最新的 CUDA 13 环境下。
然而,"最强硬件"往往伴随着"最难环境"。由于 Grace CPU 采用 ARM (aarch64) 架构,且 CUDA 13 过于前沿,传统的 PyTorch 安装方法极易失败。
本文将手把手教你如何在这台超级计算机上部署 Stable Diffusion 3.5 Large ,并利用其 128GB 海量显存 开启高性能模式,实现秒级、零延迟的创作体验。
🛠️ 硬件环境规格 (DGX Spark Specs)
本次部署基于 NVIDIA 最新一代个人 AI 超级计算机:
- Platform : NVIDIA DGX Spark (Personal AI Supercomputer)
- Architecture: NVIDIA Blackwell (GB10 / GB200 Tensor Core GPU)
- VRAM : 128GB HBM3e (Unified Memory Architecture)
- CPU : NVIDIA Grace CPU (144-core ARM64)
- Software Stack: NVIDIA AI Enterprise
- CUDA Version : CUDA 13.0
💡 核心挑战与优势:
- 挑战:标准 PyPI 源的 PyTorch 通常只适配 CUDA 11/12,直接安装会导致找不到 GPU。
- 优势 :128GB 显存允许我们将 SD3.5 的 20GB 模型 + 10GB T5 编码器永久驻留显存,消除模型加载时间。
📦 第一步:构建兼容 CUDA 13 的基础环境
1.1 创建 Conda 环境
推荐使用 Python 3.11,它在 ARM 架构下的库支持最完善。
bash
conda create -n sd-runtime python=3.11 -y
conda activate sd-runtime1.2 安装适配 ARM + CUDA 13 的 PyTorch
这是最关键的一步。由于 CUDA 13 非常新,必须使用 NVIDIA 官方 PyPI 索引 来获取正确的 wheel 包。
bash
# 1. 确保 pip 是最新的
pip install --upgrade pip
# 2. 从 NVIDIA 官方源安装 PyTorch
# 注意:NVIDIA 的 index 通常会包含对最新 CUDA 版本的兼容包
pip install torch torchvision torchaudio --index-url https://pypi.nvidia.com1.3 验证环境 (关键)
安装完成后,务必验证 PyTorch 是否成功链接到了 Blackwell GPU。
bash
python -c "import torch; print(f'PyTorch Version: {torch.__version__}'); print(f'CUDA Available: {torch.cuda.is_available()}'); print(f'Device Name: {torch.cuda.get_device_name(0)}'); print(f'CUDA Version: {torch.version.cuda}')"- 预期输出:
CUDA Available: TrueDevice Name: NVIDIA GB10 (或相关 Blackwell 代号)CUDA Version: 13.x
📥 第二步:下载 Stable Diffusion 3.5 Large
SD3.5 是门控模型,请确保您已在 Hugging Face 签署协议并持有 Access Token。
bash
# 1. 安装下载工具
pip install huggingface_hub
# 2. 配置环境变量 (使用国内镜像加速)
export HF_ENDPOINT=https://hf-mirror.com
export HF_HUB_ENABLE_HF_TRANSFER=1
export HF_TOKEN="你的_HF_Token_粘贴在这里"
# 3. 创建目录
mkdir -p /home/david/workspaces/models/stabilityai/
# 4. 高速下载 (包含 Checkpoint 和 T5/CLIP 编码器)
huggingface-cli download stabilityai/stable-diffusion-3.5-large \
--token $HF_TOKEN \
--local-dir /home/david/workspaces/models/stabilityai/stable-diffusion-3.5-large🖥️ 第三步:部署 ComfyUI & 修复 ARM 依赖
3.1 克隆与安装
bash
cd /home/david/workspaces
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
# 安装常规依赖 (使用 --no-deps 防止破坏 Torch 环境)
pip install -r requirements.txt --no-deps
# 🔥 核心修复:补齐 ARM 架构下缺失的特殊库
# 如果缺少这些,ComfyUI 启动时会报错 "No module named kornia_rs" 或 "trampoline"
pip install trampoline kornia_rs mako comfyui-workflow-templates sqlalchemy alembic requests3.2 挂载模型 (软链接方案)
为了利用 DGX Spark 的存储性能,我们使用软链接映射模型。
bash
# 1. 链接主模型
ln -s /home/david/workspaces/models/stabilityai/stable-diffusion-3.5-large/sd3.5_large.safetensors \
./models/checkpoints/
# 2. 链接 CLIP 模型 (SD3 需要 3 个 CLIP)
# 注意:我们直接使用 FP16 精度的 T5,因为显存足够大
ln -s /home/david/workspaces/models/stabilityai/stable-diffusion-3.5-large/text_encoders/clip_l.safetensors ./models/clip/
ln -s /home/david/workspaces/models/stabilityai/stable-diffusion-3.5-large/text_encoders/clip_g.safetensors ./models/clip/
ln -s /home/david/workspaces/models/stabilityai/stable-diffusion-3.5-large/text_encoders/t5xxl_fp16.safetensors ./models/clip/🚀 第四步:高性能启动 (High VRAM Mode)
针对 128GB 显存,我们开启"疯狗模式"------让所有模型永久驻留显存,拒绝反复加载。
创建启动脚本 run_comfy.sh:
bash
#!/bin/bash
WORKDIR="/home/david/workspaces/ComfyUI"
PYTHON_PATH="/root/miniconda3/envs/sd-runtime/bin/python"
# 日志管理
LOG_DIR="$WORKDIR/logs"
mkdir -p "$LOG_DIR"
LOG_FILE="$LOG_DIR/server_$(date "+%Y-%m-%d_%H-%M-%S").log"
cd "$WORKDIR" || exit
echo "🚀 Starting ComfyUI on DGX Spark (Blackwell)..."
echo "⚡ Mode: High VRAM (Force Resident)"
# --highvram: 强制模型常驻显存
nohup "$PYTHON_PATH" main.py \
--listen 0.0.0.0 \
--port 8188 \
--highvram \
> "$LOG_FILE" 2>&1 &
echo "✅ Service PID: $!"启动服务:chmod +x run_comfy.sh && ./run_comfy.sh
🎨 第五步:导入 SD3.5 标准工作流 (JSON)
SD3.5 采用了分离式文本编码器架构(CLIP-L + CLIP-G + T5),默认工作流无法正常出图。
请复制下方完整的 JSON 代码 ,保存为 sd3_workflow.json,直接拖入 ComfyUI 浏览器界面即可使用。此工作流已针对 1024x1024 分辨率和 DGX Spark 进行了优化。
json
{
"last_node_id": 10,
"last_link_id": 16,
"nodes": [
{
"id": 1,
"type": "KSampler",
"pos": [960, 190],
"size": { "0": 315, "1": 262 },
"flags": {},
"order": 0,
"mode": 0,
"inputs": [
{ "name": "model", "type": "MODEL", "link": 1 },
{ "name": "positive", "type": "CONDITIONING", "link": 2 },
{ "name": "negative", "type": "CONDITIONING", "link": 3 },
{ "name": "latent_image", "type": "LATENT", "link": 4 }
],
"outputs": [
{ "name": "LATENT", "type": "LATENT", "links": [5], "slot_index": 0 }
],
"properties": { "Node name for S&R": "KSampler" },
"widgets_values": [
1234567890, "randomize", 30, 4.5, "euler", "sgm_uniform", 1
]
},
{
"id": 2,
"type": "CheckpointLoaderSimple",
"pos": [50, 50],
"size": { "0": 315, "1": 98 },
"flags": {},
"order": 1,
"mode": 0,
"outputs": [
{ "name": "MODEL", "type": "MODEL", "links": [1], "slot_index": 0 },
{ "name": "CLIP", "type": "CLIP", "links": [], "slot_index": 1 },
{ "name": "VAE", "type": "VAE", "links": [6], "slot_index": 2 }
],
"properties": { "Node name for S&R": "CheckpointLoaderSimple" },
"widgets_values": ["sd3.5_large.safetensors"]
},
{
"id": 3,
"type": "TripleCLIPLoader",
"pos": [50, 200],
"size": { "0": 315, "1": 150 },
"flags": {},
"order": 2,
"mode": 0,
"outputs": [
{ "name": "CLIP", "type": "CLIP", "links": [7, 8], "slot_index": 0 }
],
"properties": { "Node name for S&R": "TripleCLIPLoader" },
"widgets_values": [
"clip_l.safetensors",
"clip_g.safetensors",
"t5xxl_fp16.safetensors"
]
},
{
"id": 4,
"type": "CLIPTextEncode",
"pos": [450, 100],
"size": { "0": 425, "1": 180 },
"flags": {},
"order": 3,
"mode": 0,
"inputs": [
{ "name": "clip", "type": "CLIP", "link": 7 }
],
"outputs": [
{ "name": "CONDITIONING", "type": "CONDITIONING", "links": [2], "slot_index": 0 }
],
"properties": { "Node name for S&R": "CLIPTextEncode" },
"widgets_values": [
"a highly detailed cyberpunk city, neon lights, 8k resolution, cinematic lighting, masterpiece, sharp focus, ray tracing, nvidia blackwell style"
],
"color": "#233",
"bgcolor": "#353"
},
{
"id": 5,
"type": "CLIPTextEncode",
"pos": [450, 350],
"size": { "0": 425, "1": 180 },
"flags": {},
"order": 4,
"mode": 0,
"inputs": [
{ "name": "clip", "type": "CLIP", "link": 8 }
],
"outputs": [
{ "name": "CONDITIONING", "type": "CONDITIONING", "links": [3], "slot_index": 0 }
],
"properties": { "Node name for S&R": "CLIPTextEncode" },
"widgets_values": [
"low quality, blurry, ugly, bad anatomy, watermark, text, jpeg artifacts"
],
"color": "#332",
"bgcolor": "#533"
},
{
"id": 6,
"type": "EmptyLatentImage",
"pos": [50, 450],
"size": { "0": 315, "1": 106 },
"flags": {},
"order": 5,
"mode": 0,
"outputs": [
{ "name": "LATENT", "type": "LATENT", "links": [4], "slot_index": 0 }
],
"properties": { "Node name for S&R": "EmptyLatentImage" },
"widgets_values": [1024, 1024, 1]
},
{
"id": 7,
"type": "VAEDecode",
"pos": [1300, 190],
"size": { "0": 210, "1": 46 },
"flags": {},
"order": 6,
"mode": 0,
"inputs": [
{ "name": "samples", "type": "LATENT", "link": 5 },
{ "name": "vae", "type": "VAE", "link": 6 }
],
"outputs": [
{ "name": "IMAGE", "type": "IMAGE", "links": [9], "slot_index": 0 }
],
"properties": { "Node name for S&R": "VAEDecode" }
},
{
"id": 8,
"type": "SaveImage",
"pos": [1550, 190],
"size": { "0": 500, "1": 600 },
"flags": {},
"order": 7,
"mode": 0,
"inputs": [
{ "name": "images", "type": "IMAGE", "link": 9 }
],
"properties": { "Node name for S&R": "SaveImage" },
"widgets_values": ["ComfyUI"]
}
],
"links": [
[1, 2, 0, 1, 0, "MODEL"],
[2, 4, 0, 1, 1, "CONDITIONING"],
[3, 5, 0, 1, 2, "CONDITIONING"],
[4, 6, 0, 1, 3, "LATENT"],
[5, 1, 0, 7, 0, "LATENT"],
[6, 2, 2, 7, 1, "VAE"],
[7, 3, 0, 4, 0, "CLIP"],
[8, 3, 0, 5, 0, "CLIP"],
[9, 7, 0, 8, 0, "IMAGE"]
],
"groups": [],
"config": {},
"extra": {},
"version": 0.4
}流程如下:
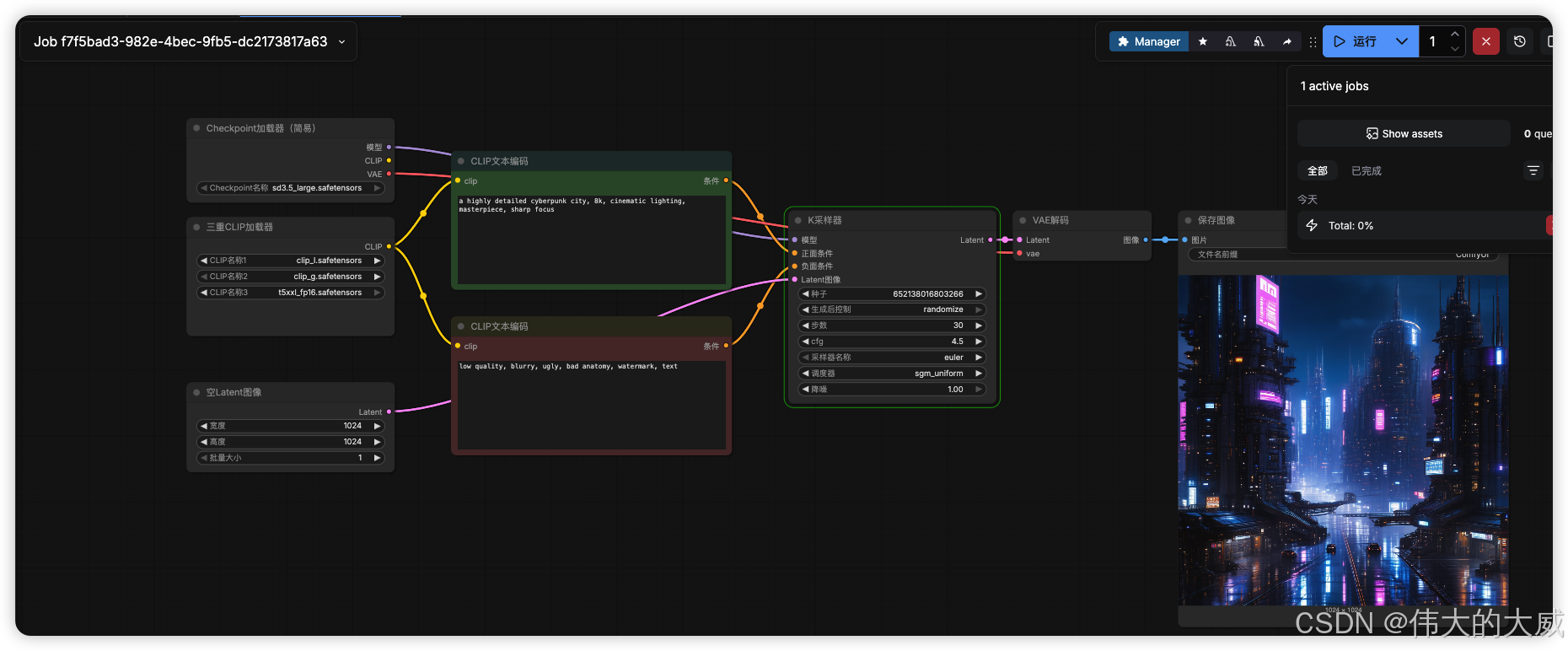
效果如下:

💡 工作流配置说明:
- TripleCLIPLoader : 这是核心。我们明确指定了
clip_l,clip_g和t5xxl_fp16。如果这三个没选对,生成的图片将无法理解你的 Prompt。 - Scheduler: sgm_uniform: Stable Diffusion 3 必须使用 SGM Uniform 调度器,否则画面会充满噪点。
- Resolution: 默认设为 1024x1024。在 Blackwell 上,你可以尝试将其改为 2048x2048 进行原生 4K 生成。
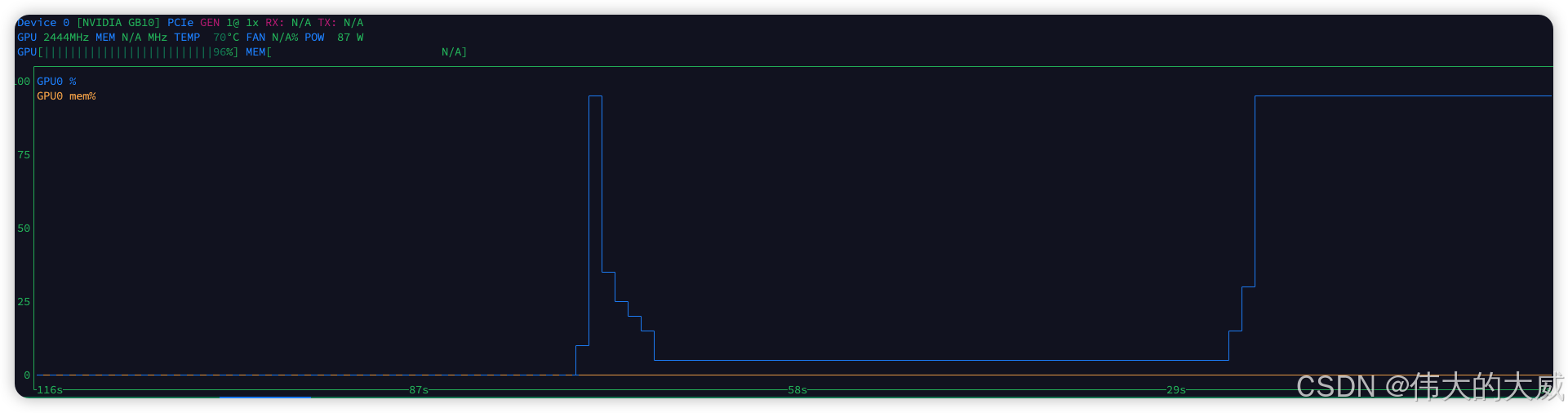
📊 性能总结
在 DGX Spark 上完成上述部署后,性能表现如下:
- 模型加载 : 首次启动后,模型将永久驻留显存 (High VRAM Mode)。
- 生成速度: 1024x1024 分辨率下,实现秒级出图。
- 并发能力 : 得益于 128GB 显存,你可以同时开启
Batch Size = 4甚至更高,或者在后台同时运行一个 70B 的大语言模型而不发生 OOM。
资源占用: