-
P - Empowering (赋能 / 增强)
-
E - Geologic (地质的)
-
A - Map (地图)
-
C - Holistic Understanding (整体理解)
-
E - with MLLMs (通过多模态大语言模型)
原论文:https://arxiv.org/abs/2501.06184
代码:https://github.com/microsoft/PEACE
数据集:https://modelscope.cn/datasets/microsoft/PEACE


目录
1.简介
1.1.地质图的重要性
地质科学在全面理解地球45亿年演化历史中具有核心作用,通过划分地球历史为宙、代、纪、世等时间单元,并以重大地质与生物事件为标志,揭示了地球的动态演变过程。地质图作为关键工具,不仅记录了岩石单元和地质构造的空间分布及其相互关系,还为破译地球历史提供了基础。
在实际应用中,地质图具有三大重要作用:
- 灾害检测:用于评估山体滑坡、地震、地下水污染等自然灾害的风险;
- 资源勘探:指导矿产、石油和天然气等自然资源的定位与开发;
- 土木工程:辅助基础设施规划,通过分析地下地质条件确保工程安全。
例如,在油气勘探中,背斜圈闭因构造隆升形成储层上拱,其顶部被不透水层封闭、底部由水体或致密岩层隔离,构成理想的油气聚集构造。这体现了地质结构与资源分布之间的紧密联系。
1.2.现有VLM的不足
尽管多模态大语言模型(MLLMs,如GPT-4、LLaVA)在通用图像理解中表现出色,但在地质图理解中存在显著瓶颈,主要源于以下挑战:
(1)高分辨率图像处理难题:
地质图通常为高分辨率(如平均6,146²像素),远超普通图像的输入限制。直接压缩会导致细节丢失(如微小断层符号模糊),而分块处理需解决局部与全局信息的关联问题。
例如,一张1:50,000比例尺的地质图可能包含数千个独立符号,模型需同时捕捉微观细节和宏观结构。
(2)多关联组件的复杂交互:
地质图包含七大核心组件(标题、比例尺、图例、主图、索引图、剖面图、地层柱状图)及数十种符号化标记(如颜色编码的岩石类型、线状断层、面状岩层边界)。这些组件需联合解读,例如:
(1)图例与主图关联:不同颜色对应特定岩石类型(如红色代表花岗岩),需模型将颜色映射到地质术语。
(2)剖面图与主图联动:垂直剖面图需与平面主图结合,以理解三维地质结构。
组件间的空间和语义关联增加了模型推理的复杂度。
(3)领域知识依赖性强:
地质图的符号系统高度专业化,需结合地质学、地理学、地震学等知识。
例如:
(1)断层符号:需区分正断层、逆断层、走滑断层,并关联其活动性与地震风险。
(2)地层年代:需理解国际地层年代表(如"侏罗纪""白垩纪")及其对应的岩石特征。
通用MLLMs缺乏此类领域知识库,导致回答模糊或错误。例如,GPT-4可能无法准确解释"背斜构造中不透水层如何封闭油气"。
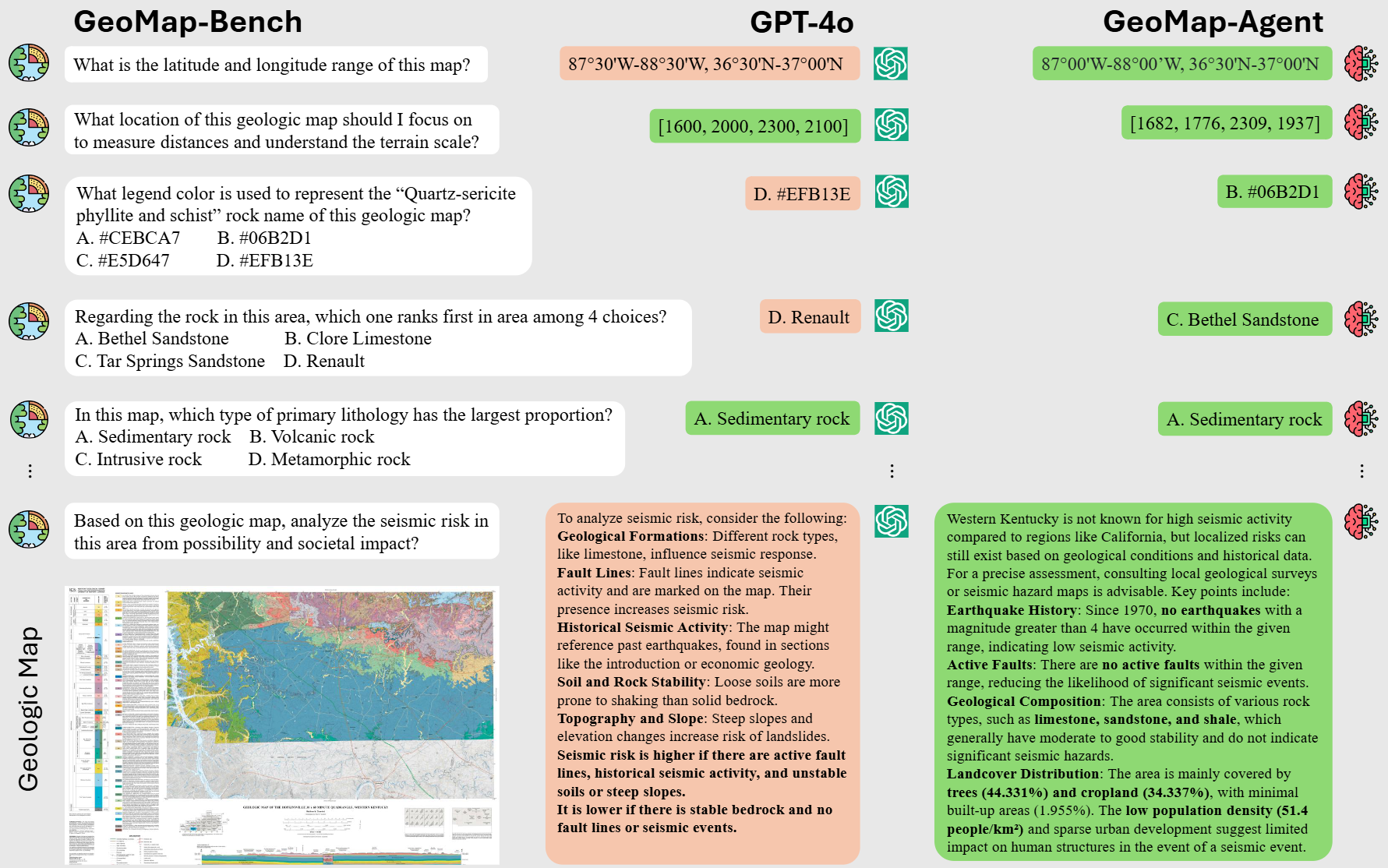
1.3.核心创新点
- 为提升AI对地质图的理解能力,研究提出了 GeoMap-Bench 基准,从提取、参考、基础、推理和分析五个方面评估大模型表现;
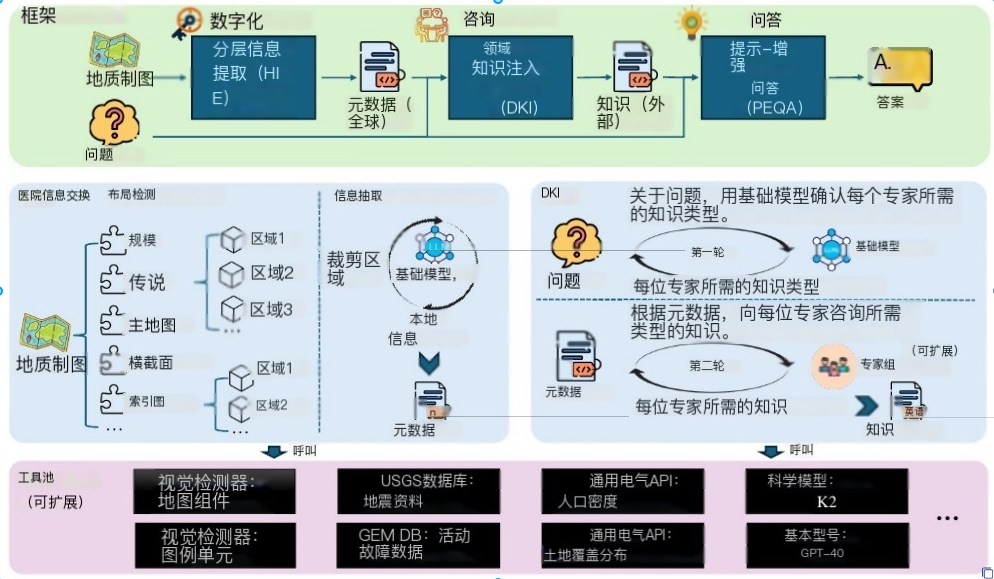
- GeoMap-Agent 系统,通过层次信息提取(HIE)、领域知识注入(DKI)和提示增强问答(PEQA)三个模块,实现地质图的数字化、智能问答及下游应用支持。
2.相关工作
2.1.科学评估基准
现有多个科学领域的评估基准,但大多未覆盖地质图理解:
- Geobench 专注于评估大模型在地球科学中的文本理解能力;
- 新界标尺 引入视觉任务,用于测试大模型的地理与地理空间推理能力;
- OceanBench 针对海洋科学任务进行评估;
- ScienceQA 是一个涵盖多学科的多模态选择题基准,但其中地质科学内容极少;
- LHRS-Bench 则聚焦于遥感图像理解。
尽管这些基准推动了地球科学相关能力的评测,但目前尚无一个专门针对地质图综合理解(包括符号识别、空间关系、构造解释等)而设计的评估体系。
2.2.科学智能体系统
一些面向科学任务的智能体已取得进展:
- GeoGPT 结合思维链推理与GIS工具处理地理空间问题;
- ChemCrow 、SocialSimulacra 和 DS-Agent 分别在化学合成、社会模拟和数据科学中展现能力。
然而,这些系统均未聚焦于地质图的理解与分析,且通用方法难以应对地质图所特有的多模态、高专业性和复杂空间结构等挑战。
2.3.面向科学的大模型
地球科学领域已出现若干专用大模型:
- GeoLLM 通过指令微调提升地理空间预测能力;
- GeoGalactica 基于地质文本语料库优化地质问答;
- K2 是首个专为地球科学设计的大模型,但仅支持纯文本交互。
其他领域如医学(MedGPT、Clinical LLMs)、生物(BioGPT)和海洋科学(OceanGPT)也发展出专用模型,但地质领域仍缺乏能融合文本与地图图像的多模态大模型。
2.4.通用大模型与多模态进展
近年来,通用大模型(如 GPT-4V、Qwen-VL、LLaVA 等)在多模态理解方面取得显著突破,支持图像、视频、语音等多种输入。尽管如此,这些模型在面对专业性强、符号复杂的地质图时仍表现有限。因此,研究者将强大基础多模态大模型(如 GPT-4o)作为底层引擎,结合领域知识构建专用系统------如 GeoMap-Agent,以填补当前在地质图智能理解方面的空白。
综上,尽管科学大模型和评估体系快速发展,地质图的多模态、专业化理解仍是未被充分探索的关键方向,亟需针对性的基准(如 GeoMap-Bench)和智能体系统(如 GeoMap-Agent)来推动该领域的智能化进程。
3.GeoMap-Bench
我们构建了一个地质图基准,GeoMap-Bench,以评估mllm在不同能力的地质图理解方面的性能,其概述如表2所示。在以下小节中提供了详细的介绍,并在附录中定义了评估指标。

3.1.数据来源
- 标准化数据源:**整合来自美国地质调查局(USGS)和中国地质调查局(CGS)**的公开地质图,覆盖不同区域(如北美、东亚)和比例尺(1:24,000至1:500,000),确保数据多样性和专业性。
- 数据集规模:包含124张高分辨率地质图(平均分辨率6,146²像素)和3,864个标注问题,涵盖中英文双语环境。
- 标注与验证:通过人工标注与专家审核,记录每张地图的元数据(标题、比例尺、经纬度范围)及组件信息(图例颜色、岩石类型、断层分布等),确保答案的准确性。
USGS官网地址:https://www.usgs.gov
CGS官网地址:http://www.cgs.gov.cn
3.2.数据集构建
1.Rasterization(光栅化)
2.Annotation(注释)
3.Definition(定义)
4.Generation(生成)
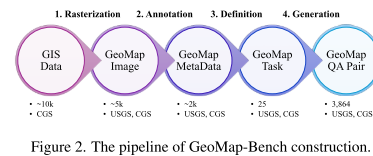
1.Rasterization(光栅化)
为构建高质量的地质图多模态数据集,研究团队整合了来自中国地质调查局 (CGS)和美国地质调查局(USGS)的公开地质图资源,并针对其格式差异采取了相应的处理策略:
-
CGS地图处理 :
由于CGS发布的"国家1:20万数字地质图(公开版)空间数据库"采用专有的 MapGIS 格式 ,与主流 GIS 软件(如 ArcGIS)不兼容,研究团队使用官方 MapGIS 软件 将其渲染为标准栅格图像(如 PNG 或 TIFF)。为提升效率,开发了一个自动化模拟程序 ,通过脚本自动执行软件内的键盘与鼠标操作,实现批量导出。该数据库共包含 1,163 张 地质图。
-
USGS地图处理 :
选取了 1990 年代以后出版 的 USGS 地质图,这些地图本身已以栅格图像格式 (如 GeoTIFF、JPEG)公开发布,共计 6,415 张。
-
数据筛选 :
对所有原始图像进行质量评估与过滤 (如去除模糊、缺失图例、比例尺不清或严重裁剪的图件),最终保留约 5,000 张高质量栅格化地质图,用于后续的模型训练、基准构建(如 GeoMap-Bench)和智能体系统(如 GeoMap-Agent)开发。
这一流程有效解决了中外地质图数据格式异构的问题,为构建首个面向地质图理解的多模态基准奠定了坚实的数据基础。
2.Annotation(注释)
在完成地质图的栅格化处理之后,为了进一步提升这些图像的可用性和研究价值,进行了细致的手动标注工作。以下是具体步骤和结果:
手动标注元数据
- 成分边界框:为每张地图上的地质成分添加边界框标注,精确界定各类地质体的空间分布。
- 基本信息记录:包括但不限于每个成分的名称、地理位置(经度)、比例尺等关键信息。
- 图例单位细节:详细记录了图例中各个单元的信息,如边界框位置、颜色编码、文字描述、岩性特征及地层年龄等,确保能够准确解读地质图内容。
- 统计信息采集:计算并记录了岩性组成比例、各岩石单元覆盖面积大小以及区域内是否存在断层等地质结构特征。
数据精度交叉检查
- 在所有元数据录入完成后,进行了严格的精度交叉检查,以保证数据的准确性与一致性。这一过程可能涉及多次审核,甚至可能需要对比原始地图资料或其他可靠来源的数据来验证标注的正确性。
最终成果
经过上述详尽的工作流程后,得到了大约 2000 张 配备了高质量元数据的地质图图像。这些富含信息的地图不仅为后续的科学研究提供了坚实的基础,同时也极大地增强了基于这些数据开发的各种应用(例如 GeoMap-Bench 和 GeoMap-Agent)的实用性和可靠性。
3.Definition(定义)
为了彻底衡量mllm在地质图理解方面的表现,我们与高级地质学家合作,定义了五个方面的测量能力:
- 提取:它评估从地图中准确提取基本信息的能力,比如标题、比例尺和纬度坐标。
- 接地:它衡量的是根据组件的名称或意图在地图上精确定位组件的能力。
- 参考:它评估将名称与其相应属性联系起来的技能,例如通过其传说颜色识别岩石名称。
- 推理能力:它评估执行高级逻辑任务的能力,这些任务需要跨组件连接信息或整合外部知识。
- 分析能力;它评估全面解读地图上给定主题的能力,并从不同角度提供详细而有意义的见解。

题目类型"FITB"、"MCQ"和"EQ"分别代表填空题、选择题和作文题
4.Generation(生成)
基于前期对约2000张地质图的精细标注元数据(包括图例、边界框、岩性、地层年代、比例尺、断层信息等),研究团队通过自动检索、定量计算与统计分析,为每个评估问题生成了准确的 ground-truth 答案。
为确保答案的科学性与可靠性,项目特别邀请了资深地质学家对全部"**地图--问题--答案"**三元组进行人工审查与修正。这一严谨的质量控制流程有效避免了因自动处理或标注误差导致的错误,显著提升了数据集的专业性和可信度。
最终,该过程构建出 GeoMap-Bench 的核心评估数据集,包含:
- 124 张高质量地质图(覆盖中美不同区域与地质背景)
- 3,864 个结构化问题,涵盖五大能力维度:提取、接地、参考、推理和分析
如图3所示,这些问题在不同能力层级和任务类型之间实现了合理分布,既包括基础信息读取(如"该图比例尺是多少?"),也包含高阶地质推断(如"根据背斜构造和岩性组合,是否可能存在油气圈闭?"),全面反映模型在真实地质场景下的理解与应用潜力。
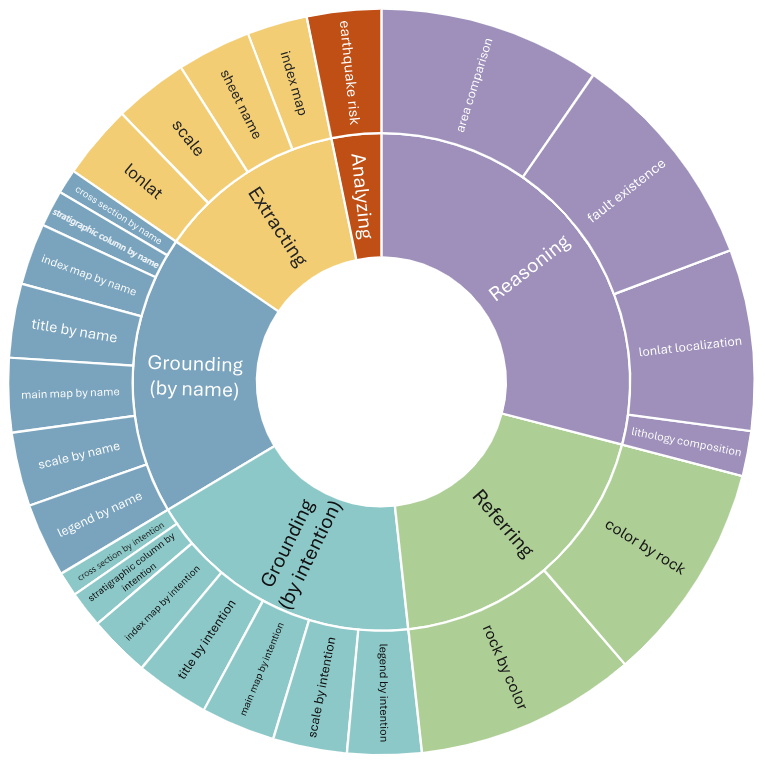
GeoMap-Bench中问题的分布。它由25个任务类型组成,衡量mllm在5个方面的能力。这些不同任务类型中的问题分布相对均匀,如每个任务的面积所示。
4.GeoMap-Agent
通常会面临高分辨率、多个关联组件以及对专业领域知识的需求等挑战。这些属性使得即使是像假设中的GPT-40这样强大的多模态语言模型(MLLMs)也难以充分理解并准确解析地质图的复杂信息。地质图不仅包含了丰富的地学信息,如岩性、地层、构造特征等,还需要结合空间关系和地质背景进行综合分析。
为了解决这些挑战,提出了一种基于多模态学习模型(MLLM)的图像理解新范式。这一范式旨在通过结合深度学习与领域专家知识,提高模型对复杂图像内容的理解能力。GeoMap-Agent作为这一范式的实例,展示了如何利用先进的机器学习技术来理解和解析地质图中蕴含的信息。
4.1.模块
GeoMap-Agent框架由三个模块组成
- 层次信息提取(HIE)
- 领域知识注入(DKI)
- 提示增强问答(PEQA)

4.1.1.层次信息提取(HIE)
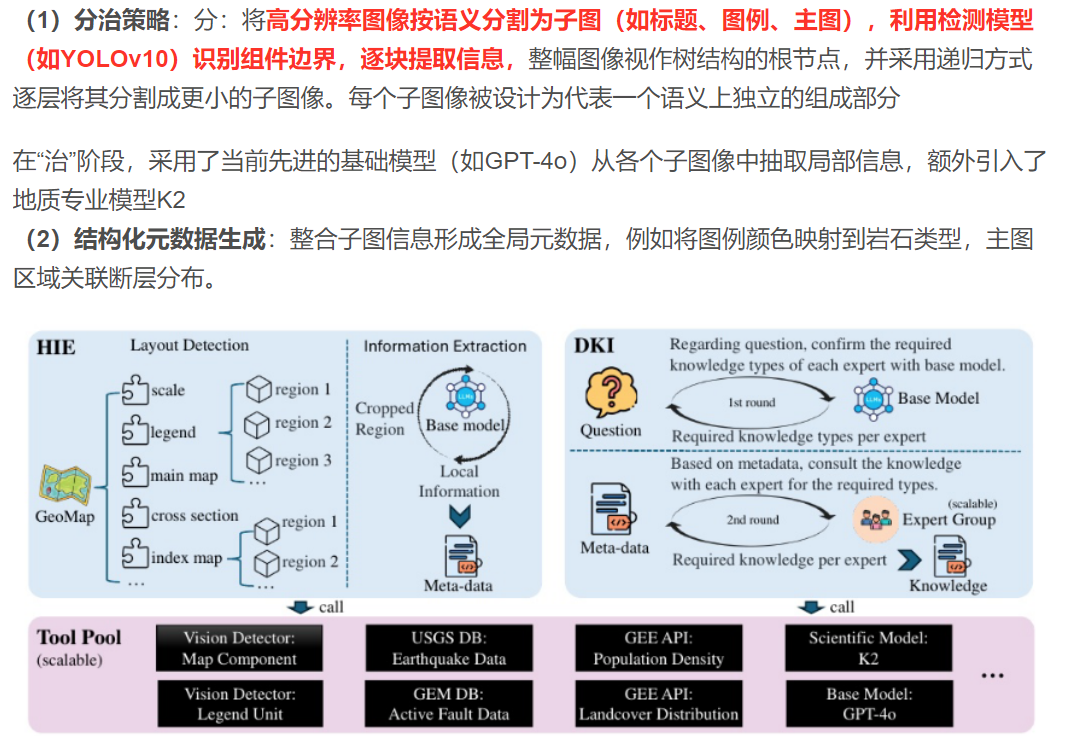
(1)分治策略 :分:将**高分辨率图像按语义分割为子图(如标题、图例、主图),利用检测模型(如YOLOv10)识别组件边界,逐块提取信息,**整幅图像视作树结构的根节点,并采用递归方式逐层将其分割成更小的子图像。每个子图像被设计为代表一个语义上独立的组成部分
在"治"阶段,采用了当前先进的基础模型(如GPT-4o)从各个子图像中抽取局部信息,额外引入了地质专业模型K2
(2)结构化元数据生成:整合子图信息形成全局元数据,例如将图例颜色映射到岩石类型,主图区域关联断层分布。
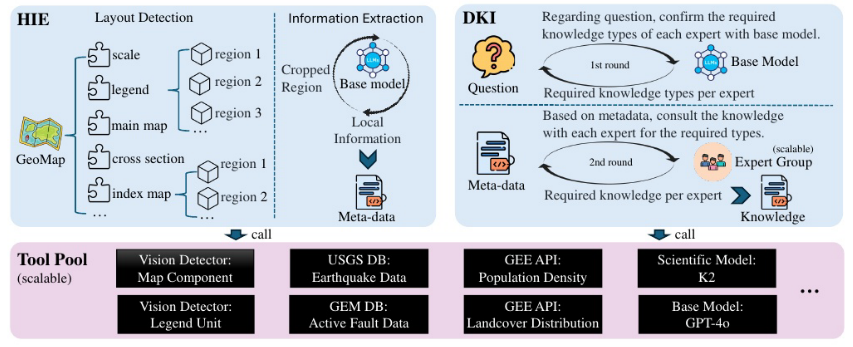
4.1.2.领域知识注入(DKI)
DKI模块旨在为问题回答提供必要的领域知识,尤其针对需要推理 和分析能力的复杂地质图理解任务。该模块分为以下两个步骤:
-
知识需求确认
- 对于给定的问题,首先调用基础模型(如GPT-4o)进行判断,确认是否需要引入外部领域知识;
- 若需要,则进一步识别所需知识的具体类型,并确定应咨询专家小组中的哪些成员。
-
专家知识获取与链接
- 针对确认所需的知识类型,逐一咨询相关领域的专家;
- 专家在回答时可利用工具库中的专业工具,并结合HIE模块提取的经纬度范围等元数据,实现知识与地图空间信息的精准关联;
- 当前专家小组包括:
- 一名地质学家(负责岩性、地层、构造等)
- 一名地理学家(负责空间分布、地貌、区域背景等)
- 一名地震学家(负责活动断层、地震风险等)
- 专家小组设计为可扩展架构,可根据具体任务需求灵活增补其他领域专家。
通过上述机制,DKI模块有效弥合了通用大模型与地质科学专业深度之间的鸿沟,显著提升了GeoMap-Agent在高阶地质任务中的准确性与可信度。
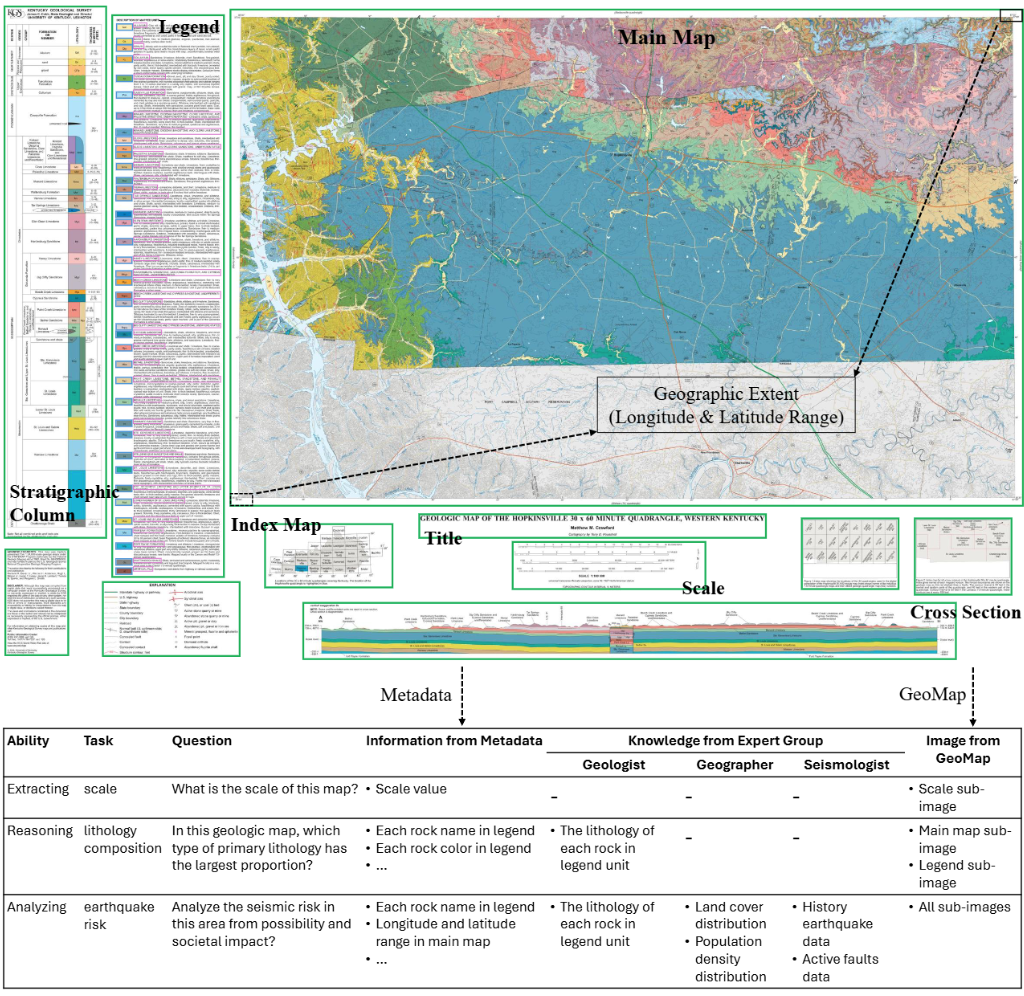
图5。地质图示例及其问答。地质图包含许多具有特定信息的语义成
分。视觉检测器通过HIE识别这些区域,基模型逐区域提取信息,合
并成全局元数据。在DKI模块中,每个问题通过咨询专家组获得特定
的知识。最后,PEQA模块利用元数据和知识执行快速增强的QA。
4.1.3.提示增强问答(PEQA)
在前两个模块------层次化信息提取 (HIE)和领域知识注入 (DKI)------分别获取了地质图的全局元数据 (内部信息)与回答特定问题所需的外部领域知识的基础上,
PEQA模块通过多维度的提示工程策略,显著提升基础模型(如GPT-4o)在地质图问答任务中的准确性与结构化输出能力。具体设计包括以下四个方面:
多模态提示词设计:
1.上下文增强 :在提示(prompt)中显式注入由 HIE 提取的结构化元数据 (如图例、比例尺、经纬度范围、岩性单元等)以及由 DKI 获取的相关领域知识,为模型提供充分的上下文支持。
2.思维链 (Chain-of-Thought, CoT):要求基础模型不仅输出最终答案,还需逐步展示推理过程,从而促进更深入、可解释的地质逻辑推演,尤其适用于需要分析与综合判断的问题。
3.Few-shot 示例与结构化输出 :在提示中嵌入一个高质量示例问答对 (few-shot example),并明确指示模型以JSON 格式返回答案,确保输出格式统一、机器可解析,便于下游应用集成。
4.问题导向的图像裁剪 (Attention-like Design):针对具体问题,从原始高分辨率地质图中裁剪出相关组件区域(如特定构造、岩性单元或断层),并将该局部图像作为视觉输入嵌入提示中,模拟"注意力聚焦"机制,引导模型关注关键区域。
通过上述四项提示增强策略的协同作用,PEQA模块有效提升了模型在复杂地质图理解任务中的表现,为 GeoMap-Agent 实现高精度、可解释、结构化的问答能力提供了关键支撑。
通过提示工程将GPT-4o的答案准确率提升30%以上。
4.2.专家组
- 跨学科协作:模拟真实科研团队中不同领域专家协同工作的模式。
- 模块化与可扩展性 :
- 每个"专家"是一个功能模块,专精于特定知识领域;
- 专家组的成员数量和知识类型可根据任务需求动态增减。
| 专家角色 | 专业知识领域 |
|---|---|
| 地质学家 | 地质图构成、地层年代表、岩性分类、地质单元信息图式等 |
| 地理学家 | 全球土地覆盖类型(如森林、沙漠、城市)、人口密度空间分布 |
| 地震学家 | 历史地震事件数据库(时间、震级、位置)、活动断层分布、地震危险性评估基础数据 |
4.3.工具池
| 工具类别 | 具体工具 / 接口 | 功能描述 |
|---|---|---|
| 视觉探测器 | 地图组件检测器 | 识别地质图中的7类标准组件(如图名、比例尺、图例、指北针等) |
| 图例单元检测器 | 解析图例中的文本(岩石名称)与颜色块(岩性颜色),支持后续语义映射 | |
| GEE API | Google Earth Engine (人口密度) | 根据经纬度范围获取区域人口密度 |
| Google Earth Engine (土地覆盖) | 获取对应区域的土地覆盖类型(如森林、农田、城市等,引用 | |
| 科学数据库 | USGS 地震数据库 | 查询历史地震事件(时间、震级、位置等) |
| GEM 活动断层数据库 | 获取活动断层的空间分布与属性信息 | |
| AI 模型 | K2 科学模型 | 提供地质领域知识,特别是地质图语义理解(如地层关系、岩性解释) |
| GPT-4o 基模型 | 执行通用任务:信息抽取、问答、推理、报告生成等 |
5.实验
5.1.主要实验
- 评估基准:GeoMap-Bench(包含 USGS 和 CGS 两个子集,可能分别代表美国地质调查局和中国地质调查局的数据)。
- 对比方法 :
- 闭源 API 模型:如 GPT-4o ;
- 开源对话模型:如 Qwen-Chat (即通义千问的对话版本)。
- 评估维度 :涵盖五项关键能力:
- 提取(Extraction):从地质图或文本中抽取结构化信息;
- 接地(Grounding):将语义概念与空间坐标/图面元素对齐;
- 参考(Referencing):正确引用图例、地层表等辅助材料;
- 推理(Reasoning):基于地质规则进行逻辑推断(如岩层相对年代);
- 分析(Analysis):综合多源信息完成高阶任务(如灾害评估、资源潜力判断)。
- 主要结论 :GeoMap-Agent 在所有子集和所有能力维度上均取得最优性能。
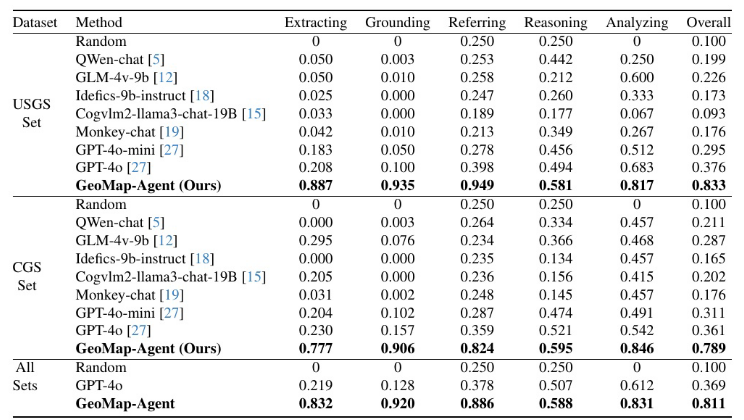
"为了验证 GeoMap-Bench 的任务难度并提供性能下界,我们引入了一个随机基线(Random),该基线在所有子任务中均通过均匀采样生成预测结果。如表3所示,其整体得分仅为0.124,显著低于所有智能方法,表明本基准具有足够的挑战性。"
- USGS :代表来自 United States Geological Survey(美国地质调查局)的地质图样本;
- CGS :代表来自 China Geological Survey(中国地质调查局)的地质图样本;
- All Sets :
是对 USGS 和 CGS 两个子集的评估结果进行汇总(通常为加权平均或简单平均) 后得到的总体得分,用于反映模型在整个基准测试集上的平均能力。
5.2.消融实验
为进一步深入理解 GeoMap-Agent 的工作机制与性能边界,我们开展了多项补充实验,包括:(1)各功能模块的消融研究,以量化专家协作与工具池中关键组件的贡献;
(2)在不同基础大语言模型(如 Qwen、Llama3 等)上的适配性测试,验证架构的通用性;(3)在低分辨率地质图输入下的鲁棒性评估,模拟真实场景中的图像质量退化。
5.2.1.对不同模块的贡献
通过移除 GeoMap-Agent 的某些模块进行消融实验,评估每个模块的贡献。

Ext,Gro,Ref,Rea,Ana,Ove就是那五类任务,ove为综合得分
5.2.2.对不同基础模型
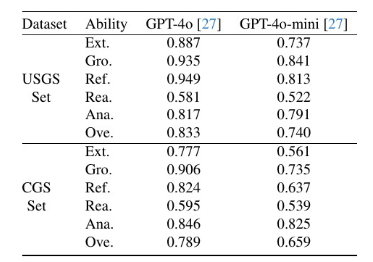
GeoMap-Agent 的设计原则之一是与基础多模态大语言模型(MLLM)解耦 ,理论上支持任意 MLLM 作为其推理引擎。为验证框架对不同底座模型的适应性,我们分别以 GPT-4o 27 和 GPT-4o Mini 27 作为基础模型构建 GeoMap-Agent 实例,并在 GeoMap-Bench 上进行评估。
如表 5 所示,尽管两种配置均显著优于基线方法,但性能提升幅度存在差异:GPT-4o 版本在综合得分(Overall)上达到 0.811,而 GPT-4o Mini 版本为 0.732。这一结果表明,GeoMap-Agent 的性能随基础模型能力增强而提升,但其核心优势------跨学科专家协作与工具调用机制------在不同 MLLM 上均能有效发挥作用。因此,该框架并不依赖于特定闭源模型,未来可无缝集成更强大或开源的 MLLM(如 Qwen-VL、LLaVA-NeXT 等),具备良好的可扩展性与技术前瞻性。
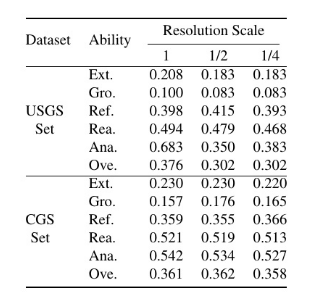
5.2.3.不同分辨率下的性能
高分辨率对 MLLMs 理解地质图提出了重大挑战。为了解决这个问题,GeoMap-Agent 中的 HIE 将地图的语义区域裁剪成子图像进行信息提取。如表 6 所示,降低地质图的分辨率并不能提高性能。因此,我们得出结论,HIE 提供的改进不是由于分辨率的直接降低,而是来自"分而治之"策略。
6.补充材料
6.1.地质图
地质图确实是一种专门类型的地图,专注于展现特定区域内的岩石单元分布、特征以及它们之间的年代关系,还包括断层和褶皱等构造特征的描绘。对于地质学家和地球科学家而言,这些地图是不可或缺的工具,因为它们以直观的方式展示了某一地区的地质情况。
通常情况下,一张标准的地质图包含以下几个关键元素:
- 标题:提供了关于地图所涵盖的物理区域、地图类型以及作者的基本信息。
- 比例尺:指示了地图上的距离与实际地面距离之间的转换关系。
- 图例:解释了用于表示不同类型的岩石、其年龄以及地质特征的符号和颜色。这有助于读者理解地图上使用的各种标记。
- 主图:这是地质图的核心部分,详细描绘了被研究区域的地质结构,包括岩石种类、年龄及其分布,还有诸如褶皱和断层等地质现象的位置。
- 索引图:帮助将地质图置于更广泛的地理背景中,显示该地区与周边地区的相对位置和联系。
- 横截面图:提供了一种观察地表以下岩石排列方式的方法,通过垂直切片的形式展示地下地质结构。
- 地层柱:展示了某一特定区域内存在的岩层顺序、厚度和类型,为分析地层历史提供了基础。
- 其他成分:除了上述7个关键组成部分之外,还可能包含一些补充信息或图表,用以进一步说明该地区的地质特征和条件。
结合这些元素,地质图不仅能够呈现一个地区的地质现状,还能揭示其地质演变的历史和过程。参考图A1中的示例,可以更好地理解各个组成部分如何协同工作来提供全面的地质信息。
6.2.评价指标
1.总分

| 符号 | 含义 |
|---|---|
| Sall | 该 AI 方法在 GeoMap-Bench 上的 总分(Overall Score) |
| M | 要测量的能力数量(即任务维度) |
| Si | 第 i 项能力的得分(如提取、接地等) |
| T | 输入任务类型(例如:从图中提取岩性名称) |
| Q | 提问或指令(Question/Instruction) |
| A | 模型输出答案(Answer) |
| L | 标注标准/参考答案(Label/Ground Truth) |
2.能力评分
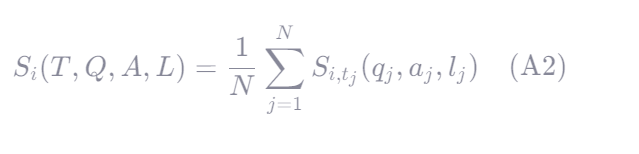
| 符号 | 含义 |
|---|---|
| Si | 第 i 项能力的平均得分(例如:Extracting、Grounding 等) |
| T | 任务类型(Task Type),如"从图例中提取岩性名称" |
| Q | 所有问题集合(Question Set) |
| A | AI 模型对这些问题的回答集合(Answer Set) |
| L | 专家标注的真实答案集合(Label/Ground Truth) |
| N | 与第 i 项能力相关的总问题数量 |
| tj | 第 j 个问题对应的任务类型(子任务) |
| qj | 第 j 个问题 |
| aj | 对应的 AI 回答 |
| lj | 对应的专家标注答案 |
| Si,tj(qj,aj,lj) | 针对该子任务 tj 的评分函数,衡量回答 aj 与真实答案 lj 的匹配程度 |
3.类型得分
该部分内容定义了如何根据问题类型(选择题、填空题、作答题)计算每类任务的 类型得分(Type Score),并进一步用于计算能力得分(见公式 A2)。整体分为三类:
- 选择题:使用 Smcq
- 填空题:使用 Sfub
- 作答题(开放性问答):使用 Seq
选择题评分:
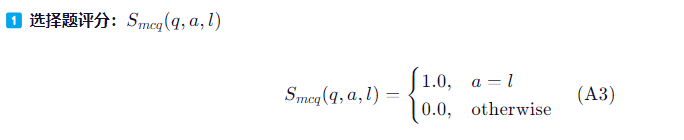
- 若 AI 回答 a 与真实答案 l 完全一致,则得 1.0 分;
- 否则得 0.0 分。
- 适用于单选或多选中的精确匹配场景。
填空题评分:
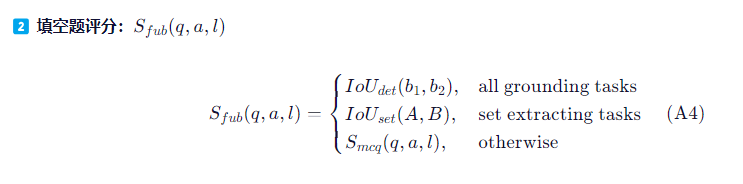
- 根据任务子类型采用不同的评分方式:
- 接地任务(Grounding) :如"请标注出花岗岩所在区域",用 边界框 IoU 评估;
- 集合提取任务(Set Extracting) :如"列出所有断层名称",用 集合交并比 评估;
- 其他情况(如文本填空):退化为选择题评分(即精确匹配)。


3.作文题评分


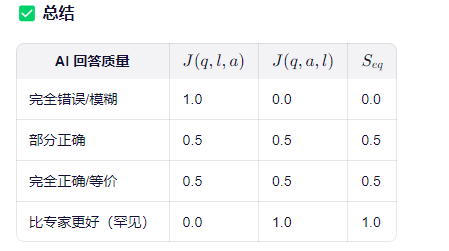
6.3.提示词
1.问答提示
bash
- QA Prompt
Image prompt: ${selected sub-images in geologic map}
Instruction prompt:
Extracted information: ${information}
Injected knowledge: ${knowledge}
This is a ${question type} question.
Based on the provided text and image, reason and answer the question in JSON format only, for example: {"reason": "XXX", "answer": "XXX"}
Question:
${question}
Answer:中文:
bash
- QA提示
图像提示:${地质图中的选定子图像}
指令提示:
提取的信息:${信息}
注入的知识:${知识}
这是一个${问题类型}问题。
基于提供的文本和图像,以仅JSON格式推理并回答问题,例如: {"reason": "XXX", "answer": "XXX"}
问题:
${问题}
答案:2.答疑提示(裁判智能体)
bash
- AJ Prompt
Image prompt: ${entire image of geologic map}
Instruction prompt:
Please evaluate which of the two answers below is better for the essay question {question}, consider the following criteria:
1. Diversity: The answer should address various aspects of the question, providing a well-rounded perspective.
2. Specificity: The answer should be detailed and precise, avoiding vague or general statements.
3. Professionalism: The answer should be articulated in a professional manner, demonstrating expertise and credibility.
Answer1:
${answer1}
Answer2:
${answer2}
Question: which answer is better?
A. Answer1 is better than Answer2
B. Answer1 is worse than Answer2
C. Answer1 and Answer2 are comparable
Only respond with A, B or C in JSON format, for example: {"answer": "C"}
Answer:
bash
图像提示:${地质图的完整图像}
指令提示:
请评估以下两个答案中,哪一个对于论述题 {question} 更优,并参考以下评判标准:
多样性:答案应涵盖问题的多个方面,提供全面、多角度的分析。
具体性:答案应详细且精确,避免模糊或笼统的表述。
专业性:答案应以专业的方式表达,体现出相关领域的知识深度与可信度。
答案1:
${answer1}
答案2:
${answer2}
问题:哪个答案更好?
A. 答案1 优于 答案2
B. 答案1 劣于 答案2
C. 答案1 与 答案2 水平相当
请仅以 JSON 格式返回 A、B 或 C,例如:{"answer": "C"}
答案:6.4.评价设置
基础模型 。
我们固定所有随机种子为 42,温度(temperature)设为 0,基础模型的最大输出令牌数(max tokens)限制为 2048。对于 GPT-4o 和 GPT-4o Mini,我们启用了结构化输出模式(structured output mode),强制模型以 JSON 格式返回响应。由于当前其他开源多模态大语言模型(MLLMs)尚不支持该功能,因此该设置仅适用于上述两个闭源模型。系统提示(system prompt)统一设置为:"您是地质学和地图学专家,专注于地质图。"
探测模型 。
我们采用 YOLOv10作为检测框架,分别训练地图组件检测器 与图例单元检测器。
训练配置如下:输入图像统一调整为 640×640;优化器选用 SGD,初始学习率为 0.01,线性衰减至 0.0001;权重衰减设为 0.0005;总训练轮数(epoch)为 500。模型在单块 NVIDIA Ampere A100 GPU(80GB 显存)上训练,批大小(batch size)为 32。我们人工筛选并标注了约 1,000 张原始地质图作为训练数据集,确保其与 GeoMap-Bench 评估集无重叠。在推理阶段,非极大值抑制(Non-Maximum Suppression, NMS)的 IoU 阈值设为 0.8。
GEE API 。
在 Google Earth Engine(GEE)13 中,我们调用 "WorldPop/GP/100m/pop" 影像集获取人口密度数据,使用 "ESA/WorldCover/v200" 44 影像集获取土地覆盖数据。两个数据集的空间分辨率(scale)均设为 100 米。
科学数据库 。
历史地震数据来自 USGS 地震数据库 39,检索范围为 20 世纪 70 年代至今、震级大于 2.5 的地震事件。活动断层数据源自 GEM 全球活动断层数据库(GEM DB)36,该数据库目前覆盖了除马来群岛、马达加斯加、加拿大等少数区域外的全球主要构造变形区。
7.代码解析
7.1.智能体
这么里面定义了三个智能体:
首先看智能体的大脑LLM:
utils\api.py
python
# === Azure OpenAI 配置 ===
azure_endpoint = "" # 【待填写】Azure OpenAI 服务终结点 URL
identity_id = "" # 【待填写】托管身份客户端 ID(用于认证)
# 使用 Azure 托管身份获取访问令牌(无需密钥)
token_provider = get_bearer_token_provider(
DefaultAzureCredential(managed_identity_client_id=identity_id),
"https://cognitiveservices.azure.com/.default" # Azure AI 服务作用域
)
api_version = "2024-08-01-preview" # API 版本(需与 Azure 控制台一致)
# 创建 Azure OpenAI 客户端(使用令牌认证)
client = AzureOpenAI(
azure_endpoint=azure_endpoint,
azure_ad_token_provider=token_provider,
api_version=api_version,
max_retries=0, # 禁用 SDK 内置重试,由自定义逻辑控制
)
# === 核心函数:调用大模型生成回答 ===
def answer_wrapper(
messages,
max_tks=2048,
temperature=0.0,
structured=False,
tools=None):
"""
封装 Azure OpenAI 调用,支持 JSON 结构化输出、工具调用、错误重试。
参数:
messages: 对话消息列表(含 system/user/assistant 角色)
max_tks: 最大生成 token 数(默认 2048)
temperature: 采样温度(0.0 表示确定性输出)
structured: 是否强制 JSON 格式输出
tools: 可选的函数调用工具列表
返回:
成功时返回模型响应内容(str 或 ChatCompletionMessage),
失败时返回 None。
"""
models = [common.model_name] # 从 common 模块获取当前模型名(如 "gpt-4o")
max_trial = len(models) # 最大尝试次数(当前为 1)
current = random.randint(0, len(models) - 1) # 随机选择模型索引(多模型场景预留)
answer = None
for i in range(max_trial):
try:
response = None
# 如果启用了工具调用(Function Calling)
if tools is not None:
response = client.chat.completions.create(
model=models[current],
messages=messages,
temperature=temperature,
max_tokens=max_tks,
# 强制 JSON 输出(当 structured=True)
response_format={"type": "json_object" if structured else "text"},
tools=tools,
tool_choice="auto", # 自动决定是否调用工具
)
# 工具调用时返回完整 message 对象(含 tool_calls)
answer = response.choices[0].message
else:
# 普通问答模式
response = client.chat.completions.create(
model=models[current],
messages=messages,
temperature=temperature,
max_tokens=max_tks,
response_format={"type": "json_object" if structured else "text"},
)
# 仅返回文本内容
answer = response.choices[0].message.content
# ========== 错误处理 ==========
except openai.RateLimitError as e:
# 触发速率限制:等待后重试
logging.warning(f"RateLimitError: {e}. Retrying...")
time.sleep(2)
except openai.BadRequestError as e:
# 请求错误:根据错误类型决定跳过或终止
if e.code == "content_filter":
logging.warning(f"BadRequestError: content_filter triggered: {e}. Skipping...")
break # 内容被过滤,直接退出
elif e.code == "context_length_exceeded":
logging.warning(f"BadRequestError: context too long: {e}. Skipping...")
break # 上下文超长,无法修复
else:
logging.warning(f"BadRequestError: {e}. Skipping...")
break
except openai.APITimeoutError as e:
# API 超时:等待后重试
logging.warning(f"APITimeoutError: {e}. Retrying...")
time.sleep(2)
except openai.APIConnectionError as e:
# 连接中断(如网络问题):等待后重试
logging.warning(f"Connection aborted: {e}. Retrying...")
time.sleep(2)
except Exception as e:
# 兜底异常处理:检查是否因内容过滤导致
if response is not None and response.choices[0].finish_reason == "content_filter":
print("Messages that triggered content filter:")
print(messages)
print("Content filter details:", response.choices[0].content_filter_results)
logging.warning(f"{type(e).__name__}: content_filter triggered. Skipping...")
break
else:
# 其他未知错误:重试
logging.warning(f"{type(e).__name__}: {e}. Retrying...")
time.sleep(2)
# 成功获取回答则跳出循环
if answer is not None:
break
return answer地理学家智能体:geographer.py
python
# 定义地理学家智能体(Geographer Agent)
class geographer_agent:
"""
一个封装地理信息查询能力的智能体,
可自动获取指定区域的土地覆盖类型分布与人口密度数据。
"""
def __init__(self):
# 初始化两个外部 API 工具实例
self.landcover_type_api = landcover_type_api() # 土地覆盖分析工具
self.population_density_api = population_density_api() # 人口密度分析工具
def get_knowledge(self, min_lon, min_lat, max_lon, max_lat):
"""
根据给定的经纬度边界框(Bounding Box),获取该区域的地理知识。
参数:
min_lon (float): 西边界经度(例如 108.00°E)
min_lat (float): 南边界纬度(例如 19.33°N)
max_lon (float): 东边界经度(例如 109.00°E)
max_lat (float): 北边界纬度(例如 20.00°N)
返回:
dict: 包含土地覆盖分布和人口密度的字典
"""
# 调用土地覆盖 API,获取区域内各类地表覆盖的比例或统计信息
landcover_distribution = self.landcover_type_api.get_landcover_distribution(
min_lon, min_lat, max_lon, max_lat
)
# 调用人口密度 API,获取该区域的平均或总人口密度(单位:人/平方公里)
population_density = self.population_density_api.get_population_density(
min_lon, min_lat, max_lon, max_lat
)
# 整合为结构化地理知识
geographical_data = {
"landcover_distribution": landcover_distribution, # 如 {"森林": 45%, "农田": 30%, ...}
"population_density": population_density, # 如 120.5(人/km²)
}
return geographical_data还有的地质学家智能体和地震学家就不再赘述,基本原理:差不多就是传入数据然后调用工具返回想要的数据
7.2.资源目录
7.2.1.知识库
7.2.2.目标检测YOLO
这部分暂时跳过,
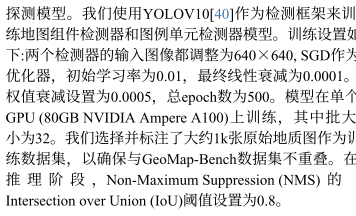
YOLO数据训练方法
7.3.模块
7.3.1.分层信息提取模块(HIE)
python
# 定义分层信息提取器(Hierarchical Information Extraction)
class hierarchical_information_extraction:
"""
对输入的地质图图像进行全自动数字化(Digitalization),
提取结构化元数据,包括:
- 地图组件布局(图例、主图、比例尺等)
- 图例内容(颜色、文字、岩石类型、年代)
- 基础信息(标题、经纬度、比例尺等)
- 岩石区域分割(可选)
所有结果缓存为 JSON 元数据文件,避免重复处理。
"""
def __init__(self):
# 初始化地质学家智能体(封装了图例识别、知识查询等能力)
self.geologist = geologist_agent()
def digitalize(self, image_path):
"""
对一张地质图进行端到端数字化处理,返回结构化元数据。
参数:
image_path (str): 输入地质图的路径(如 "sample.jpg")
返回:
dict: 包含所有提取信息的元数据字典
"""
# 读取原始图像
image = cv2.imread(image_path)
# 从路径中提取文件名(不含扩展名),作为地图唯一标识
name = common.path2name(image_path)
# 构建缓存元数据文件路径
meta_path = os.path.join(common.cache_path(), "meta", name + ".json")
# 如果已存在缓存,直接加载并返回(避免重复计算)
if os.path.exists(meta_path):
meta = json.loads(open(meta_path).read())
return meta
# ────────────────────────────────────────
# 初始化元数据结构
# ────────────────────────────────────────
meta = dict()
meta["date"] = common.today_date() # 处理日期(如 "2026-01-04")
meta["name"] = name # 地图名称(文件名)
meta["version"] = "v1.0" # 版本号
meta["source"] = common.dataset_source # 数据来源(如 "China Geological Survey")
meta["size"] = {"width": image.shape[1], "height": image.shape[0]} # 图像尺寸
meta["regions"] = dict() # 各组件边界框
meta["legend"] = dict() # 图例详细信息
meta["information"] = dict() # 结构化基础信息(标题、经纬度等)
meta["faults"] = None # 断层信息(当前未实现)
# ────────────────────────────────────────
# 步骤1:检测地图整体布局(定位各组件)
# ────────────────────────────────────────
map_layout = self.geologist.get_map_layout(image_path)
regions = map_layout["regions"] # 如 {"legend": [[x0,y0,x1,y1]], "main_map": [...], ...}
meta["regions"] = regions
# 使用 defaultdict 存储每个组件的裁剪路径和原始坐标
region_path_and_bbox = collections.defaultdict(list)
# 遍历所有检测到的组件(如图例、主图、比例尺等)
for region_name, region_bndboxes in regions.items():
for i, region_bndbox in enumerate(region_bndboxes):
# 构建裁剪后图像的保存路径
region_path = os.path.join(common.cache_path(), "det", name, f"{region_name}_{i}.png")
common.create_folder_by_file_path(region_path) # 自动创建目录
vision.crop_and_save_image(image, region_bndbox, region_path) # 裁剪并保存
region_path_and_bbox[region_name].append((region_path, region_bndbox))
# 特殊处理:主图(main_map)
if "main_map" == region_name:
# 进一步裁剪主图四角的经纬度标注区域(用于后续 OCR 提取坐标)
lonlat_name = "lonlat"
lonlat_region_path = os.path.join(common.cache_path(), "det", name, f"{lonlat_name}_{i}.png")
common.create_folder_by_file_path(lonlat_region_path)
vision.crop_corners_and_save_image(region_path, lonlat_region_path)
region_path_and_bbox[lonlat_name].append((lonlat_region_path, None)) # 无全局 bbox
# 特殊处理:索引图(index_map)
elif "index_map" == region_name:
# 在索引图上添加方向标注(如指北针、比例尺提示),辅助后续理解
vision.annotate_image_with_directions(region_path, region_path)
# ────────────────────────────────────────
# 步骤2:解析图例内容(颜色 + 文字 + 地质知识)
# ────────────────────────────────────────
if len(region_path_and_bbox["legend"]) > 0:
# 取第一个图例(通常只检测到一个)
legend_path, legend_bndbox = region_path_and_bbox["legend"][0]
# 调用地质学家智能体解析图例
legend_metadata = self.geologist.get_legend_metadata(legend_path, legend_bndbox)
legends = legend_metadata["legend"] # dict of legend units
# 为每个图例单元补充地质知识:岩石类型 & 地质年代
for legend in legends.values():
# 查询岩石类型(如 "花岗岩" → {"rock_type": "Igneous"})
rock_type_info = self.geologist.get_knowledge(
geological_knwoledge_type.Rock_Type, legend["text"]
)
legend["lithology"] = rock_type_info["rock_type"]
# 查询地质年代(如 "侏罗纪" → {"rock_age": "Mesozoic"})
rock_age_info = self.geologist.get_knowledge(
geological_knwoledge_type.Rock_Age, legend["text"]
)
legend["stratigraphic_age"] = rock_age_info["rock_age"]
meta["legend"] = legends
# ────────────────────────────────────────
# 步骤3:提取基础信息(标题、比例尺、经纬度等)
# ────────────────────────────────────────
# 定义需要 OCR + LLM 解析的组件类型
region_names = ["title", "scale", "lonlat", "index_map"]
for region_name in region_names:
if region_name not in region_path_and_bbox:
continue # 若未检测到该组件则跳过
# 取第一个实例
region_path, region_bndbox = region_path_and_bbox[region_name][0]
# 获取针对该组件的提示词(instruction)和预期输出键(keys)
keys, instruction = prompt.get_component_instruction(region_name)
# 构造多模态提示:图像 + 指令
prompt_content = [
{"type": "image_url", "image_url": {"url": api.local_image_to_data_url(region_path)}},
{"type": "text", "text": instruction},
]
messages = [
{"role": "system", "content": prompt.system_prompt}, # 系统角色设定
{"role": "user", "content": prompt_content},
]
# 调用大模型获取结构化信息
answer = api.answer_wrapper(messages, structured=True)
try:
infos = eval(answer) # ⚠️ 建议改用 json.loads(answer)
except:
infos = {}
# 将模型输出转换为标准键值对(如 {"title": "XX地区地质图"})
key_value_pairs = prompt.get_basic_information(region_name, infos)
for key, value in key_value_pairs:
meta["information"][key] = value
# ────────────────────────────────────────
# 步骤4:岩石区域语义分割(可选,用于统计分析)
# ────────────────────────────────────────
if len(region_path_and_bbox["main_map"]) > 0:
main_map_path, main_map_bndbox = region_path_and_bbox["main_map"][0]
# 基于图例颜色,对主图进行岩石类型区域分割(输出掩码或统计)
vision.rock_region_seg(main_map_path, list(meta["legend"].values()))
# ────────────────────────────────────────
# 保存并返回元数据
# ────────────────────────────────────────
common.create_folder_by_file_path(meta_path)
with open(meta_path, "w", encoding="utf-8") as f:
f.write(json.dumps(meta, indent=4, ensure_ascii=False))
return meta7.3.2.领域知识注入模块(DKI)

python
# 定义领域知识注入器(Domain Knowledge Injection)
class domain_knowledge_injection:
"""
根据给定的问题和地质图元数据,自动选择相关的领域知识(如地震风险、地理信息等)。
使用地震学家和地理学家智能体获取外部知识,并基于问题选择最相关的知识片段。
"""
def __init__(self):
# 初始化智能体(封装了知识查询能力)
self.seismologist = seismologist_agent() # 地震学家智能体
self.geographer = geographer_agent() # 地理学家智能体
def select(self, question, knowledge):
"""
基于给定问题,从专家小组提供的知识类型中选择最有帮助的知识类型。
参数:
question (str): 用户询问的问题
knowledge (dict): 知识字典,键为知识类型,值为对应内容
返回:
dict: 经过筛选后的知识字典
"""
# 获取所有知识类型的列表
knowledge_types = list(knowledge.keys())
# 示例答案格式
examples = '{"required_knowledge_types": %s}' % knowledge_types
# 构造多模态提示
instructions = [
{"type": "text", "text": f"The given question is '{question}'."},
{"type": "text", "text": f"The knowledge types from expert group are {', '.join(knowledge_types)}."},
{"type": "text",
"text": f'What are the helpful knowledge types among them to answer the given question, the example is {examples}, only respond with JSON format.\n'},
]
messages = [
{"role": "system", "content": prompt.system_prompt},
{"role": "user", "content": instructions},
]
# 调用API获取答案
answer = api.answer_wrapper(messages, structured=True)
try:
answer = eval(answer) # 解析回答
keys = answer["required_knowledge_types"]
except:
keys = list()
# 根据选定的知识类型过滤原始知识
selected_knowledge = dict()
for key in keys:
if key in knowledge:
selected_knowledge[key] = knowledge[key]
return selected_knowledge
def consult(self, question, meta):
"""
对给定的问题进行咨询,基于地质图元数据提取相关信息并选择相关领域知识。
参数:
question (str): 用户询问的问题
meta (dict): 地质图元数据
返回:
dict: 经筛选后适用于解答问题的相关知识
"""
if meta is None:
print("Missing metadata in DKI module", flush=True)
return None
# 构建缓存文件路径
knowledge_path = os.path.join(common.cache_path(), "knowledge", meta["name"] + ".json")
# 如果已有缓存,则直接加载
if os.path.exists(knowledge_path):
knowledge = json.loads(open(knowledge_path).read())
else:
# 处理经纬度范围
longitude_range = list(map(lambda x: common.convert_to_decimal(x), meta["information"]["longitude"]))
latitude_range = list(map(lambda x: common.convert_to_decimal(x), meta["information"]["latitude"]))
min_lon, max_lon = min(longitude_range), max(longitude_range)
min_lat, max_lat = min(latitude_range), max(latitude_range)
# 验证经纬度有效性
if common.is_valid_longitude(min_lon) and \
common.is_valid_longitude(max_lon) and \
common.is_valid_latitude(min_lat) and \
common.is_valid_latitude(max_lat):
# 调用地震学家智能体获取地震相关知识
seismic_data = self.seismologist.get_knowledge(min_lon, min_lat, max_lon, max_lat)
# 调用地理学家智能体获取地理相关知识
geographical_data = self.geographer.get_knowledge(min_lon, min_lat, max_lon, max_lat)
# 合并两种知识
knowledge = seismic_data | geographical_data
else:
knowledge = dict()
# 输出外部知识到缓存文件
common.create_folder_by_file_path(knowledge_path)
with open(knowledge_path, "w", encoding="utf-8") as f:
f.write(json.dumps(knowledge, indent=4, ensure_ascii=False))
# 根据问题选择相关知识
selected_knowledge = self.select(question, knowledge)
return selected_knowledge7.3.3.提示增强问答模块(PEQA)

python
class prompt_enhanced_QA:
"""
基于地质图组件关系进行提示增强的问答系统。
功能包括:
- 自动构建地质图各组件之间的语义关系;
- 根据问题类型和内容,动态选择最相关的地图组件;
- 构造多模态(图文)+ 结构化提示,引导大模型精准作答。
"""
def __init__(self):
# 获取所有预定义的地质图组件列表(如 "main_map", "legend", "title" 等)
self.components = list(prompt.components)
# 构建组件关系缓存路径
relation_path = os.path.join(common.cache_path(), "component", "relations.json")
# 若已缓存组件关系,则直接加载
if os.path.exists(relation_path):
self.component_relations = json.loads(open(relation_path).read())
else:
# 否则,调用大模型生成所有组件对之间的语义关系
examples = [
{"component1": "main_map", "component2": "legend", "relation": "XXX"},
{"component1": "scale", "component2": "title", "relation": "XXX"},
]
instructions = [
{"type": "text", "text": f"The components of geologic map are {', '.join(self.components)}."},
{"type": "text", "text": f'What are the relations for all the component pairs in geologic map, the example is {examples}, only respond with JSON format.\n'},
]
messages = [
{"role": "system", "content": prompt.system_prompt},
{"role": "user", "content": instructions},
]
# 调用大模型生成组件关系
self.component_relations = api.answer_wrapper(messages, structured=True)
# 缓存生成的关系到磁盘
common.create_folder_by_file_path(relation_path)
with open(relation_path, "w", encoding="utf-8") as f:
f.write(json.dumps(self.component_relations, indent=4, ensure_ascii=False))
def select(self, question, question_type):
"""
根据问题和问题类型,从地质图组件中选择最相关的若干组件。
参数:
question (str): 用户提出的问题
question_type (str): 问题类型(如 "extracting-sheet_name")
返回:
list[str]: 按重要性排序的组件名称列表(如 ["title", "index_map"])
"""
# 构建针对该问题类型的组件选择缓存路径
component_path = os.path.join(common.cache_path(), "component", question_type + ".json")
# 若已缓存,则直接返回
if os.path.exists(component_path):
selected_components = json.loads(open(component_path).read())
return selected_components
# 示例输出格式(键为序号,值为组件名)
examples = {"1": "XXX", "2": "XXX"}
# 构造提示:提供组件关系 + 问题,要求模型按重要性排序选择组件
instructions = [
{"type": "text", "text": f"The component relations of geologic map are {self.component_relations}"},
{"type": "text", "text": f"Select component(s) from {', '.join(self.components)}, which is/are used to answer the question, {question}, the example is: {examples}, only respond with JSON format by the order of importance.\n"},
]
messages = [
{"role": "system", "content": prompt.system_prompt},
{"role": "user", "content": instructions},
]
# 调用大模型获取选择结果
answer = api.answer_wrapper(messages, structured=True)
try:
selected_components = eval(answer) # ⚠️ 建议改用 json.loads
# 按字典键(序号)排序后提取组件名
selected_components = list(map(lambda x: x[1], sorted(selected_components.items(), key=lambda x: x[0])))
except:
selected_components = None
# 缓存选择结果
common.create_folder_by_file_path(component_path)
with open(component_path, "w", encoding="utf-8") as f:
f.write(json.dumps(selected_components, indent=4, ensure_ascii=False))
return selected_components
def answer(self, information, knowledge, enhance_prompt, image_path, question, question_type):
"""
构造增强提示并调用大模型回答问题。
参数:
information (dict): 地质图结构化元数据(来自 hierarchical_information_extraction)
knowledge (dict): 领域知识(来自 domain_knowledge_injection)
enhance_prompt (bool): 是否启用组件选择与上下文增强
image_path (str): 原始地质图路径
question (str): 用户问题
question_type (str): 问题类型
返回:
str: 大模型返回的答案(通常是 JSON 字符串)
"""
instructions = list()
# ────────────────────────
# 上下文增强:注入元数据和领域知识
# ────────────────────────
if information is not None:
# 对元数据进行清洗/标准化(如统一单位、格式)
prompt.polish_information(information)
instructions.append({"type": "text", "text": str(information)})
if knowledge is not None:
instructions.append({"type": "text", "text": str(knowledge)})
# ────────────────────────
# 提示增强模式(含组件选择 + 多图输入)
# ────────────────────────
if enhance_prompt:
# 动态选择相关组件
selected_components = self.select(question, question_type)
if selected_components is not None:
if information is not None:
# 如果有元数据,尝试加载对应组件的裁剪图像
for selected_component in selected_components:
selected_image_path = os.path.join(
common.cache_path(), "det", information["name"], f"{selected_component}_0.png"
)
if os.path.exists(selected_image_path):
# 添加裁剪后的组件图像到提示中
instructions.append({
"type": "image_url",
"image_url": {"url": api.local_image_to_data_url(selected_image_path)}
})
# 若未成功添加任何图像(如缓存缺失),则回退到原图 + 文本提示
if len(instructions) == (2 if information and knowledge else 1 if information or knowledge else 0):
if len(selected_components) > 0:
instructions.append({"type": "text", "text": f"Let's focus more on {', '.join(selected_components)}"})
instructions.append({
"type": "image_url",
"image_url": {"url": api.local_image_to_data_url(image_path)}
})
else:
# 无元数据时,仅用文本强调 + 原图
if len(selected_components) > 0:
instructions.append({"type": "text", "text": f"Let's focus more on {', '.join(selected_components)}"})
instructions.append({
"type": "image_url",
"image_url": {"url": api.local_image_to_data_url(image_path)}
})
# 添加针对问题类型的指令(含思维链 CoT + JSON 输出格式 + few-shot 示例)
question_instruction = prompt.ability2instruction(question_type, vision.image_size(image_path))
instructions.append({"type": "text", "text": f"Instruction: {question_instruction}\n"})
# ────────────────────────
# 非增强模式:仅使用原图 + 简化指令
# ────────────────────────
else:
instructions.append({
"type": "image_url",
"image_url": {"url": api.local_image_to_data_url(image_path)}
})
# 构造简化指令(仅保留 JSON 输出格式示例)
question_instruction = prompt.ability2instruction(question_type, vision.image_size(image_path))
question_instruction = question_instruction[:question_instruction.find('{"answer":')] + '{"answer": "XXX"}'
instructions.append({"type": "text", "text": f"Instruction: {question_instruction}\n"})
# 添加最终问题和答案占位符
instructions.append({"type": "text", "text": f"Question: {question}\n"})
instructions.append({"type": "text", "text": f"Answer: "})
# 构建完整消息
messages = [
{"role": "system", "content": prompt.system_prompt},
{"role": "user", "content": instructions},
]
# 调试输出(若开启 echo)
if common.echo:
print("======================================================")
print("Image:", image_path, flush=True)
print("Question Type:", question_type, flush=True)
print("Question Instruction:", question_instruction, flush=True)
print("Question:", question, flush=True)
# 调用大模型获取结构化答案
answer = api.answer_wrapper(messages, structured=True)
return answer7.4.工具池

7.4.1.活动断层数据获取工具
python
class active_fault_db:
"""
封装 GEM 全球活动断层数据库的查询功能。
支持根据经纬度范围提取相交的活动断层,并计算其在该区域内的长度(km)。
"""
def __init__(self, db_path="./dependencies/knowledge/gem_active_faults_harmonized.geojson"):
"""
初始化:加载 GeoJSON 格式的活动断层数据库。
参数:
db_path (str): GeoJSON 文件路径,默认为项目依赖目录下的 GEM 数据。
"""
self.fault_db = gpd.read_file(db_path) # 使用 GeoPandas 读取矢量数据
def get_active_faults(self, min_lon, min_lat, max_lon, max_lat):
"""
查询与给定经纬度矩形范围相交的所有活动断层,并返回其关键属性及在范围内的长度。
参数:
min_lon, max_lon (float): 经度范围(东经)
min_lat, max_lat (float): 纬度范围(北纬)
返回:
list[dict] 或 str:
- 若有断层:返回包含断层信息的字典列表;
- 若无断层:返回提示字符串。
"""
# 创建一个 Shapely 的矩形边界框(注意:box(minx, miny, maxx, maxy))
bbox = box(min_lon, min_lat, max_lon, max_lat)
# 筛选出与该边界框相交的断层线(LineString 或 MultiLineString)
intersecting_lines = self.fault_db[self.fault_db.intersects(bbox)]
# 如果没有相交的断层
if intersecting_lines.empty:
active_fault_lines = "No active fault within the given range."
else:
# 避免 SettingWithCopyWarning,先复制一份
intersecting_lines = intersecting_lines.copy()
# 计算每条断层与查询区域的实际交集几何(可能是 LineString 片段)
intersecting_lines["intersection"] = intersecting_lines.geometry.intersection(bbox)
# 自动估算适合该区域的投影坐标系(通常是 UTM)
utm_crs = intersecting_lines.estimate_utm_crs()
# 将几何列切换为交集部分,并投影到 UTM(以米为单位,便于计算长度)
intersecting_lines = intersecting_lines.set_geometry("intersection")
intersecting_lines = intersecting_lines.to_crs(utm_crs)
# 计算交集部分的长度(单位:米)
intersecting_lines["length_m"] = intersecting_lines.length
# 转换为公里,并保留两位小数
intersecting_lines["length_in_kilometers"] = round(intersecting_lines["length_m"] / 1000.0, 2)
# 选择需要返回的字段
selected_columns = [
"slip_type", # 滑动类型(正断层、逆断层、走滑等)
"name", # 断层名称
"catalog_name", # 来源目录名
"length_in_kilometers", # 在查询区域内的长度(km)
"dip_dir", # 倾向(dip direction)
"average_dip", # 平均倾角
"average_rake", # 平均 rake 角(滑动方向)
"lower_seis_depth", # 地震活动下界深度(km)
"upper_seis_depth" # 地震活动上界深度(km)
]
# 转换为字典列表格式(便于 JSON 序列化)
active_fault_lines = intersecting_lines[selected_columns].to_dict(orient="records")
return active_fault_lines7.4.2.地图组件检测器
python
import os
os.sys.path.append(f"{os.path.dirname(os.path.realpath(__file__))}/..")
from dependencies.ultralytics import YOLOv10
class map_component_detector:
def __init__(self, model_path="./dependencies/models/det_component/weights/best.pt"):
self.model = YOLOv10(model_path)
def detect(self, image_path):
objs = self.model.predict(source=image_path)[0]
return objs
if __name__ == "__main__":
map_component_detector = map_component_detector()
print(map_component_detector.detect("sample.jpg"))这个模型权重下载:
python
pip install gdown
gdown https://drive.google.com/uc?id=1f7dUdfA_W8He9czG6SoYQBmUsSPrA6MZ
unzip models.zip -d dependencies梯子直接连接下载:

可以运行以一下:
python
import os
import sys
current_dir = os.path.dirname(os.path.abspath(__file__))
project_root = os.path.dirname(current_dir)
dependencies_path = os.path.join(project_root, 'dependencies')
# 将项目的 dependencies 路径插入到 sys.path 的第0位(最高优先级)
# 这样在 import ultralytics 时,会优先从这里找,而不是去 venv 里找
if dependencies_path not in sys.path:
sys.path.insert(0, dependencies_path)
sys.path.insert(0, project_root) # 把项目根目录也加入,以防万一
# Ensure local ultralytics is loaded before any site-packages version
ROOT = os.path.abspath(os.path.join(os.path.dirname(os.path.realpath(__file__)), ".."))
if ROOT not in sys.path:
sys.path.insert(0, ROOT)
from dependencies.ultralytics import YOLOv10
class map_component_detector:
def __init__(self, model_path=r"..\dependencies\models\det_component\weights\best.pt"):
self.model = YOLOv10(model_path)
def detect(self, image_path):
objs = self.model.predict(source=image_path)[0]
return objs
if __name__ == "__main__":
print("Testing map_component_detector...")
map_component_detector = map_component_detector()
print(map_component_detector.detect("G4704.jpg"))

基本检测的都是对的
7.5.工具函数
其实应该第一详细讲这个目录的
api.py就是之前讲的LLM的API
common.py就是一个格式转换的功能函数
python
# 初始化谷歌地球引擎。
ee.Authenticate(auth_mode="notebook")
ee.Initialize()
def today_date():
"""获取当前日期并格式化为YYYYMMDD字符串"""
today = date.today()
formatted_date = today.strftime("%Y%m%d")
return formatted_date
def path2name(path):
"""从文件路径中提取文件名(不含扩展名)"""
name = os.path.splitext(os.path.basename(path))[0]
return name
def cache_path():
"""构建并返回缓存文件夹路径"""
cache_path = os.path.join(".cache", dataset_source, model_name)
return cache_pathvision.py:对目标检测区域进行裁剪,
python
def crop_corners_and_save_image(image, cropped_image_path, relative_size=0.1):
"""裁剪图像的四个角落(例如用于捕捉边缘标记)并拼接保存
Args:
image: 输入图像路径或图像数组
cropped_image_path: 保存路径
relative_size: 角落裁剪的相对大小(相对于图像宽高的比例)
"""
if isinstance(image, str):
image = cv2.imread(image)
# 定义要裁剪的角落的相对大小(例如高度的10%和宽度的10%)
height, width, _ = image.shape
corner_height = int(height * relative_size)
corner_width = int(width * relative_size)
# 裁剪左上角
top_left = image[0:corner_height, 0:corner_width]
# 裁剪右上角
top_right = image[0:corner_height, width - corner_width:width]
# 裁剪左下角
bottom_left = image[height - corner_height:height, 0:corner_width]
# 裁剪右下角
bottom_right = image[height - corner_height:height, width - corner_width:width]
# 将角落合并为一张图像
# 首先水平合并上方的角落
top_combined = np.hstack((top_left, top_right))
# 然后水平合并下方的角落
bottom_combined = np.hstack((bottom_left, bottom_right))
# 最后垂直堆叠上方和下方合并后的图像
cropped_image = np.vstack((top_combined, bottom_combined))
cv2.imwrite(cropped_image_path, cropped_image)
def calc_image_rgb(image):
"""计算图像的主要颜色(中位数),过滤掉接近黑色的像素
Returns:
RGB颜色的numpy数组
"""
# 过滤掉深色像素(R,G,B均小于16的像素),然后计算中位数颜色
pixel_list = np.array(
list(filter(lambda c: not (c[0] < 16 and c[1] < 16 and c[2] < 16), list(image.reshape(-1, 3)))),
dtype=image.dtype)
# color, _ = Counter(map(tuple, pixel_list)).most_common(1)[0]
# color = np.mean(pixel_list, axis=0)
color = np.median(pixel_list, axis=0)
return color[::-1] # OpenCV默认是BGR,这里转换为RGB