文章目录
- 前言
- 应用层
-
- 应用层协议原理
- [Web 和 HTTP](#Web 和 HTTP)
-
- [HTTP 概况](#HTTP 概况)
- 非持续连接和持续连接
-
- [采用非持续连接的 HTTP](#采用非持续连接的 HTTP)
- [采用持续连接的 HTTP](#采用持续连接的 HTTP)
- [HTTP 报文格式](#HTTP 报文格式)
-
- [HTTP 请求报文](#HTTP 请求报文)
- [HTTP 响应报文](#HTTP 响应报文)
- [用户与服务器的交互: cookie](#用户与服务器的交互: cookie)
- [Web 缓存](#Web 缓存)
- [条件 GET 方法](#条件 GET 方法)
- 因特网中的电子邮件
- 参考目录
前言
阅读本文前请注意最后编辑时间,文章内容可能与目前最新的技术发展情况相去甚远。欢迎各位评论与私信,指出错误或是进行交流等。
本文是关于《计算机网络:自顶向下方法(第七版)》的学习分享,内容书写顺序也是按照书中的顺序。本文并不会提及书中的所有内容,主要写重点的知识,以及自己感兴趣的内容。会对原文中的内容进行一定的精简,或者加上个人的理解。
应用层
应用层协议原理
研发网络应用程序的核心是写出能够运行在不同的端系统和通过网络彼此通信的程序。例如, 在Web应用程序中,有两个互相通信的不同的程序: 一个是运行在用户主机上的浏览器程序;另一个是运行在Web服务器主机上的Web 服务器程序。此外,你不需要写在网络核心设备如路由器或链路层交换机上运行的软件。 (网络核心设备并不在应用层上起作用,而仅在较低层起作用,特别是在网络层及下面层次起作用。)
网络应用程序体系结构
当进行应用程序编码之前,应当有一个宽泛的体系结构计划。 应用程序体系结构由研发者设计,规定了如何在各种端系统上组织该应用程序。 在选择应用程序体系结构时,研发者很可能利用现代网络应用程序中所使用的两种主流体系结构之一:客户-服务器体系结构或对等 (P2P) 体系结构。
在客户-服务器体系结构中,有一个总是打开的主机称为服务器,它服务于来自许多其他称为客户的主机的请求。一个典型的例子是Web应用程序,其中总是打开的 Web 服务器服务于来自浏览器(运行在客户主机上)的请求。 当Web 服务器接收到来自某客户对某对象的请求时,它向该客户发送所请求的对象作为响应。 值得注意的是客户-服务器体系结构,客户相互之间不直接通信;客户-服务器体系结构的另一个特征是该服务器具有固定的、周知的地址,该地址称为IP地址。 因为该服务器具有固定的、 周知的地址,并且因为该服务器总是打开的,客户总是能够通过向该服务器的 IP地址发送分组来与其联系。
客户-服务器体系结构,又分为两种主流的软件架构模式:C/S(Client-Server,客户端/服务器)与B/S(Browser-Server,浏览器/服务器)是两种主流的软件架构模式,核心区别在于客户端的形式、部署方式及适用场景:CS架构需安装专用客户端软件,适用于局域网内高安全性需求;BS架构通过浏览器访问,依托广域网实现跨平台,但安全性相对较低。关于C/S与B/S的其他知识请自行查阅资料
在P2P体系结构中,对服务器有最小的(或者没有)依赖。 与客户-服务器体系结构相反,P2P体系结构中的主机对之间使用直接通信,这些主机对被称为对等方。 这些对等方并不是服务提供商所有,是用户控制的主机,大多数对等方在家庭、大学和办公室。 因为这种对等方通信不必通过专门的服务器,该体系结构被称为对等方到对等方的。 许多目前流行的、流量密集型应用都是P2P体系结构的。 这些应用包括文件共享(例如BitTorrent) 、对等方协助下载加速器 (例如迅雷)、因特网电话和视频会议(例如 Skype)。 需要提及的是,某些应用具有混合的体系结构,它结合了客户-服务器和P2P的元素。
进程通信
在构建网络应用程序前,还需要对运行在多个端系统上的程序是如何互相通信的情况有一个基本了解。 用操作系统的术语来说,进行通信的实际上是进程而不是程序。当多个进程运行在相同的端系统上时,它们使用进程间通信机制相互通信。 进程间通信的规则由端系统上的操作系统确定。 我们并不特别关注同一台主机上的进程间的通信,而关注运行在不同端系统(可能具有不同的操作系统)上的进程间的通信。
在两个不同端系统上的进程,通过跨越计算机网络交换报文 (message) 而相互通信。发送进程生成报文并向网络中发送;接收进程接收这些报文并可能通过回送报文进行响应。
客户和服务器进程
网络应用程序由成对的进程组成,这些进程通过网络相互发送报文。 例如,在 Web应用程序中, 一个客户浏览器进程与一台 Web 服务器进程交换报文。 在一个P2P文件共享系统中,文件从一个对等方中的进程传输到另一个对等方中的进程。 对每对通信进程,我们通常将这两个进程之一标识为客户 (client) , 而另一个进程标识为服务器 (server)。对于 Web而言,浏览器是一个客户进程, Web 服务器是一台服务器进程。 对于P2P文件共享,下载文件的对等方标识为客户,上载文件的对等方标识为服务器。在P2P文件共享的某些应用中, 一个进程能够既是客户又是服务器。 在P2P文件共享系统中,一个进程的确既能上载文件又能下载文件。
进程与计算机网络之问的接口
进程通过一个称为套接字 (socket) 的软件接口向网络发送报文和从网络接收报文。如下图所示,两个经过因特网通信的进程(图中假定该进程使用的运输层协议是TCP协议)。 套接字是一台主机内应用层与运输层之间的接口。 该套接字可称为应用程序和网络之间的应用程序编程接口 (Application Programming Interface, API) 。应用程序开发者可以控制套接字在应用层端的一切,但是对该套接字的运输层端几乎没有控制权。 应用程序开发者对于运输层的控制仅限有: 1.选择运输层协议; 2.也许能设定几个运输层参数,如最大缓存和最大报文段长度等。一旦应用程序开发者选择了一个运输层协议(如果可供选择的话),则应用程序就建立在由该协议提供的运输层服务之上。
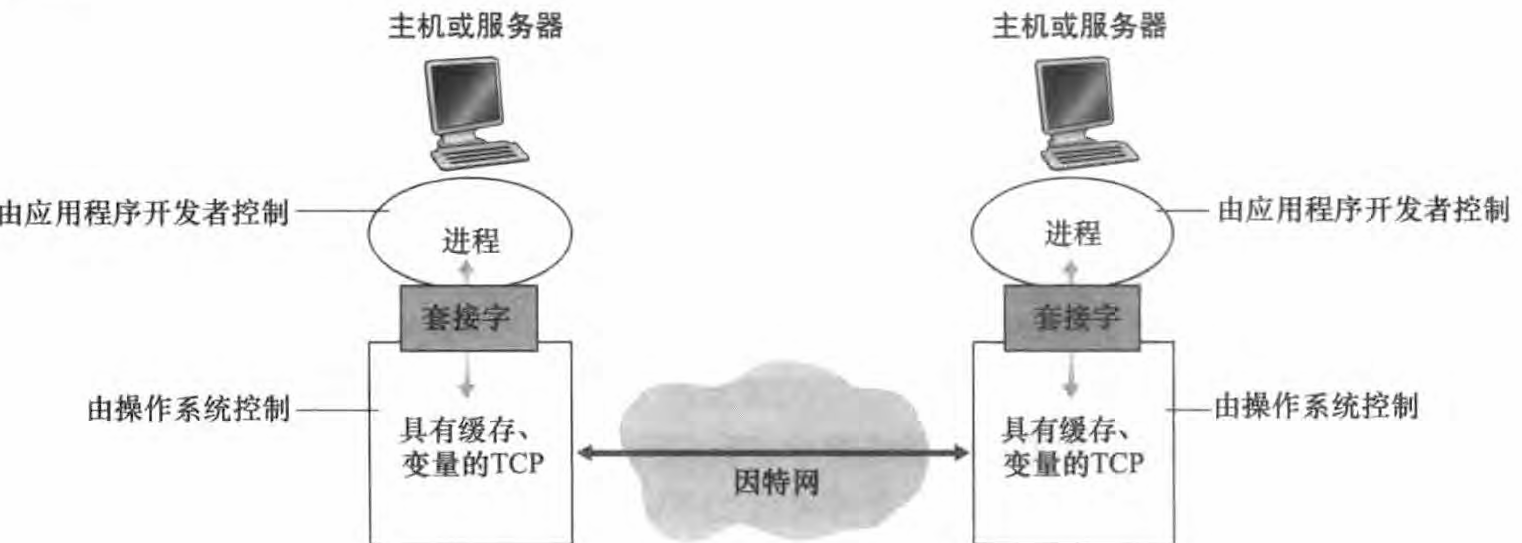
进程寻址
在一台主机上运行的进程为了向在另一台主机上运行的进程发送分组,接收进程需要有一个地址。 为了标识该接收进程, 需要定义两种信息: 1.主机的地址; 2.在目的主机中指定接收进程的标识符。在因特网中,主机由其IP地址标识。除了知道报文发送目的地的主机地址外,发送进程还必须指定运行在接收主机上的接收进程(更具体地说,接收套接字)。 因为一般而言一台主机能够运行许多网络应用,目的地端口号 (port number) 用于指定接收进程的标识。 对于一些流行的应用已经分配了特定的端口号。 例如, Web 服务器用端口号80来标识。
可供应用程序使用的运输服务
套接字是应用程序进程和运输层协议之间的接口。 在发送端的应用程序进程将报文推进该套接字,运输层协议通过该套接字接收到该报文(往下进行传输)。在接收端的主机,运输层将收到的报文交给套接字,套接字解析后给到上层的应用程序进程。
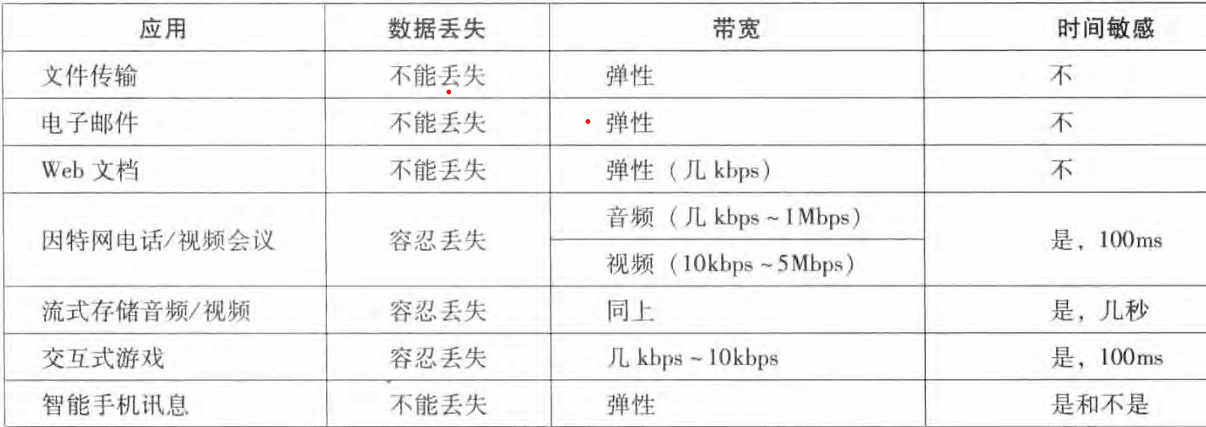
网络提供了不止一种运输层协议。 当开发一个应用时,必须选择一种可用的运输层协议。通过研究这些可用的运输层协议所提供的服务,选择一个最能为你的应用需求提供恰当服务的协议。一个运输层协议能够为调用它的应用程序提供什么样的服务呢?我们大体能够从四个方面对应用程序服务要求进行分类:可靠数据传输、 吞吐量、时延和安全性。
可靠数据传输
分组在计算机网络中可能丢失。例如,分组能够使路由器中的缓存溢出,或者当分组中的某些比特损坏后可能被丢弃。像电子邮件、文件传输、 远程主机访问、 Web文档传输以及金融应用等这样的应用,数据丢失可能会造成灾难性的后果 。 因此,为了支持这些应用,必须做
一些工作以确保由发送端的数据正确、 完全地交付给接收端。如果一个协议提供了确保数据交付服务,就认为提供了可靠数据传输。运输层协议能够潜在地向应用程序提供的一个重要服务是进程到进程的可靠数据传输。 当一个运输协议提供这种服务时,发送进程只要将其数据传递进套接字,就可以完全相信该数据将能无差错地到达接收进程。
当一个运输层协议不提供可靠数据传输时,由发送进程发送的某些数据可能到达不了接收进程。 这可能能被容忍丢失的应用所接受,如交谈式音频/视频,它们能够承受一定量的数据丢失。 在这些多媒体应用中,丢失的数据引起播放的音频/视频出现小干扰,而不是致命的损伤。
吞吐量
在沿着一条网络路径上的两个进程之间的通信会话场景中,可用吞吐量就是发送进程能够向接收进程交付比特的速率。因为其他会话将共享该网络路径的带宽,并且因为这些会话将会到达和离开,该可用吞吐量将随时间波动。因此需要提供另一种服务,即运输层协议能够以某种特定的速率提供确保的可用吞吐量。假如应用程序需要r 比特/秒的确保吞吐量,该运输协议能够确保可用吞吐量总是至少为r 比特/秒。例如,如果因特网电话应用程序对语音以 32kbps 的速率进行编码,那么它需要以这个速率向网络发送数据,并以该速率向接收应用程序交付数据。如果运输协议提供的吞吐量不够,该应用程序可能以较低速率进行编码、或它可能必须放弃发送。这是因为对于这种因特网电话应用
而言,吞吐量只达到所需的一半是几乎没有用处的。具有吞吐量要求的应用程序被称为带宽敏感的应用。许多当前的多媒体应用是带宽敏
感的, 某些多媒体应用程序可能采用自适应编码技术对数字语音或视频以与当前可用带宽相匹配的速率进行编码。
时延
运输层协议也能提供时延保证。 如同具有吞吐量保证那样,时延保证能够以多种形式实现。 例如: 发送方注入进套接字中的每个比特到达接收方的套接字不迟于100ms。 这种服务将对交互式实时应用程序有吸引力,如因特网电话、虚拟环境、电话会议和多方游戏,所有这些服务为了有效性而要求数据交付有严格的时间限制。 例如,在因特网电话中,较长的时延会导致会话中出现不自然的停顿;
安全性
运输协议能够为应用程序提供一种或多种安全性服务。 例如, 在发送主机中,运输协议能够加密由发送进程传输的所有数据,在接收主机中,运输层协议能够在将数据交付给接收进程之前解密这些数据。 运输协议还能提供除了机密性以外的其他安全性服务,包括数据完整性和端点鉴别。
因特网提供的运输服务
现在我们要更为具体地考察由因特网提供的运输服务类型。 因特网(更一般的是TCP/IP 网络)为应用程序提供两个运输层协议,即 UDP和TCP。 当你(作为一个软件开发者)为因特网创建一个新的应用时,首先要做出的决定是,选择UDP还是选择TCP.。应用程序根据其所需要的服务选择UDP或者TCP。如下图所示,是一些常见应用的服务需求。
TCP
TCP 协议提供面向连接服务和可靠数据传输服务,当某个应用程序调用TCP作为其运输协议时,该应用程序就能获得来自 TCP的这两种服务。
- 面向连接的服务:在应用层数据报文开始流动之前, TCP让客户和服务器互相交换运输层控制信息。 这个所谓的握手过程提醒客户和服务器,让它们为大量分组的到来做好准备。 在握手阶段后,一个TCP连接就在两个进程的套接字之间建立了。 这条连接是全双工的,即连接双方的进程可以在此连接上同时进行报文收发。 当应用程序结束报文发送时,必须拆除该连接。
- 可靠的数据传送服务: 通信进程能够依靠TCP, 无差错、按适当顺序交付所有发送的数据。 当应用程序的一端将字节流传进套接字时,它能够依靠TCP将字节流交付给接收方的套接字,而没有字节的丢失和冗余。
TCP 协议还具有拥塞控制机制,这种服务不一定能为通信进程带来直接好处,但能为因特网带来整体好处。 当发送方和接收方之间的网络出现拥塞时, TCP 的拥塞控制机制会抑制发送进程(客户或服务器)。
UDP
UDP 是一种不提供不必要服务的轻量级运输协议,它仅提供最小服务。 UDP是无连接的,因此在两个进程通信前没有握手过程。 UDP协议提供一种不可靠数据传送服务,也就是说,当进程将一个报文发送进套接字时, UDP协议并不保证该报文将到达接收进程。 不仅如此,到达接收进程的报文也可能是乱序到达的。UDP 没有包括拥塞控制机制,所以 UDP 的发送端可以用它选定的任何速率向其下层(网络层)注入数据。 (然而,值得注意的是实际端到端吞吐量可能小于该速率,这可能是因为中间链路的带宽受限或因为拥塞而造成的。)
关注安全性
无论TCP还是 UDP 都没有提供任何加密机制,这就是说发送进程传进套接字的数据,与经网络传送到目的进程的数据相同。 举例来说如果某发送进程以明文方式(即没有加密)发送了一个口令进入它的套接字,该明文口令将经过发送方与接收方之间的所有链路传送,这就可能在任何中间链路被嗅探和发现。 因为隐私和其他安全问题对许多应用而言已经成为至关重要的问题,所以因特网界已经研制了 TCP 的加强版本,称为安全套接字层 (Secure Sockets Layer, SSL) 。用 SSL 加强后的 TCP 不仅能够做传统的TCP 所能做的一切,而且提供了关键的进程到进程的安全性服务,包括加密、 数据完整性和端点鉴别。SSL不是与 TCP和 UDP在相同层次上的笫三种运输协议,而是一种对TCP的加强,这种强化是在应用层上实现的。 如果一个应用程序要使用 SSL 的服务,它需要在该应用程序的客户端和服务器端拥有SSL代码。 SSL有它自己的套接字API, 这类似于传统的 TCP套接字API。 当一个应用使用 SSL 时,发送进程向 SSL套接字传递明文数据;在发送主机中的 SSL 则加密该数据并将加密的数据传递给TCP套接字。 加密的数据经因特网传送到接收进程中的TCP套接字。 该接收套接字将加密数据传递给SSL, 由其进行解密。 最后, SSL通过它的 SSL套接宇将明文数据传递给接收进程。
应用层协议
通过把报文发送进套接字实现网络进程间的相互通信。 但是如何构造这些报文?在这些报文中的各个字段的含义是什么?进程何时发送这些报文?这些问题将我们带进应用层协议的范围。 应用层协议定义了运行在不同端系统上的应用程序进程如何相互传递报文。 特别是应用层协议定义了:
- 交换的报文类型,例如请求报文和响应报文。
- 各种报文类型的语法,如报文中的各个字段及这些字段是如何描述的。
- 字段的语义,即这些字段中的信息的含义。
- 确定一个进程何时以及如何发送报文,对报文进行响应的规则。
有些应用层协议是由 RFC 文档定义的,因此它们位于公共域中。 例如, Web 的应用层协议HTTP (超文本传输协议RFC 2616) 。 如果浏览器开发者遵从HTTP RFC 规则,所开发出的浏览器就能访问任何遵从该文档标准的Web服务器并获取相应Web页面。 还有很多别的应用层协议是专用的,有意不为公共域使用。 例如Skype 使用了专用的应用层协议。
区分网络应用和应用层协议是很重要的。 应用层协议只是网络应用的一部分。 例如,Web是一种客户-服务器应用,它允许客户按照需求从 Web 服务器获得文档。 该Web应用有很多组成部分,包括文档格式的标准(即 HTML) 、 Web 浏览器(如Firefox 和 Microsoft Internet Explorer) 、Web 服务器(如 Apache、 Microsoft 服务器程序),以及一个应用层协议。 Web 的应用层协议是HTTP, 它定义了在浏览器和 Web 服务器之间传输的报文格式和序列。 因此, HTTP只是Web应用的一个部分(尽管是重要部分)。
Web 和 HTTP
HTTP 概况
Web 的应用层协议是超文本传输协议 (HyperText Transfer Protocol, HTTP) , 它是 Web的核心,在 RFC 1945 和RFC 2616 中进行了定义。客户端和服务器程序通过交换HTTP 报文进行会话。HTTP定义了这些报文的结构以及客户和服务器进行报文交换的方式。 在详细解释HTTP之前,应当回顾某些 Web术语。
Web 页面(也叫文档)是由对象组成的。 一个对象是一个文件,诸如一个 HTML文件、一个JPEG 图形、 一个 Java 小程序或一个视频片段这样的文件,且它们可通过一个URL地址寻址。 多数Web 页面含有一个 HTML基本文件以及几个引用对象。 例如,如果一个Web 页面包含HTML文本和5 个JPEG 图形,那么这个Web 页面有6个对象: 一个HTML基本文件加5个图形。 HTML基本文件通过对象的 URL地址引用页面中的其他对象。 每个 URL地址由两部分组成:存放对象的服务器主机名和对象的路径名。 例如, URL 地址 http://www. someSchool.edu/someDepartment/picture.gif, 其中的 www. someSchool. edu 就是主机名, /someDepartment/picture. gif就是路径名。 因为Web浏览器(例如 Intemel Explorer 和 Firefox) 实现了HTTP 的客户端,所以在Web环境中我们经常交替使用"浏览器"和"客户"这两个术语。 Web服务器实现了 HTTP 的服务器端,它用于存储Web对象,每个对象由 URL 寻址。 流行的Web服务器有 Apache 和 Microsoft Internet Information Server
HTTP 定义了 Web 客户向 Web 服务器请求 Web页面的方式,以及服务器向客户传送 Web 页面的方式。
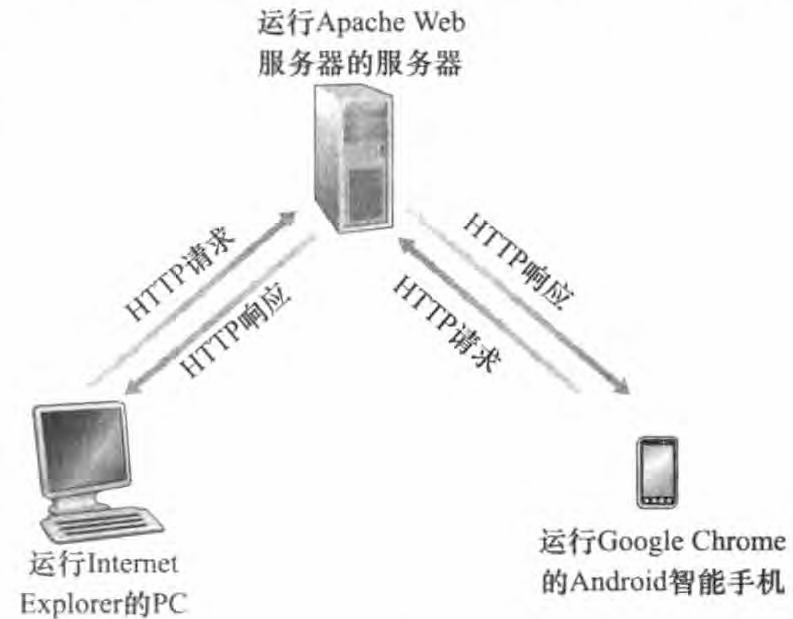
如上图所示, 当用户请求一个 Web 页面(如点击一个超链接)时,浏览器向服务器发出对该页面中所包含对象的HTTP请求报文, 服务器接收到请求并用包含这些对象的HTTP响应报文进行响应。
HTTP 使用 TCP 作为它的支撑运输协议(而不是在 UDP上运行)。 HTTP 客户首先发起一个与服务器的TCP连接。一旦连接建立,该浏览器和服务器进程就可以通过套接字接口访问 TCP。 客户向它的套接字接口发送HTTP 请求报文并从它的套接字接口接收HTTP 响应报文。类似地,服务器从它的套接字接口接收HTTP请求报文和向它的套接字接口发送HTTP响应报文。 一旦客户向它的套接字接口发送了一个请求报文,该报文就脱离了客户控制并进入TCP 的控制。TCP 为 HTTP 提供可靠数据传输服务。 这意味着, 一个客户进程发出的每个 HTTP请求报文最终能完整地到达服务器;类似地,服务器进程发出的每个 HTTP响应报文最终能完整地到达客户。 这里我们看到了分层体系结构最大的优点,即 HTTP协议不用担心数据丢失, 也不关注TCP从网络的数据丢失和乱序故障中恢复的细节。 那是TCP 以及协议栈较低层协议的工作。
注意下列现象: 服务器向客户发送被请求的文件,而不存储任何关于该客户的状态信息。 假如某个特定的客户在短短的几秒内两次请求同一个对象,服务器并不会因为刚刚为该客户提供了该对象就不再做出反应,而是重新发送该对象,就像服务器已经完全忘记不久之前所做过的事一样。 因为 HTTP服务器并不保存关于客户的任何信息,所以我们说HTTP 是一个无状态协议。我们同时也注意到 Web 使用了客户-服务器应用程序体系结构。 Web 服务器总是打开的,具有一个固定的IP 地址, 且它服务于可能来自数以百万计的不同浏览器的请求
非持续连接和持续连接
在许多因特网应用程序中,客户和服务器在一个相当长的时间范围内通信,其中客户发出一系列请求并且服务器对每个请求进行响应。依据应用程序以及该应用程序的使用方式, 这一系列请求可以按规则的间隔周期性地或者间断性地一个接一个发出。 当这种客户-服务器的交互是经TCP进行的,应用程序的研制者就需要做一个重要决定,即每个请求/响应对是经一个单独的 TCP连接发送,还是所有的请求及其响经相同的TCP连接发送呢?采用前一种方法, 该应用程序被称为使用非持续连接; 采用后一种方法,该应用程序被称为使用持续连接;为了深入地理解该设计问题,我们研究在特定的应用程序即 HTTP 的情况下持续连接的优点和缺点,即使HTTP既能够使用非持续连接,也能够使用持续连接。
采用非持续连接的 HTTP
在非待续连接情况下,从服务器向客户传送一个Web 页面的步骤。假设该页面含有一个HTML基本文件和 10个JPEG 图形、并且这 11 个对象位于同一台服务器上。 进一步假设该HTML文件的URL为: http://www. someSchool. edu/someDepartment/home. index
我们看看发生了什么情况:
- HTTP 客户进程在端口号 80 发起一个到服务器www. someSchool.edu 的 TCP 连接,该端口号是HTTP 的默认端口。 在客户和服务器上分别有一个套接字与该TCP连接相关联。
- HTTP 客户经它的套接字向该服务器发送一个 HTTP请求报文。 请求报文中包含了路径名/someDepartment/home. index
- HTTP 服务器进程经它的套接字接收该请求报文,从其存储器 (RAM 或磁盘)中检索出对象www.someSchool.edu/someDepartment/home. index, 在一个 HTTP 响应报文中封装对象,并通过其套接字向客户发送响应报文。
- HTTP 服务器进程通知 TCP 断开该 TCP连接。 (直到 TCP确认客户已经完整地收到响应报文为止,它才会实际中断连接。)
- HTTP 客户接收响应报文, TCP 连接关闭。 该报文封装的对象是一个 HTML文件。客户从响应报文中提取出该文件,检查该HTML文件,并得到对10个JPEG 图形的引用。
- 对每个引用的JPEG 图形对象重复前4 个步骤。
当浏览器收到Web页面后,向用户显示该页面。 两个不同的浏览器也许会以不同的方式向用户显示该页面。 HTTP 与浏览器如何解释一个 Web 页面毫无关系。HTTP 规范 (RFC 1945 和RFC 2616) 仅定义了在HTTP 客户程序与 HTTP 服务器程序之间的通信协议。
上面的步骤举例说明了非持续连接的使用,其中每个TCP连接在服务器发送一个对象后关闭,即该连接并不为其他的对象而持续下来。 值得注意的是每个TCP连接只传输一个请求报文和一个响应报文。 因此在本例中,当用户请求该Web页面时,要产生11 个TCP连接。
在上面描述的步骤中,并不明确客户获得这10个JPEG 图形对象是使用10个串行的TCP连接,还是使用了一些并行的TCP连接。 事实上,用户能够配置现代浏览器来控制连接的并行度。 在默认方式下,大部分浏览器打开5-10个并行的TCP连接,每条连接处理一个请求响应事务。如果用户愿意,最大并行连接数可以设置为1, 这样10条接就会串行建立。使用并行连接可以缩短响应时间。
我们来简单估算一下从客户请求HTML基本文件起到该客户收到整个文件止所花费的时间。 为此,我们给出往返时间 (Round-Trip Time, RTT) 的定义,该时间是指一个分组从客户到服务器然后再返回客户所花费的时间。 RTT包括分组传播时延、分组在中间路由器和交换机上的排队时延以及分组处理时延。 现在考虑当用户点击超链接时会发生什么现象。
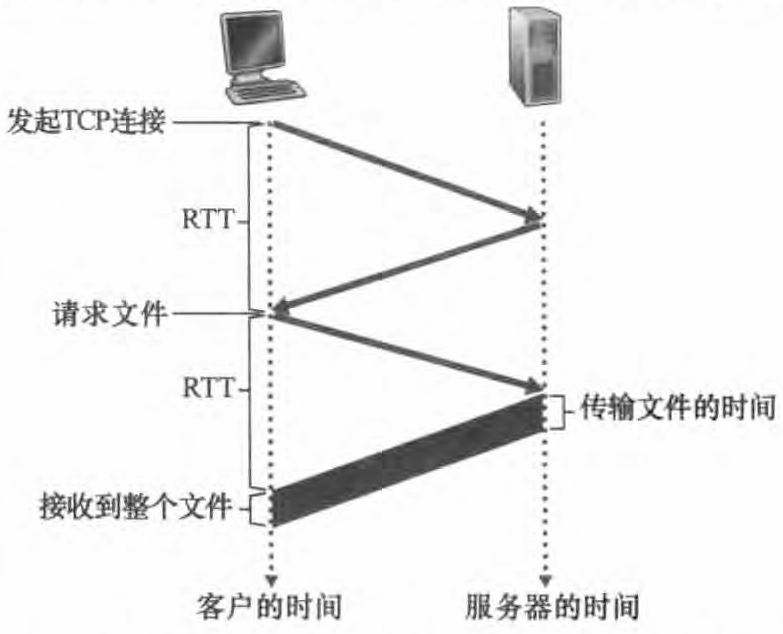
如图所示,浏览器在它和Web服务器之间发起一个TCP连接;这涉及一次"三次握手"过程,即客户向服务器发送一个小TCP报文段,服务器用一个小TCP报文段做出确认和响应,最后,客户向服务器返回确认。 三次握手中前两个部分所耗费的时间占用了一个RTT。 完成了三次握手的前两个部分后,客户结合三次握手的第三部分(确认)向该TCP连接发送一个 HTTP请求报文。 一旦该请求报文到达服务器,服务器就在该TCP连接上发送HTML文件。 该HTTP 请求/响应用去了另一个RTT。 因此,粗略地讲,总的响应时间就是两个RTT加上服务器传输 HTML文件的时间。在请求完基本HTML文件后,客户端继续重复以上过程请求剩余的10个JPEG 图形对象。假如获取HTML和10个JPEG 图形对象都是串行进行的话,总归需要花费22个RTT。
采用持续连接的 HTTP
非持续连接有一些缺点。 第一,必须为每一个请求的对象建立和维护一个全新的连接。 对于每个这样的连接,在客户和服务器中都要分配TCP 的缓冲区和保持TCP变量,这给Web服务器带来了严重的负担,因为一台 Web服务器可能同时服务数以百计不同的客户的请求。 第二,就像我们刚描述的那样,每一个对象经受两倍RTT 的交付时延,即一个RTT用于创建TCP, 另一个RTT用于请求和接收一个对象。
在采用持续连接的清况下,服务器在发送响应后保持该TCP连接打开。 在相同的客户与服务器之间,后续的请求和响应报文能够通过相同的连接进行传送。 特别是,一个完整的Web页面(上例中的 HTML基本文件加上 10 个图形,实际页面的对象数量会更多)可以用单个持续TCP 连接进行传送。 更有甚者,位于同一台服务器的多个Web页面在从该服务器发送给同一个客户时,可以在单个持续TCP连接上进行。 一般来说,如果一条连接经过一定时间间隔(可配置的超时间隔)仍未被使用, HTTP服务器就关闭该连接。 相比于上述的非持续连接,传输一个HTML基本文件加上 10 个图形,三次握手中前两个部分所耗费的时间占用了一个RTT。客户结合三次握手的第三部分(确认)向该TCP连接发送一个 HTTP请求报文。 该请求报文到达服务器,服务器就在该TCP连接上发送HTML文件。这个过程又花去了一个RTT。随后10个图形仍然可以使用该TCP连接进行传输,再需要10个RTT即可。从建立TCP连接到所有文件传输一共花去了12个RTT。
HTTP 报文格式
HTTP 规范包含了对HTTP 报文格式的定义。 HTTP报文有两种:请求报文和响应报文。
HTTP 请求报文
下面提供了一个典型的HTTP请求报文:
csharp
GET /somedir/page.html HTTP/1.1
Host: www.someschool.edu
Connection : close
User-agent: Mozilla/5. 0
Accept-language: fr该报文是用普通的ASCII 文本书写的,该报文由 5行组成,每行由一个回车和换行符结束。最后一行后再附加一个回车换行符。虽然这个特定的报文仅有5 行,但一个请求报文能够具有更多的行或者至少为一行。HTTP 请求报文的第一行叫作请求行,其后继的行叫作首部行(更常见的说法是请求头)。请求行有 3 个字段:方法字段(请求方法)、 URL字段和 HTTP版本字段。方法字段可以取几种不同的值,包括GET、 POST、 HEAD、 PUT 和 DELETE。当浏览器请求一个对象时,使用GET方法,在URL字段带有请求对象的标识。在本例中,该浏览器正在请求象/somedir/ page. html ,浏览器实现的是HTTP/1. 1 版本。
现在我们看看本例的首部行。 首部行Host: www. sorneschool. edu 指明了对象所在的主机。Connection: close 首部行,该浏览器告诉服务器不要麻烦地使用持续连接,它要求服务器在发送完被请求的对象后就关闭这条连接。 User-agent: 首部行用来指明用户代理即向服务器发送请求的浏览器的类型。 这里浏览器类型是Mozilla/5.0, 即 Firefox 浏览器。这个首部行是有用的,因为服务器可以有效地为不同类型的用户代理实际发送相同对象的不同版本。 (每个版本都由相同的URL寻址。)最后, Accept-language : 首部行表示用户想得到该对象的法语版本 (如果服务器中有这样的对象的话); 否则,服务器应当发送它的默认版本。
看过一个例子之后,再来看如图所示的一个请求报文的通用格式。
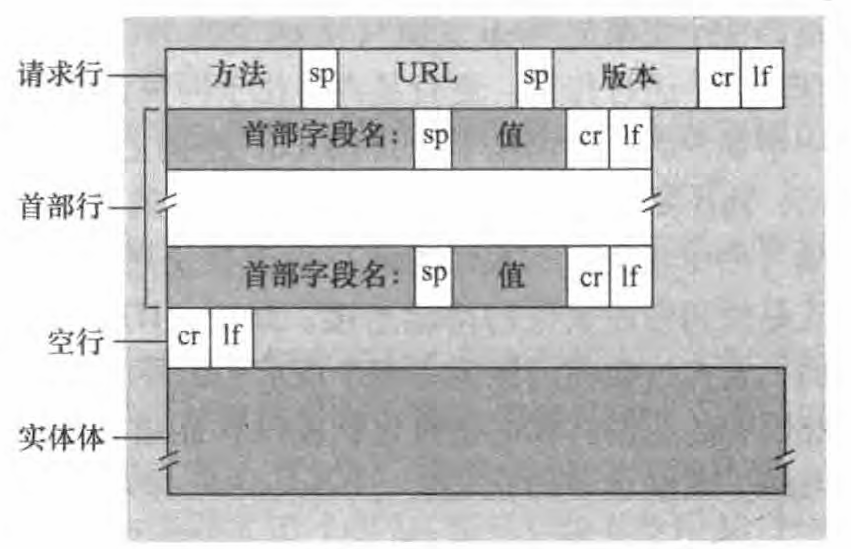
首部行(常称为请求头)之后还有一个空行,后面再跟有一个实体体(更多的称为请求体)。使用 GET 方法时实体体为空,使用 POST等方法时,会使用请求体,并在其中填入数据。例如,当用户向搜索引擎提供搜索关键词时,使用 POST 报文请求一个 Web 页面,服务器提供的Web 页面内容依赖于用户在表单字段中输入的内容。(方法字段的值为POST时,实体体中包含的就是用户在表单字段中的输入值。也就是在搜索框中输入的内容)。但用表单生成的请求报文不是必须使用 POST方法,HTML表单经常使用 GET方法,并在所请求的 URL 中包括输入的数据。例如, 一个表单使用 GET方法,它有两个字段,分别填写的是"monkeys'' 和"bananas" , 这样,该 URL 结构为 www. somesite. com/ animalsearch? monkeys&bananas。在日复一日的网上冲浪中,你也许已经留意到了这种扩展的 URL
HTTP 响应报文
csharp
HTTP/1.1 200 OK
Connection: close
Date: Tue, 18 Aug 2015 15:44 :04 GMT
Server: Apache/2.2.3 (CentOS)
Last-Modified: Tue, 18 Aug 2015 15:11:03 GMT
Content-Length: 6821
Content-Type : text/html
( data data data data data ...)响应报文有三个部分: 一个状态行 , 6个首部行(常称为响应头) , 然后是实体体(常称为响应体)。实体体部分是报文的主要部分,它包含了所请求的对象。状态行有 3 个字段: 协议版本字段、 状态码和相应状态信息。
Connection: close 首部行告诉客户,发送完报文后将关闭该TCP连接。
Date: 首部行指示服务器产生并发送该响应报文的日期和时间。这个时间不是指对象创建或者最后修改的时间,而是服务器从它的文件系统中检索到该对象,将该对象插入响应报文,并发送该响应报文的时间。
Server: 首部行指示该报文是由一台Apache Web 服务器产生的
Last-Modified: 首部行指示了对象创建或者最后修改的日期和时间。
Content-Length : 首部行指示了被发送对象中的字节数。
Content-Type : 首部行指示了实体体中的对象是HTML文本。

看过一个例子后,再来查看响应报文的通用格式。并补充说明一下常见的状态码和它们对应的信息。
- 200 OK: 请求成功,信息在返回的响应报文中。
- 301 Moved Permanently: 请求的对象已经被永久转移了,新的 URL 定义在响应报文的Location: 首部行中。 客户端将自动获取新的URL
- 400 Bad Request : 一个通用差错代码,指示该请求不能被服务器理解。
- 404 Not Found: 被请求的文档不在服务器上
- 505 HTTP Version Not Supported : 服务器不支持请求报文使用的 HTTP 协议版本。
用户与服务器的交互: cookie
可参考另外一篇关于cookie的博客,此处不再做介绍
Web 缓存
Web 缓存器也叫代理服务器,它是能够代表初始(源)Web 服务器来满足HTTP请求的网络实体。Web 缓存器有自己的磁盘存储空间,
并在存储空间中保存最近请求过的对象的副本。如图所示

可以配置用户的浏览器,使得用户的所有 HTTP请求首先指向 Web 缓存器。假设浏览器请求对象http://www. someschool. edu/campus. gif,将会发生如下情况:
- 浏览器创建一个到 Web 缓存器的 TCP连接,并向 Web缓存器发送一个HTTP请求,请求campus.gif对象。
- Web 缓存器进行检查,看看本地是否存储了该对象副本。 如果有, Web缓存器就向客户浏览器用 HTTP 响应报文返回该对象。
- 如果 Web 缓存器中没有该对象,它就打开一个与该对象的初始服务器(即www. someschool. edu) 的 TCP 连接。 在这个TCP 连接上发送一个对该对象的HTTP请求。 在收到该请求后,初始服务器向该Web缓存器发送具有该对象的HTTP 响应。
- 当 Web缓存器接收到该对象时,它在本地存储空间存储一份副本,并向客户的浏览器用HTTP 响应报文发送该副本(通过现有的客户浏览器和Web缓存器之间的TCP连接)。
值得注意的是,Web缓存器既是服务器又是客户。 当它接收浏览器的请求并发回响应时,它是一个服务器。 当它向初始服务器发出请求并接收响应时,它是一个客户。Web 缓存器通常由 ISP 购买并安装。 例如, 一所大学可能在它的校园网上安装一台缓存器,并且将所有校园网上的用户浏览器配置为指向它。
在因特网上部署Web缓存器有两个原因。 首先, Web缓存器可以大大减少对客户请求的响应时间,特别是当客户与初始服务器之间的瓶颈带宽远低于客户与Web缓存器之间的瓶颈带宽时。如果在客户与 Web缓存器之间有一个高速连接,并且如果用户所请求的对象在Web缓存器上,则 Web缓存器可以迅速将该对象交付给用户。其次,Web缓存器能够大大减少一个机构的接入链路到因特网的通信量。 通过减少通信量,该机构就不必急于增加带宽,因此降低了费用。
条件 GET 方法
尽管高速缓存能减少用户感受到的响应时间,但也引入了一个新的问题,即存放在缓存器中的对象副本可能是陈旧的。HTTP协议有一种机制,允许缓存器证实它的对象是最新的。 这种机制就是条件GET方法。先看一个例子,首先,一个缓存器代替一个客户浏览器向某Web服务器发送一个请求报文,随后,该Web服务器向缓存器发送具有被请求的对象的响应报文。
csharp
HTTP/1.1 200 OK
Date: Sat, 3 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix}
Last-Modified: Wed, 9 Sep 2015 09:23:24
Content-Type: image/gif
(data data data data data ... )该缓存器在将对象转发到请求的客户浏览器的同时,也在本地缓存了该对象。 重要的是,缓存器在存储该对象时也存储了最后修改日期。一个星期后,另一个用户经过该缓存器请求同一个对象,该对象仍在这个缓存器中。 由于在过去的一个星期中位于Web服务器上的该对象可能已经被修改了,该缓存器通过发送一个条件GET执行最新检查。该缓存器发送:
csharp
GET /fruit/kiwi.git HTTP/1.1
Host: www.exotiquecuisine.com
If-modified-since: Wed, 9 Sep 2015 09:23:24If-Modified-Since: 首部行的值正好等于一星期前服务器发送的响应报文中的 Last-Modified : 首部行的值。如果在该日期之后该对象被修改过,才发送该对象的新版本。如果没有修改则发送如下报文
csharp
HTTP/1.1 304 Not Modified
Date: Sat, 10 Oct 2015 15:39:29
Server: Apache/1.3.0 (Unix)
(empty entity body) 因特网中的电子邮件
与普通邮件一样,电子邮件是一种异步通信媒介,即当人们方便时就可以收发邮件,不必与他人的计划进行协调。 与普通邮件相比,电子邮件更为快速并且易于分发,而且价格便宜。 现代电子邮件具有许多强大的特性,包括具有附件、 超链接、 HTML格式文本和图片。

上图给出了因特网电子邮件系统的总体情况。它有 3个主要组成部分:用户代理 、 邮件服务器和简单邮件传输协议 (Simple Mail Transfer Protocol, SMTP) 。 用户代理允许用户阅读、回复、转发、 保存和撰写报文。 微软的 Outlook是电子邮件用户代理的例子。
邮件服务器形成了电子邮件体系结构的核心。 每个接收方在其中的某个邮件服务器上有一个邮箱,接收方的邮箱管理和维护着发送给他的报文。一个典型的邮件发送过程是:从发送方的用户代理开始,传输到发送方的邮件服务器,再传输到接收方的邮件服务器,然后在这里被分发到接收方的邮箱中。当接收方要在他的邮箱中读取该报文时,包含他邮箱的邮件服务器(使用用户名和口令)来对其进行鉴别。此外,发送方的邮箱也必须能处理接收方的邮件服务器的故障。如果发送方不能将邮件交付给接收方的服务器,
SMTP
SMTP 是因特网电子邮件中主要的应用层协议。它使用TCP可靠数据传输服务,从发送方的邮件服务器向接收方的邮件服务器发送邮件。SMTP 问世的时间很早,导致继承了某些陈旧的特征,例如,它限制所有邮件报文体只能采用简单的7 比特ASCII 表示,即在用 SMTP传送邮件之前, 需要将二进制多媒体数据编码为 ASCII码,并且在使用 SMTP 传输后要求将相应的ASCII 码邮件解码还原为多媒体数据。
为了描述SMTP 的基本操作,我们假设Alice 想给 Bob 发送一封简单的ASCII 报文。
- Alice 调用她的邮件代理程序并提供 Bob 的邮件地址(例如 bob@someschool. edu) , 撰写报文,然后指示用户代理发送该报文。
- Alice 的用户代理把报文发给她的邮件服务器,在那里该报文被放在报文队列中。
- 运行在 Alice 的邮件服务器上的 SMTP客户端发现了报文队列中的这个报文,它就 创建一个到Bob 邮箱所在的邮件服务器上的 SMTP服务器的TCP连接。
- 在经过一些初始SMTP握手后, SMTP客户端通过该TCP连接发送Alice 的报文。
5 ) Bob 邮箱所在的邮件服务器上, SMTP 的服务器端接收该报文。 Bob 的邮件服务器然后将 该报文放入Bob 的邮箱中。 - 在Bob 方便的时候,他调用用户代理阅读该报文。
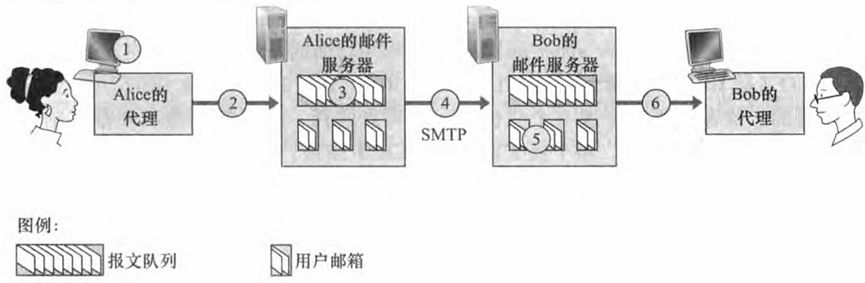
SMTP一般不使用中间邮件服务器发送邮件,即使这两个邮件服务器位于地球的两端也是这样。 假设Alice 的邮件服务器在中国香港,而Bob 的服 务器在美国圣路易斯,那么这个TCP连接也是从香港服务器到圣路易斯服务器之间的直接相连。如果Bob 的邮件服务器没有开机,该报文会保留在 Alice 的邮件服务器上 并等待进行新的尝试
现在讨论一下,SMTP是如何将一个报文从发送邮件服务器传送到接收 邮件服务器的。首先,客户 SMTP (运行在发送邮件服务器主机上)在25 号端口建立一个到服务器 SMTP (运行在接收邮件服务器主机上)的 TCP连接。 如果服务器没有开机,客户会 在稍后继续尝试连接。 一旦连接建立,服务器和客户执行某些应用层的握手,就像人 们在互相交流前先进行自我介绍一样。 SMTP 的客户和服务器在传输信息前先相互介绍。 在SMTP 握手的阶段, SMTP 客户表明发送方的邮件地址和接收方的邮件地址。 一旦该SMTP 客户和服务器彼此介绍之后,客户发送该报文。 SMTP 能依赖 TCP 提供的可靠数据传输无差错地将邮件投递到接收服务器。 该客户如 果有另外的报文要发送到该服务器,就在该相同的TCP连接上重复这种处理;否则, 它指示 TCP关闭连接。
与 HTTP 的对比
SMTP和 HTTP这两个协议都用于从一台主机向另一台主机传 送文件: HTTP从 Web 服务器向 Web 客户(通常是一个浏览器)传送文件(对象);SMTP从一个邮件服务器向另一个邮件服务器传送文件(即电子邮件报文)。进行文件传送时,HTTP和SMTP都使用持续连接。两者之间也有一些重要的区别。HTTP 主要是一个拉协议,用户使用HTTP从服务器拉取信息,TCP连接是由想接收文件的机器发起的。SMTP基本上是一个推协议, 即发送邮件服务器把文件推向接收邮件服务器,TCP 连接是由要发送该文件的机器发起的。
第二个区别就是SMTP要求每个报文(包括它们的体)采 用7 比特ASCII 码格式。如果某报文包含了非7 比特 ASCII 字符(如图形文件),必须按照7 比特ASCII码进行编码。HTTP数 据则不受这种限制。
邮件报文格式
From: alice@crepes.fr
To : bob@hamburger.edu
Subject: Searching for t he meaning of life.
Data data data data data data...
邮件报文由首部行和该报文的体组成,他们之间用空行(即回车换行) 进行分隔。如同 HTTP协议,每个首部行包含了可读的文本,是由关键词后跟冒号及其值组成的。 某些关键词是必需 的,另一些则是可选的。每个首部必须含有一个From: 首部行和一个To: 首部行;一个Subject: 首部行。在报文首部之后,紧接着一个空白行,然后是以ACSII格式表示的报文体。
邮件访问协议
一旦SMTP 将邮件报文从 Alice 的邮件服务器交付给 Bob 的邮件服务器,该报文就被 放入了 Bob 的邮箱中。今天,邮件访问使用客户-服务器体系结构,即典型的用户 通过在用户端系统上运行的客户程序来阅读电子邮件,这里的端系统可能是办公室的PC、 笔记本或者是智能手机。 通过在本地主机上运行邮件客户程序,用户享受一系列丰富的特 性,包括查看多媒体报文和附件的能力。
假设Bob(接收方)在其本地PC 上运行用户代理程序,考虑在他的本地PC 上也 放置一个邮件服务器是可以的。在这种情况下, Alice 的邮件服务器就能直接与 Bob 的 PC 进行对话了。然而这种方法会有一个问题,Bob 的邮件服务器位于他的PC上,那么为了能够及时接收可能在任何时候到达的新邮件,他的 PC必须总是不间断 地运行着并一直保持在线。这对于许多因特网用户而言是不现实的。相反,典型的用 户通常在本地PC 上运行一个用户代理程序,而它访问存储在总是保持开机的共享邮 件服务器上的邮箱。 该邮件服务器与其他用户共享,并且通常由用户的 ISP进行维护。
现在我们考虑当从Alice 向 Bob发送一个电子邮件报文时所取的路径。Alice 的用户代理用 SMTP 将电子邮件报文推入她的邮件服务器,接着她的 邮件服务器 (作为一个SMTP客户)再用SMTP将该邮件中继到 Bob 的邮件服务器。为什 么该过程要分成两步呢? 主要是因为不通过Alice 的邮件服务器进行中继, Alice 的用户代 理将没有任何办法到达一个不可达的目的地接收服务器。 通过首先将邮件存放在自己的邮 件服务器中, Alice 的邮件服务器可以重复地尝试向 Bob 的邮件服务器发送该报文, 如每 30 分钟一次,直到Bob 的邮件服务器变得运行为止。
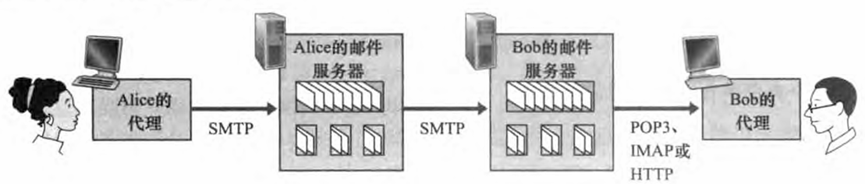
但是对于该过程仍然有一个疏漏的环节!像Bob这样的接收方,是如何通过运行其本 地PC 上的用户代理,获得位于他的某ISP 的邮件服务器上的邮件呢?值得注意的是Bob 的用户代理不能使用SMTP得到报文,因为取报文是一个拉操作,而SMTP协议是一个推 协议。通过引入一个特殊的邮件访问协议来解决这个难题,该协议将Bob 邮件服务器上的 报文传送给他的本地PC。 目前有一些流行的邮件访问协议,包括第三版的邮局协议 (Post Office Protocol ---Version 3, POP3 ) 、 因特网邮件访问协议 ( Internet Mail Access Protocol,IMAP) 以及 HTTP。
POP3
POP3 是一个极为简单的邮件访问协议,由 RFC 1939 进行定义。当用户代理(客户)打开了一个到邮件服务器(服务器)端口 110上的TCP连接后, POP3 就开始工作了。 随着建立TCP连接, POP3 按照三个阶段进行工作:授权 (authorization) 、事务处理以及更新。第一个阶段,用户代理发送(以明文形式)用户名和口令以鉴别用户。在第二个阶段即事务处理阶段,用户代理取回报文;同时在这个阶段用户代理还能进行如下操作,对报文做删除标记,取消报文删除标记,以及获取邮件的统计信息。 在第三个阶段即更新阶段, 它出现在客户发出了quit命令之后,目的是结束该POP3 会话;这时,该邮件服务器删除那些被标记为删除的报文。
授权有两个主要的命令: user < user name >和 pass < password > 。
在POP3 的事务处理过程中,用户代理发出一些命令,服务器对每个命令做出回答。回答可能有两种: +OK (有时后面还跟有服务器到客户的数据),被服务器用来指示前面的命令是正常的;- ERR, 被服务器用来指示前面的命令出现了某些差错。使用 POP3 的用户代理通常被用户配置为"下载并删除"或者"下载并保留"方式。用户代理发出 list、 retr和dele 命令 。举例来说,,假设用户在他(她)的邮箱里有两个报文。 在下面的对话中,C: (代表客户)是用户代理, S: (代表服务器)是邮件服务器。
csharp
C: list
S : 1 498
S : 2 912
s : .
C: retr 1
S : (blah blah . ..
s : ........... .. .. . .
S : ......... blah)
s : .
C: dele 1
C: retr 2
S : (blah blah ...
s : ........... .. .. . .
S: .......... blah)
s : .
C: dele 2
C: quit
S : +OK POP3 server signing off用户代理首先请求邮件服务器列出所有存储的报文的长度。 接着用户代理从邮件服务器取回并删除每封邮件。用户代理仅使用四个命令list、 retr、 dele 和 quit,分别用来列出所有存储的报文的长度、返回报文、删除报文、退出POP3连接。在处理 quit命令后, POP3 服务器进人更新阶段,从用户的邮箱中删除邮件1和2。
使用下载并删除方式存在的问题是,邮件接收方Bob可能是移动的,可能希望从多个不同的机器访问他的邮件报文,如从办公室的PC、家里的PC或他的便携机来访问邮件。使用下载并保留方式,用户代理下载某邮件后,该邮件仍保留在邮件服务器上。 这时, Bob就能通过不同的机器重新读取这些邮件;他能在工作时收取一封报文,而在工作回家后再次访问它。
IMAP
IMAP 是一个邮件访问协议,但是它比 POP3 具有更多的特色。IMAP 服务器把每个报文与一个文件夹联系起来;当报文第一次到达服务器时,它与收件人的收件箱文件夹相关联。 收件人则能够把邮件移到一个新的、用户创建的文件夹中,阅读邮件,删除邮件等。 IMAP协议为用户提供了创建文件夹以及将邮件从一个文件夹移动到另一个文件夹的命令。IMAP 的另一个重要特性是它具有允许用户代理获取报文某些部分的命令) 例如, 一个用户代理可以只读取一个报文的报文首部。
基于Web的电子邮件
今天越来越多的用户使用他们的 Web浏览器收发电子邮件。使用这种服务,用户代理就是普通的浏览器,用户和他远程邮箱之间的通信则通过 HTTP进行。 当一个收件人(如 Bob), 想从他的邮箱中访问一个报文时,该电子邮件报文从Bob的邮件服务器发送到他的浏览器,使用的是HTTP 而不是 POP3 或者 IMAP协议。 当发件人(如 Alice) 要发送一封电子邮件报文时,该电子邮件报文从Alice 的浏览器发送到她的邮件服务器,使用的是HTTP而不是SMTP, 然而, Alice的邮件服务器在与其他的邮件服务器之间发送和接收邮件时,仍然使用的是SMTP。
参考目录
书籍:《计算机网络:自顶向下方法(第七版)》
https://blog.csdn.net/weixin_48024605/article/details/132426862