标准 RAG 流水线有个根本性的毛病:检索到的文档一旦与用户意图对不上号,模型照样能面不改色地输出一堆看似合理的胡话,既没有反馈机制也谈不上什么纠错能力。
而Agentic RAG 的思路截然不同,它不急着从检索结果里硬挤答案,而是先判断一下拿回来的东西到底有没有用,如果没用则会重写查询再来一轮。这套机制实际上构建了一条具备自我修复能力的检索链路,面对边界情况也不至于直接崩掉。
本文要做的就是用 LangGraph 做流程编排、Redis 做向量存储,搭一个生产可用的 Agentic RAG 系统。涉及整体架构设计、决策逻辑实现,以及状态机的具体接线方式。
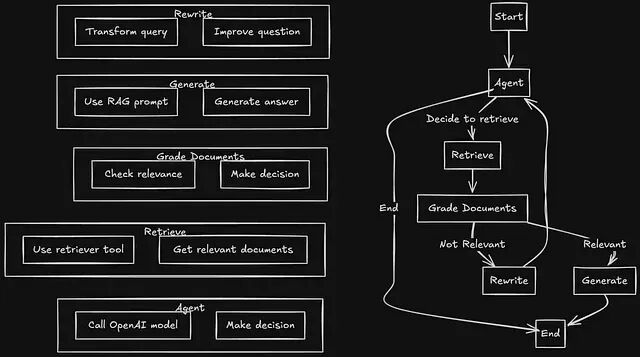
传统 RAG 的"一锤子买卖"
假设知识库里有一篇《大语言模型的参数高效训练方法》,用户问的是"怎么微调 LLM 效果最好"。
语义相似度确实存在但不够强。检索器拉回来的可能是模型架构相关的内容虽然沾边但答非所问,LLM 本身没法意识到上下文是错的,照样能生成一段貌似专业实则离题万里的回答。
传统 RAG 对这种失败模式完全没有办法。查询文档、生成答案,整个过程是单向的没有任何质量把关环节。
Agentic RAG 的解法是在流程中插入检查点:智能体先判断要不要检索;检索完了有评分环节确认相关性;不相关就重写查询再试;如此循环直到拿到合格的上下文,或者把重试次数耗尽为止。
系统架构拆解
整个系统拆成六个模块:
配置层负责环境变量和 API 客户端的初始化工作。Redis 连接串、OpenAI 密钥、模型名称全部归拢到这里统一管理。
检索器模块承担文档摄取的全套流程,文档经过
WebBaseLoader加载后用
RecursiveCharacterTextSplitter切块,再通过 OpenAI Embedding 向量化,最后存进
RedisVectorStore。检索器本身会被包装成 LangChain 工具供智能体调用。
智能体节点是决策入口。拿到用户问题后先做判断:这个问题需要查资料还是直接能答?需要查就调检索器,不需要就直出答案。
评分(Grade Edge)决定检索结果的去向。相关性够就往生成环节走;不够就触发重写。这是整个系统里最关键的质量关卡。
重写节点把原始问题改写成更适合检索的形式,用户表述太口语化、缺少关键词,这些问题都在这里修正。
生成节点只有在评分环节确认上下文合格后才会执行,基于检索到的文档产出最终答案。
流程图和代码
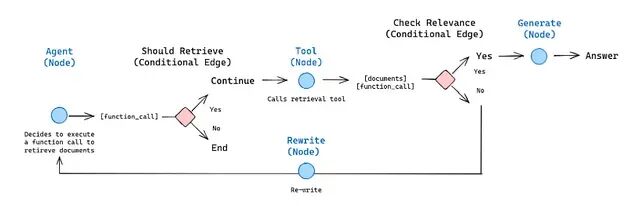
关键在于从"重写"回到"智能体"这条反馈路径。系统不会因为一次检索失败就直接给出一个牵强附会的答案,它会调整策略重新尝试。
src/
├── config/
│ ├── settings.py # 环境变量
│ └── openai.py # 模型名称和 API 客户端
├── retriever.py # 文档摄取和 Redis 向量存储
├── agents/
│ ├── nodes.py # 智能体、重写和生成函数
│ ├── edges.py # 文档评分逻辑
│ └── graph.py # LangGraph 状态机
└── main.py # 入口点职责划分很清晰:配置归
config/,智能体相关的都在
agents/,向量存储操作全在
retriever.py。这种结构调试起来方便,单测也好写。
配置模块设计
配置层解决两个问题:环境变量加载和 API 客户端复用。
settings.py集中读取 Redis 连接信息、OpenAI API Key、索引名称,不用满项目找配置。
openai.py负责实例化 Embedding 模型和 LLM 客户端。切换到别的模型、调整 Embedding 维度等等配置也只要一处
这个设计在生产环境里很实用,因为模型会迭代、Key 会轮换、服务商可能换掉,集中管理意味着改动成本可控。
检索器实现
检索器负责整条数据摄取链路:抓文档、切块、向量化、入库。
语料选的是 Lilian Weng 关于 Agent 和 Prompt Engineering 的博客文章。
WebBaseLoader负责抓取,
RecursiveCharacterTextSplitter切分成适当大小的块,OpenAI Embedding 完成向量化。
向量存储用
RedisVectorStore。检索器通过
create_retriever_tool封装成 LangChain 工具形态。这一步的意义在于让智能体能够"调用"检索而不是被动触发,意味着它有权决定什么时候需要查资料、什么时候直接回答。
为什么用Redis?因为够快,够简单。向量相似度搜索本身 Redis 就能做,不用额外引入专门的向量数据库。对于已经跑着 Redis 的技术栈来说,加 RAG 能力几乎零额外运维负担。
智能体节点
nodes.py里有三个核心函数。
智能体函数接收当前状态(用户问题、历史对话等),判断下一步怎么走。它能调用包括检索器在内的工具集。问题需要外部知识就调检索,不需要就直接生成回答。
重写函数处理那些被评分环节打回来的查询。它会让 LLM 把原始问题改写成检索友好的形式,用词更精准、关键信息更突出。改写后的查询再交回智能体重新发起检索。
生成函数产出最终答案。输入是原始问题加上已确认相关的文档,输出是基于这些上下文的回答。
三个函数都是无状态的。状态走图,不走函数内部变量。这对测试和排查问题都有好处。
文档评分逻辑
edges.py里的
grade_documents是整个 Agentic 机制的核心。
检索完成后它会逐个审视返回的文档:这东西跟用户问的相关不相关?能不能帮上忙?
评分本身是通过一次 LLM 调用完成的,Prompt 设计成要求模型返回二元判断------相关或者不相关。
判定相关就返回
"generate",流程走向答案生成;判定不相关则返回
"rewrite",触发查询改写。
这个环节的价值在于拦截那些本会导致标准 RAG 胡说八道的情况,与其硬着头皮从不靠谱的上下文里编答案,不如给系统一次修正查询的机会。
状态机接线
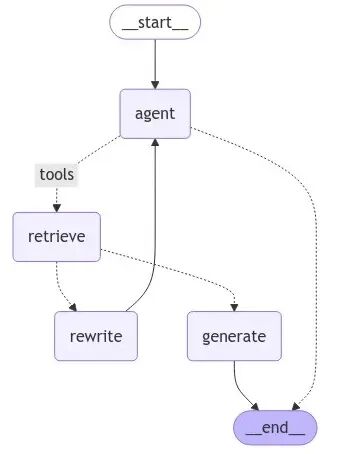
graph.py用 LangGraph 的状态机原语把所有节点串起来。
图结构定义了节点(智能体、检索、生成、重写)和边(节点间的连接关系,包括基于评分结果的条件路由)。
接线逻辑如下:查询先到智能体节点,智能体决定调检索器的话流程就到检索节点,检索完进评分,评分过了走生成,没过走重写,重写完的查询再回智能体重新来过。生成节点执行完流程结束。
LangGraph 接管状态流转的细节。每个节点只管接收当前状态、返回状态更新,具体消息怎么路由由图引擎根据边的条件逻辑处理。
运行时流程
main.py是入口,做三件事:构建图、接收问题、流式输出结果。
build_graph()在启动时执行一次,完成 LangGraph 状态机的构建和检索器工具的初始化.
问题进来之后的流转过程:智能体接收问题决定调检索 → Redis 返回文档 → 评分环节判断相关性 → 相关就生成答案,不相关就重写查询继续循环。
脚本会把各节点的输出实时打到控制台,方便观察决策过程------什么时候触发了检索、评分结果如何、有没有走到重写环节,一目了然。
架构的优势
自校正能力:检索质量差能发现并修复,不会闷头输出一个基于垃圾上下文的错误答案然后假装没事发生。
决策透明:状态机让每个分支点都是显式的。路由决策可以全量记录,想排查为什么系统选择了重写而不是直接生成,日志里全有。
模块解耦:每个组件职责单一。想把 Redis 换成 Pinecone?改检索模块。想把 OpenAI 换成 Anthropic?改配置层。其他部分不受影响。
总结
标准 RAG 把检索当黑盒,查询丢进去、文档出来,至于相不相关全凭运气。Agentic RAG 打开这个黑盒在关键位置加了质量控制。
LangGraph 加 Redis 的组合提供了一个可以直接上生产的骨架。流程编排的复杂度 LangGraph 消化掉了,向量检索的性能 Redis 兜住了,剩下的评分和重写逻辑负责兜底那些简单系统搞不定的边角案例。
代码:
https://avoid.overfit.cn/post/a45e19af576a4826a605807d8fcfe298
作者:Kushal Banda