文章目录
前言
对于刚接触机器学习聚类算法的小伙伴来说,K-Means(K 均值聚类) 是最经典的无监督学习算法之一。但很多新手都会遇到一个核心问题:怎么确定聚类的最优 K 值(簇的数量)?
本文用啤酒数据集作为实战案例,选择 K-Means 最优聚类数,代码全程可直接运行,有需要可自取。
一、环境准备
我们需要 3 个核心库,提前安装:
-
pandas:读取和处理数据
-
scikit-learn:实现 K-Means 聚类和轮廓系数计算
-
matplotlib:绘制评估曲线
c
pip install pandas scikit-learn matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple/二、数据集说明
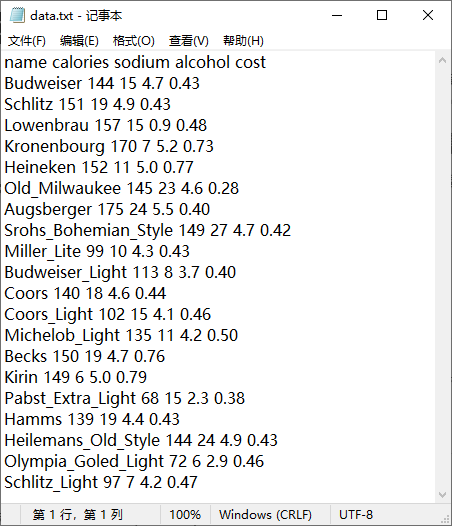
我们使用啤酒数据集(data.txt),数据格式是空格分隔,包含 4 个特征:
-
calories:热量
-
sodium:钠含量
-
alcohol:酒精度
-
cost:价格
数据文件data.txt需要和代码放在同一目录,直接用pandas读取即可。
数据集预览:
三、完整代码解析
完整代码如下:
c
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import metrics
beer = pd.read_table('data.txt', sep = ' ',encoding = 'utf-8',engine='python')
X = beer[['calories','sodium','alcohol','cost']]
scores = []
for k in range(2,10):
labels = KMeans(n_clusters=k).fit(X).labels_
score = metrics.silhouette_score(X,labels)
scores.append(score)
print(scores)
import matplotlib.pyplot as plt
plt.plot(list(range(2,10)),scores)
plt.xlabel("number of clusters initiailzed")
plt.ylabel('sihoustte score')
plt.show()
km = KMeans(n_clusters=2).fit(X)
beer['cluster'] = km.labels_
score = metrics.silhouette_score(X,beer.cluster)
print(score)解析
首先导入所有需要的工具库:
导入pandas库,简写为pd,专门用来读取、处理表格数据;
从sklearn.cluster模块中导入KMeans算法,这是我们的聚类模型;
再从sklearn中导入metrics评估模块,用来计算轮廓系数,评估聚类效果;
c
import pandas as pd
from sklearn.cluster import KMeans
from sklearn import metrics然后读取数据 + 提取聚类特征:
其中sep=' ':指定数据分隔符为空格 (数据里每列用空格分开),如果数据是被逗号分隔开的,用逗号替换空格就行。
从读取的beer数据中,提取4列作为聚类的特征数据
\['calories','sodium','alcohol','cost'] 双括号表示提取多列
再把提取好的特征数据赋值给 X,X是机器学习里固定的特征变量写法。
c
beer = pd.read_table('data.txt', sep = ' ',encoding = 'utf-8',engine='python')
X = beer[['calories','sodium','alcohol','cost']]遍历不同 K 值,计算轮廓系数
首先创建一个空列表 scores,用来存储每个K值对应的轮廓系数;
然后进行for循环遍历,k从2到9遍历循环;
之后创建KMeans模型,用特征数据X训练模型,同时获取训练后每条数据的聚类标签,赋值给labels;
计算轮廓系数,并添加到先前创建的空列表。
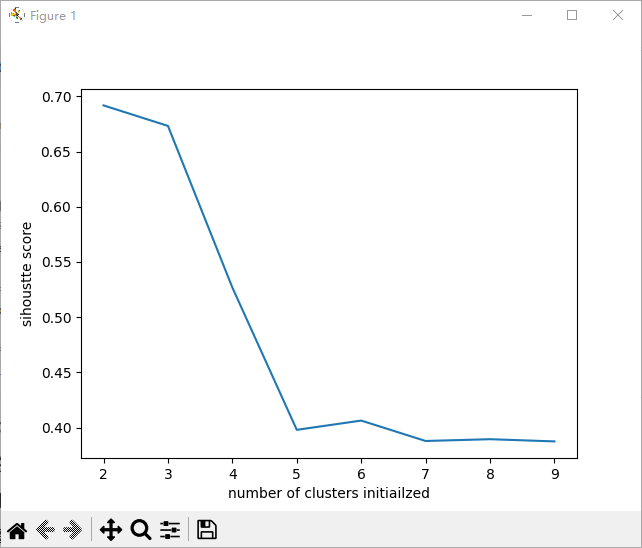
循环结束后,打印所有k值对应的轮廓系数结果,轮廓系数范围-1,1,数值越大,聚类效果越好。
c
scores = []
for k in range(2,10):
labels = KMeans(n_clusters=k).fit(X).labels_
score = metrics.silhouette_score(X,labels)
scores.append(score)
print(scores)导入matplotlib.pyplot库,简写为plt,用来绘制折线图可视化结果
X轴数据为k值:range(2,10)
Y轴数据为对应k值的轮廓系数scores。
附上标题,并显示折线图
c
import matplotlib.pyplot as plt
plt.plot(list(range(2,10)),scores)
plt.xlabel("number of clusters initiailzed")
plt.ylabel('sihoustte score')
plt.show()根据折线图结果,得到最优k值为2,创建并训练KMeans模型,n_clusters=2:指定分成2类;
把聚类结果(0/1标签)添加到原始beer数据中,新增一列名为 cluster 的列,存储每条数据的类别;
最后计算最终聚类(k=2)的轮廓系数,验证效果并打印分数。
c
km = KMeans(n_clusters=2).fit(X)
beer['cluster'] = km.labels_
score = metrics.silhouette_score(X,beer.cluster)
print(score)运行结果:
c
[0.6917656034079486, 0.6731775046455796, 0.5267665961530135, 0.39795307968774635, 0.4063314658707994, 0.3878463360806727, 0.38946337473125997, 0.3874759334160638]运行折线图:
总结
K-means 聚类广泛应用于市场细分、图像分割、文档聚类等领域。例如,在市场营销中,可以将客户划分为不同的群体,以便进行更针对性的推广策略;在图像处理中,可以将图像分割成多个区域,以便进一步分析或压缩。但同时也拥有自己的优缺点。
优点:
- 简单易实现。
- 对大数据集具有较好的可扩展性。
- 当簇的密度大致相同且簇间分离良好时,效果非常好。
缺点:
- 需要预先指定 K 值,而 K 的选择通常不直观。
- 结果可能受到初始质心选择的影响,可能导致局部最优解。
- 对异常值(噪声)和簇的形状(非球形)敏感。