作者:卢建晖 - 微软高级云技术布道师
排版:Alan Wang
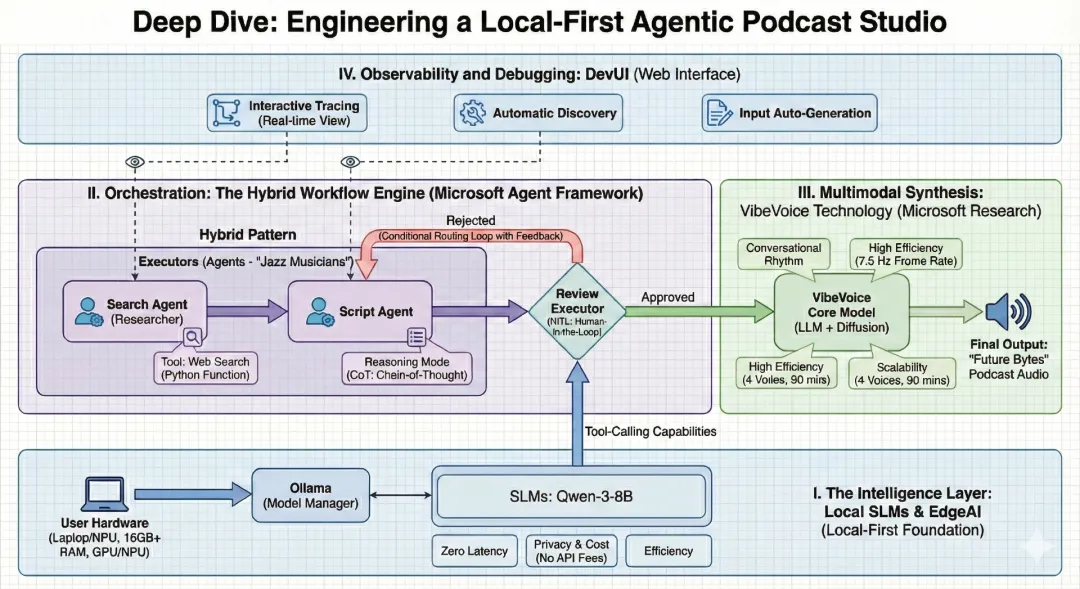
从独立的大语言模型(LLM)向智能体编排的转变,标志着 AI 发展的下一个前沿。我们正在从简单的"提示---响应"交互模式,迈向一种全新的范式:由具备专长、可自主运行的单元------AI 智能体------协同合作,来解决复杂的、多步骤问题。作为一名技术布道师,我的关注重点在于完全基于边缘端构建这些可用于生产环境的系统,从而在隐私保护、响应速度和成本效率之间取得最佳平衡。
本技术指南将深入探讨 AI Podcast Studio 的架构与实现方式。该项目展示了 Microsoft Agent Framework 、本地小语言模型(SLM)以及 VibeVoice 的无缝集成,自动化完成一条端到端的技术播客生产线。
战略智能层:为什么选择本地优先?
我们工作室的核心理念是本地优先(Local-First)。尽管基于云端的大语言模型能力强大,但在高频、强创意需求的生产流水线中,它们往往会带来额外的摩擦与成本。通过使用 Ollama 作为模型管理器,我们能够将 Qwen-3-8B 等小语言模型直接运行在用户本地硬件之上。
架构对比:本地部署 vs. 云端部署
选择部署环境是一项基础性的架构决策。对于一个智能体化的播客工作流而言,边缘端(本地)具备显著优势:
| 维度 | 本地模型(如 Qwen-3-8B) | 云端模型(如 GPT-5.2) |
|---|---|---|
| 延迟 | 零 / 极低:无需网络传输,Token 即时生成,无网络"波动"。 | 不稳定:依赖网络状况及 API 流量负载。 |
| 隐私 | 完全自主:创作数据与草稿始终保留在本地设备。 | 共享风险:数据需在第三方服务器上处理。 |
| 成本 | 零 API 费用:一次性硬件投入,可无限生成 Token。 | 按量付费:成本随 Token 数量和调用频率线性增长。 |
| 可用性 | 离线可用:即使没有互联网连接,工作室仍可正常运行。 | 仅限在线:依赖稳定且高速的网络连接。 |
边缘端的推理与工具调用
为了超越简单的对话式交互,我们引入了推理模式 ,并采用思维链(Chain-of-Thought,CoT)提示。这使得本地智能体在正式撰写内容之前,能够先对播客的整体结构进行"思考"和规划。此外,我们通过工具调用赋予智能体"超能力",使其能够执行 Python 函数,进行实时的网络搜索,从而获取最新的新闻与信息。
编排引擎:Microsoft Agent Framework
本项目真正的复杂性在于智能体编排------即协调多个具备不同专长的智能体,使其像一个高效协作的团队一样运作。我们明确区分两类核心概念:
-
Agent :如同"爵士乐手",能够根据上下文灵活决策、即兴发挥。
-
Workflow :如同"交响乐团",按照预先定义好的乐谱有序执行。
高级编排模式
借鉴 WorkshopForAgentic 的架构设计,播客工作室采用了多种成熟而复杂的编排模式:
-
顺序执行:严格的流水线模式,例如由 Researcher 的输出直接传递给 Scriptwriter。
-
并发执行:多个智能体同时检索不同的新闻来源,加速信息收集过程。
-
任务交接:智能体可根据任务上下文,动态将控制权"移交"给更合适的专业智能体。
-
Magentic-One:由一个高层级的"管理者"智能体实时决策,判断下一步应由哪位专家接手任务。
实现方式:代码分析(Workshop 模式)
为了保持生产级别的代码质量,我们遵循 WorkshopForAgentic/code 目录中采用的模块化结构设计。这种方式确保了智能体、客户端与工作流之间的解耦,提升了系统的可维护性与可扩展性。
配置:连接本地 SLM
第一步是通过框架对 Ollama 的集成,初始化本地小模型的客户端。
bash
# Based on WorkshopForAgentic/code/config.py
from agent_framework.ollama import OllamaChatClient
# Initialize the local client for Qwen-3-8B
# Standard Ollama endpoint on localhost
chat_client = OllamaChatClient(
model_id="qwen3:8b",
endpoint="http://localhost:11434"
)智能体定义:专属角色分工
每个智能体都是一个 ChatAgent 实例,通过其角色设定与指令来进行定义。
bash
# Based on WorkshopForAgentic/code/agents.py
from agent_framework import ChatAgent
# The Researcher Agent: Responsible for web discovery
researcher_agent = client.create_agent(
name="SearchAgent",
instructions="You are my assistant. Answer the questions based on the search engine.",
tools=[web_search],
)
# The Scriptwriter Agent: Responsible for conversational narrative
generate_script_agent = client.create_agent(
name="GenerateScriptAgent",
instructions="""
You are my podcast script generation assistant. Please generate a 10-minute Chinese podcast script based on the provided content.
The podcast script should be co-hosted by Lucy (the host) and Ken (the expert). The script content should be generated based on the input, and the final output format should be as follows:
Speaker 1: ......
Speaker 2: ......
Speaker 1: ......
Speaker 2: ......
Speaker 1: ......
Speaker 2: ......
"""
)工作流配置:顺序流水线
为了构建一条确定性的生产线,我们使用 WorkflowBuilder 将各个智能体连接起来。
bash
# Based on WorkshopForAgentic/code/workflow_setup.py
from agent_framework import WorkflowBuilder
# Building the podcast pipeline
search_executor = AgentExecutor(agent=search_agent, id="search_executor")
gen_script_executor = AgentExecutor(agent=gen_script_agent, id="gen_script_executor")
review_executor = ReviewExecutor(id="review_executor", genscript_agent_id="gen_script_executor")
# Build workflow with approval loop
# search_executor -> gen_script_executor -> review_executor
# If not approved, review_executor -> gen_script_executor (loop back)
workflow = (
WorkflowBuilder()
.set_start_executor(search_executor)
.add_edge(search_executor, gen_script_executor)
.add_edge(gen_script_executor, review_executor)
.add_edge(review_executor, gen_script_executor) # Loop back for regeneration
.build()
)多模态合成:VibeVoice 技术
"Future Bytes" 播客通过 VibeVoice 技术得以生动呈现。VibeVoice 是 Microsoft Research 推出的一项专用技术,旨在实现自然、流畅的对话式语音合成。
-
对话节奏:自动处理自然的轮流发言与语音韵律。
-
高效率 :以极低的 7.5 Hz 帧率 运行,在保证高保真音频质量的同时,大幅降低计算资源消耗。
-
可扩展性 :支持最多 4 种不同声音 ,并可生成长达 90 分钟的连续音频内容。
可观测性与调试:DevUI
构建多智能体系统需要对智能体"思考"过程具备高度可见性。为此,我们引入 DevUI ------ 一个用于测试与追踪的专用 Web 界面:
-
交互式追踪:开发者可实时观察消息流转及工具调用过程。
-
自动发现:DevUI 会自动识别并加载项目结构中定义的智能体。
-
输入自动生成:根据工作流需求自动生成输入表单,支持快速迭代与调试。
边缘端部署的技术要求
将该播客工作室部署在本地,需要相应的软硬件配置,以支撑 LLM 与 TTS 的并行推理:
-
软件环境:Python 3.10 及以上版本、Ollama、Microsoft Agent Framework。
-
硬件配置:最低 16GB 内存;若需同时运行多个智能体与 VibeVoice,建议 32GB 内存。
-
计算能力:需要现代化的 GPU / NPU(如 NVIDIA RTX 或 Snapdragon X Elite),以确保推理过程流畅稳定。
最终视角:从编码走向导演式创作
AI Podcast Studio 代表了向智能体内容创作的重要转变。通过掌握这些编排模式并充分利用本地 EdgeAI,开发者可以从单纯的编写代码,进阶到指导整个智能体生态系统的运行。这种 "本地优先" 模式保证了未来创作的隐私性、高效性和无限可扩展性。