Abstract
在本文中,我们提出了一种新颖的元学习(Meta Learning)方法,用于极深神经网络的自动通道剪枝 。我们首先训练一个 PruningNet(一种元网络),它能够为给定的目标网络生成任意剪枝结构的权重参数 。我们使用一种简单的随机结构采样方法来训练 PruningNet 。然后,我们应用进化过程来搜索性能良好的剪枝网络 。由于权重是由训练好的 PruningNet 直接生成的,且我们在搜索时不需要任何微调,因此搜索非常高效 。利用针对目标网络训练的单个 PruningNet,我们可以在极少人工参与的情况下,搜索满足不同约束条件的各种剪枝网络 。与最先进的剪枝方法相比,我们在 MobileNet V1/V2 和 ResNet 上展示了卓越的性能 。代码可在 https://github.com/liuzechun/MetaPruning 获取 。
1. Introduction
通道剪枝已被公认为一种有效的神经网络压缩/加速方法 32, 22, 2, 3, 21, 52,并在工业界广泛使用 。一个典型的剪枝方法包含三个阶段:训练一个大型的过参数化网络,修剪不重要的权重或通道,微调或重新训练剪枝后的网络 。第二阶段是关键,它通常执行迭代式的逐层剪枝和快速微调或权重重构以保持准确性 17, 1, 33, 41 。传统的通道剪枝方法主要依赖于数据驱动的稀疏性约束 28, 35 或人工设计的策略 22, 32, 40, 25, 38, 2 。最近的 AutoML 风格的工作基于反馈循环 52 或强化学习 21,以迭代模式自动修剪通道 。与传统剪枝方法相比,AutoML 方法节省了人力,并且可以优化诸如硬件延迟之类的直接指标 。
除了在剪枝网络中保留重要权重的想法之外,最近的一项研究 36 发现,无论剪枝网络是否继承原始网络中的权重,它都能达到相同的精度 。这一发现表明,通道剪枝的本质是寻找良好的剪枝结构------即逐层的通道数量 。然而,穷举寻找最佳剪枝结构在计算上是不可行的 。考虑一个具有 10 层且每层包含 32 个通道的网络 ,其逐层通道数量的可能组合可能是 3210 。受最近的神经架构搜索(NAS),特别是 One-Shot 模型 5 以及 HyperNetwork 15 中的权重预测机制的启发,我们建议训练一个 PruningNet,它可以为所有候选剪枝网络结构生成权重,这样我们就只需通过在验证数据上评估其精度来搜索表现良好的结构,这非常高效 。
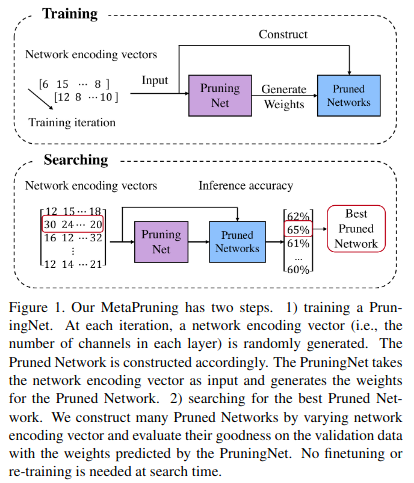
为了训练 PruningNet,我们使用了随机结构采样 。如图 1 所示,PruningNet 根据相应的网络编码向量(即每层中的通道数)为剪枝网络生成权重 。通过随机输入不同的网络编码向量,PruningNet 逐渐学会为各种剪枝结构生成权重 。训练结束后,我们通过进化搜索方法来搜索表现良好的剪枝网络,该方法可以灵活地纳入各种约束,如计算 FLOPs 或硬件延迟 。此外,通过确定每层或每个阶段的通道来直接搜索最佳剪枝网络,我们可以毫不费力地修剪 shortcut(捷径连接)中的通道,这在以前的通道剪枝解决方案中很少涉及 。我们将提出的方法命名为 MetaPruning 。
我们将我们的方法应用于 MobileNets 24, 46 和 ResNet 19 。在相同的 FLOPs 下,我们的准确率比 MobileNet V1 高 2.2%-6.6%,比 MobileNet V2 高 0.7%-3.7%,比 ResNet-50 高 0.6%-1.4% 。在相同的延迟下,我们的准确率比 MobileNet V1 高 2.1%-9.0%,比 MobileNet V2 高 1.2%-9.9% 。与最先进的通道剪枝方法 21, 52 相比,我们的 MetaPruning 也产生了优越的结果 。
我们的贡献主要体现在四个方面 :
我们提出了一种用于通道剪枝的元学习方法 MetaPruning 。该方法的核心是学习一个元网络(称为 PruningNet),它为各种剪枝结构生成权重 。使用单个训练好的 PruningNet,我们可以在不同约束下搜索各种剪枝网络 。
与传统剪枝方法相比,MetaPruning 将人类从繁琐的超参数调整中解放出来,并能够直接优化所需指标 。
与其他 AutoML 方法相比,MetaPruning 可以轻松地在所需结构的搜索中强制执行约束,而无需手动调整强化学习超参数 。
元学习能够毫不费力地修剪 ResNet 类结构中 short-cut 的通道,这并非易事,因为 short-cut 中的通道会影响多个层 。
2.Related Works
关于压缩和加速神经网络的研究非常广泛,例如量化(Quantization)、剪枝(Pruning)和紧凑网络设计(Compact Network Design)。文献 47 提供了一份全面的综述 。在这里,我们总结与我们工作最相关的方法。
剪枝 (Pruning) 网络剪枝是去除深度神经网络(DNN)冗余的流行方法 。权重剪枝 (Weight Pruning): 人们修剪单个权重以压缩模型大小 。然而,权重剪枝会导致非结构化的稀疏滤波器,这很难被通用硬件加速 。通道剪枝 (Channel Pruning): 最近的工作 专注于卷积神经网络(CNN)中的通道剪枝,它移除整个权重滤波器而不是单个权重。传统的通道剪枝方法基于每个通道的重要性进行修剪,要么采用迭代模式 ,要么添加数据驱动的稀疏性约束 。在大多数传统通道剪枝中,每一层的压缩比需要基于人类专家或启发式规则手动设置,这既耗时又容易陷入次优解 。
AutoML (自动化机器学习) 最近,AutoML 方法 将多设备上的实时推理延迟考虑在内,通过强化学习 或自动反馈循环 迭代地修剪网络中不同层的通道。与传统通道剪枝方法相比,AutoML 方法有助于减少调整通道剪枝超参数的人工努力 。我们提出的 MetaPruning 同样涉及极少的人工参与 。与之前的 AutoML 剪枝方法(在"逐层剪枝"和"微调"的循环中执行)不同,我们的方法受到最近发现 36 的启发,该发现表明:与其选择"重要"的权重,通道剪枝的本质有时在于识别最佳的剪枝网络结构 。从这个角度来看,我们提出 MetaPruning 直接寻找最佳的剪枝网络结构 。与之前的 AutoML 剪枝方法 21, 52 相比,MetaPruning 在精确满足约束方面享有更高的灵活性,并拥有修剪捷径连接(short-cut)中通道的能力 。
元学习 (Meta Learning) 元学习是指通过观察不同机器学习方法在各种学习任务上的表现来进行学习 。元学习可用于少样本/零样本学习(Few/Zero-shot learning)和迁移学习(Transfer learning)。文献 31 提供了元学习的全面综述 。在这项工作中,我们受 15 启发,使用元学习进行权重预测 。权重预测是指神经网络的权重是由另一个神经网络预测的,而不是直接学习得到的 。最近的工作也将元学习应用于各种任务,并在检测 51、任意倍率超分辨率 27 和实例分割 26 方面取得了最先进的结果 。
神经架构搜索 (Neural Architecture Search - NAS) 神经架构搜索的研究试图通过强化学习 、遗传算法 或基于梯度的方法 找到最佳的网络结构和超参数。参数共享(Parameter sharing)和权重预测(Weights prediction) 方法也在 NAS 中被广泛研究。One-shot 架构搜索 5 使用一个每一层都有多种操作选择的过参数化网络。通过联合训练多种选择与 drop-path,它可以在训练好的网络中搜索准确率最高的路径,这也启发了我们的两步剪枝流程 。调整通道宽度(Channel width)也包含在一些神经架构搜索方法中 。ChamNet 9 在贝叶斯优化的高斯过程之上构建了一个精度预测器,以预测具有各种通道宽度、扩展比和每个阶段块数的网络精度。尽管精度高,但构建这样的精度预测器需要大量的计算能力 。FBNet 49 和 ProxylessNas 7 在搜索空间中包含了具有几种不同中间通道选择的模块 与神经架构搜索不同,在通道剪枝任务中,每一层的通道宽度选择是连续的(consecutive),这使得枚举每一个通道宽度的选择作为独立操作变得不可行 。提出的针对通道剪枝的 MetaPruning 能够通过训练带有权重预测的 PruningNet 来解决这个连续通道剪枝的挑战,这将在第 3 节中解释 。
3. Methodology

3.1.PruningNet Training
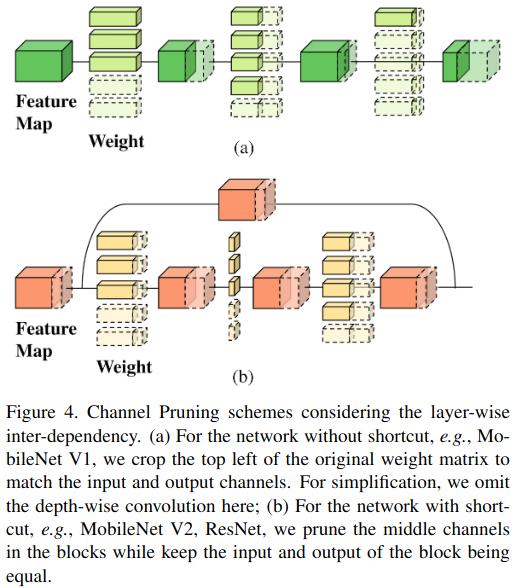
通道剪枝并非易事,因为通道存在层间依赖性,修剪一个通道可能会显著影响后续层,反过来降低整体精度 。之前的方法试图将通道剪枝问题分解为逐层修剪不重要通道的子问题 22 或添加稀疏正则化 28 。AutoML 方法通过反馈循环 52 或强化学习 21 自动修剪通道 。在这些方法中,如何修剪 shortcut(捷径连接)中的通道很少被提及 。大多数以前的方法仅修剪每个块(block)中间的通道 52, 21,这限制了整体压缩率 。
在考虑整体剪枝网络结构的情况下执行通道剪枝任务,有利于找到通道剪枝的最优解,并能解决 shortcut 剪枝问题 。然而,获得最佳剪枝网络并非易事,考虑到一个只有 10 层且每层包含 32 个通道的小型网络,可能的剪枝网络结构组合也是巨大的 。
受最近工作 36 的启发(该工作表明,与剪枝网络结构相比,剪枝后留下的权重并不重要),我们有动力直接寻找最佳的剪枝网络结构 。从这个意义上说,我们可以直接预测最佳剪枝网络,而无需迭代地决定重要的权重滤波器 。为了实现这一目标,我们构建了一个元网络 PruningNet,用于为各种剪枝网络结构提供合理的权重,以便对它们的性能进行排序 。
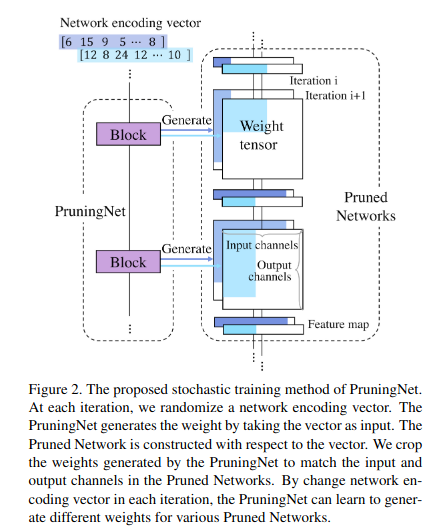

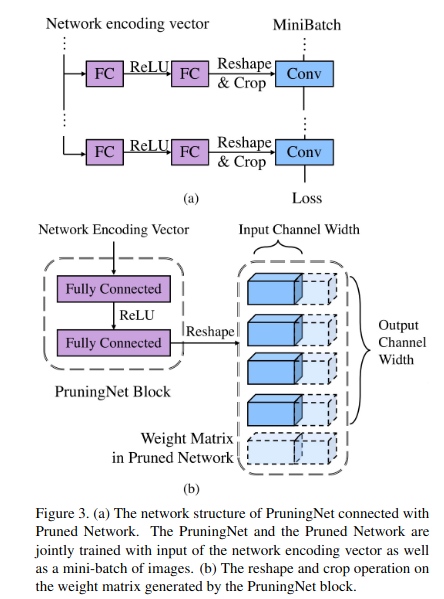
3.2. Pruned-Network search
PruningNet 训练完成后,我们可以通过将网络编码输入 PruningNet,生成相应的权重并在验证数据上进行评估,从而获得每个潜在剪枝网络的准确率 。由于网络编码向量的数量巨大,我们无法进行枚举 。为了找出在约束条件下具有高精度的剪枝网络,我们使用了进化搜索(evolutionary search),它能够轻松地纳入任何软约束或硬约束 。
在 MetaPruning 使用的进化算法中,每个剪枝网络都编码为一个包含每层通道数的向量,称为剪枝网络的基因(genes)。在硬约束下,我们首先随机选择一定数量的基因,并通过评估获得相应剪枝网络的准确率 。然后,选择准确率最高的前 k 个基因,通过变异(mutation)和交叉(crossover)生成新的基因 。变异是通过随机改变基因中一定比例的元素来进行的 。交叉是指我们随机重组两个父代基因中的基因以生成后代 。我们可以通过剔除不合格的基因来轻松强制执行约束 。通过进一步重复前 k 选择过程和新基因生成过程若干次迭代,我们可以获得在满足约束的同时达到最高准确率的基因 。详细算法在算法 1 中描述 。
4. Experimental Results
在本节中,我们展示了我们提出的 MetaPruning 方法的有效性 。我们首先解释实验设置,并介绍如何将 MetaPruning 应用于 MobileNet V1 24、V2 46 和 ResNet 19,这也可以轻松推广到其他网络结构 。其次,我们将我们的结果与均匀剪枝基线以及最先进的通道剪枝方法进行比较 。第三,我们将通过 MetaPruning 获得的剪枝网络进行可视化 。最后,我们进行消融研究,以详细说明权重预测在我们方法中的作用 。
4.1. Experiment settings
提出的 MetaPruning 非常高效。因此,在 ImageNet 2012 分类数据集 10 上进行所有实验是可行的 。MetaPruning 方法包含两个阶段。在第一阶段,使用随机结构采样从头开始训练 PruningNet,这只需花费正常训练一个网络 1/4 的 epoch 。进一步延长 PruningNet 的训练对最终获得的剪枝网络的精度增益微乎其微 。
在第二阶段,我们使用进化搜索算法来寻找最佳的剪枝网络 。由于 PruningNet 可以预测所有剪枝网络的权重,因此在搜索时无需进行微调或重新训练,这使得进化搜索非常高效 。推断一个剪枝网络在 8 个 Nvidia 1080Ti GPU 上仅需几秒钟 。
搜索获得的最佳剪枝网络随后会从头开始训练 。对于两个阶段的训练过程,我们使用与 19 相同的标准数据增强策略来处理输入图像 。对于 MobileNets 的实验,我们采用与 39 相同的训练方案;对于 ResNet,我们采用 19 中的训练方案 。所有实验的输入图像分辨率均设置为 224×224 。
在训练时,我们将原始训练图像划分为子验证数据集(sub-validation dataset)和子训练数据集(sub-training dataset)。子验证数据集包含从训练图像中随机选取的 50000 张图像(每个类别 50 张),子训练数据集包含其余图像 。在搜索阶段,我们在子训练数据集上训练 PruningNet,并在子验证数据集上评估剪枝网络的性能 。在搜索时,我们使用 20000 张子训练图像重新计算 BatchNorm 层中的运行均值(running mean)和运行方差(running variance),以正确推断剪枝网络的性能,这仅需几秒钟 。获得最佳剪枝网络后,该剪枝网络将在原始训练数据集上从头开始训练,并在测试数据集上进行评估 。
4.2.Meta Pruning on MobileNets and ResNet
为了证明我们 MetaPruning 方法的有效性,我们将其应用于 MobileNets 24, 46 和 ResNet 19 。
4.2.1 MobileNet V1

4.2.2 MobileNet V2

4.2.3 ResNet
作为一个带有 shortcut 的网络,ResNet 具有与 MobileNet V2 相似的网络结构,仅在中间层的卷积类型、下采样块和每个阶段的块数上有所不同 。因此,我们对 ResNet 采用与 MobileNet V2 相似的 PruningNet 设计 。
4.3.Comparisons with state-of-the-arts
我们将我们的方法与均匀剪枝基线、传统剪枝方法以及最先进的通道剪枝方法进行比较 。
4.3.1Pruning under FLOPs constraint
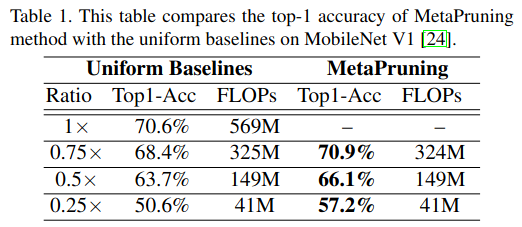
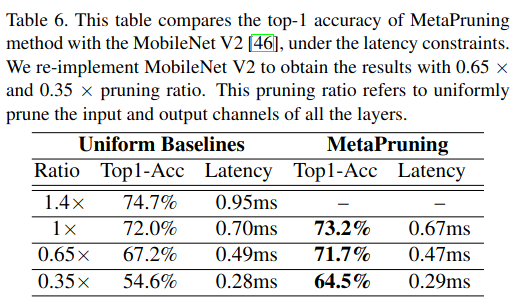
表 1 比较了我们的精度与 24 中报告的均匀剪枝基线 。利用 MetaPruning 学习到的剪枝方案,我们的精度比基线 0.25x MobileNet V1 高出 6.6% 。此外,由于我们的方法可以推广到修剪网络中的 shortcut,我们在 MobileNet V2 上也取得了不错的改进,如表 2 所示。以前的剪枝方法仅修剪 bottleneck 结构的中间通道 52, 21,这限制了其在给定输入分辨率下的最大压缩比 。使用 MetaPruning,当模型大小小至 43M FLOPs 时,我们可以获得 3.7% 的精度提升 。
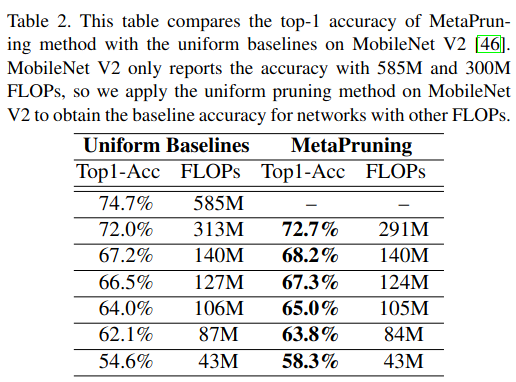
对于像 ResNet 这样的重型模型,MetaPruning 也大幅优于均匀基线和其他传统剪枝方法,如表 3 所示 。
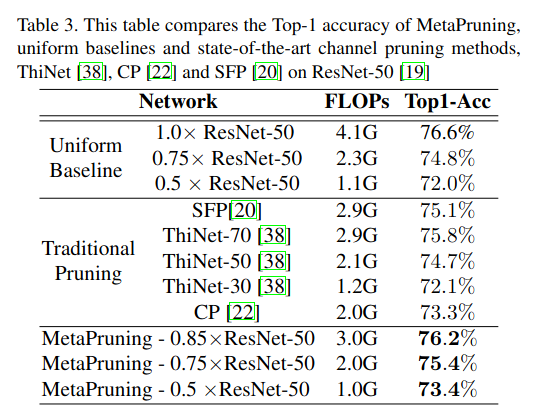
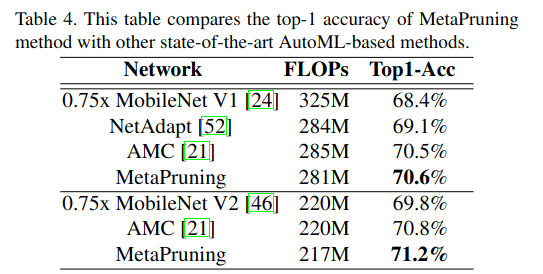
在表 4 中,我们将 MetaPruning 与最先进的 AutoML 剪枝方法进行了比较 。MetaPruning 取得了比 AMC 21 和 NetAdapt 52 更优异的结果 。此外,MetaPruning 摆脱了手动调整强化学习超参数的麻烦,并且可以获得精确满足 FLOPs 约束的剪枝网络 。仅使用正常训练目标网络四分之一的 epoch 训练一次 PruningNet,我们就可以获得多个剪枝网络结构以达成不同的精度-速度权衡,这比最先进的 AutoML 剪枝方法 21, 52 更高效 。时间成本在 4.1 节中报告 。
4.3.2 Pruning under latency constraint
人们越来越关注直接优化目标设备上的延迟 。在不知道设备内部实现细节的情况下,MetaPruning 学习根据从设备估计的延迟来修剪通道 。
由于潜在的剪枝网络数量众多,测量每个网络的延迟太耗时 。基于每一层的执行时间是独立的这一合理假设,我们可以通过将网络中所有层的运行时间相加来获得网络延迟 。遵循 49, 52 中的做法,我们首先构建一个查找表,通过在目标设备(在我们的实验中是 Titan Xp GPU)上估计具有不同输入和输出通道宽度的不同卷积层的延迟来实现 。然后我们可以从查找表中计算构建网络的延迟 。
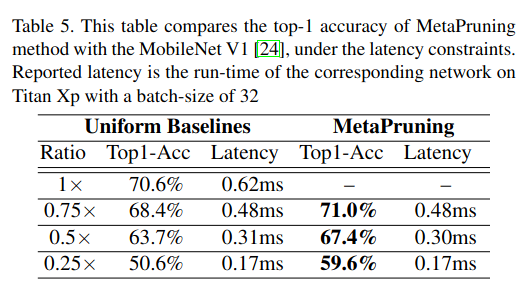
我们在 MobileNet V1 和 V2 上进行了实验。表 5 和表 6 显示,MetaPruning 发现的剪枝网络在相同延迟下比均匀基线取得了显著更高的精度 。
4.4. Pruned result visualization
在通道剪枝中,人们很好奇什么是最佳的剪枝启发式策略,许多人类专家致力于手动设计剪枝策略 。带着同样的好奇心,我们想知道我们的 MetaPruning 方法是否学到了一些有助于其高精度的合理剪枝方案 。在可视化剪枝网络结构时,我们发现 MetaPruning 确实学到了一些有趣的东西 。
图 5 显示了 MobileNet V1 的剪枝网络结构 。我们观察到,每当有下采样操作时,剪枝网络中都会出现显著的峰值 。当使用步长为 2 的深度卷积进行下采样时,特征图尺寸的分辨率降低需要通过使用更多通道来携带相同量的信息进行补偿 。因此,MetaPruning 自动学会了在下采样层保留更多通道 。在 MobileNet V2 中也观察到了同样的现象,如图 6 所示。当相应的块负责缩小特征图尺寸时,中间通道被修剪得较少 。
此外,当我们用 MetaPruning 自动修剪 MobileNet V2 中的 shortcut 通道时,我们发现,尽管 145M 的剪枝网络仅包含 300M 剪枝网络一半的 FLOPs,但 145M 网络在最后阶段保留了与 300M 网络相似数量的通道,而在早期阶段修剪了更多通道 。我们怀疑这是因为 ImageNet 数据集的分类器包含 1000 个输出节点,因此在后期阶段需要更多通道来提取足够的特征 。当 FLOPs 被限制在 45M 时,网络几乎达到了最大剪枝率,它别无选择,只能修剪后期阶段的通道,从 145M 网络到 45M 网络的精度下降比从 300M 到 145M 的下降要严重得多 。
4.5. Ablation study
在本节中,我们讨论权重预测在 MetaPruning 方法中的作用 。
我们想知道如果我们不在 PruningNet 中使用两个全连接层进行权重预测,而是直接应用所提出的随机训练并裁剪相同的权重矩阵以匹配剪枝网络中的输入和输出通道,会有什么后果 。我们比较了带有权重预测和不带权重预测的 PruningNet 的性能 。我们通过以 0.25, 1 范围内的比率均匀修剪每一层来选择通道数,并使用这两个 PruningNet 生成的权重评估精度 。图 8 显示,没有权重预测的 PruningNet 取得的精度低了 10% 。
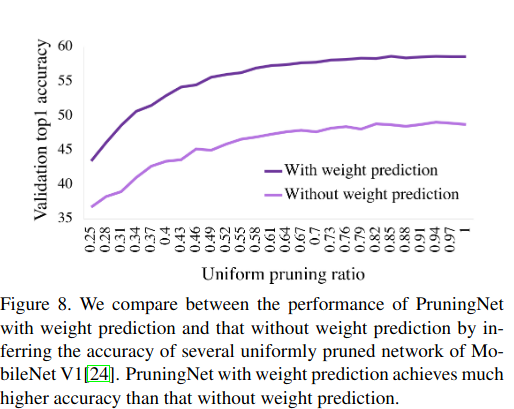
我们进一步使用没有权重预测的 PruningNet 来搜索 FLOPs 小于 45M 的剪枝 MobileNet V1 。获得的网络仅达到 55.3% 的 top1 精度,比通过权重预测获得的剪枝网络低 1.9% 。这是直观的。例如,当总输入通道增加到 128(后面增加了 64 个通道)时,针对 64 个输入通道宽度的权重矩阵可能不是最优的 。在这种情况下,元学习中的权重预测机制在去相关不同剪枝结构的权重方面是有效的,从而为 PruningNet 实现了更高的精度 。