深度网络的顽疾:梯度消失问题
在深度学习领域,构建更深的神经网络是提升模型性能的关键路径。然而,随着网络层数的增加,一个难题,梯度消失(Vanishing Gradient)便会浮出水面,它如同一个无形的枷锁,阻碍着深度网络的训练。简单来说,梯度消失是指在深度神经网络的反向传播过程中,损失函数对前面层权重参数的梯度变得极其微小,趋近于零 。这导致的直接后果是:网络的前面层参数几乎得不到有效的更新。因为参数更新的大小正比于梯度,梯度近乎为零,意味着这些层的权重在训练中几乎停滞不前。
问题根源
梯度消失问题的根源,可以追溯到某些激活函数自身的特性,尤其是Sigmoid函数 。Sigmoid函数有一个关键的数学特性:当输入值非常大或非常小(即其输出接近0或接近1)时,它的导数(derivative)会变得非常平缓,并趋近于零。
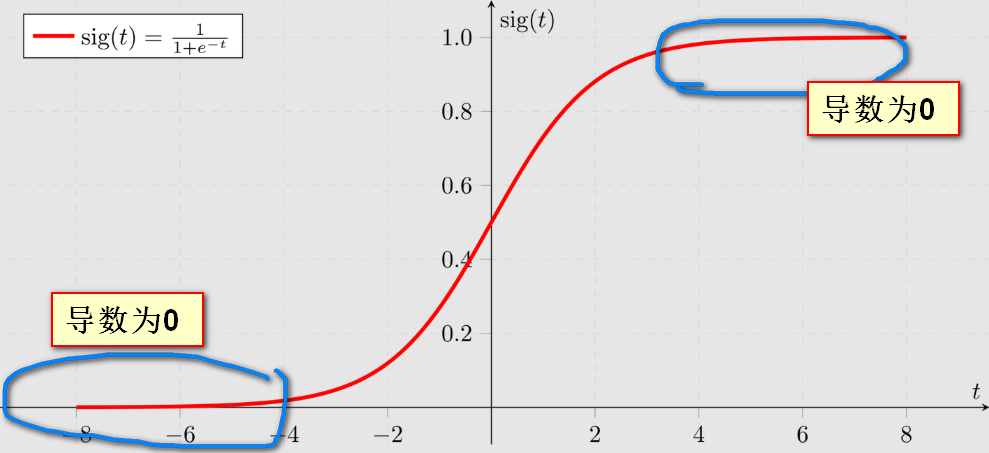
在深度神经网络中,通过链式法则进行反向传播时,梯度是各层激活函数导数的连乘积。如果这些导数持续小于1,连乘效应就会导致梯度值指数级地缩小。因此,当网络的激活值落入Sigmoid函数的"饱和区"时,这些近乎为零的导数项就会像一个不断调低的音量旋钮,将反向传播的梯度信号层层衰减,最终导致传递到前面层的梯度消失殆尽。所以,我们既不喜欢 sigmoid 的导数出现在梯度计算的链条中,也不喜欢 sigmoid 函数本身。
补救办法一:改用更聪明的损失函数
有时,问题出在终点。一个不合适的损失函数与输出层激活函数的组合,会从一开始就"掐灭"梯度的火苗。当我们使用 Sigmoid 或 Softmax 作为输出层激活函数 ,并配以均方误差(MSE)损失函数 时,会遭遇典型的梯度消失。Sigmoid/Softmax函数在饱和区(输出接近0或1时)的导数趋近于零。而MSE损失函数的梯度计算中恰好包含了Sigmoid 的导数项。那我们换个损失函数呗!
解决方案是使用交叉熵损失函数(Cross-Entropy Loss) ,它与Softmax/Sigmoid函数结合使用时,能在反向传播的梯度计算中巧妙地抵消激活函数的导数项(这个导数就不出现了),确保误差越大时梯度越大,学习信号越强。
补救办法二:改用不易饱和的激活函数
梯度消失的另一个重灾区是网络的中间层,传统的Sigmoid或Tanh激活函数是主要元凶。这些S型激活函数在两侧饱和区导数近乎为零。一旦激活值落入这些区域,梯度就会消失,并通过链式法则放大到前面的层。
解决方案是使用整流线性单元ReLU 及其变种。ReLU在正区间的导数为常数1,彻底解决了梯度消失问题。
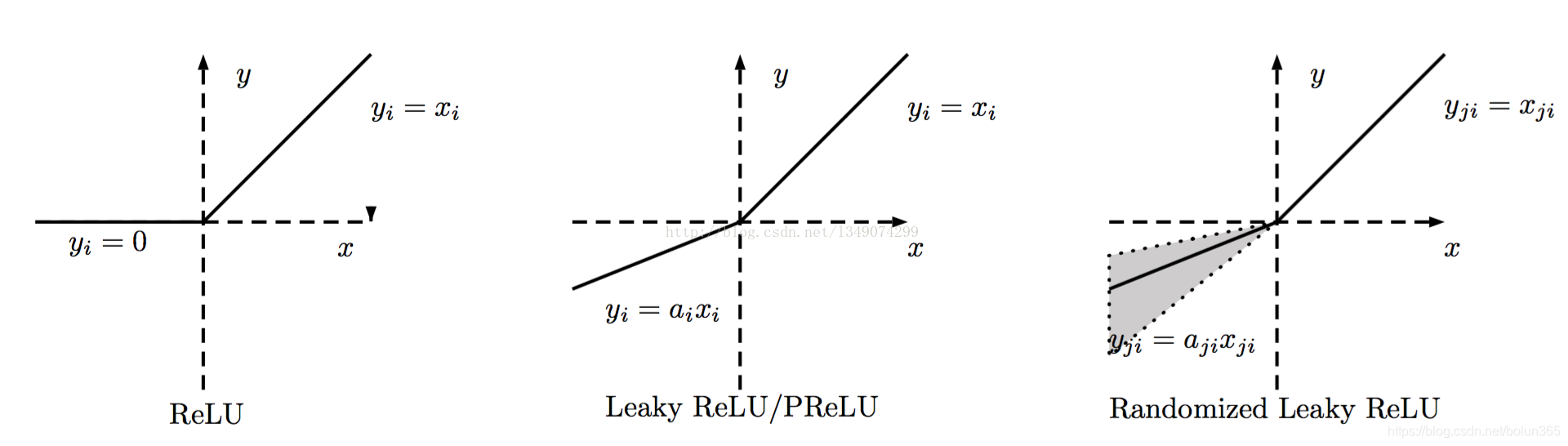
ReLU 把小于 0 的梯度直接变成 0,看似也"消失",但大于 0 的部分保持 1,不再额外缩小。只要网络里还有活着的神经元,它们的梯度就不会因为层数变深而衰减,因此训练能继续往下走。
虽然ReLU可能存在神经元死亡的问题,但其变种如Leaky ReLU、PReLU和ELU通过在负区间提供小的非零斜率,确保了梯度始终可以流动。
补救办法三:加深度监督
换了损失函数,换了激活函数,就万事大吉了吗?不。
如果网络极深,即便使用了ReLU,梯度流经数十上百层后,到达最前端时可能依然很微弱。
您提出的问题非常深刻,点明了即使解决了激活函数和损失函数的问题,深度网络训练依然面临的根本性挑战。
您说得非常对,仅仅更换损失函数和激活函数,并不足以确保极深网络的稳定训练。如果网络极深,即便使用了ReLU,梯度在流经数十甚至上百层后,到达最前端时其幅度可能依然会变得非常微弱。
一个关键原因,与权重矩阵 W 的取值密切相关。 具体来说,在每一层的反向传播中,梯度都需要乘以该层权重矩阵 W 的转置。如果网络初始化或训练过程中,使得多数权重 W 的值都小于1(即 |W| < 1),那么梯度每经过一层,就会被持续地"压缩"。经过足够多层的连乘,这种指数级的衰减效应会使得初始层收到的梯度信号微乎其微,即使激活函数的导数是1也无济于事。
深度监督(Deep Supervision)通过在网络中间层额外添加辅助分类器和辅助损失函数 来解决这个问题。这些辅助损失会直接对中间层的特征表示进行监督和惩罚,为靠近网络前端的层提供直接的监督信号 。这个信号无需经过后面所有层的漫长反向传播,路径大大缩短,从而避免了梯度在长路径中消失。深度监督不仅确保了前面层能被有效训练,还起到了隐式的正则化作用。
总结
通过综合运用交叉熵损失配对Softmax/Sigmoid、在中间层采用ReLU及其变种、在极深网络中引入深度监督这三种方法,我们可以构建起稳定、高效的梯度流动通道。这些方法相互补充,共同解决了深度网络中的梯度消失问题,使得训练极深神经网络成为可能。现代深度学习架构如ResNet、DenseNet等都在不同程度上借鉴了这些思想,推动着深度学习技术不断向前发展。
(图源:https://pic4.zhimg.com/v2-24758bffbd6a9a5d243ff226cb1e3306_1440w.jpg