说的神马?基于 Wav2Vec2 的端到端中文语音识别系统
代码详见:https://github.com/xiaozhou-alt/Chinese_Speech_Recognition
文章目录
- [说的神马?基于 Wav2Vec2 的端到端中文语音识别系统](#说的神马?基于 Wav2Vec2 的端到端中文语音识别系统)
- 一、项目介绍
- 二、文件夹结构
- 三、数据集介绍
- [四、Wav2Vec2 模型介绍](#四、Wav2Vec2 模型介绍)
-
- [1. 特征编码器:从原始波形到声学特征](#1. 特征编码器:从原始波形到声学特征)
- [2. 上下文网络:捕捉语音序列依赖关系](#2. 上下文网络:捕捉语音序列依赖关系)
- [3. CTC 头与损失函数:解决时序对齐难题](#3. CTC 头与损失函数:解决时序对齐难题)
- [4. 自监督预训练机制:无标注数据的知识积累](#4. 自监督预训练机制:无标注数据的知识积累)
- 五、项目实现
-
- [1. 评估指标初始化](#1. 评估指标初始化)
- [2. 数据集准备](#2. 数据集准备)
-
- [2.1 数据路径与文件列表](#2.1 数据路径与文件列表)
- [2.2 训练集与验证集划分](#2.2 训练集与验证集划分)
- [3. 自定义数据集类](#3. 自定义数据集类)
-
- [3.1 初始化方法 (`init`)](#3.1 初始化方法 (
__init__)) - [3.2 长度方法 (`len`)](#3.2 长度方法 (
__len__)) - [3.3 数据获取方法 (`getitem`)](#3.3 数据获取方法 (
__getitem__))
- [3.1 初始化方法 (`init`)](#3.1 初始化方法 (
- [4. 模型加载与配置](#4. 模型加载与配置)
-
- [4.1 Wav2Vec2 模型结构](#4.1 Wav2Vec2 模型结构)
- [4.2 关键参数解析](#4.2 关键参数解析)
- [4.3 模型初始化](#4.3 模型初始化)
- [5. 数据加载器配置](#5. 数据加载器配置)
-
- [5.1 自定义数据整理函数 (data_collator)](#5.1 自定义数据整理函数 (data_collator))
- [5.2 数据加载器创建](#5.2 数据加载器创建)
- [6. 优化器与学习率调度器](#6. 优化器与学习率调度器)
-
- [6.1 优化器选择](#6.1 优化器选择)
- [6.2 学习率调度器](#6.2 学习率调度器)
- [7. 验证集评估函数](#7. 验证集评估函数)
-
- [7.1 评估流程](#7.1 评估流程)
- [7.2 CTC 解码](#7.2 CTC 解码)
- [8. 开始训练!](#8. 开始训练!)
-
- [8.1 训练阶段](#8.1 训练阶段)
- [8.2 验证阶段](#8.2 验证阶段)
- [8.3 训练记录与早停检查](#8.3 训练记录与早停检查)
- [9. 样本可视化测试](#9. 样本可视化测试)
-
- [9.1 样本选择与处理](#9.1 样本选择与处理)
- [9.2 模型预测](#9.2 模型预测)
- 六、结果展示
一、项目介绍
本项目是一个基于深度学习的中文语音识别系统,旨在将中文语音信号准确转换为对应的文本内容。该系统利用 Hugging Face 的 Transformers 库中预训练的 Wav2Vec2 模型进行微调,专门针对中文语音识别任务进行优化。
Wav2Vec2 是 Facebook AI 研究院提出的一种先进的自监督学习语音模型,能够从大量未标注的语音数据中学习语音表示。本项目基于预训练的 "wav2vec2-large-xlsr-53-chinese-zh-cn" 模型进行微调,该模型已经在大量中文语音数据上进行了预训练,非常适合中文语音识别任务。
系统采用了 CTC(Connectionist Temporal Classification)损失函数,这是一种常用于序列到序列学习的损失函数,特别适合语音识别这类输入和输出序列长度不一致的任务。
项目实现了完整的语音识别流程,包括:
- 音频数据预处理(格式转换、重采样、声道处理)
- 自定义数据集加载和处理
- 模型训练与微调
- 模型评估(使用 WER 指标)
二、文件夹结构
c
Chinese_Speech_Recognition\
├── README.md
├── data.ipynb # 用于数据分析和预处理
├── data\
├── data_thchs30\ # THCHS-30中文语音数据集
├── README-data.md # 数据集说明文档
└── data\ # 实际音频数据存放目录
├── log\
├── output\ # 输出结果目录
├── model\ # 模型存储目录
├── sound.pth # 训练好的模型权重文件
└── wav2vec2-large-xlsr-53-chinese-zh-cn\ # 预训练模型目录
├── pic\ # 图片和可视化结果目录
├── test_results.xlsx # 测试结果数据表
└── training_history.xlsx # 训练历史记录数据表
├── requirements.txt
└── train.py三、数据集介绍
数据集下载可前往:THCHS-30
本项目使用 THCHS-30 中文语音数据集进行模型训练和评估。THCHS-30 是一个常用的中文语音识别数据集,包含 30 小时的语音数据。
数据集的组织结构如下:
- 音频文件:以 WAV 格式存储,采样率可能有所不同
- 标签文件:与音频文件同名的.trn 文件,包含对应的中文文本标签
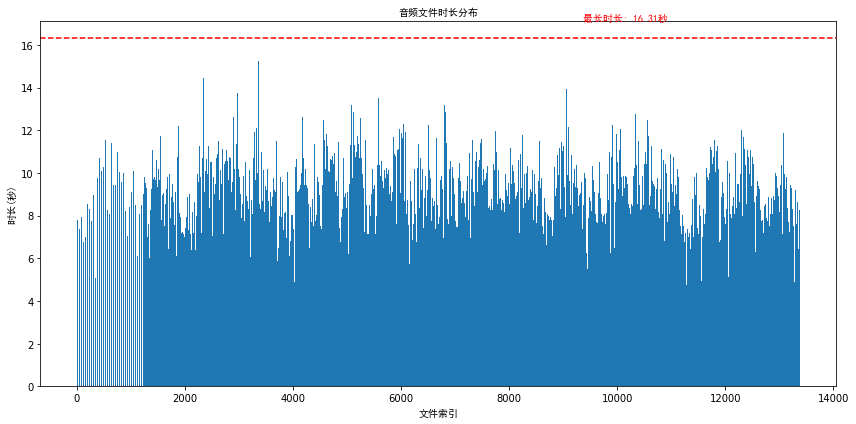
数据集的音频时长与索引分布如下所示:
四、Wav2Vec2 模型介绍
1. 特征编码器:从原始波形到声学特征
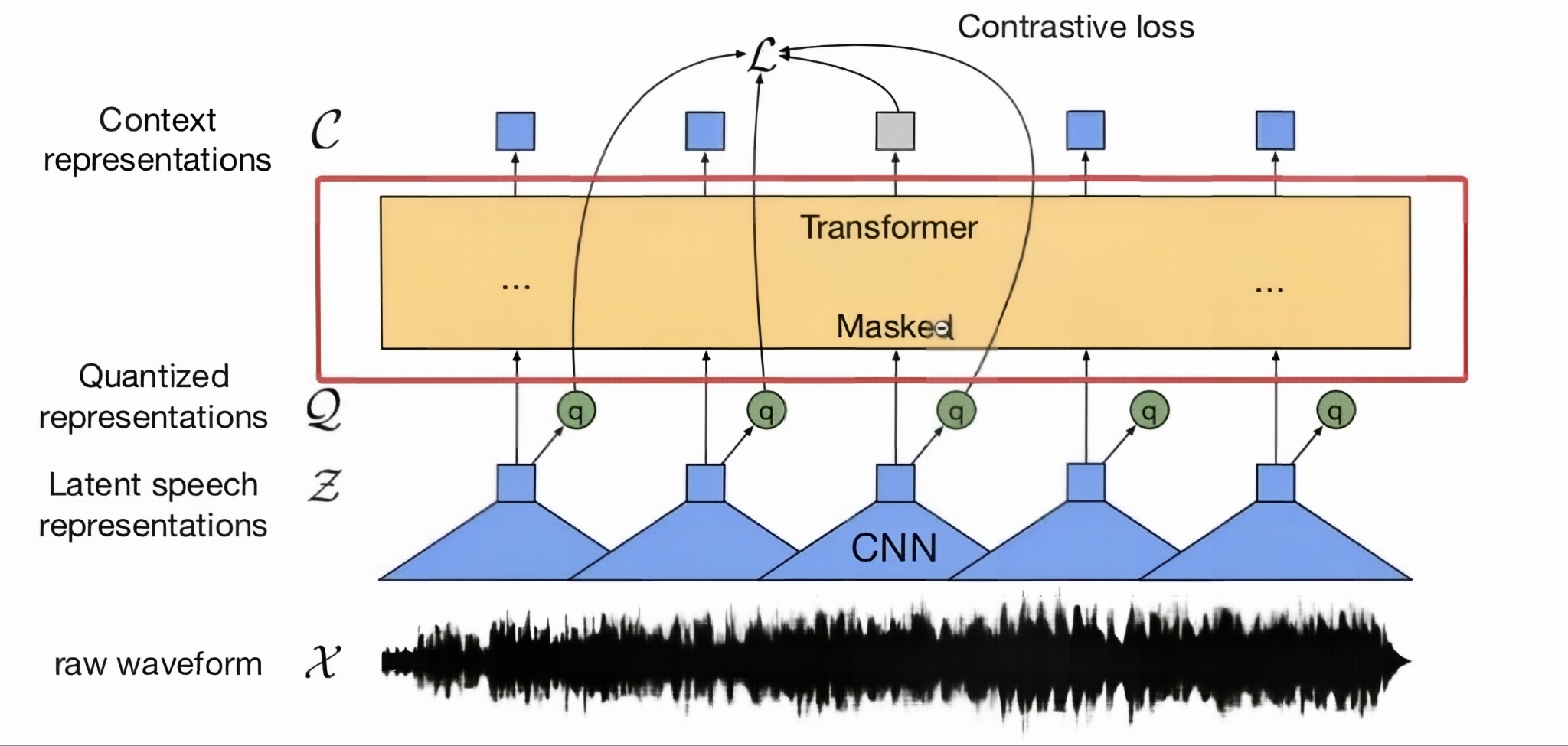
特征编码器是 Wav2Vec2 的 "耳朵",负责将原始音频波形转换为有意义的声学特征表示。它采用 7 层卷积神经网络结构,通过逐步下采样捕捉不同尺度的音频特征:
x _ l + 1 = GELU ( Conv ( x _ l , k = 3 , s = 2 ) ) x\_{l+1} = \text{GELU}(\text{Conv}(x\_l, k=3, s=2)) x_l+1=GELU(Conv(x_l,k=3,s=2))
其中 x _ l x\_l x_l 表示第 l l l 层的输入特征, k k k 为卷积核大小, s s s 为步长。前 6 6 6 层卷积使用步长为 2 2 2 的 3×3 \textbf{3×3} 3×3 卷积核,最后一层使用步长为 1 1 1 的卷积核,将原始 16 k H z 16kHz 16kHz 音频(每秒 16000 16000 16000 个采样点)压缩为每秒 50 50 50 个特征帧,实现了 320 320 320 倍的时间维度压缩。
在代码实现中,我们通过librosa.resample将所有音频统一处理为 16 k H z 16kHz 16kHz 采样率,为特征编码器提供标准化输入,这一步对应着让 所有 "说话人" 使用相同的 "语速" 发言,便于后续处理。
🤓🤓🤓小周有话说 :
想象你在听一段 中文新闻播报 ,原始音频就像一条连续不断的声波河流。特征编码器就像一系列精密滤网,第一层滤网捕捉
"你好"中"你"的基础声波振动,经过多层过滤后,最终提取出"你"、"好"等音节的核心声学特征,过滤掉背景噪音等无关信息。这就像我们听人说话时,自动忽略环境杂音,只关注关键语音信息 的过程。
2. 上下文网络:捕捉语音序列依赖关系
上下文网络是 Wav2Vec2 的 "大脑",由多个 Transformer 层组成,通过自注意力机制捕捉语音序列中的长距离依赖关系。其核心是多头自注意力计算:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V MultiHead ( Q , K , V ) = Concat ( head 1 , ... , head h ) W O \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \\ \ \\ \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \dots, \text{head}_h)W^O Attention(Q,K,V)=softmax(dk QKT)V MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中 Q Q Q、 K K K、 V V V 分别为查询、键和值矩阵, d k d_k dk 为特征维度, h h h 为注意力头数。这种机制允许模型在处理 "北京天安门" 这样的短语时,同时关注 "北京" 和 "天安门" 之间的语义关联。
这种机制特别适合中文语音识别,因为中文词语之间没有明显分隔,需要通过上下文理解 "下雨天留客天留我不留" 这样的歧义句子
🤓🤓🤓小周有话说 :
假设我们识别
"我爱北京天安门"这句话,当处理到"北京"时,上下文网络会像人类理解语言一样,自动联想到后面可能出现的"天安门"。自注意力权重就像句子中词语间的"关联强度表","北京"与"天安门"之间的权重会显著高于与其他词的关联。代码中的attention_dropout=0.1参数就像给这个联想过程增加一点 "遗忘概率",防止模型过度依赖某些固定关联,增强泛化能力。
3. CTC 头与损失函数:解决时序对齐难题
CTC(Connectionist Temporal Classification)头是 Wav2Vec2 的 "翻译官",负责将声学特征序列转换为文本序列,并通过 CTC 损失函数优化模型参数:
L = − log ( ∑ π ∈ B ( l ) P ( π ∣ x ) ) L = -\log\left(\sum_{\pi \in \mathcal{B}(l)} P(\pi | x)\right) L=−log π∈B(l)∑P(π∣x)
其中 B ( l ) \mathcal{B}(l) B(l) 表示所有与标签序列 l l l 对齐的路径集合, P ( π ∣ x ) P(\pi | x) P(π∣x) 为路径 π \pi π 的概率。CTC 引入空白标签 ∅ 解决语音与文本的时序不对齐问题,允许模型学习发音 - 文本的多对多映射关系
这种特性让模型特别适合处理中文语音中常见的 连读 、吞音 现象,比如将 "不知道" 的实际发音正确转换为标准文本,而不会被发音的模糊边界干扰
🤓🤓🤓小周有话说 :
当我们说
"中国"这个词时,实际发音可能是"中 ------ 国"(中间有自然停顿),也可能是快速连读"中国"。CTC 头就像一位 智能校对员 ,能自动忽略多余的停顿(对应空白标签 ),无论你说得快还是慢,都能正确转换为"中国"这两个字。代码中ctc_loss_reduction="mean"参数表示采用平均损失策略,就像老师批改作业时,综合评估所有错题的平均错误程度来打分。
4. 自监督预训练机制:无标注数据的知识积累
Wav2Vec2 的成功很大程度上归功于其创新的自监督预训练机制,通过对比损失和掩码预测任务学习通用语音表示:
L contrastive = − log ( e s ( z i , c i ) / τ ∑ j = 1 N e s ( z j , c i ) / τ ) L_{\text{contrastive}} = -\log\left(\frac{e^{s(z_i, c_i)/\tau}}{\sum_{j=1}^N e^{s(z_j, c_i)/\tau}}\right) Lcontrastive=−log(∑j=1Nes(zj,ci)/τes(zi,ci)/τ)
其中 s ( z i , c i ) s(z_i, c_i) s(zi,ci) 表示特征 z i z_i zi 与上下文向量 c i c_i ci 的相似度, τ \tau τ 为温度参数。预训练时随机掩码 50 % 50\% 50% 的时间步,让模型从上下文预测被掩码的声学特征。
🤓🤓🤓小周有话说 :
这就像我们学习中文听力时,即使某些词语 没听清 (被掩码 ),也能 根据上下文推测 出内容。模型在预训练阶段
"收听"了大量无标注语音数据,就像婴儿在学会说话前先 "聆听" 周围环境的语言,积累了丰富的语音知识。我们使用的jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn模型已经通过这种方式学习了中文语音的基本规律,再通过 THCHS-30 数据集微调,就像给模型"上中文强化班",使其专门适应中文语音识别任务
五、项目实现
1. 评估指标初始化
语音识别任务中最常用的评估指标是词错误率 (WER):
python
# 加载WER评估指标
wer_metric = evaluate.load("wer")词错误率 (WER) 是衡量语音识别系统性能的核心指标,计算方法为:
W E R = ( 替换错误 + 插入错误 + 删除错误 ) / 参考词总数 WER = (替换错误 + 插入错误 + 删除错误) / 参考词总数 WER=(替换错误+插入错误+删除错误)/参考词总数
值越低表示系统性能越好,0 表示完全正确识别。
2. 数据集准备
2.1 数据路径与文件列表
python
# 数据集路径
data_dir = "/kaggle/input/chinese-speech-to-textthchs30/data/data" # 修改为你的数据路径
# 获取所有文件
wav_files = [f for f in os.listdir(data_dir) if f.endswith('.wav')]
print(f"Found {len(wav_files)} WAV files")2.2 训练集与验证集划分
python
# 划分训练集和验证集 (80%训练, 20%验证)
train_size = int(0.8 * len(wav_files))
val_size = len(wav_files) - train_size
train_files, val_files = random_split(wav_files, [train_size, val_size])
print(f"Training set: {len(train_files)} samples")
print(f"Validation set: {len(val_files)} samples")数据集划分策略:
- 采用 8 : 2 8:2 8:2 的比例划分训练集和验证集
- 使用
random_split函数进行随机划分 - 训练集用于模型参数学习,验证集用于监控训练过程中的过拟合情况
3. 自定义数据集类
P y T o r c h PyTorch PyTorch 通过自定义Dataset类来处理数据加载,这里我们创建专门的语音数据集类:
python
# 创建自定义数据集类
class SpeechDataset(Dataset):
def __init__(self, file_list, data_dir):
self.file_list = file_list
self.data_dir = data_dir
self.processor = Wav2Vec2Processor.from_pretrained("jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn")
def __len__(self):
return len(self.file_list)
def __getitem__(self, idx):
wav_file = self.file_list[idx]
wav_path = os.path.join(self.data_dir, wav_file)
trn_path = os.path.join(self.data_dir, wav_file + ".trn")
# 读取音频文件
try:
speech_array, sampling_rate = sf.read(wav_path)
speech_array = speech_array.astype(np.float32)
except Exception as e:
print(f"读取音频文件错误 {wav_path}: {e}")
return None
# 如果音频是双声道,转换为单声道
if len(speech_array.shape) > 1:
speech_array = np.mean(speech_array, axis=1)
# 重采样到16kHz
if sampling_rate != 16000:
speech_array = librosa.resample(speech_array, orig_sr=sampling_rate, target_sr=16000)
# 读取标签
try:
with open(trn_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
# 使用第一行作为标签文本
text = lines[0].strip() if lines else ""
except Exception as e:
print(f"读取标签文件错误 {trn_path}: {e}")
text = ""
# 处理音频和标签
inputs = self.processor(
speech_array,
sampling_rate=16000,
text=text,
padding=True,
return_tensors="pt"
)
# 移除批次维度
inputs = {key: inputs[key].squeeze(0) for key in inputs}
return inputs3.1 初始化方法 (__init__)
- 接收文件列表和数据目录
- 加载 W a v 2 V e c 2 Wav2Vec2 Wav2Vec2 处理器 (
processor),这是连接原始数据与模型输入的关键组件 - 使用的预训练模型是专门为中文优化的
jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn
W a v 2 V e c 2 P r o c e s s o r Wav2Vec2Processor Wav2Vec2Processor 整合了特征提取器和tokenizer,能同时处理音频数据和文本标签:
- 对音频:将原始波形转换为模型需要的特征表示
- 对文本:将文字转换为模型可理解的
token ID
3.2 长度方法 (__len__)
简单返回数据集中样本的数量,是 PyTorch Dataset 的必需方法。
3.3 数据获取方法 (__getitem__)
这是数据集类的核心,负责加载和预处理单个样本:
-
音频加载与预处理:
l i b r o s a librosa librosa 的重采样使用基于 FFT 的方法,能在 改变采样率的同时保持音频质量,确保不同来源的音频具有一致的时间尺度。
- 使用
soundfile读取音频文件,获取音频数组和采样率 - 处理双声道音频:通过求平均值转换为单声道
- 重采样:统一将音频采样率转换为 16 k H z 16kHz 16kHz,这是 Wav2Vec2 模型的期望输入采样率
- 使用
-
标签加载:
- 从对应的
.trn文件中读取文本标签 - 处理可能的文件读取错误,提高代码健壮性
- 从对应的
-
数据处理:
- 使用
processor同时处理音频和文本 - 转换为 PyTorch 张量格式
- 移除多余的批次维度,确保单个样本的正确格式
- 使用
4. 模型加载与配置
Wav2Vec2 是一种基于自监督学习的语音表示模型,在语音识别任务上表现优异:
python
# 加载预训练模型
model = Wav2Vec2ForCTC.from_pretrained(
"jonatasgrosman/wav2vec2-large-xlsr-53-chinese-zh-cn",
attention_dropout=0.1,
hidden_dropout=0.1,
feat_proj_dropout=0.0,
mask_time_prob=0.05,
layerdrop=0.1,
ctc_loss_reduction="mean",
pad_token_id=processor.tokenizer.pad_token_id,
vocab_size=len(processor.tokenizer)
)
# 设置模型为训练模式
model.train()
model.to(device)4.1 Wav2Vec2 模型结构
Wav2Vec2ForCTC 是专为 CTC 损失设计的 Wav2Vec2 变体,其结构包括:
- 特征编码器:将原始音频转换为高级特征表示
- 上下文网络:捕获长时依赖关系
- CTC 头:输出每个时间步的字符概率分布
4.2 关键参数解析
- Dropout 参数 :
attention_dropout、hidden_dropout等用于防止过拟合 - mask_time_prob:训练时对时间步进行掩码的概率,是 Wav2Vec2 的自监督学习遗产
- layerdrop:随机丢弃整个层的概率,增强模型鲁棒性
- ctc_loss_reduction :CTC 损失的聚合方式,这里使用
"mean" - pad_token_id:指定填充 token 的 ID,用于处理不等长序列
4.3 模型初始化
- 加载预训练权重,这是迁移学习的关键
- 设置为训练模式 (
model.train()) - 将模型移动到之前确定的计算设备 (GPU 或 CPU)
5. 数据加载器配置
PyTorch 的 DataLoader 负责批处理、打乱数据和并行加载:
python
# 定义数据整理函数
def data_collator(batch):
# 过滤掉None值
batch = [item for item in batch if item is not None]
if not batch:
return None
# 找出批次中最长的音频长度
max_length = max(item['input_values'].shape[0] for item in batch)
# 找出批次中最长的标签长度
max_label_length = max(item['labels'].shape[0] for item in batch)
# 初始化填充后的张量
padded_input_values = []
padded_attention_mask = []
padded_labels = []
for item in batch:
# 填充音频输入
input_length = item['input_values'].shape[0]
padding_length = max_length - input_length
if padding_length > 0:
padded_input = torch.cat([
item['input_values'],
torch.zeros(padding_length, dtype=item['input_values'].dtype)
])
padded_attention = torch.cat([
item['attention_mask'],
torch.zeros(padding_length, dtype=item['attention_mask'].dtype)
])
else:
padded_input = item['input_values']
padded_attention = item['attention_mask']
# 填充标签
label_length = item['labels'].shape[0]
label_padding_length = max_label_length - label_length
if label_padding_length > 0:
padded_label = torch.cat([
item['labels'],
torch.full((label_padding_length,), -100, dtype=item['labels'].dtype)
])
else:
padded_label = item['labels']
padded_input_values.append(padded_input)
padded_attention_mask.append(padded_attention)
padded_labels.append(padded_label)
return {
'input_values': torch.stack(padded_input_values),
'attention_mask': torch.stack(padded_attention_mask),
'labels': torch.stack(padded_labels)
}
# 创建数据加载器
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True, collate_fn=data_collator)
val_loader = DataLoader(val_dataset, batch_size=2, shuffle=False, collate_fn=data_collator)5.1 自定义数据整理函数 (data_collator)
由于语音数据长度不一,需要自定义整理函数来处理批处理:
-
过滤无效样本 :移除加载失败的样本 (
None 值) -
确定填充长度:找出批次中最长的音频和标签长度
-
音频填充:
- 对短于最大长度的音频补零
- 相应调整注意力掩码 (
attention mask),指示有效音频部分
-
标签填充:
- 使用 − 100 -100 −100 填充标签,这是 PyTorch 中 CTC 损失忽略的特殊值
- 确保损失计算时不考虑填充部分
5.2 数据加载器创建
batch_size=4:训练批次大小,根据 GPU 显存调整shuffle=True:训练集打乱顺序,增强训练随机性collate_fn=data_collator:使用自定义整理函数- 验证集使用较小批次,且不打乱顺序
6. 优化器与学习率调度器
python
# 设置优化器
optimizer = torch.optim.AdamW(model.parameters(), lr=1e-4)
# 学习率调度器
num_epochs = 8 # 适当增加训练轮数以获得更好效果
num_training_steps = num_epochs * len(train_loader)
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=num_training_steps)6.1 优化器选择
使用 AdamW 优化器,这是 Adam 优化器的变体,增加了权重衰减 (weight decay) 正则化,有助于防止过拟合。初始学习率设置为 1e-4,适合预训练模型的微调。
6.2 学习率调度器
采用 余弦退火 调度器:
- 学习率随训练步骤按余弦曲线逐渐降低
- T_max设置为总训练步数,完整经历一个余弦周期
- 这种策略通常比固定学习率收敛更快,泛化性能更好
7. 验证集评估函数
python
# 定义验证集评估函数(计算Loss和WER)
def evaluate_on_validation_set(model, dataloader, processor, device):
model.eval()
total_loss = 0
all_predictions = []
all_references = []
with torch.no_grad():
for batch in tqdm(dataloader, desc="Evaluating on validation set"):
if batch is None:
continue
input_values = batch['input_values'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
# 计算损失
with torch.cuda.amp.autocast(enabled=device.type == "cuda"):
outputs = model(input_values=input_values, attention_mask=attention_mask, labels=labels)
total_loss += outputs.loss.item()
# 生成预测
logits = outputs.logits
predicted_ids = torch.argmax(logits, dim=-1)
# 解码预测结果和标签(转换为文本)
predictions = processor.batch_decode(predicted_ids)
references = processor.batch_decode(labels, group_tokens=False) # 不解码成组,保持原始标签
all_predictions.extend(predictions)
all_references.extend(references)
# 计算平均损失和WER
avg_loss = total_loss / len(dataloader) if len(dataloader) > 0 else 0
wer = wer_metric.compute(predictions=all_predictions, references=all_references)
return avg_loss, wer, all_predictions, all_references7.1 评估流程
模型状态设置:将模型设为评估模式 (model.eval()),关闭 dropout 等训练特有的操作
梯度禁用:使用torch.no_grad()上下文管理器,减少内存占用并加速计算
批量处理:
将数据移至计算设备
使用混合精度计算损失
生成模型预测(logits)
解码过程:
将模型输出的 logits 通过 argmax 获取预测的 token ID
使用 processor 将 token ID 转换为文本(解码)
特别注意标签解码使用group_tokens=False,确保正确计算 WER
指标计算:计算平均损失和整体 WER
7.2 CTC 解码
代码中使用的是贪婪解码(取每个时间步概率最大的 token),这是一种简单高效的解码策略。更复杂的解码策略(如 beam search)可以进一步提高性能,但计算成本更高。
8. 开始训练!
python
# 训练循环
for epoch in range(num_epochs):
# 训练阶段
model.train()
train_loss = 0
train_bar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs} [Train]")
for batch in train_bar:
if batch is None:
continue
# 将数据移动到设备
input_values = batch['input_values'].to(device)
attention_mask = batch['attention_mask'].to(device)
labels = batch['labels'].to(device)
# 前向传播 - 使用混合精度
optimizer.zero_grad()
with torch.cuda.amp.autocast(enabled=device.type == "cuda"):
outputs = model(input_values=input_values, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
# 反向传播 - 使用混合精度
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
lr_scheduler.step()
train_loss += loss.item()
train_bar.set_postfix(loss=loss.item())
avg_train_loss = train_loss / len(train_loader) if len(train_loader) > 0 else 0
# 验证阶段(计算Loss和WER)
avg_val_loss, val_wer, _, _ = evaluate_on_validation_set(model, val_loader, processor, device)
# 记录训练历史
train_history.append({
'epoch': epoch + 1,
'train_loss': avg_train_loss,
'val_loss': avg_val_loss,
'val_wer': val_wer, # 记录WER
'learning_rate': lr_scheduler.get_last_lr()[0] if len(train_loader) > 0 else 0
})
# 打印当前epoch的评估结果
print(f"\nEpoch {epoch+1}/{num_epochs}")
print(f"Train Loss: {avg_train_loss:.4f}")
print(f"Val Loss: {avg_val_loss:.4f}")
print(f"Val WER: {val_wer:.4f} (越低越好,0表示完全正确)")
# 早停检查(基于WER)
if val_wer < best_val_wer:
best_val_wer = val_wer
patience_counter = 0
# 保存最佳模型
torch.save(model.state_dict(), "/kaggle/working/best_model.pth")
print(f"保存最佳模型 (WER: {best_val_wer:.4f})")
else:
patience_counter += 1
print(f"早停计数器: {patience_counter}/{early_stopping_patience}")
if patience_counter >= early_stopping_patience:
print(f"早停触发,在第 {epoch+1} 轮停止训练")
break8.1 训练阶段
- 模型状态 :设置为训练模式 (
model.train()) - 进度跟踪:使用 tqdm 显示训练进度和当前损失
- 批量训练步骤 :
- 数据移至计算设备
- 梯度清零 (
optimizer.zero_grad()) - 前向传播:使用混合精度 (
autocast) 计算输出和损失 - 反向传播:使用
scaler处理混合精度梯度 - 参数更新:
scaler.step(optimizer)确保安全更新 - 学习率调整:调度器更新学习率
- 损失累积:计算整个 epoch 的平均训练损失
8.2 验证阶段
每个 epoch 结束后,在验证集上评估模型性能:
- 调用前面定义的
evaluate_on_validation_set函数 - 获取验证损失和 WER
8.3 训练记录与早停检查
- 记录每个 epoch 的关键指标:损失、WER、学习率
- 打印 epoch 总结,可视化训练进展
- 早停检查:如果 WER 改善则保存模型并重置计数器,否则递增计数器
- 当计数器达到耐心值时,停止训练
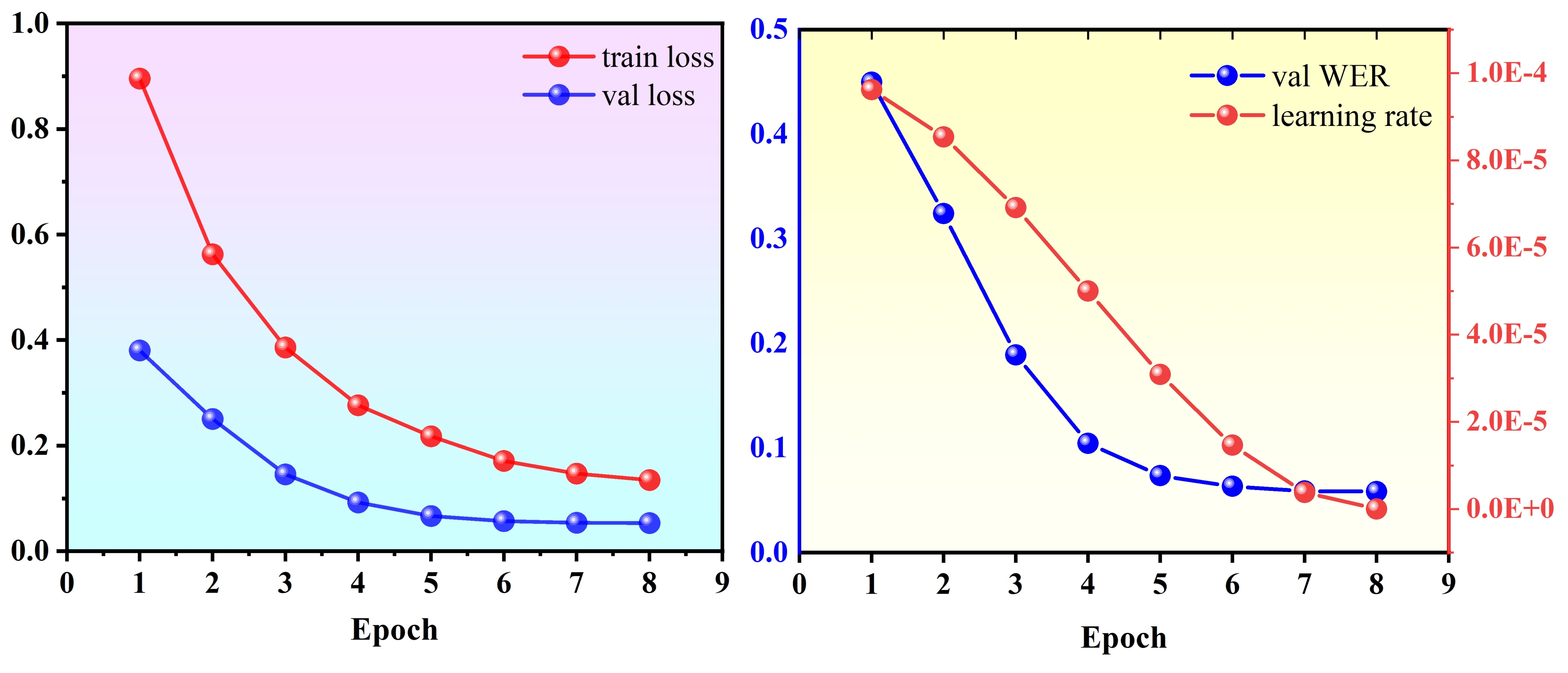
训练示例输出:
Using device: cuda
混合精度训练: 启用(需要CUDA支持)
Found 13388 WAV files
Training set: 10710 samples
Validation set: 2678 samples
Epoch 1/8
Train Loss: 0.8957
Val Loss: 0.3803
Val WER: 0.4495 (越低越好,0表示完全正确)
保存最佳模型 (WER: 0.4495)
...
Epoch 8/8
Train Loss: 0.1346
Val Loss: 0.0532
Val WER: 0.0584 (越低越好,0表示完全正确)
保存最佳模型 (WER: 0.0584)
最终模型在验证集上的表现:
最终验证Loss: 0.0532
最终验证WER: 0.0584 (错误率:5.84%)
9. 样本可视化测试
为直观展示模型性能,随机选择部分验证样本进行详细测试:
python
# 随机选择10个验证样本进行详细测试
val_file_list = [val_files.dataset[i] for i in val_files.indices]
test_samples = random.sample(val_file_list, min(10, len(val_file_list)))
# 创建测试结果列表
test_results = []
# 进行详细测试
for i, wav_file in enumerate(test_samples):
wav_path = os.path.join(data_dir, wav_file)
trn_path = os.path.join(data_dir, wav_file + ".trn")
# 读取真实文本
try:
with open(trn_path, 'r', encoding='utf-8') as f:
lines = f.readlines()
true_text = lines[0].strip() if lines else ""
except Exception as e:
print(f"读取标签文件错误 {trn_path}: {e}")
true_text = ""
# 读取和处理音频
try:
speech_array, sampling_rate = sf.read(wav_path)
speech_array = speech_array.astype(np.float32)
except Exception as e:
print(f"读取音频文件错误 {wav_path}: {e}")
continue
if len(speech_array.shape) > 1:
speech_array = np.mean(speech_array, axis=1)
if sampling_rate != 16000:
speech_array = librosa.resample(speech_array, orig_sr=sampling_rate, target_sr=16000)
# 模型预测
inputs = processor(speech_array, sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
with torch.cuda.amp.autocast(enabled=device.type == "cuda"):
logits = model(inputs.input_values.to(device)).logits
predicted_ids = torch.argmax(logits, dim=-1)
prediction = processor.batch_decode(predicted_ids)[0]
# 保存结果
test_results.append({
'audio_file': wav_file,
'true_text': true_text,
'predicted_text': prediction,
'audio_array': speech_array,
'sampling_rate': 16000
})
print(f"\nSample {i+1}:")
print(f"True: {true_text}")
print(f"Predicted: {prediction}")
print("-" * 50)9.1 样本选择与处理
- 从验证集中随机选择 10 个样本
- 对每个样本进行完整处理:音频加载、预处理、文本读取
9.2 模型预测
- 使用
processor准备模型输入 - 禁用梯度计算加速推理
- 使用混合精度提高效率
- 模型输出
logits后,通过argmax获取预测的token ID - 解码 token ID 为文本,得到最终识别结果
六、结果展示
训练的历史记录 Loss 和 WER 如下所示:
在验证集上得到的部分测试结果如下(下面的语音是假的):

这个才是真的 (因为这个是视频):
中文语音转换
如果你喜欢我的文章,不妨给小周一个免费的点赞和关注吧!