RAG流程:
-
用户提问(
q) -
对
q做处理(重写 \ 查询扩展 \ 向量化) -
向量库检索(向量相似度匹配)
-
将
q+选出的文档片段组合成prompt -
调用大模型回答
a
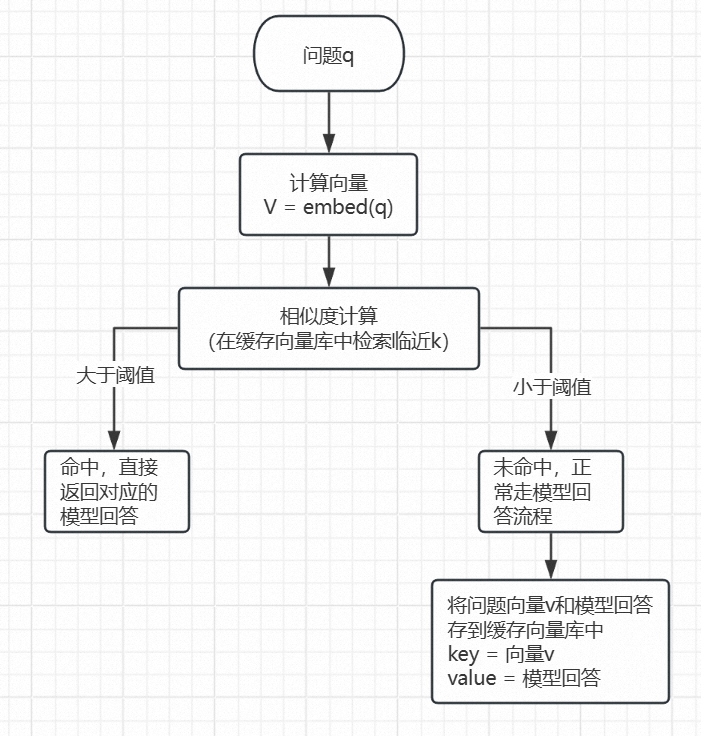
1.完整问答缓存(q → a cache)
将每个q标准化以后,与对应的a做匹配后存入缓存,当用户再问同样的问题后直接返回与其对应的a
key : q问题(标准化后的问题)
value :模型返回的答案
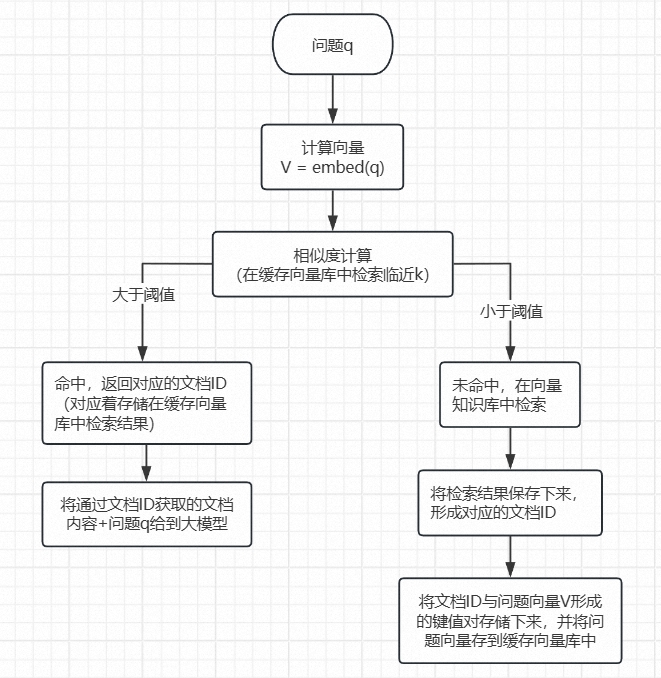
2. 近似问题缓存
3. 检索结果缓存