文章:A Benchmark for Ultra-High-Resolution Remote Sensing MLLMs
代码:https://github.com/Yunkaidang/RSHR
单位:南京大学
一、问题背景:现有基准的四大"硬伤"
-
分辨率严重脱节:多数遥感基准用512×512或1024×1024的小图,与真实卫星/无人机拍摄的4K+超高清图像差距巨大,无法测试模型对大场景的理解能力。
-
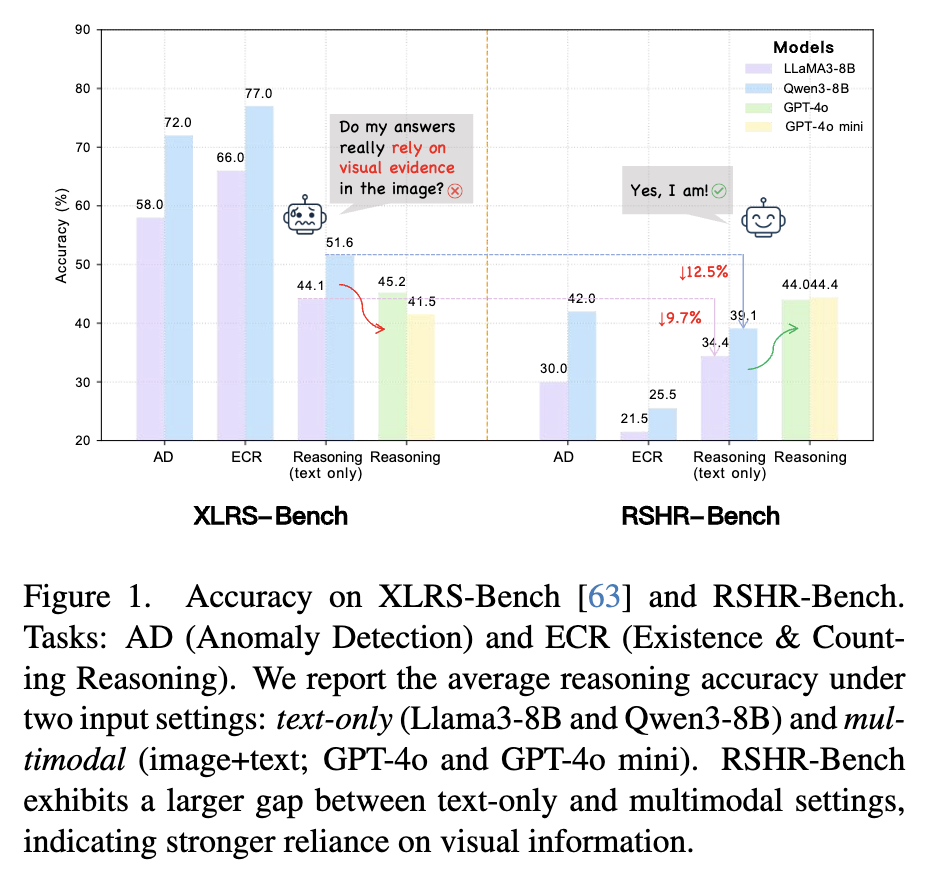
语言先验干扰严重:很多问题不用看图像,纯文本模型靠常识就能答对------比如某基准中纯文本模型推理准确率达51.6%,甚至超过了多模态模型的45.2%,根本测不出真实视觉理解能力。
-
任务设计单一:大多局限于单轮选择题,缺乏多轮对话、多图对比等真实遥感分析场景,实用性不足。
-
缺乏严格校验:大量问答对自动生成,没有经过人工审核,存在"图像中明明只有10辆车,答案却写300辆"的离谱情况。
二、方法创新:RSHR-Bench的三大核心突破
1. 超高清图像 corpus 构建
精选5329张全场景遥感图像,长边均≥4000像素,最高达3亿像素(300MP),涵盖卫星影像、无人机航拍等真实数据源,完整保留原生分辨率和场景上下文。
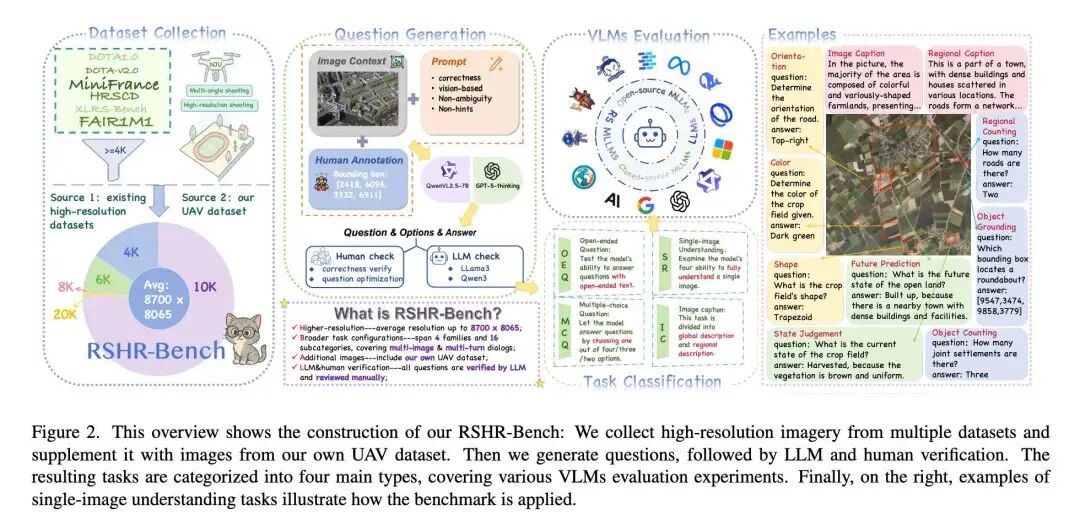
2. 多元任务体系设计
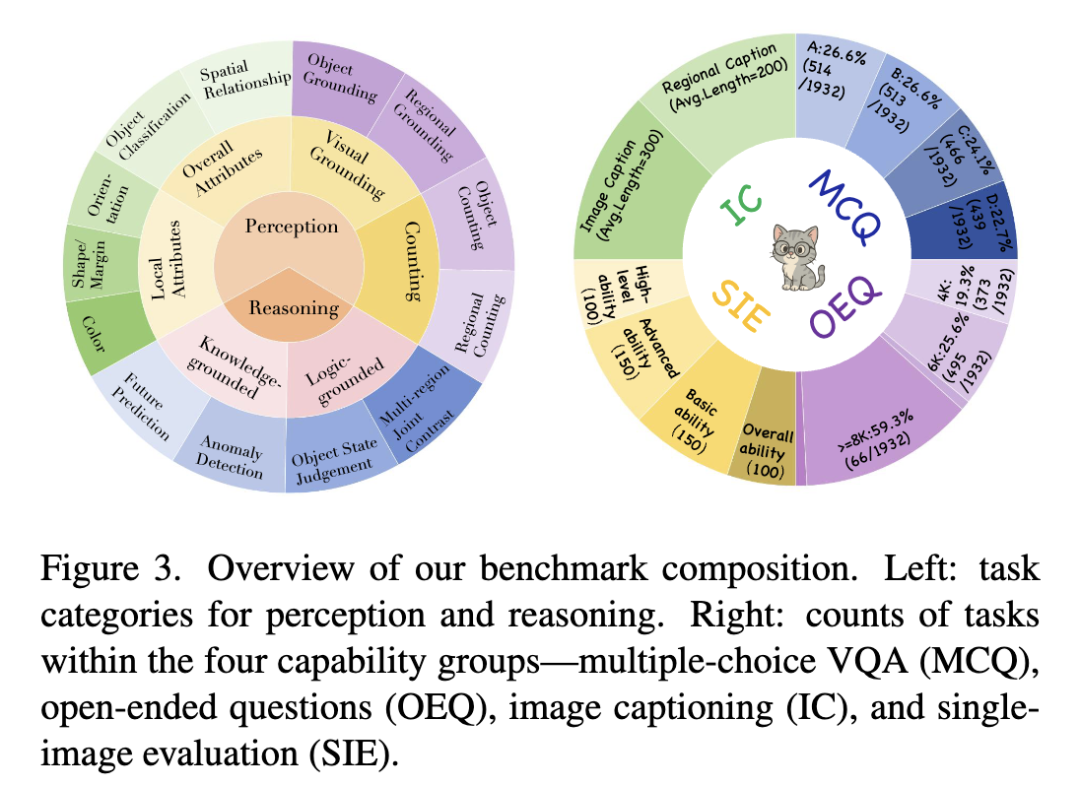
包含四大任务家族,覆盖9类感知任务(颜色识别、形状判断、计数等)和4类推理任务(异常检测、未来预测等),支持多轮对话和多图对比,完美贴合实际应用场景:
-
选择题问答:固定选项测试决策能力
-
开放式问答:无选项约束,考验自由表达与理解
-
图像描述:要求精准描述全局与区域细节
-
单图综合评估:每图配10个问题,全面考核感知与推理
3. 双阶段校验确保质量
先通过纯文本大模型进行"对抗性过滤",剔除无需图像就能解答的问题;再经6名专业标注员300小时人工审核,修正歧义、确保答案必须依赖视觉信息,最终形成高质量问答对超1.2万条。
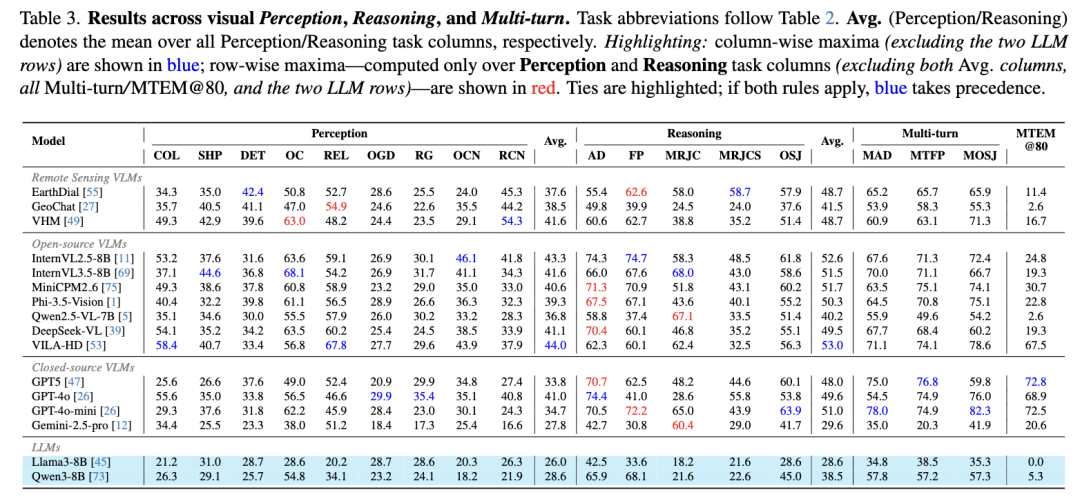
三、实验结果:现有模型集体"露短板"
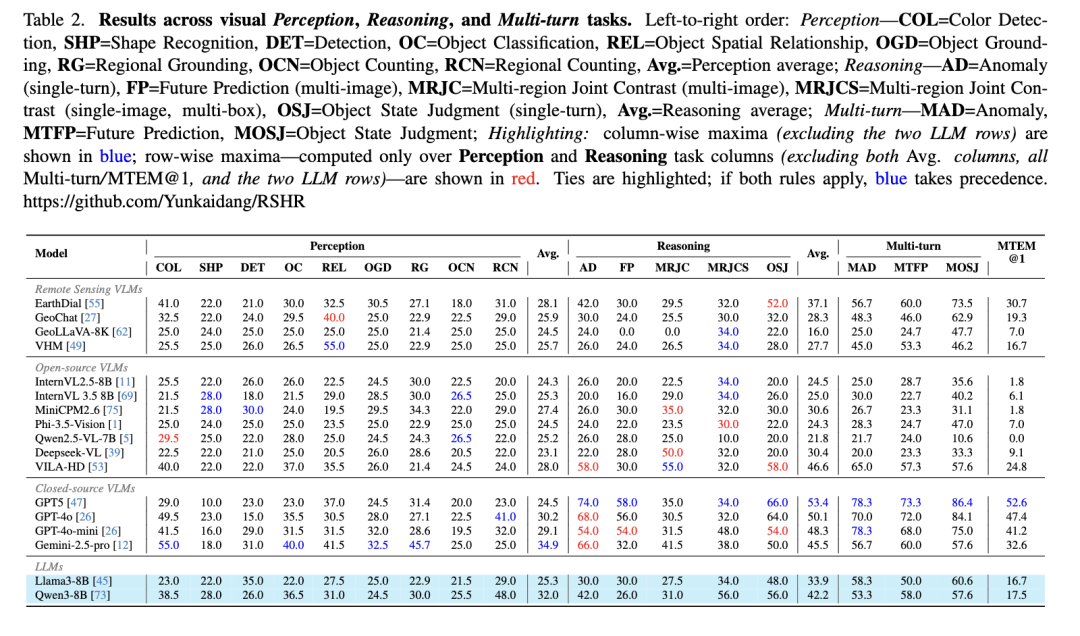
测试了14款主流模型(含通用大模型GPT-4o、遥感专用模型GeoLLaVA-8K等),结果令人意外:
-
整体表现拉胯:所有模型在四大任务中准确率普遍偏低,纯文本模型仍能靠常识答对30%以上推理题,凸显现有模型对超高清遥感场景的适配不足。
-
短板集中凸显:计数、小目标识别、多区域对比任务表现最差,超高清图像下模型检测召回率大幅下降。
-
闭源模型略胜一筹:GPT-5、GPT-4o等闭源模型在推理任务中准确率领先(最高74%),但与人类92.94%的准确率仍有巨大差距;开源模型平均准确率仅25%左右, compositional reasoning 能力严重不足。
四、优势与局限
核心优势
-
分辨率保真:首次实现亿级像素图像的标准化评测,贴合真实应用场景。
-
任务全面:覆盖从基础感知到复杂推理的全链路能力,支持多轮/多图交互。
-
质量可控:LLM+人工双校验,彻底摆脱语言先验干扰,评测结果更可信。
现存局限
-
数据来源仍有拓展空间:虽包含卫星、无人机数据,但特定场景(如极地、海洋)覆盖不足。
-
模型适配成本高:超高清图像对模型算力和输入处理能力要求极高,部分开源模型因显存限制无法充分测试。
-
暂无动态场景数据:缺乏时序变化的遥感图像,无法评估模型对场景演变的跟踪能力。
五、一句话总结
RSHR-Bench填补了超高清遥感多模态模型评测的空白,用严格的设计和真实的场景,揭示了当前大模型的能力短板,为后续技术突破提供了可靠的"风向标"。