文章目录
- 一:环境准备
-
- [1、安装 FFmpeg](#1、安装 FFmpeg)
- [2、安装 Python 库](#2、安装 Python 库)
- [二:编写与运行 Python 脚本](#二:编写与运行 Python 脚本)
-
- [1、创建一个新的 Python 文件,内容如下:](#1、创建一个新的 Python 文件,内容如下:)
- 2、设置参数
- 三:运行脚本
一:环境准备
1、安装 FFmpeg
-
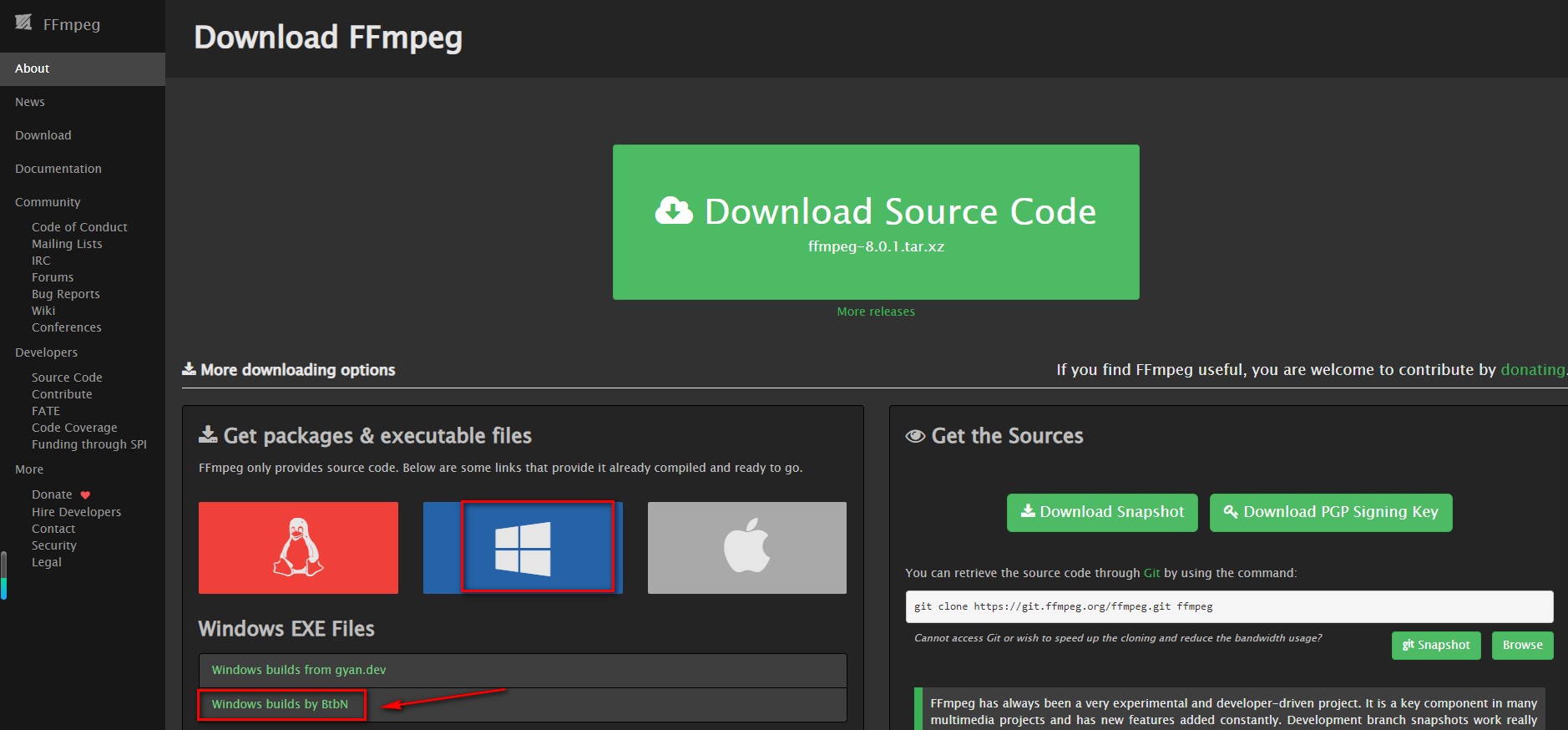
从 FFmpeg官网下载FFmpeg
-
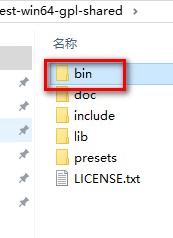
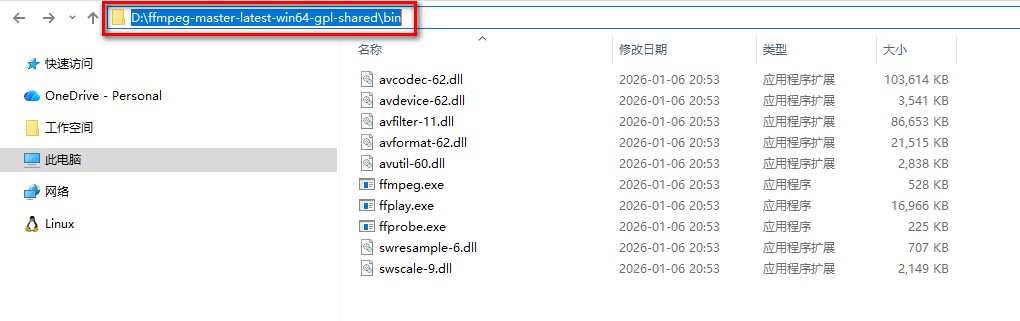
解压后将 bin 目录路径添加到系统环境变量 PATH 中,如下图所示
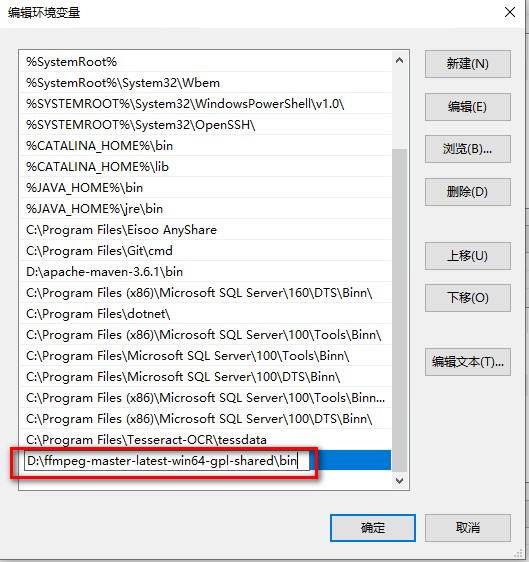
-
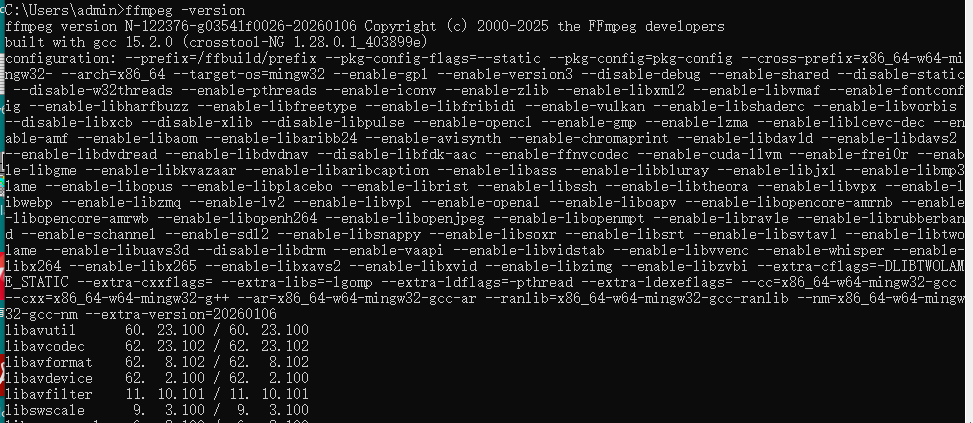
验证安装:在终端输入 ffmpeg -version,看到版本信息即成功。
ffmpeg -version
2、安装 Python 库
- 打开命令提示符安装开源语音识别模型openai-whisper。
- 打开命令提示符安装用于音频切割和格式处理的工具 pydub。
pip install openai-whisper pydub

二:编写与运行 Python 脚本
1、创建一个新的 Python 文件,内容如下:
import whisper
from pydub import AudioSegment
import json
import os
def split_mp3_by_sentences(input_mp3_path, output_dir="output_chunks", model_size="base"):
# 1. 准备输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 2. 加载 Whisper 模型并转写,获取带时间戳的文本
print(f"正在加载 Whisper '{model_size}' 模型...")
model = whisper.load_model(model_size)
print(f"正在转写音频: {input_mp3_path},请稍候...")
result = model.transcribe(input_mp3_path, word_timestamps=False, language="zh")
# 3. 从结果中提取句子和其时间戳
# Whisper 的 'segments' 就是句子/段落级的时间戳
segments = result['segments']
print(f"识别出 {len(segments)} 个句子/段落。")
# 4. 加载原始音频
audio = AudioSegment.from_mp3(input_mp3_path)
# 5. 根据时间戳切割并导出音频
for i, seg in enumerate(segments):
start_time = int(seg['start'] * 1000) # 转为毫秒
end_time = int(seg['end'] * 1000) # 转为毫秒
text = seg['text'].strip()
# 切割音频
chunk = audio[start_time:end_time]
# 创建文件名(清除文件名中的非法字符)
safe_text = "".join(c for c in text if c.isalnum() or c in (' ', '-', '_')).strip()
chunk_filename = f"sentence_{i+1:03d}_{safe_text[:30]}.mp3"
chunk_filepath = os.path.join(output_dir, chunk_filename)
# 导出音频片段
chunk.export(chunk_filepath, format="mp3")
print(f"已保存: {chunk_filename} (来自 {seg['start']:.2f}s - {seg['end']:.2f}s)")
print(f"\n所有分割完成!文件保存在目录: {output_dir}")
#你的MP3文件路
if __name__ == "__main__":
# 输入你的长 MP3 文件路径
your_audio_file = "123_test.mp3" # 请修改为你的文件路径
# 选择模型大小:对于中文,'base' 是速度和精度的良好平衡
model_to_use = "base"
# 输出文件夹名称
output_folder = "sentences_output"
# 运行函数
split_mp3_by_sentences(your_audio_file, output_folder, model_to_use)2、设置参数
- 将上述代码保存为一个py文件,如 mp3_cut.py

- 打开 mp3_cut.py文件,设置你的音频文件路径。如下图

三:运行脚本
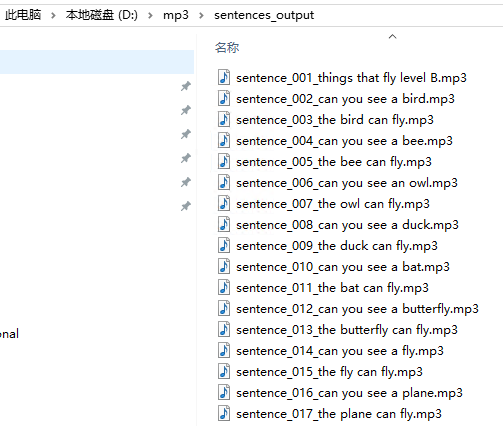
1、运行脚本,生成目标文件。
- 打开终端,运行mp3_cut.py
- 如果你是首次运行,会自动下载指定的 Whisper 模型,下图中的 base模型。

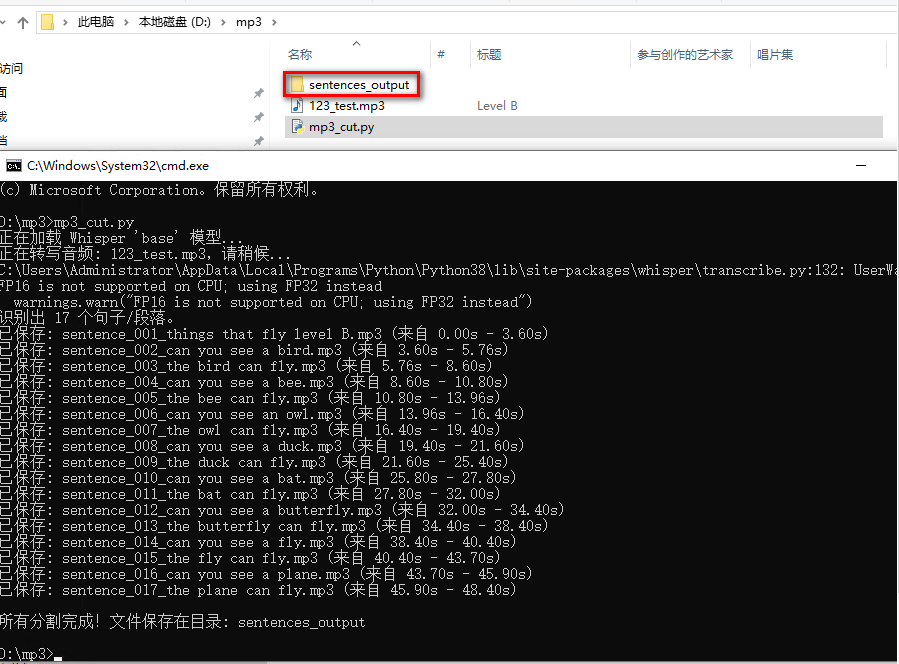
2、测试目标文件
- 完成后,你的目标文件会保存在脚本所在目录下的 sentences_output 文件夹中