openCHA: 个性化LLM驱动的对话健康代理框架
- 发明openCHA:让LLM成为真正的健康助手
- 核心演化路径总结
- 一、解法拆解:技术、问题与同类算法对比
- [1.1 核心问题定义](#1.1 核心问题定义)
- [1.2 与同类算法的主要区别](#1.2 与同类算法的主要区别)
- [1.3 总体解法公式化表达](#1.3 总体解法公式化表达)
- 二、子解法详细拆解
- [子解法1: Interface(接口层)](#子解法1: Interface(接口层))
- [子解法2: Task Planner(任务规划器)](#子解法2: Task Planner(任务规划器))
- [子解法3: Task Executor(任务执行器)](#子解法3: Task Executor(任务执行器))
- [子解法4: Data Pipe(数据管道)](#子解法4: Data Pipe(数据管道))
- [子解法5: Promptist(提示工程器)](#子解法5: Promptist(提示工程器))
- [子解法6: Response Generator(响应生成器)](#子解法6: Response Generator(响应生成器))
- [子解法7: External Sources(外部资源)](#子解法7: External Sources(外部资源))
- 三、子解法逻辑链:决策树形式
- 四、隐性方法分析
- [4.1 隐性方法1: 双阶段Prompt生成](#4.1 隐性方法1: 双阶段Prompt生成)
- [4.2 隐性方法2: Data Pipe键引用传递](#4.2 隐性方法2: Data Pipe键引用传递)
- [4.3 隐性方法3: Thinker信息隔离](#4.3 隐性方法3: Thinker信息隔离)
- 五、隐性特征分析
- [5.1 隐性特征1: 任务间数据格式异构性](#5.1 隐性特征1: 任务间数据格式异构性)
- [5.2 隐性特征2: LLM的Token边界约束](#5.2 隐性特征2: LLM的Token边界约束)
- [5.3 隐性特征3: 策略选择的不确定性](#5.3 隐性特征3: 策略选择的不确定性)
- 六、方法潜在局限性
- [6.1 规划鲁棒性](#6.1 规划鲁棒性)
- [6.2 延迟问题](#6.2 延迟问题)
- [6.3 Token限制](#6.3 Token限制)
- [6.4 隐私与安全](#6.4 隐私与安全)
- [6.5 评估困难](#6.5 评估困难)
- [七、多题一解 / 一题多解](#七、多题一解 / 一题多解)
- [7.1 多题一解:Agent框架通用模式](#7.1 多题一解:Agent框架通用模式)
- [7.2 一题多解:不同规划策略](#7.2 一题多解:不同规划策略)
- 八、暴露决策过程:尝试过但放弃的方案
- [8.1 规划方法选择](#8.1 规划方法选择)
- [8.2 数据传递方式](#8.2 数据传递方式)
- [8.3 Response Generator独立性](#8.3 Response Generator独立性)
- [8.4 多语言处理](#8.4 多语言处理)
- 九、隐蔽知识
- [9.1 新手注意不到的规律和模式](#9.1 新手注意不到的规律和模式)
- [9.2 新手无法觉察到的微小区别](#9.2 新手无法觉察到的微小区别)
- [9.3 对意外的敏感](#9.3 对意外的敏感)
- 十、总结
论文:Conversational Health Agents: A Personalized LLM-Powered Agent Framework
代码:https://github.com/Institute4FutureHealth/CHA
发明openCHA:让LLM成为真正的健康助手
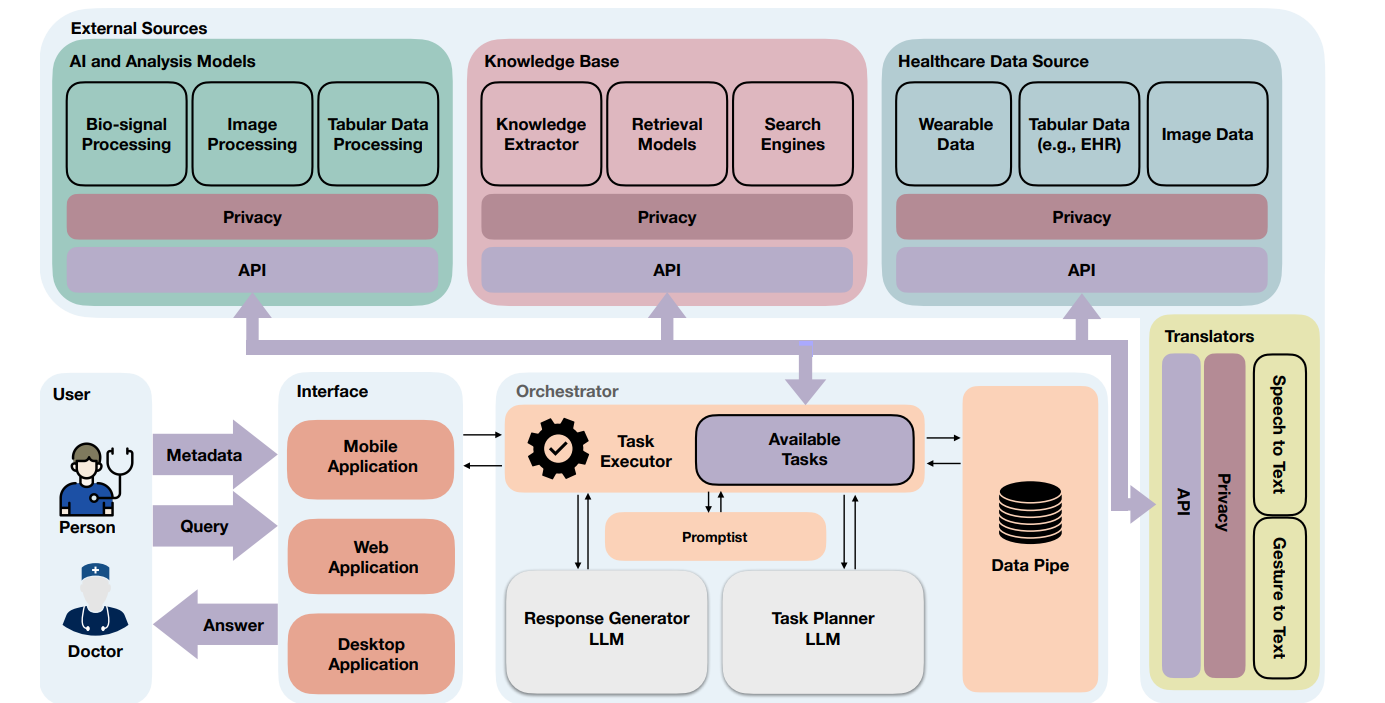
如果把大语言模型接入聊天界面,用户输入问题,模型吐出答案
看起来像个医生,实际上是个复读机
它只会背书本,不认识你,也不知道你今天血压多少
为了让它获取最新医学知识,你接入Google搜索API
用户问"如何改善睡眠",模型先搜网页,再提取内容,最后生成回答
可问题又来了,它搜到的是大众建议,不是针对你的
于是,你打通健康数据接口------可穿戴设备、电子病历、mHealth平台
用户说"分析我8月的睡眠",系统调用sleep_get获取你的真实数据
可问题又来了,原始数据是一串数字,LLM看不懂PPG信号
于是,你接入AI分析模型------信号处理、HRV分析、压力估计
数据进来,模型处理,结果出去
可问题又来了,一个复杂问题要调好几个工具,谁来决定调哪个、按什么顺序?
于是,你设计Task Planner,让LLM自己规划
采用Tree of Thought:先生成三个策略,列出优缺点,选最优的执行
用户问"我的压力水平",Planner规划:ppg_get → ppg_analysis → stress_analysis
可问题又来了,PPG原始数据几千个采样点,塞进Prompt直接爆Token
于是,你设计Data Pipe,大数据存仓库,只传键名
ppg_get执行完,返回datapipe:0f1a...,下一个任务拿着键去仓库取数据
LLM只看键,不碰数据,Token安全
可问题又来了,规划和执行混在一起,LLM又要逻辑严谨又要共情表达,顾此失彼
于是,你把Orchestrator拆成两块
Task Planner专注规划,冷静理性
Response Generator专注表达,温暖共情
Planner收集信息,Generator组织语言,各司其职
可问题又来了,用户用西班牙语提问怎么办?传张图片怎么办?
于是,你在入口设置Interface层
语音转文字,手势转文字,西班牙语转英语
多模态输入统一成Query + Metadata,送进Orchestrator
回复时再翻译回去
可问题又来了,怎么告诉Planner有哪些工具可用、每个工具要什么输入?
于是,你定义Task规范
python
name = "stress_analysis" # 内部标识
description = "基于HRV估计压力" # 帮Planner决策
inputs = ["HRV特征数据"] # 输入说明
outputs = ["1-5级压力值"] # 输出说明
output_type = False # False直接返回,True存Data PipePlanner读规范,自动匹配工具,自动填参数
可问题又来了,万一Planner规划错了怎么办?
于是,你设计双向通信
Task Executor执行完一个任务,把结果返回给Planner
Planner看结果,决定下一步------继续执行、换策略、还是结束
迭代循环,直到信息收集完毕
可问题又来了,用户想知道系统用了哪些工具,怎么解释?
于是,你保留"previous_actions"记录
用户问"用了什么任务",系统列出:ppg_get → ppg_analysis → stress_analysis
透明可解释,用户放心
恭喜你,发明了openCHA
openCHA支持多模态输入、多语言对话、实时个人数据访问、最新知识检索、AI模型调用、多步推理规划
在糖尿病饮食推荐测试中,准确率92%,超过单独ChatGPT
在心理健康聊天机器人评估中,MAE比GPT-4低1个等级
这不仅是一个聊天机器人,更是一个能访问你的数据、调用专业工具、规划复杂任务的个人健康Agent
核心演化路径总结
核心问题: LLM只会背书,不认识用户,不会调工具,无法多步推理
核心解法: Orchestrator架构------Task Planner(ToT规划) + Task Executor(双向通信) + Data Pipe(键引用) + Response Generator(共情表达)
技术支撑:
- Tree of Thought三策略决策
- Data Pipe键引用解决Token限制
- Task规范化定义实现工具自动匹配
最终成果 : 糖尿病推荐准确率92% ,心理评估MAE比GPT-4低1级 ,支持多模态+多语言
本质升华: 从"背书的复读机"变成"能看你数据、调专业工具、做多步规划的私人健康顾问"
一、解法拆解:技术、问题与同类算法对比
1.1 核心问题定义
问题本质: 现有LLM-based CHAs(对话健康代理)仅聚焦对话层面,缺乏真正的Agent能力
四大核心痛点:
| 痛点 | 具体表现 | 导致后果 |
|---|---|---|
| 个性化不足 | 无法实时访问用户纵向健康数据(EHR、可穿戴设备) | 只能给出通用回复 |
| 知识过时 | 依赖训练时数据,无法获取最新医学文献 | 回复可能已过时 |
| 工具集成缺失 | 无法调用外部AI分析模型(信号处理、图像分析) | 多模态分析能力弱 |
| 多步推理缺乏 | 无法分解复杂查询为任务序列 | 只能处理简单问答 |
1.2 与同类算法的主要区别
c
┌─────────────────────────────────────────────────────────────────┐
│ 方法对比矩阵 │
├──────────────┬────────────┬─────────────┬──────────────────────┤
│ 维度 │ ChatGPT类 │ 专用医疗LLM │ openCHA (本文) │
├──────────────┼────────────┼─────────────┼──────────────────────┤
│ 个性化数据 │ ✗ 无法访问 │ ✗ 训练时固定 │ ✓ 实时API访问 │
│ 知识更新 │ △ 联网搜索 │ ✗ 静态 │ ✓ 知识库+检索模型 │
│ 外部工具调用 │ ✗ 无 │ ✗ 无 │ ✓ AI/分析模型集成 │
│ 多步推理 │ △ 有限 │ ✗ 单任务 │ ✓ Task Planner编排 │
│ 多模态支持 │ △ 基础 │ △ 特定模态 │ ✓ 完整多模态管道 │
│ 多语言支持 │ ✓ 内置 │ △ 有限 │ ✓ 翻译器集成 │
└──────────────┴────────────┴─────────────┴──────────────────────┘1.3 总体解法公式化表达
openCHA框架 = Interface子解法 + Orchestrator子解法 + External Sources子解法
其中:
- Orchestrator = Task Planner + Task Executor + Data Pipe + Promptist + Response Generator
形式化表示:
c
Response = ResponseGenerator(
TaskExecutor(
TaskPlanner(Query, Metadata, History, AvailableTasks),
ExternalSources
),
Context
)二、子解法详细拆解
子解法1: Interface(接口层)
为什么需要?
- 特征: 用户输入多样化(文本、语音、图像、手势)
- 不处理后果: 系统只能处理单一文本输入,排斥非文字用户群体
具体怎么做?
c
用户输入 → [多模态接收器] → [Translator转换] → 标准化Query + Metadata
↓ ↓
文本/语音/图像 Speech-to-Text
Gesture-to-Text关键技术:
- 翻译器集成(Google Translate API)
- 语音转文字模块
- 元数据解析器
预期效果
- 支持移动/桌面/Web多平台
- 支持非英语用户
- 支持图像等多模态输入
可能风险
- 翻译误差传递到后续环节
- 语音识别在嘈杂环境下失准
- 元数据解析可能遗漏关键信息
之所以用Interface子解法,是因为"用户输入多样化"这一特征。
举例: 用户用西班牙语语音询问"我的压力水平",Interface将其转为英文文本Query,并标记原始语言以便最终响应翻译回去。
子解法2: Task Planner(任务规划器)
为什么需要?
- 特征: 健康查询往往需要多步骤信息收集和推理
- 不处理后果: 系统无法将复杂问题分解,只能给出浅层回答
具体怎么做?
方案选项1: ReAct Prompting
- 做法: 交替进行Reasoning(推理)和Acting(行动)
- 优点: 灵活,可中途调整
- 缺点: 可能陷入循环
方案选项2: Tree of Thought (ToT) Prompting 本文选择
- 做法:
- 生成3个独立策略(任务序列)
- 列出各策略优缺点
- 选择最优策略执行
- 优点: 策略比较更全面,决策质量高
- 缺点: 计算开销较大(需评估多策略)
最终选择: Tree of Thought
选择理由: 医疗场景错误代价高,需要更审慎的决策过程
实施要点
python
# Tree of Thought 两阶段实现
# 阶段1: 策略生成与选择
prompt_stage1 = """
给定工具列表、元数据、历史记录、用户查询
1. 提出3个策略(任务序列)
2. 分析各策略优缺点
3. 选择最佳策略,以'Decision:'开头
"""
# 阶段2: 转换为可执行代码
prompt_stage2 = """
基于选定策略,生成Python代码
使用 self.execute_task('tool_name', [inputs]) 调用工具
"""关键动作
- 解析用户Query意图
- 匹配可用Task集合
- 生成策略树
- 评估策略优劣
- 输出执行计划
成功标准
- 生成的任务序列逻辑正确
- 任务间依赖关系正确处理
- 选择的策略能获取所需信息
风险预案
- 策略生成失败 → 回退到ReAct模式
- 任务不存在 → 提示用户该功能不可用
之所以用Task Planner子解法,是因为"复杂查询需要多步骤分解"这一特征。
举例: 用户问"Patient 5在2020年8月的压力水平"
- 策略1: ppg_get → ppg_analysis → stress_analysis
- 策略2: 直接搜索互联网(不够个性化)
- 策略3: 先获取活动数据再分析(数据类型不匹配)
- 选择策略1
子解法3: Task Executor(任务执行器)
为什么需要?
- 特征: 规划与执行需要解耦,且执行结果需反馈给规划器
- 不处理后果: 规划无法落地,或执行结果无法影响后续规划
具体怎么做?
双向通信机制:
c
Task Planner ←→ Task Executor ←→ External Sources
↑ │
└──────────────┘ (中间结果反馈)两大职责:
- 数据转换器: 将输入Query/Metadata转换为Task可用格式
- 任务执行器: 通过API调用External Sources并返回结果
实施要点
python
def execute_task(self, task_name: str, inputs: List[Any]) -> Any:
# 1. 查找Task定义
task = self.available_tasks[task_name]
# 2. 验证输入
validated_inputs = self.validate_inputs(task, inputs)
# 3. 处理Data Pipe引用
resolved_inputs = self.resolve_datapipe_keys(validated_inputs)
# 4. 执行Task
result = task._execute(resolved_inputs)
# 5. 根据output_type决定存储方式
if task.output_type: # True = 存入Data Pipe
key = self.data_pipe.store(result)
return key
else:
return result成功标准
- 任务执行成功率 > 95%
- 中间结果正确传递
- 错误能被捕获并报告
之所以用Task Executor子解法,是因为"规划与执行需要解耦"这一特征。
举例: Executor执行ppg_get后返回Data Pipe key,Planner用此key作为ppg_analysis的输入参数。
子解法4: Data Pipe(数据管道)
为什么需要?
- 特征: 多模态分析涉及中间数据,这些数据可能很大或不适合直接传给LLM
- 不处理后果: Token限制超出,或LLM无法理解原始信号数据
具体怎么做?
c
┌────────────────────────────────────────────────┐
│ Data Pipe │
├────────────────────────────────────────────────┤
│ Key: datapipe:0f1a864c-... │
│ Value: [PPG信号数组,32维HRV特征,...] │
├────────────────────────────────────────────────┤
│ Key: datapipe:122e7f94-... │
│ Value: [HRV分析结果,RMSSD=45.2, LF=...] │
└────────────────────────────────────────────────┘设计决策:
- 简单场景: 内存键值存储
- 复杂场景: 数据库系统
实施要点
- 自动生成唯一键
- 键传递给Task Planner用于后续引用
- 支持不同数据类型(数组、JSON、二进制)
之所以用Data Pipe子解法,是因为"中间数据可能很大且LLM难以直接处理"这一特征。
举例 : PPG原始数据有数千个采样点,存入Data Pipe后只传递键名
datapipe:xxx给LLM,避免Token爆炸。
子解法5: Promptist(提示工程器)
为什么需要?
- 特征: 不同LLM、不同任务需要不同的提示格式
- 不处理后果: 提示质量低下,LLM输出不稳定
具体怎么做?
可集成的提示技术:
| 技术 | 适用场景 | 核心思想 |
|---|---|---|
| LLM-REC | 个性化推荐 | 丰富文本描述以增强推荐 |
| Prompt Adaptation | 多模态生成 | 强化学习优化提示 |
| OpenAI最佳实践 | 通用场景 | 清晰指令编写原则 |
实施要点
- 提供prefix配置接口
- 支持动态提示组装
- 允许开发者自定义提示模板
之所以用Promptist子解法,是因为"不同任务需要不同提示格式"这一特征。
子解法6: Response Generator(响应生成器)
为什么需要?
- 特征: 规划器专注于任务调度,需要独立模块处理用户交互的共情与表达
- 不处理后果: 回复生硬,缺乏医疗对话应有的同理心
具体怎么做?
与Task Planner分离的设计理由:
c
Task Planner: 专注规划 → 不回复用户
Response Generator: 专注表达 → 处理共情、陪伴感Mega Prompt构建:
c
===========Thinker: {Task执行结果汇总}
===========
System: 你是有同理心的健康助手...
- 基于Thinker信息回答
- 不要使用内部知识
- 不要暴露datapipe键
User: {原始查询}关键约束
- 只用Thinker信息: 确保回复基于可验证数据
- 保留URL原样: 不修改外部引用
- 隐藏系统细节: 不暴露datapipe键等内部实现
之所以用Response Generator子解法,是因为"医疗对话需要共情与规划解耦"这一特征。
子解法7: External Sources(外部资源)
为什么需要?
- 特征: LLM单独无法完成:实时数据访问、专业计算、最新知识检索
- 不处理后果: 系统能力被限制在LLM训练数据范围内
具体怎么做?
四类外部资源:
c
┌─────────────────────────────────────────────────────────────┐
│ External Sources │
├──────────────────┬──────────────────┬───────────────────────┤
│ Healthcare Data │ Knowledge Base │ AI & Analysis Models │
│ Source │ │ │
├──────────────────┼──────────────────┼───────────────────────┤
│ • 可穿戴设备数据 │ • Google Search │ • PPG信号处理 │
│ • EHR电子病历 │ • 医学文献检索 │ • HRV分析 │
│ • mHealth平台 │ • 知识图谱 │ • 压力估计模型 │
│ (ZotCare等) │ │ • 图像处理 │
├──────────────────┴──────────────────┴───────────────────────┤
│ Translators │
│ • Google Translate (多语言支持) │
└─────────────────────────────────────────────────────────────┘Task定义规范
python
class GoogleSearch(BaseTask):
name = "google_search" # 系统内部标识
chat_name = "GoogleSearch" # 用户可见名称
description = "搜索互联网..." # 帮助Planner决策
dependencies = [] # 依赖的其他Task
inputs = ["搜索查询字符串"] # 输入说明
outputs = ["返回url的JSON对象"] # 输出说明
output_type = False # False=直接返回,True=存Data Pipe
def _execute(self, inputs):
query = inputs[0]
return {"url": search(query)[0]}之所以用External Sources子解法,是因为"LLM能力边界需要外部扩展"这一特征。
三、子解法逻辑链:决策树形式
c
[用户查询]
│
▼
┌───────────────┐
│ Interface │
│ (多模态接收) │
└───────┬───────┘
│
┌───────────────┼───────────────┐
▼ ▼ ▼
[非英语?] [有元数据?] [标准文本]
│ │ │
▼ ▼ │
Translator Metadata解析 │
│ │ │
└───────────────┴───────────────┘
│
▼
┌───────────────┐
│ Task Planner │
│ (ToT规划) │
└───────┬───────┘
│
┌───────────────┴───────────────┐
│ 生成3个策略 │
│ 评估优缺点 │
│ 选择最优策略 │
└───────────────┬───────────────┘
│
▼
┌───────────────┐
│ Task Executor │
└───────┬───────┘
│
┌───────────────────┼───────────────────┐
▼ ▼ ▼
[Healthcare Data] [Knowledge Base] [AI Models]
(获取PPG等) (搜索文献) (分析处理)
│ │ │
└─────────┬─────────┴─────────┬─────────┘
│ │
▼ ▼
[小数据?] [大数据?]
│ │
▼ ▼
直接返回LLM 存入Data Pipe
│ │
└─────────┬─────────┘
│
┌─────────┴─────────┐
│ 需要更多信息? │
└─────────┬─────────┘
Yes↓ ↓No
返回Task Planner │
│
▼
┌───────────────┐
│ Promptist │
│ (构建Mega │
│ Prompt) │
└───────┬───────┘
│
▼
┌───────────────┐
│ Response │
│ Generator │
└───────┬───────┘
│
▼
[最终回复]逻辑结构 : 这是一个带循环的有向图(不是纯链条也不是纯树)
- Task Planner与Task Executor形成迭代循环
- 多个External Sources可并行调用
- Data Pipe提供跨步骤的数据共享
四、隐性方法分析
4.1 隐性方法1: 双阶段Prompt生成
课本方法: 单个Prompt完成规划
本文隐性方法: 两阶段Prompt分离
c
阶段1: 策略生成Prompt → 输出: 自然语言决策
阶段2: 代码生成Prompt → 输出: Python可执行代码为什么隐性:
- 论文未将此命名为独立方法
- 分散在Appendix 2中描述
- 实际上是确保LLM输出可执行的关键技巧
关键步骤定义 : "策略-代码分离生成法"
- 第一阶段让LLM专注于逻辑推理
- 第二阶段让LLM专注于格式化输出
- 避免单个Prompt中逻辑与格式混杂导致的错误
4.2 隐性方法2: Data Pipe键引用传递
课本方法: 直接传递数据
本文隐性方法: 键引用机制
python
# 表面上看是简单的变量传递
ppg_result = execute_task('ppg_get', [...])
hrv_result = execute_task('ppg_analysis', [ppg_result])
# 实际ppg_result是键,不是数据
# execute_task内部解析键,获取真实数据为什么隐性:
- 论文仅在代码示例中体现
- 未作为独立概念强调
- 实际上解决了LLM Token限制的关键问题
关键步骤定义 : "键引用解耦法"
- LLM操作的是轻量级键
- 系统自动解析键获取重量级数据
- 实现了LLM与大数据的解耦
4.3 隐性方法3: Thinker信息隔离
课本方法: LLM直接用内部知识回答
本文隐性方法: 强制Response Generator只用Thinker信息
c
"Consider Thinker as your trusted source"
"Never answer outside of the Thinker's provided information"为什么隐性:
- 论文仅在Prompt示例中体现
- 实际上是防止LLM幻觉的关键约束
关键步骤定义 : "信息来源隔离法"
- 通过Prompt约束切断LLM内部知识
- 强制回复基于可验证的外部数据
- 提高医疗场景的可信度
五、隐性特征分析
5.1 隐性特征1: 任务间数据格式异构性
表面问题: 需要调用多个Task
隐性特征: 不同Task的输入输出格式不一致
- ppg_get 输出: 时间序列数组
- ppg_analysis 输入: 需要特定格式的PPG数据
- stress_analysis 输入: 需要HRV特征向量
对应解法: Task定义规范中的inputs/outputs字段 + Data Pipe的格式无关存储
5.2 隐性特征2: LLM的Token边界约束
表面问题: 需要处理大量健康数据
隐性特征: LLM有严格的Token限制,无法直接处理原始信号
对应解法: output_type配置 + Data Pipe存储机制
5.3 隐性特征3: 策略选择的不确定性
表面问题: 需要规划任务序列
隐性特征: 对于同一查询,可能有多个"看起来合理"的策略
对应解法: Tree of Thought的三策略生成 + 优缺点分析 + 显式选择
六、方法潜在局限性
6.1 规划鲁棒性
| 局限 | 具体表现 | 影响程度 |
|---|---|---|
| LLM幻觉 | Task Planner可能生成不存在的Task名 | 高 |
| 策略循环 | 复杂查询可能导致无限规划循环 | 中 |
| 依赖错误 | 任务依赖链断裂时缺乏恢复机制 | 中 |
6.2 延迟问题
c
单次查询延迟 = Interface处理 + ToT规划(3策略) + N次Task执行 + Response生成
↑ ↑ ↑
~100ms ~2-5秒 取决于External Source问题: 外部源越多,延迟越高,用户体验下降
6.3 Token限制
- Task数量增加 → Task Planner Prompt变长 → 可能超出Token限制
- 虽然Data Pipe解决了数据传递问题,但Task描述本身仍占用Token
6.4 隐私与安全
- 用户健康数据通过API传输
- 需要外部源提供数据保密机制
- 论文仅提及"应该"做,未给出具体实现
6.5 评估困难
- 缺乏标准化的CHA评估基准
- 准确性依赖外部源质量,难以独立评估框架本身
七、多题一解 / 一题多解
7.1 多题一解:Agent框架通用模式
共用特征: 需要LLM调用外部工具完成复杂任务
通用解法名称 : LLM-Powered Agent Orchestration
适用题目类型:
- 需要实时数据访问的对话系统
- 需要多步骤推理的问答系统
- 需要调用专业工具的辅助系统
核心模式:
c
Query → Planner(LLM) → Executor → External Tools → Response Generator(LLM)其他应用此模式的系统:
- LangChain Agent
- AutoGPT
- HuggingGPT
7.2 一题多解:不同规划策略
同一问题: 如何让LLM有效调度多个Task?
| 解法 | 对应特征 | 优势 | 劣势 |
|---|---|---|---|
| ReAct | 需要灵活调整 | 适应性强 | 可能陷入循环 |
| Tree of Thought | 需要审慎决策 | 决策质量高 | 计算开销大 |
| Plan-and-Solve | 需要一次性规划 | 效率高 | 难以处理意外 |
| 直接Function Calling | 任务简单 | 最快 | 无法处理复杂依赖 |
八、暴露决策过程:尝试过但放弃的方案
8.1 规划方法选择
尝试过 : ReAct
放弃原因 : 医疗场景需要更审慎的决策,ReAct的即时决策可能遗漏重要考量
最终选择: Tree of Thought
8.2 数据传递方式
尝试过 : 直接在Prompt中传递所有数据
放弃原因 : Token限制
最终选择: Data Pipe + 键引用
8.3 Response Generator独立性
尝试过 : 让Task Planner同时负责规划和回复
放弃原因:
- 规划需要逻辑严谨
- 回复需要共情表达
- 两者风格冲突
最终选择: 分离Task Planner和Response Generator
8.4 多语言处理
方案1 : 让LLM直接处理非英语(保留源语言)
方案2 : 翻译为英语 → 处理 → 翻译回源语言
选择 : 两者都支持,但推荐方案2
原因: LLM在英语上的规划能力最强
九、隐蔽知识
9.1 新手注意不到的规律和模式
规律1: Task描述的质量决定规划质量
c
差的描述: "搜索互联网"
好的描述: "使用Google搜索互联网并返回顶部网站的URL。
这个工具的优先级较低,应该先尝试使用患者数据任务。"新手可能只写功能,忽略优先级和使用条件的描述
规律2: output_type的选择逻辑
c
output_type = True → 数据大,或需要被其他Task使用
output_type = False → 数据小,可直接给LLM理解新手可能随意设置,导致Token溢出或数据丢失
规律3: 双向通信的必要性
c
Task Planner → Task Executor → External Source
↑ │
└──────────(中间结果)──────────┘新手可能设计成单向流程,无法处理需要多轮交互的场景
9.2 新手无法觉察到的微小区别
区别1 : name vs chat_name
name: 系统内部用,小写下划线chat_name: 用户可见,驼峰命名- 微小但重要: 用户询问"用了哪些任务"时,显示的是chat_name
区别2: Task Planner的Prompt vs Response Generator的Prompt
- Task Planner: 强调逻辑、步骤、约束
- Response Generator: 强调共情、表达、用户友好
- 微小但重要: 用错Prompt风格会导致规划混乱或回复生硬
区别3: 策略"生成"与策略"选择"的分离
- 阶段1: 只生成策略,不执行
- 阶段2: 将选定策略转为代码
- 微小但重要: 合并会导致LLM同时考虑太多事情,输出质量下降
9.3 对意外的敏感
意外1: Task执行失败
- 敏感设计: Task Executor捕获异常,返回错误信息给Task Planner
- Planner行为: 可以选择重试、换策略、或告知用户
意外2: External Source返回空结果
- 敏感设计: outputs字段明确说明可能的返回格式
- Planner行为: 根据空结果决定下一步(如换数据源)
意外3: 用户查询超出系统能力
- 敏感设计: Task Planner在无合适Task时,生成"无法回答"的响应
- 而非: 强行用不匹配的Task凑答案
意外4: 多语言翻译歧义
- 敏感设计: 保留原始Query语言标记
- Response Generator: 最终回复时使用正确的目标语言
十、总结
核心创新点
- Orchestrator架构: 将LLM的能力边界通过External Sources扩展
- Tree of Thought规划: 在医疗场景提供更审慎的决策
- Task-Data Pipe机制: 解决LLM Token限制与大数据处理的矛盾
- Planner-Generator分离: 实现逻辑规划与共情表达的解耦
方法论价值
- 提供了LLM-Agent系统的可扩展框架
- Task定义规范可复用于其他领域
- 双阶段Prompt设计可推广
实践指导
- 设计Task时:重视description的完整性
- 处理大数据时:善用Data Pipe
- 需要多步骤时:采用Tree of Thought
- 医疗对话时:分离规划与表达