大语言模型系统:【CMU 11-868】课程学习笔记02------GPU编程基础1(GPU Programming Basics 1))
- 前言
- [一、神经网络层和低级运算符(Neural Network Layer and low-level operators)](#一、神经网络层和低级运算符(Neural Network Layer and low-level operators))
-
- [1.1 典型神经网络层(A Simple Feedforward Neural Network)](#1.1 典型神经网络层(A Simple Feedforward Neural Network))
- [1.2 低级计算运算符(Low-level Computing Operators)](#1.2 低级计算运算符(Low-level Computing Operators))
- [二、GPU服务器的组件(Components of A GPU Server)](#二、GPU服务器的组件(Components of A GPU Server))
-
- [2.1 现代 GPU 服务器配置示例(A Modern Computing Server)](#2.1 现代 GPU 服务器配置示例(A Modern Computing Server))
- [2.2 服务器核心组件(Modern Computing Server Architecture)](#2.2 服务器核心组件(Modern Computing Server Architecture))
- [三、GPU架构(GPU Architecture)](#三、GPU架构(GPU Architecture))
- [四、GPU上的程序执行(Program Execution on GPU)](#四、GPU上的程序执行(Program Execution on GPU))
前言
【CMU 11-868】课程面向研究生开设,聚焦"从算法到工程"的大语言模型系统构建全过程。课程内容包括但不限于:
- GPU 编程与自动微分:掌握 CUDA kernel 调用、并行编程基础,以及深度学习框架设计原理
- 模型训练与分布式系统:学习高效的训练算法、通信优化(ZeRO、FlashAttention)、分布式训练框架(DDP、GPipe、Megatron-LM)。
- 模型压缩与加速:量化(GPTQ)、稀疏化(MoE)、编译技术(JAX、Triton)、以及推理时的服务化设计(vLLM、CacheGen)。
- 前沿技术与系统实践:涵盖检索增强生成(RAG)、多模态 LLM、RLHF 系统,以及端到端的在线维护和监控。
一、神经网络层和低级运算符(Neural Network Layer and low-level operators)
LLM 的核心计算单元是神经网络,其底层由特定层结构和基础算子构成,GPU 的高效计算能力正是通过优化这些底层操作实现性能提升。
1.1 典型神经网络层(A Simple Feedforward Neural Network)
以文本情感分类任务(判断电影评论为正面、负面或中性)为例,简单前馈神经网络包含以下核心层:

- 嵌入层(Embedding):将文本词汇映射为低维稠密向量(查找表机制);
- 线性层(Linear):实现向量的线性变换(核心是矩阵乘法);
- 激活层(ReLU):引入非线性,增强模型表达能力;
- 平均池化层(Average Pooling):对特征进行下采样,降低计算量;
- Softmax 层:将输出转换为概率分布,实现分类;
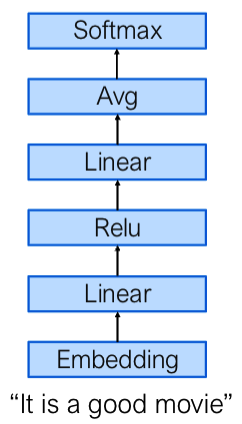
1.2 低级计算运算符(Low-level Computing Operators)
所有神经网络层的计算最终可拆解为四类基础算子,这些算子的并行效率直接决定模型性能:
- 矩阵乘法(最核心算子,占 LLM 计算量的 80% 以上)
- 元素级操作(add、scale、ReLU 等,逐元素独立计算)
- 归约操作(sum、avg 等,对向量 / 矩阵进行聚合计算)
- 查找操作(嵌入层核心,基于索引获取向量)
这些算子的高效执行高度依赖 GPU 的并行架构,CPU 在大规模并行计算场景下性能差距显著。
二、GPU服务器的组件(Components of A GPU Server)
2.1 现代 GPU 服务器配置示例(A Modern Computing Server)
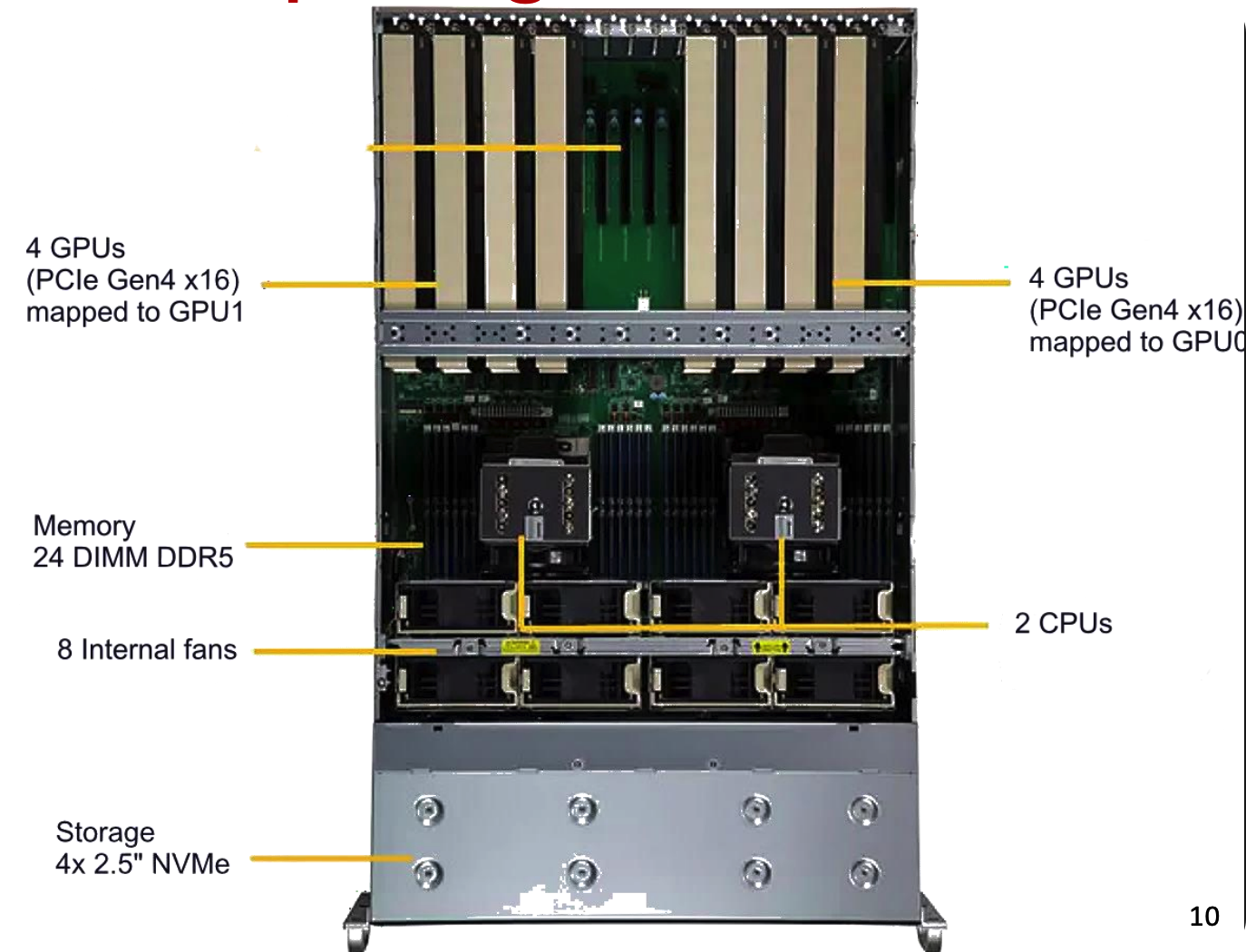
一台高性能 LLM 计算服务器的典型配置的核心参数如下:
- 处理器:2 颗 AMD EPYC 9354 CPU(多核架构,支撑主机端调度)
- 内存:16×64GB DDR5 内存(总计 1TB,满足模型参数临时存储)
- 存储:4 块 Intel D7 P5520 15.36TB Gen4 NVMe SSD(高速存储训练数据与模型文件)
- GPU:8 块 NVIDIA A6000(48GB 显存,单卡 10752 个核心,支持 38.7 TFLOPS 算力)
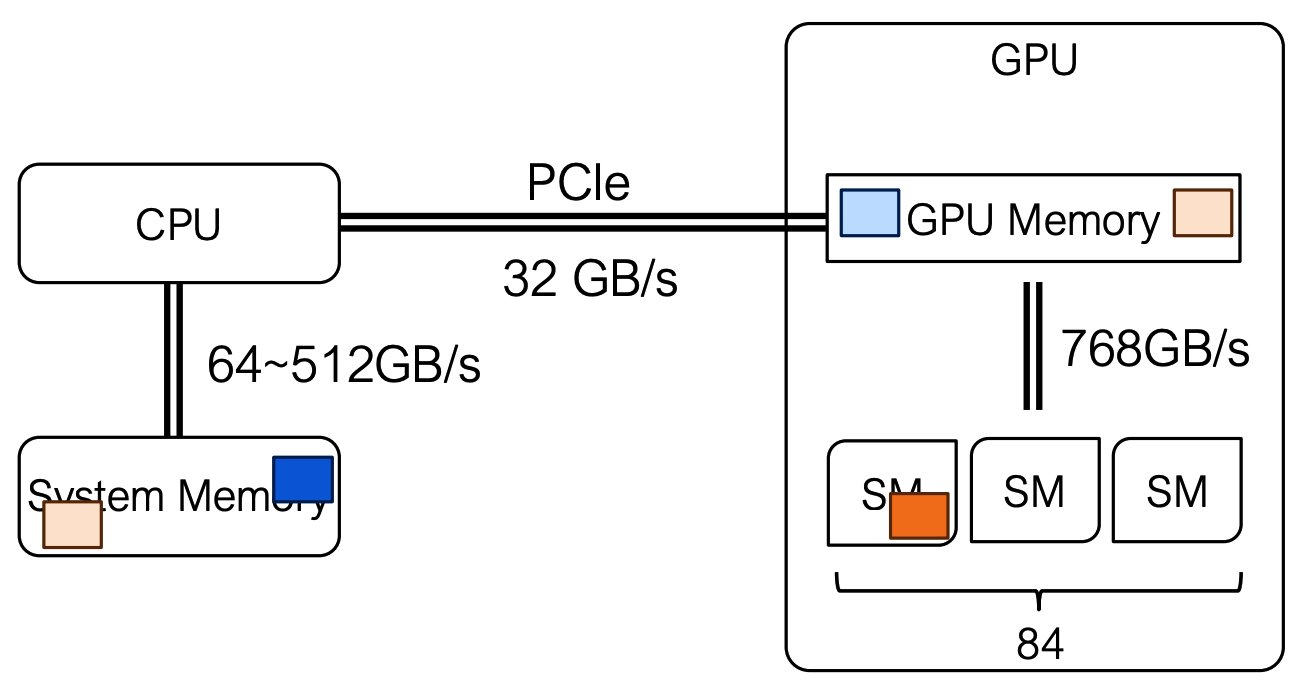
- 通信:4 条 2 槽 NVLink(GPU 间带宽 112.5 GB/s)+ PCIe Gen4(单路 32 GB/s)
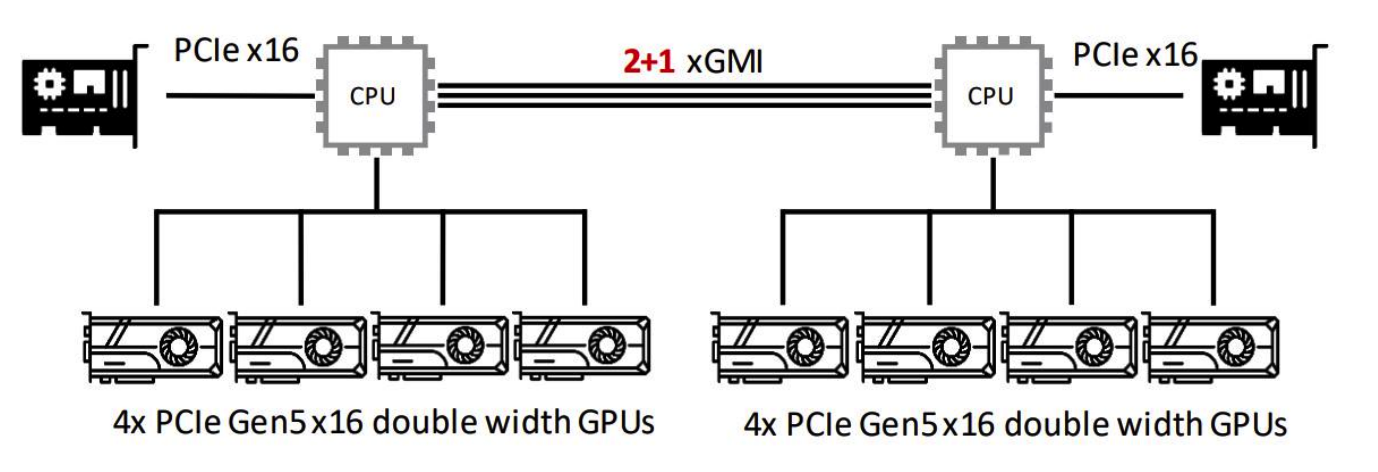
2.2 服务器核心组件(Modern Computing Server Architecture)
- CPU:负责主机端程序调度、数据预处理与 GPU 任务分发;
- 内存(DDR5):CPU 与 GPU 间数据传输的临时缓冲区;
- 存储(NVMe SSD):解决海量训练数据的高速读写需求,避免 I/O 瓶颈;
- GPU:核心计算单元,承担 99% 以上的神经网络计算任务;
- 通信链路(NVLink/PCIe):保障多 GPU 间梯度同步、参数传输的效率(梯度移动是多 GPU 训练的关键瓶颈);
计算设备(Computing Devices)

三、GPU架构(GPU Architecture)
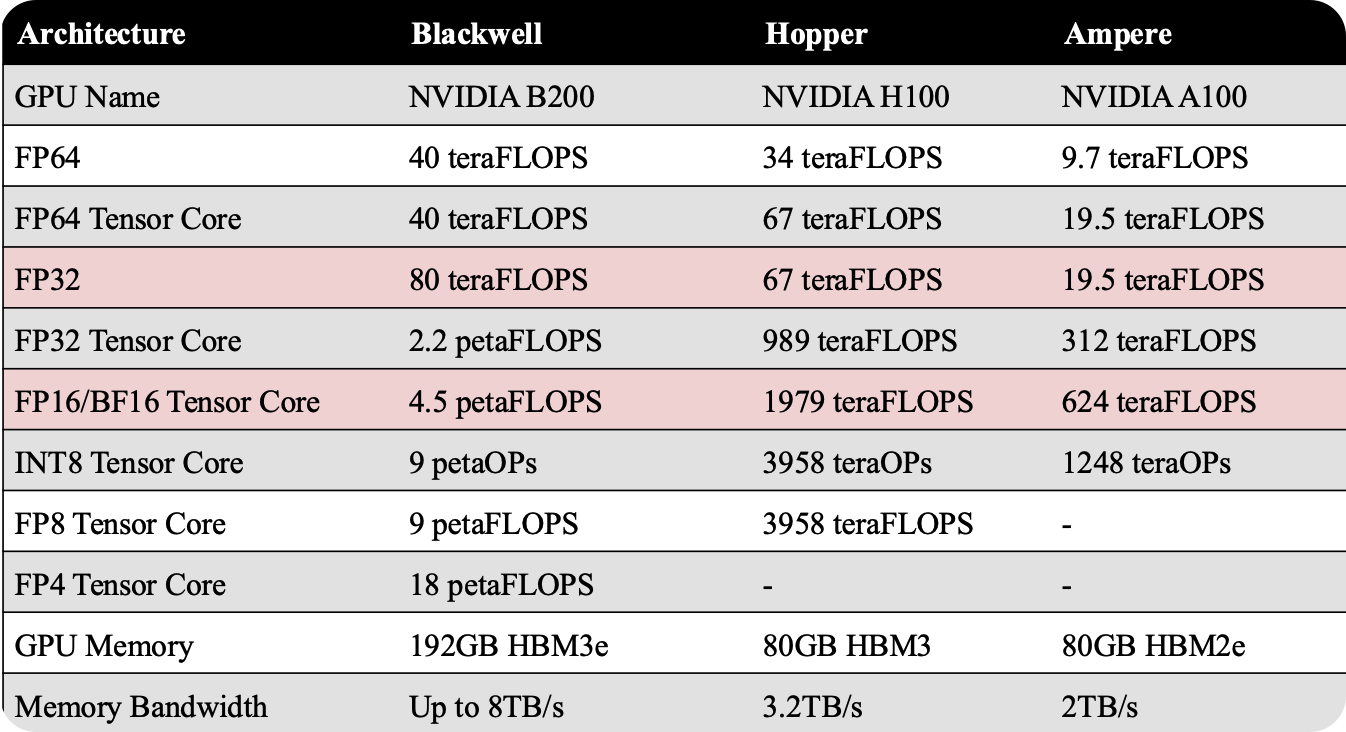
GPU 架构演进(GPU Lineup)
NVIDIA 的 GPU 架构持续迭代,从 Ampere 到 Hopper 再到最新的 Blackwell,性能与功能大幅提升,以下是三代架构的核心参数对比:
GPU架构(GPU Architecture)
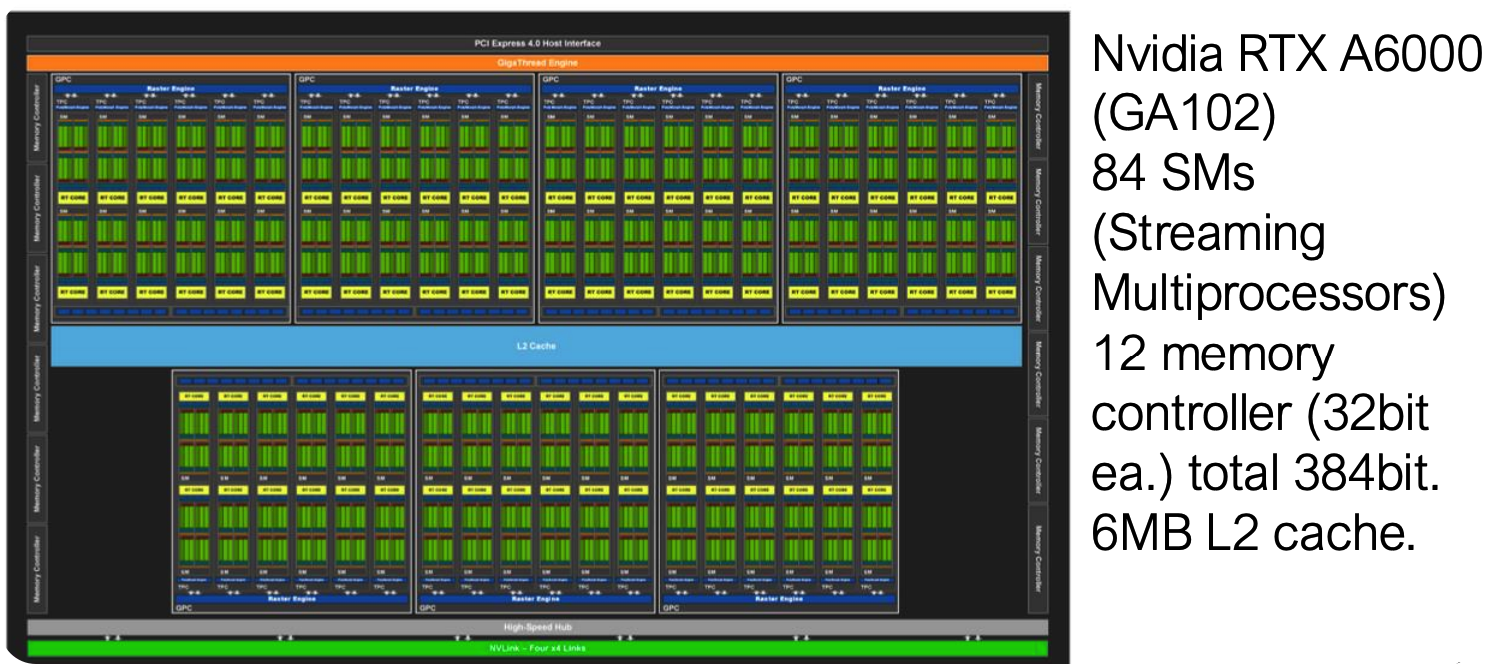
流式多处理器(Streaming Multiprocessor)
SM 是 GPU 的计算核心单元,以 NVIDIA RTX A6000(GA102 架构)为例,其包含 84 个 SM,每个 SM 的结构如下:
- 4 个分区,每个分区 32 个核心,单个 SM 共 128 个核心
- 存储资源:每个分区 64KB 寄存器(最快访问速度),单个 SM 共享 128KB L1 缓存 / 共享内存
- 计算能力:单周期可执行 128 次 FP32 运算,支持张量核心加速矩阵乘法
- 辅助单元: warp 调度器、加载 / 存储单元(LD/ST)、特殊功能单元(SFU)
CPU和GPU对比(CPU vs. GPU)

四、GPU上的程序执行(Program Execution on GPU)
1️⃣ GPU编程模型(GPU Programming Model)
CUDA 是 NVIDIA 推出的 GPU 编程框架,采用 "主机 - 设备"(CPU-GPU)异构计算模式:
- 主机(CPU):运行 C/C++ 等常规程序,负责任务调度、数据预处理与 GPU 控制;
- 设备(GPU):运行 CUDA 内核(Kernel)代码,负责并行计算任务;
- 数据传输:需显式在 CPU 系统内存与 GPU 显存间移动数据(通过 PCIe 或 NVLink);
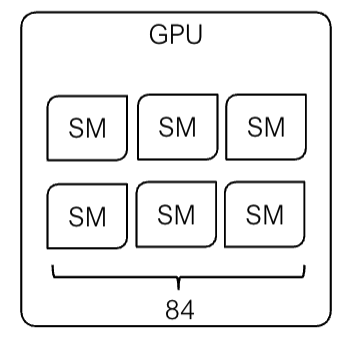
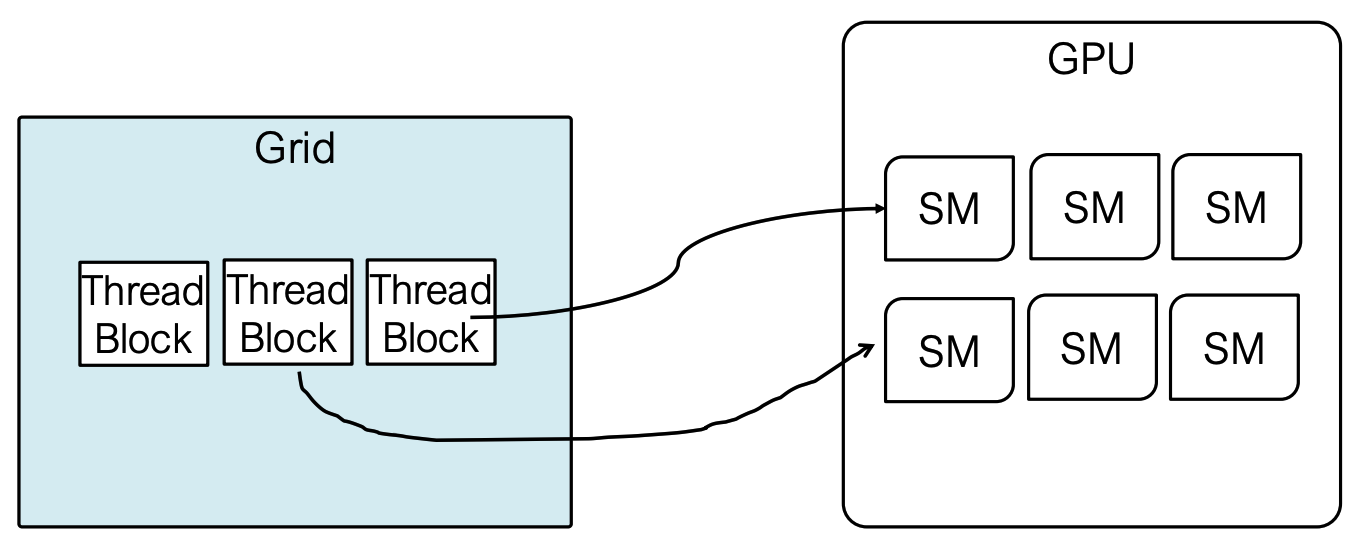
2️⃣ GPU上的SIMT执行(SIMT Execution on GPU)
GPU 采用 "单指令多线程"(Single Instruction Multiple Threads,SIMT)模式执行并行任务,线程组织层次如下:
- 线程被分组为线程块(Threads are grouped into Thread Blocks);
- 线程块被分组为网格(Thread Blocks are grouped into Grid);
- 内核作为由线程块组成的网格执行(Kernel executed as Grid of Blocks of Threads);
3️⃣ GPU上指令的执行方式(How instructions are executed on GPU)
4️⃣ 内核线程的执行方式(How Kernel Threads are Executed)
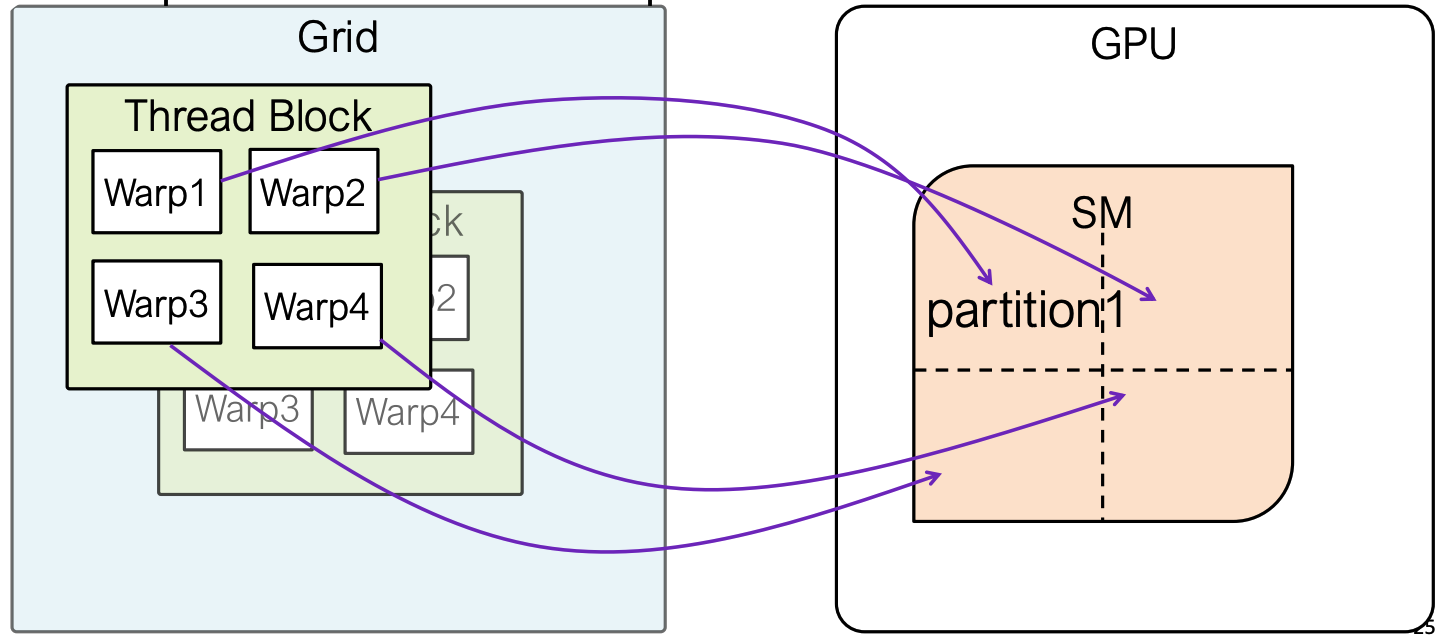
- SM将线程块划分为线程束;
- Warp是GPU创建、管理、调度和执行线程的单位;
- 每个线程束包含32个线程(为什么是32个?)
- 从相同的程序地址开始;
- 拥有自己的程序计数器和寄存器;
- 在一个周期内执行一条共同的指令;
- 可以分支并独立执行。
5️⃣ GPU上的线程束执行(Warp Execution on GPU)
- 执行上下文在warp的生命周期内一直存在于SM上(程序计数器、寄存器、共享内存);
- 线程束之间的上下文切换是即时的;
- 在运行时,线程束调度器选择具有活跃线程的 warp,向线程束的线程发布指令;
- 流式多处理器(SM)上的线程束数量取决于所需内存和可用内存;
6️⃣ 在一个SM上执行一个线程块(Executing one Thread block on one SM)
- 4 warps can be executed in parallel at one time on each SM
7️⃣ CPU-GPU数据传输(CPU-GPU Data Movement)
8️⃣ CUDA内核(CUDA Kernel)
- 每个内核都是一个在GPU上运行的函数(程序);
- 程序本身是串行的;
- 可以同时运行许多(10k)线程;
- 使用线程索引计算数据的右侧部分;
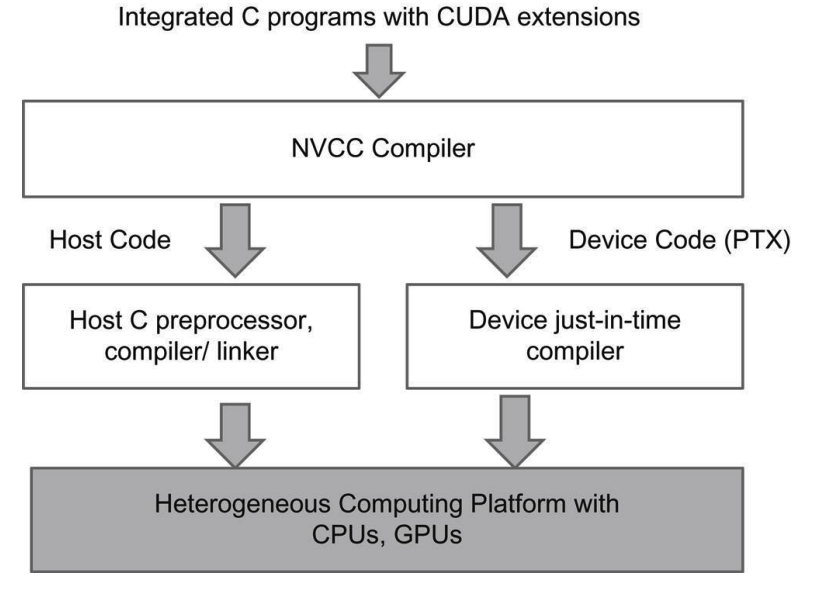
9️⃣ 编译CUDA代码(Compiling CUDA Code)
bash
nvcc -o output.so --shared src.cu -Xcompiler -fPIC