一、需求从哪来?
去年下半年,公司HR部门找到我们,说员工每天都在问重复的问题:
- "入职需要准备什么材料?"
- "出差住宿能报多少钱?"
- "忘记密码怎么办?"
HR同事每天要回答几十遍同样的问题,实在受不了了。他们希望能有个系统,员工自己问,系统自己答。
听起来很简单对吧?不就是做个FAQ吗?但当我们深入聊下去,发现事情没那么简单。
财务部也有类似需求,但他们的文档员工不能随便看。IT部也想把他们的操作手册接进来,但也不想让其他部门看到内部系统配置。
核心需求其实是:
- 员工能用自然语言提问
- 系统能理解并给出准确答案
- 不同部门的文档要严格隔离
二、第一个思考:检索方式怎么选?
当时我们调研了两种主流方案:
方案A:关键词检索(Elasticsearch)
就是传统的全文检索,用户输入"出差住宿",系统找包含这些词的文档。
优点很明显:
- 可控性强,结果可预测
- 能精确匹配术语
- 出问题容易调试
但问题也很明显:
员工实际问的是:"去上海出差,酒店能报多少钱?"
你的文档写的是:"一线城市差旅住宿标准为500元/天"
关键词检索可能就找不到了,因为它看不懂"上海"="一线城市","酒店"="住宿"。
方案B:向量检索(Embedding)
把文档和问题都转成向量,然后算相似度。理论上能理解语义。
听起来很美好:
- 不用维护同义词库
- 能理解自然语言
- 对提问方式不敏感
但我们测试的时候发现了个大问题。
三、关键转折点:HR-Link的困境
我们有个内部系统叫"HR-Link",是公司自研的人事系统。
测试中发现两个典型场景:
场景1:新员工直接问系统名称
员工问:"HR-Link的登录地址是什么?"
- Elasticsearch:✅ 能找到,精确匹配"HR-Link"这个词
- 向量检索:❌ 找不到,因为embedding模型没见过这个专有名词
场景2:员工用自然语言问功能
员工问:"忘记密码怎么办?"
文档写的是:"无法登录时,请在HR-Link中点击'忘记密码'重置凭证"
- Elasticsearch:❌ 找不到,因为员工没提"HR-Link"这个词
- 向量检索:✅ 能找到,理解"忘记密码"和"无法登录"是同一件事
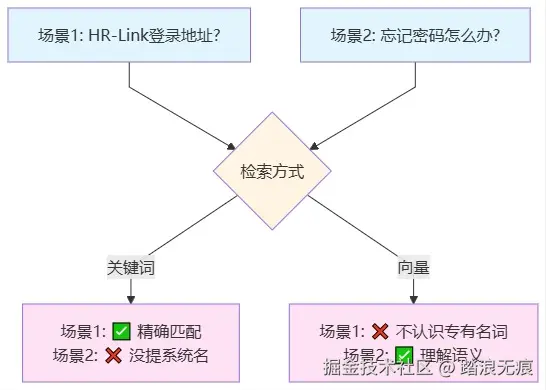
这时候我们意识到:两种方法各有盲区。
关键词检索的盲区:
- 理解不了同义替换
- 处理不了口语化表达
- 需要人工维护词典
向量检索的盲区:
- 不认识公司内部术语(HR-Link、F-Flow、IT-SOP-005...)
- 对专有名词、项目代号无能为力
那怎么办呢?
四、我们的方案:混合检索
既然单独用都有问题,那就两个一起用。
核心思路:
- Elasticsearch找10条(保证内部术语能命中)
- 向量检索找10条(保证语义相关的能找到)
- 合并去重,按文档元数据排序
- 把最终结果交给LLM生成答案
举个实际例子:
场景1:内部系统名称
员工问:"HR-Link的登录地址是什么?"
- ES搜"HR-Link" → 找到文档(精确匹配专有名词)✓
- 向量搜索 → 找不到(模型不认识这个词)✗
最终能返回正确答案,因为ES找到了。
场景2:功能性提问
员工问:"忘记密码怎么办?"
文档写的是:"无法登录时,请在HR-Link中点击'忘记密码'重置凭证"
- ES搜"忘记密码" → 可能找不到(员工没提"HR-Link",排名靠后)✗
- 向量搜索 → 理解"忘记密码"和"无法登录"的语义关联 ✓
最终也能返回正确答案,因为向量找到了。
场景3:口语化表达
员工问:"我登不上代码平台了"
文档写的是:"无法访问GitLab时,请检查VPN连接"
- ES搜"登不上代码平台" → 找不到(字面不匹配)✗
- 向量搜索 → 理解"登不上"≈"无法访问","代码平台"≈"GitLab"✓
最终也能返回正确答案。
这就是互补。
五、第二个难题:多轮对话
方案跑起来后,我们又发现了新问题。
员工第一次问:"一线城市出差住宿标准是多少?"
系统答:"500元/天"
紧接着员工问:"二线城市呢?"
系统懵了。
为什么?因为"二线城市呢?"这个问题:
- 没有主语
- 没有动词
- 没有完整语境
如果直接去检索"二线城市",可能会找到:
- "二线城市招聘政策"
- "二线城市办公室地址"
- 各种不相关的内容
解决方案:Query Rewriting(查询重写)
在检索之前,先让LLM看一眼对话历史,把问题补全。
vbnet
历史:
Q1: "一线城市出差住宿标准是多少?"
A1: "500元/天"
当前问题:"二线城市呢?"
重写后:"二线城市出差住宿标准是多少?"重写后再去检索,就能准确找到文档了。
六、权限隔离怎么做?
这是整个系统的安全基线。
我们的做法很简单:在文档入库时打标签,检索时过滤。
文档入库
python
# 文档元数据
{
"content": "差旅住宿标准...",
"metadata": {
"department": "finance", # 所属部门
"doc_type": "policy", # 文档类型
"is_latest": true, # 是否最新版本
"update_time": "2024-12-01"
}
}检索时过滤
python
# 用户登录后,获取部门信息
user_department = "finance"
# ES检索时加filter
es_filter = {
"department": user_department
}
# 向量检索时也加filter
vector_filter = {
"department": user_department
}这样就能保证:
- 财务部员工只能搜到财务文档
- HR部员工只能搜到HR文档
- 完全在检索层面隔离,不是生成时才过滤
七、技术实现
整个系统基于LangChain构建,主要组件:
1. 文档处理
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 文档分块
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=50
)
chunks = text_splitter.split_documents(documents)2. 双路检索
python
from langchain.retrievers import EnsembleRetriever
from langchain.vectorstores import FAISS
from langchain.retrievers import BM25Retriever
# Elasticsearch检索器
bm25_retriever = BM25Retriever.from_documents(chunks)
bm25_retriever.k = 10
# 向量检索器
vectorstore = FAISS.from_documents(chunks, embeddings)
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
# 混合检索
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, vector_retriever],
weights=[0.5, 0.5]
)3. Query重写
python
from langchain.prompts import ChatPromptTemplate
from langchain.chat_models import ChatAnthropic
rewrite_prompt = ChatPromptTemplate.from_messages([
("system", "根据对话历史,将用户的简短问题补全为完整的问题。"),
("human", "对话历史:{history}\n当前问题:{question}")
])
llm = ChatAnthropic(model="claude-sonnet-4-20250514")
rewrite_chain = rewrite_prompt | llm4. 完整流程
python
from langchain.chains import ConversationalRetrievalChain
# 构建问答链
qa_chain = ConversationalRetrievalChain.from_llm(
llm=llm,
retriever=ensemble_retriever,
return_source_documents=True,
verbose=True
)
# 执行查询
result = qa_chain({
"question": user_question,
"chat_history": chat_history
})八、实际效果
系统上线三个月后,我们看了下数据:
问答准确率:
- 单次问答:85%以上
- 多轮对话:78%左右
召回率提升:
- 纯ES:62%
- 纯向量:71%
- 混合检索:89%
典型成功案例:
- "报销需要什么发票?" → 准确找到《差旅报销制度》
- "忘记密码怎么办?" → 准确找到《IT自助服务指南》(向量理解语义)
- "HR-Link登录地址?" → 精确匹配内部系统文档(ES精确匹配)
- "我登不上代码平台" → 准确找到GitLab相关文档(向量理解口语)
典型失败案例:
- "能不能提前报销?" → 文档没有这个例外情况
- "去年的制度是怎样的?" → 旧版本文档被降权了
九、踩过的坑
坑1:分块大小
最开始我们设置chunk_size=1000,结果发现很多问题只需要一句话就能回答,但系统返回了一大段无关内容。
后来改成500,效果好多了。
坑2:向量模型选择
一开始用的英文模型,中文效果很差。后来换成BGE中文模型,准确率直接提升20%。
坑3:权限过滤的位置
最开始是检索完再过滤,结果发现可能检索20条,过滤后只剩3条。
改成检索前就加filter,问题解决。
坑4:文档更新不同步
Elasticsearch更新了,向量库没更新,导致返回的内容不一致。
后来加了版本号机制,强制同步更新。
十、总结
回过头看,整个方案的核心其实就三点:
-
混合检索解决了单一方案的盲区
- ES保证精确匹配
- 向量保证语义理解
-
Query重写解决了多轮对话问题
- 不能简单地用原始问题检索
- 需要补全上下文
-
元数据过滤解决了权限隔离
- 检索前就过滤
- 不是生成时才控制
这不是什么高深的技术,就是针对真实业务场景,一步步解决实际问题。
最重要的是:不要迷信某一种方案,要根据实际情况组合使用。
关键词检索和向量检索,不是替代关系,而是互补关系。
希望这篇文章能给正在做企业知识库的同学一些参考。
如果有问题,欢迎讨论。