在 Kafka 消费消息的流程中,「偏移量(Offset)」是核心机制 ------ 它就像消费者的 "书签",记录着每次消费到了哪里。很多开发者只知道 "消费者会自动记住位置",却不懂 Offset 的存储逻辑、提交方式,遇到重复消费、数据丢失时无从下手。
一、先搞懂:Offset 到底是什么?
1. Offset 的定义
Offset 是消息在分区(Partition)中的唯一序号,从 0 开始递增 ------ 每一条消息被写入分区时,Kafka 都会给它分配一个全局唯一的 Offset 值。
可以用「书籍页码」类比:
- 一个 Topic 的分区 = 一本书;
- 分区中的消息 = 书中的每页内容;
- Offset = 页码(从 0 开始);
- 消费者 = 读者,Offset 就是读者上次读到的页码,下次打开直接从该页继续读。
2. Offset 的核心作用
记录消费进度
:消费者每次消费消息后,会更新 Offset,标识 "已消费到这个位置";
支持断点续传
:消费者重启、集群故障后,能通过 Offset 恢复消费,不会重复消费已处理的消息,也不会遗漏未消费的消息;
实现消息分区消费
:多个消费者在同一消费者组时,通过 Offset 分配不同分区的消费范围,避免重复消费。
3. 关键结论
Offset 是分区级别的:每个分区有独立的 Offset 序列,不同分区的 Offset 互不影响(比如 Topic 有 3 个分区,每个分区的 Offset 都从 0 开始);
Offset 是单调递增的:消息一旦写入分区,Offset 就固定不变,新消息的 Offset 永远比旧消息大。
二、Offset 存在哪里?(存储位置演变)
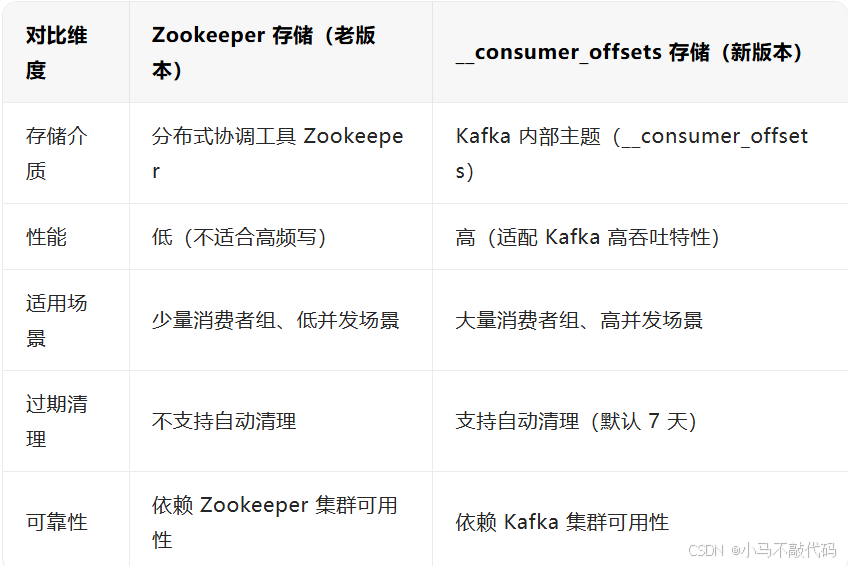
Kafka 的 Offset 存储位置经历了两个版本的变化,面试中常考两者的区别:
1. 老版本(0.9.x 之前):存储在 Zookeeper
存储方式:每个消费者组的 Offset 以「/consumers/ 消费者组名 /offsets/Topic 名 / 分区号」的路径存储在 Zookeeper 中;
优点:无需额外配置,依赖 Zookeeper 的分布式一致性;
缺点:
Zookeeper 是分布式协调工具,不适合高频写操作(消费者每消费一条消息就可能更新 Offset,高频写入会导致 Zookeeper 压力过大);
性能瓶颈:当消费者组和分区数量较多时,Offset 更新会严重影响 Kafka 集群性能。
2. 新版本(0.9.x 及之后):存储在__consumer_offsets 主题
为了解决 Zookeeper 存储的性能问题,Kafka 引入了「内部主题__consumer_offsets」,专门用于存储 Offset:
存储方式:__consumer_offsets 是 Kafka 的系统主题,默认有 50 个分区,Offset 以键值对(Key-Value)的形式存储为消息:
Key:{消费者组名, Topic名, 分区号};
Value:{Offset值, 时间戳, 元数据};
优点:
基于 Kafka 自身的存储机制,支持高吞吐、低延迟的 Offset 写入;
支持 Offset 的过期清理(默认保留 7 天,可通过配置调整);
查看方式:通过 Kafka 提供的命令行工具查看 Offset 存储情况:
java
# 查看指定消费者组的Offset
kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group 消费者组名 --describe面试真题:Offset 存储在 Zookeeper 和__consumer_offsets 的区别?
参考答案:
三、Offset 怎么提交?(提交方式详解)
Offset 的提交方式决定了消费进度的更新时机,直接影响消息的可靠性(是否重复消费、是否丢失),是开发和面试的核心考点。
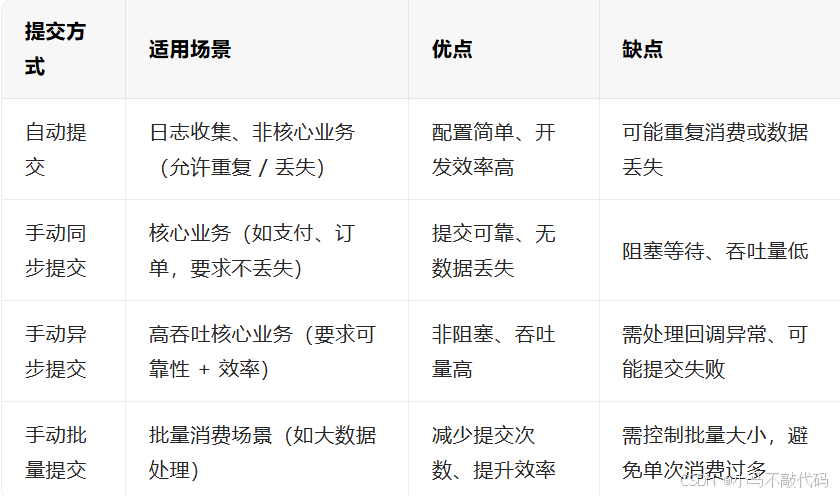
Kafka 提供两种核心提交方式:自动提交和手动提交,还有同步 / 异步的细分场景。
1. 自动提交(默认方式)
核心逻辑:
消费者会定期自动提交当前的 Offset,提交时机由配置参数auto.commit.interval.ms控制(默认 5 秒)------ 消费者后台线程每隔指定时间,就会把当前消费到的最大 Offset 提交到__consumer_offsets。
配置示例(Spring Boot):
java
# 开启自动提交(默认true)
spring.kafka.consumer.enable-auto-commit=true
# 自动提交间隔(默认5000ms)
spring.kafka.consumer.auto-commit-interval=5000优点:
配置简单,无需手动处理 Offset,开发效率高;
适合对消息重复消费不敏感的场景(如日志收集)。
缺点(核心坑点):
可能导致重复消费
:比如消费者在自动提交前宕机,已消费但未提交的 Offset 会丢失,重启后会从上次提交的 Offset 重新消费,导致重复;
可能导致数据丢失
:如果消费者消费消息后、业务处理前,自动提交了 Offset,此时消费者宕机,业务未完成但 Offset 已更新,导致消息丢失。
2. 手动提交(推荐生产环境使用)
为了避免自动提交的可靠性问题,生产环境通常采用手动提交 ------ 开发者通过代码控制 Offset 的提交时机,确保 "业务处理成功后再提交 Offset"。
手动提交又分为「同步提交」和「异步提交」,需先关闭自动提交:
java
# 关闭自动提交
spring.kafka.consumer.enable-auto-commit=false子场景 1:同步提交(commitSync ())
核心逻辑:调用consumer.commitSync()后,消费者会阻塞等待 Offset 提交成功,直到收到 Kafka 的确认响应才继续执行;
代码示例(Java):
java
@KafkaListener(topics = "test_topic", groupId = "test_group")
public void consume(ConsumerRecord<String, String> record, Consumer<?, ?> consumer) {
try {
// 1. 处理业务逻辑(如保存数据库、调用接口)
System.out.println("消费消息:" + record.value());
// 2. 业务处理成功后,同步提交Offset
consumer.commitSync();
} catch (Exception e) {
// 处理异常(如重试、告警)
log.error("消费失败", e);
}
}优点:提交可靠性高,能确保 Offset 提交成功;
缺点:阻塞等待会降低消费吞吐量,适合对可靠性要求极高、吞吐量要求不高的场景。
子场景 2:异步提交(commitAsync ())
核心逻辑:调用consumer.commitAsync()后,消费者不会阻塞,继续处理下一条消息,Offset 提交结果通过回调函数返回;
代码示例(Java):
java
@KafkaListener(topics = "test_topic", groupId = "test_group")
public void consume(ConsumerRecord<String, String> record, Consumer<?, ?> consumer) {
// 1. 处理业务逻辑
System.out.println("消费消息:" + record.value());
// 2. 异步提交Offset,通过回调函数处理提交结果
consumer.commitAsync((offsets, exception) -> {
if (exception != null) {
// 提交失败处理(如记录日志、重试)
log.error("Offset提交失败:{}", offsets, exception);
} else {
log.info("Offset提交成功:{}", offsets);
}
});
}优点:非阻塞,不影响消费吞吐量,适合高吞吐场景;
缺点:可能存在提交失败的情况,需要在回调函数中处理异常(如重试)。
子场景 3:批量提交(手动批量提交 Offset)
对于批量消费的场景(如一次拉取 100 条消息),可以批量提交 Offset,提升效率:
java
@KafkaListener(topics = "test_topic", groupId = "test_group")
public void consumeBatch(List<ConsumerRecord<String, String>> records, Consumer<?, ?> consumer) {
try {
// 1. 批量处理业务逻辑
for (ConsumerRecord<String, String> record : records) {
System.out.println("消费消息:" + record.value());
}
// 2. 批量提交Offset(提交最后一条消息的Offset)
if (!records.isEmpty()) {
TopicPartition topicPartition = new TopicPartition(records.get(0).topic(), records.get(0).partition());
OffsetAndMetadata offsetAndMetadata = new OffsetAndMetadata(records.get(records.size() - 1).offset() + 1);
consumer.commitSync(Collections.singletonMap(topicPartition, offsetAndMetadata));
}
} catch (Exception e) {
log.error("批量消费失败", e);
}
}关键注意:提交的 Offset 是「下一条要消费的消息的 Offset」,所以需要在当前最大 Offset 的基础上加 1(比如最后消费的消息 Offset 是 99,提交 100,表示下次从 100 开始消费)。
3. 提交方式选型建议
四、生产环境常见问题与解决方案
1. 问题 1:重复消费(最常见)
现象:
消费者重启后,之前已经消费过的消息被再次消费。
原因:
手动提交场景:业务处理成功,但 Offset 提交失败(如网络异常、消费者宕机);
自动提交场景:消费者消费消息后、自动提交前宕机,Offset 未更新。
解决方案:
核心思路:实现消费幂等性(即使重复消费,也不会影响业务结果);
具体方案:
数据库唯一键:消息消费后写入数据库时,用消息 ID 作为唯一键,重复消费时会触发主键冲突,直接忽略;
分布式锁:消费前用消息 ID 获取分布式锁,获取成功则消费,失败则跳过;
本地缓存:将已消费的消息 ID 存入本地缓存(如 Redis),消费前先校验是否已存在。
2. 问题 2:数据丢失
现象:
消费者消费消息后,业务处理未完成,但 Offset 已提交,此时消费者宕机,导致消息丢失。
原因:
自动提交场景:消费者先提交 Offset,再处理业务,宕机后业务未完成,但 Offset 已更新;
手动提交场景:代码逻辑错误(如先提交 Offset,再处理业务)。
解决方案:
严格遵循「业务处理成功后再提交 Offset」的原则(手动提交的核心逻辑);
关闭自动提交,改用手动同步或异步提交;
业务处理加入重试机制,确保业务能正常完成(如数据库写入失败时重试 3 次)。
3. 问题 3:Offset 过期导致数据丢失
现象:
消费者长时间未消费(如停机维护),重启后发现部分消息丢失,Offset 无法恢复。
原因:
__consumer_offsets 主题的 Offset 有过期时间(默认 7 天,由offsets.retention.minutes配置控制),超过过期时间的 Offset 会被自动清理 ------ 消费者重启后,找不到对应的 Offset,会从最新的消息开始消费(默认配置),导致中间的消息丢失。
解决方案:
调整 Offset 保留时间:根据业务场景延长offsets.retention.minutes(如设置为 30 天);
java
# 修改server.properties配置,重启Kafka
offsets.retention.minutes=43200(30天)
消费者启动时指定消费起始位置:如果 Offset 过期,可通过代码指定从最早消息(earliest)开始消费:
# Spring Boot配置:从最早消息开始消费(默认是latest)
spring.kafka.consumer.auto-offset-reset=earliest4. 问题 4:消费者组重平衡导致 Offset 错乱
现象:
消费者组内新增 / 删除消费者,或 Topic 分区数变化,触发重平衡(Rebalance),重平衡后部分消息重复消费或丢失。
原因:
重平衡期间,消费者会暂停消费,重新分配分区 ------ 如果重平衡前 Offset 未提交,或重平衡后分区分配变化,会导致 Offset 与分区不匹配。
解决方案:
避免不必要的重平衡:
合理设置session.timeout.ms(默认 10 秒)和heartbeat.interval.ms(默认 3 秒),避免消费者因网络波动被误判为下线;
消费者处理消息时,定期发送心跳(或确保处理时间不超过 session.timeout.ms);
重平衡后校验 Offset:重平衡完成后,消费者启动时先获取当前分区的 Offset,与本地记录的 Offset 对比,确保一致性。
五、面试高频真题解析
真题 1:Kafka 的 Offset 是什么?有什么作用?
参考答案:
Offset 是消息在分区中的唯一递增序号,用于标识消息在分区中的位置;
核心作用:记录消费者的消费进度,支持断点续传,避免重复消费和数据丢失;
关键特性:分区级别唯一、单调递增。
真题 2:Kafka 的 Offset 存储在哪里?新版本和老版本有什么区别?
参考答案:
老版本(0.9.x 之前)存储在 Zookeeper,以节点路径形式存储,适合低并发场景,但性能差、不支持自动清理;
新版本(0.9.x 及之后)存储在 Kafka 内部主题__consumer_offsets,以键值对形式存储,性能高、支持自动过期清理,适合高并发场景。
真题 3:Kafka 的 Offset 提交方式有哪些?各自的优缺点是什么?
参考答案:
自动提交:优点是配置简单,缺点是可能重复消费或数据丢失,适合非核心业务;
手动同步提交:优点是提交可靠、无数据丢失,缺点是阻塞等待、吞吐量低,适合核心业务;
手动异步提交:优点是非阻塞、吞吐量高,缺点是需处理回调异常,适合高吞吐核心业务。
真题 4:如何避免 Kafka 消息重复消费?
参考答案:
根本方案是实现消费幂等性,具体包括:数据库唯一键、分布式锁、本地缓存校验;
辅助方案:优化 Offset 提交策略(如手动同步提交),减少 Offset 提交失败的概率;
避免重平衡期间的 Offset 错乱(合理配置会话超时时间)。
六、总结:核心要点速记
Offset 是分区级别的 "消费书签",唯一且单调递增;
新版本 Offset 存储在__consumer_offsets 主题,老版本存储在 Zookeeper;
提交方式优先选手动提交(业务成功后提交),核心业务用同步提交,高吞吐场景用异步提交;
生产环境的核心坑是重复消费和数据丢失,解决关键是 "幂等性 + 正确的提交策略"。