智能体基础执行模式实战指南(第2-3周):拆解、决策、并行与自优化
引言
在智能体开发中,基础执行模式是构建复杂自主系统的基石。第2-3周的8课时聚焦四大核心模式------提示链(Prompt Chaining)、路由(Routing)、并行化(Parallelization)与反思(Reflection),核心目标是帮开发者掌握"任务拆解→动态决策→高效执行→自我优化"的完整逻辑链。
通过这8课时的学习,你将从"单一指令执行"升级为"复杂流程编排",能够独立设计多步骤任务流、动态分流请求、优化执行效率,并实现智能体的自我纠错。本文将详细拆解每个模式的原理、实现步骤、实践任务与效果验证,配套可视化图表与可直接运行的代码,助力快速落地。
整体学习框架图
基础执行模式总目标
掌握任务拆解、动态决策、并行处理、自我优化
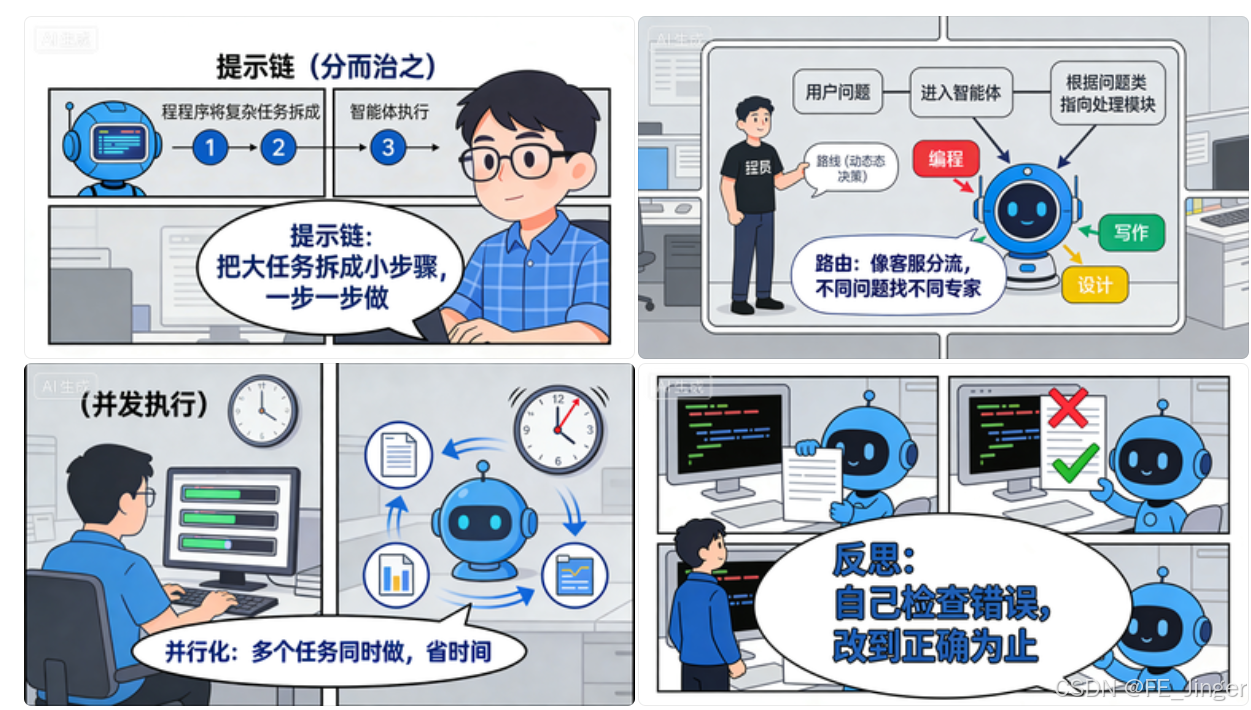
提示链:分而治之拆解任务
路由:条件逻辑分流请求
并行化:并发执行提升效率
反思:迭代优化修正输出
学习:核心思想+结构化输出+LangChain实现
实践:文档摘要→趋势提取→邮件生成
学习:条件逻辑+LLM/规则路由
实践:客服路由智能体(订单/产品/技术支持)
学习:适用场景+RunnableParallel
实践:多主题摘要并行生成+效率对比
学习:生产者-批评者模型+迭代逻辑
实践:代码生成与自动纠错智能体
课时5-6:提示链(Prompt Chaining)------ 用分而治之拆解复杂任务
一、核心学习内容
1. 提示链的核心思想:分而治之
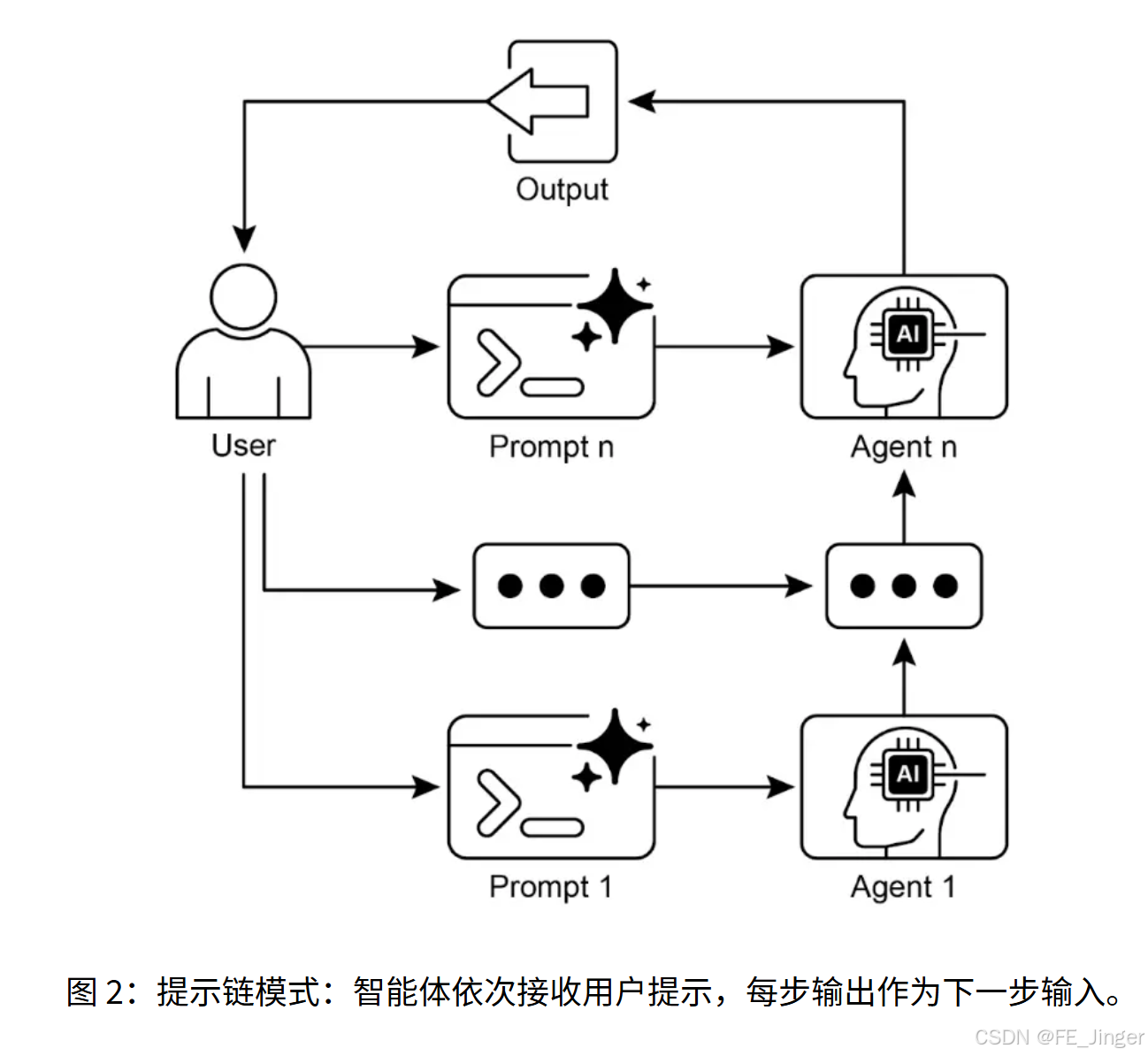
提示链(又称流水线模式)的核心是将复杂任务拆解为多个小而聚焦的子任务,每个子任务通过专用提示独立处理,前一步输出作为后一步输入,形成链式依赖。
解决的核心问题:单一复杂提示易导致模型忽略指令、丢失上下文、错误累积(如"分析报告→提取趋势→写邮件"的多步骤任务,单一提示可能遗漏关键数据)。
2. 结构化输出设计
为确保子任务间数据传递的准确性,必须定义结构化输出格式(如JSON),避免自然语言歧义。示例:趋势提取步骤的输出格式:
json
{
"trends": [
{"trend_name": "AI驱动个性化", "supporting_data": "73%消费者偏好个性化服务"},
{"trend_name": "可持续消费", "supporting_data": "ESG产品销量年增28%"}
]
}3. LangChain实现核心组件
- PromptTemplate:定义每个子任务的专用提示
- LLM:选择ChatOpenAI/Gemini等模型
- StrOutputParser:解析模型输出为字符串
- LCEL(LangChain Expression Language):串联多个子任务形成链
二、可视化:提示链工作流程图
用户输入:市场调研报告
提示1:文档摘要
LLM:生成报告摘要
提示2:趋势提取
LLM:提取核心趋势+数据
提示3:邮件生成
LLM:生成市场团队邮件
最终输出:结构化邮件
三、实践任务:构建"文档摘要→趋势提取→邮件生成"三步提示链
1. 环境准备
安装依赖:
bash
pip install langchain langchain-openai langchain-core python-dotenv配置环境变量(.env文件):
env
OPENAI_API_KEY=你的API密钥2. 完整代码实现
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
# 加载环境变量
load_dotenv()
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 第一步:文档摘要提示
summary_prompt = ChatPromptTemplate.from_template(
"请总结以下市场调研报告的核心发现(不超过300字):\n\n{report_text}"
)
summary_chain = summary_prompt | llm | StrOutputParser()
# 第二步:趋势提取提示(结构化输出)
trend_prompt = ChatPromptTemplate.from_template(
"根据以下报告摘要,提取3个核心趋势,每个趋势需包含名称和支持数据,输出JSON格式(仅JSON,无其他内容):\n\n{summary_text}"
)
trend_chain = trend_prompt | llm | StrOutputParser()
# 第三步:邮件生成提示
email_prompt = ChatPromptTemplate.from_template(
"为市场团队撰写一封简明邮件,概述以下趋势及数据支持,语气专业且简洁:\n\n{trend_data}"
)
email_chain = email_prompt | llm | StrOutputParser()
# 串联完整提示链
full_chain = (
{"summary_text": summary_chain}
| {"trend_data": trend_chain}
| email_chain
)
# 测试输入(模拟市场调研报告)
test_report = """
2024年Q3消费市场调研报告显示:
1. 个性化服务需求激增:73%消费者表示更愿意与提供个性化推荐的品牌合作,较去年增长15%;
2. 可持续消费成主流:带ESG标签的产品销量同比增长28%,无ESG标签产品仅增长20%;
3. 即时服务偏好强化:68%用户希望品牌响应时间不超过1小时,较Q2提升10%;
4. 全渠道购物占比达62%:用户平均通过3个以上渠道完成购物决策。
"""
# 运行链
result = full_chain.invoke({"report_text": test_report})
print("最终邮件输出:\n", result)3. 运行结果与验证
- 第一步输出:报告核心发现的300字摘要;
- 第二步输出:符合JSON格式的3个趋势数据;
- 第三步输出:结构化的市场团队邮件,包含趋势名称、数据支撑与行动建议。
四、关键要点总结
- 提示链的核心是"模块化拆解",每个子任务仅聚焦一个目标;
- 结构化输出是链稳定性的关键,优先使用JSON/XML格式;
- LCEL的
|运算符简化了链的串联,支持灵活调整步骤顺序。
课时7-8:路由(Routing)------ 动态决策分流请求
一、核心学习内容
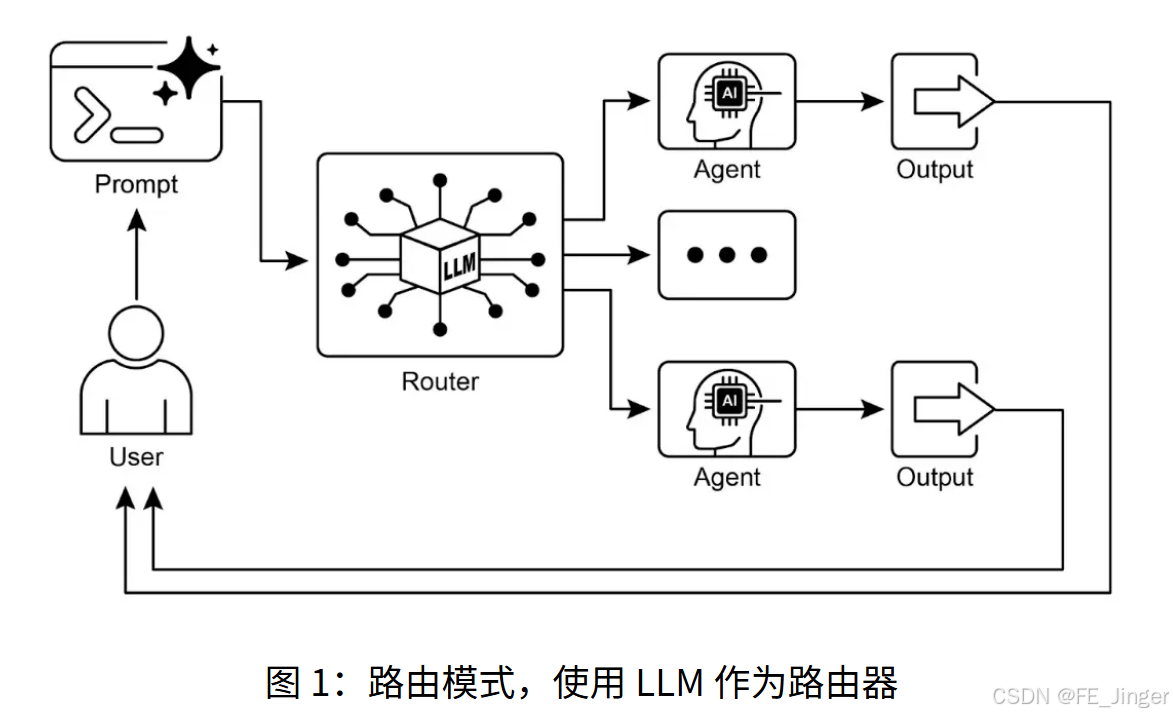
1. 路由模式的核心价值:条件逻辑调度
路由模式为智能体引入动态决策能力,能够根据用户输入、环境状态或前序结果,将控制流导向不同的工具、子智能体或流程。解决的核心问题:单一线性流程无法应对多样化请求(如客服智能体需区分订单查询、产品咨询等不同意图)。
2. 两种核心路由实现方式
| 路由类型 | 原理 | 优势 | 适用场景 |
|---|---|---|---|
| LLM路由 | 让LLM分析输入并输出路由标识(如"order""product""support") | 灵活处理模糊意图 | 自然语言请求分类 |
| 规则路由 | 基于关键词、正则表达式等预定义规则匹配 | 速度快、确定性高 | 明确关键词的请求分流 |
3. 路由模式的核心组件
- 路由器:负责分析输入并决策路由方向(LLM或规则引擎);
- 目标节点:被路由的子智能体、工具或流程(如订单查询工具、技术支持智能体);
- 调度器:执行路由决策,将输入传递到目标节点。
二、可视化:客服路由智能体工作流程图
意图=订单查询
意图=产品咨询
意图=技术支持
意图不明确
用户请求
路由器:LLM+规则混合
订单查询子智能体:调用订单数据库
产品咨询子智能体:检索产品知识库
技术支持子智能体:触发故障排查流程
澄清子智能体:请求用户补充信息
统一响应输出
三、实践任务:开发客服路由智能体
1. 功能需求
- 区分"订单查询""产品咨询""技术支持"三类请求;
- 支持模糊意图识别(如"我的订单怎么还没到"→订单查询);
- 意图不明确时主动澄清(如"你问的是订单相关还是产品相关问题?")。
2. 完整代码实现(LangChain)
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableBranch, RunnablePassthrough
# 加载环境变量
load_dotenv()
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 定义子智能体处理器
def order_handler(request: str) -> str:
"""处理订单查询请求"""
return f"订单查询处理结果:已为你查询到订单状态(模拟),你的订单正在配送中,预计2天内送达。"
def product_handler(request: str) -> str:
"""处理产品咨询请求"""
return f"产品咨询处理结果:你咨询的产品支持7天无理由退货,质保期1年,详细参数可查看官网说明书。"
def support_handler(request: str) -> str:
"""处理技术支持请求"""
return f"技术支持处理结果:请先尝试重启设备,若问题未解决,可提供设备序列号,我们将安排专属工程师对接。"
def unclear_handler(request: str) -> str:
"""处理意图不明确请求"""
return f"抱歉,我未能明确你的需求~ 你是想查询订单状态、咨询产品信息,还是需要技术支持?请补充说明。"
# 定义路由器提示(LLM路由)
router_prompt = ChatPromptTemplate.from_messages([
("system", """
分析用户请求,判断意图并输出唯一标识:
- 涉及订单查询、物流状态、退款申请→输出'order'
- 涉及产品参数、功能、价格、售后政策→输出'product'
- 涉及设备故障、使用问题、技术对接→输出'support'
- 无法明确归类→输出'unclear'
仅输出标识,无其他内容。
"""),
("user", "{request}")
])
# 构建路由器链
router_chain = router_prompt | llm | StrOutputParser()
# 构建分支路由逻辑
delegation_branch = RunnableBranch(
(lambda x: x["decision"] == "order", RunnablePassthrough.assign(output=lambda x: order_handler(x["request"]))),
(lambda x: x["decision"] == "product", RunnablePassthrough.assign(output=lambda x: product_handler(x["request"]))),
(lambda x: x["decision"] == "support", RunnablePassthrough.assign(output=lambda x: support_handler(x["request"]))),
RunnablePassthrough.assign(output=lambda x: unclear_handler(x["request"])) # 默认分支
)
# 构建完整路由智能体
support_agent = {
"decision": router_chain,
"request": RunnablePassthrough()
} | delegation_branch | (lambda x: x["output"])
# 测试用例
test_cases = [
"我的订单号12345,现在到哪了?",
"你们的无线耳机续航多久?",
"设备连接不上网络,怎么解决?",
"我想了解一下相关服务。"
]
# 运行测试
for idx, case in enumerate(test_cases, 1):
print(f"\n测试用例{idx}:{case}")
result = support_agent.invoke({"request": case})
print(f"智能体响应:{result}")3. 运行结果验证
- 测试用例1(订单查询)→ 触发order_handler,返回订单状态;
- 测试用例2(产品咨询)→ 触发product_handler,返回产品参数;
- 测试用例3(技术支持)→ 触发support_handler,返回故障排查建议;
- 测试用例4(意图模糊)→ 触发unclear_handler,请求补充信息。
四、关键要点总结
- 路由模式的核心是"意图识别+动态调度",需明确路由规则或训练LLM准确分类;
- 混合路由(LLM+规则)是平衡灵活性与效率的最佳实践;
- LangChain的RunnableBranch简化了分支逻辑的定义,支持多条件路由。
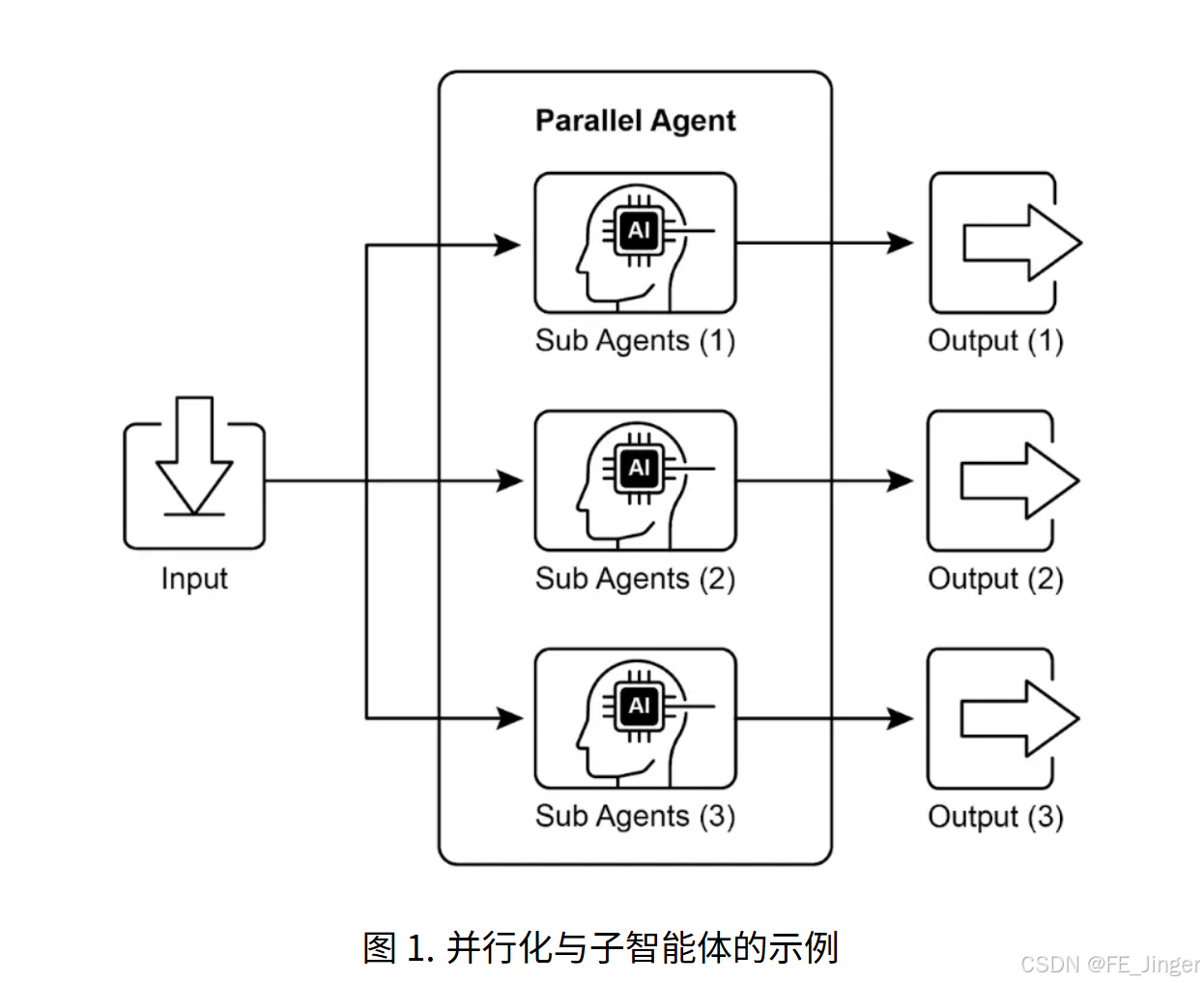
课时9-10:并行化(Parallelization)------ 并发执行提升效率
一、核心学习内容
1. 并行化的核心思想:同时执行独立任务
并行化模式指同时执行多个无依赖的子任务,而非串行等待前一步完成,核心价值是缩短复杂任务的总执行时间。
适用场景:
- 多源信息收集(如同时查询天气、航班、酒店);
- 多维度数据处理(如同时对文本做情感分析、关键词提取);
- 多方案生成(如同时生成3个营销文案版本)。
2. 串行vs并行效率对比
| 执行方式 | 流程 | 总耗时 | 适用场景 |
|---|---|---|---|
| 串行 | 任务A→任务B→任务C | T_A + T_B + T_C | 任务间有依赖 |
| 并行 | 任务A、B、C同时执行 | max(T_A, T_B, T_C) | 任务间无依赖 |
示例:3个主题摘要生成(每个任务耗时2秒)→ 串行需6秒,并行仅需2秒。
3. LangChain实现核心:RunnableParallel
LangChain的RunnableParallel组件支持将多个链或工具并发执行,结果以字典形式返回,便于后续汇总。
二、可视化:并行化执行流程图
用户输入:3个主题
并行执行器:RunnableParallel
子任务A:主题1摘要
子任务B:主题2摘要
子任务C:主题3摘要
结果汇总:整合3个摘要
最终输出:结构化报告
三、实践任务:并行处理多主题摘要生成
1. 功能需求
- 同时生成"AI发展趋势""可再生能源进展""元宇宙应用"3个主题的摘要;
- 对比串行与并行的执行时间差异;
- 汇总并行结果生成最终报告。
2. 完整代码实现
python
import os
import time
import asyncio
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
# 加载环境变量
load_dotenv()
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.7)
# 定义单个主题摘要链
def create_summary_chain(topic: str) -> Runnable:
prompt = ChatPromptTemplate.from_messages([
("system", "请为以下主题生成200字左右的简明摘要,突出核心进展:{topic}"),
("user", "生成摘要")
])
return prompt | llm | StrOutputParser()
# 定义3个目标主题
topics = {
"ai_trend": "AI发展趋势",
"energy_trend": "可再生能源进展",
"metaverse_trend": "元宇宙应用"
}
# 构建并行链
parallel_chain = RunnableParallel({
"ai_summary": create_summary_chain(topics["ai_trend"]),
"energy_summary": create_summary_chain(topics["energy_trend"]),
"metaverse_summary": create_summary_chain(topics["metaverse_trend"])
})
# 构建汇总链(整合并行结果)
merge_prompt = ChatPromptTemplate.from_messages([
("system", "将以下3个主题的摘要整合为一篇结构化报告,每个主题用小标题区分:\n\nAI趋势:{ai_summary}\n\n可再生能源:{energy_summary}\n\n元宇宙:{metaverse_summary}"),
("user", "生成最终报告")
])
full_chain = parallel_chain | merge_prompt | llm | StrOutputParser()
# 测试串行执行时间
def test_sequential():
start_time = time.time()
# 串行执行3个任务
ai_summary = create_summary_chain(topics["ai_trend"]).invoke({})
energy_summary = create_summary_chain(topics["energy_trend"]).invoke({})
metaverse_summary = create_summary_chain(topics["metaverse_trend"]).invoke({})
end_time = time.time()
return end_time - start_time
# 测试并行执行时间
async def test_parallel():
start_time = time.time()
# 并行执行
result = await full_chain.ainvoke({})
end_time = time.time()
return end_time - start_time, result
# 运行对比测试
if __name__ == "__main__":
# 串行时间
sequential_time = test_sequential()
print(f"串行执行时间:{sequential_time:.2f}秒")
# 并行时间
parallel_time, final_report = asyncio.run(test_parallel())
print(f"并行执行时间:{parallel_time:.2f}秒")
print(f"\n并行生成的最终报告:\n{final_report}")3. 结果分析
- 预期效果:并行执行时间约为串行的1/3(因3个任务并发);
- 核心优势:无依赖任务的并发执行大幅缩短总耗时;
- 注意事项:并行执行会增加并发API调用,需注意模型的QPS限制。
四、关键要点总结
- 并行化的核心是"识别无依赖子任务",避免强行并行有依赖的任务;
- LangChain的RunnableParallel支持字典形式定义并行任务,结果自动对齐;
- 适合IO密集型任务(如API调用、信息检索),CPU密集型任务需结合多进程。
课时11-12:反思(Reflection)------ 生产者-批评者模型实现自优化
一、核心学习内容
1. 反思模式的核心逻辑:迭代纠错
反思模式通过"生产者-批评者"双智能体架构,实现输出的迭代优化:
- 生产者(Producer):生成初始输出(如代码、文案、方案);
- 批评者(Critic):根据目标标准评估输出,提出具体改进建议;
- 迭代循环:生产者根据批评意见修正输出,直到满足要求。
解决的核心问题:单一智能体生成的输出可能存在错误、不完整或不符合要求,缺乏自我纠错能力。
2. 反思模式的关键组件
- 目标标准:明确输出的评估维度(如代码的语法正确性、文案的流畅度);
- 批评者提示:引导LLM聚焦评估要点,避免泛泛而谈;
- 迭代终止条件:设定最大迭代次数或"完美输出"标识(如"CODE_IS_PERFECT")。
3. 适用场景
- 代码生成与调试;
- 文案优化(如营销文案、学术写作);
- 方案规划(如项目计划、策略制定)。
二、可视化:反思模式迭代流程图
是
否
达到最大迭代次数
开始
生产者:根据建议优化输出
批评者:评估输出+提出改进建议
是否满足要求?
输出最终结果
三、实践任务:构建代码生成与纠错智能体
1. 功能需求
- 生成满足特定需求的Python函数(计算阶乘);
- 自动检测语法错误、边界条件遗漏等问题;
- 迭代修正,直到生成无错误的代码。
2. 完整代码实现
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage, HumanMessage
# 加载环境变量
load_dotenv()
llm = ChatOpenAI(model="gpt-4o-mini", temperature=0.1)
# 定义任务目标(计算阶乘的Python函数)
task_prompt = """
创建一个名为calculate_factorial的Python函数,要求:
1. 仅接受一个整数参数n;
2. 计算n的阶乘(n! = 1×2×...×n,0! = 1);
3. 包含清晰的docstring;
4. 处理边界条件:n=0时返回1;
5. 处理无效输入:n为负数时抛出ValueError。
"""
# 定义批评者提示(代码审查)
critic_prompt = ChatPromptTemplate.from_messages([
SystemMessage(content="""
你是资深Python工程师,负责审查代码是否满足所有要求:
1. 语法是否正确(无语法错误);
2. 是否处理边界条件(n=0);
3. 是否处理无效输入(负数);
4. 是否包含docstring;
5. 功能是否正确(计算阶乘)。
若完全满足要求,仅输出'CODE_IS_PERFECT';否则,用项目符号列出具体问题。
"""),
HumanMessage(content="原始任务:{task}\n\n待审查代码:{code}")
])
# 反思迭代循环
def run_reflection_loop(max_iterations=3):
current_code = ""
message_history = [HumanMessage(content=task_prompt)]
for i in range(max_iterations):
print(f"\n=== 迭代第{i+1}次 ===")
# 生产者:生成/优化代码
if i == 0:
print("→ 生成初始代码...")
response = llm.invoke(message_history)
current_code = response.content
else:
print("→ 根据批评优化代码...")
message_history.append(HumanMessage(content="请根据以下批评意见优化代码:\n{critique}".format(critique=critique)))
response = llm.invoke(message_history)
current_code = response.content
print(f"生成的代码:\n{current_code}")
message_history.append(response)
# 批评者:评估代码
print("→ 审查代码...")
critique_response = llm.invoke(critic_prompt.format(task=task_prompt, code=current_code))
critique = critique_response.content
print(f"批评意见:\n{critique}")
# 终止条件
if "CODE_IS_PERFECT" in critique:
print("→ 代码满足所有要求,终止迭代!")
break
message_history.append(HumanMessage(content=f"批评意见:{critique}"))
return current_code
# 运行反思循环
final_code = run_reflection_loop()
print(f"\n=== 最终优化后的代码 ===")
print(final_code)3. 运行结果示例
- 第1次迭代:生成的代码可能遗漏负数处理;
- 第2次迭代:批评者指出"未处理负数输入",生产者优化代码添加异常抛出;
- 第3次迭代:批评者确认所有要求满足,输出"CODE_IS_PERFECT",终止迭代。
四、关键要点总结
- 反思模式的核心是"明确评估标准",批评者提示需具体、可落地;
- 迭代次数需合理设置(通常3-5次),避免无限循环;
- 适合对输出质量要求高的场景,但会增加LLM调用次数,需权衡成本与质量。
总结:基础执行模式的核心价值与应用场景
一、四大模式对比总结表
| 模式 | 核心思想 | 解决问题 | 关键组件 | 适用场景 |
|---|---|---|---|---|
| 提示链 | 分而治之 | 复杂任务拆解 | PromptTemplate、LCEL | 多步骤流程(如报告生成) |
| 路由 | 动态分流 | 多样化请求处理 | 路由器、分支逻辑 | 客服、请求分发 |
| 并行化 | 并发执行 | 效率提升 | RunnableParallel | 多源信息收集、多方案生成 |
| 反思 | 迭代纠错 | 输出质量优化 | 生产者、批评者 | 代码生成、文案优化 |
二、学习建议与进阶方向
- 基础优先级:先掌握提示链(流程拆解)和路由(动态决策),再学习并行化(效率优化)和反思(质量优化);
- 框架选择:LangChain适合快速原型开发,Google ADK适合企业级部署;
- 进阶方向:将四大模式组合使用(如"提示链+并行化+反思"),构建更复杂的智能体系统。
三、最终框架图:基础执行模式的协同关系
复杂任务输入
提示链:拆解为子任务
路由:分流子任务到对应节点
并行化:并发执行无依赖子任务
反思:优化各节点输出
汇总结果:生成最终响应