YOLO模型精度优化需要从数据、模型、训练三个核心层次系统性提升 YOLO 模型精度,这是解决 "精度不达标、漏检 / 误检多、定位不准" 等问题的核心思路。以下是分层次、可落地的优化方案(以 YOLOv8 为例,v5 通用)。
核心优化逻辑
模型精度的瓶颈往往不是单一环节导致的,需按 "先数据、再模型、最后训练" 的顺序优化(数据决定精度上限,模型和训练只是逼近这个上限):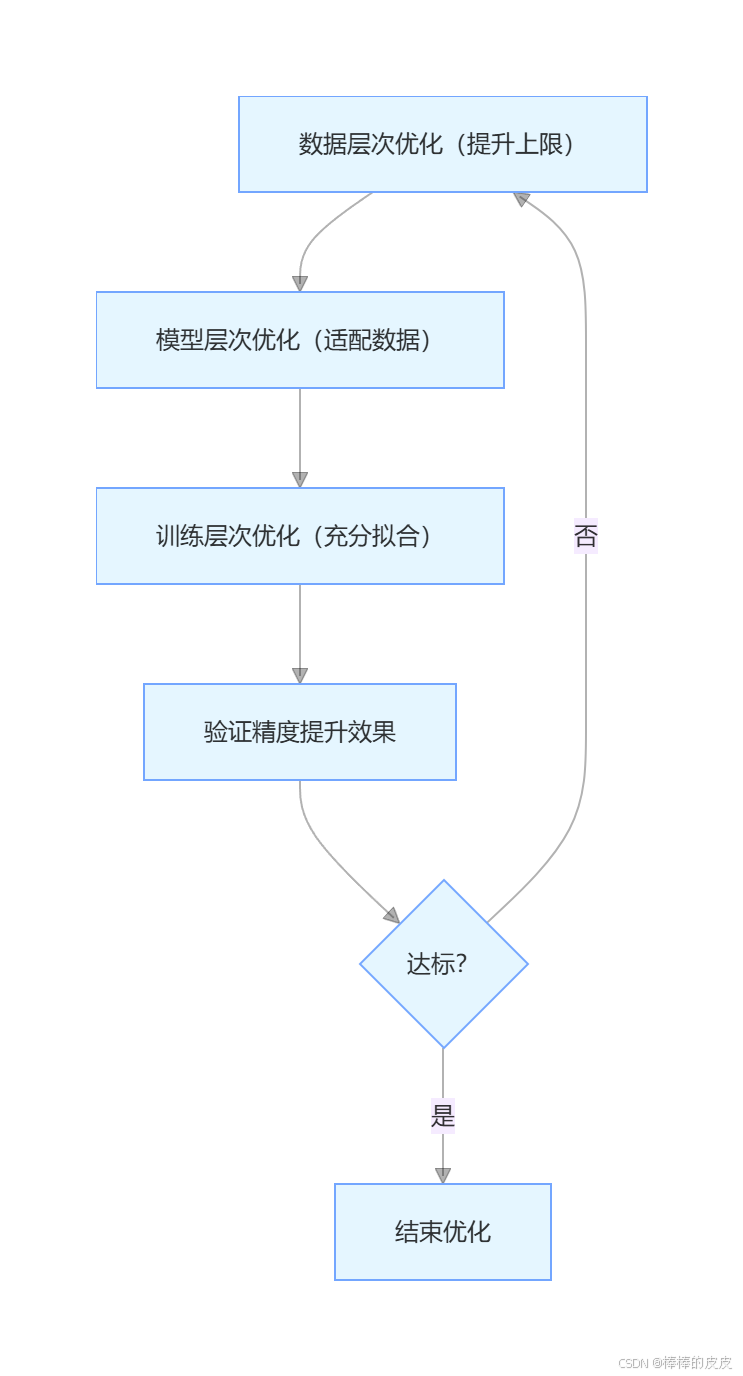
一、数据层次优化(最核心,优先做)
数据是模型的 "学习素材",数据质量 / 数量 / 分布直接决定精度上限,这一步优化的投入产出比最高。
1. 数据数量扩充(解决 "样本不足")
| 场景 |
优化方案 |
实操方法 |
| 小数据集(单类别<200 张) |
扩充真实样本 |
1. 爬取同场景目标图片(如爬虫 / 公开数据集);2. 采集不同角度 / 光照 / 背景的目标(如用手机多角度拍摄);3. 合并公开数据集子集(如 COCO 中同类目标补充)。 |
| 无法采集更多真实样本 |
智能数据增强(避免过拟合) |
1. 开启 YOLO 内置增强:mosaic=1.0 + mixup=0.3 + copy_paste=0.2;2. 自定义增强:用 Albumentations 库添加高斯噪声、随机裁剪、色彩抖动;3. 小目标专属:增加缩放增强(scale=0.8),放大小目标。 |
2. 数据质量提升(解决 "标注 / 样本差")
| 问题类型 |
优化方案 |
实操方法 |
| 标注错误(漏标 / 错标 / 框不准) |
数据集质检 + 修正 |
1. 用 YOLO 工具检查标注:yolo data check data.yaml;2. 可视化标注:绘制目标框与图片叠加图,人工核对;3. 修正规则: - 框不准:紧贴目标边缘,不包含多余背景; - 错标:统一类别名称(如 "猫"≠"猫咪"); - 漏标:补全所有目标标注。 |
| 样本质量差(模糊 / 过曝 / 过暗) |
过滤低质量样本 |
1. 人工筛选:删除严重模糊、目标占比<5% 的图片;2. 自动筛选:用 OpenCV 计算图片清晰度(方差<100 视为模糊),批量过滤;3. 图像修复:对轻微模糊 / 低光图片,用 Retinex 算法增强对比度。 |
3. 数据分布优化(解决 "分布不均")
| 问题类型 |
优化方案 |
实操方法 |
| 类别不平衡(某类样本占比>80%) |
重采样 + 损失加权 |
1. 重采样:训练时对少样本类别加权采样(smote=True);2. 损失加权:在配置文件中设置cls_weights(如少样本类别权重设为 2);3. 扩充少样本类别:优先采集少样本类别的真实样本。 |
| 目标尺寸分布不均(小目标占比>70%) |
适配小目标 |
1. 输入尺寸调大:imgsz=800/1024(32 的倍数);2. 锚框重新聚类:anchor=auto(让锚框适配小目标尺寸);3. 降低马赛克增强比例:mosaic=0.5-0.7(避免小目标被切割)。 |
数据层次优化实操脚本(样本筛选)
import cv2
import os
import shutil
# 筛选清晰图片(方差阈值筛选)
def is_image_clear(img_path, threshold=100):
img = cv2.imread(img_path, 0) # 灰度图
laplacian = cv2.Laplacian(img, cv2.CV_64F)
variance = laplacian.var()
return variance > threshold
# 筛选目标占比≥5%的图片(基于标注文件)
def is_object_enough(label_path, img_w, img_h, min_ratio=0.05):
if not os.path.exists(label_path):
return False
with open(label_path, 'r') as f:
lines = f.readlines()
for line in lines:
_, x, y, w, h = map(float, line.strip().split())
obj_w = w * img_w
obj_h = h * img_h
obj_area = obj_w * obj_h
img_area = img_w * img_h
if obj_area / img_area >= min_ratio:
return True
return False
# 批量筛选
img_dir = "datasets/images/train"
label_dir = "datasets/labels/train"
save_dir = "datasets/filtered_images/train"
os.makedirs(save_dir, exist_ok=True)
for img_file in os.listdir(img_dir):
if not img_file.endswith(('.jpg', '.png')):
continue
img_path = os.path.join(img_dir, img_file)
label_file = os.path.splitext(img_file)[0] + ".txt"
label_path = os.path.join(label_dir, label_file)
# 读取图片尺寸
img = cv2.imread(img_path)
h, w = img.shape[:2]
# 筛选条件
if is_image_clear(img_path) and is_object_enough(label_path, w, h):
shutil.copy(img_path, os.path.join(save_dir, img_file))
shutil.copy(label_path, os.path.join(save_dir.replace("images", "labels"), label_file))
print("数据筛选完成,保留清晰且目标占比达标的样本!")
二、模型层次优化(适配数据,释放潜力)
模型层次优化是让模型 "更好地学习数据特征",核心是选对模型规模、优化网络结构、适配目标特性。
1. 模型规模选择(基础优化)
| 精度需求 |
模型选择 |
适配硬件 |
实操命令 |
| 通用场景(平衡精度 / 速度) |
YOLOv8s → YOLOv8m |
GPU≥6G |
yolo detect train model=yolov8m.pt |
| 高精度需求(无速度约束) |
YOLOv8m → YOLOv8l/YOLOv8x |
GPU≥8G |
yolo detect train model=yolov8l.pt |
| 小目标密集场景 |
YOLOv8s(优先)+ 小目标适配 |
GPU≥6G |
结合锚框聚类 + 大输入尺寸 |
2. 网络结构优化(进阶)
| 优化方向 |
核心思路 |
实操方法 |
| 提升小目标检测能力 |
增强浅层特征(小目标在浅层) |
1. 保留更多浅层特征图(如 YOLOv8 的 P2 层);2. 开启多尺度融合:multi_scale=True;3. 增加浅层卷积核数量(需修改模型配置文件)。 |
| 提升定位精度 |
优化坐标预测 |
1. 使用 CIoU/DIoU 损失(YOLOv8 默认,无需改);2. 增加 box_loss 权重:box=0.05→0.08;3. 锚框重新聚类:anchor=auto。 |
| 提升类别分类精度 |
增强特征提取 |
1. 更换骨干网络:如用 EfficientNet 替换 CSPDarknet(需改配置);2. 增加注意力机制:添加 CBAM/SE 模块(YOLOv8 可通过插件集成)。 |
3. 模型轻量化与精度平衡(部署友好)
若需兼顾精度和速度,可采用 "知识蒸馏":
# 用YOLOv8l(教师模型)蒸馏YOLOv8s(学生模型)
yolo detect train \
model=yolov8s.pt \
data=data.yaml \
epochs=50 \
distill=yolov8l.pt \ # 教师模型权重
imgsz=640
三、训练层次优化(充分拟合,逼近上限)
训练层次优化是让模型 "把数据中的特征学透",核心是调优超参数、优化训练策略,避免过拟合 / 欠拟合。
1. 超参数调优(核心)
| 问题类型 |
超参数调整 |
实操示例 |
| 过拟合(训练集精度高,验证集低) |
增强正则化 |
1. 权重衰减:weight_decay=0.0005→0.001;2. Dropout:dropout=0.0→0.1-0.2;3. 早停:patience=5(5 轮精度不涨则停止);4. 减少训练轮次:epochs=100→80。 |
| 欠拟合(训练 / 验证集精度都低) |
增强拟合能力 |
1. 学习率:lr0=0.01→0.008(小幅调低,避免震荡);2. 批次大小:batch=16→32(显存足够时);3. 训练轮次:epochs=50→100;4. 关闭正则化:weight_decay=0.001→0.0005。 |
| 训练震荡(损失曲线波动大) |
稳定训练 |
1. 学习率预热:warmup_epochs=3→5;2. 梯度累加:accumulate=2(显存不足时替代大 batch);3. 优化器:SGD→AdamW(收敛更稳)。 |
2. 训练策略优化
| 策略 |
核心思路 |
实操方法 |
| 迁移学习(小数据集必备) |
利用预训练权重初始化 |
1. 加载官方预训练权重:model=yolov8s.pt(而非从头训练);2. 冻结骨干网络:freeze=10(前 10 层冻结,先训练头部);3. 解冻后微调:训练 10 轮后解冻,调低学习率(lr0=0.001)继续训练。 |
| 多尺度训练 |
提升模型对不同尺寸目标的适应能力 |
1. 开启多尺度:imgsz=[480,640,800];2. 关闭矩形训练:rect=False(随机尺寸)。 |
| 混合精度训练 |
加速训练,不损失精度 |
1. 开启 AMP:amp=True(YOLOv8 默认开启);2. 需安装 NVIDIA Apex(可选)。 |
训练层次优化实操配置文件
# 训练优化配置文件(anti_overfit_config.yaml)
model: yolov8s.pt
data: data.yaml
epochs: 80
batch: 16
imgsz: 640
# 学习率优化
lr0: 0.008
lrf: 0.01
warmup_epochs: 5
cos_lr: True # 余弦学习率退火
# 正则化(防过拟合)
weight_decay: 0.001
dropout: 0.15
patience: 8 # 早停耐心值
# 优化器
optimizer: AdamW
momentum: 0.937
# 训练策略
freeze: 10 # 冻结前10层
multi_scale: True # 多尺度训练
amp: True # 混合精度训练
3. 后处理优化(提升最终检测效果)
| 优化点 |
核心思路 |
实操方法 |
| NMS 优化(减少重复框) |
提升框的筛选精度 |
1. 改用 DIoU-NMS:nms_mode='diou';2. 调整 NMS 阈值:iou_thres=0.45→0.35(密集目标)。 |
| 置信度阈值调整 |
平衡漏检 / 误检 |
1. 漏检多:conf_thres=0.3→0.2;2. 误检多:conf_thres=0.3→0.4。 |
四、精度优化实操流程(按优先级)
- 数据质检与修正:先用工具检查标注错误,修正框不准 / 错标 / 漏标问题(1 天内可完成);
- 数据扩充与增强:扩充真实样本 + 开启智能增强(小数据集必做);
- 基础训练调优:用默认配置 + 预训练权重跑基线,查看指标;
- 针对性优化 :
- 过拟合:调正则化 + 早停;
- 欠拟合:调学习率 + 增加训练轮次;
- 小目标漏检:调输入尺寸 + 锚框聚类 + 降低马赛克;
- 进阶优化:知识蒸馏 / 注意力机制(精度仍不达标时);
- 验证效果:重新评估 mAP@0.5/mAP@0.5:0.95,确认精度提升。
五、常见精度问题与对应优化方案(速查表)
| 问题现象 |
核心原因 |
优先优化层次 |
具体方案 |
| 小目标漏检多(Recall 低) |
小目标特征未被捕捉 |
数据层 → 模型层 → 训练层 |
1. 调大 imgsz(800/1024);2. anchor=auto 聚类锚框;3. mosaic=0.5-0.7;4. 扩充小目标样本。 |
| 误检多(Precision 低) |
背景复杂 / 类别特征混淆 |
数据层 → 训练层 → 后处理 |
1. 增加背景样本;2. 调高 conf_thres;3. 增加类别损失权重;4. DIoU-NMS 替换普通 NMS。 |
| 定位不准(mAP@0.5:0.95 低) |
坐标损失高 / 锚框不匹配 |
模型层 → 训练层 |
1. 增加 box_loss 权重;2. anchor=auto;3. 减少透视变换增强;4. 改用 CIoU 损失。 |
| 类别分类错误(混淆矩阵差) |
类别样本不平衡 / 特征相似 |
数据层 → 训练层 |
1. 扩充少样本类别;2. 设置 cls_weights 加权;3. 增强类别特征提取(SE 模块);4. 降低学习率微调。 |
| 过拟合(训练集精度远高于验证集) |
样本少 / 正则化弱 |
数据层 → 训练层 |
1. 开启 mixup/copy_paste;2. 增加 weight_decay/dropout;3. 早停策略;4. 扩充样本。 |
总结
核心优化要点
- 数据层:优先解决标注错误、样本不足、分布不均,这是精度提升的核心;
- 模型层:小数据集选中等模型(YOLOv8s/m),小目标场景适配锚框和输入尺寸;
- 训练层:用迁移学习避免从头训练,正则化防过拟合,学习率调优防震荡。
优化原则
- 小步迭代:每次只改 1-2 个优化点,验证效果后再调整,避免多变量无法定位;
- 先易后难:先做数据层优化(低成本高收益),再做模型 / 训练层优化;
- 平衡精度与速度:不要盲目追大模型,需兼顾部署场景的速度要求。