读写分离架构,分散了数据库读写操作的压力,但无论是主库还是从库,都管理着一个完整的数据库。由于关系型数据库大多采用 B+ 树类型的索引,随着系统的运行,单个表中的数据也会不断增长,从而导致索引深度(树高)的增加,使得磁盘访问的 IO 次数增加,进而导致查询性能的下降; 同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。为了满足业务数据存储的需求,就需要将数据分散到多台数据库服务器上。
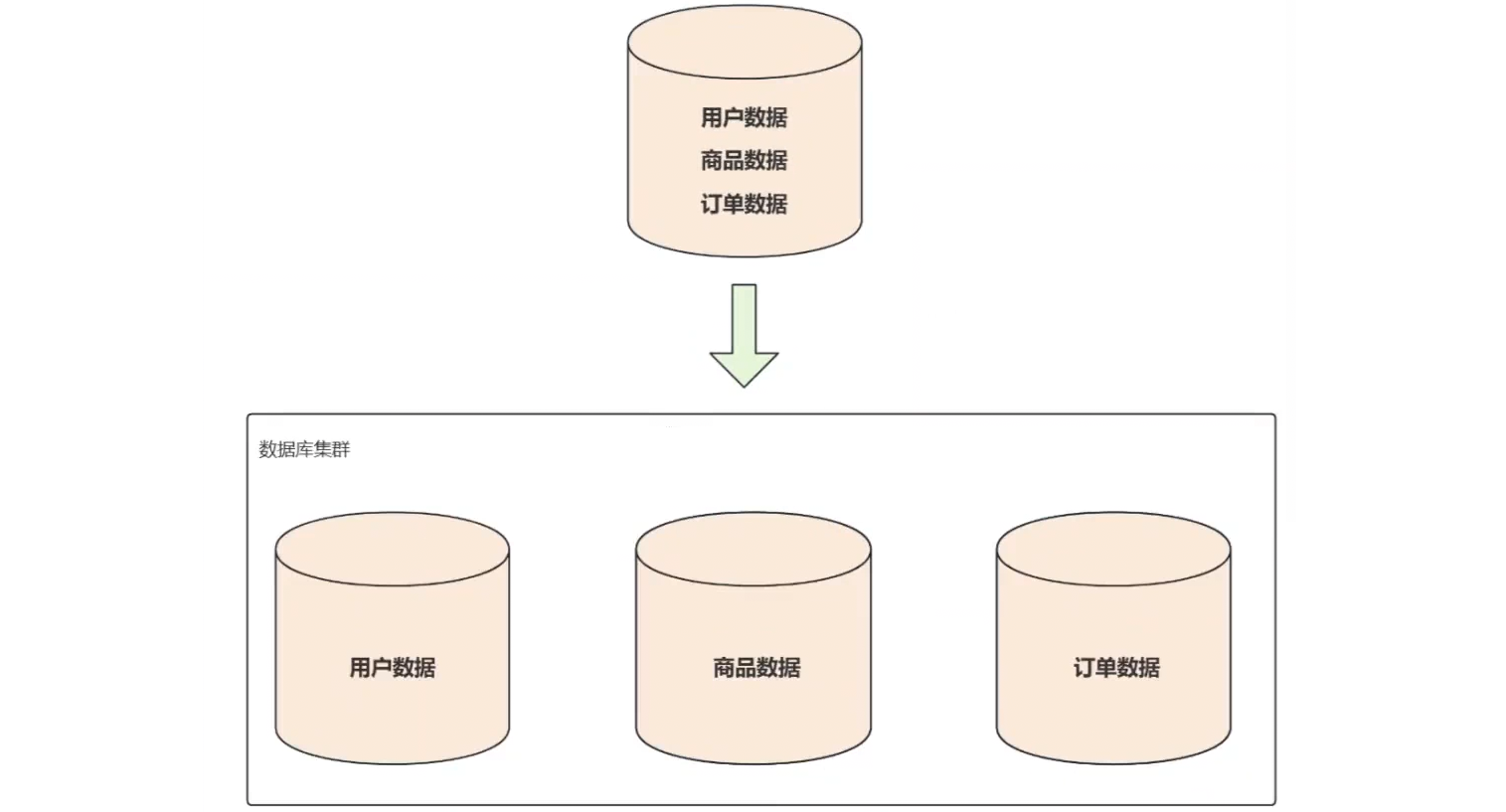
数据分片指按照某个维度将存放在单一数据库中的数据分散地存放至多个数据库或表中以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库 和分表 。数据分片的拆分方式又分为垂直分片 和水平分片。
一.垂直分片
按照业务 拆分的方式称为垂直分片 ,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。
应用场景
随着应用程序不断的迭代,功能越来越多,业务的复杂度越来越高,一个数据库中包含所有业务的表已不能满足性能的要求,就需要降低数据库的压力,让单个数据库只负责存储某个或几个功能对应的表,也就是说把不同业务功能对应的表分散到不同的数据库当中,也可以理解为专库专用,从而减轻单个数据库服务的压力。以电商平台为例,可以将其划分为用户模块、订单模块、商品模块等,并将每个模块的数据存储在不同的数据库中。
不同的业务功能访问不同的数据库即可,有效分担了单库的负载,而且相互之间互不干扰。重直分库之后还可以为每个分库部署主从复制和读写分离。
下面给出垂直分库的实例。
1.创建 Docker 容器
1)创建server-user容器
bash
docker run -d \
-p 53310:3306 \
-v /mysql/user/conf:/etc/mysql/conf.d \
-v /mysql/user/mysql:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name server-user \
mysql:8.0.38更改 root 密码:
bash
# 进入Docker容器,env LANG=C.UTF-8避免中文乱码问题
docker exec -it server-user env LANG=C.UTF-8 /bin/bash
# 运行Mysql客户端
mysql -uroot -p
# 修改root用户密码
mysql> SET PASSWORD = '123456';创建数据库:
sql
-- 创建数据库
create database if not exists user_db character set utf8mb4 collate
utf8mb4_0900_ai_ci;
-- 选择数据库
use user_db;
-- 创建⽤⼾表
create table if not exists t_user (
id bigint primary key auto_increment,
name varchar(20)
);2)创建server-order容器
bash
docker run -d \
-p 53311:3306 \
-v /mysql/order/conf:/etc/mysql/conf.d \
-v /mysql/order/mysql:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name server-order \
mysql:8.0.38更改 root 密码:
bash
# 进入Docker容器,env LANG=C.UTF-8避免中文乱码问题
docker exec -it server-order env LANG=C.UTF-8 /bin/bash
# 运行Mysql客户端
mysql -uroot -p
# 修改root用户密码
mysql> SET PASSWORD = '123456';创建数据库:
sql
-- 创建数据库
create database if not exists order_db character set utf8mb4 collate
utf8mb4_0900_ai_ci;
-- 选择数据库
use order_db;
-- 创建订单表
create table if not exists t_order (
id bigint primary key auto_increment,
order_no varchar(30) comment '订单号',
amount decimal(12, 2) comment '订单金额',
user_id bigint comment '用户编号'
);2.垂直分库配置
数据分片需要配置的文件是: conf/config-sharding.yaml
1)配置数据源
bash
# 在MySQL部分配置如下内容
databaseName: sharding_db # ShardinSphere逻辑库名
# 数据库
dataSources:
server_user: # User数据源名
url: jdbc:mysql://你的云服务器的IP地址:53310/user_db?characterEncoding=utf8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
server_order: # Order数据源名
url: jdbc:mysql://你的云服务器的IP地址:53311/order_db?characterEncoding=utf8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 12)配置分片规则
bash
rules:
- !SHARDING
tables:
t_user: # 逻辑表名
actualDataNodes: server_user.t_user # 由数据源名 + 表名组成
t_order: # 逻辑表名
actualDataNodes: server_order.t_orderactualDataNodes :真实数据节点,由于垂直分库把不同的表分散在了不同的数据器上,要指定具体的数据节点,可以使用 数据源.表名 的方式。
3.测试
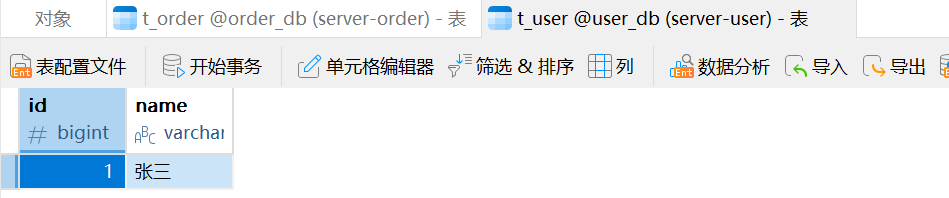
我们预期的结果是在 ShardingSphere 中插入数据,往t_user 表中插入的数据会放到 server_user 中,往 t_order 表中插入的数据会放到 server_order 中。
在 ShardingSphere 插入数据:
sql
-- 向t_user表中插入数据
insert into t_user(name) values ('张三');
-- 向t_order 表中插入数据
insert into t_order (order_no, user_id, amount) values ('KaKa001', 1, 20.00);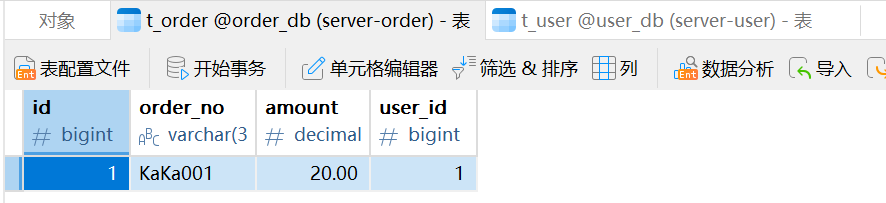
二.水平分片
水平分片 又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分,从而减轻单库或单表的访问压力。
应用场景
随着系统运行时间越来越久,各功能产生的数据也越来越多,单个数据表中的数据量不断增长,B+树的树高也会不断增长,这时当重直分库就遇到了性能瓶颈。为了降低树高,稳定查询效率,就要考虑进行水平分片,把一个表中的数据拆分到多个相同的表中,每个分片只保存表中一部分数据,从而提升数据库的性能。
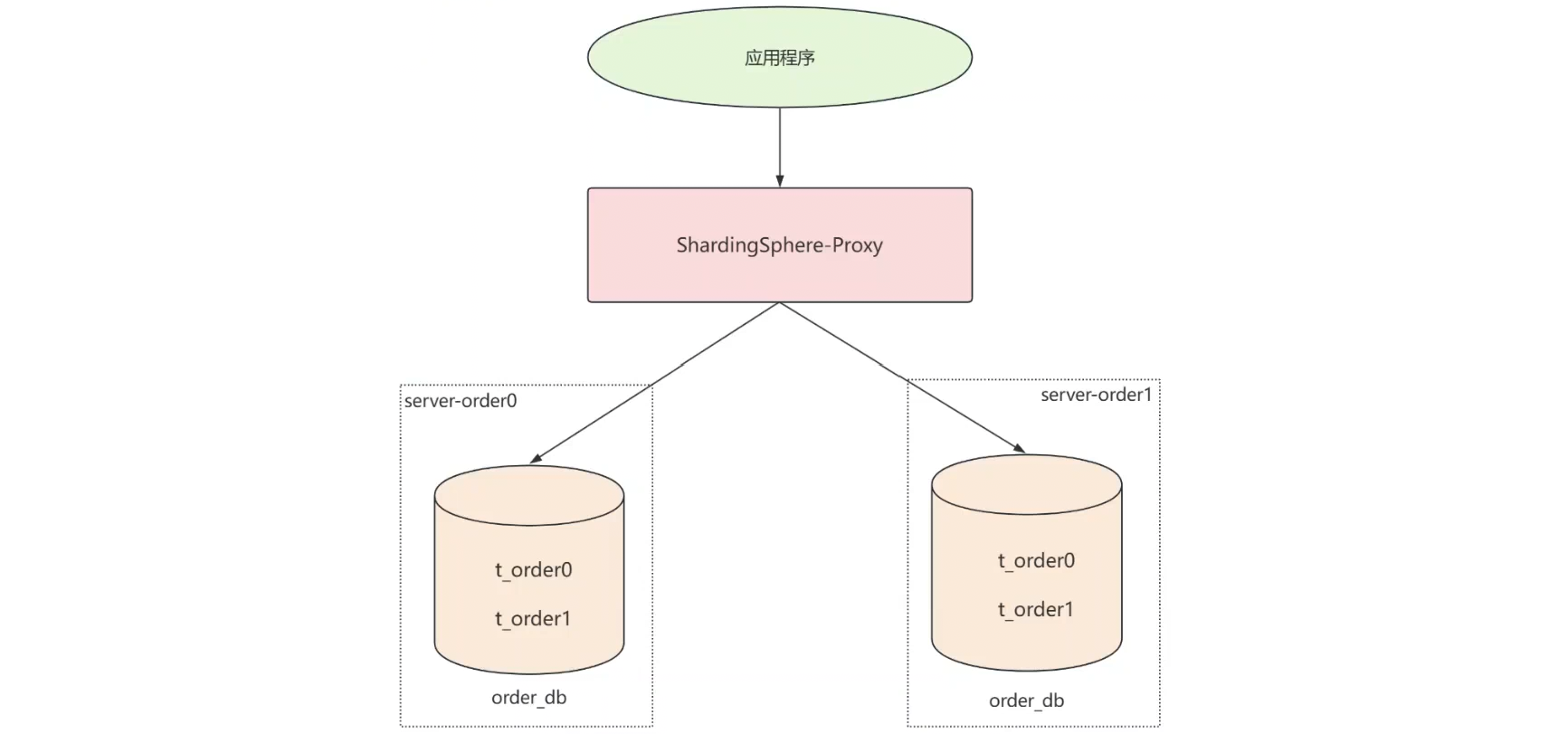
在前面重直分库实践的础上, server-order 节点中 t_order 表的的存储压力不断增大,这时就需要对 t_order 表进行横向拆分,也就是水平分片,具体的实现方式是:用多个数据节点替换原来的单一数据节点。
1.创建容器
bash
# 创建server-order0,注意修改相应的容器名、端口号和映射路径
docker run -d \
-p 63310:3306 \
-v /mysql/order0/conf:/etc/mysql/conf.d \
-v /mysql/order0/mysql:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name server-order0 \
--restart always \
mysql:8.0.38
# 创建server-order1,注意修改相应的容器名、端口号和映射路径
docker run -d \
-p 63311:3306 \
-v /mysql/order1/conf:/etc/mysql/conf.d \
-v /mysql/order1/mysql:/var/lib/mysql \
-e MYSQL_ROOT_PASSWORD=123456 \
--name server-order1 \
--restart always \
mysql:8.0.38修改 root 密码:
bash
# 进入Docker容器,env LANG=C.UTF-8避免中文乱码问题
docker exec -it server-order0 env LANG=C.UTF-8 /bin/bash
# 运行Mysql客户端
mysql -uroot -p
# 修改root用户密码
mysql> SET PASSWORD = '123456';给 server-order0 和 server-order1 都创建数据库:
sql
-- 创建数据库
create database if not exists order_db character set utf8mb4 collate utf8mb4_0900_ai_ci;
-- 选择数据库
use order_db;
-- 创建订单表t_order0
create table if not exists t_order0 (
id bigint primary key,
order_no varchar(30) comment '订单号',
amount decimal(12, 2) comment '订单金额',
user_id bigint comment '用户编号'
);
-- 创建订单表t_order1
create table if not exists t_order1 (
id bigint primary key,
order_no varchar(30) comment '订单号',
amount decimal(12, 2) comment '订单金额',
user_id bigint comment '用户编号'
);2.数据节点配置
数据节点配置与可以称为标准分片表配置:
1)配置数据源
数据分片需要配置的文件是: conf/config-sharding.yaml ,配置 server_user 、 server_order0 、 server_order1 三个数据源。
bash
# 逻辑库
databaseName: sharding_db
# 数据源
dataSources:
server_user:
url: jdbc:mysql://你的云服务器的IP地址:53310/user_db?characterEncoding=utf8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
server_order0:
url: jdbc:mysql://你的云服务器的IP地址:63310/order_db?characterEncoding=utf8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 1
server_order1:
url: jdbc:mysql://你的云服务器的IP地址:63311/order_db?characterEncoding=utf8&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true&useSSL=false
username: root
password: 123456
connectionTimeoutMilliseconds: 30000
idleTimeoutMilliseconds: 60000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 50
minPoolSize: 12)配置数据节点
每个 t_order 表都是一个数据节点,当前 t_order 表分布如下:
|------------------------|
| server_order0.t_order0 |
| server_order0.t_order1 |
| server_order1.t_order0 |
| server_order1.t_order1 |
修改 rules 节点,使用行表达式对 t_order 表进行水平分库配置:
bash
# 规则配置
rules:
# 分片配置
- !SHARDING
tables: # 逻辑表配置
t_user: # 逻辑表名
actualDataNodes: server_user.t_user # 真实数据节点
t_order: # 逻辑表名
actualDataNodes: server_order${0..1}.t_order${0..1} # 真实数据节点注意,此时你尝试插入数据会报错,原因是现在还没有设置分库。
3.分库配置
1)配置分库策略
根据订单记录中的 user_id 来确定数据写入哪个数据节点:
bash
# 规则配置
rules:
# 分片配置
- !SHARDING
tables: # 逻辑表配置
t_user: # 逻辑表名
actualDataNodes: server_user.t_user # 真实数据节点
t_order: # 逻辑表名
actualDataNodes: server_order${0..1}.t_order${0..1} # 真实数据节点
databaseStrategy: # 分库策略
standard: # 用于单分片键的标准分片场景
shardingColumn: user_id # 分片列名称
shardingAlgorithmName: alg_db_inline_userid # 分片算法名称(自定义)2)行表达式分片算法
订单表中 user_id % 2 来确定当前记录写入哪个数据库:
bash
# 规则配置
rules:
# 分片配置
- !SHARDING
tables: # 逻辑表配置
t_user: # 逻辑表名
actualDataNodes: server_user.t_user # 真实数据节点
t_order: # 逻辑表名
actualDataNodes: server_order${0..1}.t_order${0..1} # 真实数据节点
databaseStrategy: # 分库策略
standard: # 用于单分片键的标准分片场景
shardingColumn: user_id # 分片列名称
shardingAlgorithmName: alg_db_inline_userid # 分片算法名称
# 分片算法配置
shardingAlgorithms:
alg_db_inline_userid: # 前面定义的分片算法名称
type: INLINE # 分片算法类型
props:
algorithm-expression: server_order${user_id % 2} # 分片算法,根据user_id对2取模此时就能写入了吗?还不行。报错的原因是当前虽然根据 user_id 指定了分库策略,但是没有指定分表策略,也就是说当前不知道写入数据库中的 t_order0 表还是 t_order1 表。
4.分表配置
1)配置分表策略
还原数据节点的配置,根据订单记录中的 order_no 来确定数据写入哪个数据节点:
bash
# 规则配置
rules:
# 分片配置
- !SHARDING
tables: # 逻辑表配置
t_user: # 逻辑表名
actualDataNodes: server_user.t_user # 真实数据节点
t_order: # 逻辑表名
actualDataNodes: server_order${0..1}.t_order${0..1} # 真实数据节点
databaseStrategy: # 分库策略
standard: # 用于单分片键的标准分片场景
shardingColumn: user_id # 分片列名称
shardingAlgorithmName: alg_mod # 分片算法名称
tableStrategy: # 分表策略
standard:
shardingColumn: order_no # 分片列名称
shardingAlgorithmName: alg_hash_mod # 分片算法名称
# 分片算法配置
shardingAlgorithms:
alg_db_inline_userid: # 前面定义的分片算法名称
type: INLINE # 分片算法类型
props:
algorithm-expression: server_order${user_id % 2} # 分片算法,根据user_id对2取模
alg_mod:
type: MOD # 分片算法类型
props:
sharding-count: 2 # 分片数量,表示根据分片列对2取模
alg_hash_mod:
type: HASH_MOD # 分片算法类型
props:
sharding-count: 2 # 分片数量,表示根据分片列对2取模对上面的配置进行解释:
首先分库使用的分片算法是MOD,根据user_id进行分片。
然后分表使用的分片算法是HASH_MOD,根据order_no进行分片。
2)测试
此时已经完成了正确的配置,现在可以测试了。
执行插入语句:
sql
-- 每条记录的用户Id相同,订单号不同
insert into t_order (id, order_no, user_id, amount) values (1, 'KaKa001', 1,20.00);
insert into t_order (id, order_no, user_id, amount) values (2, 'KaKa002', 1,20.00);
insert into t_order (id, order_no, user_id, amount) values (3, 'KaKa003', 1,20.00);
insert into t_order (id, order_no, user_id, amount) values (4, 'KaKa004', 1,20.00);我们的预期结果:user_id 都是1,根据分片规则,这些数据都会路由到 server-order1 中;根据order_no 的不同,id=1,3的插入到了 t_order1 中,id=2,4的插入到了 t_order0 中。

执行结果是,这四条内容都插入到了server-order1中,并且id=1,3的插入到了t_order1中,id=2,4的插入到了t_order0中,符合我们的预期结果。
下面执行查询语句:
sql
select * from t_order;
可以看出 ShardinSphere 在所有的数据节点查询记录,并把各个节点的记录组装好,统一返回给客户端。
条件查询:
sql
select * from t_order where user_id = 1;
当查询条件中包含精准匹配的分片字段时,ShardingSphere 会通过分片规则计算并访问指定的数据节点(而非所有节点),从而提升查询效率;因此分片键应优先选择业务中高频用于等值查询、且能均匀分布数据的字段。
5.分片算法
官网对分片算法的介绍:数据分片 :: ShardingSphere
1)取模分片算法
bash
# 规则配置
rules:
# 分片配置
- !SHARDING
tables: # 逻辑表配置
t_user: # 逻辑表名
actualDataNodes: server_user.t_user # 真实数据节点
t_order: # 逻辑表名
actualDataNodes: server_order${0..1}.t_order0 # 真实数据节点
databaseStrategy: # 分库策略
standard: # 用于单分片键的标准分片场景
shardingColumn: user_id # 分片列名称
shardingAlgorithmName: alg_mod # 分片算法名称
# 分片算法配置
shardingAlgorithms:
alg_db_inline_userid: # 前面定义的分片算法名称
type: INLINE # 分片算法类型
props:
algorithm-expression: server_order${user_id % 2} # 分片算法,根据user_id对2取模
alg_mod:
type: MOD # 分片算法类型
props:
sharding-count: 2 # 分片数量,表示根据分片列对2取模2)HASH取模分片算法
bash
rules:
# 分片配置
- !SHARDING
tables: # 逻辑表配置
t_user: # 逻辑表名
actualDataNodes: server_user.t_user # 真实数据节点
t_order: # 逻辑表名
actualDataNodes: server_order${0..1}.t_order${0..1} # 真实数据节点
databaseStrategy: # 分库策略
standard: # 用于单分片键的标准分片场景
shardingColumn: user_id # 分片列名称
shardingAlgorithmName: alg_mod # 分片算法名称
tableStrategy: # 分表策略
standard:
shardingColumn: order_no # 分片列名称
shardingAlgorithmName: alg_mod # 分片算法名称
# 分片算法配置
shardingAlgorithms:
alg_db_inline_userid: # 前面定义的分片算法名称
type: INLINE # 分片算法类型
props:
algorithm-expression: server_order${user_id % 2} # 分片算法,根据user_id对2取模
alg_mod:
type: MOD # 分片算法类型
props:
sharding-count: 2 # 分片数量,表示根据分片列对2取模三.分布式序列算法
1.介绍
传统数据库软件开发中,主键自动生成技术是基本需求。而各个数据库对于该需求也提供了相应的支持,比如 MySQL 的自增键,Oracle 的自增序列等。 数据分片后,不同数据节点生成全局唯一主键是非常棘手的问题。同一个逻辑表内的不同实际表之间的自增键由于无法互相感知而产生重复主键。 虽然可通过约束自增主键初始值和步长的方式避免碰撞,但需引入额外的运维规则,使解决方案缺乏完整性和可扩展性。
目前有许多第三方解决方案可以完美解决这个问题,如 UUID 等依靠特定算法自生成不重复键,或者通过引入主键生成服务等。为了方便用户使用、满足不同用户不同使用场景的需求, ApacheShardingSphere 不仅提供了内置的分布式主键生成器,例如 UUID、SNOWFLAKE,还抽离出分布式主键生成器的接口,方便用户自行实现自定义的自增主键生成器。
UUID
UUID是ShardingSphere内置的分布式序列算法之一。可以生成时间、空间上都独一无二的值,但是由于UUID是无序的,不太适合作为数据库的主键。
雪花算法
ShardingSphere在分片规则配置模块可配置每个表的主键生成策略,默认使用雪花算法(snowflake)生成 64bit 的长整型数据。
雪花算法是由 Twitter 公布的分布式主键生成算法,它能够保证不同进程主键的不重复性,以及相同进程主键的有序性。
1)实现原理
在同⼀个进程中,首先是通过时间位保证不重复,如果时间相同则是通过序列位保证。 同时由于时间位是单调递增的,且各个服务器如果大体做了时间同步,那么生成的主键在分布式环境可以认为是总体有序的,这就保证了对索引字段的插入的高效性。 例如 MySQL 的 Innodb 存储引擎的主键。
使用雪花算法生成的主键,二进制表示形式包含 4 部分,从高位到低位分别为:1bit 符号位、41bit 时间戳位、10bit 工作进程位以及 12bit 序列号位。如下图所示:
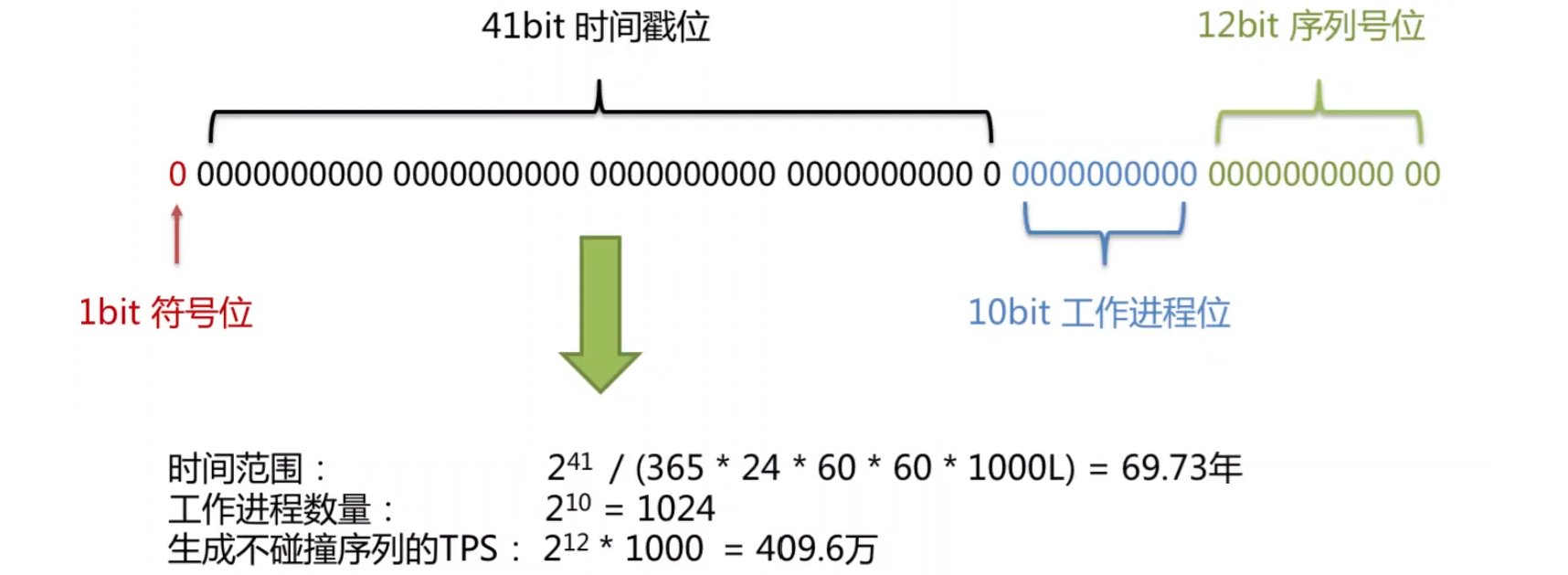
|--------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 符号位(1bit) | 预留的符号位,恒为零 |
| 时间戳位(41bit) | 41 位的时间戳可以容纳的毫秒数是 2 的 41 次幂,一年所使用的毫秒数是: 365 * 24 * 60 * 60 * 1000 。 通过计算可知: Math.pow(2, 41) / (365 * 24 * 60 * 60 * 1000L); 结果约等于 69.73 年。 Apache ShardingSphere 的雪花算法的时间纪元从 2016年11月1日 零点开始,可以使用到 2086 年,相信能满足绝大部分系统的要求 |
| 工作进程位(10bit) | 该标志在 Java 进程内是唯一的,如果是分布式应用部署应保证每个工作进程的 id 是不同的。 该值默认为 0,可通过属性设置 |
| 序列号位(12bit) | 该序列是用来在同一个毫秒内生成不同的 ID。如果在这个毫秒内生成的数量超过 4096 (2 的 12 次幂),那么生成器会等待到下个毫秒继续生成 |
2)时钟回拨
服务器时钟回拨会导致产生重复序列,因此默认分布式主键生成器提供了一个最大容忍的时钟回拨毫秒数。 如果时钟回拨的时间超过最大容忍的毫秒数阈值,则程序报错;如果在可容忍的范围内,默认分布式主键生成器会等待时钟同步到最后一次主键生成的时间后再继续工作。 最大容忍的时钟回拨毫秒数的默认值为 0,可通过属性设置。
2.分存式序列配置
bash
# 规则配置
rules:
# 分片配置
- !SHARDING
tables: # 逻辑表配置
t_user: # 逻辑表名
actualDataNodes: server_user.t_user # 真实数据节点
t_order: # 逻辑表名
actualDataNodes: server_order${0..1}.t_order${0..1} # 真实数据节点
# ... 省略
keyGenerateStrategy: # 分布式序列策略
column: id # 列名
keyGeneratorName: alg_snowflake # 分布式序列算法名
# 分片算法配置
shardingAlgorithms:
# ... 省略
# 分布式序列配置
keyGenerators:
alg_snowflake: # 分布式序列算法名
type: SNOWFLAKE # 分布式序列类型(雪花算法)注意这里加了两部分,一个是分布式序列策略,一个是分布式序列配置。
插入没有写主键的insert语句进行测试:
sql
-- user_id=1的订单
insert into t_order (order_no, user_id, amount) values ('KaKa001', 1, 20.00);
insert into t_order (order_no, user_id, amount) values ('KaKa002', 1, 20.00);
insert into t_order (order_no, user_id, amount) values ('KaKa003', 1, 20.00);
insert into t_order (order_no, user_id, amount) values ('KaKa004', 1, 20.00);

四.多表关联查询
在真实的业务中,订单通常与订单详情关联,订单详情记录用户购买商品的单价以及个数,订单与订单详情是⼀对多关系。
同时为了避免跨库关联,把同一个用户产生的订单数据以及订单详情数据存在同一个数据源中,因此两张表可以采用相同的分片策略。
订单详情表名为: t_order_item ,由于要与 t_order 采用相同的分片策略,所以也需要添加 order_no 和 user_id 两个分片键。
1.配置策略
t_order_item 的数据节点,分库策略,分表策略,分存式序列策略与 t_order 一致。
在 conf/config-sharding.yaml 配置文件中添加对 t_order_item 的配置项:
bash
# 规则配置
rules:
# 分片配置
- !SHARDING
tables: # 逻辑表配置
t_user: # 逻辑表名t_user
# ...省略
t_order: # 逻辑表名t_order
# 省略
t_order_item: # 逻辑表名t_order_item
actualDataNodes: server_order${0..1}.t_order_item${0..1} # 真实数据节点
databaseStrategy: # 分库策略
standard: # 用于单分片键的标准分片场景
shardingColumn: user_id # 分片列名称
# shardingAlgorithmName: alg_db_inline_userid # 分片算法名称(注释备用)
shardingAlgorithmName: alg_mod # 分片算法名称
tableStrategy: # 分表策略
standard:
shardingColumn: order_no # 分片列名称
shardingAlgorithmName: alg_hash_mod # 分片算法名称
keyGenerateStrategy: # 分布式序列策略
column: id # 列名
keyGeneratorName: alg_snowflake # 分布式序列算法名
# 分片算法配置
shardingAlgorithms:
# ...省略
alg_hash_mod:
type: HASH_MOD # 分片算法类型
props:
sharding-count: 2 # 分片数量,表示根据分片列对2取模
# 分布式序列配置
keyGenerators:
alg_snowflake: # 分布式序列算法名
type: SNOWFLAKE # 分布式序列类型(雪花算法)2.测试
分别在 server-order0 和 server-order1 服务器创建订单详情表 t_order_item0 和 t_order_item1 , 表结构如下:
sql
-- 创建订单详情t_order_item0
create table if not exists t_order_item0 (
id bigint primary key,
order_no varchar(30) comment '订单号',
user_id bigint comment '⽤⼾编号',
price decimal(12, 2) comment '商品单价',
count int comment '商品个数'
);
-- 创建订单详情t_order_item1
create table if not exists t_order_item1 (
id bigint primary key,
order_no varchar(30) comment '订单号',
user_id bigint comment '⽤⼾编号',
price decimal(12, 2) comment '商品单价',
count int comment '商品个数'
);为每个订单构造订单详情记录,SQL语句如下:
sql
-- 订单号KaKa001, 用户编号 1
insert into t_order_item (order_no, user_id, price, count) values ('KaKa001',1, 10, 3);
insert into t_order_item (order_no, user_id, price, count) values ('KaKa001',1, 10, 3);
insert into t_order_item (order_no, user_id, price, count) values ('KaKa001',1, 10, 3);
-- 订单号KaKa002
insert into t_order_item (order_no, user_id, price, count) values ('KaKa002',1, 10, 3);
insert into t_order_item (order_no, user_id, price, count) values ('KaKa002',1, 10, 3);
insert into t_order_item (order_no, user_id, price, count) values ('KaKa002',1, 10, 3);
-- 订单号KaKa003
insert into t_order_item (order_no, user_id, price, count) values ('KaKa003',1, 10, 3);
insert into t_order_item (order_no, user_id, price, count) values ('KaKa003',1, 10, 3);
insert into t_order_item (order_no, user_id, price, count) values ('KaKa003',1, 10, 3);
-- 订单号KaKa004
insert into t_order_item (order_no, user_id, price, count) values ('KaKa004',1, 10, 3);
insert into t_order_item (order_no, user_id, price, count) values ('KaKa004',1, 10, 3);
insert into t_order_item (order_no, user_id, price, count) values ('KaKa004',1, 10, 3);进行关联查询:
sql
-- 查询所有订单和详情信息
select * from t_order o, t_order_item i where o.order_no = i.order_no;关联查询时,使用分片键进行表关联,为了后面使用绑定表,ShardinSphere可以根据分片策略帮我们自动路由到对应的数据节点。
也可以使用订单号进行关联,但是ShardinSphere无法感知到目标数据在哪个数据节点,会在所有数据源中进行查询,对效率的影响比较大。
3.绑定表
为了提升效率,规避无效查询,可以设置绑定表,告诉ShardinSphere哪些表需要通过分片规则进行路由。需要绑定的表分片规则必须一致,查询时必须使用分片键进行关联,否则会出现笛卡尔积关联或跨库关联,从而影响效率。修改配置文件,添加绑定表规则:
bash
# 规则配置
rules:
# 分片配置
- !SHARDING
tables: # 逻辑表配置
# .. 省略
# 绑定表规则
bindingTables:
- t_order,t_order_item # 设置需要根据分片规则进行绑定的表
# 分片算法配置
shardingAlgorithms:
# .. 省略
# 分布式序列配置
keyGenerators:
# .. 省略4.广播表
在数据库中有些表中存的数据一般不怎么改变,比如用于配置的表,也就是常说的字典表,这种类型的表在表关联查询时也会被经常使用,在分布式场景中,这类表在每个数据源中都保存一个复本,可以减少跨库关联提升查询效率。
广播表:指所有分片数据源中都存在的表,表结构及表中的数据在每个数据库中完全一致,适用于数据量不大且需要与海量数据表进行关联的场景。广播表具有以下特性:
|-----------------------------------|
| 插入、更新操作会实时在所有数据节点上执行,保持各个分片的数据一致性 |
| 查询时只从一个数据节点获取数据 |
| 可以和任何一个表进行表关联查询 |
bash
# 规则配置
rules:
# 分片配置
- !SHARDING
tables: # 逻辑表配置
# ... 省略
# 绑定表规则
bindingTables:
# ... 省略
# 分片算法配置
shardingAlgorithms:
# ... 省略
# 广播表
broadcastTables:
- t_dict
# 分布式序列配置
keyGenerators:
# ... 省略在所有数据源 server-user , server-order0 , server-order1 中创建广播表:
sql
-- 创建⼴播表t_dict,不使⽤⾃增主键,由应⽤程序传⼊
create table if not exists t_dict (
id bigint primary key,
type varchar(30) comment '类型'
);