JdbcTemplate 性能好,但 Hibernate 生产力高。选择哪一个,本质上是在"开发效率/系统复杂度"与"运行时性能/控制力"之间做权衡。
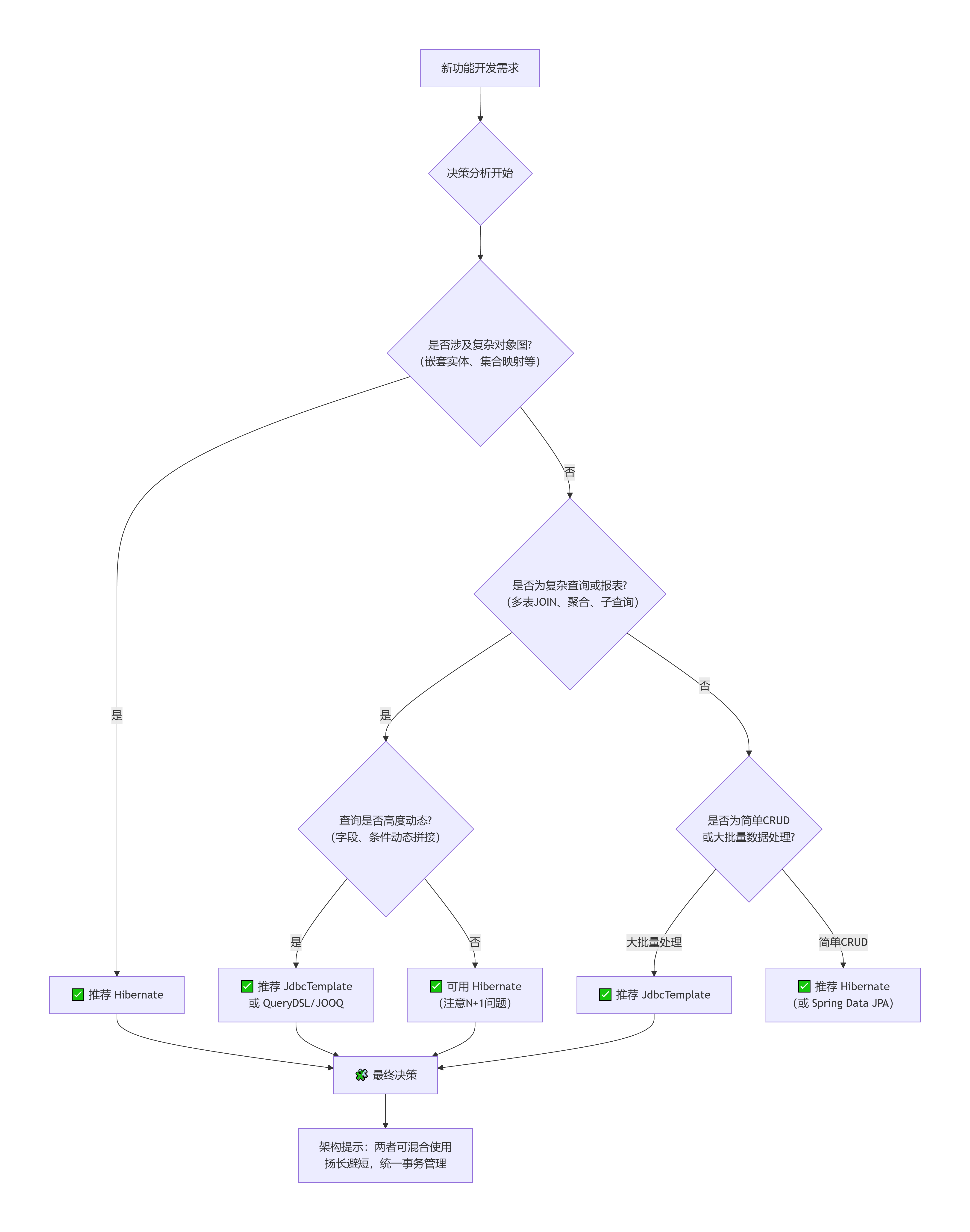
下面,我们对图中的关键判断点进行详细说明。
📝 详细解读:何时用 Hibernate?
当以下一个或多个条件成立时,优先选择 Hibernate:
-
领域模型驱动设计(DDD) :你的业务核心是复杂的对象关系网(一对多、多对多、继承)。Hibernate 的关联映射(
@OneToMany,@ManyToOne)和级联操作能极大简化代码。 -
需要快速原型或开发:简单的 CRUD 操作,用 Hibernate 或它的"升级版" Spring Data JPA,几行代码就能完成,开发效率极高。
-
数据库可移植性要求高:产品可能需要支持 MySQL、Oracle、PostgreSQL 等多种数据库。Hibernate 的 HQL 和方言机制可以很大程度上屏蔽数据库差异。
-
对数据库控制权要求低:你希望将数据库操作尽可能抽象为对象操作,不想写太多 SQL,让框架帮你处理细节。
-
需要强大的缓存机制:Hibernate 的一级、二级缓存可以显著减少对数据库的重复查询,提升读性能(但在并发写时需要注意缓存一致性)。
📝 详细解读:何时用 JdbcTemplate?
当以下一个或多个条件成立时,优先选择 JdbcTemplate:
-
复杂的、动态的查询或报表 :查询条件需要动态拼接,或者涉及大量分组聚合、窗口函数、原生SQL函数。虽然 Hibernate 的
Criteria API或QueryDSL也能做,但往往不如直接写 SQL 直观和高效。 -
大数据量的批量处理 :正如我们之前讨论的,处理成千上万条数据的导入、更新、清洗任务,JdbcTemplate 的
batchUpdate性能优势明显。 -
调用存储过程或数据库特定功能:需要使用数据库独有的特性和函数。
-
对性能有极致要求:你已经定位到某个数据库操作是性能瓶颈,且优化 Hibernate 生成的 SQL 非常困难。直接使用 JdbcTemplate 可以编写和优化最精确的 SQL。
-
遗留系统或复杂SQL迁移:在维护老系统时,已有大量复杂 SQL,用 JdbcTemplate 接入成本最低。
🧩 最佳实践:混合架构(多数中大型项目的选择)
在实际项目中,已有的 Spring + Hibernate 架构中,混合使用是最明智的选择。可以遵循以下原则:
-
80/20 法则 :用 Hibernate(或 Spring Data JPA)处理 80% 的标准 CRUD 和核心领域对象操作。
-
专用通道 :用 JdbcTemplate(或更优雅的 QueryDSL 、JOOQ )处理 20% 的复杂查询、报表和批量任务。
示例:在Service层中混合使用
java
@Service
@Transactional // 默认使用Hibernate事务管理器
public class OrderService {
@Autowired
private OrderRepository orderRepository; // Spring Data JPA 接口,用于CRUD
@Autowired
private JdbcTemplate jdbcTemplate; // 用于复杂查询和批量操作
// 场景1:使用JPA进行领域操作(简单、面向对象)
public Order createOrder(Order order) {
// Hibernate自动处理关联、校验等
return orderRepository.save(order);
}
// 场景2:使用JdbcTemplate进行复杂报表查询(高效、灵活)
public List<OrderReportDTO> getOrderReport(LocalDate startDate, LocalDate endDate) {
String sql = """
SELECT o.order_number, o.amount, c.name,
SUM(oi.quantity) as total_items
FROM orders o
JOIN customer c ON o.customer_id = c.id
LEFT JOIN order_item oi ON o.id = oi.order_id
WHERE o.create_time BETWEEN ? AND ?
GROUP BY o.order_number, o.amount, c.name
HAVING SUM(oi.quantity) > ?
ORDER BY o.amount DESC
""";
// 直接使用SQL,清晰且易于优化
return jdbcTemplate.query(sql,
new BeanPropertyRowMapper<>(OrderReportDTO.class),
startDate, endDate, 10);
}
// 场景3:使用JdbcTemplate进行批量状态更新
@Transactional(propagation = Propagation.REQUIRES_NEW) // 可开启新事务,避免长事务
public int batchUpdateOrderStatus(List<Long> orderIds, String newStatus) {
String sql = "UPDATE orders SET status = ? WHERE id = ?";
List<Object[]> batchArgs = orderIds.stream()
.map(id -> new Object[]{newStatus, id})
.collect(Collectors.toList());
int[] updateCounts = jdbcTemplate.batchUpdate(sql, batchArgs);
return Arrays.stream(updateCounts).sum();
}
}⚠️ 混合使用的注意事项
-
事务一致性:确保两个数据源在同一个事务管理器中。对于关键事务,混合操作要小心。
-
缓存一致性:用 JdbcTemplate 直接更新数据库后,Hibernate 的缓存(尤其是二级缓存)可能不知道数据已变,需要手动清理或设置缓存的过期策略。
java
// JdbcTemplate更新后,清除Hibernate相关缓存 sessionFactory.getCache().evictEntityRegion(Order.class); -
对象状态 :JdbcTemplate 操作会绕过 Hibernate 的实体状态管理(如
@Version乐观锁),需要额外注意。
💎 总结与最终建议
| 维度 | Hibernate (Spring Data JPA) | JdbcTemplate |
|---|---|---|
| 核心理念 | 面向对象,让开发者用操作对象的方式操作数据库 | 面向SQL,让开发者直接、精确地控制数据库 |
| 优势 | 开发快、维护简单、对象关系处理强、可移植性好 | 性能高、控制力强、SQL灵活、无额外开销 |
| 劣势 | 有学习曲线、可能生成低效SQL、对复杂查询支持笨重 | 代码啰嗦、容易出错、需要自己处理对象映射 |
-
Hibernate 作为你应用的主体框架,处理核心业务逻辑和标准CRUD。
-
果断引入 JdbcTemplate 作为性能关键路径和复杂查询的专用工具
-
考虑在两者之间增加一个 QueryDSL 层,它能在面向对象和SQL控制力之间取得更好的平衡,可以用Java代码类型安全地构建复杂查询。
技术选型没有错误,根据场景选择正确的工具,并良好地组织它们,才是高级工程师的标志。