这个批量识别功能是免费的、无限制的、可批量使用的功能,可实现音频、视频文件语音识别转txt文本、srt字幕,主要是能批量执行识别任务,不用手动一个个去识别,这是与其他语音识别软件的最大的区别,而且可同时处理视频和音频文件,非常适合批量创作的公司和工作室。
一、具体使用步骤说明
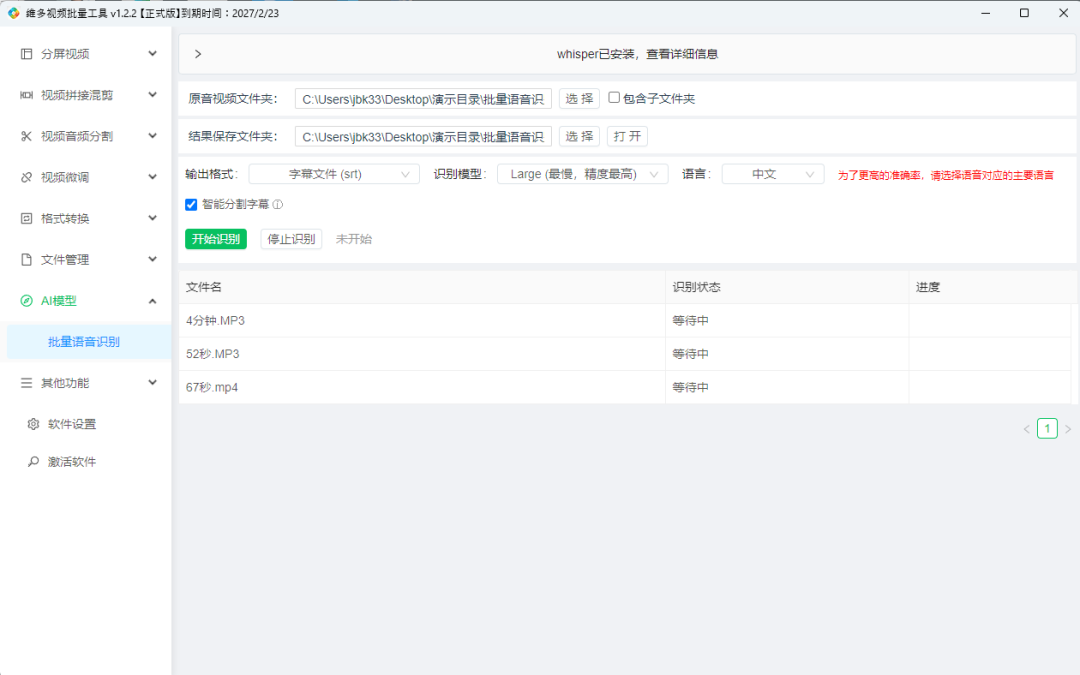
1、打开维多视频批量工具,在左侧功能栏中找到「AI模型」模块,选择「批量语音识别」功能,进入操作界面。
2、点击选择要处理的音视频文件夹,可将音频、视频文件同时放入该目录,软件会自动识别可处理文件,无需手动分类。建议将输出文件夹与待处理音视频文件夹设置为同一目录,方便后续查找结果。
3、选择文件夹后,软件会自动将目录内可处理的音视频文件添加至任务列表,音频、视频格式均支持处理。示例中测试了三个文件(1个4分钟音频、1个52秒音频、1个67秒视频)。
4、设置输出格式,在输出设置中选择文件格式,支持单独生成TXT文本文件、SRT字幕文件,也可选择同时输出两种格式,适配不同使用场景(如纯文本整理、视频剪辑字幕导入)。
5、配置识别模型与语言,选择需使用的大模型(多模型配置方法见后续补充),为提升识别准确率,需选择与语音对应的语言,不建议使用「自动检测」模式,因为这可能会影响识别结果准确性和处理速度。
6、保持「智能分割字幕」功能默认选中状态,该功能可优化SRT字幕的分段效果,使字幕与语音节奏更匹配。
二、Whisper模型安装与配置
语音识别依赖的是Whisper大模型,我已经把对应的整合包打包好了,安装流程非常简单,软件内页也提供了详细说明,使用时软件会自动检测模型配置状态,未正确配置则需按以下步骤操作。
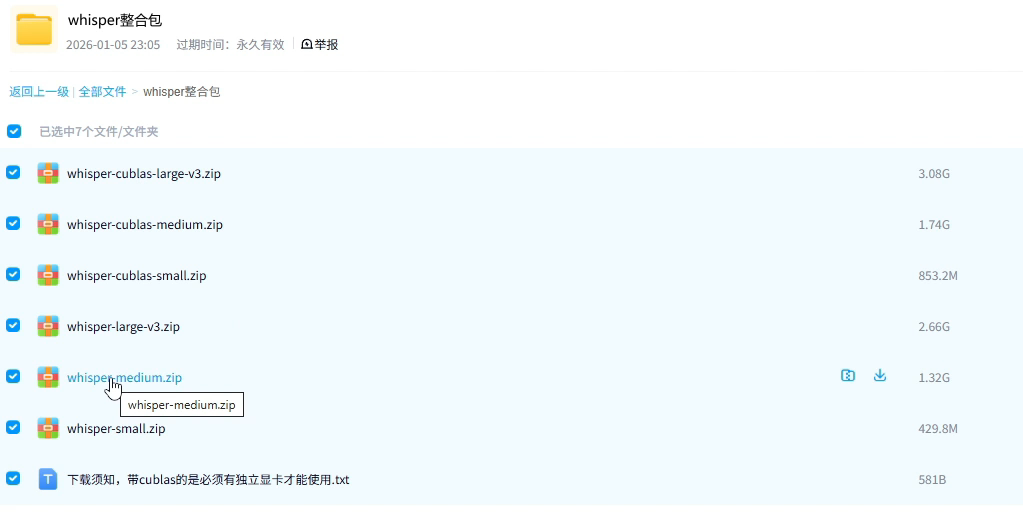
**1、先下载模型,**根据电脑配置选择对应整合包,有比较好独立显卡的电脑,建议选择支持GPU的模型,提升识别速度。如果电脑没有独立显卡或者显示比较差的,选择使用纯CPU模型,实测纯CPU模型识别准确率较高,就是速度比较慢,另外如果没有独立显卡,选择带Cabus标识的模型是用不了的,会报错。
2、下载压缩包后,解压至无中文路径的文件夹(重点提醒:Whisper模型所在路径不能包含中文,否则会影响配置生效和使用)。
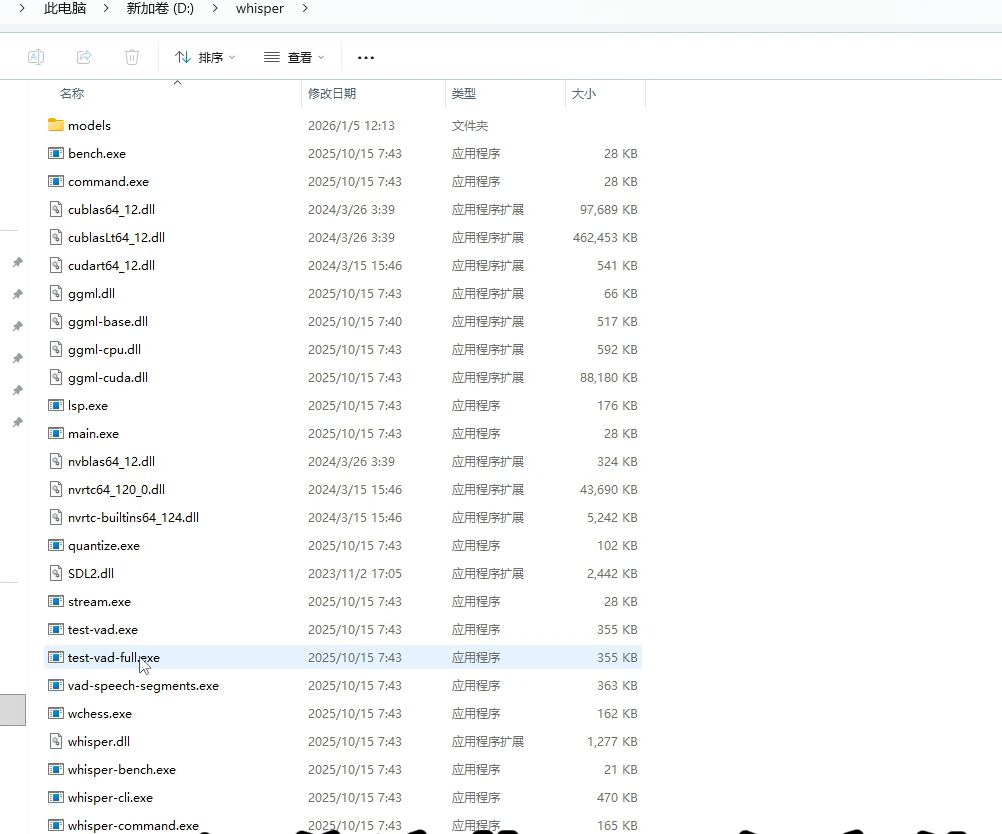
3、解压好whisper模型后,在维多视频批量工具设置界面选择已解压的Whisper目录,软件会自动检测配置是否成功。
4、如果你需使用多个模型,只需将不同模型的bin文件下载并放入解压目录下的models文件夹中即可,软件会自动识别,软件对应的bin模型文件在models这个文件夹中,需求的可以同时下载多个模型,然后把不同模型中的models文件夹下面的bin文件复制到同一个模型目录中就可以了。