实现最简单的神经网络模型的基本步骤

在整个模型的实现过程中工作量最大的应该是数据处理部分,如怎么选择数据的格式,选择多少的数据合适,这些问题往往与模型最终的性能也息息相关。
数据集包括数据和标签,说白了就是自变量x和因变量y的关系,数据就是x,标签就是y。
我们求loss也是用真实的y减去估计的y来衡量模型,进行训练。
定义模型和确定参数的过程往往比较固定。
训练集train,验证集val,和测试集test
训练集------通常占总数据量的最大部分(如 60%-80%)。
模型用来学习和调整参数的数据。模型通过训练集来"认识"数据中的模式。
模型在此阶段的行为:计算损失、更新权重(参数)。例如,在训练集上运行梯度下降算法。
验证集
-
作用:在训练过程中,用来调整超参数、选择模型、进行早期停止的数据。
-
它是模型在训练时"偷偷看一眼"的模拟考试题,用于指导训练方向,但不参与参数更新。
-
特点:
-
不用于学习参数,用于"验证"当前模型的好坏。
-
是模型选择和调优的唯一依据。
-
帮助判断是否出现过拟合(训练集误差小,验证集误差大)。
-
-
关键用途:
-
超参数调优:例如,调整学习率、神经网络层数、正则化强度等。
-
模型选择:比较不同算法(如随机森林 vs. SVM)或不同架构哪个在验证集上更好。
-
早停:当验证集性能不再提升时,停止训练,防止对训练集的过拟合。
-
测试集
-
在模型训练和调优完全结束后,用来最终、无偏地评估模型性能的数据。它是"最终的高考",只在最后使用一次。
-
特点:
-
绝对禁止在训练和调优的任何阶段使用。
-
模型在训练中绝不能"看到"或"学到"任何测试集的信息。
-
用于报告模型的最终泛化性能(如准确率、F1分数等)。
-
模拟模型部署到现实世界后,面对全新数据时的表现。
-
"为什么训练多个 epoch 有意义?"
梯度下降的优化过程 :神经网络的优化通常使用梯度下降(如 SGD、Adam 等)。如果只训练一轮(epoch),优化器可能无法充分调整模型参数,使其收敛到较优的解。训练多轮可以让模型参数逐步调整,找到更好的参数组合。
数据顺序的影响:如果数据集很大且多样化,数据的顺序会影响梯度的计算。每轮打乱数据顺序可以防止模型过早陷入局部最优(即某种特定的学习模式)。
批量梯度下降(Mini-batch SGD):数据可能被分成多个 mini-batch,每个 mini-batch 的数据在每一轮的顺序不同,这样可以让模型学习到不同的数据特征,提高泛化能力。
每一轮的数据顺序都不同,梯度下降的路径也不同,最终参数更新的轨迹也不同。如果只训练一轮,模型可能还未收敛,无法达到较优的效果。数据虽然来源于同一个文件,但每一轮的数据顺序不同,这使得模型不会总是按照相同的模式学习,可以帮助模型更好地泛化。
一些关于优化模型性能的方法:
正则化: 在计算loss值时候使用,loss = loss + a*参数的平方,可以缓解过拟合,让曲线更加平滑(a是一个自己设置的超参数)
相关系数: 主要是在数据处理的过程中使用。我们的数据集被分为好多列,每一列都代表了一个指标,在正常的训练过程中,每一个指标都被传入到模型中并对模型的训练效果产生了影响。但是实际的情况是这么多列的指标中,每一个指标对于要预测的结果的影响肯定是不尽相同的,因此为了突出这些影响更好的达到更好的预测效果,通过相关系数选出对最终结果影响最大的K列,也就是K个特征,并在训练过程中只传入这K列数据。
主成分分析(PCA) :是一种用于降维的数据分析方法。它通过线性变换将原始数据投影到新的坐标系中,使得数据的方差尽可能集中在较少的维度上,同时尽可能减少信息损失。举个例子,四个人站成一排,当我们从x轴方向和y轴方向进行观察时,每个数据体现出来的内容量时是不一样的。
第四象限的这批数据也是相同的例子,就是我们要尽量选择最能体现各个数据特征的维度,尽量避免出现信息的损失,消除特征之间的相关性,使数据更易于分析。
独热编码
对于一个有 N 个可能取值的特征,我们创建 N 个新的二进制特征。对于原始特征的每一个取值,只有对应的那个新特征被标记为 1,其他所有新特征都为 0。
主要目的是将离散的分类特征转换为机器学习算法能够处理的数值格式,从而避免引入数值偏误。
-
"红" 编码为
[1, 0, 0] -
"绿" 编码为
[0, 1, 0] -
"蓝" 编码为
[0, 0, 1]
进入正文
新冠病毒感染人数预测:
美国有40个州,统计了连续三天的新冠阳性人数,和每天的一些社会特征,比如带口罩情况, 居家办公情况等等。现在有一群人比较坏,把第三天的数据遮住了,我们就要用前两天的情况以及第三天的特征,来预测第三天的阳性人数。但幸好的是,我们还是有一些数据可以作为参考的,就是我们的训练集。
kaggle比赛题目链接:![]() https://www.kaggle.com/competitions/ml2021spring-hw1
https://www.kaggle.com/competitions/ml2021spring-hw1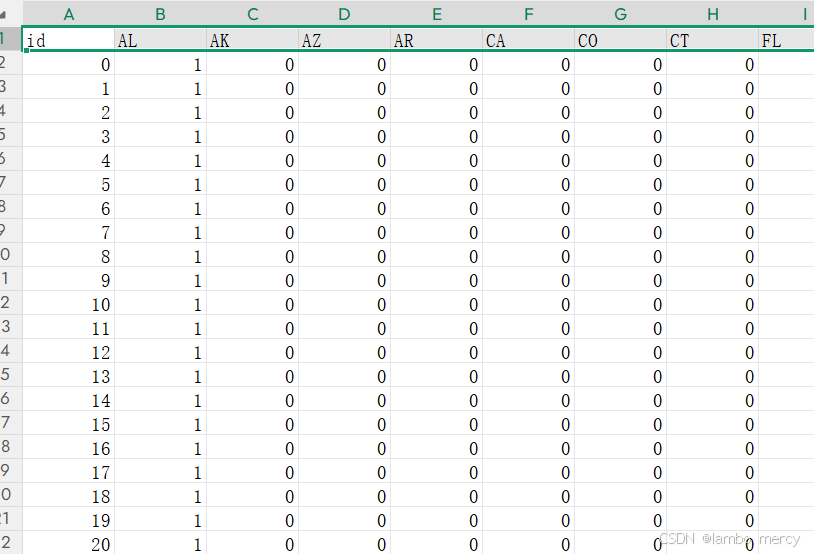
这是一个2701行,94列的数据,第一行是数据名称,第一列是下标。
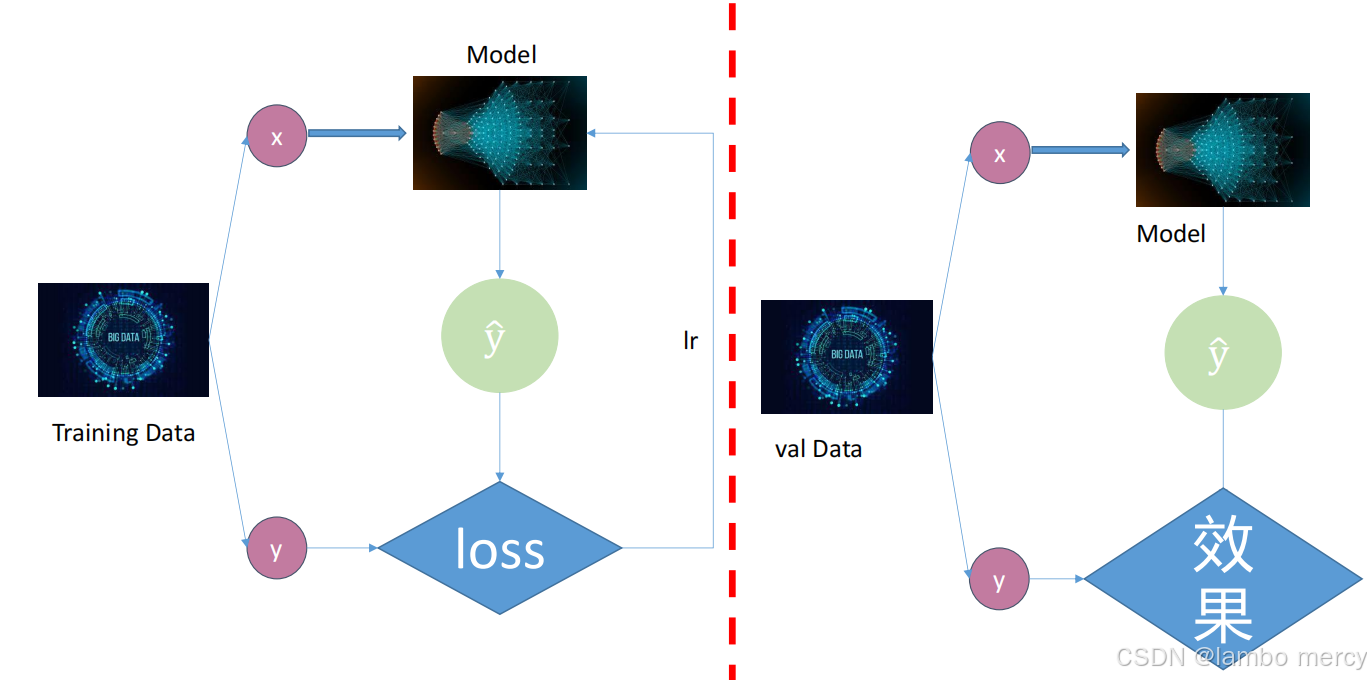
具体的训练流程步骤:一般分为训练数据和验证数据。
**训练数据(Training Data):**通过数据处理部分(data process),得到x和真实值y,让x通过模型Model得到一个预测值y尖,y与y尖通过处理得到loss,再让loss乘以学习率lr,就可以得到梯度grad,这个模型就可更新,以使得下一次得到的预测值更靠近真实值y。
**验证数据(Val Data ):**让x通过模型Model得到一个预测值y尖,y与y尖进行一次计算得到一个效果的判断,在验证集上不更新模型,故理论上说模型的参数与验证集的数据无关。
我们一定要用所有的数据算一次loss?
三种主要的Loss计算策略:
- 全批梯度下降
方法 :使用整个训练集计算一次loss,然后更新一次权重。
优点:
Loss计算非常稳定,平滑收敛。
梯度方向是数据集上的真实梯度。
理论分析简单。
缺点:
计算代价极高,大数据集上几乎不可行。
内存要求大(需要一次性加载所有数据)。
- 随机梯度下降(Stochastic Gradient Descent, SGD)
方法 :对每一个样本都计算一次loss并立即更新权重。
优点:
更新频率快,收敛速度快。
可以跳出局部极小值(有噪声的梯度)。
内存需求小。
缺点:
Loss波动非常大,收敛不稳定。
梯度方向是单个样本的梯度,可能偏离全局最优方向。
无法利用现代硬件的并行计算优势。
- 小批梯度下降(Mini-batch Gradient Descent)
方法 :这是现代深度学习的标准做法 。使用一小批数据(比如32、64、128个样本)计算一次loss,然后更新一次权重。
优点:
平衡了稳定性和速度:比SGD稳定,比全批快。
可以利用GPU的并行计算能力。
梯度方向相对准确,又有一定的随机性帮助跳出局部最优。
缺点:
- 需要调整批次大小这个超参数。
在深度学习中,Linear(线性层)是一种常用的神经网络层,也被称为全连接层或密集层。
Linear 层接受一个输入张量,通过一个矩阵乘法和一个偏置向量相加的方式计算输出张量,其中矩阵和偏置向量是 Linear 层的可学习参数。
**思路:**数据处理,构建模型,进行训练和检验,最后进行测试。
导入库
import torch
import numpy as np #矩阵处理
import csv #读excel文件
import pandas as pd #pandas的封装很高级
from torch.utils.data import DataLoader,Dataset #这两个都是数据处理相关的包
import torch.nn as nn #Pytorch中导入神经网络模块,其实import torch已经包含它了,但为了代码简洁,这里重命名一下方便引用
from torch import optim #引入优化器
import time
import matplotlib.pyplot as plt #画图
from sklearn.feature_selection import SelectKBest,chi2 #用于特征选择的模块,chi2是卡方分布class 处理数据输入
这一步一般通过实现一个类Dataset完成。Dataset类中需要实现三个函数:
(1)__init__初始化
(2)__getitem__获得单个实例(单个X或者单个Y)
(3)__len__获得数据集的长度
__init__初始化,实现的代码如下:
class covidDataset(Dataset):
def __init__(self, path, mode="train", feature_dim=5, all_feature=False):
# 以只读模式打开CSV文件,使用with语句确保文件正确关闭。
with open(path,'r') as f:
csv_data = list(csv.reader(f)) # 转换为Python列表
column = csv_data[0]
x = np.array(csv_data)[1:,1:-1] # 获取CSV文件的第一行作为表头(列名)。
y = np.array(csv_data)[1:,-1]
if all_feature:
col_indices = np.array([i for i in range(0,93)])
else:
_, col_indices = get_feature_importance(x, y, feature_dim, column)
col_indices = col_indices.tolist()
csv_data = np.array(csv_data[1:])[:,1:].astype(float)
if mode == 'train':
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
self.y = torch.tensor(csv_data[indices,-1])
elif mode == 'val':
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
self.y = torch.tensor(csv_data[indices,-1])
else:
indices = [i for i in range(len(csv_data))]
data = torch.tensor(csv_data[indices, :])
self.data = data[:, col_indices]
self.mode = mode
self.data = (self.data - self.data.mean(dim=0,keepdim=True)) / self.data.std(dim=0,keepdim=True)
assert feature_dim == self.data.shape[1]
print('Finished reading the {} set of COVID19 Dataset ({} samples found, each dim = {})'
.format(mode, len(self.data), feature_dim))定义名为
covidDataset的类,继承自PyTorch的Dataset基类,用于创建自定义数据集。为什么要继承自PyTorch的Dataset基类?
PyTorch的数据加载系统(
DataLoader)依赖于Dataset类定义的统一接口继承
Dataset后,可以直接使用PyTorch的DataLoader如果不继承Dataset
需要手动实现所有功能
需要自己处理索引、分批、洗牌等
需要自己实现迭代器、分批逻辑等
代码更复杂,容易出错
def __init__(self, file_path, mode):类的初始化方法,接收四个参数:
file_path: CSV文件路径-
mode: 数据集模式,默认为"train"with open(file_path, "r") as f: # 使用 CSV 读取器、读取文件内容,并转换为 Python 列表。每个子列表代表 CSV 的一行。 ori_data = list(csv.reader(f))
csv.reader(f)读到的是一个对象,用list转为我们需要的列表存储到ori_data
csv_data = np.array(ori_data)[1:, 1:].astype(float) # 这行代码做了三件事:
# np.array(ori_data):将列表转换为 NumPy 数组
# [1:, 1:]:切片操作:跳过第一行(表头)和第一列(索引)
# .astype(float):将数据转换为浮点数类型根据模式选择数据索引
# 训练集:取不是5的倍数的行(即80%的数据)
if mode == "train":
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
# 如果模式是验证集,只选择索引是5的倍数的行,即20%的数据。
elif mode == "val":
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
# 如果模式是测试集,选择所有行。
elif mode == "test":
indices = [i for i in range(len(csv_data))]#如果模式是训练集,创建索引列表:range(len(csv_data)):生成从0到数据行数-1的序列
if i % 5 != 0:只选择不是5的倍数的索引
X = torch.tensor(csv_data[indices, :93])
# 如果不是测试集(即训练集或验证集),提取最后一列作为标签(Y),并保存为实例变量。
if mode != "test":
self.Y = torch.tensor(csv_data[indices, -1])
# self.X:保存标准化后的特征
self.X = (X - X.mean(dim=0, keepdim=True)) / X.std(dim=0, keepdim=True)
# 保存数据集模式到实例变量。
self.mode = mode输入特征X
- csv_dataindices, :93:根据选择的索引,提取前93列作为特征
- torch.tensor():将 NumPy 数组转换为 PyTorch 张量
- X = torch.tensor(csv_dataindices, :93)
对特征进行标准化(z-score归一化):
X.mean(dim=0, keepdim=True):计算每个特征列的均值
X.std(dim=0, keepdim=True):计算每个特征列的标准差
(X - 均值)/标准差
(2)__getitem__获得单个实例(单个X或者单个Y)
(3)__len__获得数据集的长度
# 实现获取单个样本的方法,这是 Dataset 类的必需方法。
def __getitem__(self, item):
# 如果是测试集,只返回特征,并确保返回的数据类型是 float。
if self.mode == "test":
return self.X[item].float()
# 如果是训练集或验证集,同时返回特征和对应的标签。
else:
return self.X[item].float(), self.Y[item].float()
# 返回数据集的样本数量,这是 Dataset 类的另一个必需方法。
def __len__(self):
return len(self.X)class 神经网络模型
定义一个新的神经网络模型类 myModel,继承自 PyTorch 的 nn.Module 基类,这是构建所有 PyTorch 神经网络的标准方式。
先搭一个架子:
class myModel(nn.Module):
def __init__(self, inDim):
super(myModel, self).__init__()
self.fc1 = nn.Linear(inDim, 128)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(128, 1) 类的初始化方法 ,接收一个参数 inDim(输入特征x的维度)。
def init(self, inDim):
调用父类 nn.Module 的初始化方法(这是必要的步骤,用于正确设置模型的内部结构)
super(myModel, self).init()
全连接层(fully connected layer):
inDim:输入特征的维度
128:输出特征的维度(隐藏层大小)
这是一个线性变换层:y = xWᵀ + b,其中 W 是权重矩阵,b 是偏置向量
self.fc1 = nn.Linear(inDim, 128)
输入 (inDim) → Linear(inDim→128) → ReLU → Linear(128→1) → 输出
定义前向传播方法
这是模型的核心部分,指定了数据如何通过网络层流动。让x通过上面搭好的架子计算
def forward(self, x):
# 将输入 x 通过第一个全连接层进行线性变换:
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
# 检查输出张量的维度数量:
# 如果维度大于1, 就去掉第二个维度
if len(x.size()) > 1:
x = x.squeeze(1) #squeeze(1):移除大小为 1 的维度
return x模型训练的准备和执行阶段
1. 选择计算设备
device = "cuda" if torch.cuda.is_available() else "cpu"作用:自动检测并选择使用GPU还是CPU。
# 检查是否有可用的CUDA(NVIDIA GPU)
torch.cuda.is_available() # 返回True或False
# 相当于:
if torch.cuda.is_available():
device = "cuda" # 使用GPU
else:
device = "cpu" # 使用CPU为什么重要:
-
GPU:并行计算能力强,适合深度学习(快10-100倍)
-
CPU:通用计算,速度较慢但兼容性好
2. 定义模型输入维度
data_dim = 93作用:指定输入特征的维度。
来源:根据数据集中有93个特征列:
# 在CovidDataset中:
X = torch.tensor(csv_data[indices, :93]) # 取前93列作为特征3. 创建模型实例并移动到设备
model = myModel(data_dim).to(device)分步解释:
# 步骤1:创建模型实例
model = myModel(data_dim) # 输入维度93,输出维度1
# 步骤2:将模型移动到指定设备
model = model.to(device)4. 设置保存路径
save_path = "model_save/best_model.pth"
rel_path = "pred.csv"-
save_path:保存训练好的模型权重 -
rel_path:保存测试预测结果
5. 创建优化器
optimizer = optim.SGD(params=model.parameters(), lr=lr, momentum=0.9)优化器的作用:更新模型参数以减少损失。
参数详解:
optim.SGD(
params=model.parameters(), # 要优化的参数(模型的所有权重和偏置)
lr=0.001, # 学习率(learning rate),控制更新步长
momentum=0.9 # 动量,帮助加速收敛并减少震荡
)为什么使用动量?
没有动量(普通SGD):
问题:在平坦区域更新慢,容易震荡
有动量(momentum=0.9):
速度:v = 0.9*v - lr*∇θ # 累积历史梯度
更新:θ = θ + v
优点:加速收敛,减少震荡
6. 开始训练
train_val(model, train_loader, val_loader, lr, optimizer, device, epochs, save_path)传递的参数:
-
model:要训练的神经网络模型 -
train_loader:训练数据加载器 -
val_loader:验证数据加载器 -
lr:学习率(0.001) -
optimizer:SGD优化器 -
device:计算设备(GPU/CPU) -
epochs:训练轮数(20) -
save_path:模型保存路径
def 训练和验证
def train_val(model, train_loader, val_loader, lr, optimizer, device, epochs, save_path):功能:执行模型的训练、验证,并保存最佳模型。
1. 初始化阶段
model = model.to(device) #防止意外确保模型在正确的设备上(即使之前已经移动过)。
plt_train_loss = [] #总训练loss
plt_val_loss = []初始化列表,用于记录每个epoch的训练和验证损失,便于后续可视化。
min_val_loss = 999999999999999999.9初始化一个极大值,用于跟踪最佳验证损失。使用极大值确保第一个验证损失一定能更新它。
2. 训练循环
for epoch in range(epochs): # 遍历所有epoch2.1 设置训练模式
model.train()告诉模型:"我现在要训练了,请开启Dropout等训练特有的功能。"
2.2 训练批次循环
for x, y in train_loader:
x, y = x.to(device), y.to(device) # 移动数据到设备假设batch_size=16:
x的形状: 16, 93 # 16个样本,93个特征
y的形状: 16 # 16个标签值
2.3 前向传播
y_pred = model(x)
# y_pred的形状: [16] # 16个预测值2.4 计算损失
bat_loss = loss(y_pred, y, model)这里的loss函数是之前定义的mseLoss,包含:
-
均方误差损失(MSE)
-
L2正则化项(防止过拟合)
2.5 反向传播和优化
bat_loss.backward() # 计算梯度
optimizer.step() # 更新参数
optimizer.zero_grad() # 清除梯度这三步的顺序很重要:
-
backward():计算损失对每个参数的梯度
-
step():使用梯度更新参数
-
zero_grad():清除梯度,为下一批次准备
2.6 累积训练损失
train_loss += bat_loss.cpu().item()-
.cpu():如果损失在GPU,移到CPU -
.item():从张量提取Python标量值
2.7 计算平均训练损失
plt_train_loss.append(train_loss/train_loader.__len__())train_loader.__len__()返回批次数,所以这是每个批次的平均损失。
3. 验证阶段
model.eval()告诉模型:"我现在要验证了,请关闭Dropout等随机性功能。"
3.1 验证批次循环
with torch.no_grad():
for val_x, val_y in val_loader:
val_pred_y = model(val_x)
val_bat_loss = loss(val_pred_y, val_y, model)
val_loss += val_bat_loss.cpu().item()**禁用梯度计算------**验证数据不需要计算梯度
-
减少内存使用
-
加速计算
-
防止验证数据影响模型参数
注意 :验证时没有 调用backward()、step()、zero_grad(),因为不更新参数。
3.2 计算平均验证损失
plt_val_loss.append(val_loss / val_loader.__len__())4. 模型保存(早停策略)
if val_loss < min_val_loss:
min_val_loss = val_loss
torch.save(model, save_path)早停(Early Stopping):
-
只保存验证损失最低的模型
-
防止过拟合(如果验证损失开始上升,说明可能过拟合)
5. 进度输出
print("[%03d/%03d] %2.2f sec(s) train_loss: %.6f val_loss:%.6f" % \
(epoch, epochs, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1]))6. 损失可视化
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()-
观察训练是否收敛
-
检测过拟合(训练损失下降但验证损失上升)
def 测试评估函数
加载训练好的模型,对测试集进行预测,并保存预测结果到CSV文件。
def evaluate(model_path, test_loader, rel_path, device):1. 加载模型
model = torch.load(model_path).to(device)作用:从保存的文件中加载模型,并移动到指定设备。
注意 :这里使用的是保存整个模型的方式(torch.save(model, save_path)),所以直接加载整个模型对象。
2. 初始化结果列表
rel = [] # 记录预测结果创建一个空列表,用于存储每个测试样本的预测值。
3. 设置评估模式
model.eval()告诉模型:"我现在要测试/评估了,请关闭Dropout等随机性功能。"
4. 测试批次循环
-
测试时不需要计算梯度(不更新参数)
with torch.no_grad(): for x in test_loader: x = x.to(device) pred = model(x) rel.append(pred.cpu().item())
4.1 数据移动
x = x.to(device)将测试数据移动到与模型相同的设备(GPU/CPU)。
4**.2 前向传播**
pred = model(x)通过模型获得预测值。
4.3 保存结果
rel.append(pred.cpu().item())-
.cpu():如果预测结果在GPU,移到CPU -
.item():从张量中提取Python标量值 -
append():添加到结果列表
5. 保存结果到CSV文件
with open(rel_path, "w", newline="") as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["id", "tested_positive"])-
"w":写入模式(覆盖原有内容) -
newline="":防止CSV文件中有空行 -
writerow():写入表头行
6. 写入预测结果
for i, pred in enumerate(rel):
csv_writer.writerow([str(i), str(pred)])enumerate()函数
# enumerate() 的作用: # 同时获取索引和值 rel = [0.5, 0.6, 0.7] for i, pred in enumerate(rel): print(i, pred) # 输出: # 0 0.5 # 1 0.6 # 2 0.7为什么测试时使用 batch_size=1?
# 回顾之前的代码: test_loader = DataLoader(test_set, batch_size=1, shuffle=False) # 原因: # 1. 顺序保证:shuffle=False 确保预测顺序与原始数据一致 # 2. 内存灵活:即使单个样本很大也不会内存溢出 # 3. 结果对应:每个预测结果对应一个明确的IDmodel.eval()的重要性
在测试时,
model.eval()确保:
Dropout层:不随机丢弃神经元,使用所有神经元
BatchNorm层:使用训练时累积的统计信息,而不是当前批次的
一致性:确保测试结果稳定、可重复
全部代码
import torch
import matplotlib.pyplot as plt
import numpy as np
import csv
from torch.utils.data import Dataset, DataLoader
import torch.nn as nn
from torch import optim
import time
class CovidDataset(Dataset):
def __init__(self, file_path, mode):
with open(file_path, "r") as f:
ori_data = list(csv.reader(f))
csv_data = np.array(ori_data)[1:, 1:].astype(float)
if mode == "train":
indices = [i for i in range(len(csv_data)) if i % 5 != 0]
elif mode == "val":
indices = [i for i in range(len(csv_data)) if i % 5 == 0]
elif mode == "test":
indices = [i for i in range(len(csv_data))]
X = torch.tensor(csv_data[indices, :93])
if mode != "test":
self.Y = torch.tensor(csv_data[indices, -1])
self.X = (X - X.mean(dim=0, keepdim=True)) / X.std(dim=0, keepdim=True)
self.mode = mode
def __getitem__(self, item):
if self.mode == "test":
return self.X[item].float()
else:
return self.X[item].float(), self.Y[item].float()
def __len__(self):
return len(self.X)
class myModel(nn.Module):
def __init__(self, inDim):
super(myModel, self).__init__()
self.fc1 = nn.Linear(inDim, 128)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(128, 1)
def forward(self, x):
x = self.fc1(x)
x = self.relu1(x)
x = self.fc2(x)
if len(x.size()) > 1:
x = x.squeeze(1)
return x
def train_val(model, train_loader, val_loader, lr, optimizer, device, epochs, save_path):
model = model.to(device)
plt_train_loss = []
plt_val_loss = []
min_val_loss = 999999999999999999.9
for epoch in range(epochs):
model.train()
start_time = time.time()
train_loss = 0.0
for x, y in train_loader:
x, y = x.to(device), y.to(device)
y_pred = model(x)
bat_loss = loss(y_pred, y, model)
bat_loss.backward()
optimizer.step()
optimizer.zero_grad()
train_loss += bat_loss.cpu().item()
plt_train_loss.append(train_loss/train_loader.__len__())
model.eval()
val_loss = 0.0
with torch.no_grad():
for val_x, val_y in val_loader:
val_x, val_y = val_x.to(device), val_y.to(device)
val_pred_y = model(val_x)
val_bat_loss = loss(val_pred_y, val_y, model)
val_loss += val_bat_loss.cpu().item()
plt_val_loss.append(val_loss / val_loader.__len__())
if val_loss < min_val_loss:
min_val_loss = val_loss
torch.save(model, save_path)
print("[%03d/%03d] %2.2f sec(s) train_loss: %.6f val_loss:%.6f" % \
(epoch, epochs, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1]))
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title("loss")
plt.legend(["train", "val"])
plt.show()
def evaluate(model_path, test_loader, rel_path, device):
model = torch.load(model_path).to(device)
rel = []
model.eval()
with torch.no_grad():
for x in test_loader:
x = x.to(device)
pred = model(x)
rel.append(pred.cpu().item())
with open(rel_path, "w", newline="") as f:
csv_writer = csv.writer(f)
csv_writer.writerow(["id", "tested_positive"])
for i, pred in enumerate(rel):
csv_writer.writerow([str(i), str(pred)])
print("结果保存到了"+rel_path)
train_file = r"E:\桌面\深度学习\第三节,回归实战代码\第三节,回归实战代码\regression\covid\covid.train.csv"
test_file = r"E:\桌面\深度学习\第三节,回归实战代码\第三节,回归实战代码\regression\covid\covid.test.csv"
batch_size = 16
train_set = CovidDataset(train_file, "train")
val_set = CovidDataset(train_file, "val")
test_set = CovidDataset(test_file, "test")
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_set, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_set, batch_size=1, shuffle=False)
def mseLoss(pred, target, model):
loss = nn.MSELoss(reduction='mean')
regularization_loss = 0
for param in model.parameters():
regularization_loss += torch.sum(param ** 2)
return loss(pred, target) + 0.00075 * regularization_loss
loss = mseLoss
epochs = 20
lr = 0.001
device = "cuda" if torch.cuda.is_available() else "cpu"
data_dim = 93
model = myModel(data_dim).to(device)
save_path = "model_save/best_model.pth"
rel_path = "pred.csv"
optimizer = optim.SGD(params=model.parameters(), lr=lr, momentum=0.9)
train_val(model, train_loader, val_loader, lr, optimizer, device, epochs, save_path)
evaluate(save_path, test_loader, rel_path, device)