引言:从图像识别到深度学习革命
在当今的数字时代,图像识别技术已经渗透到我们生活的方方面面。从智能手机的拍照识别,到自动驾驶汽车的物体检测,再到医疗影像的诊断分析,这些都离不开一种强大的工具------卷积神经网络(Convolutional Neural Network,简称CNN)。CNN是深度学习领域的一个核心架构,它模拟了人类视觉系统的处理方式,能够从海量图像数据中自动提取特征,实现高精度的分类和识别。
VGGNet,正是CNN家族中的一位经典代表。它由牛津大学的Visual Geometry Group(视觉几何组,简称VGG)在2014年提出,全称为"Very Deep Convolutional Networks for Large-Scale Image Recognition"(用于大规模图像识别的非常深的卷积网络)。VGGNet在ImageNet大规模视觉识别挑战赛(ILSVRC)中脱颖而出,特别是在2014年的比赛中,它以简洁的结构和出色的性能,成为了深度学习历史上的里程碑。
为什么说VGGNet"经典"?因为它不像一些复杂的网络那样花里胡哨,而是通过简单却有效的设计------小卷积核和深度堆叠------证明了"深度"的威力。在AlexNet(2012年ImageNet冠军)的基础上,VGGNet将网络层数推向了16层或19层,展示了增加深度如何显著提升模型的准确率。今天,我们就来通俗地拆解VGGNet的架构,让即使是零基础的读者也能轻松理解它的原理和魅力。
ImageNet是一个庞大的图像数据集,包含1400多万张标注图像,覆盖1000个类别,如猫、狗、汽车等。VGGNet就是在这样一个战场上证明了自己的实力。它不仅仅是一个模型,更是一种思想:用小而多的卷积层来捕捉更精细的特征。这篇文章将从CNN基础入手,逐步深入VGGNet的架构、变体、优缺点,以及实际应用。让我们开始吧!
CNN基础知识:VGGNet的基石
要理解VGGNet,首先得搞清楚CNN的基本组件。CNN不是凭空而来,它的设计灵感来源于生物视觉系统,比如猫的视觉皮层如何处理图像。简单来说,CNN通过层层处理,将原始图像转化为高维特征,最终输出分类结果。
1. 输入层:图像的起点
一切从一张图片开始。假设我们输入一张彩色图像,大小为224x224像素(VGGNet的标准输入尺寸),每个像素有红绿蓝(RGB)三个通道,所以输入是一个三维张量:224(高)x 224(宽)x 3(通道)。为什么是224?因为VGGNet的设计考虑了计算效率,经过多次池化后,能正好得到合适的特征图大小。
2. 卷积层:特征提取的核心
卷积层是CNN的灵魂。它用一个小的"滤波器"(也叫卷积核)在图像上滑动,计算局部区域的加权和,从而提取边缘、纹理等特征。VGGNet的一个关键创新是统一使用3x3的小卷积核,而不是像AlexNet那样混用大核(如11x11)。
想象一下:一个3x3的卷积核就像一个小窗户,它在图像上从左到右、从上到下移动,每次计算窗户内像素的加权平均(权重是可学习的参数)。如果核的参数设置为检测垂直边缘,它就会在边缘处输出高值,其他地方低值。这样,一层卷积就能生成多个特征图(取决于滤波器数量)。
为什么小核好?两个3x3核的叠加相当于一个5x5核的效果,但参数更少(3x3x2=18 vs 5x5=25),而且能引入更多非线性(通过激活函数)。VGGNet通过堆叠多个3x3卷积,实现了更深的特征提取。
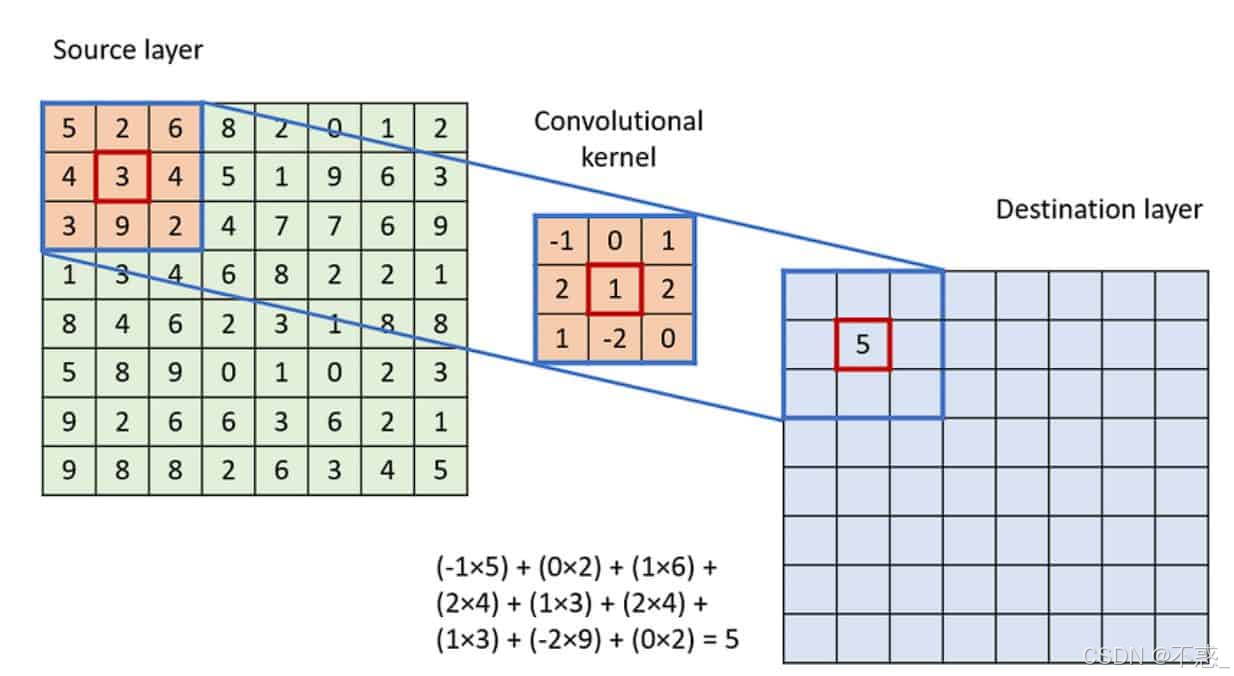
上图展示了一个典型的卷积操作示例:输入图像被一个3x3核卷积,输出一个缩小或保持尺寸的特征图(取决于padding)。在VGGNet中,所有卷积都使用"same" padding,确保输出尺寸不变。
3. 激活函数:引入非线性
卷积后,通常加一个激活函数,如ReLU(Rectified Linear Unit)。ReLU简单粗暴:如果输入>0,就输出原值;否则输出0。这避免了梯度消失问题,让网络训练更稳定。VGGNet全程使用ReLU,比AlexNet的sigmoid或tanh更高效。
4. 池化层:降维与鲁棒性
池化层用来缩小特征图尺寸,减少计算量,同时保留重要信息。最常见的是最大池化(Max Pooling):在一个2x2区域内,取最大值作为输出。这能使特征对小位移不敏感(平移不变性),并降低过拟合风险。
VGGNet统一用2x2的最大池化,步长为2,每次池化将尺寸减半。比如,从224x224到112x112。
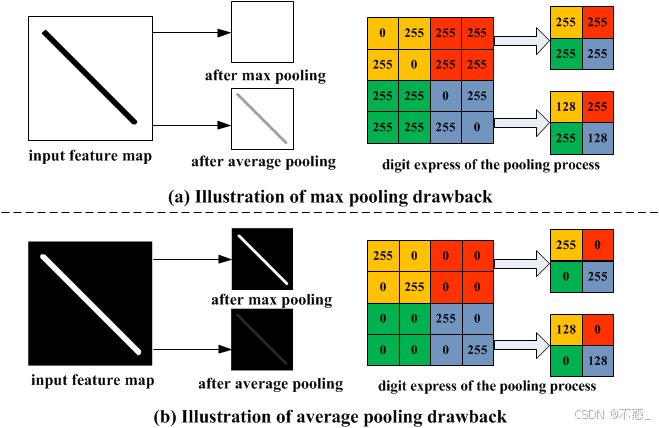
如图所示,最大池化从4个值中选最大,简化了数据但保留了突出特征。
5. 全连接层:决策阶段
在卷积和池化后,特征图被展平(flatten)成一维向量,输入到全连接层(Fully Connected, FC)。FC层像传统神经网络一样,每神经元连接所有输入,用于高层次决策。VGGNet有3个FC层,最后一个输出1000类概率(softmax激活)。
6. 其他技巧:正则化和优化
VGGNet训练时用了Dropout(随机丢弃神经元,防过拟合)和SGD优化器。损失函数是交叉熵,针对多类分类。
这些基础构成了VGGNet的框架。接下来,我们深入它的具体架构。
VGGNet架构详解:简单却深刻的堆叠
VGGNet的核心思想是"深度优先":通过增加层数来提升性能,而不是复杂的设计。论文中,作者测试了从11层到19层的多种配置,最终VGG-16和VGG-19成为明星。
VGGNet的总体结构
VGGNet分为5个卷积块(Conv Blocks),每个块包含多个卷积层+一个池化层。输入224x224x3,经过5个块后,特征图变为7x7x512,然后展平到全连接层。
- 块1:2个Conv(64滤波器,3x3) + MaxPool → 输出112x112x64
- 块2:2个Conv(128滤波器,3x3) + MaxPool → 输出56x56x128
- 块3:3个Conv(256滤波器,3x3) + MaxPool → 输出28x28x256(注意:从块3开始,Conv层增加到3个)
- 块4:3个Conv(512滤波器,3x3) + MaxPool → 输出14x14x512
- 块5:3个Conv(512滤波器,3x3) + MaxPool → 输出7x7x512
然后:
- Flatten:7x7x512 → 25088维向量
- FC1:25088 → 4096(ReLU + Dropout)
- FC2:4096 → 4096(ReLU + Dropout)
- FC3:4096 → 1000(Softmax)
总参数约1.38亿!为什么这么多?因为深度和滤波器数量的增加。
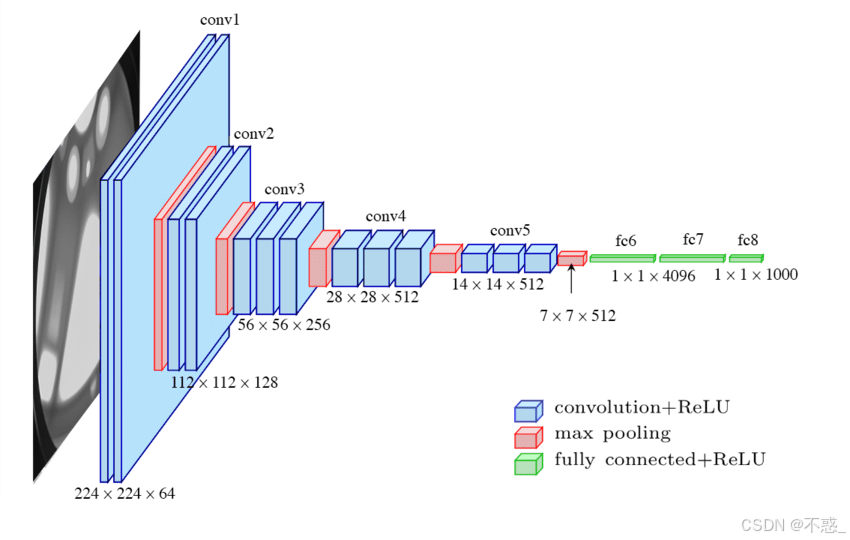
上图是VGG-16的架构图,直观显示了层级堆叠。每个Conv块的滤波器数翻倍,从64到512,捕捉从低级(边缘)到高级(物体部分)的特征。
VGG-16 vs VGG-19:变体的区别
VGGNet有多个变体,命名基于权重层数(卷积+全连接):
- VGG-11:8 Conv + 3 FC,较浅。
- VGG-16:13 Conv + 3 FC,最常用。ImageNet top-5错误率7.3%。
- VGG-19:16 Conv + 3 FC,更深。在块3、4、5各多一个Conv层。性能略好,但参数更多(1.43亿)。
为什么VGG-16更流行?因为它平衡了深度和效率。实验显示,超过19层收益递减,还易梯度爆炸。
| 变体 | Conv层数 | 总权重层 | 参数量(百万) | ImageNet Top-5 Error |
|---|---|---|---|---|
| VGG-11 | 8 | 11 | 133 | 10.4% |
| VGG-16 | 13 | 16 | 138 | 7.3% |
| VGG-19 | 16 | 19 | 143 | 7.3% |
从表中可见,深度增加带来准确率提升,但边际效应减弱。
与AlexNet的比较:从粗放到精细
AlexNet是2012年的先驱,8层,6000万参数,用大核(11x11)和GPU并行。但VGGNet改进了:
- 深度:AlexNet 8层 vs VGG-16 16层。深度让VGG捕捉更复杂特征。
- 核大小:AlexNet混用大核 vs VGG统一3x3。小核参数少、非线性多。
- 性能:AlexNet top-5 error 15.3% vs VGG 7.3%。VGG在ImageNet上更准。
- 参数:AlexNet 60M vs VGG 138M。VGG更重,但准确率高。
缺点:VGG计算密集,训练慢。
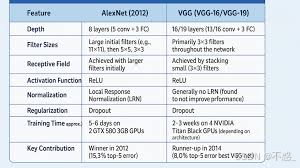
如图,VGG vs AlexNet的架构对比:VGG更均匀、 deeper。
VGGNet的训练与性能:从ImageNet到现实
VGGNet在ImageNet上训练:1400万图像,1000类。训练用多GPU,批大小256,学习率0.01(逐步衰减),动量0.9。初始化重要:浅层从浅模型迁移,深层随机。
性能:在ILSVRC-2014,VGG-16分类第二(7.32% top-5 error),定位第一(25.32% error)。它证明深度(16-19层)优于宽度。

上图是ImageNet分类示例:模型预测狗的品种等。
泛化:VGG用小核和ReLU,易迁移到其他任务,如人脸识别。
优点与缺点:VGGNet的双刃剑
优点
- 简单易懂:统一3x3核,易实现和修改。
- 高准确率:深度提取丰富特征。
- 预训练模型可用:Keras、PyTorch有现成权重,方便迁移学习。
- 影响力大:启发后续如ResNet的深度设计。
缺点
- 参数爆炸:1.38亿参数,内存大、训练慢(需几天GPU)。
- 计算密集:推理时慢,不适合移动设备。
- 梯度问题:深度易 vanishing/exploding gradients,虽ReLU缓解但仍需小心。
- 过时:比现代如EfficientNet重而准确率类似。
尽管缺点,VGG仍是基准模型。
VGGNet的应用与影响:从学术到产业
VGGNet不止于ImageNet。它在转移学习中闪光:用预训权重微调新任务,如医疗图像分类(检测肿瘤)、安防监控(物体检测)。
例如,在COCO数据集上,VGG基的Faster R-CNN提升检测精度。在艺术风格迁移(Neural Style Transfer),VGG特征用于内容/风格分离。
影响:VGG证明"深度为王",推动ResNet、DenseNet等。至今,在小数据集任务,VGG仍是首选。
结论:VGGNet的永恒价值
VGGNet虽2014年诞生,但其简单、深刻的架构仍值得学习。它告诉我们:复杂问题有时用简单方法解决------堆叠小核、加深网络。虽参数多、计算重,但在理解CNN本质上,无可替代。
如果你想上手,试试PyTorch实现VGG-16,加载预训模型分类照片。深度学习之路,从VGG开始!