**【本节概要】**本节主要讨论如何将知识图谱与图学习技术相结合,支撑图谱推理应用。
目录
[1.1 图表示学习问题概述](#1.1 图表示学习问题概述)
[1.2 基于随机游走的图表示学习](#1.2 基于随机游走的图表示学习)
[2.1 TransE:基于 "向量平移" 的基础模型](#2.1 TransE:基于 “向量平移” 的基础模型)
[2.2 TransH:通过 "超平面投影" 优化复杂关系](#2.2 TransH:通过 “超平面投影” 优化复杂关系)
[2.3 TransR:"实体空间→关系空间" 的独立映射](#2.3 TransR:“实体空间→关系空间” 的独立映射)
[2.4 TransD:动态映射矩阵,适配 "实体 - 关系" 差异](#2.4 TransD:动态映射矩阵,适配 “实体 - 关系” 差异)
[2.5 DistMult:基于 "对角矩阵" 的关系线性变换](#2.5 DistMult:基于 “对角矩阵” 的关系线性变换)
[3.1 基于符号/规则逻辑的推理方法](#3.1 基于符号/规则逻辑的推理方法)
[3.2 基于表示学习(嵌入)的归纳推理](#3.2 基于表示学习(嵌入)的归纳推理)
一、图表示学习技术
1.1 图表示学习问题概述
图表示学习算法指的是将图数据进行向量化表征,映射到一个低维的向量空间,在这个低维向量空间中,图的结构特征和语义特征得到最大限度的保留。
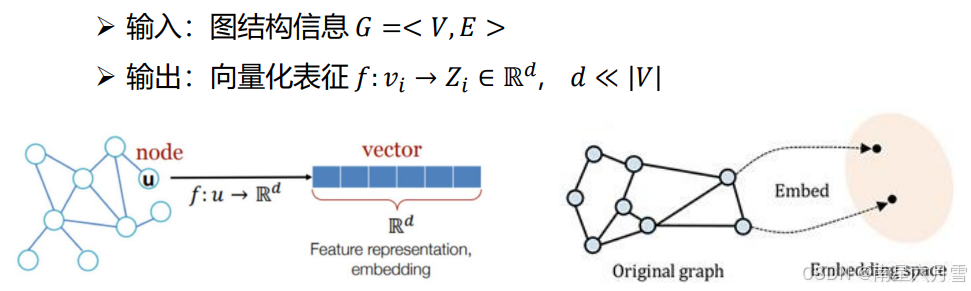
图的基本表示形式之一:邻接图矩阵。其中,每一行表示一个节点,1/0分别表示与对应节点是/否连接。这一行可以视作该节点的一个表示向量。这里另外介绍一种不同的图表示学习算法。
1.2 基于随机游走的图表示学习
基于随机游走的图表示学习,核心是通过模拟节点在图中的随机游动生成节点序列,再借鉴自然语言处理(NLP)的词向量学习思路,将节点转化为低维稠密向量,同时保留图的结构和语义特征。
它的核心灵感的是:
- 把图中 "节点" 类比为 NLP 中的 "单词";
- 把 "随机游走生成的节点序列" 类比为 NLP 中的 "句子";
- 沿用 NLP 中 Word2Vec 的思路(通过上下文预测学习词向量),学习节点的向量表示。
1. DeepWalk
DeepWalk 是该方向的开创性算法,步骤简单直接,分为两步:
- 生成随机游走序列 :
- 对图中每个节点,以其为起点,随机选择相邻节点作为下一跳,重复l次,生成长度为l的节点序列(例如:Z={z1,z2,...,zl});
- 多次重复该过程,得到大量节点序列(类比语料库)。
- 用 Skip-gram 学习节点向量 :
- 对每个节点序列,将其作为 "句子",用 Word2Vec 的 Skip-gram 模型训练:目标是最大化 "给定中心节点zi,预测其窗口内(窗口大小w)上下文节点的概率";
- 目标函数:其中Φ(vi)是节点vi的向量表示。
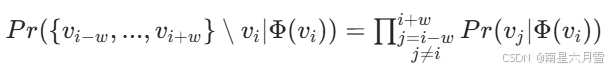

优点 :简单易实现,能捕捉节点的全局结构关联;局限性:游走完全随机,未考虑图的局部结构差异(如节点的重要性、结构相似性)。
2. Node2vec
Node2vec 针对 DeepWalk "纯随机游走" 的缺陷,引入有偏随机游走策略,既能捕捉 "宏观同质性"(Homophily),又能捕捉 "局部结构等价性"(Structural Equivalence):
定义节点t(上一跳节点)与候选节点x的最短距离dtx:
- dtx=0:回到上一跳节点(走回头路);
- dtx=1:当前节点的直接邻居;
- dtx=2:邻居的邻居(远离上一跳)。
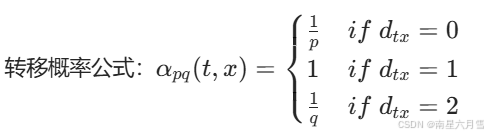
参数作用:
- p(回头概率):p越小,越容易重复访问上一跳节点(偏向 BFS,聚焦局部);
- q(远走概率):q越小,越容易访问邻居的邻居(偏向 DFS,探索全局)。
优点:通过参数灵活控制游走模式,同时捕捉局部结构和全局关联,适用范围更广。
3. Metapath2Vec
前两种算法针对 "同质图"(所有节点类型相同,如社交网络中都是 "人"),而 Metapath2Vec 解决异质图(节点 / 关系类型多样,如 "作者 - 论文 - 会议""用户 - 商品 - 类别")的表示问题。
引入Meta-path(元路径)
- Meta-path 是人工定义的 "节点类型序列",用于约束随机游走的方向(例如:APA = 作者→论文→作者,APVPA = 作者→论文→会议→论文→作者);
- 作用:确保游走序列符合异质图的语义逻辑(如只在 "作者 - 论文""论文 - 会议" 等有效关系间游走)。
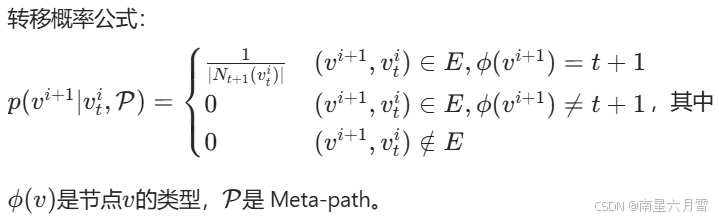
适用场景:异质图结构,如学术图谱、电商图谱等需要区分节点类型的场景。
二、知识图谱表示学习
知识图谱表示学习主要为知识图谱中的实体和关系提供向量表示,同时保留语义信息。不仅表征实体(节点),也表征关系(边)。不仅表征结构信息,也融合富语义关系类别信息。
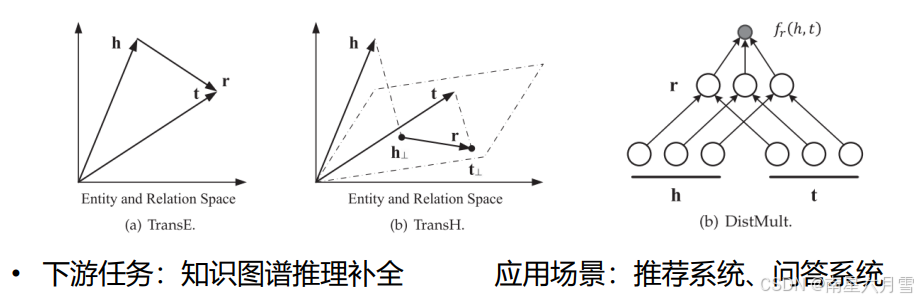
2.1 TransE:基于 "向量平移" 的基础模型
TransE(Translating Embeddings)是知识图谱嵌入的 "奠基性模型",灵感源自 Word2Vec 的词向量 "平移不变性"(如 "king - man + woman ≈ queen"),核心是将 "关系" 定义为 "头实体向量到尾实体向量的平移"。
- 核心假设与数学逻辑
- 核心假设:对于真实三元组(h,r,t)(头实体h、关系r、尾实体t),头实体向量h加上关系向量r,应尽可能接近尾实体向量t,即h+r≈t。
- 评分函数:用 L1/L2 范数衡量 "h+r与t的距离",距离越小,三元组越可能为真:fr(h,t)=∥h+r−t∥L1/L2
- 训练目标:通过 "对比学习" 优化损失函数,让真实三元组的评分(距离)远小于伪造三元组(如替换头 / 尾实体生成):JSE=∑tr∈Tr∑tr′∈Tr′max(0,γ+f(tr)−f(tr′))其中Tr是真实三元组集合,Tr′是伪造三元组集合,γ是正负样本的间隔阈值(确保真实样本评分更低)。
- 优势与局限性
- 优势:模型结构简单、参数少(仅实体和关系向量)、训练效率高,适合处理 "一对一" 关系(如 "姚明 - 身高 - 226cm")。
- 局限性 :无法处理一对多 / 多对一 / 多对多 复杂关系。例如:
- 一对多:"莫言 - 创作 - 红高粱""莫言 - 创作 - 丰乳肥臀",按 TransE 逻辑会要求 "红高粱向量 ≈ 丰乳肥臀向量",违背语义;
- 多对一:"英达 - 兄弟 - 英壮""英宁 - 兄弟 - 英壮",会导致 "英达向量 ≈ 英宁向量" 的错误。
2.2 TransH:通过 "超平面投影" 优化复杂关系
TransH 是对 TransE 的直接改进,核心解决 TransE "实体与关系共享同一空间" 的缺陷 ------ 为每个关系定义专属 "超平面",将实体投影到超平面后再进行平移计算,让实体在不同关系中呈现不同语义特征。
- 核心假设与数学逻辑
- 核心假设:实体在不同关系的超平面上,会凸显不同的语义属性(如 "莫言" 在 "创作" 关系中凸显 "作家属性",在 "国籍" 关系中凸显 "中国属性")。
- 关键操作:超平面投影 :对每个关系r,定义超平面的法向量wr(垂直于超平面),将头实体h、尾实体t投影到超平面上,得到投影向量h⊥和t⊥(本质是 "去掉实体向量在法向量上的分量,保留超平面内的语义"):h⊥=h−wr⊤h⋅wrt⊥=t−wr⊤t⋅wr
- 评分函数:在超平面内计算平移距离,逻辑与 TransE 一致:fr(h,t)=∥h⊥+r−t⊥∥22
- 优势与局限性
- 优势:通过 "超平面投影" 区分实体在不同关系中的语义,有效解决一对多 / 多对一关系(如 "莫言" 在 "创作" 超平面上的投影,可分别对应 "红高粱""丰乳肥臀")。
- 局限性:仍未完全脱离 "实体与关系共享底层空间"------ 超平面是原空间的子集,无法为不同关系构建完全独立的语义空间(如 "位于" 需要地理语义,"出生地" 需要时间语义,超平面无法彻底区分)。
2.3 TransR:"实体空间→关系空间" 的独立映射
TransR 进一步突破 TransH 的局限,核心创新是将 "实体空间" 和 "关系空间" 完全分离:为每个关系定义专属 "映射矩阵",将实体从统一的实体空间 "转换" 到该关系的专属空间后,再进行平移计算,彻底适配不同关系的语义需求。
- 核心假设与数学逻辑
- 核心假设:不同关系有完全独立的语义空间(如 "位于" 对应地理空间,"创作" 对应文学作品空间),实体需通过 "关系专属映射" 适配不同空间的特征。
- 关键操作:空间映射 :
- 为每个关系r定义映射矩阵Mr(维度:关系空间维度 × 实体空间维度);
- 将实体h、t通过Mr映射到关系空间,得到映射向量hr和tr(矩阵乘法实现 "维度转换 + 语义筛选"):hr=h⋅Mrtr=t⋅Mr
- 评分函数:在关系空间内计算平移距离:fr(h,t)=∥hr+r−tr∥22
- 优势与局限性
- 优势:彻底分离实体与关系空间,能精准建模多类型关系的语义差异,多跳推理能力显著提升(如 "北京 - 位于 - 中国""中国 - 属于 - 亚洲",可通过不同映射矩阵处理地理层级语义)。
- 局限性 :
- 参数量爆炸:每个关系对应一个映射矩阵(若实体维度 100、关系维度 50,每个矩阵有 5000 个参数),大规模图谱(百万级关系)难以承受;
- 映射粗糙:同一关系下,头实体和尾实体用相同矩阵(如 "创作" 关系中,"莫言"(人)和 "红高粱"(作品)用同一矩阵,未考虑实体类型差异)。
2.4 TransD:动态映射矩阵,适配 "实体 - 关系" 差异
TransD 是对 TransR 的优化,核心解决 TransR "同一关系下映射矩阵固定" 的问题 ------ 为每个 "实体 - 关系对" 动态生成映射矩阵,而非为关系固定一个矩阵,同时大幅减少参数计算量。
- 核心假设与数学逻辑
- 核心假设:同一关系下,不同实体的映射需求不同(如 "创作" 关系中,"莫言" 需映射 "作家属性","红高粱" 需映射 "文学属性",应使用不同矩阵)。
- 关键操作:动态生成映射矩阵 :
- 为每个实体(h/t)和关系r定义投影向量:实体投影向量hp/tp(描述实体的映射偏好),关系投影向量rp(描述关系的映射需求);
- 动态生成头实体映射矩阵Mrh和尾实体映射矩阵Mrt(单位矩阵保证基础映射,rp⋅hp⊤是动态调整项):Mrh=rp⋅hp⊤+Im×nMrt=rp⋅tp⊤+Im×n
- 实体通过动态矩阵映射到关系空间:h⊥=Mrh⋅ht⊥=Mrt⋅t
- 评分函数:与 TransR 逻辑一致,在关系空间计算距离:fr(h,t)=∥h⊥+r−t⊥∥
- 优势与局限性
- 优势 :
- 动态矩阵适配 "实体 - 关系" 专属需求,建模更精细;
- 用 "投影向量 + 单位矩阵" 替代 TransR 的大维度矩阵,参数量大幅减少(投影向量维度远低于矩阵),训练效率更高。
- 局限性:动态矩阵依赖 "实体投影向量" 和 "关系投影向量" 的协同学习,对数据量要求高 ------ 低频实体 / 关系的投影向量学习不充分,可能导致映射偏差。
2.5 DistMult:基于 "对角矩阵" 的关系线性变换
DistMult 与上述 "平移模型"(Trans 系列)思路完全不同,核心是将 "关系" 视为 "实体向量的线性变换",通过对角矩阵简化计算,专注建模实体间的 "成对关联"(如对称关系、自反关系)。
- 核心假设与数学逻辑
- 核心假设:关系的语义可通过 "实体向量的元素级乘法" 体现(如 "配偶" 关系是 "性别""年龄" 等元素的关联,"位于" 关系是 "经纬度" 元素的关联)。
- 关键操作:对角矩阵变换 :对每个关系r,定义对角矩阵Mr(仅对角线有值,非对角线为 0),其含义是 "对实体向量的每个维度(语义特征)进行加权";(对角矩阵的优势:将矩阵乘法简化为元素级乘法,计算量仅为普通矩阵的 1/d,d 为向量维度)
- 评分函数:通过 "头实体→关系变换→尾实体" 的内积计算三元组合理性,内积越大,三元组越可能为真:fr(h,t)=h⋅Mr⋅t⊤(展开后为∑i=1dhi⋅Mr,ii⋅ti,即元素级加权后的内积)
- 优势与局限性
- 优势 :
- 模型简单、计算高效(对角矩阵减少运算量);
- 擅长建模 "对称关系"(如 "朋友",若h⋅Mr⋅t⊤高,则t⋅Mr⋅h⊤也高)和 "自反关系"(如 "等于")。
- 局限性 :
- 无法建模 "非对称关系"(如 "父亲",h是t的父亲,不代表t是h的父亲,但 DistMult 的评分会对称);
- 线性变换的表达能力有限,难以处理复杂的语义关联(如多跳推理中的间接关系)。
三、知识图谱推理补全(KGC)
从已知事实推断出新的事实或知识的过程叫做推理。知识图谱的推理,主要关注围绕关系的推理。基于图谱中已有的事实或关系来推断未知的事实或关系。
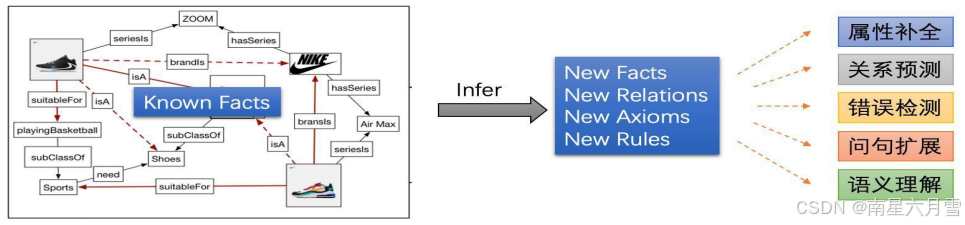
- 链接预测:给定两个实体,预测它们之间是否存在 r 关系。
- 实体预测:给定头实体和关系,预测未知的尾实体。
- 事实三元组预测:给定一个三元组判断其是否为真或假。
知识图谱"生来"不完整,多数的现有知识图谱都是稀疏的,由此引出了图谱补全来向知识图谱添加新的三元组。我们需要做的,是基于图谱里已有的事实,去推理出缺失的事实。本质上说,图谱补全和推理任务非常类似,都是"无中生有"的过程,推理的结果可以作为新"知识"加入图谱。
如何评估一个图谱的推理任务的完成情况呢?预测问题与推理评价
- Hit@n:所有正确样本中排名在n以内的比例,n常用的取值为1,3,5,10
- MR:Mean Rank 所有预测样本的平均排名
- MRR:Mean Reciprocal Rank 先对所有预测样本的排名求倒数,然后求平均
3.1 基于符号/规则逻辑的推理方法
这是知识图谱补全(KGC)的一个研究方向 ------ 通过学习 "逻辑规则",用规则来推导图谱中缺失的关系或实体。
规则的格式是 head ← body:
head(头部):是一个 "原子"(可以理解为要推导的结论 ,通常是一个三元组,比如(Y, sonOf, X));body(身体):是一组 "原子"(可以理解为结论成立的条件,多个条件用 "∧" 表示 "同时满足")。
用关系sonOf(是... 的儿子)、hasChild(有孩子)、性别,以及实体X(父)、Y(子),规则可以写成:(Y,sonOf,X)←(X,hasChild,Y)∧(Y,性别,男性)。
3.2 基于表示学习(嵌入)的归纳推理
当有大量的关系或三元组需要推理时,基于向量表征的推理更有效率。将图谱推理问题转化为向量计算问题。缺陷在于可解释性问题,即我们知道预测的结果,但不知道为什么。
核心是先把知识图谱的实体、关系转化为低维向量(嵌入),再利用向量的数学特性来推理图谱中缺失的三元组。
整个方法分 2 步:嵌入学习 + 补全推理。
- 嵌入学习:把实体 / 关系转成向量
用专门的模型(比如你之前了解的 TransE、TransR、DistMult 等),以 "图谱中已有的三元组" 为训练数据,学习出每个实体、关系对应的低维向量:
- 目标是让 "真实三元组的向量满足模型假设"(比如 TransE 要求 "h + r ≈ t");
- 最终得到一个 "向量字典":每个实体 / 关系对应一个固定长度的向量。
- 补全推理:用向量找缺失的三元组
对于图谱中缺失的部分(比如 "(h, r, ?)" 或 "(?, r, t)"),利用向量的特性推理:
- 以 "补全尾实体" 为例:已知头实体 h 和关系 r,计算 "h 向量 + r 向量",然后在所有实体向量中找最接近这个结果的向量,对应的实体就是补全的尾实体 t;
- 本质是用 "向量空间的相似度" 替代 "语义 / 结构的合理性"。
