摘要
问答、机器翻译、阅读理解和文本摘要等自然语言处理任务,通常是通过在特定任务数据集上进行监督学习来实现的。我们的研究表明,当语言模型在一个名为 WebText、包含数百万网页内容的新型数据集上完成训练后,无需任何显式监督,就能自主习得这类任务的处理能力。当给定一篇文档和若干问题作为输入条件时,该语言模型在 CoQA 数据集上生成的答案可达到 55 的 F1 值 ------ 在未借助 12.7 万余条训练样本的情况下,其性能已持平甚至超越了 4 个基线系统中的 3 个。语言模型的容量是实现零样本任务迁移 的关键所在,且增大模型容量能够以对数线性的方式提升各任务的性能表现。我们研发的最大规模模型 GPT-2,是一个拥有 15 亿参数的 Transformer 模型;在零样本设置下,该模型在 8 个受测语言建模数据集里,有 7 个取得了当前最优的性能结果,但它在 WebText 数据集上仍存在欠拟合现象。从该模型生成的文本样本可以看出上述性能提升的效果,样本中包含了语义连贯的完整段落。这些研究发现,为构建基于自然出现的任务示例来自主学习执行能力的语言处理系统,指明了一条极具前景的技术路径。
1.介绍
借助大规模数据集、高容量模型与监督学习的组合方式,机器学习系统如今在其受训任务上的表现(平均来看)已十分出色(Krizhevsky 等人,2012;Sutskever 等人,2014;Amodei 等人,2016)。然而,这类系统鲁棒性较差,对数据分布的细微变化(Recht 等人,2018)以及任务设定的微调均十分敏感(Kirkpatrick 等人,2017)。当前的系统更适合被定义为 "专精型专家",而非 "全能型通才"。我们期望朝着构建更通用系统的方向迈进 ------ 这类系统能够胜任多项任务,最终甚至无需为每项任务手动创建并标注训练数据集。
构建机器学习(ML)系统的主流方法是:先收集一组训练样本数据集,其中样本需能体现目标任务所需的正确行为模式;随后训练系统模仿这些行为模式;最后,利用 ** 独立同分布(IID)** 的预留测试样本对系统性能进行验证。
这种方法在打造 "专精型任务模型" 方面成效显著。然而,图像描述模型(Lake 等人,2017)、阅读理解系统(Jia & Liang, 2017)以及图像分类器(Alcorn 等人,2018)在面对丰富多样的输入数据时,往往会表现出不稳定的行为,这也凸显出该方法存在的部分缺陷(Narrow experts专精型任务模型,Independent and identically distributed (IID)独立同分布(IID),Erratic behavior不稳定的行为,Held-out examples预留测试样本)。
我们推测,在单一领域数据集上开展单任务训练的普遍做法,是导致现有系统泛化能力不足的主要原因。若想依托现有模型架构实现鲁棒性更强的系统,就需要在多领域、多任务的场景下开展训练并评估性能。近来,研究界已提出若干相关基准测试集,例如 GLUE(Wang 等人,2018)与 decaNLP(McCann 等人,2018),以此着手开展该方向的研究(Generalization泛化能力)。
多任务学习 (Caruana, 1997)是一种有望提升模型通用性能的有效框架。然而,多任务学习在自然语言处理领域的应用仍处于初步探索阶段 。近期相关研究显示,该方法仅能带来小幅的性能提升(Yogatama et al., 2019);迄今为止,两项最具挑战性的尝试也仅分别基于 10 组和 17 组 **(数据集 - 目标任务)配对 ** 展开训练(McCann et al., 2018; Bowman et al., 2018)。从元学习的视角来看,每一组(数据集 - 目标任务)配对,都可视为从 "数据集 - 目标任务" 分布中采样得到的一个独立训练样本。当前的机器学习系统通常需要数百乃至数千个样本,才能学习到具备良好泛化能力的函数。这意味着,在现有技术方案下,多任务学习若要充分发挥其潜力,或许也需要同等规模的有效训练配对。但依靠现有技术手段,要将数据集构建与目标任务设计的规模拓展到实现这一目标所需的程度,难度极大。这也促使学界开始探索适用于多任务学习的其他训练范式。(Nascent初步探索阶段,Induce functions学习到函数,Brute force依靠现有技术手段,Setups训练范式)
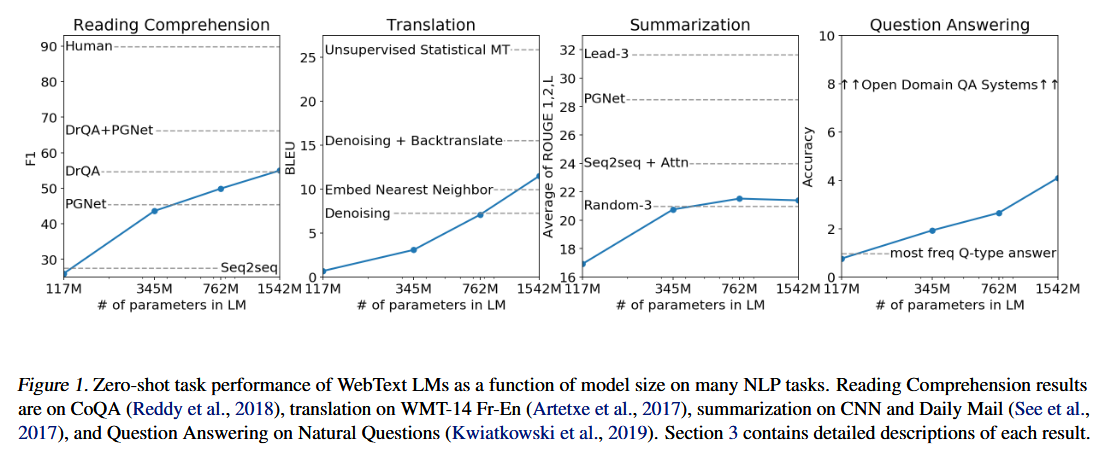
图1。WebText LMs在许多NLP任务中随模型规模变化的零样本任务表现。阅读理解结果包括CoQA(Reddy等,2018)、WMT-14法语翻译(Artetxe等,2017)、CNN和每日邮报的摘要(见等,2017),以及自然问题的问答(Kwiatkowski等,2019)。第3节详细描述了每个结果。
当前在各类语言任务上表现最优的系统,均采用了预训练 与监督微调相结合的技术方案。这种方法由来已久,且一直朝着更灵活的迁移学习范式方向发展。最初,研究人员先学习得到词向量,并将其作为特定任务模型架构的输入(Mikolov 等人,2013;Collobert 等人,2011);随后,循环神经网络的上下文表征被用于迁移学习(Dai & Le, 2015;Peters 等人,2018);而近期的研究表明,特定任务的模型架构已不再是必需的,迁移多个自注意力模块便足以完成相关任务(Radford 等人,2018;Devlin 等人,2018)。
这类方法在执行任务时,仍需依赖监督式训练。而当仅有少量监督数据、甚至完全没有监督数据可用时,另有一类研究已证实:语言模型具备完成特定任务的潜力,例如常识推理任务(Schwartz 等人,2017)与情感分析任务(Radford 等人,2017)。(Minimal supervised data少量监督数据,Commonsense reasoning常识推理,Demonstrate the promise of证实...... 的潜力)
在本文中,我们将这两类研究工作相结合,并延续了更通用迁移方法 的发展趋势。研究证实,语言模型能够在零样本设置 下完成下游任务 ------ 且无需对模型参数或架构进行任何修改。我们通过验证语言模型在零样本场景下完成各类任务的能力,证明了该方法的应用潜力。根据任务类型的不同,我们的方法取得了兼具前景性、竞争力的效果,部分任务上甚至达到了当前最优水平( State of the art results当前最优水平**)**。
2.方法
我们研究方法的核心是语言建模。语言建模通常被定义为一项基于样本集的无监督分布估计任务,样本集中的每个样本 (x1,x2,...,xn) 均由可变长度的符号序列 (s1,s2,...,sn) 构成。由于语言本身具有天然的序列顺序,学界普遍做法是将符号的联合概率分解为条件概率的乘积形式(Jelinek & Mercer, 1980;Bengio et al., 2003):
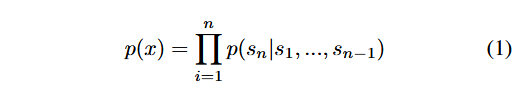
这种方法不仅能够便捷地对概率分布 p(x) 进行采样与估计,还可处理任意形如 p(sn−k,...,sn∣s1,...,sn−k−1) 的条件概率。近年来,可计算此类条件概率的模型在表达能力上实现了显著提升,例如以 Transformer 为代表的自注意力架构(Vaswani 等人,2017)。(Tractable sampling便捷采样,Estimation估计)
学习完成单一任务的过程,在概率框架中可被描述为对条件概率分布 p(输出∣输入) 的估计。由于一个通用系统应当能够完成多种不同任务,即便对于相同的输入,该系统也不仅需要以输入为条件,还需以待执行的任务为条件。也就是说,系统需要对概率分布 p(输出∣输入,任务) 进行建模。这一思路已在多任务学习与元学习的研究框架中被赋予了多种形式化定义。
任务条件机制的实现方式通常分为两类:一类是在架构层面 实现,例如凯泽等人(Kaiser et al., 2017)提出的任务专属编码器与解码器;另一类是在算法层面 实现,例如模型无关元学习(MAML)所采用的内外循环优化框架(Finn et al., 2017)。但正如麦肯等人(McCann et al., 2018)的研究实例所揭示的那样,语言能够提供一种灵活的方式,将任务、输入与输出全部表示为符号序列。例如,一个机器翻译的训练样本可被写成如下序列:(翻译成法语,英文文本,法语文本)。同理,一个阅读理解的训练样本可被写成:(回答问题,文档,问题,答案)。麦肯等人(2018)的研究证实,基于上述格式的样本,能够训练出一个单一模型 ------多任务问答网络(MQAN),该模型可自主推断并完成多种不同的任务。
从原理上来说,语言建模同样能够完成麦肯等人(2018)提出的各项任务,且无需对哪些符号属于待预测输出进行显式监督。由于监督学习的目标函数与无监督学习的目标函数本质相同,二者的区别仅在于监督学习的目标函数仅在序列的一个子集上进行评估,因此无监督目标函数的全局最小值同时也是监督目标函数的全局最小值。在这种略显简化的设定下,萨特克韦等人(2015)所探讨的、将密度估计作为一种规范训练目标所存在的问题便被规避了。相应地,问题的核心转变为:在实际操作中,我们能否将无监督目标函数优化至收敛状态。初步实验证实,规模足够大的语言模型能够在这种简化设定下完成多任务学习,但相较于显式监督学习方法,其学习效率要低得多。(Explicit supervision显式监督,Supervised/unsupervised objective监督 / 无监督目标函数,Global minimum全局最小值,Optimize... to convergence优化至收敛状态,Toy-ish setup简化设定)
尽管从上述定义明确的设定,到真实场景中 "杂乱无章的语言数据",这中间还存在巨大的跨越,但韦斯顿(Weston, 2016)在对话系统的研究背景下指出,我们亟需开发能够直接从自然语言中学习的系统,并完成了一项概念验证 ------ 通过对 "教师模型" 输出结果的正向预测,在无需奖励信号的条件下实现了问答任务的学习。(Well-posed setup定义明确的设定,Language in the wild真实场景中杂乱无章的语言数据,Forward prediction正向预测)
对话式学习固然是一种颇具吸引力的方法,但我们认为其局限性过于明显。互联网中蕴藏着海量的信息资源,这些信息可被动获取,完全不需要通过交互式通信的方式。我们推测,只要语言模型具备足够的容量,它就会自主学习去推断并执行那些隐含在自然语言序列中的任务,进而更精准地完成预测工作,且这一过程与信息的获取方式无关。如果语言模型确实能够实现这一点,那么它实际上就是在执行无监督多任务学习。为了验证这一猜想,我们通过分析语言模型在零样本设定下,于各类不同任务中的性能表现展开了相关测试。(Passively available可被动获取)
2.1训练数据集
此前的大多数研究仅在单一文本领域训练语言模型,例如新闻稿件(Jozefowicz 等人,2016)、维基百科词条(Merity 等人,2016)或虚构类书籍(Kiros 等人,2015)。而我们的方法则主张构建尽可能规模庞大、类型多样的数据集,以期在尽可能丰富的领域与场景下,收集到各类任务的自然语言示例。
一种极具潜力、类型多样且近乎取之不竭的文本数据源,是诸如Common Crawl (通用网络爬虫数据集)这类网络爬取数据。尽管这类数据档案库的规模,要比现有语言建模数据集大数个数量级,但它们存在着严重的数据质量问题。(Many orders of magnitude数个数量级)
陈庭和乐(Trinh & Le, 2018)曾在其常识推理相关研究中使用过 Common Crawl 数据集,不过他们也指出,该数据集中存在大量 "内容基本难以理解" 的文档。我们在初期使用 Common Crawl 开展实验时,也发现了类似的数据问题。陈庭和乐团队之所以能取得最优实验结果,是因为他们仅选取了 Common Crawl 数据集中的一个小型子集 ------ 该子集只包含与他们的目标数据集(威诺格拉德模式挑战数据集)最为相似的文档。

虽然这种方法对于提升特定任务的性能而言,不失为一种务实的策略,但我们希望避免提前对待执行的任务做出任何预设。(Pragmatic approach务实的策略)
因此,我们构建了一个全新的网络爬取数据集 ,其核心在于对文档质量的把控。为达成这一目标,我们仅爬取那些经过人工筛选或审核的网页。若要对完整的网络爬取数据进行人工过滤,成本会高得惊人。因此,我们选择了一个切入点:爬取社交媒体平台Reddit上所有获得至少 3 个 ** 点赞积分(karma)** 的外链内容。这一指标可被视为一种启发式判断依据,用于衡量其他用户是否认为该链接内容有趣、具有教育意义或是能让人产生共鸣。(Curated/filtered筛选或审核)
最终得到的数据集 WebText ,包含了这 4500 万条链接对应的文本子集。在从 HTML 响应中提取文本时,我们结合使用了 Dragnet (Peters & Lecocq, 2013)与 Newspaper1 这两款内容提取工具。本文所呈现的所有实验结果,均基于 WebText 数据集的一个初步版本 ------ 该版本未纳入 2017 年 12 月之后生成的链接;经过去重与基于启发式规则的清洗流程后,它共包含略超 800 万份文档,文本总量达 40GB。我们从 WebText 中剔除了所有维基百科文档,原因在于维基百科是其他数据集的常用数据源,其内容若与测试评估任务的训练数据存在重叠,可能会使分析过程变得复杂。(De-duplication去重,Heuristic based cleaning基于启发式规则的清洗)
2.2输入表示
一个通用的语言模型(LM)应当能够计算任意字符串的概率(同时也能生成任意字符串)。当前的大规模语言模型会包含一些预处理步骤,例如小写转换 、分词 以及未登录词处理,而这些步骤会限制模型可建模的字符串范围。(Lowercasing小写转换,Out-of-vocabulary tokens未登录词处理,)
尽管如吉利克等人(Gillick et al., 2015)的研究所示,将 Unicode 字符串作为 UTF-8 字节序列来处理,能够巧妙地满足这一通用建模需求,但在诸如十亿词基准数据集(Al-Rfou et al., 2018)这类大规模数据集上,现有的字节级语言模型与词级语言模型相比,性能仍存在差距。我们在 WebText 数据集上训练标准字节级语言模型时,也观察到了类似的性能落差。(Byte-level LMs字节级语言模型,Word-level LMs词级语言模型)
字节对编码(Byte Pair Encoding, BPE)(森里希等人,2015)是一种介于字符级与词级语言建模之间的实用折中方案,它能针对高频符号序列采用词级输入,针对低频符号序列采用字符级输入,实现二者的有效插值融合。(Character/word level language modeling字符级 / 词级语言建模,Interpolates插值融合)
尽管名称中带有 "字节" 字样,但主流的 BPE 实现方案通常是基于Unicode 码点而非字节序列运行的。若要对所有 Unicode 字符串进行建模,这类实现方案就必须纳入全部 Unicode 符号,这会导致在添加任何多符号标记之前,基础词表规模就超过 13 万个。相较于 BPE 常用的 3.2 万至 6.4 万标记词表,这样的规模过于庞大,难以实际应用。(Greedy frequency based heuristic基于频率的贪心启发式算法)
相比之下,字节级 BPE 仅需一个规模为 256 的基础词表。然而,直接将 BPE 应用于字节序列会产生非最优的合并结果 ,因为 BPE 采用的是基于频率的贪心启发式算法来构建标记词表。我们观察到,BPE 会生成同一个常用词的多种变体形式,例如 "dog" 一词会衍生出dog、dog!、dog?等多个标记;这会造成有限的词表空间与模型容量无法得到合理分配。(Suboptimal merges非最优的合并结果,Compression efficiency压缩效率)
为规避这一问题,我们限制 BPE 在处理任意字节序列时,不能跨字符类别进行合并操作。同时,我们对空格做了例外处理 ------ 这一改动在仅导致单词被切分为多个词表标记的情况小幅增加的前提下,显著提升了编码的压缩效率。
这种输入表示方式,能够让我们兼具词级语言模型的实证优势与字节级方法的通用性。由于我们的方法可以为任意 Unicode 字符串分配概率,因此我们能够在任意数据集上对语言模型进行评估,且不受预处理方式、分词策略或词表规模的限制。(Empirical benefits实证优势,Generality通用性,Assign a probability分配概率,Tokenization分词策略)
2.3模型
我们的语言模型(LM)采用了基于Transformer 架构的模型方案(Vaswani 等人,2017)。该模型大体上沿用了 OpenAI GPT 模型的技术细节(Radford 等人,2018),仅做了几处修改:
- 我们将层归一化 (Ba 等人,2016)迁移至每个子模块的输入端,这一改动与预激活残差网络的设计思路一致(He 等人,2016);同时,在最后的自注意力模块之后新增了一层归一化操作。
- 采用了一种改进的参数初始化策略,该策略能够适配残差路径上的参数累积效应与模型深度的关联。在初始化阶段,我们将残差层的权重按 1/N 的系数进行缩放,其中 N 代表残差层的数量。
- 将词表规模扩充至 50,257。
- 另外,我们还将上下文窗口大小从 512 个标记扩充至 1024 个标记,并采用了更大的批次尺寸,设为 512。
3.实验
我们训练并评测了4 个语言模型 ,其规模按近似对数均匀分布的方式设定。各模型的架构参数详见表 2 。其中,最小模型的规模与原版 GPT 模型相当;次小模型则与 BERT 系列中参数量最大的模型(Devlin 等人,2018)规模持平。我们将最大的模型命名为 GPT-2,其参数量较原版 GPT 提升了一个数量级以上。
为了在 WebText 数据集 5% 的预留验证集上实现最优困惑度,我们对每个模型的学习率都进行了手动调优。目前所有模型均未对 WebText 数据集产生过拟合,并且随着训练时长的增加,预留验证集上的困惑度指标至今仍在持续优化。(Held-out sample预留验证集,An order of magnitude一个数量级)
3.1语言建模
作为零样本任务迁移 的初步探索,我们旨在探究 WebText 语言模型在其训练的主任务 ------ 语言建模任务上,实现零样本领域迁移的表现。由于我们的模型基于字节级运行,且无需进行有损耗的预处理或分词操作,因此它能够在任意语言建模基准测试集上完成评估。
语言建模数据集的评测结果,通常以一个特定指标来呈现:该指标是标准预测单元(通常为字符、字节或单词)的平均负对数概率的标度化或指数化形式。我们采用了相同的指标进行评估,具体方式为:根据 WebText 语言模型计算数据集的对数概率,再除以标准预测单元的数量。
对于其中的诸多数据集而言,WebText 语言模型的测试场景会存在显著的分布偏移 ------ 模型需要预测高度标准化的文本、分词操作带来的冗余内容(例如分离的标点符号与缩约形式)、打乱顺序的句子,甚至是 <UNK> 这类特殊字符串。而 <UNK> 在 WebText 数据集中极为罕见,在 400 亿字节的文本里仅出现过 26 次。
我们在表 3 中报告了核心实验结果,该结果的获取借助了可逆反分词器 ------ 这类工具能够最大程度消除上述由分词或预处理引入的冗余干扰。由于反分词器具备可逆性,我们仍可计算出数据集的对数概率,同时这类工具也可被视作一种简易的领域适配方法。实验结果显示,搭配可逆反分词器后,GPT-2 模型的困惑度指标降低了 2.5~5 个单位。(Canonical prediction unit标准预测单元,Out-of-distribution分布偏移,Tokenization artifacts分词操作冗余内容,Invertible de-tokenizers可逆反分词器)
WebText 语言模型在不同领域与数据集间展现出优异的迁移性能,在零样本设定下,它在8 个数据集里的 7 个上刷新了当前最优水平。
在部分小规模数据集(例如仅包含 100 万至 200 万训练标记的宾州树库与 WikiText-2)上,模型性能实现了大幅提升。同时,在那些用于衡量长程依赖关系的数据集(如 LAMBADA 数据集(帕佩尔诺等人,2016)与儿童书籍测试集(希尔等人,2015))上,模型也取得了显著改进。
不过,在十亿词基准数据集(切尔巴等人,2013)上,我们的模型性能仍明显落后于此前的研究成果。这一现象很可能是两方面因素共同作用的结果:其一,该数据集是所有实验数据集中规模最大的;其二,它采用了破坏性极强的预处理流程 ------ 十亿词基准数据集执行的句子级打乱操作,彻底消除了文本中原有的所有长程结构信息。(Sentence level shuffling句子级打乱操作)
3.2儿童图书测试
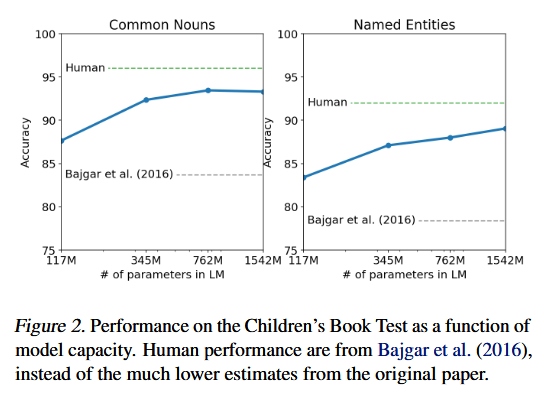
儿童书籍测试集(Children's Book Test, CBT) (希尔等人,2015)的构建初衷,是为了考察语言模型在不同词汇类别上的性能表现,具体包括命名实体、名词、动词与介词四类词汇。
该测试集并未采用困惑度作为评估指标,而是通过自动构建的完形填空测试来衡量准确率 ------ 测试任务为从 10 个候选词中,预测被省略单词的正确答案。我们沿用了原始论文提出的语言模型评估方法:根据模型计算每个候选词的概率,以及基于该候选词的句子剩余部分的概率,最终选取概率最高的候选词作为预测结果。
如图 2 所示,随着模型规模的增大,性能表现稳步提升,且大幅缩小了与人类水平在该测试上的差距。数据重叠性分析显示,CBT 测试集中的一本读物 ------ 拉迪亚德・吉卜林所著的《丛林之书》,其文本内容存在于 WebText 数据集中。因此,我们最终报告的是验证集上的实验结果,该验证集与 WebText 无显著内容重叠。
GPT-2 模型在该验证集上取得了全新的当前最优结果:普通名词类任务准确率达 93.3%,命名实体类任务准确率达 89.1%。此外,我们还对 CBT 数据应用了反分词器,以去除其中宾州树库(PTB)风格的分词冗余内容。(Cloze test完形填空测试,)
3.3 LAMBADA 数据集
LAMBADA 数据集(帕佩尔诺等人,2016)用于测试模型对文本中长程依赖关系的建模能力。该任务的目标是预测句子的末尾单词,而人类要成功完成这一预测,需要依托至少 50 个标记的上下文信息。
GPT-2 模型将该任务的当前最优困惑度指标从 99.8(格雷夫等人,2016)降至 8.6,同时将语言模型在该测试中的准确率从 19%(德加尼等人,2018)提升至 52.66%。对 GPT-2 错误案例的分析显示:模型的大多数预测结果虽能构成句子的合理延续,但并非符合任务要求的句末目标词。这表明语言模型未能利用一个额外的有效约束条件 ------预测单词必须是句子的最后一个词。
我们通过添加停用词过滤器来近似实现这一约束,此举将模型准确率进一步提升至 63.24%,较该任务此前的最优水平整体提升 4%。此前的最优模型(黄等人,2018)采用了一种限制性更强的预测设定:模型输出被限定为仅能从上下文已出现的词汇中选取。而对于 GPT-2 而言,这种限制弊大于利,因为该任务中 19% 的正确答案并未出现在上下文语境中。本研究使用的数据集版本未经过任何预处理操作。(Perplexity困惑度)
3.4. Winograd Schema Challenge
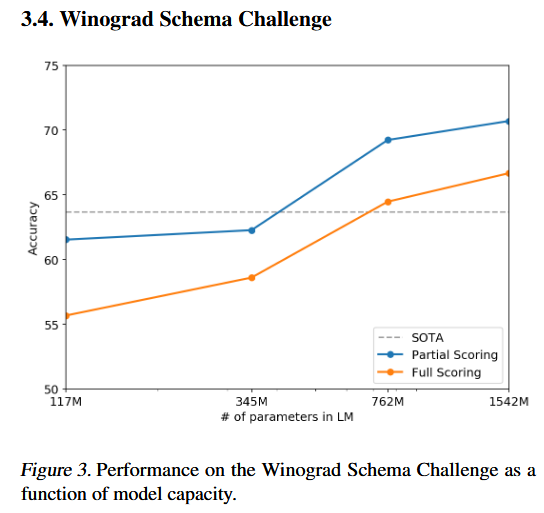
威诺格拉德模式挑战任务 (莱韦斯克等人,2012)的设计初衷,是通过衡量系统消解文本歧义的能力,来评估其常识推理的性能。(Commonsense reasoning常识推理)
近期,陈庭和乐(Trinh & Le, 2018)借助语言模型在该任务上取得了显著进展,其核心方法是让模型对歧义消解的正确结果输出更高的预测概率。我们沿用了他们提出的问题建模方式,并在图 3 中分别展示了模型在全评分法 与部分评分法两种评估方式下的性能表现。GPT-2 模型将该任务的当前最优准确率提升了 7 个百分点,最终达到 70.70%。需要说明的是,该数据集规模极小,仅包含 273 个样本,因此我们建议读者参考特里谢莱尔等人(Trichelair et al., 2018)的研究,以更全面地理解本研究结果的背景。
3.5阅读理解
对话问答数据集(CoQA) (雷迪等人,2018)包含来自 7 个不同领域的文档,每个文档均配有提问者与回答者围绕该文档展开的自然语言对话内容。CoQA 不仅用于测试模型的阅读理解能力,还可评估模型回答那些依赖对话历史语境的问题(例如 "为什么?" 这类问题)的能力。
以文档、对应对话历史以及最终标记 A: 为条件,对 GPT-2 模型执行贪心解码 ,在开发集上取得了 55 的 F1 值 。这一性能达到甚至超过了 4 个基线系统中 3 个 的水平,且该模型并未使用那些基线系统所依赖的、超过 12.7 万条人工标注的问答对进行训练。(Greedy decoding贪心解码,Development set开发集,)
目前该任务的监督式最优模型 是一个基于 BERT 的系统(德夫林等人,2018),其 F1 值已接近人类水平的 89 。尽管对于一个未经过任何监督训练的模型而言,GPT-2 的这一性能表现已十分亮眼,但对其答案与错误案例的分析显示:GPT-2 往往会采用基于简单信息检索的启发式策略生成回答,例如在回答 who(谁) 类问题时,直接从文档中提取人名作为答案。(Supervised SOTA监督式最优模型)
3.6总结
我们在 CNN 与每日邮报数据集 (纳拉帕蒂等人,2016)上测试了 GPT-2 模型的文本摘要生成能力。为引导模型产生摘要生成行为,我们在文章末尾添加文本标记 TL;DR: (即 "太长不看"),随后采用 Top-k 随机采样策略(范等人,2018)生成 100 个标记,其中 k 值设为 2。该策略相较于贪心解码,能够有效减少文本重复,且更易生成侧重语义提炼的摘要。我们将生成的 100 个标记中前 3 个完整句子作为最终摘要。
如表 14 所示,尽管生成的摘要在质量上已具备摘要的基本特征,但它们往往聚焦于文章末尾的内容,或是混淆具体细节信息 ------ 例如某次车祸的涉事车辆数量、某一标识是印在帽子上还是衬衫上。在常用的 ROUGE-1、ROUGE-2、ROUGE-L 评价指标上,这些生成摘要的性能仅开始接近传统神经基线模型,且仅微弱优于直接从文章中随机选取 3 个句子的效果。
当移除任务提示标记后,GPT-2 在综合指标上的得分下降了 6.4 个百分点。这一结果证明,可以通过自然语言指令触发语言模型执行特定任务的行为。()
3.7翻译

我们测试了 GPT-2 是否已具备跨语言翻译能力。为引导模型推断出这一预期任务,我们为语言模型设定了特定上下文 ------ 即若干组格式为英文句子 = 法文句子 的示例对;随后,在给出英文句子 = 这一最终提示后,采用贪心解码策略从模型中采样生成内容,并将生成的第一句作为翻译结果。
在 WMT-14 英法翻译测试集 上,GPT-2 的 BLEU 得分 为 5,这一成绩略逊于此前无监督单词翻译研究中,基于双语词典实现的逐词替换方法(Conneau 等人,2017b)。而在 WMT-14 法英翻译测试集上,GPT-2 得以借助其性能强劲的英文语言建模能力,取得了更为亮眼的表现,BLEU 得分达到 11.5。该成绩优于 Artetxe 等人(2017)与 Lample 等人(2017)提出的多款无监督机器翻译基线模型,但与当前最优无监督机器翻译方法的 33.5 BLEU 得分相比,仍存在较大差距(Artetxe 等人,2019)。
GPT-2 在翻译任务上的表现令我们颇感意外,因为在数据过滤阶段,我们就已刻意从 WebText 数据集中剔除了所有非英文网页内容。为验证这一点,我们在 WebText 上运行了一个字节级语言检测器,结果显示数据集中仅检测出 10MB 的法语文本数据 ------ 这一规模约为以往无监督机器翻译研究中常用单语法语语料库的 1/500。
3.8问答
检验语言模型中包含何种信息的一个潜在方法,是评估模型针对事实类问题生成正确答案的频率。此前在参数化存储全部信息的神经模型中,例如《神经对话模型》(维尼亚尔斯与乐,2015),就曾展示过这种能力,但受限于缺乏高质量的评估数据集,当时仅公布了定性分析结果。
近期推出的自然问题数据集 (克维亚特科夫斯基等人,2019),为更精准地开展定量测试提供了极具价值的资源。与翻译任务的设置类似,我们在语言模型的上下文输入中加入了若干问答示例对,以此引导模型匹配该数据集所需的简短答案格式。
在阅读理解类数据集(如斯坦福问答数据集 SQUAD)常用的精确匹配指标 下,GPT-2 的问题答对率为 4.1%。作为对比参照,实验中最小规模的模型,其准确率未能超过一个极为简单的基线模型 ------ 该基线模型的策略是针对不同类型的问题(如人物类、事物类、地点类等),直接返回对应类别中最常见的答案,其准确率仅为 1.0%。GPT-2 的正确答题数是该基线模型的 5.3 倍,这表明模型容量是迄今为止制约神经模型在该类任务中表现不佳的关键因素。
GPT-2 为生成答案分配的概率具有良好的校准性:在模型最有把握回答的 1% 的问题上,其准确率达到了 63.1%。表 5 展示了 GPT-2 针对开发集问题生成的 30 个置信度最高的答案。尽管表现有所突破,但相较于结合信息检索与抽取式文档问答技术的开放域问答系统(阿尔贝蒂等人,2019)所能达到的 30%---50% 的准确率区间,GPT-2 的性能仍存在巨大差距。(Factoid-style questions事实类问题,Qualitative results定性分析结果,Quantitative test定量测试,Well calibrated概率校准性良好)
4. 泛化能力与记忆能力
计算机视觉领域的近期研究表明,常用图像数据集内存在数量不容忽视的近似重复图像。例如,CIFAR-10 数据集的训练图像与测试图像之间存在 3.3% 的重叠率(巴尔茨与登茨勒,2019)。这一现象会导致机器学习系统的泛化性能被高估。随着数据集规模的不断扩大,此类问题出现的概率也会持续上升,这意味着 WebText 数据集可能也存在类似的现象。因此,分析测试数据在训练数据中的重合比例,是一项至关重要的工作。(Near-duplicate images近似重复图像,Over-reporting高估)
为开展此项研究,我们构建了包含 WebText 训练集标记 8 元语法 的布隆过滤器。为提升召回率,我们对字符串进行了归一化处理:仅保留小写字母和数字字符,且以单个空格作为分隔符。在布隆过滤器的构建过程中,我们将误报率的上限设定为 1×10−8。为进一步验证该低误报率,我们生成了 100 万个测试字符串,结果显示过滤器未检测到任何误报情况。(False positive rate误报率)
我们的方法以提升召回率 为优化目标。人工核查重叠内容后发现,其中既包含大量常见短语,也存在不少由数据重复导致的长文本匹配情况。这种现象并非 WebText 数据集所独有。例如,我们发现 WikiText-103 的测试集中,有一篇文章同时存在于其训练集内。鉴于该测试集仅包含 60 篇文章,这意味着其自身训练集与测试集的重叠率至少达到 1.6%。更值得警惕的是,依据我们的检测流程,十亿词基准数据集(1BW)的测试集与其自身训练集的重叠率高达 13.2%。
在威诺格拉德模式挑战任务的检测中,我们发现仅有 10 个模式案例与 WebText 训练集存在 8 元语法的重叠情况。这 10 个案例里,有 2 个属于虚假匹配 。在剩下的 8 个真实匹配案例中,仅有 1 个模式案例出现在了能够泄露答案线索的上下文语境中。(Gave away the answer泄露答案线索,Spurious matches虚假匹配)
在 CoQA 数据集上,新闻领域约 15% 的文档已包含在 WebText 数据集中,且模型在这些文档上的 F1 值提升了约 3 个单位。CoQA 开发集的评估指标为 5 个不同领域的平均性能,经测算,受各领域数据重叠的影响,模型整体性能的 F1 值提升了约 0.5 至 1.0 个单位。不过,由于 CoQA 的发布时间晚于 WebText 数据集的链接采集截止日期,WebText 中并未包含该数据集任何真实的训练问答对。(Cutoff date采集截止日期)
在 LAMBADA 数据集上,平均重叠率为 1.2%。对于重叠率高于 15% 的样本,GPT-2 的困惑度指标优化了约 2 个单位。
当剔除所有存在重叠的样本后重新计算指标,困惑度从 8.6 上升至 8.7,准确率则从 63.2% 下降至 62.9%。整体指标的变化幅度极小,这很可能是因为在全部样本中,存在显著重叠的样本占比仅为 1/200。(Overlap重叠率,Perplexity困惑度)
总体而言,我们的分析表明 :WebText 训练数据与各特定评估数据集之间的数据重叠 ,会对报告的实验结果产生小幅但持续的增益 。不过,正如表 6所强调的那样,对于大多数数据集而言,我们并未发现其与 WebText 的重叠程度,显著高于标准训练集与测试集之间本身就存在的重叠程度。
探究并量化高度相似文本 对模型性能的影响,是一项重要的研究课题。性能更优的去重技术(例如可扩展模糊匹配),同样有助于更精准地解答这类问题。目前,我们建议:在构建新的自然语言处理(NLP)数据集的训练集与测试集划分时,应将基于 n 元语法重叠的去重方法作为一项重要的验证步骤与合理性检验手段。(De-duplication techniques去重技术,Scalable fuzzy matching可扩展模糊匹配,Sanity check合理性检验)
判断 WebText 语言模型的性能是否源于记忆效应 ,另一种潜在方法是检验模型在其预留验证集 上的表现。如图 4 所示,模型在 WebText 训练集与测试集上的性能表现相近,且均会随着模型规模的增大同步提升。这表明,即便像 GPT-2 这样的大模型,在很多方面仍对 WebText 数据集存在欠拟合现象。
GPT-2 还能够撰写关于发现会说话的独角兽的新闻报道。相关示例详见表 13。
5.相关工作
本研究的一大部分工作,旨在评估基于更大规模数据集训练的大语言模型 的性能表现。这与约泽夫维奇等人(2016)的研究具有相似性 ------ 后者曾在十亿词基准数据集上,对基于循环神经网络(RNN)的语言模型进行了规模扩展实验 。巴伊加尔等人(2016)此前也做过相关探索:他们借助古腾堡计划 的语料构建了一个规模庞大得多的训练数据集,以此补充标准训练数据集,最终在儿童书籍测试集(CBT)上取得了性能提升。赫斯特尼斯等人(2017)则开展了一项全面分析,探究各类深度学习模型的性能如何随模型容量 与数据集规模 这两个变量的变化而改变。尽管我们的实验在不同任务上的表现波动更大,但实验结果表明:这一规律同样适用于某一目标任务下的各类子任务,并且该规律在模型参数量突破10 亿级后依然成立。(Noisier across tasks任务间表现波动更大)
生成式模型中一些有趣的习得功能 此前已有相关研究记载,例如卡帕西等人(2015)发现,循环神经网络(RNN)语言模型的神经元具备行宽追踪 和引号 / 注释识别 的能力。对本研究更具启发意义的,则是刘等人(2018)的一项发现:一个经训练用于生成维基百科词条的模型,竟也学会了在不同语言之间进行人名翻译。
此前已有研究探索了网页大规模文本语料库的其他过滤与构建方法,例如iWeb 语料库(戴维斯,2018)。
针对语言任务的预训练方法,已有大量相关研究成果 。除引言部分提及的方法外,GloVe 模型 (彭宁顿等人,2014)将词向量表示学习的规模拓展至了整个通用网络爬虫语料库(Common Crawl) 。在文本深度表示学习领域,一项具有开创性的早期研究是跳读向量模型(Skip-thought Vectors) (基罗斯等人,2015)。麦肯等人(2017)探索了如何利用机器翻译模型生成的特征表示;霍华德与鲁德尔(2018)则改进了戴和乐(2015)提出的基于循环神经网络(RNN)的微调方法。康诺等人(2017a)研究了自然语言推理模型所学习到的特征表示的迁移性能;萨布拉马尼亚恩等人(2018)则开展了大规模多任务训练的相关探索。(Fine-tuning approaches微调方法,Transfer performance迁移性能)
拉马钱德兰等人(2016)的研究表明,若将预训练语言模型用作编码器与解码器的初始化参数,序列到序列(seq2seq)模型的性能将得到显著提升。近期还有研究显示,针对闲聊对话、对话式问答系统这类难度较高的生成任务,在微调阶段引入语言模型预训练的方法同样能起到良好效果(沃尔夫等人,2019;迪南等人,2018)。
6. 讨论
已有大量研究致力于学习 (希尔等人,2016)、理解 (利维与戈德堡,2014)以及严格评估 (维廷与基拉,2019)监督式和无监督式预训练方法所生成的特征表示。本研究的结果表明,无监督任务学习是另一个极具前景的探索方向。这些发现或有助于解释预训练技术在下游自然语言处理任务中广泛应用并取得成功的原因 ------ 因为我们的研究显示,从理论极限来看,此类预训练技术中的一种已能够直接学习执行任务,无需借助监督式适配或修改。
在阅读理解任务上,GPT-2 在零样本设置 下的性能可与监督式基线模型相媲美。然而,在文本摘要等其他任务中,尽管从定性角度来看模型确实完成了任务,但从定量指标衡量,其性能仍仅处于基础水平。这项成果虽具有一定的研究参考价值,但就实际应用而言,GPT-2 的零样本性能仍远未达到可用标准。(Rudimentary基础水平)
我们已在诸多经典自然语言处理任务 上,对基于 WebText 训练的语言模型的零样本性能 展开了研究,但仍有大量其他任务有待评估。毫无疑问,在许多实际任务中,GPT-2 的性能仍与随机猜测 无异。即便是在我们已评估的问答、翻译等常见任务上,语言模型也只有在具备足够容量 的前提下,才能够开始超越那些简易基线模型。(Canonical NLP tasks经典自然语言处理任务,No better than random与随机猜测无异)
零样本性能为 GPT-2 在诸多任务上的潜在表现划定了基准,但目前尚不清楚通过微调能将其性能上限提升至何种程度。在部分任务中,GPT-2 生成的完全抽象式输出 ,与当前在众多问答及阅读理解数据集上表现最优的、基于抽取式指针网络 (维尼亚尔斯等人,2015)的输出有着显著区别。鉴于此前 GPT 微调所取得的成功,我们计划在decaNLP 与GLUE 等基准测试集上开展微调相关研究;尤其是考虑到,目前还无法确定 GPT-2 所具备的额外训练数据与模型容量,是否足以弥补由 BERT(德夫林等人,2018)所揭示的单向特征表示的局限性。
7. 结论
当大语言模型在规模足够大且类型足够丰富的数据集上完成训练后,便能够在诸多领域与数据集上表现出优异性能。在 8 个受测的语言建模数据集中,GPT-2 在零样本设置下,有 7 个数据集的性能达到了当前最优水平。该模型能够在零样本条件下完成的任务种类十分多样,这表明:以最大化多样化文本语料的似然概率为目标训练的大参数量模型,无需借助显式监督,就可以习得数量惊人的任务执行能力。
致谢
感谢所有为 WebText 撰写文本、分享链接并为内容点赞的贡献者。参与构建 GPT-2 训练数据集的人员多达数百万。
同样感谢所有为我们提供训练基础设施支持的谷歌员工,包括扎克・斯通、JS・里尔、乔纳森・休、拉塞尔・鲍尔、程油龙、诺阿姆・沙泽尔、所罗门・布洛斯、迈克尔・班菲尔德、阿曼・古普塔、丹尼尔・索恩以及其他众多同仁。
最后,感谢为论文初稿提供反馈意见的各位:雅各布・斯坦哈特、山姆・鲍曼、杰弗里・欧文和麦迪逊・梅。