逆向某气骑士 - 绕过某讯的防御dump内存分析
书接上回本文章主要参考了:
https://www.52pojie.cn/thread-1844587-1-1.html
https://www.52pojie.cn/thread-1842883-1-1.html
https://www.bilibili.com/read/cv25143217/?opus_fallback=1
https://reimu.moe/2024/06/09/IL2Cpp-String-Literals/
前言
在我发布上一个帖子的12小时后,看到了一个大哥的评论

然后我突发奇想,是不是版本不对,虽然里面写的是18,但是会不会应该是1F,于是开始修改,没想到真的通了
修复后分析
修改版本号:
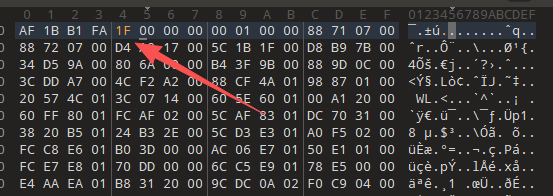
然后放到il2cppdumper中,得到最终数据,哈!真出来了
首先需要用sofix修复so文件:https://github.com/Chenyangming9/SoFixer#
然后使用IDA打开修复后的so文件(新版某气骑士文件很大,分析起来要花很长时间),使用File -Script File,选择ida_py3.py(il2cppdumper安装包中自带的那个),选择分析出的stringliteral.json
之后选择 ida_with_struct_py3.py,分析script.json和il2cpp.h
分析完成了!!!
既然已经分析完成了,那就搞点事情干,直接分析解密的存档的方式:
可以通过查看包内文件的方式找到实际的存档文件,这次就以game.data为例进行分析
分析存档
首先找到game.data
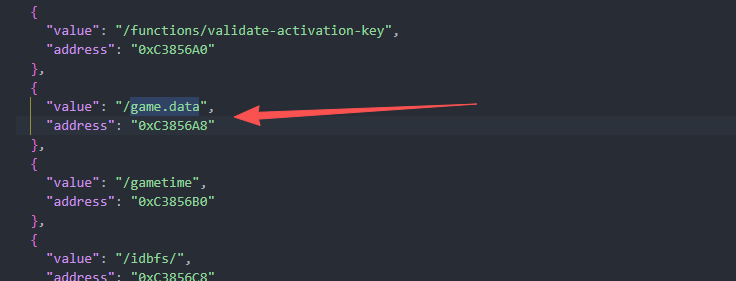
然后再IDA中按G ,输入地址后跳跃到对应的位置,之后在对应位置右键查询 List cross references to...
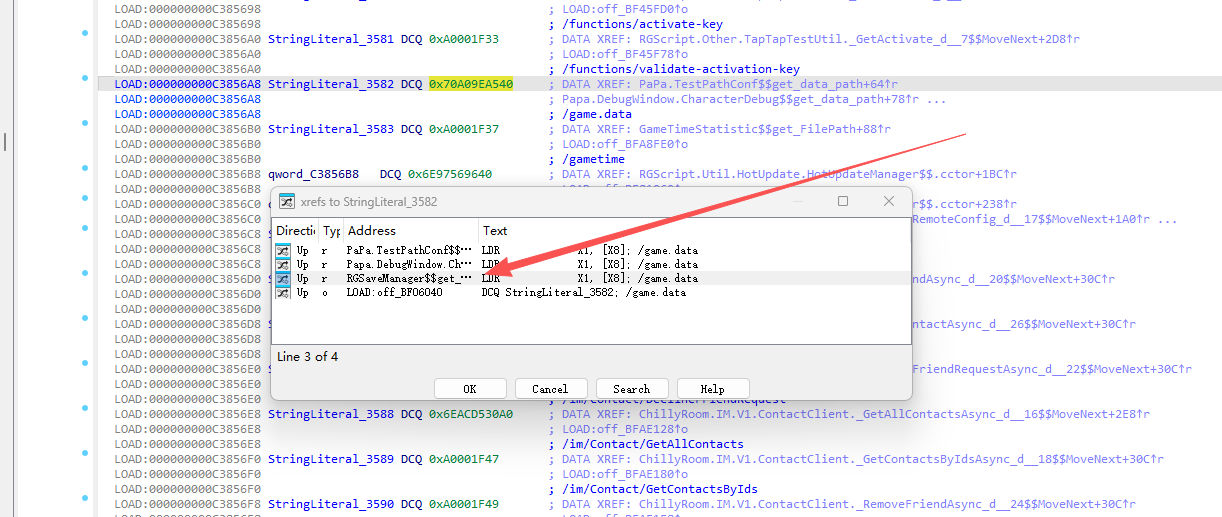
看名字就知道这是个存档的地方,然后分析这个函数:
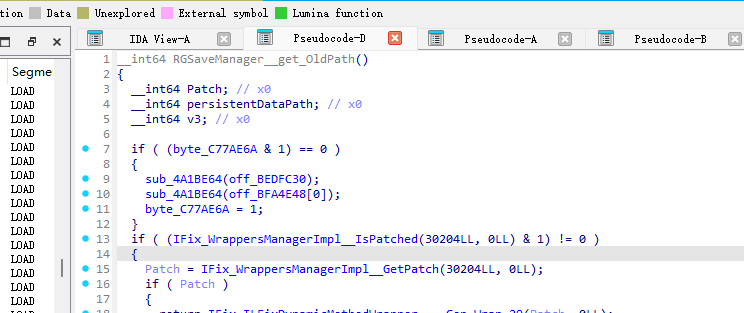
看看是谁调用的这个函数:
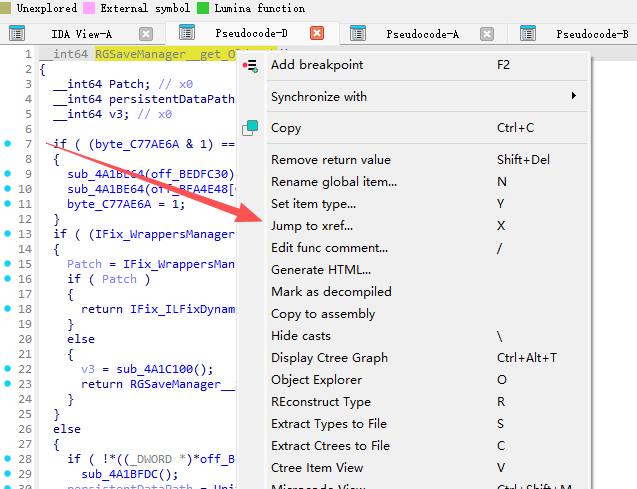
可以跳转到了LoadGameData,然后分析可以找到加密函数:
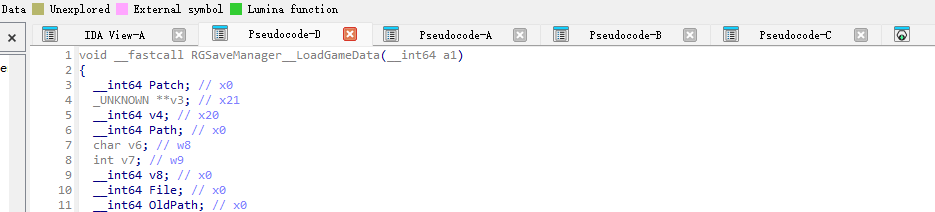
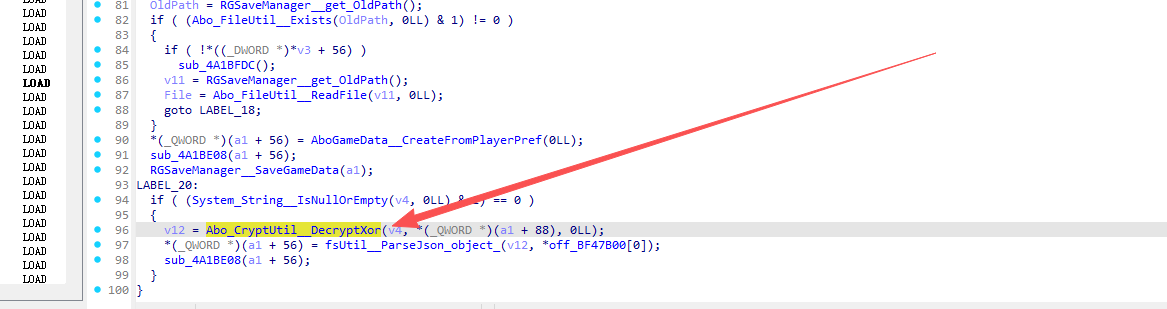
进去看看:
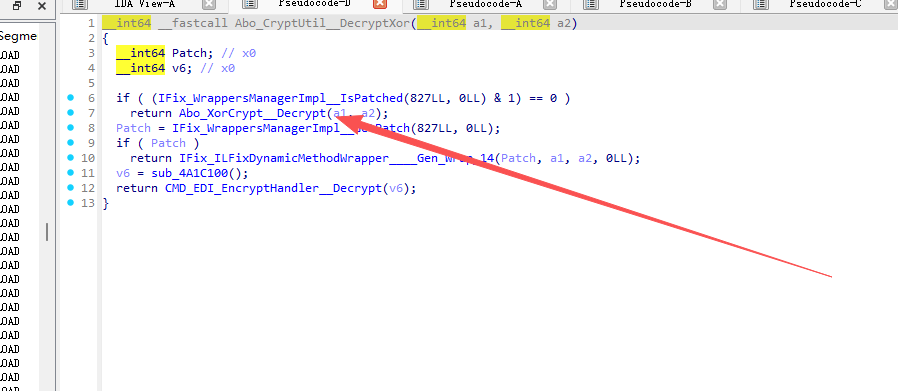
接着跟,这个代码就是最新版元气骑士的解密算法:
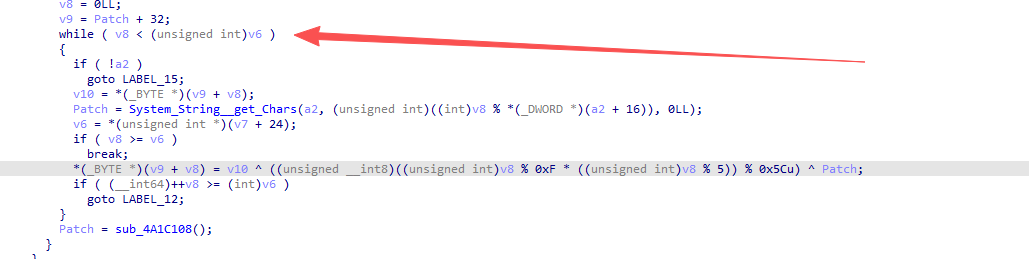
使用python简单复现一下:
python
def xor_crypt(data: bytes, password: str) -> bytes:
result = bytearray(data)
pwd_len = len(password)
for i in range(len(result)):
pc = ord(password[i % pwd_len])
t = ((i % 15) * (i % 5)) % 92
result[i] = result[i] ^ pc ^ t
return bytes(result)然后为了解密这个data,有一个简单的密码学方法,就是爆破,因为我们已经知道了加密算法,其次json格式的前两位是**{和"**。
通过这个我们可以爆破,爆破也是有技巧的,首先这是一个简单的xor加密,也就是说,如果尝试的密码和真实密码很相近,那么json格式中出现下列字符的数量会越多
python
patterns=[b'{"', b'":', b',"', b'"}', b':[', b']}']根据这个特性可以辅助我们选定密钥的长度,然后根据长度进行爆破
使用AI写一个爆破的脚本:
python
# -*- coding: utf-8 -*-
import json
from collections import defaultdict
def xor_crypt(data: bytes, password: str) -> bytes:
result = bytearray(data)
pwd_len = len(password)
for i in range(len(result)):
pc = ord(password[i % pwd_len])
t = ((i % 15) * (i % 5)) % 92 # 修正括号
result[i] = result[i] ^ pc ^ t
return bytes(result)
def crack_by_your_idea(ciphertext: bytes, max_pwd_len: int = 50):
"""破解XOR密码"""
cipher_bytes = bytearray(ciphertext)
# JSON 常见的重复模式
patterns = [b'{"', b'":', b',"', b'"}', b':[', b']}']
candidates = {}
for pattern in patterns:
pattern_bytes = list(pattern)
# 对每个密码长度
for pwd_len in range(1, max_pwd_len + 1):
votes = [defaultdict(int) for _ in range(pwd_len)]
# 扫描密文的每个位置
for start_pos in range(len(cipher_bytes) - len(pattern_bytes) + 1):
temp_pwd = {}
conflict = False
for i, plain_byte in enumerate(pattern_bytes):
pos = start_pos + i
t = ((pos % 15) * (pos % 5)) % 92 # 修正括号
recovered = cipher_bytes[pos] ^ t ^ plain_byte
# 必须是可打印字符
if not (32 <= recovered < 127):
conflict = True
break
pwd_idx = pos % pwd_len
if pwd_idx in temp_pwd:
if temp_pwd[pwd_idx] != recovered:
conflict = True
break
else:
temp_pwd[pwd_idx] = recovered
if not conflict:
for pwd_idx, byte_val in temp_pwd.items():
votes[pwd_idx][byte_val] += 1
# 构建密码
password = bytearray(pwd_len)
min_votes = float('inf')
for i in range(pwd_len):
if not votes[i]:
password = None
break
most_common = max(votes[i].items(), key=lambda x: x[1])
password[i] = most_common[0]
min_votes = min(min_votes, most_common[1])
if password and min_votes >= 2:
try:
pwd_str = password.decode('utf-8')
if pwd_str not in candidates or min_votes > candidates[pwd_str][1]:
candidates[pwd_str] = (pattern.decode('utf-8'), min_votes)
except:
pass
return sorted(candidates.items(), key=lambda x: -x[1][1])
# 主破解流程
if __name__ == "__main__":
# 二进制模式读取
with open("game.data", "rb") as f:
ciphertext = f.read()
print(f"密文长度: {len(ciphertext)} 字节")
print("="*60)
results = crack_by_your_idea(ciphertext, max_pwd_len=50)
print(f"找到 {len(results)} 个候选密码\n")
for pwd, (pattern, votes) in results[:20]:
print(f"密码: '{pwd}' (长度={len(pwd)}, 票数={votes}, 模式='{pattern}')")
try:
result = xor_crypt(ciphertext, pwd)
result_str = result.decode('utf-8', errors='replace')
json.loads(result_str)
print(f" ✓✓ 成功!这是有效的 JSON!")
print(f" 预览: {result_str[:200]}...")
# 二进制模式保存
with open("output.txt", "wb") as f:
f.write(result)
print(f" 已保存到 output.txt\n")
break
except json.JSONDecodeError as e2:
print(f" ✗ 不是有效 JSON: {e2}")
except Exception as e:
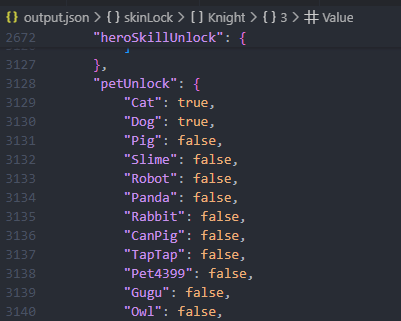
print(f" ✗ 错误: {e}")然后就可以得到输出的结果,成果破解出来了某气骑士的密码:
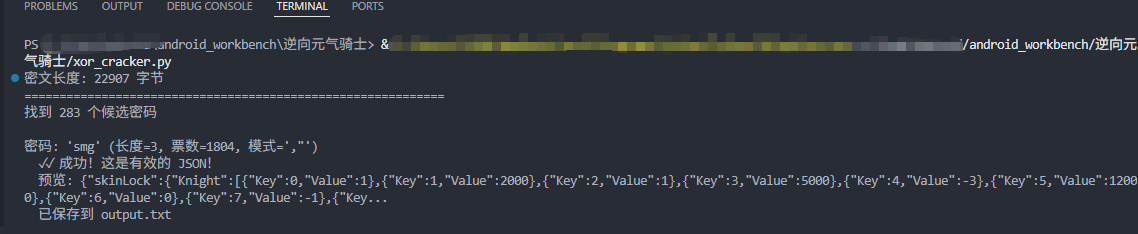
可以看到里面有很多宠物解锁和技能解锁相关的数据: