Wan2.1是阿里云开源的顶尖AI视频生成大模型,支持文生视频(T2V)、图生视频(I2V)等核心功能,具备复杂运动生成、物理规律模拟、多风格适配及中文文字特效生成能力,在VBench权威榜单中综合评分稳居第一。相较于其他开源模型,Wan2.1的核心优势在于硬件门槛亲民------1.3B参数版本仅需8GB显存即可流畅运行,消费级GPU(如RTX 4090、RTX 5070 Ti)均可胜任,普通用户也能轻松实现本地离线视频生成。
本文将提供两种主流部署方案:ComfyUI可视化部署 (适合新手,操作直观)和原生代码部署(适合开发者,灵活度高),全程嵌入可直接复制的代码片段,同时覆盖常见问题解决方案,确保部署过程顺畅。

一、部署前置条件
1.1 硬件要求
-
GPU:推荐NVIDIA显卡(AMD显卡兼容性较差),显存≥8GB(1.3B模型);若使用14B模型或720P高分辨率生成,建议显存≥16GB(如RTX 5070 Ti 16GB)。
-
CPU:多核处理器(≥4核),推荐i5及以上。
-
内存:≥16GB(避免生成过程中内存溢出)。
-
存储:预留≥50GB空闲空间(用于存放模型、环境及生成文件)。
1.2 系统与软件基础
-
操作系统:Windows 10/11 64位、Ubuntu 22.04 LTS(推荐,兼容性更佳)。
-
核心依赖:
-
CUDA Toolkit:≥12.1(Windows需安装对应版本显卡驱动;Ubuntu需手动配置CUDA环境)。
-
Python:3.10~3.12(建议通过conda管理虚拟环境,避免版本冲突)。
-
PyTorch:≥2.4.0(需与CUDA版本匹配)。
-
二、方案一:ComfyUI可视化部署(新手首选)
ComfyUI是一款开源的AI生成可视化工具,支持Wan2.1原生适配,通过拖拽工作流即可完成视频生成,无需复杂代码编写。
2.1 步骤1:安装ComfyUI与虚拟环境
Windows系统(一键包安装)
-
下载ComfyUI一键包:访问ComfyUI官方网站,选择Windows版本下载。
-
解压并安装:双击安装程序,选择GPU类型(NVIDIA),自定义安装路径(如D:\ComfyUI),点击"安装"(自动部署Python环境及基础依赖,耗时约5分钟)。
Ubuntu系统(命令行安装)
通过conda创建独立虚拟环境,避免依赖冲突:
# 1. 克隆ComfyUI仓库
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
# 2. 安装Miniconda(若已安装可跳过)
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh # 按提示输入yes,完成后初始化
source ~/.bashrc
# 3. 创建并激活虚拟环境
conda create -n comfyui python=3.11 -y
conda activate comfyui
# 4. 安装PyTorch(适配CUDA 12.1)
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
# 5. 安装项目依赖
pip install -r requirements.txt2.2 步骤2:下载Wan2.1模型及配套组件
所有模型均从Hugging Face官方仓库下载(需注册账号并同意用户协议),仓库地址:Wan_2.1_ComfyUI_repackaged
2.2.1 核心模型(必下载)
-
扩散模型(Diffusion Models):根据显存选择版本,下载后放入
ComfyUI/models/diffusion_models/目录:-
显存8GB:选择1.3B参数版本(如
wan2.1_t2v_1.3B_fp16.safetensors,2.84GB)。 -
显存16GB:选择14B参数版本(如
wan2.1_i2v_480p_14B_fp8.safetensors,兼顾效果与速度)。
-
-
文本编码器(Text Encoders):二选一,放入
ComfyUI/models/text_encoders/目录:-
FP8版本(推荐,6.7GB):
umt5_xxl_fp8_e4m3fn_scaled.safetensors(显存占用小,兼容性好)。 -
FP16版本(11.4GB):
umt5_xxl_fp16.safetensors(精度更高,需显存≥12GB)。
-
-
视频VAE:下载
wan_2.1_vae.safetensors,放入ComfyUI/models/vae/目录(负责视频编解码,确保画面流畅)。
2.2.2 可选组件(图生视频需下载)
若需实现图生视频(I2V),需额外下载CLIP Vision模型:
# 下载地址:https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/blob/main/split_files/clip_vision/clip_vision_h.safetensors
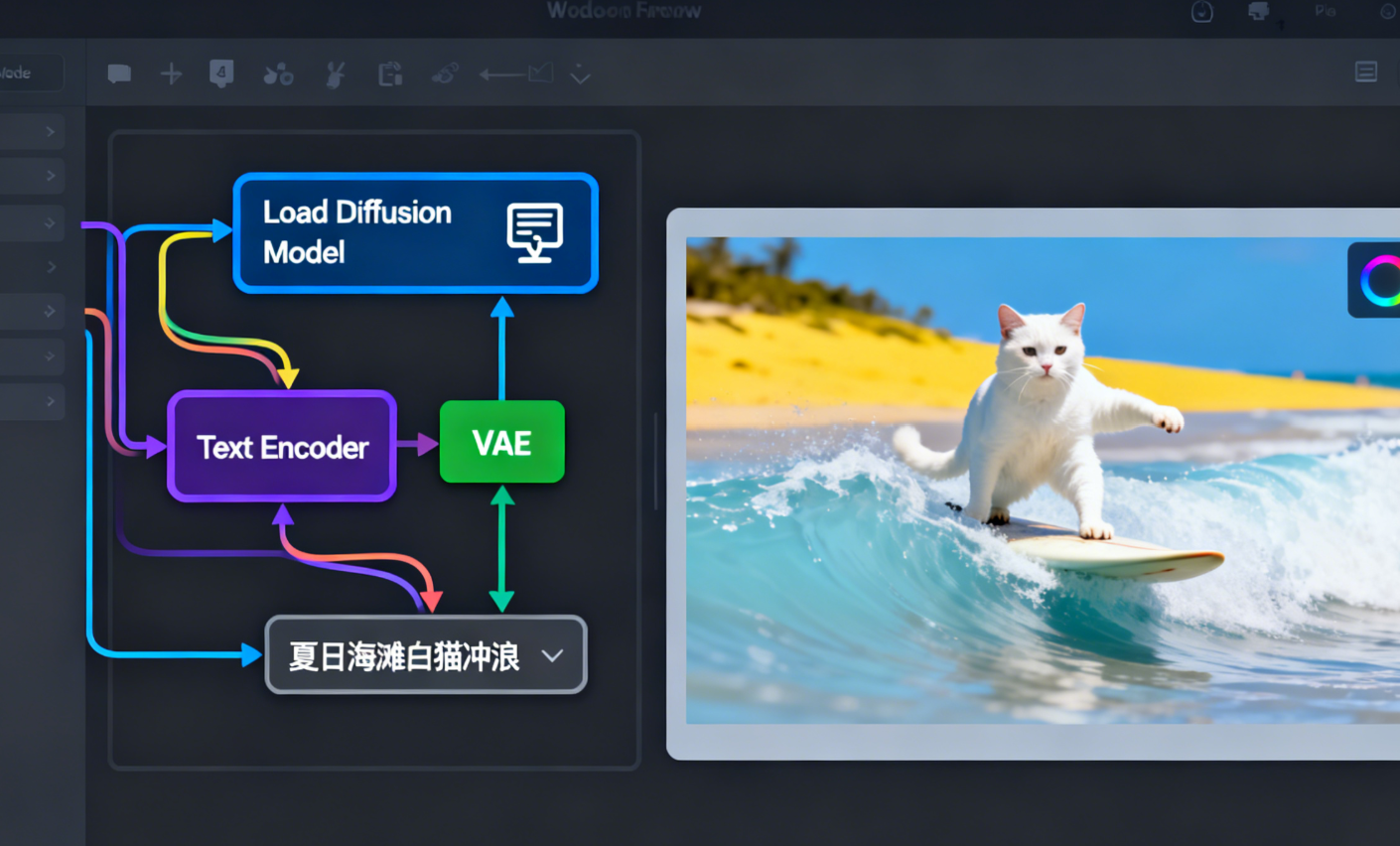
# 放置路径:ComfyUI/models/clip_vision/2.3 步骤3:加载工作流并测试生成
-
启动ComfyUI:
-
Windows:双击ComfyUI安装目录下的
run_nvidia_gpu.bat。 -
Ubuntu:在虚拟环境中执行命令:
conda activate comfyui ``cd ComfyUI ``python main.py
-
-
加载预设工作流:
-
文生视频(T2V):下载工作流文件text_to_video_wan.json,将文件拖拽到ComfyUI界面即可加载。
-
图生视频(I2V):下载工作流文件 image_to_video_wan_example.json,同样拖拽加载。
-
-
配置工作流参数:
-
模型匹配:确保"Load Diffusion Model"节点加载的模型与本地下载的一致(如
wan2.1_t2v_1.3B_fp16.safetensors)。 -
编码器匹配:"Load Clip Text Encoder"节点选择本地下载的文本编码器(如
umt5_xxl_fp8_e4m3fn_scaled.safetensors)。 -
生成参数:
-
分辨率:1.3B模型建议设为640×480(480P),14B模型可设为1280×720(720P)。
-
帧数:建议45帧左右(按16帧/秒计算,可生成约2.8秒视频)。
-
提示词:支持中文,例如"夏日海滩,一只戴太阳镜的白猫坐在冲浪板上,微风拂过"(正提示词);反向提示词默认即可(如"模糊、扭曲、低质量")。
-
-
-
执行生成:点击界面右上角"Queue Prompt"按钮(或按Ctrl+Enter),等待生成完成。生成的视频文件默认保存于
ComfyUI/output/目录,格式为MP4。
三、方案二:原生代码部署(开发者方案)
原生部署通过命令行操作,适合需要集成到自定义项目中的开发者,支持更多参数自定义(如提示词扩展、多GPU并行等)。
3.1 步骤1:搭建基础环境
# 1. 创建并激活conda虚拟环境
conda create -n wan21_env python=3.11 -y
conda activate wan21_env
# 2. 安装PyTorch(适配CUDA 12.1,需根据实际CUDA版本调整)
pip install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu121
# 3. 安装核心依赖(含xfuser加速库,确保torch≥2.4.0)
pip install "xfuser>=0.4.1"
pip install flash-attn --no-build-isolation # 安装Flash Attention加速注意力计算
# 4. 克隆Wan2.1官方仓库(若无法访问GitHub,可通过阿里云镜像获取)
git clone https://github.com/alibaba/Wan.git
cd Wan3.2 步骤2:下载模型文件
从阿里云官方模型仓库下载对应版本模型,以14B图生视频(I2V)720P版本为例:
# 1. 创建模型存放目录
mkdir -p ./Wan2.1-I2V-14B-720P
# 2. 下载模型文件(需先同意阿里云模型使用协议,获取下载权限)
# 官方下载链接:https://developer.aliyun.com/article/1653942(含模型下载入口)
# 下载完成后,将所有模型文件解压至 ./Wan2.1-I2V-14B-720P 目录3.3 步骤3:运行生成代码
原生部署支持单GPU、多GPU并行生成,以下提供两种常见场景的代码示例。
3.3.1 单GPU图生视频(I2V)生成
# 基本生成命令(使用本地提示词扩展)
python generate.py \
--task i2v-14B \
--size 1280*720 \
--ckpt_dir ./Wan2.1-I2V-14B-720P \
--image examples/i2v_input.JPG # 本地输入图片路径
--use_prompt_extend \
--prompt_extend_model Qwen/Qwen2.5-VL-7B-Instruct \
--prompt "夏日海滩度假风格,一只戴着太阳镜的白猫坐在冲浪板上"
# 使用Dashscope API扩展提示词(需先获取API密钥)
DASH_API_KEY=your_dashscope_api_key python generate.py \
--task i2v-14B \
--size 1280*720 \
--ckpt_dir ./Wan2.1-I2V-14B-720P \
--image examples/i2v_input.JPG \
--use_prompt_extend \
--prompt_extend_method 'dashscope' \
--prompt "夏日海滩度假风格,一只戴着太阳镜的白猫坐在冲浪板上"3.3.2 多GPU并行生成(8卡,提升速度)
torchrun --nproc_per_node=8 generate.py \
--task i2v-14B \
--size 1280*720 \
--ckpt_dir ./Wan2.1-I2V-14B-720P \
--image examples/i2v_input.JPG \
--dit_fsdp \
--t5_fsdp \
--ulysses_size 8 \
--prompt "夏日海滩度假风格,一只戴着太阳镜的白猫坐在冲浪板上"3.3.3 启动本地Gradio可视化界面
原生部署也支持快速启动Gradio界面,兼顾灵活度与可视化操作:
cd gradio
# 仅使用480P模型
DASH_API_KEY=your_dashscope_api_key python i2v_14B_singleGPU.py \
--prompt_extend_method 'dashscope' \
--ckpt_dir_480p ./Wan2.1-I2V-14B-480P
# 同时支持480P和720P模型
DASH_API_KEY=your_dashscope_api_key python i2v_14B_singleGPU.py \
--prompt_extend_method 'dashscope' \
--ckpt_dir_480p ./Wan2.1-I2V-14B-480P \
--ckpt_dir_720p ./Wan2.1-I2V-14B-720P启动成功后,终端会显示本地访问地址(如 http://localhost:7860),打开浏览器即可通过可视化界面调整参数、上传图片、输入提示词生成视频。
四、常见问题解决方案
4.1 Flash Attention报错(assert FLASH_ATTN_2_AVAILABLE)
错误原因:系统未正确配置Flash Attention 2.0组件,导致模型加速失败。解决方案:
# 方案1:重新安装Flash Attention(Ubuntu/WSL环境)
pip uninstall flash-attn -y
pip install flash-attn --no-build-isolation
# 方案2:Ubuntu/WSL环境下安装完整CUDA Toolkit 12.8(以12.8为例)
wget https://developer.download.nvidia.com/compute/cuda/repos/wsl-ubuntu/x86_64/cuda-wsl-ubuntu.pin
sudo mv cuda-wsl-ubuntu.pin /etc/apt/preferences.d/cuda-repository-pin-600
wget https://developer.download.nvidia.com/compute/cuda/12.8.0/local_installers/cuda-repo-wsl-ubuntu-12-8-local_12.8.0-1_amd64.deb
sudo dpkg -i cuda-repo-wsl-ubuntu-12-8-local_12.8.0-1_amd64.deb
sudo cp /var/cuda-repo-wsl-ubuntu-12-8-local/cuda-*-keyring.gpg /usr/share/keyrings/
sudo apt-get update
sudo apt-get -y install cuda-toolkit-12-8
# 方案3:使用Docker环境规避兼容性问题
docker pull hunyuanvideo/hunyuanvideo:cuda_11
docker run -it --gpus all -p 7860:7860 hunyuanvideo/hunyuanvideo:cuda_114.2 模型加载失败(找不到模型文件)
错误原因:模型放置路径错误或文件名不匹配。解决方案:
-
ComfyUI部署:严格按照本文2.2节要求,将模型放入对应目录(如扩散模型→models/diffusion_models)。
-
原生部署:确保
--ckpt_dir参数指定的路径与模型实际存放路径一致(建议使用绝对路径,如/home/user/Wan/Wan2.1-I2V-14B-720P)。
4.3 生成过程中显存溢出(Out of Memory)
解决方案:
-
降低分辨率:将720P改为480P(
--size 640*480)。 -
选择低精度模型:将FP16模型替换为FP8模型(显存占用减少约40%)。
-
减少帧数:将帧数从45帧改为30帧以下。
-
关闭不必要的程序:释放系统内存和GPU显存。

五、总结
Wan2.1的本地部署核心在于"环境适配+模型匹配":新手优先选择ComfyUI可视化方案,通过一键包安装和拖拽工作流即可快速上手;开发者可选择原生代码部署,灵活配置多GPU并行、提示词扩展等高级功能。只要确保GPU显存达标、依赖版本匹配,即可顺利实现本地离线生成高质量视频。
若需获取最新模型、工作流及问题支持,可关注阿里云开发者社区(Wan2.1官方指南)或ComfyUI官方文档(ComfyUI Wan2.1教程)。