人工智能学习-AI-MIT公开课第 17.-学习:boosting 算法
- 1-前言
- 2-课程链接
- 3-具体内容解释说明
-
- [一、Boosting 在讲什么(一句话)](#一、Boosting 在讲什么(一句话))
- [二、为什么要讲 Boosting?(动机)](#二、为什么要讲 Boosting?(动机))
- [三、Boosting 的基本流程(入试超爱)](#三、Boosting 的基本流程(入试超爱))
- 四、最重要的具体算法:AdaBoost(必考)
-
- [AdaBoost 在干嘛?](#AdaBoost 在干嘛?)
- [AdaBoost 的关键特性(直接能出选择题)](#AdaBoost 的关键特性(直接能出选择题))
- [五、Boosting vs Bagging(一定会对比)](#五、Boosting vs Bagging(一定会对比))
- [六、Boosting 的进阶(点到为止)](#六、Boosting 的进阶(点到为止))
- 七、和你考试内容的直接关系(很重要)
- 八、给你一个「入试一句话模板」
- 4-课后练习(日语版本)
-
- [問題1(Boosting の基本概念)](#問題1(Boosting の基本概念))
- [問題2(AdaBoost の特性)](#問題2(AdaBoost の特性))
- [問題3(Bagging との比較)](#問題3(Bagging との比較))
- [問題4(Boosting の性質と注意点)](#問題4(Boosting の性質と注意点))
- 5-课后练习(日语版本)解析
- [✅ 採点結果](#✅ 採点結果)
- [🔍 逐题解析(入试出题人视角)](#🔍 逐题解析(入试出题人视角))
- [🧠 入试级总结(你现在要记住的)](#🧠 入试级总结(你现在要记住的))
-
-
- [Boosting 三句话模板](#Boosting 三句话模板)
-
- [🎯 给你一个「提分建议」](#🎯 给你一个「提分建议」)
- 6-总结
1-前言
为了应对大学院考试,我们来学习相关人工智能相关知识,并且是基于相关课程。使用课程为MIT的公开课。
通过学习,也算是做笔记,让自己更理解些。
2-课程链接
是在B站看的视频,链接如下:
https://www.bilibili.com/video/BV1dM411U7qK?spm_id_from=333.788.videopod.episodes&vd_source=631b10b31b63df323bac39281ed4aff3&p=17
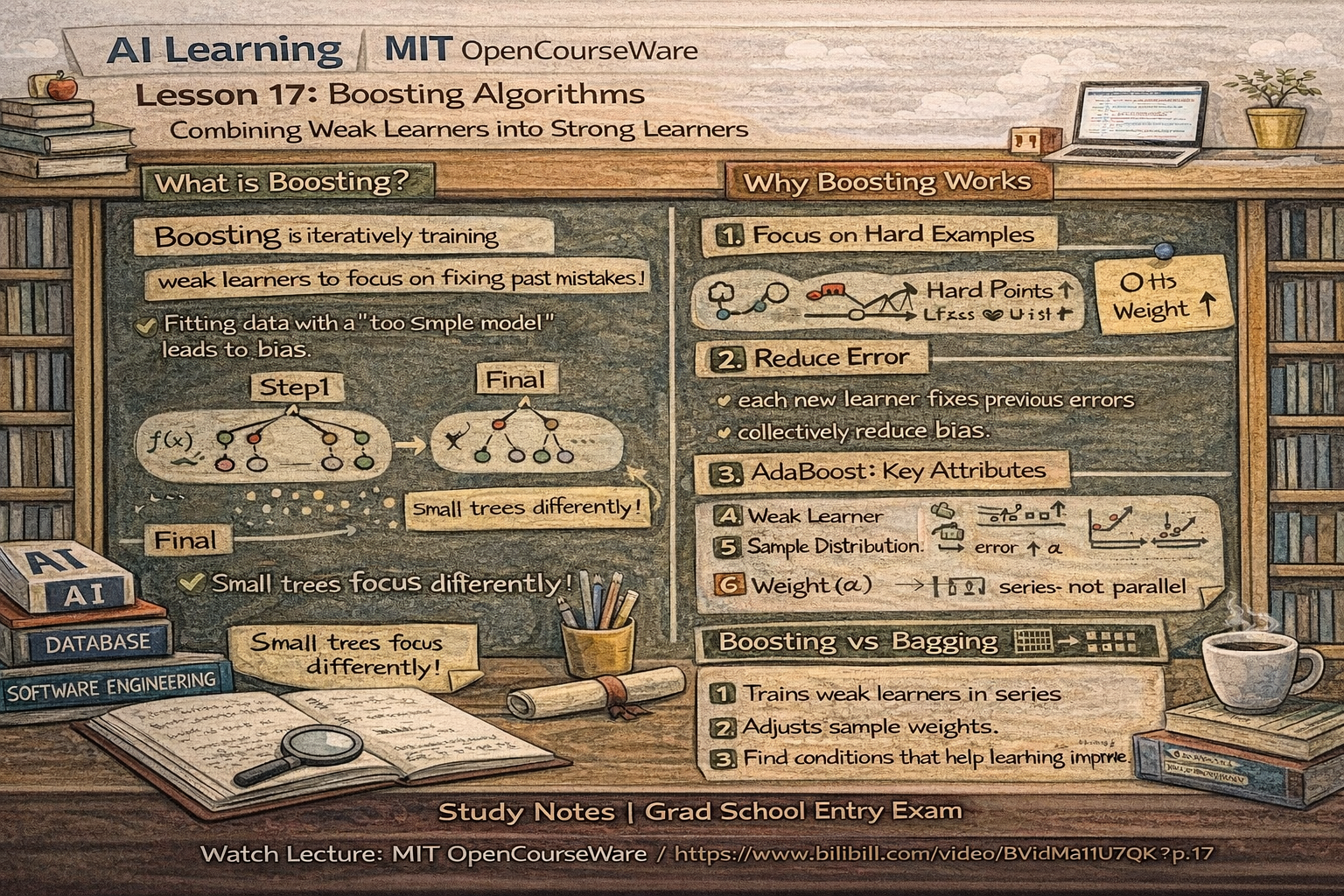
3-具体内容解释说明
一、Boosting 在讲什么(一句话)
Boosting = 通过"不断关注之前犯错的样本",把很多弱分类器组合成一个强分类器的方法。
和你前面学的 SVM、相近差错、受迫条件 是一个体系里的。
二、为什么要讲 Boosting?(动机)
-
单个模型(如:一棵很浅的决策树)
- 表达能力弱
- 但不容易过拟合
-
Boosting 的想法:
- 错的样本 → 以后更重视
- 对的样本 → 权重降低
👉 核心思想:
"让后面的模型专门修前面模型的错误"
三、Boosting 的基本流程(入试超爱)
-
初始化:
- 所有样本权重相同
-
训练第 1 个弱分类器
-
找出 被分错的样本
-
提高这些样本的权重
-
用新权重训练下一个弱分类器
-
重复多次
-
最终:
- 加权投票 / 加权求和
👉 考试常问:
为什么 Boosting 对噪声敏感?
→ 因为会不断"执着"于被分错的点
四、最重要的具体算法:AdaBoost(必考)
AdaBoost 在干嘛?
-
每一轮都会算:
- 当前分类器的错误率 ε
-
根据 ε 计算该分类器的权重 α
- 错得越少 → α 越大
最终模型是:
多个弱分类器的加权组合
AdaBoost 的关键特性(直接能出选择题)
✅ 使用 样本权重更新
✅ 使用 分类器权重 α
❌ 不是并行(是串行)
❌ 对异常值、噪声敏感
五、Boosting vs Bagging(一定会对比)
| 对比点 | Boosting | Bagging |
|---|---|---|
| 训练方式 | 串行 | 并行 |
| 样本处理 | 改权重 | 重采样 |
| 关注重点 | 错分样本 | 降低方差 |
| 抗噪声 | 弱 | 强 |
| 代表算法 | AdaBoost | Random Forest |
👉 入试常问:
"哪种方法对噪声更鲁棒?" → Bagging
六、Boosting 的进阶(点到为止)
课程里一般会提到但不深推:
- Gradient Boosting
- XGBoost(思想来源)
- Loss function 的逐步最小化
但入试重点仍是 AdaBoost 的思想,不是工程细节。
七、和你考试内容的直接关系(很重要)
你这门课前后顺序是:
相近差错 → SVM → Boosting
说明老师在强调:
- 泛化能力
- 模型组合
- 理论理解
👉 在日本大学院入试里,Boosting 通常考:
- 概念判断
- 特性对比
- "为什么这样做"
不考代码、不考公式推导。
八、给你一个「入试一句话模板」
Boosting は,誤分類されたサンプルに重点を置きながら弱学習器を逐次学習し,それらを組み合わせることで高精度な分類器を構成する手法である。
(这一句话,面试 + 笔试都能用)
4-课后练习(日语版本)
問題1(Boosting の基本概念)
Boosting に関する説明として,最も適切なものを選べ。
A. 複数の学習器を独立に学習し,多数決によって結果を統合する手法である。
B. 誤分類されたサンプルに対して重みを下げることで,過学習を防ぐ手法である。
C. 弱学習器を逐次的に学習し,誤分類されたサンプルを重視しながら学習を進める手法である。
D. 単一の高性能分類器を用いて誤差を最小化する手法である。
問題2(AdaBoost の特性)
AdaBoost に関する記述として,正しいものを選べ。
A. 各弱学習器は同じ重みで最終分類に寄与する。
B. 誤分類率が高い弱学習器ほど,大きな重みが与えられる。
C. 学習は並列的に行われ,計算効率が高い。
D. 誤分類率が低い弱学習器ほど,大きな重みが与えられる。
問題3(Bagging との比較)
Boosting と Bagging の違いに関する説明として,最も適切なものを選べ。
A. Boosting はサンプルの重みを更新するが,Bagging は重みを更新しない。
B. Bagging は逐次学習であり,Boosting は並列学習である。
C. Boosting は分散を低減し,Bagging はバイアスを低減する。
D. 両者とも誤分類されたサンプルに重点を置く点で同じである。
問題4(Boosting の性質と注意点)
Boosting の性質として,最も適切なものを選べ。
A. ノイズを含むデータに対しても常に安定した性能を示す。
B. 誤分類されたサンプルを重視するため,ノイズの影響を受けやすい。
C. 学習器の数を増やしても性能は変化しない。
D. 単一の決定木よりも常に単純なモデルになる。
5-课后练习(日语版本)解析
✅ 採点結果
| 問題 | 你的答案 | 正解 | 判定 |
|---|---|---|---|
| 1 | C | C | ✅ 正確 |
| 2 | D | D | ✅ 正確 |
| 3 | D | A | ❌ 不正解 |
| 4 | A | B | ❌ 不正解 |
👉 得分:2 / 4(本番ならギリ可)
下面是最重要的:为什么错。
🔍 逐题解析(入试出题人视角)
問題1(Boosting 的本质)✅
C 正解
弱学習器を逐次的に学習し,誤分類されたサンプルを重視
这是 Boosting 的标准定义句 ,必背句型 。
你选对,说明概念是稳的。
問題2(AdaBoost 的权重)✅
D 正解
誤分類率が低い弱学習器ほど,大きな重み
👉 错得少 → 更可信 → 权重大
这题是纯定义判断,你没被带偏。
問題3(Boosting vs Bagging)❌【高频陷阱】
你选了 D:
両者とも誤分類されたサンプルに重点を置く
❌ 这是典型陷阱选项
为什么错?
-
Boosting :
✅ 明确"盯着错分样本"
-
Bagging :
❌ 不区分样本对错
❌ 只是「重采样 + 多模型」
👉 所以只有 Boosting 关心错分样本
正解是 A
Boosting はサンプルの重みを更新するが,Bagging は重みを更新しない。
📌 入试口诀
重みを見る → Boosting
抽样看概率 → Bagging
問題4(Boosting 的弱点)❌【入试爱考点】
你选了 A:
ノイズを含むデータに対しても常に安定
❌ 这是反向陷阱
正确理解是:
-
Boosting:
- 会反复关注「被分错的点」
- 噪声点会被"无限放大"
- 👉 容易过拟合噪声
正解是 B
誤分類されたサンプルを重視するため,ノイズの影響を受けやすい
📌 一句话必背
Boosting はノイズに弱い。
🧠 入试级总结(你现在要记住的)
Boosting 三句话模板
1️⃣ 弱学習器を逐次的 に学習する
2️⃣ 誤分類サンプルに重点 を置く
3️⃣ ノイズに弱い
🎯 给你一个「提分建议」
你现在的水平是:
- 概念 80% OK
- 比较题 & 反向表述易踩坑
👉 这正是日本大学院选择题的杀手点
6-总结
知识一点点记录吧,最后应对考试,打下基础