系统讲解了神经网络的基础架构、核心组件及其在不同任务中的应用,重点阐述了激活函数、优化器、损失函数与模型训练流程,并结合CNN、RNN、Transformer等模型分析了其设计逻辑与工程实现。
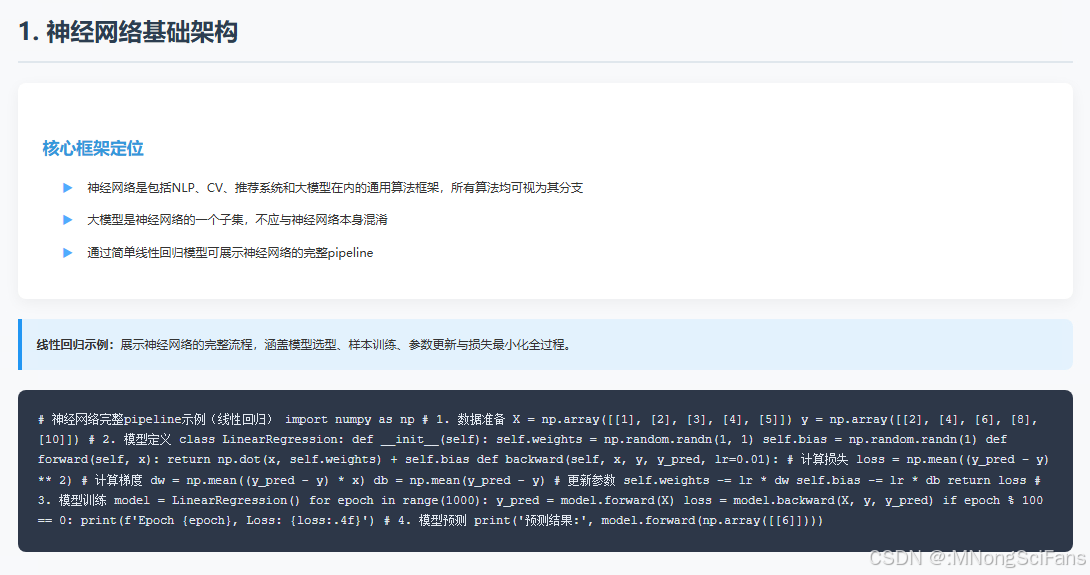
- 神经网络基础架构
• 核心框架:神经网络是包括NLP、CV、推荐系统和大模型在内的通用算法框架,所有算法均可视为其分支。
• 大模型定位:大模型是神经网络的一个子集,不应与神经网络本身混淆。
• 线性回归示例:通过简单线性回归模型展示神经网络的完整pipeline,涵盖模型选型、样本训练、参数更新与损失最小化全过程。
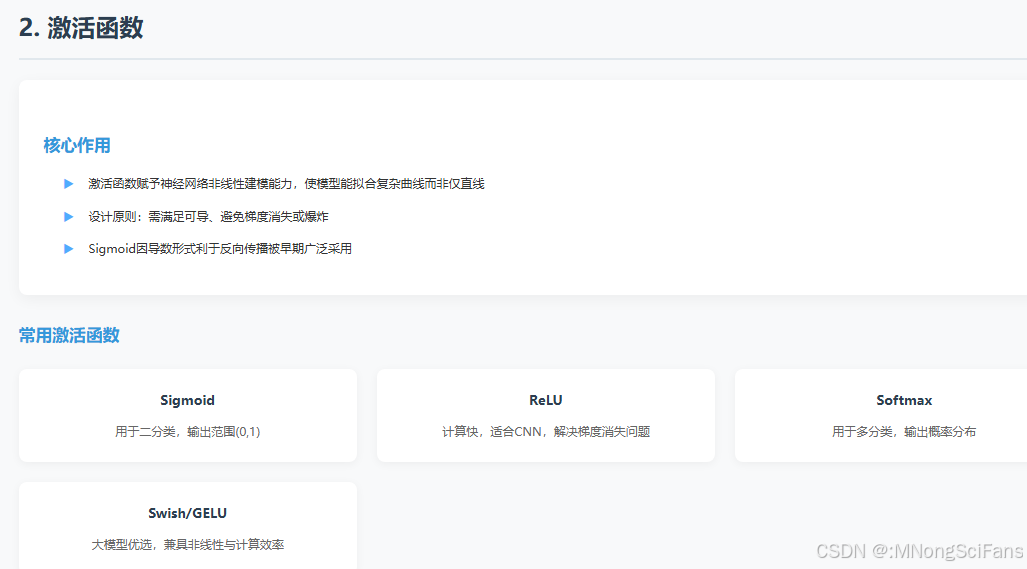
- 激活函数
• 非线性表达:激活函数赋予神经网络非线性建模能力,使模型能拟合复杂曲线而非仅直线。
• 常用函数:Sigmoid用于二分类,ReLU因计算快、适合CNN被广泛使用,Softmax用于多分类,Swish与GELU为大模型优选。
• 设计原则:激活函数需满足可导、避免梯度消失或爆炸,Sigmoid因导数形式利于反向传播被早期广泛采用。
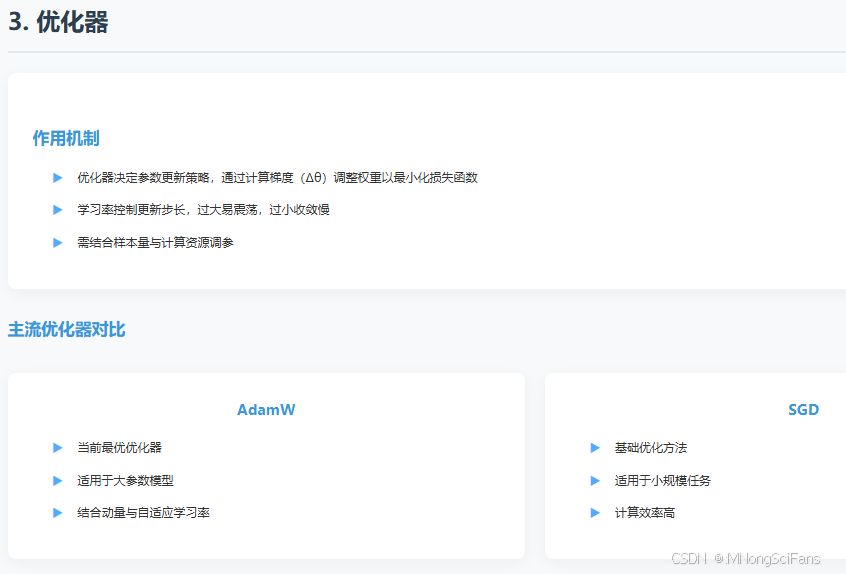
- 优化器
• 作用机制:优化器决定参数更新策略,通过计算梯度(Δθ)调整权重以最小化损失函数。
• 主流优化器:AdamW为当前最优,适用于大参数模型;SGD为基础方法,适用于小规模任务。
• 参数影响:学习率控制更新步长,过大易震荡,过小收敛慢;需结合样本量与计算资源调参。
- 损失函数
• 核心目标:衡量模型输出与真实标签的差异,训练目标为最小化损失。
• 任务适配:二分类常用交叉熵,多分类用Softmax+交叉熵,无监督任务用对比损失。
• 过拟合控制:损失接近零不一定是好事,需通过验证集监控,避免模型在训练集上过拟合。

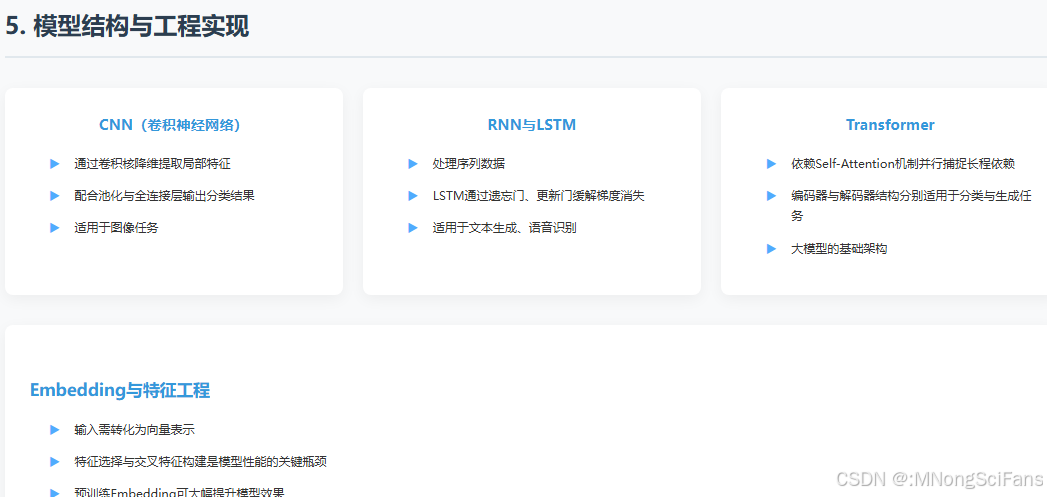
- 模型结构与工程实现
• CNN结构:通过卷积核降维提取局部特征,配合池化与全连接层输出分类结果,适用于图像任务。
• RNN与LSTM:处理序列数据,LSTM通过遗忘门、更新门缓解梯度消失问题。
• Transformer核心:依赖Self-Attention机制并行捕捉长程依赖,编码器与解码器结构分别适用于分类与生成任务。
• Embedding与特征工程:输入需转化为向量,特征选择与交叉特征构建是模型性能的关键瓶颈。
- 训练流程与工程实践
• Batch Size:因数据量大,采用分批训练以节省显存,提升训练效率。
• 模型部署:代码实现需遵循统一pipeline,框架(如PyTorch)封装底层细节,开发者聚焦模型选型与特征工程。
• 验证与测试:训练集与验证集同分布,测试集独立于训练分布,用于真实场景评估,避免过拟合误判。
• 评估指标:依赖AUC等客观指标衡量模型效果,避免主观判断。
