你听说过通用人工智能(AGI)吗?来认识它的 "听觉分身"------ 音频通用智能(Audio General Intelligence)。NVIDIA 最新发布的 Audio Flamingo 3(AF3)让机器对声音的理解与推理实现质的飞跃。过去的音频模型或许能做语音转写或音频分类,却无法像人类那样,在丰富语境中解读语音、环境音和音乐,在处理长音频内容时更是力不从心。而 AF3 正在彻底改写这一局面。
Audio Flamingo 3 是一个完全开源的大型音频语言模型(LALM),它不仅能"听懂",更能"思考"。基于五阶段训练策略,并搭载统一音频编码器 AF-Whisper,AF3 支持最长 10 分钟的音频输入、多轮多音频对话、按需推理甚至语音对语音交互。这一系列创新,重新定义了 AI 与声音的交互方式,也让我们距离真正的通用智能又近了一步。
一、音频智能的现状与挑战
音频是人类感知世界的核心通道之一,涵盖语音交流、环境音效识别、音乐情感表达等多元场景。然而,现有音频语言模型(LALM)存在三大局限:
1.能力碎片化:多数模型仅支持单一模态(如仅处理语音或音乐),难以统一理解复杂音频场景;
2.推理能力弱:缺乏类似人类的「链式思维」(Chain-of-Thought)推理能力,难以处理需要多步逻辑的任务;
3.开放性不足:闭源模型(如 GPT-4o Audio、Gemini 2.5)限制研究透明性,开源模型则性能落后。
针对这些问题,AF3 提出了全面革新的解决方案。
二、AF3 的五大核心突破
1. 统一音频编码器 AF-Whisper:跨模态理解的「神经中枢」
有模型多为不同模态设计独立编码器,导致模态间信息割裂。AF3 引入了统一音频编码器 AF-Whisper,将语音、环境音与音乐纳入统一特征空间中进行建模,从根本上简化了架构复杂性并提高了跨模态泛化能力。
AF-Whisper 基于 Whisper-large-v3 扩展而来,通过接入 Transformer 解码器,在大规模音频 - 文本对数据上进行联合表示学习。它利用 GPT-4.1 生成包含三类模态细节的自然语言描述,并结合 AF2 与 Whisper 的辅助标注,让模型能从单一编码器中提取统一的音频特征现,输出的 50Hz 特征分辨率远超 CLAP 等模型,保留了更精细的音频动态信息。这种设计不仅降低了模型复杂度,更让跨模态推理成为可能。AF-Whisper 处理后的音频特征经适配器与语言模型(LLM)对齐,再配合流式文本到语音(TTS)模块,形成了 "听 - 思 - 说" 的完整交互闭环。
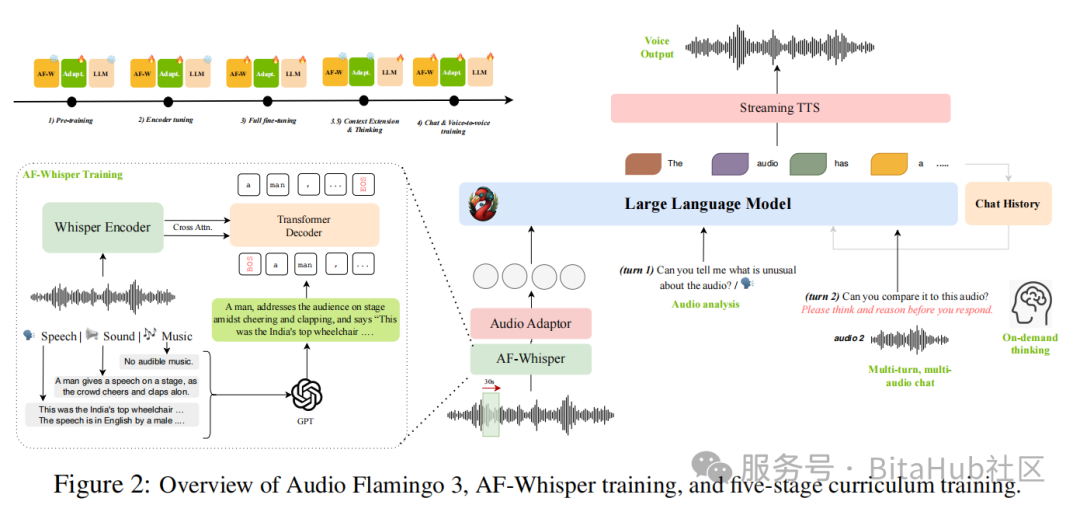
为了让模型获得真正"思考"的能力,AF3 引入了一套系统性的五阶段课程式训练策略。在训练初期,模型通过对短音频进行识别与字幕生成,完成基础能力的对齐;随后逐步引入高质量的音频问答对,以强化复杂推理与问题解决能力;进一步通过多轮音频对话数据进行语言互动能力训练;最后阶段则结合长音频输入、思维引导与语音生成能力的对齐,使得模型能够胜任长达 10 分钟的语音理解与基于内容的生成交互任务。这种逐层推进、能力驱动的训练思路,显著提升了模型的可控性与泛化能力。
2. 灵活推理机制:让模型「先思考再回答」
为了赋予模型类人的推理能力,AF3 构建了 AF-Think 数据集,包含 25 万 + 带简短推理步骤的问答对,平均每个推理过程仅 40 词,既保证了推理的有效性,又避免了冗余信息。通过在训练中加入特殊提示词,模型能够 "按需思考"------ 在面对复杂问题时自动生成推理链条,简单问题则直接给出答案,这种灵活性在音乐风格分类、语音情感因果分析等任务中尤为重要。下图示例清晰展示了这一过程:模型在回答 "哪种音乐类型最能描述这首歌曲" 前,会先分析其乐器构成、节奏特征等,再得出结论,推理过程可解释且高效。

3. 多轮多音频对话:实现自然的音频交互
针对多轮多音频对话这一实用场景,AF3 提出了 AF-Chat 数据集,包含 7.5 万对话实例,平均每轮对话涉及 4.6 个音频片段和 6.2 轮交互。其创新之处在于采用 "相似 + 相异" 音频聚类策略:为每个种子音频匹配 8 个语义相似和 8 个语义相异的音频,确保对话既保持主题连贯,又能通过对比拓展深度。这种设计让模型能在多轮交互中准确引用历史音频,模拟真实场景中的自然交流,例如在音乐制作咨询中,用户先后提供两首风格迥异的曲目,模型能结合两者的特征给出融合建议,这一能力在下表的对比中尤为突出 ------AF3 是唯一在多轮多音频对话、语音输入输出、长音频处理等维度均达满配的模型。

4. 长音频理解:突破 10 分钟语音推理极限
在长音频理解方面,AF3 通过 LongAudio-XL 数据集突破了传统模型 30 秒的时长限制,支持长达 10 分钟的音频推理,涵盖单 speaker 演讲、多 speaker 对话等多元场景。该数据集包含 125 万问答对,聚焦于 sarcasm 识别、情感状态动态推理、时序关系分析等复杂任务,例如在长达 5 分钟的辩论音频中,模型能准确判断某句话的讽刺意味,并分析其情感转变的因果关系。这使得 AF3 在会议总结、叙事理解等实用场景中表现优异,在 LongAudioBench 测试中以 68.6 分远超 Gemini 2.5 Pro 的 60.4 分。

5. 全开源生态:代码、数据、模型权重完全开放
AF3 实现了 "全开源" 的承诺,不仅开放模型权重,还公开了四大核心数据集(AudioSkills-XL、LongAudio-XL、AF-Think、AF-Chat)、完整训练代码及五阶段课程训练策略。这种开放性让研究人员能深度解析模型的工作机制,例如其五阶段训练从对齐预训练到聊天与语音微调的渐进式设计,如何让模型逐步掌握从基础识别到复杂推理的能力。
三、实验验证:20 + 基准测试全面领先
在实验结果方面,AF3 在几乎所有评估任务上都展现出显著优势。无论是在 ClothoAQA、MMAU 等通用音频理解任务上,还是在 MuchoMusic、LibriSQA 等音乐与语音理解任务上,AF3 都刷新了当前最佳水平。同时,在 ASR(自动语音识别)方面,AF3 也以非专门设计的架构实现了超过 GPT-4o 与 Qwen 系列的识别精度。在多轮对话与语音生成任务中,AF3-Chat(其对话微调版本)在 GPT-4o 评测标准下的事实性、实用性与回应深度评分均显著领先于 Qwen2.5-Omni,并在 TTS 测试中以更低的词错误率与更快的生成速度展现了工程实用价值。
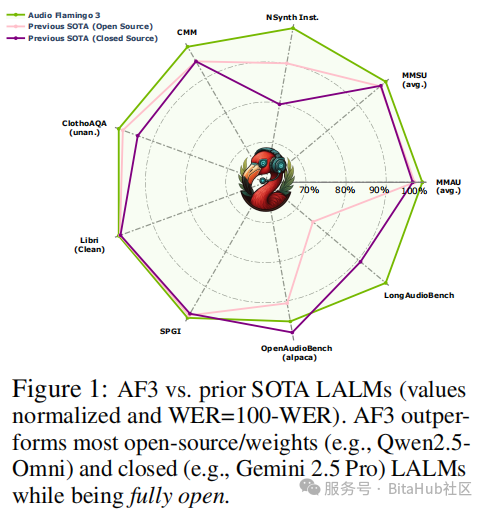
值得一提的是,AF3 并非单纯依赖大规模参数堆砌或数据倾斜,而是通过精细化数据构建、统一表示学习与任务导向训练策略实现了能力突破。其在 ablation study 中的分析也清晰表明,移除 AF-Whisper 或 AudioSkills-XL 都会导致模型在多个任务上显著退化,进一步印证了该设计的有效性。这种在设计理念、数据构建、训练策略与评估方法上的全面性与开放性,使得 AF3 成为目前最具科学价值与工程参考意义的音频语言模型之一。
四、总结与展望
AF3 不只是一次性能突破,更是一次范式创新。它展现了通过统一编码、任务导向数据设计、分阶段训练策略构建高能力、多功能、全开源音频大模型的可行路径。
未来,团队计划进一步优化:
1.简化语音交互的级联系统,提升实时性;
2.扩展多语言支持,突破英语局限;
3.减少对闭源模型生成数据的依赖,增强自主性。
对于关注 AGI 发展、音频理解、跨模态交互的研究者与工程师,Audio Flamingo 3 是一项极具参考价值的工作,代码(https://github.com/NVIDIA/audio-flamingo)、数据与模型(https://huggingface.co/nvidia/audio-flamingo-3)均已已开放。
参考链接