引言
TF-IDF是一种经典且易于理解的机器学习算法,特别适合刚开始接触自然语言处理(NLP)的初学者。它通过计算词频和逆文档频率来评估词语的重要性,其原理直观,无需深厚的数学背景即可掌握,并能有效解决文本关键词提取等实际问题。作为NLP的基石,理解TF-IDF能为后续学习更复杂的词嵌入模型(如Word2Vec)和预训练模型(如BERT)奠定坚实的基础。
一、前置基础知识:NLP 入门必备
1. 自然语言处理(NLP)是什么?
自然语言处理(NLP)是一门让计算机能够理解、解释和运用人类语言的技术。其目标是使机器能够像人一样处理文本或语音,例如识别出"我喜欢吃苹果"与"苹果是我的最爱"表达了相近的语义,或是从大量用户评论中自动归纳出"质量不佳"、"送货延迟"等关键信息。这些通常都会遵循一个标准流程:首先建立语料库,接着进行词语切分,然后通过去除无用词等进行数据清洗,之后进入关键的特征提取阶段(例如使用TF-IDF算法将文本转化为数值特征),最后才能应用各种模型完成分类或关键词挖掘等具体的任务。
2. 语料库:文本分析的 "素材库"
语料库是自然语言处理中的基础原材料。它本质上是一个经过组织、用于分析的文本数据库,必须具备几个关键特征:首先,其中的内容必须是真实使用过的语言样本,例如实际的书籍或用户评论,其次,这些文本必须以数字化形式(如TXT、CSV格式)存储,确保计算机能够直接读取和处理,最后,原始语料通常不能直接使用,必须经过清洗和预处理,包括去除多余空格、纠正乱码等步骤,才能转化为可供算法使用的干净数据。
3. 分词:让计算机 "认得出" 词语
与英文不同,中文文本没有天然的空格分隔词语,因此计算机理解中文的前提是将连续字符序列切分成独立的词,这个过程就是分词。jieba库是完成此任务的核心工具,其核心用法主要包括:首先是最常用的精确模式,能准确地将句子切分为标准词语列表,其次是应对新词或专业词汇的识别问题,可通过add_word函数添加单个词语,或使用load_userdict批量加载用户词典来提升切分准确性,最后是全模式,它会扫描出文本中所有可能的词语组合,虽然可能产生冗余,但适用于需要全面考察词网等特定场景。
4. 停用词:过滤 "无用信息"
停用词是指在文本中出现频率极高但缺乏实际语义的词语,例如"的"、"了"、"和"等。如果保留这些词汇,会干扰后续的关键词提取与文本分析效果,因此需要在预处理阶段将其过滤。处理流程通常分为两步:首先,准备一个存储常见停用词的文本文件(每行一个词),然后,在程序中使用工具(如pandas)读取该词库并转化为列表,在对文本进行分词后,通过列表推导式逐一比对并剔除属于停用词列表中的词语,从而得到一份干净的词汇集合,为后续的特征提取与分析做好准备。
5. 稀疏矩阵:TF-IDF 结果的 "存储形式"
稀疏矩阵是存储TF-IDF计算结果的一种高效格式,其特点是矩阵中绝大多数元素的值为零,仅有少量非零数值。例如,在一个包含1000个词汇的语料库中,单篇文档通常仅使用其中几十个词,其TF-IDF向量中便会存在大量零值。采用稀疏矩阵的存储方式可以极大节省内存空间。在使用sklearn库的TfidfVectorizer时,默认输出即为稀疏矩阵,若需直观查看全部数据,可通过.toarray()或.todense()方法将其转换为完整的二维数组形式。
二、TF-IDF 核心原理:为什么它能提取关键词?
TF-IDF 的全称是 "词频 - 逆文档频率",核心思想很简单:一个词的重要性 = 它在当前文章中的出现频率 × 它在所有文章中的稀有程度。
1. 先搞懂两个核心指标
(1)TF:词频------ 词在当前文章中的 "存在感"
TF(词频)是用于衡量一个词语在单篇文档中的重要性:一个词在文章中出现的次数越多,它对于该文章的主题可能就越关键。具体计算方法是(TF= 该文章的总词数/某个词在文章中的出现次数) ,用该词在文档中的出现次数除以文档的词汇总数,从而得到一个归一化的频率值。例如,如果一篇总词数为1000的文章中,"蜜蜂"一词出现了20次,那么它的TF值就是20除以1000,等于0.02。这个数值越高,就代表该词在当前文档中的相对比重越大,越可能是文档的核心词汇。
(2)IDF:逆文档频率------ 词在所有文章中的 "稀有度"
IDF(逆文档频率)是用于衡量一个词语在整个文档集合中的普遍性或稀缺性:如果一个词出现在越少的文档中,它的IDF值就越高,表明该词具有越强的区分和代表特定内容的能力。其计算公式为:以语料库总文档数除以(包含该词的文档数加一),再对结果取对数。加一是为了防止分母为零的情况。例如,在一个包含1000篇文档的语料库中,若"蜜蜂"仅出现在4篇文档里,其IDF值约为log(1000/5)≈2.3,表示辨识度很高,而像"的"这样的词几乎出现在所有文档(如999篇)中,其IDF值则为log(1000/1000)=0,说明几乎没有区分能力。

(3)TF-IDF:最终的 "重要性得分"
TF-IDF值是综合评估词语重要性的最终指标,由词频(TF)与逆文档频率(IDF)相乘得出:一个词在当前文档中出现越频繁(TF高),且在全体文档中出现越稀少(IDF高),则其TF-IDF得分就越高,表明该词对当前文档的代表性越强,越适合被提取为关键词。例如,假设"蜜蜂"在文档中的TF为0.02,其IDF为2.3,那么TF-IDF得分约为0.046;而像"的"这样的词,即便TF值较高(如0.05),但由于其IDF为0,最终得分也为0。这可以有效放大具有区分度的词汇,同时过滤掉常见而无意义的词语,从而自动识别出文档的核心内容。
三、实战演练
理论我们基本已经掌握了,现在关键的是我们要学会用代码去实现。
1、基础操作 ------ 用 TF-IDF 提取关键词
首先我们要读取语料库,用sklearn的TfidfVectorizer计算 TF-IDF,接着提取特征词(所有词语),最后排序后查看关键词。
# 导入必要的库
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# 1. 读取语料库(每行是一篇文章)
inFile = open(r".\task2_1.txt", 'r', encoding='utf-8')
corpus = inFile.readlines()
inFile.close()
# 2. 初始化TF-IDF向量器,计算TF-IDF
vectorizer = TfidfVectorizer() # 创建TF-IDF转换对象
tfidf = vectorizer.fit_transform(corpus) # 传入语料库,得到TF-IDF稀疏矩阵
# 3. 提取所有特征词(语料库中所有不重复的词)
wordlist = vectorizer.get_feature_names()
# 4. 转换为DataFrame,方便查看(行=词语,列=文章)
df_tfidf = pd.DataFrame(tfidf.T.todense(), index=wordlist)
print("TF-IDF矩阵(行:词语,列:文章):")
print(df_tfidf.head())
# 5. 提取第6篇文章的前3个关键词(索引从0开始,iloc[:,5]是第6列)
featurelist = df_tfidf.iloc[:,5].to_list() # 第6篇文章的所有TF-IDF值
resdict = {wordlist[i]: featurelist[i] for i in range(len(wordlist))} # 词语-得分字典
# 按得分降序排序
sorted_res = sorted(resdict.items(), key=lambda x: x[1], reverse=True)
print("\n第6篇文章的前3个关键词:", sorted_res[:3])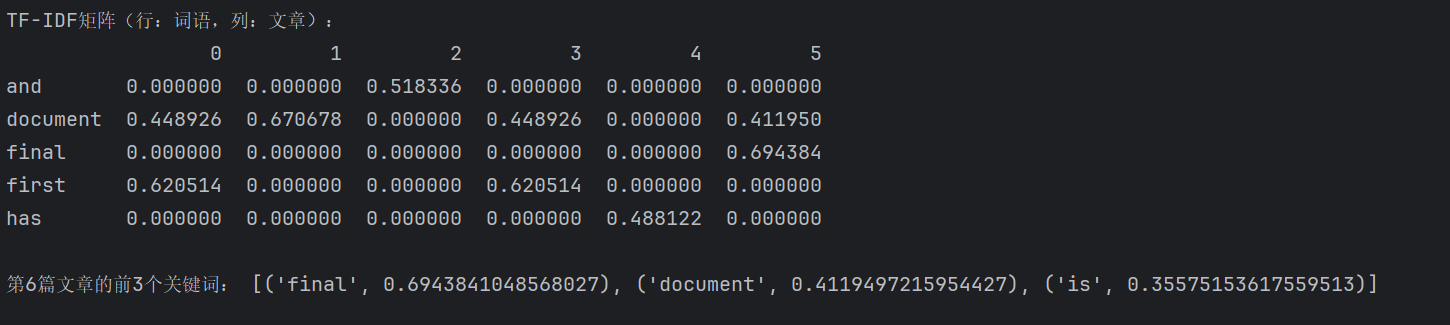
2、进阶操作 ------《红楼梦》分卷关键词提取
首先我们要拆分《红楼梦》为分卷文件,对每一卷分词,过滤停用词,还要计算每一卷的 TF-IDF,最后我们提取前 10 个关键词来查看效果。
(1)拆分《红楼梦》为分卷文件
import o
# 修正文件路径,直接在当前目录下查找红楼梦.txt
file = open('红楼梦.txt', encoding='utf-8')
flag = 0 # 用来标记当前是不是在第一次保存文件
juan_file = open('红楼梦卷开头.txt', 'w', encoding='utf-8')
for line in file: # 开始遍历整个红楼梦
if '卷 第' in line: # 找到标题
juan_name = line.strip() + '.txt'
# 确保分卷目录存在
os.makedirs('分卷', exist_ok=True)
# 构建分卷文件的完整路径
path = os.path.join('分卷', juan_name)
print(path)
if flag == 0: # 判断是否是第1次读取到 卷 第
juan_file.close() # 关闭初始文件
juan_file = open(path, 'w', encoding='utf-8') # 创建第1个卷文件
flag = 1
else: # 判断是否不是第1次读取到 卷 第
juan_file.close() # 关闭上一次的文件对象
juan_file = open(path, 'w', encoding='utf-8') # 创建一个新的卷文件
continue
juan_file.write(line)
# 关闭所有文件
juan_file.close()
file.close()
(2)分词 + 过滤停用词
import re
import pandas as pd
# 读取所有卷文件
filePaths = [] # 保存文件的路径
fileContents = [] # 保存文件路径对应的内容
for root, dirs, files in os.walk('分卷'): # os.walk是直接对文件夹进行遍历
for name in files:
filePath = os.path.join(root, name) # 获取每个卷文件的路径
filePaths.append(filePath) # 卷文件路径添加到列表FilePaths中
f = open(filePath, 'r', encoding='utf-8')
fileContent = f.read() # 读取每一卷中的文件内容
f.close()
fileContents.append(fileContent) # 将每一卷的文件内容添加到列表FileContents
corpos = pd.DataFrame({ # 将文件路径及文件内容添加为DataFrame框架中
'filePath': filePaths,
'fileContent': fileContents})
print(corpos)
# 导入jieba分词库
import jieba
# 导入分词库,把红楼梦专属的单词添加到jieba词库中
jieba.load_userdict('红楼梦词库.txt')
# 导入停用词库,把无关的词剔除
stopwords = pd.read_csv(
'StopwordsCN.txt', # StopwordsCN.txt保存的是常见的助动词
encoding='utf-8-sig', # 使用utf-8-sig编码来正确处理BOM
engine='python',
index_col=False
)
# 创建一个新文本文件用于保存分词结果
file_to_jieba = open('分词后汇总.txt', 'w', encoding='utf-8')
# 定义需要过滤的格式化词语模式(使用正则表达式)
format_patterns = [
r'^向上卷$', r'^向下卷$', r'^第\d+回$', # 卷名和回目
r'^本章$', r'^字数$', r'^更新$', r'^时间$', # 统计信息
r'^手机$', r'^电子书$', r'^大学生$', r'^小说网$', # 网站信息
r'^\d{4}$', r'^\d{2}$', r'^\d{5}$', # 日期和数字格式
]
# 特定需要过滤的词语列表
specific_words_to_filter = [
'向上卷', '向下卷', '本章', '字数', '更新', '时间',
'手机', '电子书', '大学生', '小说网', '2006', '7869'
]
# 自定义过滤函数
def should_filter_word(word):
"""判断是否应该过滤掉这个词"""
# 检查是否在停用词中
if word in stopwords['stopword'].values:
return True
# 检查是否在特定过滤词列表中
if word in specific_words_to_filter:
return True
# 检查是否匹配格式化模式(正则表达式)
for pattern in format_patterns:
if re.match(pattern, word):
return True
# 检查是否是回目组合(如"第七十回")
if re.match(r'第.*回', word):
return True
# 检查是否是页码或字数(4-5位数字)
if word.isdigit():
if len(word) >= 4 and len(word) <= 5:
return True
# 检查是否包含更新信息关键词
update_keywords = ['更新', '时间', '本章', '字数', '手机', '电子书', '小说网', '大学生']
for keyword in update_keywords:
if keyword in word:
return True
# 检查是否可能是章节标题(通常较长,3个中文字符以上)
if len(word) >= 3 and all('\u4e00' <= char <= '\u9fff' for char in word):
# 检查是否包含常见章节标题关键词
title_keywords = ['重建', '偶填', '误窃', '大闹', '戏耍', '巧遇', '巧设']
for keyword in title_keywords:
if keyword in word:
return True
return False
# 预处理文本函数:在分词前移除明显的格式文本行
def preprocess_text(text):
"""预处理文本,移除明显的格式行"""
lines = text.split('\n')
cleaned_lines = []
for line in lines:
# 跳过空行
if not line.strip():
cleaned_lines.append(line)
continue
# 检查是否是格式行(包含特定关键词)
format_keywords = [
'向上卷', '向下卷', '第', '回', '本章字数', '更新时间',
'手机电子书', '小说网', '大学生', 'www.', 'http://'
]
# 如果行中包含多个格式关键词,则跳过
keyword_count = sum(1 for keyword in format_keywords if keyword in line)
if keyword_count >= 2:
continue
# 检查行是否主要是数字和符号(如"2006 26 11 43")
if re.match(r'^[\d\s]+$', line.strip()):
continue
cleaned_lines.append(line)
return '\n'.join(cleaned_lines)
# 遍历每一卷内容进行分词处理
for index, row in corpos.iterrows(): # iterrows遍历行数据
juan_ci = '' # 空的字符串,处理后的单词依次添加到juanci后面
filePath = row['filePath']
fileContent = row['fileContent']
# 预处理文本,移除明显的格式行
fileContent = preprocess_text(fileContent)
segs = jieba.cut(fileContent) # 对文本内容进行分词,返回一个可遍历的迭代器
for seg in segs: # 遍历每一个词
# 剔除停用词、格式化词语和字符为0的内容
if not should_filter_word(seg) and len(seg.strip()) > 0:
juan_ci += seg + ' ' # juan_ci = '手机 电子书'
file_to_jieba.write(juan_ci + '\n')
file_to_jieba.close()
print("分词完成,结果已保存到 分词后汇总.txt")
(3)计算 TF-IDF
import pandas as pd
from sklearn.feature_extraction.text import TfidfVectorizer
inFile = open(r"分词后汇总.txt", 'r', encoding='utf-8')
corpus = inFile.readlines() # 返回一个列表,列表一个元素就是一行内容,一行内容一篇分词后的文章
vectorizer = TfidfVectorizer() # 类,转为TF-IDF的向量器
tfidf = vectorizer.fit_transform(corpus) # 传入数据,返回包含TF-IDF的向量值
wordlist = vectorizer.get_feature_names() # 获取特征名称,所有的词
df = pd.DataFrame(tfidf.T.todense(), index=wordlist) # tfidf.T.todense()恢复为稀疏矩阵
for i in range(len(corpus)): # 排序,将重要的关键词排序在最前面
featurelist = df.iloc[:, i].to_list() # 通过索引号获取第i列的内容并转换为列表
resdict = {} # 排序以及看输出结果对不对
for j in range(0, len(wordlist)):
resdict[wordlist[j]] = featurelist[j] # [('贾宝玉',0.223),()]
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True) # 字典的键值对,元组数据类型返回
print('第{}回的核心关键词:'.format(i + 1), resdict[0:10])
# 关闭文件
inFile.close()
现在,我们已经掌握了 TF-IDF 的核心知识和实战技巧了,下次遇到文本分析问题,我们就可以用 TF-IDF 试试 ,在下一章里,我们学习更多的机器学习中的经典算法。