一、引言
在大模型本地化部署的企业场景中,权限混乱和敏感内容生成风险是两大核心痛点:可能滥用模型生成违规内容,不同部门对模型功能的需求差异无法区分,这些问题都制约了本地模型的安全落地。
今天我们将基于 FastAPI 框架,结合给出的本地模型服务代码,整合前面我们探讨的鉴权和提示词的相关知识扩展实现一套支持角色权限分配 + 违规 Prompt 拦截的权限管控系统,让本地大模型的功能调用更合规、更可控。
二、设计思路
本地模型权限管控系统的核心目标是 "谁能调用、能调用什么、不能生成什么",围绕这个目标,我们从两个维度设计管控能力:
- 角色权限分配:将 API Key 与用户角色绑定,不同角色对应不同的模型功能权限(如生成长度限制、功能模块访问权限)
- 违规 Prompt 拦截:在模型生成前增加内容审核关卡,通过关键词匹配 + 语义检测双重机制,拦截敏感请求
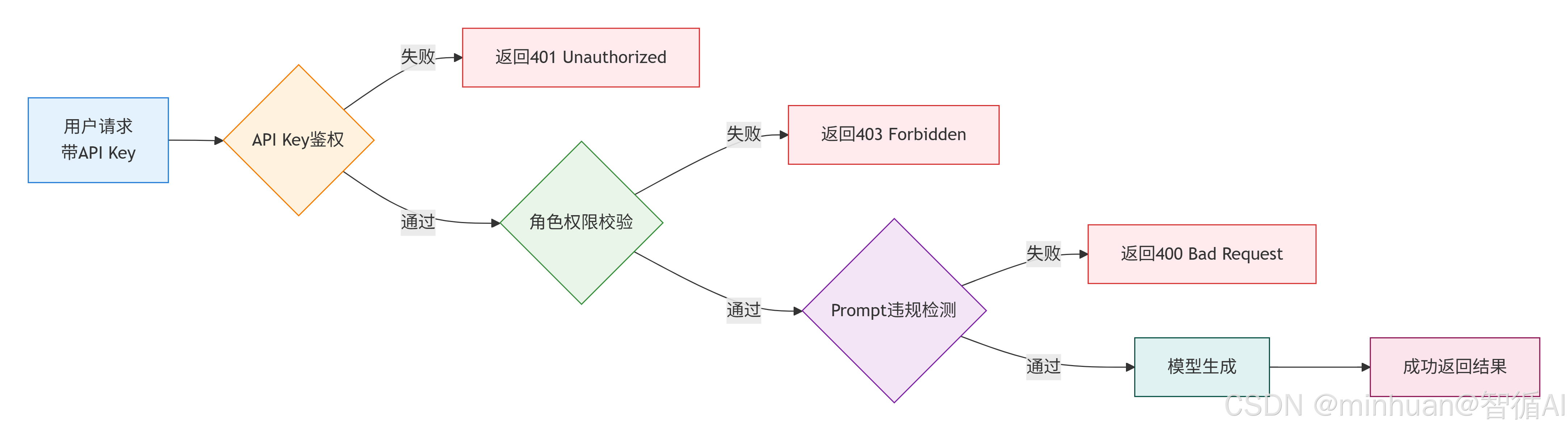
核心处理阶段:
-
- API Key鉴权:验证API Key的有效性,成功则进入下一阶段
-
- 角色权限校验:检查用户角色是否有权限执行请求的操作,成功则进入下一阶段
-
- Prompt违规检测:检查用户输入的提示词是否包含违规内容,失败提示违规,成功则进入模型生成阶段
-
- 模型生成:调用大模型进行内容生成,返回生成结果
三、核心模块实现
我们在原有的 FastAPI 本地模型服务鉴权代码的基础上,新增角色权限管理模块和Prompt 审核模块,并整合到请求处理链路中。
1. 模块配置
1.1 角色-权限映射表
简单的角色和权限映射,可迁移至MySQL/Redis实现动态配置,支持权限热更新,字段说明:max_length=最大生成长度,allow_all=是否允许全功能访问
python
ROLE_PERMISSIONS = {
"admin": {"max_length": 1000, "allow_all": True}, # 管理员:无限制,可用于系统调试
"user": {"max_length": 500, "allow_all": False}, # 普通用户:适用于内部员工日常使用
"guest": {"max_length": 200, "allow_all": False} # 访客:适用于外部合作方,严格限制权限
}1.2 API Key-角色绑定表
建议生产环境通过配置中心分发API Key,定期轮换避免泄露
python
API_KEY_ROLE_MAP = {
os.getenv("ADMIN_API_KEY", "admin_123456"): "admin",
os.getenv("USER_API_KEY", "user_123456"): "user",
os.getenv("GUEST_API_KEY", "guest_123456"): "guest"
}1.3 敏感词列表
需要过滤的敏感词列表清单,可扩展为词库文件,定期更新,建议结合行业合规要求补充,也可对接第三方内容安全接口,提升检测准确率
python
SENSITIVE_WORDS = ["敏感词1", "敏感词2", "违规内容", "违法信息", "涉密内容", "低俗内容", "暴力信息"]1.4 模型配置
模型可以根据实际需求替换模型ID和缓存路径,适配不同硬件环境,此处我们还是选择我本地已有的模型
python
MODEL_ID = "qwen/Qwen1.5-0.5B" # 轻量模型,适合CPU测试;生产可换Qwen1.5-7B(需GPU支持)
# 缓存路径适配Windows/Linux系统,确保路径存在且有读写权限
CACHE_DIR = "D:\\modelscope\\hub"
# 确保缓存目录存在,避免模型下载时路径错误
os.makedirs(CACHE_DIR, exist_ok=True)2. 基础依赖与全局配置
在代码中添加全局配置:角色权限映射、敏感词列表,这些配置可根据企业需求存入数据库或配置文件,此处为演示使用本地字典。
- 单例模式加载本地模型,避免重复加载占用内存
- 特性:1. 程序启动时仅加载一次;2. 捕获加载异常并打印详情;3. 支持模型路径复用 """
python
from fastapi import FastAPI, Header, HTTPException
from pydantic import BaseModel
from dotenv import load_dotenv
import os
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
# ===== 新增:全局配置项 =====
# 1. 角色定义与权限映射:key=角色,value=最大生成长度/可访问功能
ROLE_PERMISSIONS = {
"admin": {"max_length": 1000, "allow_all": True}, # 管理员:无限制
"user": {"max_length": 500, "allow_all": False}, # 普通用户:长度限制
"guest": {"max_length": 200, "allow_all": False} # 访客:严格长度限制
}
# 2. API Key与角色绑定(企业场景建议存入数据库/配置中心)
API_KEY_ROLE_MAP = {
"admin_123456": "admin",
"user_123456": "user",
"guest_123456": "guest"
}
# 3. 敏感词列表(企业场景可扩展为词库文件)
SENSITIVE_WORDS = ["敏感词1", "敏感词2", "违规内容"]
# ===== 原有:单例模式加载本地模型 =====
class LocalModel:
_instance = None
def __new__(cls):
if cls._instance is None:
model_id = "qwen/Qwen1.5-0.5B"
cache_dir = "D:\\modelscope\\hub"
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_id, cache_dir=cache_dir)
cls._instance = super().__new__(cls)
cls._instance.tokenizer = AutoTokenizer.from_pretrained(local_model_path)
cls._instance.model = AutoModelForCausalLM.from_pretrained(local_model_path)
return cls._instance
model = LocalModel()
load_dotenv()
app = FastAPI(title="本地大模型权限管控服务", description="支持角色权限+Prompt审核的企业级服务")3. 角色校验与 Prompt 拦截
新增两个核心函数,分别实现角色权限校验和违规 Prompt 检测,这两个函数是权限管控的核心逻辑。
python
# ===== 新增:1. 角色权限校验函数 =====
def check_role_permission(api_key: str, req_max_length: int) -> str:
"""
校验API Key合法性及对应角色的权限
:param api_key: 请求头中的API Key(必填,无默认值)
:param req_max_length: 请求指定的生成长度(需为正整数)
:return: 合法角色名(admin/user/guest)
:raise HTTPException: 鉴权/权限失败时抛出异常,包含明确错误信息
"""
# 校验API Key是否存在
if api_key not in API_KEY_ROLE_MAP:
raise HTTPException(status_code=401, detail="无效的API Key")
# 获取角色及对应权限
role = API_KEY_ROLE_MAP[api_key]
role_max_len = ROLE_PERMISSIONS[role]["max_length"]
# 校验生成长度是否超出角色权限
if req_max_length > role_max_len and not ROLE_PERMISSIONS[role]["allow_all"]:
raise HTTPException(
status_code=403,
detail=f"角色[{role}]的最大生成长度为{role_max_len},当前请求长度{req_max_length}超出限制"
)
return role
# ===== 新增:2. Prompt违规检测函数 =====
def check_prompt_safety(prompt: str) -> bool:
"""
检测Prompt是否包含敏感内容
:param prompt: 用户输入的提示词
:return: 安全返回True;违规返回False并抛出HTTPException
"""
# 1. 关键词匹配检测(基础版)
for word in SENSITIVE_WORDS:
if word in prompt:
raise HTTPException(status_code=400, detail=f"Prompt包含敏感内容:{word}")
# 2. 语义检测(进阶版,可替换为本地文本分类模型)
# 企业场景可扩展:调用本地部署的文本安全模型,对Prompt做语义级违规检测
# 示例:semantic_result = local_safety_model.predict(prompt)
# if semantic_result == "unsafe":
# raise HTTPException(status_code=400, detail="Prompt语义违规")
return True4. 整合管控逻辑
文本生成接口,在原有的/generate-text接口中,嵌入角色权限校验和Prompt 安全检测步骤,形成完整的管控链路:
-
- 身份鉴权:校验API Key有效性
-
- 权限校验:根据角色限制生成长度
-
- 内容审核:拦截违规Prompt
-
- 模型生成:调用本地模型返回结果
python
# 定义请求格式(保持原有结构)
class TextRequest(BaseModel):
prompt: str # 用户输入的提示词
max_length: int = 100 # 生成文本长度(默认100字)
# ===== 扩展:生成接口整合管控逻辑 =====
@app.post("/generate-text")
async def generate_text(
request: TextRequest,
x_api_key: str = Header(None, description="用户API Key")
):
# 步骤1:API Key鉴权 + 角色权限校验
role = check_role_permission(x_api_key, request.max_length)
# 步骤2:Prompt违规检测
check_prompt_safety(request.prompt)
# 步骤3:调用模型生成内容(原有逻辑)
inputs = model.tokenizer(request.prompt, return_tensors="pt")
outputs = model.model.generate(
**inputs,
max_length=request.max_length,
pad_token_id=model.tokenizer.eos_token_id # 防止tokenizer报错
)
result = model.tokenizer.decode(outputs[0], skip_special_tokens=True)
# 返回结果时携带角色信息(便于企业审计)
return {
"role": role,
"prompt": request.prompt,
"generated_text": result,
"used_max_length": request.max_length
}
# 启动服务(命令行执行:uvicorn filename:app --reload)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)5. 系统整体说明
- **单例模式:**示例代码中采用单例模式加载LocalModel,避免了每次请求重复加载模型,极大降低了服务器内存占用,这是本地模型服务的性能优化核心。
- **角色与 API Key 强绑定:**通过API_KEY_ROLE_MAP实现 "一机一钥一角色",企业可根据部门 / 岗位分配不同 API Key,便于权限追溯和审计。
- **双层 Prompt 检测机制:**基础层关键词匹配满足通用场景,进阶层语义检测可应对绕开关键词的隐晦违规请求,可根据安全需求灵活选择。
- **便捷性扩展:**所有管控逻辑都独立于模型调用逻辑,后续升级模型或替换模型时,无需修改管控代码,符合开闭原则。
四、系统测试与验证
1. 服务启动
首先运行启动系统,同样的看到【INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)】表示系统启动成功

访问FastAPI 的自动文档路径【http://localhost:8000/docs】,即可看到接口;
2. 需求场景
明确我们要了解的应用场景:
2.1 管理员正常请求
- x_api_key参数:admin_123456
- prompt参数:写一段春天的文案
- max_length参数:1000
- 预期响应结果:成功返回生成的文案,role 字段为 admin
2.2 普通用户超长请求
- x_api_key参数:user_123456
- prompt参数:写一段春天的文案
- max_length参数:600
- 预期响应结果:403 错误,提示 角色user的最大生成长度为500
2.3 访客敏感请求
- x_api_key参数:guest_123456
- prompt参数:敏感词1
- max_length参数:200
- 预期响应结果:400 错误,提示 Prompt包含敏感内容:敏感词1
2.4 无效 API Key 请求
- x_api_key参数:wrong_key_123
- prompt参数:写一段文案
- max_length参数:100
- 预期响应结果:401 错误,提示 无效的API Key
3. 场景测试
3.1 FastAPI 自动文档测试
-
- 打开浏览器,访问 http://127.0.0.1:8000/docs,进入自动生成的 Swagger 文档页面。
-
- 找到 /generate-text 接口,点击 Try it out 按钮,进入测试界面。
-
- 按以上提到的4个场景填写参数,点击 Execute 执行测试,查看响应结果:
测试普通用户超长请求:
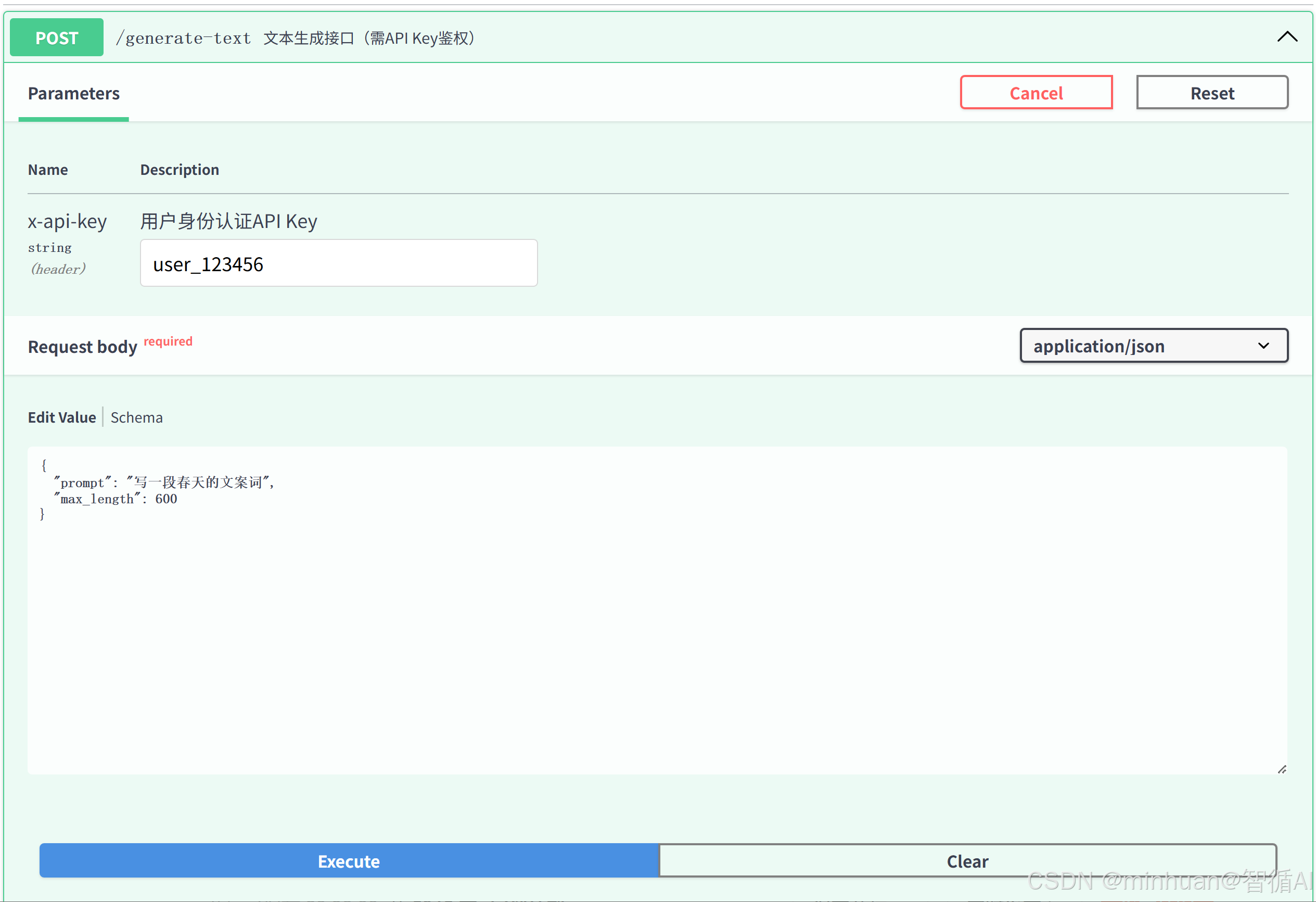
测试的结果反馈:
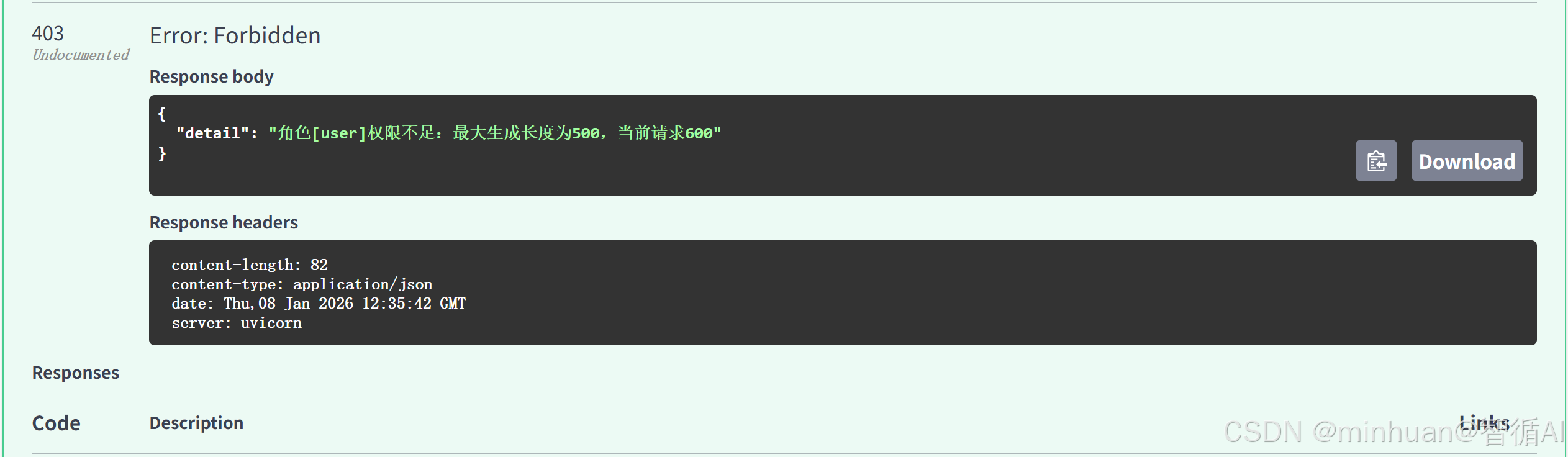
依次类推,我们可以同样测试其他形式的内容结果;
3.2 curl 命令行测试
我们采用新的方式,直观简洁,只需打开新的终端或命令行窗口,执行以下命令测试各场景(Windows 系统建议使用 Git Bash 或 PowerShell 执行):
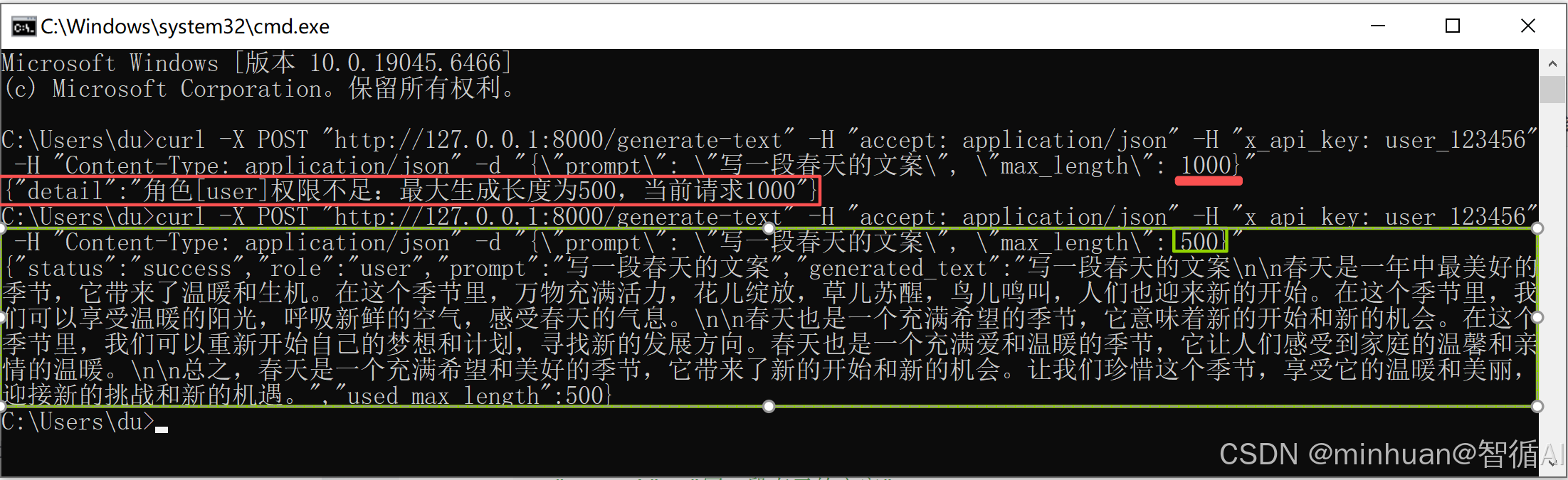
3.2.1 普通用户超长请求
bash
curl -X 'POST' \
'http://127.0.0.1:8000/generate-text' \
-H 'accept: application/json' \
-H 'x_api_key: user_123456' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "写一段春天的文案",
"max_length": 600
}'以上内容方便阅读,实际执行需清除空格和进行转义:
curl -X POST "http://127.0.0.1:8000/generate-text" -H "accept: application/json" -H "x_api_key: user_123456" -H "Content-Type: application/json" -d "{\"prompt\": \"写一段春天的文案\", \"max_length\": 600}"
我们先将长度设置为1000,提示超长,修改为500后正常输出!
3.2.2 管理员正常请求:
bash
curl -X 'POST' \
'http://127.0.0.1:8000/generate-text' \
-H 'accept: application/json' \
-H 'x_api_key: admin_123456' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "写一段春天的文案",
"max_length": 1000
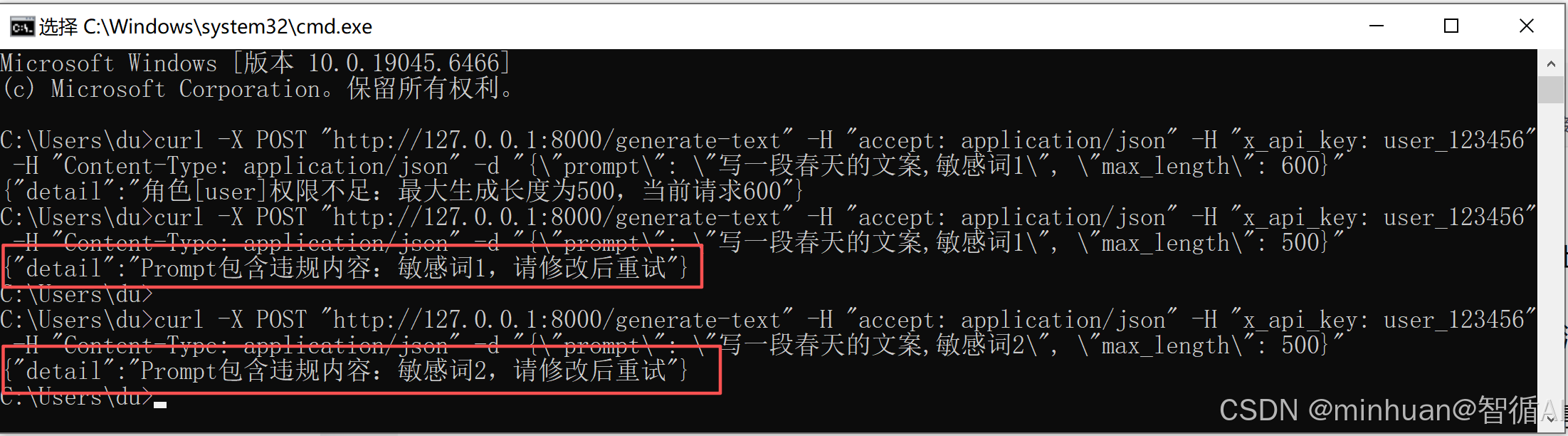
}'3.2.3 访客敏感请求
bash
curl -X 'POST' \
'http://127.0.0.1:8000/generate-text' \
-H 'accept: application/json' \
-H 'x_api_key: user_123456' \
-H 'Content-Type: application/json' \
-d '{
"prompt": "写一段春天的文案,敏感词1",
"max_length": 500
}'
4. 优化扩展
今天我们实现的是权限管控系统的基础版本,实际落地时可结合实际需求进一步扩展:
- 权限存储扩展:将ROLE_PERMISSIONS和API_KEY_ROLE_MAP迁移至 MySQL/Redis,支持动态增删改查角色和权限。
- 安全检测升级:接入本地部署的文本安全模型(如 BERT 文本分类模型),实现语义级、上下文级的违规检测。
- 日志审计模块:新增请求日志记录,记录用户角色、请求 Prompt、生成结果、请求时间,满足企业合规审计需求。
- 多模型权限管控:扩展角色权限至 "模型维度",不同角色可调用不同的本地模型,不同的需求用不同的模型执行,形成多模态的支持。
五、总结
简单说,这个系统就是给本地部署的大模型配了个智能管家,专门帮企业管好用模型的规矩,既不让人乱调用、超权限使用,也能拦住违规内容,避免出合规问题,整体轻量又好上手,不用动模型本身的代码就能用。
它核心就管两大块事,都特别好理解。一是按角色分权限,跟公司发门禁卡一个道理:管理员拿万能卡,生成长度能到1000字,功能全开放,适合内部调试;普通员工是工作卡,最多生成500字,满足日常办公需求;外部访客只有临时卡,仅限200字,防止外人滥用资源。二是守好内容关,我们输的提示词里只要有敏感词、违法信息,系统会直接拦截,压根不让模型去生成,从源头避免乱内容。
附录:完整实例代码
python
# -*- coding: utf-8 -*-
"""
功能:支持角色权限分配、违规Prompt拦截、本地模型调用
"""
# 基础依赖导入
from fastapi import FastAPI, Header, HTTPException
from pydantic import BaseModel
from dotenv import load_dotenv
import os
from transformers import AutoTokenizer, AutoModelForCausalLM
from modelscope import snapshot_download
# ===================== 全局配置模块 =====================
# 加载环境变量(存储API Key,避免硬编码,企业场景推荐)
load_dotenv()
# 1. 角色-权限映射表(可迁移至MySQL/Redis实现动态配置)
# 字段说明:max_length=最大生成长度,allow_all=是否允许全功能访问
ROLE_PERMISSIONS = {
"admin": {"max_length": 1000, "allow_all": True}, # 管理员:无限制
"user": {"max_length": 500, "allow_all": False}, # 普通用户:长度限制
"guest": {"max_length": 200, "allow_all": False} # 访客:严格限制
}
# 2. API Key-角色绑定表(从环境变量读取,安全可控)
# API_KEY_ROLE_MAP = {
# os.getenv("ADMIN_API_KEY", "admin_123456"): "admin",
# os.getenv("USER_API_KEY", "user_123456"): "user",
# os.getenv("GUEST_API_KEY", "guest_123456"): "guest"
# }
API_KEY_ROLE_MAP = {
"admin_123456": "admin",
"user_123456": "user", # 直接固定,不读环境变量
"guest_123456": "guest"
}
# 3. 敏感词列表(可扩展为词库文件,定期更新)
SENSITIVE_WORDS = ["敏感词1", "敏感词2", "违规内容", "违法信息", "涉密内容"]
# 4. 模型配置(根据实际需求替换模型ID和缓存路径)
MODEL_ID = "qwen/Qwen1.5-0.5B" # 轻量模型,适合测试;生产可换Qwen1.5-7B
CACHE_DIR = "D:\\modelscope\\hub" if os.name == "nt" else "/home/modelscope/hub"
# ===================== 单例模型加载模块 =====================
class LocalModel:
"""单例模式加载本地模型,避免重复加载占用内存"""
_instance = None
def __new__(cls):
if cls._instance is None:
try:
print(f"正在下载/校验模型【{MODEL_ID}】,缓存路径:{CACHE_DIR}")
# 从ModelScope下载模型至本地缓存
local_model_path = snapshot_download(MODEL_ID, cache_dir=CACHE_DIR)
# 初始化Tokenizer和Model
cls._instance = super().__new__(cls)
cls._instance.tokenizer = AutoTokenizer.from_pretrained(local_model_path)
cls._instance.model = AutoModelForCausalLM.from_pretrained(local_model_path)
print("模型加载完成,可正常提供服务")
except Exception as e:
print(f"模型加载失败:{str(e)}")
raise # 抛出异常,终止服务启动
return cls._instance
# 初始化模型实例(程序启动时仅加载一次)
model = LocalModel()
# ===================== 权限与安全校验模块 =====================
def check_role_permission(api_key: str, req_max_length: int) -> str:
"""
校验API Key合法性及对应角色的权限
:param api_key: 请求头中的API Key
:param req_max_length: 请求指定的生成长度
:return: 合法角色名
:raise HTTPException: 鉴权/权限失败时抛出异常
"""
# 1. 校验API Key是否存在
print(api_key)
if api_key not in API_KEY_ROLE_MAP:
raise HTTPException(status_code=401, detail="无效的API Key,无访问权限")
# 2. 获取角色及对应权限
role = API_KEY_ROLE_MAP[api_key]
role_perm = ROLE_PERMISSIONS[role]
# 3. 校验生成长度是否超出角色限制(管理员跳过)
if not role_perm["allow_all"] and req_max_length > role_perm["max_length"]:
raise HTTPException(
status_code=403,
detail=f"角色[{role}]权限不足:最大生成长度为{role_perm['max_length']},当前请求{req_max_length}"
)
return role
def check_prompt_safety(prompt: str) -> None:
"""
检测Prompt是否包含违规内容
:param prompt: 用户输入的提示词
:raise HTTPException: 包含违规内容时抛出异常
"""
# 基础关键词检测(企业场景可扩展为语义检测模型)
for sensitive_word in SENSITIVE_WORDS:
if sensitive_word in prompt:
raise HTTPException(
status_code=400,
detail=f"Prompt包含违规内容:{sensitive_word},请修改后重试"
)
# 进阶:语义违规检测(可选,需部署本地文本安全模型)
# 示例:if not local_safety_model.check(prompt):
# raise HTTPException(status_code=400, detail="Prompt语义违规")
# ===================== FastAPI接口模块 =====================
# 创建FastAPI应用实例
app = FastAPI(
title="本地大模型权限管控服务",
description="基于FastAPI实现,支持角色权限分配、违规Prompt拦截的企业级文本生成服务",
version="1.0.0"
)
# 定义请求体模型(规范请求参数格式)
class TextRequest(BaseModel):
prompt: str # 用户输入的提示词(必填)
max_length: int = 100 # 生成文本长度(默认100字,范围受角色权限限制)
# 文本生成接口(核心接口,整合全链路管控)
@app.post("/generate-text", summary="文本生成接口(需API Key鉴权)")
async def generate_text(
request: TextRequest,
x_api_key: str = Header(None, description="用户身份认证API Key")
):
# 链路1:角色权限校验
role = check_role_permission(x_api_key, request.max_length)
# 链路2:Prompt安全检测
check_prompt_safety(request.prompt)
# 链路3:调用模型生成文本
try:
# 编码输入提示词
inputs = model.tokenizer(request.prompt, return_tensors="pt", truncation=True)
# 生成文本(设置pad_token_id避免报错)
outputs = model.model.generate(
**inputs,
max_length=request.max_length,
pad_token_id=model.tokenizer.eos_token_id,
do_sample=True, # 开启采样,提升生成多样性
temperature=0.7 # 采样温度,0-1之间,值越小越稳定
)
# 解码生成结果(跳过特殊token)
generated_text = model.tokenizer.decode(outputs[0], skip_special_tokens=True)
except Exception as e:
raise HTTPException(status_code=500, detail=f"模型生成失败:{str(e)}")
# 返回结果(包含角色信息,便于审计)
return {
"status": "success",
"role": role,
"prompt": request.prompt,
"generated_text": generated_text,
"used_max_length": request.max_length
}
# 服务健康检查接口(用于监控服务状态)
@app.get("/health", summary="服务健康检查")
async def health_check():
return {"status": "running", "message": "本地大模型权限管控服务正常运行中"}
# ===================== 服务启动入口 =====================
if __name__ == "__main__":
import uvicorn
# 启动服务(默认本地访问,局域网访问需改为host="0.0.0.0")
uvicorn.run(
app="__main__:app",
host="127.0.0.1",
port=8000,
reload=True # 开发环境开启热重载,生产环境关闭(设为False)
)