作者:来自 Elastic Ioana Tagirta
亲身体验 Elasticsearch:深入了解我们的示例 notebooks,开始免费的 cloud 试用,或立即在本地机器上试用 Elastic。
在 Elasticsearch 9.2 中,我们引入了在 Elasticsearch Query Language( ES|QL )中进行密集 vector search 和 hybrid search 的能力。这延续了我们将 ES|QL 打造成解决现代 search 用例的最佳 search 语言的投入。
多阶段检索:现代搜索的挑战
现代搜索已经不再只是简单的关键词匹配。今天的搜索应用需要理解意图,处理自然语言,并结合多个排序信号来提供最佳结果。
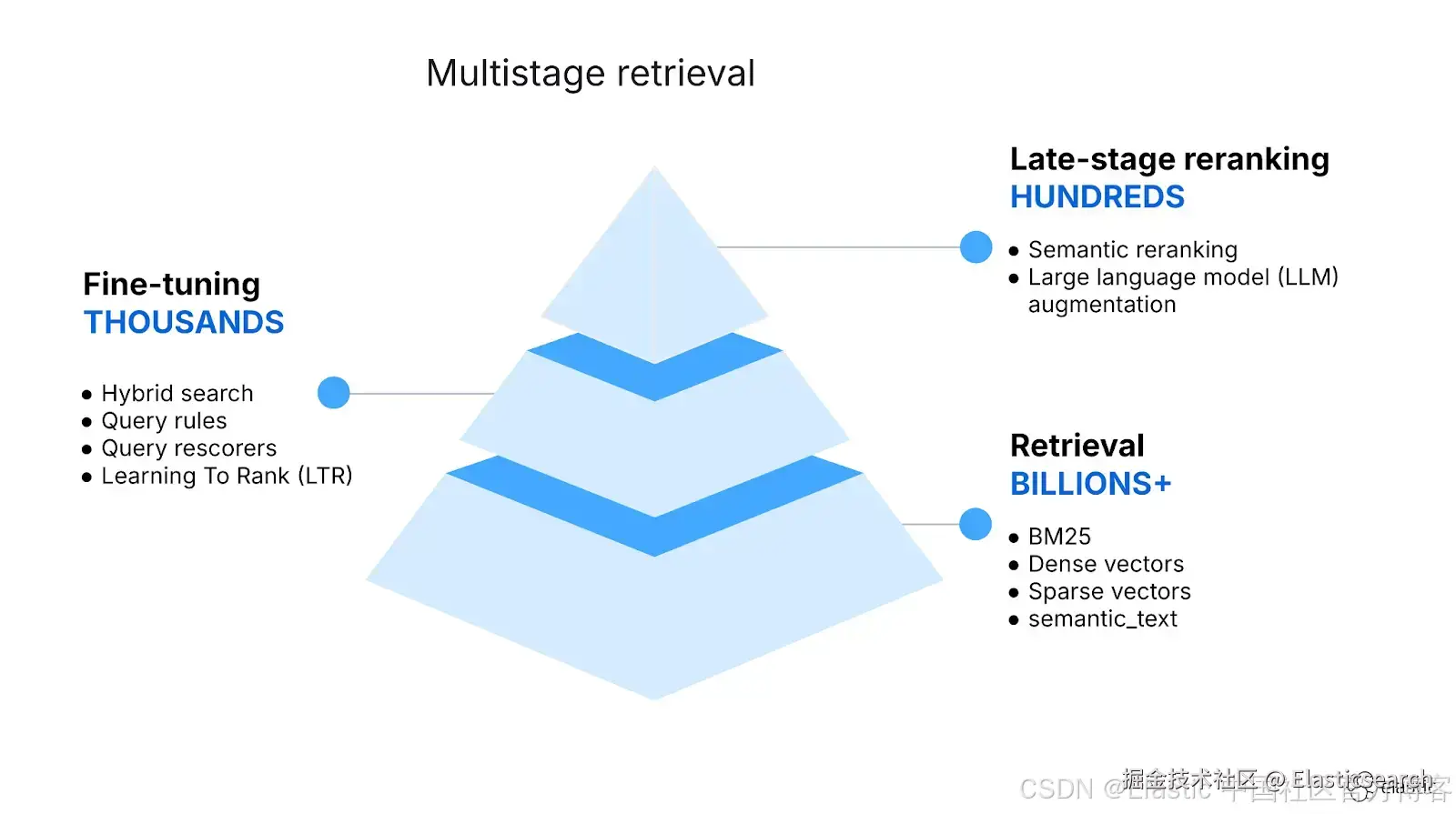
最相关结果的检索是在多个阶段中完成的,每个阶段都会逐步细化结果集。过去并非如此,当时大多数用例只需要一到两个阶段的检索:一次初始查询来获取结果,以及一个可能的重新评分阶段。
我们从初始检索开始,在这一阶段我们广泛搜索以收集与我们查询相关的结果。由于需要筛选所有数据,我们应该使用能够快速返回结果的技术,即使在索引数十亿文档时也能高效。
因此,我们采用可靠的技术,例如 Elasticsearch 从一开始就支持并优化的词汇搜索,或者 Elasticsearch 在速度和准确性上表现出色的 vector search。
使用 BM25 的 lexical search 非常快,最适合精确的术语匹配或短语匹配,而 vector 或 semantic search 更适合处理自然语言查询。Hybrid search 将 lexical 和 vector search 结果结合起来,以发挥两者的优势。Hybrid search 解决的挑战在于 vector 和 lexical search 拥有完全不同且不兼容的评分函数,它们生成的值在不同区间,并遵循不同分布。vector search 得分接近 1 可能意味着非常匹配,但 lexical search 并非如此。Hybrid search 方法,如 reciprocal rank fusion (RRF) 和 scores 的线性组合,会分配新的分数,将 lexical 和 vector search 的原始分数融合。
在 hybrid search 之后,我们可以使用 semantic reranking 和 Learning To Rank (LTR) 等技术,这些技术使用专门的 machine learning 模型对结果进行重新排序。
利用最相关的结果,我们可以使用 large language models (LLMs) 进一步丰富我们的响应,或在 Elastic Agent Builder 等工具的 agentic 工作流中,将最相关结果作为上下文传递给 LLMs。
ES|QL 能够处理检索的所有这些阶段。ES|QL 本身是一个管道语言,每条命令会转换输入并将输出发送到下一条命令。每个检索阶段由一个或多个连续的 ES|QL 命令表示。本文展示了 ES|QL 如何支持每个阶段。
Vector search - 向量搜索
在 Elasticsearch 9.2 中,我们在 ES|QL 中引入了密集 vector search 的技术预览支持。这和调用 knn 函数一样简单,只需要一个 dense_vector 字段和一个 query vector:
sql
`
1. FROM books METADATA _score
2. | WHERE KNN(description_vector, ?query_vector)
3. | SORT _score DESC
4. | LIMIT 100
`AI写代码此查询执行近似最近邻搜索,检索与 query_vector 最相似的 100 个文档。
混合搜索:Reciprocal rank fusion/RRF
在 Elasticsearch 9.2 中,我们在 ES|QL 中引入了使用 RRF 和结果线性组合的 hybrid search 支持。
这允许将 vector search 和 lexical search 结果合并为单一的结果集。
要在 ES|QL 中实现这一点,我们需要使用 FORK 和 FUSE 命令。FORK 可以运行多个执行分支,FUSE 则合并结果,并使用 RRF 或线性组合分配新的相关性分数。
在下面的示例中,我们使用 FORK 运行两个独立的分支,其中一个使用 match 函数进行 lexical search,另一个使用 knn 函数进行 vector search。然后我们使用 FUSE 将结果合并:
sql
`
1. FROM books METADATA _score, _id, _index
2. | FORK (WHERE KNN(description_vector, ?query_vector) | SORT _score DESC | LIMIT 100)
3. (WHERE MATCH(description, ?query) | SORT _score DESC | LIMIT 100)
4. | FUSE // uses RRF by default
5. | SORT _score DESC
`AI写代码让我们分解查询以更好地理解执行模型,首先来看 FORK 命令的输出:
sql
`
1. FROM books METADATA _score, _id, _index
2. | FORK (WHERE KNN(description_vector, ?query_vector) | SORT _score DESC | LIMIT 100)
3. (WHERE MATCH(description, ?query) | SORT _score DESC | LIMIT 100)
`AI写代码FORK 命令输出来自两个分支的结果,并添加了一个 _fork 鉴别器列:
| _id | title | _score | _fork |
|---|---|---|---|
| 4001 | The Hobbit | 0.88 | fork1 |
| 3999 | The Fellowship of the Ring | 0.88 | fork1 |
| 4005 | The Two Towers | 0.86 | fork1 |
| 4006 | The Return of the King | 0.84 | fork1 |
| 4123 | The Silmarillion | 0.78 | fork1 |
| 4144 | The Children of Húrin | 0.79 | fork1 |
| 4001 | The Hobbit | 4.55 | fork2 |
| 3999 | The Fellowship of the Ring | 4.25 | fork2 |
| 4123 | The Silmarillion | 4.11 | fork2 |
| 4005 | The Two Towers | 3.8 | fork2 |
| 4006 | The Return of the King | 4.1 | fork2 |
正如你会注意到的,某些文档会出现两次,这就是我们随后使用 FUSE 来合并表示相同文档的行并分配新的相关性分数的原因。FUSE 分两阶段执行:
- 对每一行,FUSE 根据所使用的 hybrid search 算法分配新的相关性分数。
- 表示相同文档的行会被合并,并计算新的分数。
在我们的示例中,我们使用 RRF。第一步,FUSE 使用 RRF 公式为每一行分配新的分数:
scss
`score(doc) = 1 / (rank_constant + rank(doc))`AI写代码其中 rank_constant 的默认值为 60,rank(doc) 表示文档在结果集中的位置。
在第一阶段,我们的结果变为:
| _id | title | _score | _fork |
|---|---|---|---|
| 4001 | The Hobbit | 1 / (60 + 1) = 0.01639 | fork1 |
| 3999 | The Fellowship of the Ring | 1 / (60 + 2) = 0.01613 | fork1 |
| 4005 | The Two Towers | 1 / (60 + 3) = 0.01587 | fork1 |
| 4006 | The Return of the King | 1 / (60 + 4) = 0.01563 | fork1 |
| 4123 | The Silmarillion | 1 / (60 + 5) = 0.01538 | fork1 |
| 4144 | The Children of Húrin | 1 / (60 + 6) = 0.01515 | fork1 |
| 4001 | The Hobbit | 1 / (60 + 1) = 0.01639 | fork2 |
| 3999 | The Fellowship of the Ring | 1 / (60 + 2) = 0.01613 | fork2 |
| 4123 | The Silmarillion | 1 / (60 + 3) = 0.01587 | fork2 |
| 4005 | The Two Towers | 1 / (60 + 4) = 0.01563 | fork2 |
| 4006 | The Return of the King | 1 / (60 + 5) = 0.01538 | fork2 |
然后这些行会被合并,并分配新的分数。由于 FUSE 命令后跟 SORT _score DESC,最终结果为:
| _id | title | _score |
|---|---|---|
| 4001 | The Hobbit | 0.01639 + 0.01639 = 0.03279 |
| 3999 | The Fellowship of the Ring | 0.01613 + 0.01613 = 0.03226 |
| 4005 | The Two Towers | 0.01587 + 0.01563 = 0.0315 |
| 4123 | The Silmarillion | 0.01538 + 0.01587 = 0.03125 |
| 4006 | The Return of the King | 0.01563 + 0.01538 = 0.03101 |
| 4144 | The Children of Húrin | 0.01515 |
混合搜索:scores 的线性组合
Reciprocal rank fusion 是执行 hybrid search 最简单的方法,但它不是我们在 ES|QL 中支持的唯一 hybrid search 方法。
在下面的示例中,我们使用 FUSE 通过 scores 的线性组合来合并 lexical 和 semantic search 结果:
sql
`
1. FROM books METADATA _score, _id, _index
2. | FORK (WHERE MATCH(semantic_description, ?query) | SORT _score DESC | LIMIT 100)
3. (WHERE MATCH(description, ?query) | SORT _score DESC | LIMIT 100)
4. | FUSE LINEAR WITH { "weights": { "fork1": 0.7, "fork2": 0.3 } }
5. | SORT _score DESC
`AI写代码让我们先分解查询,并查看当只运行 FORK 命令时 FUSE 命令的输入。
注意,我们使用 match 函数,它不仅可以查询 lexical 字段,如 text 或 keyword,还可以查询 semantic_text 字段。
第一个 FORK 分支通过查询 semantic_text 字段执行 semantic query,而第二个分支执行 lexical query:
sql
`
1. FROM books METADATA _score, _id, _index
2. | FORK (WHERE MATCH(semantic_description, ?query) | SORT _score DESC | LIMIT 100)
3. (WHERE MATCH(description, ?query) | SORT _score DESC | LIMIT 100)
`AI写代码FORK 命令的输出可能包含具有相同 _id 和 _index 值的行,这些行表示同一个 Elasticsearch 文档:
| _id | title | _score | _fork |
|---|---|---|---|
| 4001 | The Hobbit | 0.88 | fork1 |
| 3999 | The Fellowship of the Ring | 0.88 | fork1 |
| 4005 | The Two Towers | 0.86 | fork1 |
| 4006 | The Return of the King | 0.84 | fork1 |
| 4123 | The Silmarillion | 0.78 | fork1 |
| 4144 | The Children of Húrin | 0.79 | fork1 |
| 4001 | The Hobbit | 4.55 | fork2 |
| 3999 | The Fellowship of the Ring | 4.25 | fork2 |
| 4123 | The Silmarillion | 4.11 | fork2 |
| 4005 | The Two Towers | 3.8 | fork2 |
| 4006 | The Return of the King | 4.1 | fork2 |
在下一步,我们使用 FUSE 合并具有相同 _id 和 _index 值的行,并分配新的相关性分数。
新的分数是该行在每个 FORK 分支中的分数的线性组合:
ini
`_score = 0.7 *_score1 + 0.3 * _score2`AI写代码这里,_score1 和 _score2 分别表示文档在第一个 FORK 分支和第二个 FORK 分支中的分数。
注意,我们还应用了自定义权重,对 semantic score 给予比 lexical score 更高的权重,得到这一组文档:
| _id | title | _score |
|---|---|---|
| 4001 | The Hobbit | 0.7 * 0.88 + 0.3 * 4.55 = 1.981 |
| 3999 | The Fellowship of the Ring | 0.7 * 0.88 + 0.3 * 4.25 = 1.891 |
| 4006 | The Return of the King | 0.7 * 0.84 + 0.3 * 4.1 = 1.818 |
| 4123 | The Silmarillion | 0.7 * 0.78 + 0.3 * 4.11 = 1.779 |
| 4005 | The Two Towers | 0.7 * 0.86 + 0.3 * 3.8 = 1.742 |
| 4144 | The Children of Húrin | 0.7 * 0.79 + 0.3 * 0 = 0.553 |
一个挑战是 semantic score 和 lexical score 可能不兼容直接进行线性组合,因为它们可能遵循完全不同的分布。为缓解这一问题,我们首先需要对分数进行归一化,使用 score normalization 方法,如 minmax。这样可以确保每个 FORK 分支的分数在应用线性组合公式前先被归一化到 0 到 1 之间的值。
要使用 FUSE 实现这一点,我们需要指定 normalizer 选项:
sql
`
1. FROM books METADATA _score, _id, _index
2. | FORK (WHERE MATCH(semantic_description, ?query) | SORT _score DESC | LIMIT 100)
3. (WHERE MATCH(description, ?query) | SORT _score DESC | LIMIT 100)
4. | FUSE LINEAR WITH { "weights": { "fork1": 0.7, "fork2": 0.3 }, "normalizer": "minmax" }
5. | SORT _score DESC
`AI写代码Semantic reranking
在这一阶段,经过 hybrid search 后,我们应该只剩下最相关的文档。我们现在可以使用 semantic reranking 通过 RERANK 命令重新排序结果。默认情况下,RERANK 使用最新的 Elastic semantic reranking 机器学习模型,因此无需额外配置:
sql
`
1. FROM books METADATA _score, _id, _index
2. | FORK (WHERE KNN(description_vector, ?query_vector) | SORT _score DESC | LIMIT 100)
3. (WHERE MATCH(description, ?query) | SORT _score DESC | LIMIT 100)
4. | FUSE
5. | SORT _score DESC
6. | LIMIT 100
7. | RERANK ?query ON description
8. | SORT _score DESC
`AI写代码我们现在得到了按相关性排序的最佳结果。
RERANK 命令区别于其他提供 semantic reranking 集成的产品的一个关键特性是,它不要求输入必须是索引中的映射字段。RERANK 只需要一个能求值为字符串的表达式,因此可以使用多个字段进行 semantic reranking:
sql
`
1. FROM books METADATA _score, _id, _index
2. | FORK (WHERE KNN(description_vector, ?query_vector) | SORT _score DESC | LIMIT 100)
3. (WHERE MATCH(description, ?query) | SORT _score DESC | LIMIT 100)
4. | FUSE
5. | SORT _score DESC
6. | LIMIT 100
7. | RERANK ?query ON CONCAT(title, "\n", description)
8. | SORT _score DESC
`AI写代码LLM completions
现在我们有了一组高度相关、重新排序的结果。
在这一阶段,你可以选择直接将结果返回给你的应用,也可以使用 LLM completions 进一步增强结果。
如果你在 retrieval-augmented generation (RAG) 工作流中使用 ES|QL,你可以选择直接从 ES|QL 调用你喜欢的 LLM。
为此,我们新增了 COMPLETION 命令,它接受一个 prompt、一个 completion inference ID(指定调用哪个 LLM)以及一个列标识符(指定 LLM 响应输出到哪一列)。
在下面的示例中,我们使用 COMPLETION 添加了一个新的 _completion 列,其中包含 content 列的摘要:
sql
`1. FROM books METADATA _score, _id, _index
2. | FORK (WHERE KNN(description_vector, ?query_vector) | SORT _score DESC | LIMIT 100)
3. (WHERE MATCH(description, ?query) | SORT _score DESC | LIMIT 100)
4. | FUSE
5. | SORT _score DESC
6. | LIMIT 100
7. | RERANK ?query ON description
8. | SORT _score DESC
9. | LIMIT 10
10. | COMPLETION CONCAT("Summarize the following:\n", description) WITH { "inference_id" : "my_inference_endpoint" }` AI写代码每一行现在都包含一个摘要:
| _id | title | _score | summary |
|---|---|---|---|
| 4001 | The Hobbit | 0.03279 | Bilbo helps dwarves reclaim Erebor from the dragon Smaug. |
| 3999 | The Fellowship of the Ring | 0.03226 | Frodo begins the quest to destroy the One Ring. |
| 4005 | The Two Towers | 0.0315 | The Fellowship splits; war comes to Rohan; Frodo nears Mordor. |
| 4123 | The Silmarillion | 0.03125 | Ancient myths and history of Middle-earth's First Age. |
| 4006 | The Return of the King | 0.3101 | Sauron is defeated and Aragorn is crowned King. |
| 4144 | The Children of Húrin | 0.01515 | The tragic tale of Túrin Turambar's cursed life. |
在另一种用例中,你可能只是想使用自己在 Elasticsearch 中索引的专有数据来回答问题。在这种情况下,我们在前一阶段计算出的最佳搜索结果可以作为 prompt 的上下文:
sql
`
1. FROM books METADATA _score, _id, _index
2. | FORK (WHERE KNN(description_vector, ?query_vector) | SORT _score DESC | LIMIT 100)
3. (WHERE MATCH(description, ?query) | SORT _score DESC | LIMIT 100)
4. | FUSE
5. | SORT _score DESC
6. | LIMIT 100
7. | RERANK ?query ON description
8. | SORT _score DESC
9. | LIMIT 10
10. | STATS context = VALUES(CONCAT(title, "\n", description)
11. | COMPLETION CONCAT("Answer the following question ", ?query, "based on:\n", context) WITH { "inference_id" : "my_inference_endpoint" }
`AI写代码由于 COMPLETION 命令解锁了向 LLM 发送任意 prompt 的能力,可能性是无穷的。虽然我们只展示了一些示例,但 COMPLETION 命令可以用于各种场景,从安全分析师根据日志事件是否可能表示恶意行为来分配分数,到数据科学家用它分析数据,甚至到仅仅根据你的数据生成 Chuck Norris 事实的情况。
这只是开始
未来,我们将扩展 ES|QL,以改进长文档的 semantic reranking,更好地使用多个 FORK 命令进行 ES|QL 查询的条件执行,支持 sparse vector 查询,去除近似重复结果以提高结果多样性,允许对运行时生成的列进行全文搜索,以及更多其他场景。
更多教程和指南:
- ES|QL for search
- ES|QL for search tutorial
- Semantic_text field type
- FORK and FUSE 文档
- ES|QL search functions