本篇文章主要讲解 Linux 操作系统中进程的相关概念
目录
[1 冯诺依曼体系结构](#1 冯诺依曼体系结构)
[1) 冯诺依曼体系结构产生的背景](#1) 冯诺依曼体系结构产生的背景)
[2) 冯诺依曼体系结构](#2) 冯诺依曼体系结构)
[2 操作系统(Operating System,OS)](#2 操作系统(Operating System,OS))
[1) 操作系统的概念](#1) 操作系统的概念)
[2) shell 程序](#2) shell 程序)
[(1) 什么是 shell 程序](#(1) 什么是 shell 程序)
[(2) shell 程序的意义](#(2) shell 程序的意义)
[3) 设计操作系统的目的](#3) 设计操作系统的目的)
[4) 操作系统核心功能](#4) 操作系统核心功能)
[5) 系统调用与库函数](#5) 系统调用与库函数)
[(1) 系统调用](#(1) 系统调用)
[(2) 库函数](#(2) 库函数)
[3 进程的概念](#3 进程的概念)
[1) 描述进程 -- PCB](#1) 描述进程 -- PCB)
[2) 组织进程 -- 双链表](#2) 组织进程 -- 双链表)
[3) 查看进程](#3) 查看进程)
[(1) 通过 proc 目录来查看进程](#(1) 通过 proc 目录来查看进程)
[(2) 通过 ps axj 命令查看](#(2) 通过 ps axj 命令查看)
[4) 使用系统调用获取进程 pid、ppid 与 创建子进程](#4) 使用系统调用获取进程 pid、ppid 与 创建子进程)
[(1) 获取 pid 与 ppid](#(1) 获取 pid 与 ppid)
[(2) 通过 fork 系统调用来创建子进程](#(2) 通过 fork 系统调用来创建子进程)
[4 总结](#4 总结)
1 冯诺依曼体系结构
1) 冯诺依曼体系结构产生的背景
1946 年,世界上诞生了第一台电子计算机 ENIAC:

其体型庞大,造价昂贵,只能完成单一计算任务,并且具有多种缺陷,比如存储与程序分离存储、存储容量有限、通用性极差等。基于上述缺陷,美国计算机科学家约翰·冯·诺依曼于 1945 年在《关于 EDVAC 的报告草案》中提出了冯诺依曼体系结构,解决了 ENIAC 等专用计算机的缺陷,为后来通用计算机的发展奠定了基础。
2) 冯诺依曼体系结构
当前我们常见的计算机,如笔记本、服务器等都是遵循冯诺依曼体系结构的。冯诺依曼体系结构规定计算机由以下 5 大部件组成:
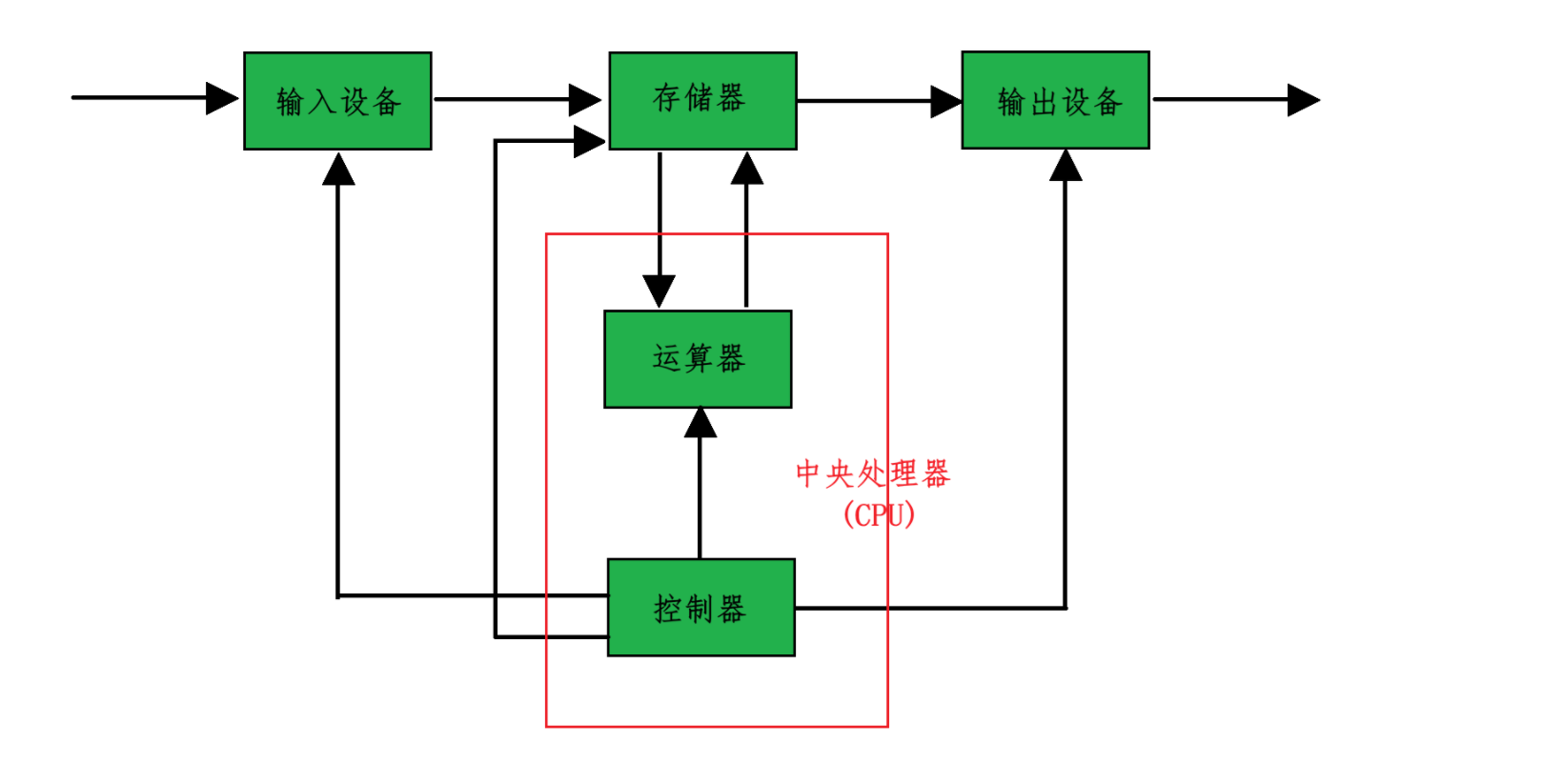
(1) 输入设备:主要是计算机上那些进行输入的硬件,包括键盘、鼠标、扫描仪等
(2) 输出设备:主要是进行输出的硬件,包括显示器、音响等。有些设备既属于输入设备,也叫做输出设备,比如网卡等
(3) 中央处理器(CPU):包括控制器和运算器。其中控制器主要是进行各种控制动作的,比如取指令、写操作、读操作等;运算器主要是进行算术运算与逻辑运算,比如 1 + 2、true && false 等运算操作。
(4) 存储器:存储器分为外存和内存,外存容量大,存取速度慢,比如磁盘,断电之后不会丢失数据;内存容量小,但是存取速度快,断电之后会丢失数据。值得注意的是,上面图中的存储器主要是值内存
(5) 计算机的各个模块之间通过总线相连,总线分为控制总线(传输控制信号)、地址总线(传输存储器地址)与数据总线(传输各种数据与指令等)
所以通过上图我们可以看出,计算器中的各种设备都只能与内存直接交流,并不能跨过内存而去与外存交流,存取数据都只能通过内存来实现。另外,在冯诺依曼体系结构中,各种硬件之间的效率是存在很大差别的:输入输出设备(外设) << 内存 << cpu,其中 << 是远远小于的意思。所以内存其实是外设与 cpu 之间的缓存。
通过冯诺依曼体系结构,我们就可以知道你在你电脑上给朋友发了一条消息,是怎么通过硬件设备来传输到你朋友的电脑上的呢?由于各种硬件只能通过内存来存取数据,所以其数据流向是这样的:
键盘 ---> 内存 ---> cpu ---> 内存 ---> 网卡 ---> 网卡 ---> 内存 ---> cpu ---> 内存 ---> 显示器
第一个网卡及之前是你电脑的硬件设备,第二个网卡及之后是你朋友的电脑和设备。
2 操作系统(Operating System,OS)
1) 操作系统的概念
我们可能都听过对于操作系统的传统概念:操作系统是一款进行软硬件管理的软件。但是其实操作系统就是任何计算机都会包含的一个基本的程序集合,这个程序的功能是管理软硬件资源,这个程序集合叫做操作系统。
操作系统分为狭义的操作系统与广义的操作系统 ,狭义的操作系统就是指内核 ,也就是负责进行各种管理的,比如进程管理、内存管理等等,他仅仅是进行各种管理工作,并不认识你输入的各种命令。而广义的操作系统不仅包括内核,还包括操作系统的外壳程序(shell 程序)、glibc 等各种库,广义的操作系统与狭义的操作系统之间的关系为:
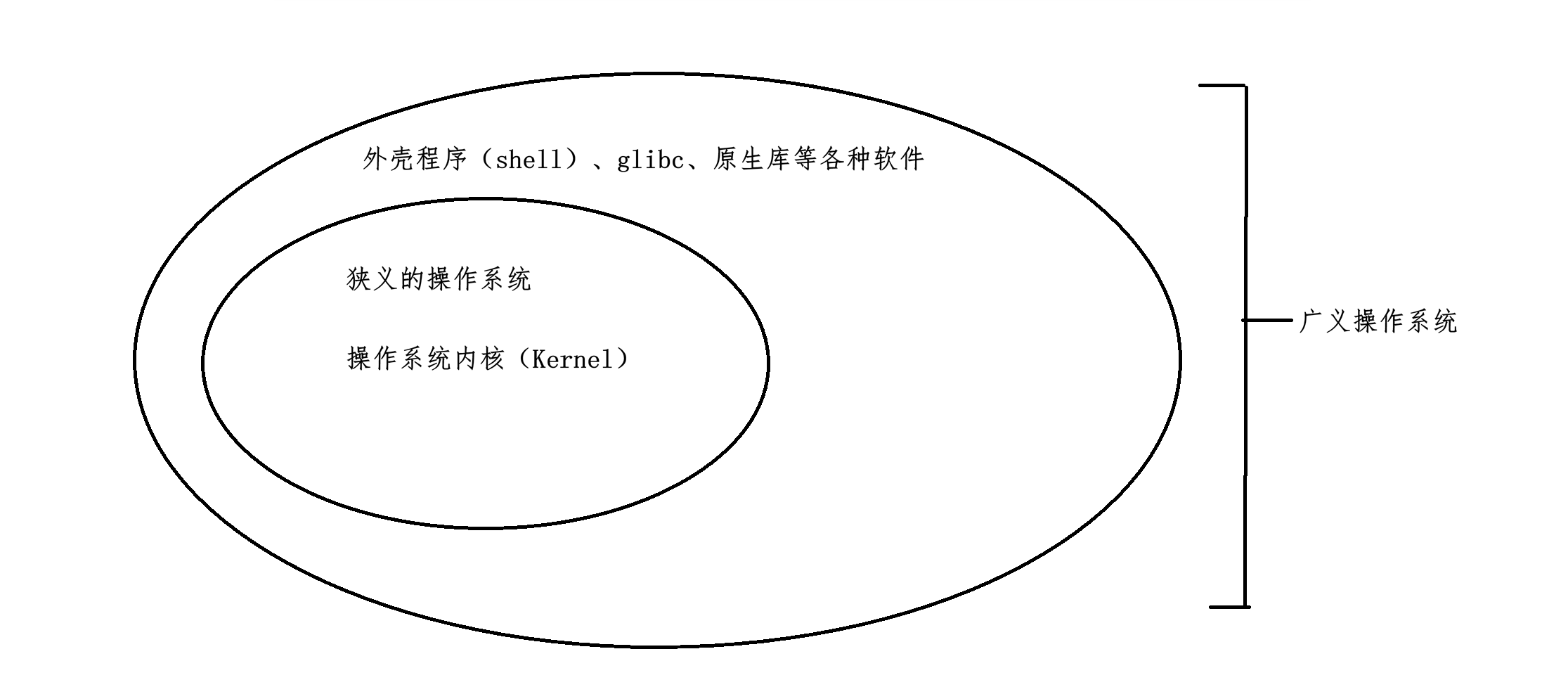
广义的操作系统不仅包含了狭义的操作系统,而且还包含了操作系统中的外壳(shell)程序,各种库等。其中 shell 进程是位于操作系统跟用户之间的中间程序,那么 shell 程序是什么呢?
2) shell 程序
(1) 什么是 shell 程序
shell 其中文翻译是外壳的意思,其还有另外一个简单的名称:命令行解释器。shell 存在的主要作用就是进行命令行解析的,所以其主要作用就是两个:
(1) 将用户的命令翻译给内核处理
(2) 将命令的处理结果返回给用户
对于 windows 操作系统,其 shell 程序不止一个,比如 powershell:
其跟 Linux 操作系统一样,可以通过命令行来控制 windows 操作系统,而 windows 命令行形式的另一个 shell 程序就是 cmd。而另一种 shell 程序就是 windows GUI,也就是我们平常常说的图形化界面。在这个 shell 程序上,我们双击一个桌面图标,就被 GUI 解析成一个命令,交给 windows 内核,然后内核来进行相关的处理。
而在 Linux 操作系统中,其 shell 程序就只有一个,叫做 bash,该程序存储在 /bin 目录下:

可以看到该程序是一个可执行程序,也就是我们 Linux 的命令行解析器,你在 Linux 操作系统上输入的任何命令,都会先由 bash 进程进行解析,然后再交给内核来处理,最终将该命令的处理结果返还给用户。比如输入了一个错误的命令:

bash 程序会首先进行解析,发现没有该命令,然后将结果告诉用户。
需要注意的是,shell 进程是一个统称,比如 windows 的 GUI,以及 Linux 的 bash 都可以称为 shell 程序,但是各个操作系统又各有自己的 shell 程序。虽然 shell 程序可以进行命令行解析,但是其存在意义不仅仅在于命令行解析,其对于内核和用户来说是十分重要的。
(2) shell 程序的意义
我们都知道,操作系统的内核非常重要,内核是进行 cpu、内存、文件、进程等各种底层资源管理的,如果放任用户对内核直接操作,一旦内核收到破坏,操作系统的资源管理功能就会遭到破坏,这是一种十分严重的现象,而 shell 进程就是位于操作系统跟用户之间的一个程序,用户通过 shell 程序来访问内核,shell 进程再将处理结果,一旦用户误操作,shell 程序会检测这种错误,并及时阻止用户,从而保护了内核。所以 shell 进程存在的意义一:shell 程序可以保护内核。
由于用户直接访问内核是一件十分危险的事情,所以操作系统的研发工程师会将内核封装起来,只留有部分接口供外部使用。但是这些接口对于没有学习过操作系统的人员来说,调用操作系统的接口是一件成本很高的事情。所以 shell 程序的存在就可以使得用户只学习少量、简单的命令就可以完成操作,不需要去调用成本很高的系统调用,进而降低了用户的使用成本。所以 shell 程序存在的意义二:shell 程序可以方便用户操作,降低用户的使用成本。
3) 设计操作系统的目的
计算机的底层硬件与上层用户我们可以抽象为下面的一张图:
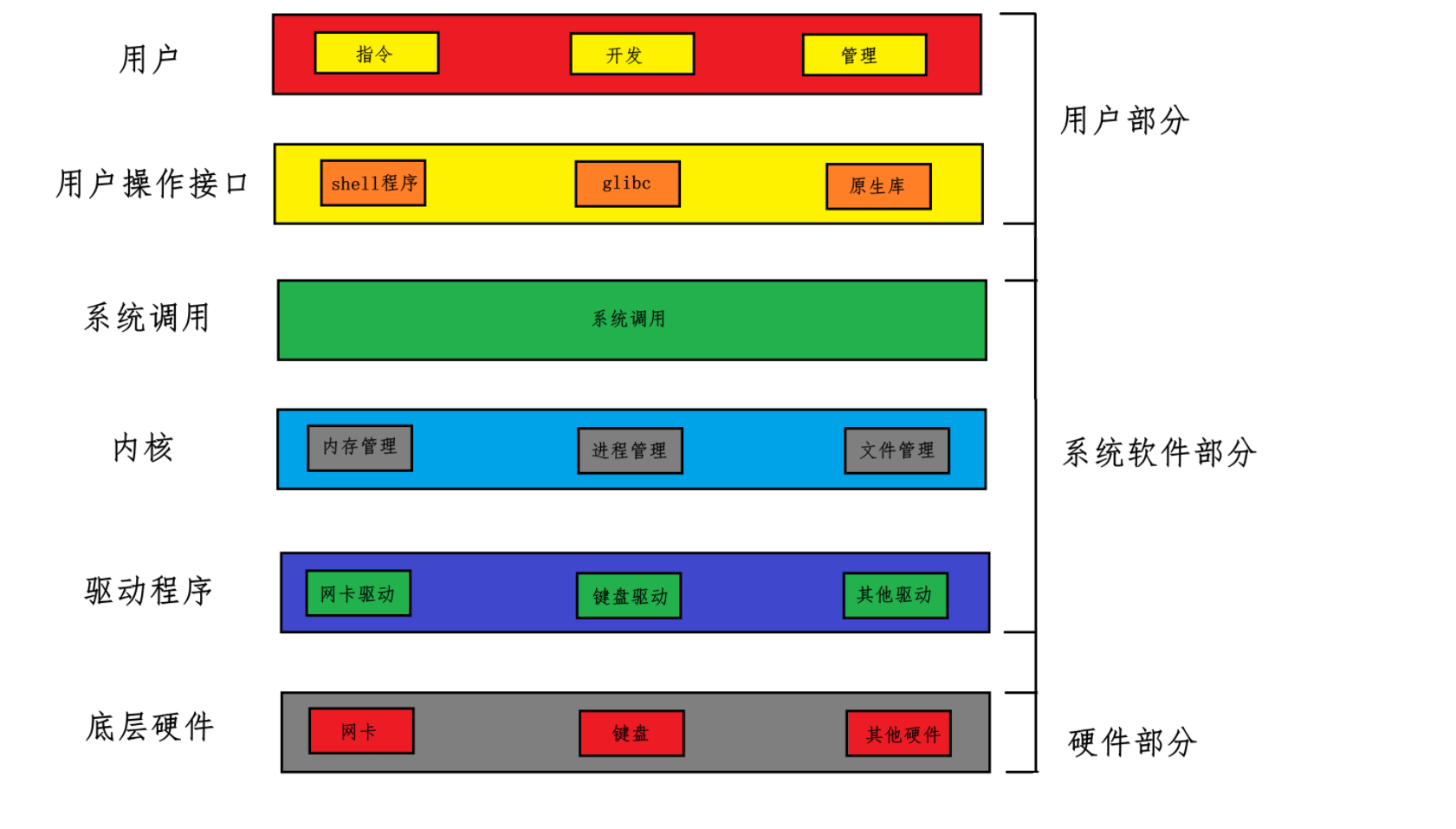
所以从这张图就可以看出操作系统的目的 ,对上就是为用户(应用程序)提供一个良好的运行环境;对下呢,就是管理好所有的软硬件资源。
4) 操作系统核心功能
在计算机中,我们编程的目的就是使用各种硬件资源来满足我们的各种需求,比如 printf("hello world\n"),就是来使用显示器这个硬件资源来满足打印 "hello world\n" 这个字符串的需求。但是各种硬件资源都是有限的,所以我们就需要一款软件来管理好各种软硬件资源,而这一软件就是操作系统。所以操作系统的核心功能就是管理软硬件资源。
如何理解管理:
在这里呢我们先举个例子来理解一下如何进行管理。假设你是一位即将要毕业的大学生,你准备好了自己的简历要去找工作了。首先你会去心仪的公司官网去投递自己的简历,但是不只有你一个即将毕业的大学生想去这一家公司,很多大学生都向该公司发了自己的简历。之后公司收到了你们的简历之后,就开始查看你们的简历,如果公司看上你的简历,就会安排给你进行笔试和面试,等笔试和面试结束之后,你就进入了这家你心仪的公司。在你找工作的整个过程中,你的简历描述了你整个人的信息。在公司查看简历的过程中,你被查看时,并不是你本人被查看了,而是描述你信息的简历被查看了;在等待被查看的过程中,也不是你本人在排队,而是描述你信息的简历在排队。所以在公司管理你们的过程中,是通过管理描述你们的简历从而管理到你们的。
如果公司将你们的信息录入相关的面试系统,那么为了管理描述你们的简历,就必须先创建一个结构体,这个结构体里面包括了你们的各种信息,包括姓名、年龄、性别、工作经历等等。所以公司管理你们,并不是管理你们本人,而是通过管理这些描述你们信息的结构体,进而就可以达到管理你们的目的。
如果这些描述你们信息的结构毫无顺序、毫无章法的放在一起,如果一个人的信息不满足该公司的要求,要将他从面试系统中删去,就需要先找到描述这个人的结构体,然后删去。但是如果又有一个人不满足要求,依然要从头找起,这样会比较麻烦。所以面试公司就采用了一个双链表的结构将描述你们信息的结构体链接起来,如果一个人不满足条件,只要删除双链表中的对应节点即可;如果后面又有一个新的简历,只需要为该简历创建对应的结构体,然后再将该结构体插入进双链表即可。从此,公司对你们的管理就转变成了双链表的增删查改,这也就是管理的本质 -- 先描述,再组织。
所以通过上面那个例子,管理其实就是为某个事物创建描述其信息的结构体,然后再为该结构体使用一定的数据结构,比如双链表将之组织起来,这样对一个事物的管理,就转变成了对一个数据结构的增删查改。与之类似,操作系统管理软硬件资源也是如此的。比如操作系统管理进程这个事物,也是通过先创建进程的描述结构体,然后再通过双链表等数据结构将其组织起来,这样就完成了对进程的管理。
5) 系统调用与库函数
(1) 系统调用
之前我们讲解过,为了防止用户直接访问内核,程序员对内核进行了封装,只留着一些接口对内核进行访问,这些接口就称为系统调用 。所以系统调用本质上就是一些函数 ,只不过这些函数使用来访问内核的。所以用户要想与操作系统 (这里指狭义的操作系统 -- 内核,以后如果不特指,操作系统就是指内核)进行交互,就只能通过系统调用。
之前在学习 man 命令时,我们说 2 号手册就是系统调用:
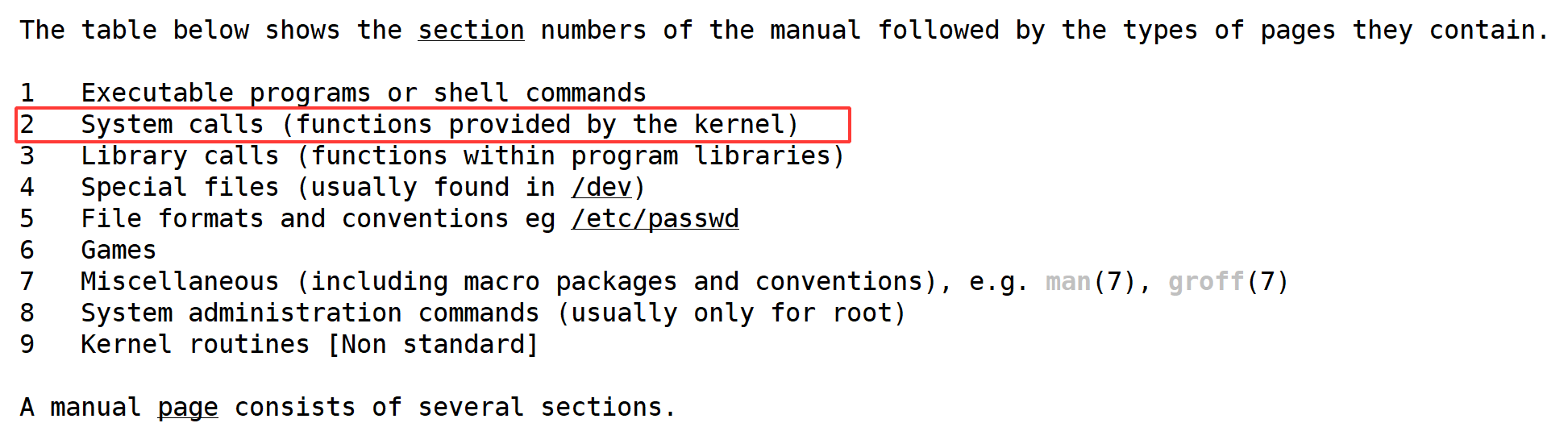
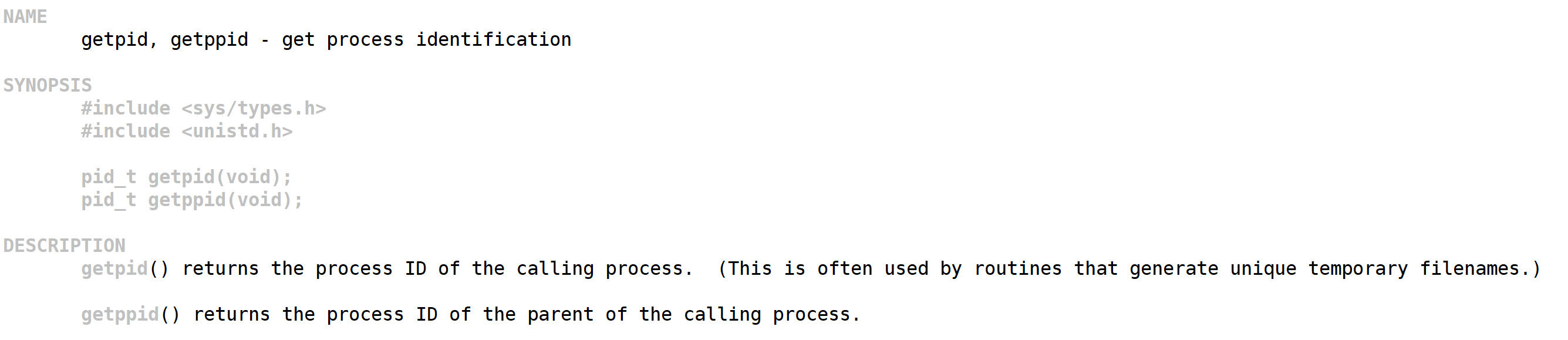
所以以后想要查看系统调用,我们就可以通过 man 2 具体函数 来进行查看系统调用,比如查看 getpid 这个系统调用:

从这个手册我们可以很清楚的看出 getpid 是返回当前进程的 ID,需要包含的头文件为 sys/types.h 与 unistd.h。
(2) 库函数
每个库函数都是跟硬件功能相关的,比如 printf 关联的就是显示器这一硬件,scanf 关联的就是键盘这一硬件。而软硬件的管理者又是操作系统,所以库函数要想接触底部硬件,就必须经过操作系统,而与操作系统交互又只能通过系统调用,所以每个库函数底层必然是封装了系统调用。但是每个操作系统的系统调用又是不同的,所以开发者为了降低用户的使用成本,就会使用一些函数来各个操作系统的系统调用;在上层用户使用的都是一样的库函数,但是在底层其实对于不同的操作系统其调用了不同的系统调用。比如 printf 函数,在上层不管是对于哪个操作系统始终都是 printf("%d\n", a),但是在 Linux 和 Windows 下如果想要通过系统调用完成这一功能,就必须使用不同的系统调用来完成这一功能。所以库函数的存在大大降低了用户的使用成本,方便用户进行二次开发。
3 进程的概念
操作系统学科对于进程定义为:程序的一个执行实例,正在执行的程序等等。实际上我们在 windows 的任务管理器中也可以看到进程:
当你在 windows 桌面上双击一个快捷方式,也就是执行一个可执行程序,那么该可执行程序就变成了一个进程。但是这样理解进程还是太抽象了,接下来我们就讲解进程到底是由什么构成的。
在操作系统管理小节我们说过,管理的本质就是先描述,再组织。操作系统管理进程也是一样的,首先需要一个结构体来描述一个进程,再通过一定的数据结构将该结构体组织起来,就完成了对进程的管理。
1) 描述进程 -- PCB
在操作系统学科里,描述一个进程的数据结构叫做 process control block,翻译过来就是控制块,简称为 PCB。PCB 中包括了对于一个进程的各种属性,所以 PCB 其实就是一个进程属性的集合。
Linux 的 PCB -- task_struct
任何一个操作系统描述进程的结构体都叫做 PCB,而在 Linux 操作系统下的 PCB 叫做 task_struct:
cpp
//Linux 2.6.18 版本内核中 task_struct
struct task_struct {
volatile long state; /* -1 unrunnable, 0 runnable, >0 stopped */
struct thread_info *thread_info;
atomic_t usage;
unsigned long flags; /* per process flags, defined below */
unsigned long ptrace;
int lock_depth; /* BKL lock depth */
#ifdef CONFIG_SMP
#ifdef __ARCH_WANT_UNLOCKED_CTXSW
int oncpu;
#endif
#endif
int load_weight; /* for niceness load balancing purposes */
int prio, static_prio, normal_prio;
struct list_head run_list;
struct prio_array *array;
unsigned short ioprio;
unsigned int btrace_seq;
unsigned long sleep_avg;
unsigned long long timestamp, last_ran;
unsigned long long sched_time; /* sched_clock time spent running */
enum sleep_type sleep_type;
unsigned long policy;
cpumask_t cpus_allowed;
unsigned int time_slice, first_time_slice;
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info;
#endif
struct list_head tasks;
/*
* ptrace_list/ptrace_children forms the list of my children
* that were stolen by a ptracer.
*/
struct list_head ptrace_children;
struct list_head ptrace_list;
struct mm_struct *mm, *active_mm;
/* task state */
struct linux_binfmt *binfmt;
long exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
/* ??? */
unsigned long personality;
unsigned did_exec:1;
pid_t pid;
pid_t tgid;
/*
* pointers to (original) parent process, youngest child, younger sibling,
* older sibling, respectively. (p->father can be replaced with
* p->parent->pid)
*/
struct task_struct *real_parent; /* real parent process (when being debugged) */
struct task_struct *parent; /* parent process */
/*
* children/sibling forms the list of my children plus the
* tasks I'm ptracing.
*/
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid; /* CLONE_CHILD_SETTID */
int __user *clear_child_tid; /* CLONE_CHILD_CLEARTID */
unsigned long rt_priority;
cputime_t utime, stime;
unsigned long nvcsw, nivcsw; /* context switch counts */
struct timespec start_time;
/* mm fault and swap info: this can arguably be seen as either mm-specific or thread-specific */
unsigned long min_flt, maj_flt;
cputime_t it_prof_expires, it_virt_expires;
unsigned long long it_sched_expires;
struct list_head cpu_timers[3];
/* process credentials */
uid_t uid,euid,suid,fsuid;
gid_t gid,egid,sgid,fsgid;
struct group_info *group_info;
kernel_cap_t cap_effective, cap_inheritable, cap_permitted;
unsigned keep_capabilities:1;
struct user_struct *user;
#ifdef CONFIG_KEYS
struct key *request_key_auth; /* assumed request_key authority */
struct key *thread_keyring; /* keyring private to this thread */
unsigned char jit_keyring; /* default keyring to attach requested keys to */
#endif
int oomkilladj; /* OOM kill score adjustment (bit shift). */
char comm[TASK_COMM_LEN]; /* executable name excluding path
- access with [gs]et_task_comm (which lock
it with task_lock())
- initialized normally by flush_old_exec */
/* file system info */
int link_count, total_link_count;
/* ipc stuff */
struct sysv_sem sysvsem;
/* CPU-specific state of this task */
struct thread_struct thread;
/* filesystem information */
struct fs_struct *fs;
/* open file information */
struct files_struct *files;
/* namespace */
struct namespace *namespace;
/* signal handlers */
struct signal_struct *signal;
struct sighand_struct *sighand;
sigset_t blocked, real_blocked;
sigset_t saved_sigmask; /* To be restored with TIF_RESTORE_SIGMASK */
struct sigpending pending;
unsigned long sas_ss_sp;
size_t sas_ss_size;
int (*notifier)(void *priv);
void *notifier_data;
sigset_t *notifier_mask;
void *security;
struct audit_context *audit_context;
seccomp_t seccomp;
/* Thread group tracking */
u32 parent_exec_id;
u32 self_exec_id;
/* Protection of (de-)allocation: mm, files, fs, tty, keyrings */
spinlock_t alloc_lock;
/* Protection of the PI data structures: */
spinlock_t pi_lock;
#ifdef CONFIG_RT_MUTEXES
/* PI waiters blocked on a rt_mutex held by this task */
struct plist_head pi_waiters;
/* Deadlock detection and priority inheritance handling */
struct rt_mutex_waiter *pi_blocked_on;
#endif
#ifdef CONFIG_DEBUG_MUTEXES
/* mutex deadlock detection */
struct mutex_waiter *blocked_on;
#endif
#ifdef CONFIG_TRACE_IRQFLAGS
unsigned int irq_events;
int hardirqs_enabled;
unsigned long hardirq_enable_ip;
unsigned int hardirq_enable_event;
unsigned long hardirq_disable_ip;
unsigned int hardirq_disable_event;
int softirqs_enabled;
unsigned long softirq_disable_ip;
unsigned int softirq_disable_event;
unsigned long softirq_enable_ip;
unsigned int softirq_enable_event;
int hardirq_context;
int softirq_context;
#endif
#ifdef CONFIG_LOCKDEP
# define MAX_LOCK_DEPTH 30UL
u64 curr_chain_key;
int lockdep_depth;
struct held_lock held_locks[MAX_LOCK_DEPTH];
unsigned int lockdep_recursion;
#endif
/* journalling filesystem info */
void *journal_info;
/* VM state */
struct reclaim_state *reclaim_state;
struct backing_dev_info *backing_dev_info;
struct io_context *io_context;
unsigned long ptrace_message;
siginfo_t *last_siginfo; /* For ptrace use. */
/*
* current io wait handle: wait queue entry to use for io waits
* If this thread is processing aio, this points at the waitqueue
* inside the currently handled kiocb. It may be NULL (i.e. default
* to a stack based synchronous wait) if its doing sync IO.
*/
wait_queue_t *io_wait;
/* i/o counters(bytes read/written, #syscalls */
u64 rchar, wchar, syscr, syscw;
#if defined(CONFIG_BSD_PROCESS_ACCT)
u64 acct_rss_mem1; /* accumulated rss usage */
u64 acct_vm_mem1; /* accumulated virtual memory usage */
clock_t acct_stimexpd; /* clock_t-converted stime since last update */
#endif
#ifdef CONFIG_NUMA
struct mempolicy *mempolicy;
short il_next;
#endif
#ifdef CONFIG_CPUSETS
struct cpuset *cpuset;
nodemask_t mems_allowed;
int cpuset_mems_generation;
int cpuset_mem_spread_rotor;
#endif
struct robust_list_head __user *robust_list;
#ifdef CONFIG_COMPAT
struct compat_robust_list_head __user *compat_robust_list;
#endif
struct list_head pi_state_list;
struct futex_pi_state *pi_state_cache;
atomic_t fs_excl; /* holding fs exclusive resources */
struct rcu_head rcu;
/*
* cache last used pipe for splice
*/
struct pipe_inode_info *splice_pipe;
#ifdef CONFIG_TASK_DELAY_ACCT
struct task_delay_info *delays;
#endif
};上面的代码就是在内核中描述进程的 task_struct,包含了一个进程的各种属性:
(1)标识符,也就是结构体中的 pid_t pid 属性,pid_t 是一个 typedef 过的类型:


所以说到底,进程的 pid 也就是一个整数。该进程标识符是描述进程的唯一标识符,用来区分其他进程。
(2) 退出状态、退出码与退出信号,结构体中的 long exit_state,int exit_code 与 exit_signal 三个属性,描述了进程退出时的各种信息。
(3) 优先级,结构体中的 int prio 属性,用来标识相对于其他进程时的调度优先级。
(4) 上下文数据,2.6.18 版本的内核并不会直接将上下文数据保存在 task_struct 中,但是在以前的内核中,比如在 0.11 版本中,会在 task_struct 中存在一个 struct tss_struct tss 字段,该属性就是保存进程执行的上下文数据的。下面是 tss_struct 结构体的定义:
cpp
//保存上下文数据的结构体 -- tss_struct
struct tss_struct {
unsigned short back_link,__blh;
unsigned long esp0;
unsigned short ss0,__ss0h;
unsigned long esp1;
unsigned short ss1,__ss1h; /* ss1 is used to cache MSR_IA32_SYSENTER_CS */
unsigned long esp2;
unsigned short ss2,__ss2h;
unsigned long __cr3;
unsigned long eip;
unsigned long eflags;
unsigned long eax,ecx,edx,ebx;
unsigned long esp;
unsigned long ebp;
unsigned long esi;
unsigned long edi;
unsigned short es, __esh;
unsigned short cs, __csh;
unsigned short ss, __ssh;
unsigned short ds, __dsh;
unsigned short fs, __fsh;
unsigned short gs, __gsh;
unsigned short ldt, __ldth;
unsigned short trace, io_bitmap_base;
/*
* The extra 1 is there because the CPU will access an
* additional byte beyond the end of the IO permission
* bitmap. The extra byte must be all 1 bits, and must
* be within the limit.
*/
unsigned long io_bitmap[IO_BITMAP_LONGS + 1];
/*
* Cache the current maximum and the last task that used the bitmap:
*/
unsigned long io_bitmap_max;
struct thread_struct *io_bitmap_owner;
/*
* pads the TSS to be cacheline-aligned (size is 0x100)
*/
unsigned long __cacheline_filler[35];
/*
* .. and then another 0x100 bytes for emergency kernel stack
*/
unsigned long stack[64];
}那么什么是上下文数据呢?实际上,在操作系统内并不只会存在一个进程,但是 cpu 等硬件只会有一套,不可能同时执行所有进程;所以为了让每个进程都能够被调度执行,操作系统并不会将一个进程执行完再执行下一个进程,而是在一个进程执行了一定的时间之后,就将该进程剥离下来,转而去调度执行其他进程;等一段时间之后,调度到上次执行的进程时,再去接着上次的程序接着执行该进程,但是想要继续执行该进程,就必须将 cpu 内部的寄存器等硬件的数据恢复才能继续执行,这时就用到了上下文数据。所以进程的上下文数据就是 cpu 中各个寄存器中的数据,等再次执行该进程时,就将寄存器内的数据恢复为上次执行的数据,这样就可以继续执行了。从上面的 tss_struct 结构体的定义中也可以看出来,其各个字段就是 cpu 中各个寄存器的名词,比如 esp、ebp 等。
(5)其他属性。在 task_struct 中还包含了除了上述属性外的其他属性,这里属性很多,就不要一 一 详述,以后用到一个属性时会进行详解。
所以一旦一个程序运行起来变成进程,操作系统为了管理它,就会为其创建与之匹配的 PCB,Linux 中会创建 task_struct。那么 cpu 执行该进程时就用到了进程自己的代码和数据。至此,我们就可以提出进程的概念,也就是进程的组成了:
进程 = PCB(task_struct) + 自己的代码和数据
当然进程的组成并不只是当前这三部分,后面还会进行扩展。
2) 组织进程 -- 双链表
前面讲解了描述一个进程的结构体 task_struct,那么操作系统为了管理进程,还需要将其组织起来,而在操作系统中就用到了双链表。
虽然在 task_struct 中并没有 struct task_struct *next, *prev 属性,但是在 task_struct 中存在这么一个属性:struct list_head tasks,而 struct list_head 的定义是:
cpp
struct list_head {
struct list_head *next, *prev;
};所以其实 task_strcut 的组织方式是这样的:
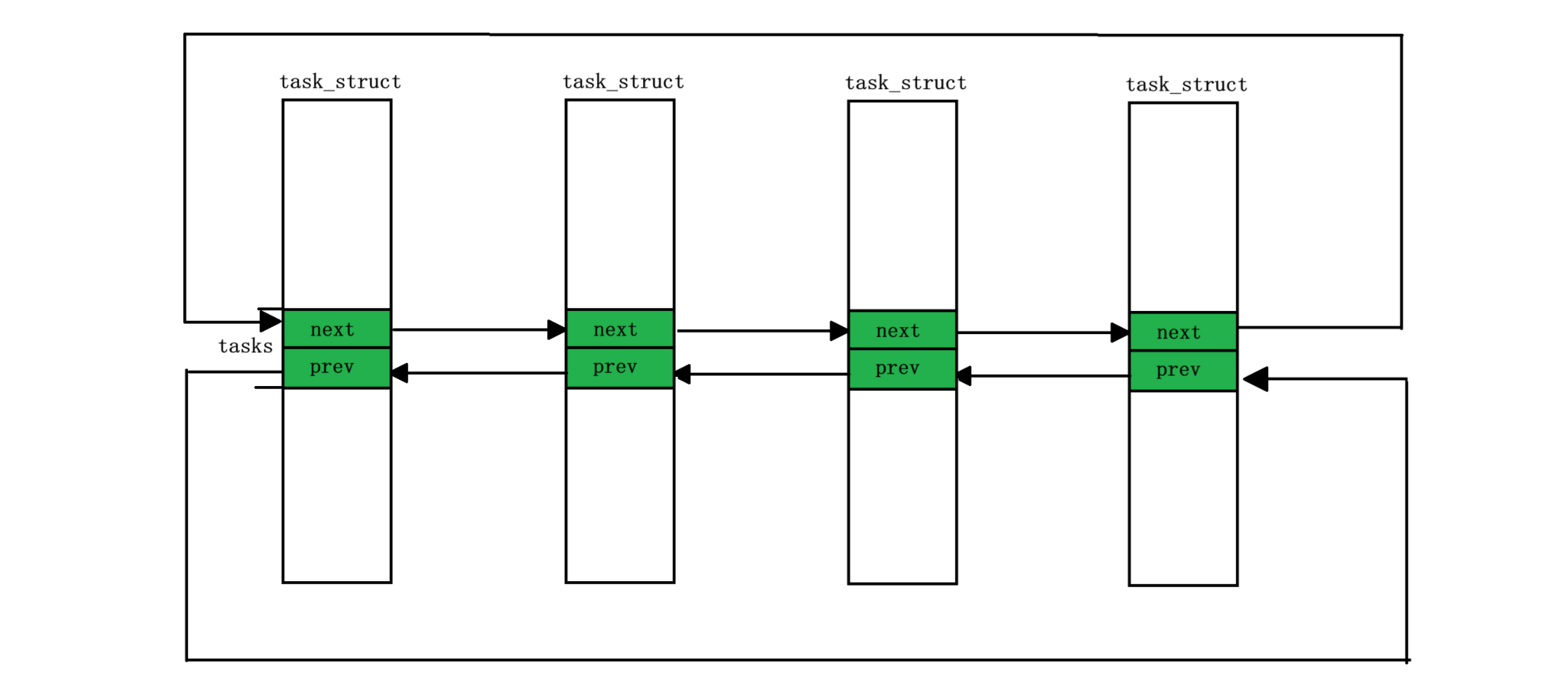
是通过 task_struct 中的 list_head 模块链接在一起的,那么这样链接在一起只能找到下一个 task_struct 的 next 和 prev 啊,怎么找到下一个 task_struct 的其他属性呢?
在 C 语言中我们学过,一个数组或者一个结构体的地址,其实就是其第一个元素或者成员的地址,比如下面这段代码:
cpp
#include <stdio.h>
struct A
{
int _a1;
char _a2;
};
int main()
{
struct A a;
a._a1 = 1;
a._a2 = 'a';
printf("&struct A: %p, _a1: %p\n", &a, &(a._a1));
return 0;
}运行结果:
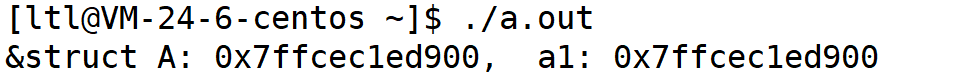
而结构体中的一个成员的地址就是结构体变量的地址 + 该成员在结构体中的偏移量:
cpp
#include <stdio.h>
struct A
{
int _a1;
char _a2;
};
int main()
{
struct A a;
a._a1 = 1;
a._a2 = 'a';
printf("&struct A: %p, _a2: %p, 偏移量: %d\n", &a, &(a._a2), (&(a._a2) - (char*)&a));
return 0;
}运行结果:

所以呢,我们只需要用结构体中的一个成员地址减去其在结构体中的偏移量,就可以找到整个结构体的地址,进而就可以访问结构体内部的成员了。使用 tasks 成员得出 task_struct 的地址的方式为:
cpp
&task_struct = &tasks - &((struct task_struct*)0->tasks)其中后面的 &((struct task_struct*)0->tasks) 就是将 0 位置强转为地址,取出其中的 tasks 成员的地址,那么这部分不就相当于 tasks 在 task_struct 中的偏移量嘛,所以在用 tasks 的地址减去其偏移量,那么就可以得出 task_struct 的地址了。
所以在内核中,进程就可以使用双链表管理起来了。结合我们上面关于管理的例子,操作系统在管理进程时,并不是在管理进程本身,而是在管理进程的 PCB,对进程的管理也就转变为了对双链表这个数据结构的增删查改;进程在等待调度执行排队时。并不是进程本身在排队,而是描述进程的 PCB 在进程排队;一个进程调度结束,要被剥离,也就是从一个队列数据结构将一个 task_struct 节点拿走,放入新的队列数据结构而已。
当然进程中并不仅仅只有双链表这一个数据结构来管理进程,还会有树等数据结构来帮助进行管理。
3) 查看进程
(1) 通过 proc 目录来查看进程
我们可以通过**/proc** 目录下查看各个进程:

在 /proc 目录下有很多数字,这些数字就是进程的 pid,如果我们使用 ls -l 命令查看一个进程的具体信息我们会得到:
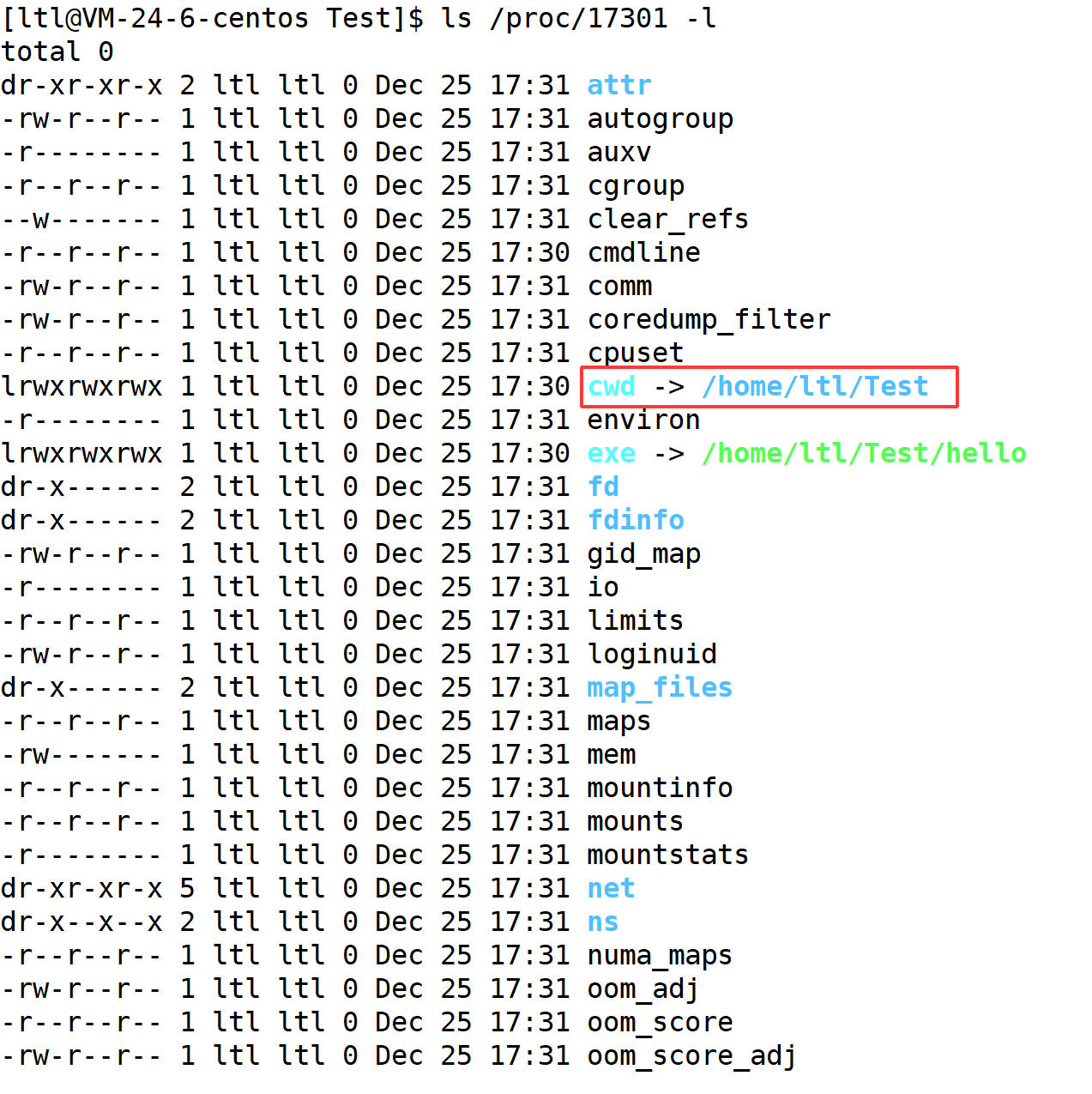
在这里面有一个比较重要的信息就是cwd,也就是current work directory的简称,也就是当前路径的意思,其会记录下一个路径,而这个路径就是我们之前在 C 语言阶段使用文件接口默认新建文件的路径。比如我们写了这么一句代码:FILE* fp = fopen("log.txt", "w"),我们如果只写一个文件名,其新建的文件其实会与 cwd 路径拼成 /home/ltl/Test/log.txt,这样就形成了完整的路径:
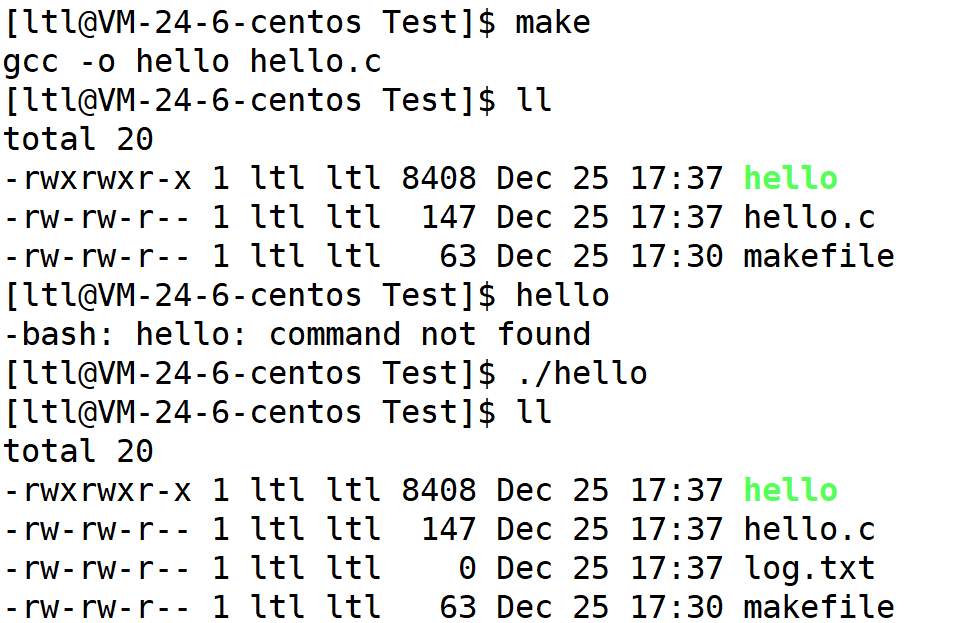
那么如果我们把 cwd 改了,那么新建的文件也就新建在 cwd 目录下了。我们可以通过 chdir 系统调用****来更改进程的当前路径:
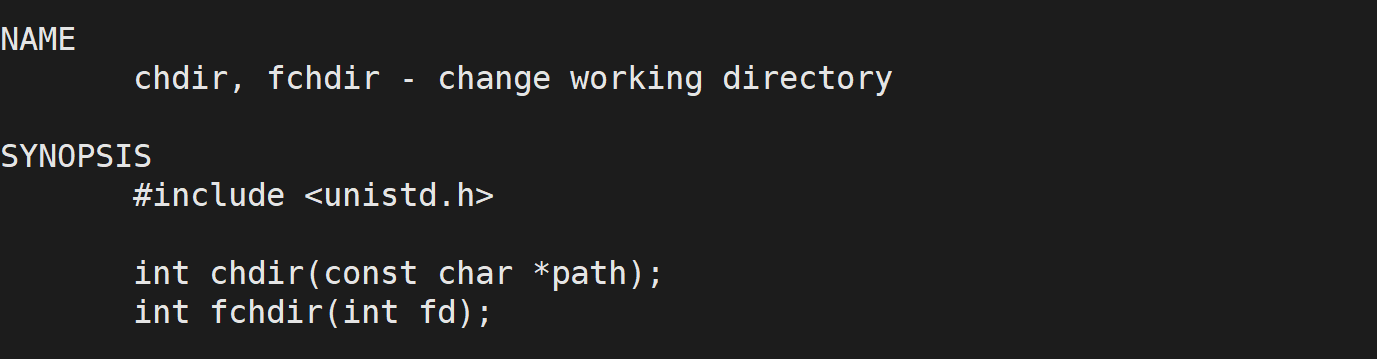

chdir 是一个系统调用,参数就是你想要将 cwd 更改为哪个路径,如果成功,返回 0,失败返回 -1。
所以我们首先通过 chdir 修改当前路径,然后再执行上面那段代码,看看文件会新建到哪里:
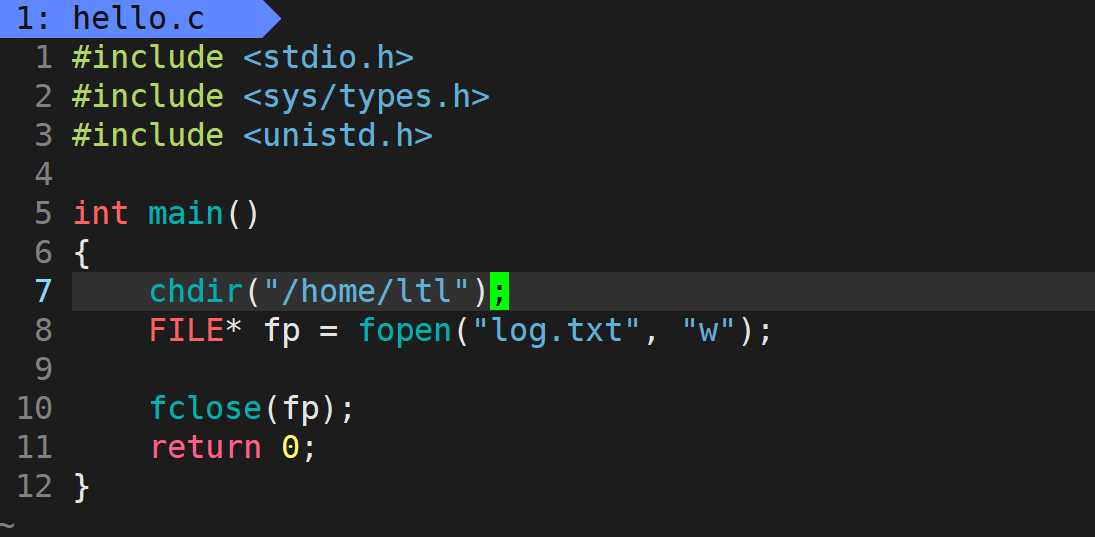
/home/ltl:
/home/ltl/Test:
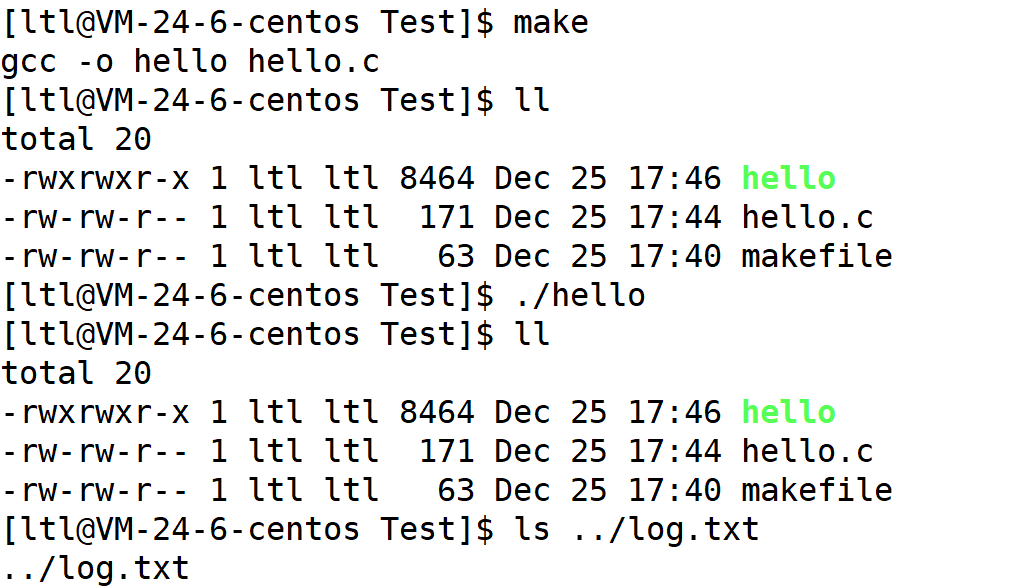
可以看到更改目录之后,并不会在当前目录下新建,而是在上级目录下新建了。
(2) 通过 ps axj 命令查看
我们也可以通过 ps axj命令来查看:

在 Linux 中如果想要同时输入多条命令,可以用 && 或者 ; 连接。
通过上述代码,我们确实看到了正在运行的进程 ./hello,同时显示了其 pid,但是为什么还存在一个 grep --color=auto hello 进程呢?这是因为每个命令其实就是一个二进制程序,你在使用了 grep 命令之后,也就相当于 grep 命令的二进制程序也变成了一个进程,所以就会多出一个 grep 进程。
4) 使用系统调用获取进程 pid、ppid 与 创建子进程
(1) 获取 pid 与 ppid
获取进程 pid 与 ppid 的系统调用叫做 getpid 与 getppid:
getpid 与 getppid 直接返回进程的 pid 与其父进程的 pid。
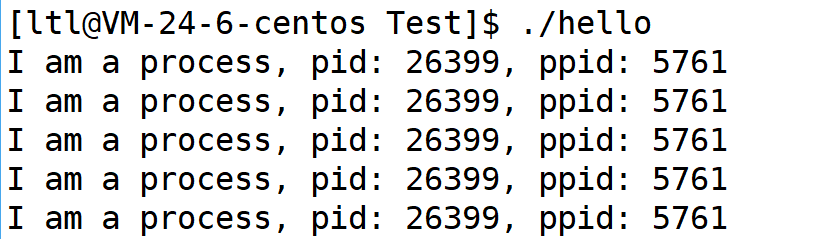

我们通过 getppid 的方式获取了进程的父进程的 pid,那么 ./hello 的父进程是谁呢?
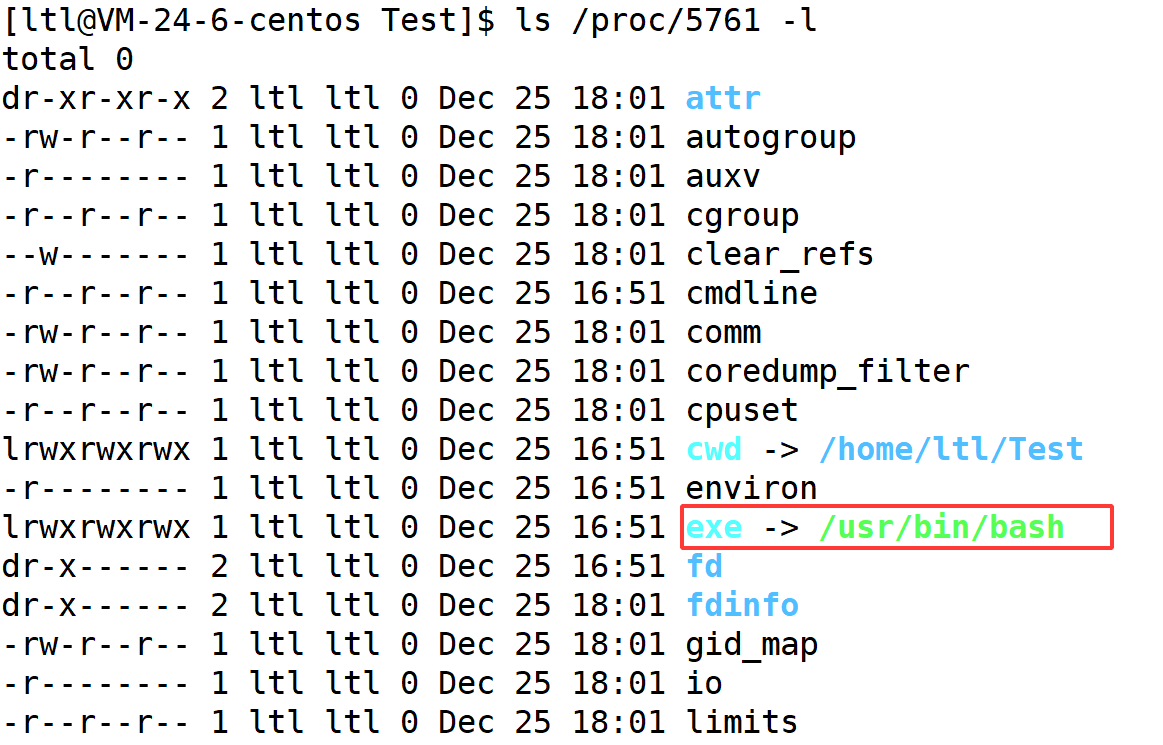
通过上图呢我们可以发现,./hello 的父进程正是 Linux 系统的命令行解释器 bash。实际上在 Linux 操作系统中,增多进程是因为父进程创建子进程的方式实现的;而在命令行中,启动命令或者程序时,其都会变成一个进程,而该进程的父进程正是 bash 进程。所以我们所写的一切代码都是通过 bash 创建子进程的方式来执行我们的代码的。
(2) 通过 fork 系统调用来创建子进程
在 Linux 系统中,创建子进程的系统调用名称为 fork:


fork 需要包含的头文件为 unistd.h,返回值比较特殊,fork 执行之后,如果创建成功,会给父进程返回子进程的 pid,给子进程返回 0;如果创建失败,会返回 -1。
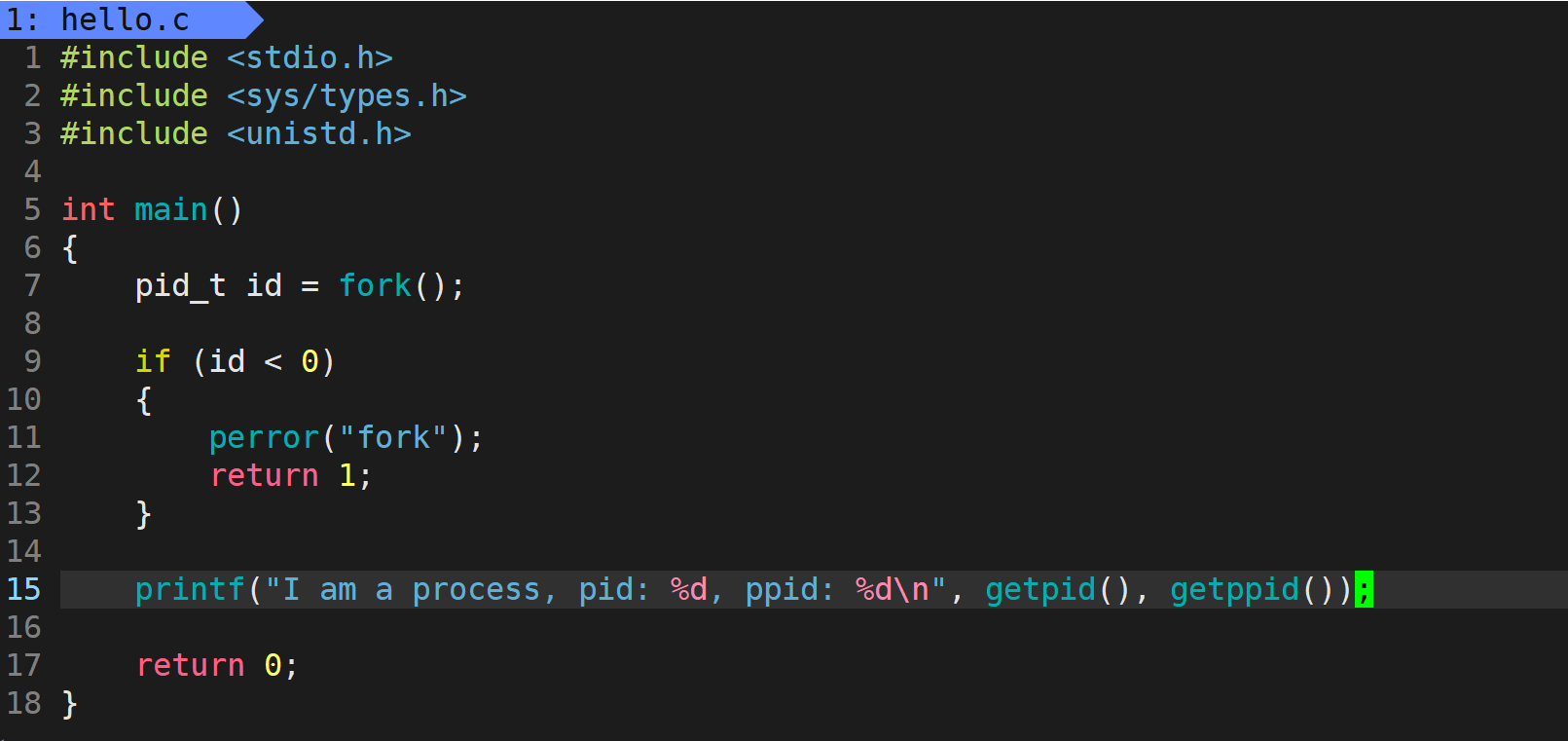

在 fork 之后,当前进程会创建一个子进程,当前进程就成为了子进程的父进程;而且在 fork 之后,父子进程的代码和数据是共享的。
上面的代码只是展示 fork 的效果,真正的用法是要使用 if 来进行分流,让父子进程执行不同的动作:
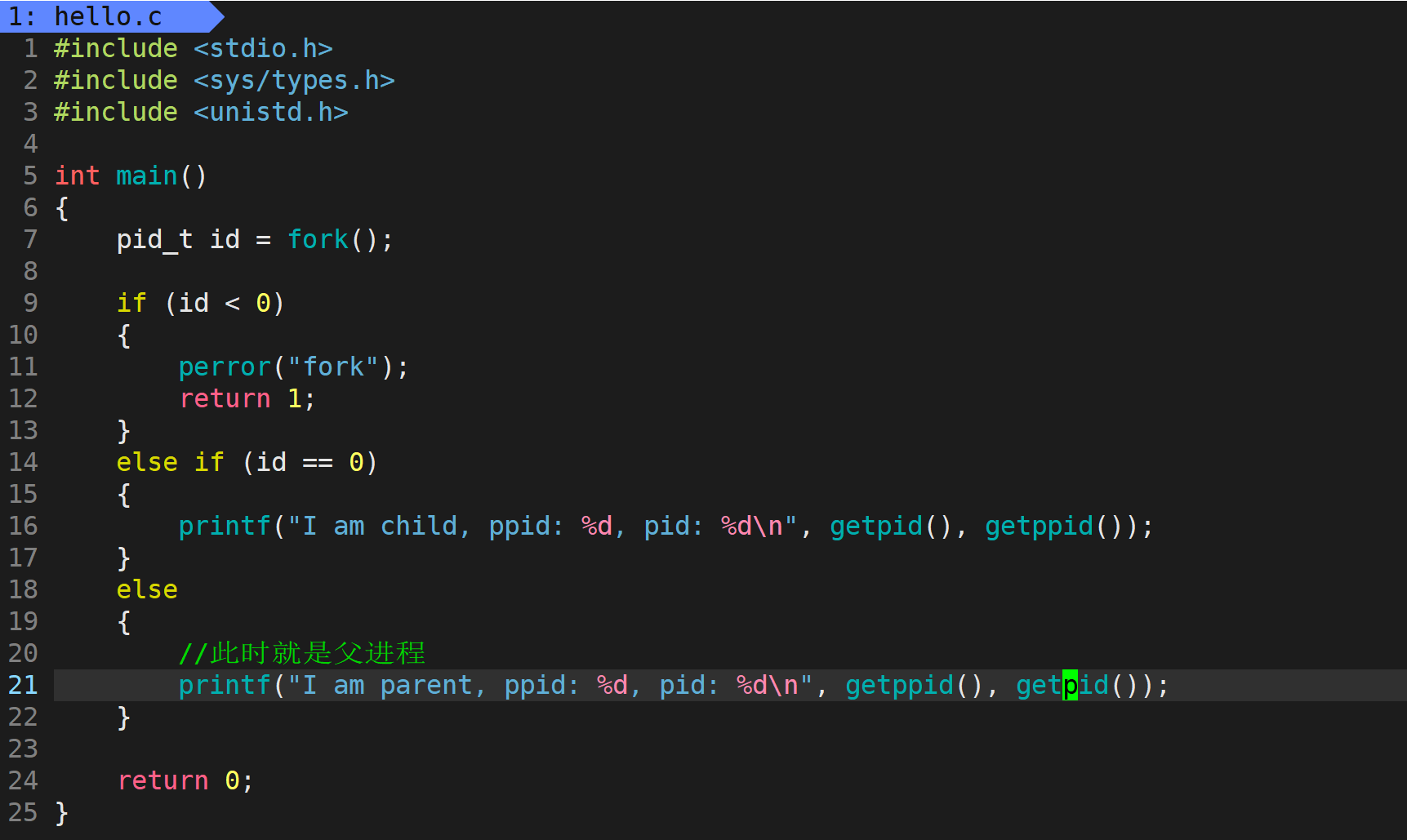

到这里就会产生几个问题:
问题1:fork 为什么要给父进程返回子进程 pid
问题2:fork 函数是怎么返回多个值的
问题3:一个变量 id 怎么会有多个值
接下来我们来一一解答。
问题1:在操作系统中,父子进程并不是一一对应的关系,父进程与子进程是 1:n 的关系,一个父进程会拥有多个子进程,所以父进程就需要控制子进程,比如需要知道子进程任务完成的怎么样,它的退出码是什么。所以给父进程返回子进程 pid,就可以让父进程来控制子进程了。
问题2:进程在 fork 之后代码和数据默认是共享的,所以在 fork 执行 return 语句之前,子进程已经被创建了,此时会被分解为两个执行流,一个是父进程的执行流,一个是子进程的执行流。所以看起来是返回了多个值,其实是给父子进程各自返回了一个值,也就是 return 语句在父进程与子进程的执行流各自返回了一次,也就是产生了返回多个值的现象。
问题3:我们可以在这里打印一下 id 的地址
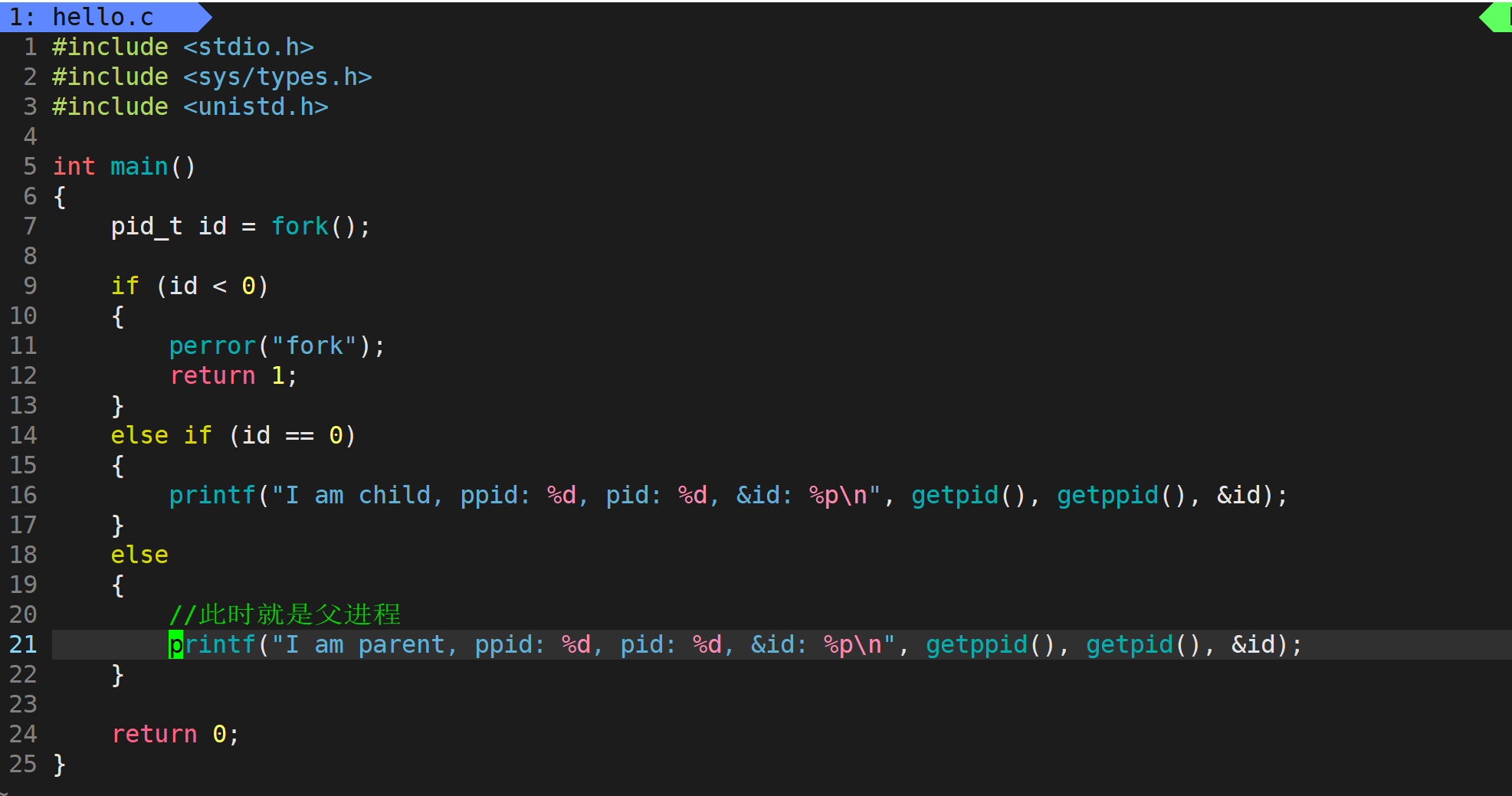

可以看到 id 的地址都是一样的,但是 id 的值确实不同的,所以这里的地址不可能是物理地址,因为如果时真实的物理地址,一个内存空间里是不可能有两个不同的值的。至于这里 id 一个变量会有多个不同的值,需要等讲解完虚拟地址空间之后再进行解答。
4 总结
本篇文章从冯诺依曼和操作系统概述入手,讲解了管理的本质是先描述,再组织。之后讲解了进程的概念:进程 = PCB + 自己的代码和数据,而在 Linux 操作系统中的 PCB 为 task_struct 结构体。操作系统管理进程就是通过 PCB 来描述进程,再通过双链表将他们组织起来。最后还讲解了 chdir、getpid、getppid、fork 四个系统调用。