文章目录
问题描述
在使用阿里云MaxCompute查询sql时发现sql正常查询并返回数据,但是查看日志时发现有报错信息:
js
2025-10-16 20:16:44.907 ERROR 36832 --- [io-10111-exec-3] c.a.d.pool.DruidPooledPreparedStatement : getMaxFieldSize error
java.sql.SQLFeatureNotSupportedException: null
at com.aliyun.odps.jdbc.OdpsStatement.getMaxFieldSize(OdpsStatement.java:438)
at com.alibaba.druid.filter.FilterChainImpl.statement_getMaxFieldSize(FilterChainImpl.java:2915)
at com.alibaba.druid.filter.FilterAdapter.statement_getMaxFieldSize(FilterAdapter.java:2562)
at com.alibaba.druid.filter.FilterChainImpl.statement_getMaxFieldSize(FilterChainImpl.java:2913)
at com.alibaba.druid.proxy.jdbc.StatementProxyImpl.getMaxFieldSize(StatementProxyImpl.java:317)
at com.alibaba.druid.pool.DruidPooledPreparedStatement.<init>(DruidPooledPreparedStatement.java:80)
at com.alibaba.druid.pool.DruidPooledConnection.prepareStatement(DruidPooledConnection.java:359)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
...解决方法
先说我这里的解决方法,将配置文件数据源配置中的spring.datasource.dynamic.druid.pool-prepared-statements和max-pool-prepared-statement-per-connection-size注释掉,因为pool-prepared-statements默认为false,所以在启动项目调用接口就可以看到没有报错了。
js
spring:
datasource:
primary: lake
dynamic: #动态数据源配置
druid:
max-active: 50
initial-size: 2
max-wait: 600000
min-idle: 2
# pool-prepared-statements: true
# max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
validation-query: select 1 #也会对数据湖查询检查
test-while-idle: true
test-on-borrow: true
test-on-return: false
filters: stat
connectionProperties: druid.stat.mergeSql=true
datasource:
lake:
driverClassName: com.aliyun.odps.jdbc.OdpsDriver
url: jdbc:odps:https://xxx.maxcompute.aliyun-inc.com/api?project=xxx&accessId=xxx&accessKey=xxx&interactiveMode=true&autoSelectLimit=1000000
druid:
validation-query:我这里使用的是mybatis-plus的多数据源,如果不想影响到其他的数据源,也可以单独配置
js
spring:
datasource:
primary: lake
dynamic: #动态数据源配置
druid:
max-active: 50
initial-size: 2
max-wait: 600000
min-idle: 2
pool-prepared-statements: true
max-pool-prepared-statement-per-connection-size: 20
time-between-eviction-runs-millis: 60000
min-evictable-idle-time-millis: 300000
validation-query: select 1 #也会对数据湖查询检查
test-while-idle: true
test-on-borrow: true
test-on-return: false
filters: stat
connectionProperties: druid.stat.mergeSql=true
datasource:
lake:
driverClassName: com.aliyun.odps.jdbc.OdpsDriver
url: jdbc:odps:https://xxx.maxcompute.aliyun-inc.com/api?project=xxx&accessId=xxx&accessKey=xxx&interactiveMode=true&autoSelectLimit=1000000
druid:
#数据湖不做查询检测
validation-query:
# 关闭预编译语句池化,只针对lake数据源
pool-prepared-statements: false
max-pool-prepared-statement-per-connection-size: 0解决思路
回到报错日志
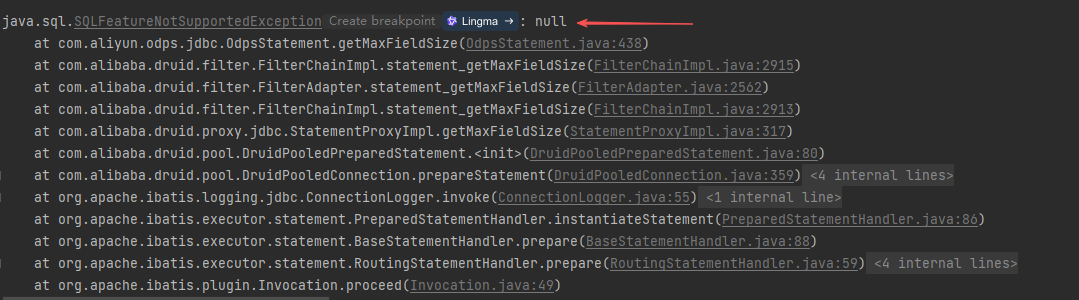
点击com.aliyun.odps.jdbc.OdpsStatement.getMaxFieldSize(OdpsStatement.java:438),可以看到OdpsStatement类实现Statement接口,但是重写接口中的getMaxFieldSize()时是直接抛出一个异常。这里就可以想到,只要让程序在执行时不走这个方法即可。
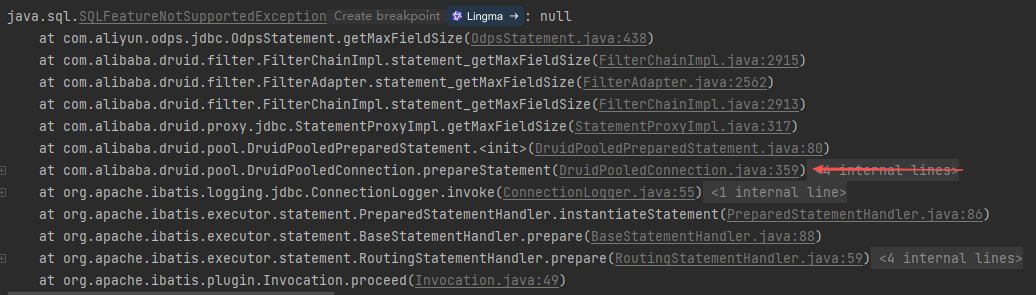
继续向上追,进入com.alibaba.druid.pool.DruidPooledConnection.prepareStatement(DruidPooledConnection.java:359)。可以看到com.alibaba.druid.pool.DruidPooledConnection#prepareStatement(java.lang.String)这个方法是重写了java.sql.Connection#prepareStatement(java.lang.String)。
而 DruidPooledConnection 是阿里巴巴 Druid 数据库连接池框架中的核心接口,因此在配置文件中寻找,将prepareStatement相关的两个配置注释,执行代码时可以发现不会报错了。
继续向上追,最后会发现在com.alibaba.druid.pool.DruidPooledPreparedStatement#DruidPooledPreparedStatement中
java
public class DruidPooledPreparedStatement extends DruidPooledStatement implements PreparedStatement {
...
private boolean pooled = false;
public DruidPooledPreparedStatement(DruidPooledConnection conn, PreparedStatementHolder holder) throws SQLException{
...
pooled = conn.getConnectionHolder().isPoolPreparedStatements();
// Remember the defaults
//当spring.datasource.dynamic.datasource.ics-datalake.druid.pool-prepared-statements=false时不走预编译的相关代码,从而解决执行代码报错问题
if (pooled) {
try {
defaultMaxFieldSize = stmt.getMaxFieldSize();
} catch (SQLException e) {
LOG.error("getMaxFieldSize error", e);
}
...
}
...
}