目录标题:
-
- 一、为什么我会去报课程
- 二、课程里学到的核心逻辑
- 三、实践操作
-
- 1.Docker环境准备
- 2.Python环境配置
-
- 2.1安装Miniconda
- 2.2加载conda环境
- [2.3创建Python 3.10环境](#2.3创建Python 3.10环境)
- 3.安装PyTorch与昇腾支持
-
- [3.1安装PyTorch 2.5.1](#3.1安装PyTorch 2.5.1)
- 3.2安装torch-npu
- 4.编译安装Apex
-
- [4.1 版本检查](#4.1 版本检查)
- [4.2 克隆源码](#4.2 克隆源码)
- [4.3 编译](#4.3 编译)
- [4.4 安装](#4.4 安装)
- 四、模型部署完整流程
- 五、社区论坛的实际帮助
- 六、几点实用建议
-
- 1.版本匹配是硬性要求
- 2.先跑通再优化
- [3. 社区论坛:开发者的技术支持与经验宝库](#3. 社区论坛:开发者的技术支持与经验宝库)
- 4.博客写作驱动知识深化
- 总结
一、为什么我会去报课程
今年五月份刷昇腾社区,看到首页推了个"MindSpeed LLM基于Qwen2.5-7B的开发实践"课程。我当时想法挺简单:反正是免费的,正好了解下国产AI芯片生态是什么样。

报名后发现这个课程不是那种纯理论课程,而是真刀真枪地带你从零搭环境、转模型、跑训练。课程内容包括深度学习基础、Transformer结构、模型适配、LoRA微调这几大块,还配了在线实验环境,可以直接在浏览器里敲代码。
我跟着课程把Qwen2.5-7B的完整流程过了一遍,然后想着:能不能在本地昇腾310系列上把这套东西复现出来?于是就有了后面这一堆实操记录。
二、课程里学到的核心逻辑
1.理解昇腾的计算架构
课程第一章讲深度学习原理,老实说我快进了不少------反向传播、梯度下降这些东西早就熟了。但有一段讲"昇腾NPU的矩阵计算单元"我反复看了几遍。
原来NPU和GPU的底层架构差异挺大的。GPU是大量小核心并行,NPU是专门的矩阵运算单元(Cube单元)。这直接影响了算子的实现方式,比如Attention机制在NPU上有硬件加速,但输入shape必须符合特定要求,否则会fallback到通用算子,性能直接腰斩。
这个知识点在后面做模型优化时特别有用。
2.模型转换的底层逻辑
课程第四章专门讲了Qwen2.5-7B的权重转换。HuggingFace格式转Megatron格式不是简单的文件拷贝,而是要重新组织权重的存储结构,适配分布式训练的张量并行策略。
课程里给的转换脚本ckpt_convert_qwen25_hf2mcore.sh可以直接用,但我看了下脚本内容,核心是调用了MindSpeed-LLM的权重映射工具,把attention层的Q、K、V权重按照TP(Tensor Parallel)切分策略重新排列。
这个原理搞明白后,后面遇到其他模型的转换就知道怎么改脚本了。
3.数据预处理的格式要求
课程提供的Orz Math数据集预处理流程很完整:原始JSON数据 → 分词 → 生成二进制索引文件。这个流程在课程里跑一遍很顺利,但实际操作时我发现有几个细节必须注意:
- 词表文件路径必须和模型的tokenizer路径一致
- 预处理时的
max_seq_length要和训练配置里的值匹配 - 生成的
.bin和.idx文件必须放在指定目录,不能随便改路径
这些细节在官方文档里不会特别强调,但课程的实验环节会明确指出来。
三、实践操作
看完课程,我决定在本地昇腾310系列上完整复现一遍。课程用的是在线环境,本地就得自己从Docker搞起。
对于手头暂时没有硬件,或者不想在配置环境上耗费太多精力的朋友,可以参考社区正在进行的【昇腾发烧友公测活动】。社区专门提供了在线环境,报名审核通过后,你就可以沉浸式体验算子、推理开发场景,直接在云端环境里实操,省去了本地部署的繁琐:https://www.hiascend.com/developer/activities/details/5407e39722d04d319cf6cf1117f39341#tab0
1.Docker环境准备
1.1拉取镜像
昇腾社区提供了适配不同架构的CANN镜像,我这边是ARM服务器,所以选了arm64版本:
plain
docker pull --platform=arm64 swr.cn-south-1.myhuaweicloud.com/ascendhub/cann:8.3.rc2-310-ubuntu22.04-py3.11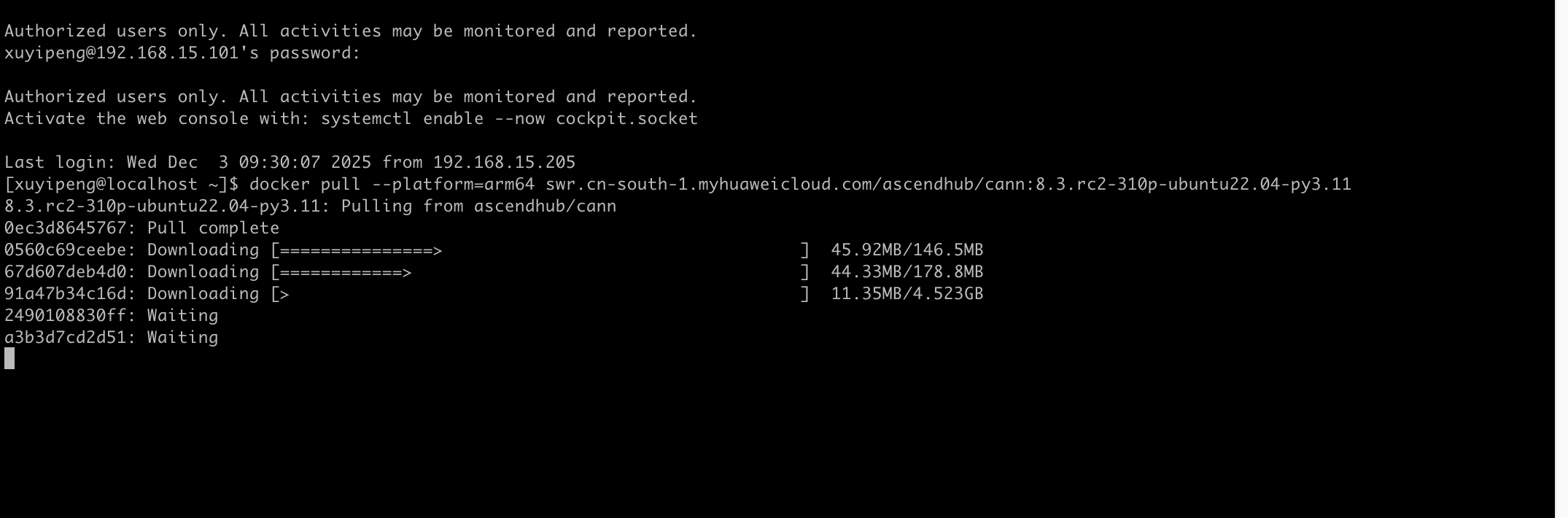
拉取完成后用docker images查看实际镜像ID,这个ID后面创建容器时要用。
1.2创建容器
这里有个小问题:我一开始直接用Digest值创建容器,结果Docker报"No such image"。后来才发现要用docker images查出来的实际ID。
还有个坑是容器创建后会直接退出。解决办法是在启动命令里加上tail -f /dev/null保持进程运行:
plain
docker run -it -d --net=host --shm-size=1g \
--privileged \
--name xyp1 \
--device=/dev/davinci_manager \
--device=/dev/hisi_hdc \
--device=/dev/devmm_svm \
-v /usr/local/Ascend/driver:/usr/local/Ascend/driver:ro \
-v /usr/local/sbin:/usr/local/sbin:ro \
-v /home/xuyipeng/weights:/path-to-weights:ro \
-v /home:/home \
66fa9b68edb9 \
bash -c "tail -f /dev/null"
创建成功后,执行docker ps | grep xyp1验证,终端显示容器状态为Up,说明容器已稳定运行。
1.3进入容器
plain
docker exec -it xyp1 bash进入容器后先装Miniconda,为后续Python环境做准备:
plain
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-aarch64.sh
2.Python环境配置
2.1安装Miniconda
执行安装脚本:
plain
bash Miniconda3-latest-Linux-aarch64.sh安装过程中有几个交互操作:
- 初始化conda时输入
yes - 安装路径直接回车用默认的
/root/miniconda3 - 询问是否自动配置环境变量时输入
yes
2.2加载conda环境
安装完成后直接运行conda会提示命令不存在,需要手动加载环境变量:
plain
source ~/.bashrc
conda --version
2.3创建Python 3.10环境
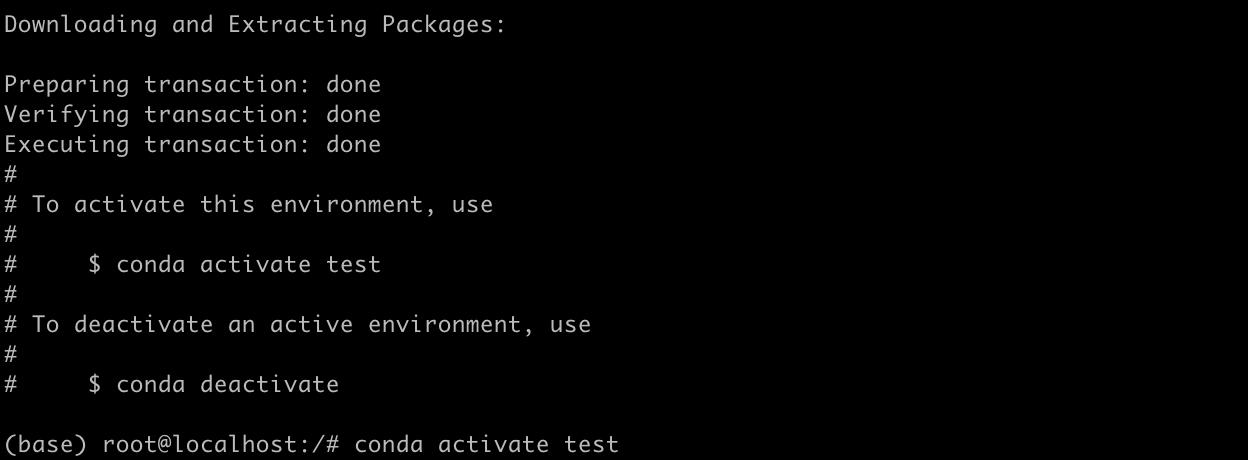
plain
conda create -n test python=3.10按提示输入a接受条款,输入y确认下载:
激活环境:
plain
conda activate test提示符从(base)变成(test)就说明成功了:
3.安装PyTorch与昇腾支持
3.1安装PyTorch 2.5.1
从ModelScope克隆预编译的ARM64版本:
plain
git clone https://oauth2:A_HhBt9-qWdhdTFy66k9@www.modelscope.cn/DanteQ/torch2.5.1.git
cd torch2.5.1
pip install torch-2.5.1-cp310-cp310-manylinux_2_17_aarch64.manylinux2014_aarch64.whl
pip会自动下载依赖包,最终输出Successfully installed torch-2.5.1。
3.2安装torch-npu
这里必须注意版本匹配。PyTorch 2.5.1对应torch-npu 2.5.1rc1,不能随便换版本:
plain
pip install pyyaml setuptools
pip install torch-npu==2.5.1rc1
4.编译安装Apex
Apex是混合精度训练工具,昇腾版针对NPU做了优化。
4.1 版本检查
昇腾版 Apex 编译对 setuptools 版本有严格要求,需先检查并调整版本,确保版本≤65.7.0,不然编译会失败:
plain
# 激活test环境(Python 3.10 + PyTorch-NPU)
conda activate test
# 检查setuptools版本
pip show setuptools | grep Version4.2 克隆源码
昇腾官方在 Gitee 维护了适配 NPU 的 Apex 分支,需克隆指定仓库:
plain
# 克隆昇腾专用Apex项目(master分支为最新适配版)
git clone -b master https://gitee.com/ascend/apex.git
# 进入源码目录
cd apex/
4.3 编译
编译前需确保 PyTorch 已正确安装(torch 2.5.1 + torch-npu 2.5.1rc1),执行昇腾定制编译脚本:
plain
bash scripts/build.sh --python=3.10
这里需要保持网络流畅,要不然很容易失败。
4.4 安装
plain
pip install --upgrade apex-0.1+ascend-cp310-cp310-linux_aarch64.whl看到"Successfully installed apex-0.1+ascend"就OK了。
四、模型部署完整流程
环境搭好后,就可以开始跑训练了。这部分完全按照课程课程的流程来。
1.获取MindSpeed生态组件
MindSpeed-RL需要集成三个仓库:MindSpeed(核心框架)、Megatron-LM(分布式训练)、MindSpeed-LLM(大模型适配)。
plain
conda activate test
# 克隆MindSpeed
git clone https://gitee.com/ascend/MindSpeed.git
cd MindSpeed
git checkout 0dfa0035ec54d9a74b2f6ee2867367df897299df
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip3 install -e .
cp -r mindspeed ../MindSpeed-RL/
cd ..
# 克隆Megatron-LM
git clone https://github.com/NVIDIA/Megatron-LM.git
cd Megatron-LM
git checkout core_r0.8.0
cp -r megatron ../MindSpeed-RL/
cd ..
# 克隆MindSpeed-LLM
git clone https://gitee.com/ascend/MindSpeed-LLM.git
cd MindSpeed-LLM
git checkout 421ef7bcb83fb31844a1efb688cde71705c0526e
cp -r mindspeed_llm ../MindSpeed-RL/
cd ..
# 安装MindSpeed-RL依赖
cd MindSpeed-RL
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install antlr4-python3-runtime==4.7.2 --no-deps2.下载模型和数据集
Qwen2.5-7B模型和Orz Math数据集建议在宿主机下载好,然后挂载到容器:
plain
# 下载Qwen2.5-7B
git clone https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-7B-Instruct.git
# 下载数据集
git clone https://gitcode.com/saulcy/orz_math_57k.git3.数据预处理
修改配置文件configs/datasets/grpo_pe_nlp.yaml,主要改三个路径:
raw_data_path:原始数据路径processed_data_path:处理后数据保存路径vocab_file:词表文件路径
执行预处理脚本:
plain
bash examples/data/preprocess_data.sh grpo_pe_nlp
看到Preprocess done, total samples: 57000就说明成功了。
4.启动训练
修改训练配置文件configs/grpo_trainer_qwen25_7b.yaml:
model.ckpt_path:转换后的权重路径data.data_path:预处理后的数据集路径train.npu_device:NPU设备编号(单卡设为0)train.batch_size:批次大小(昇腾310系列建议8/16)
启动训练:
plain
bash examples/grpo/grpo_trainer_qwen25_7b.sh
终端输出[INFO] Training started with model: Qwen2.5-7B,说明训练已经跑起来了。
五、社区论坛的实际帮助
在本地基于昇腾310系列部署Qwen2VL-7B多模态模型训练时,我遇到了一个棘手的分布式训练故障------训练进程在数据处理阶段突然中断,日志里满屏都是watchdog触发的HCCL通信超时报错,核心报错信息如下:
> [E compiler_depend.ts:421] [Rank 5] Watchdog caught collective operation timeout: WorkHCCL(SeqNum=11, OpType=ALLREDUCE, Timeout(ms)=600000) ran for 600196 milliseconds before timing out.
> [E compiler_depend.ts:475] Some HCCL operations have failed or timed out. Due to the asynchronous nature of ASCEND kernels, subsequent NPU operations might run on corrupted/incomplete data.
我尝试调整过batch_size、检查过节点间网络连通性,但问题始终没有解决。情急之下,我去昇腾论坛搜索关键词,发现早就有开发者发布了一模一样的问题及官方解决方案: https://www.hiascend.com/developer/blog/details/0272186478670135044
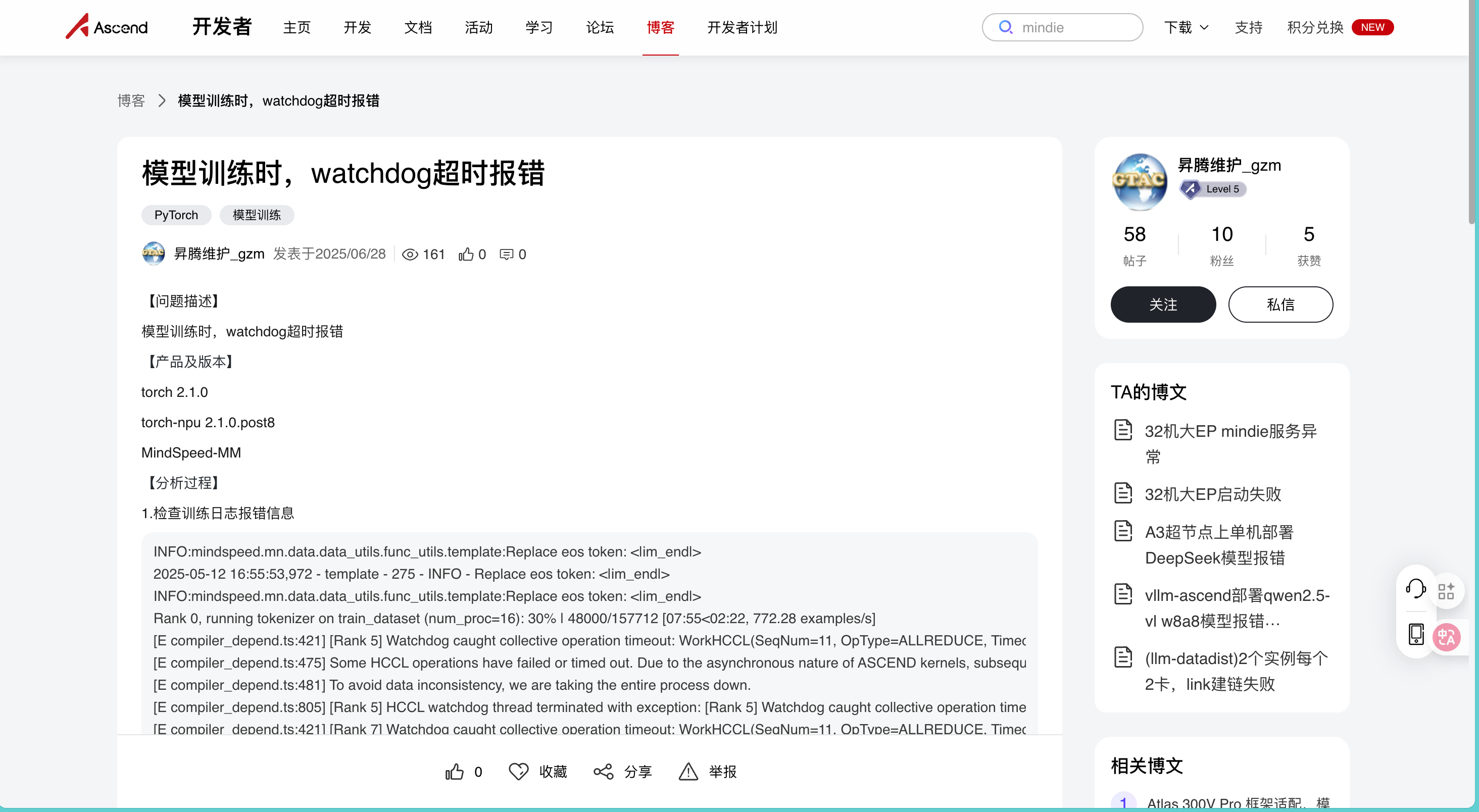
这个帖子里详细记录了问题背景(基于torch 2.1.0 + torch-npu 2.1.0.post8 + MindSpeed-MM框架训练)、完整的报错日志,还有昇腾官方技术人员的分析和解决方案:问题根源是watchdog超时时长短于HCCL超时时长 ,导致watchdog先触发超时中断进程。对应的解决办法有两个,一是通过export HCCL_ASYNC_ERROR_HANDLING=0临时关闭watchdog,先完成数据预处理;二是在MindSpeed框架启动脚本中,通过--distributed-timeout-minutes参数将watchdog超时时间设为超过HCCL超时时间(比如HCCL设30分钟,watchdog设45分钟)。
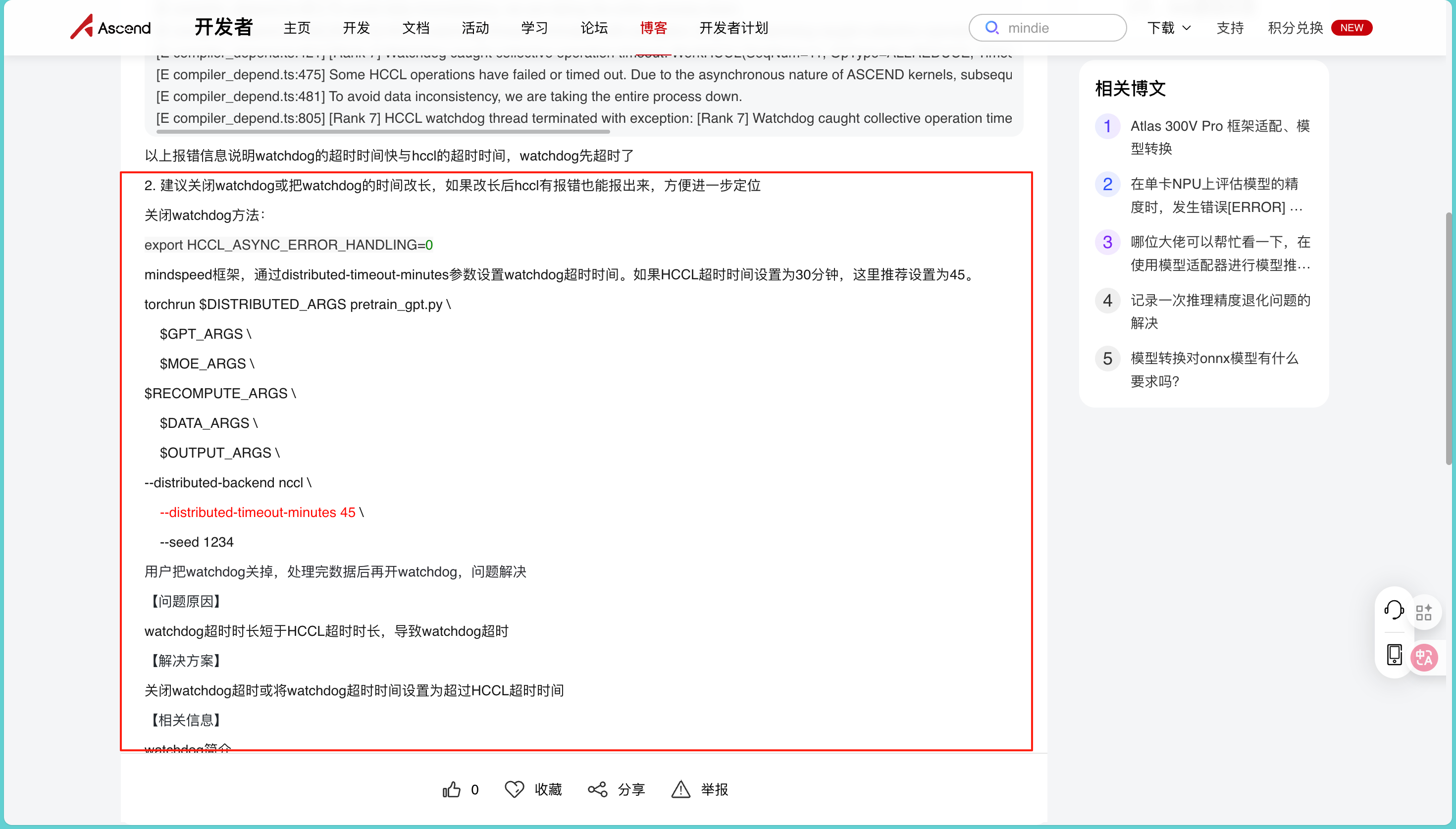
为了确保方案的严谨性,我又对照着昇腾官方文档《MindSpeed MM迁移调优指南》做了进一步验证。文档里不仅详细介绍了MindSpeed-MM框架的分布式训练通信机制,还给出了Qwen2VL-7B模型训练的启动脚本配置示例,明确标注了--distributed-timeout-minutes这类关键参数的作用和设置原则,和论坛里的解决方案完全契合:https://gitcode.com/Ascend/MindSpeed-MM/blob/2.2.0/docs/user-guide/model-migration.md
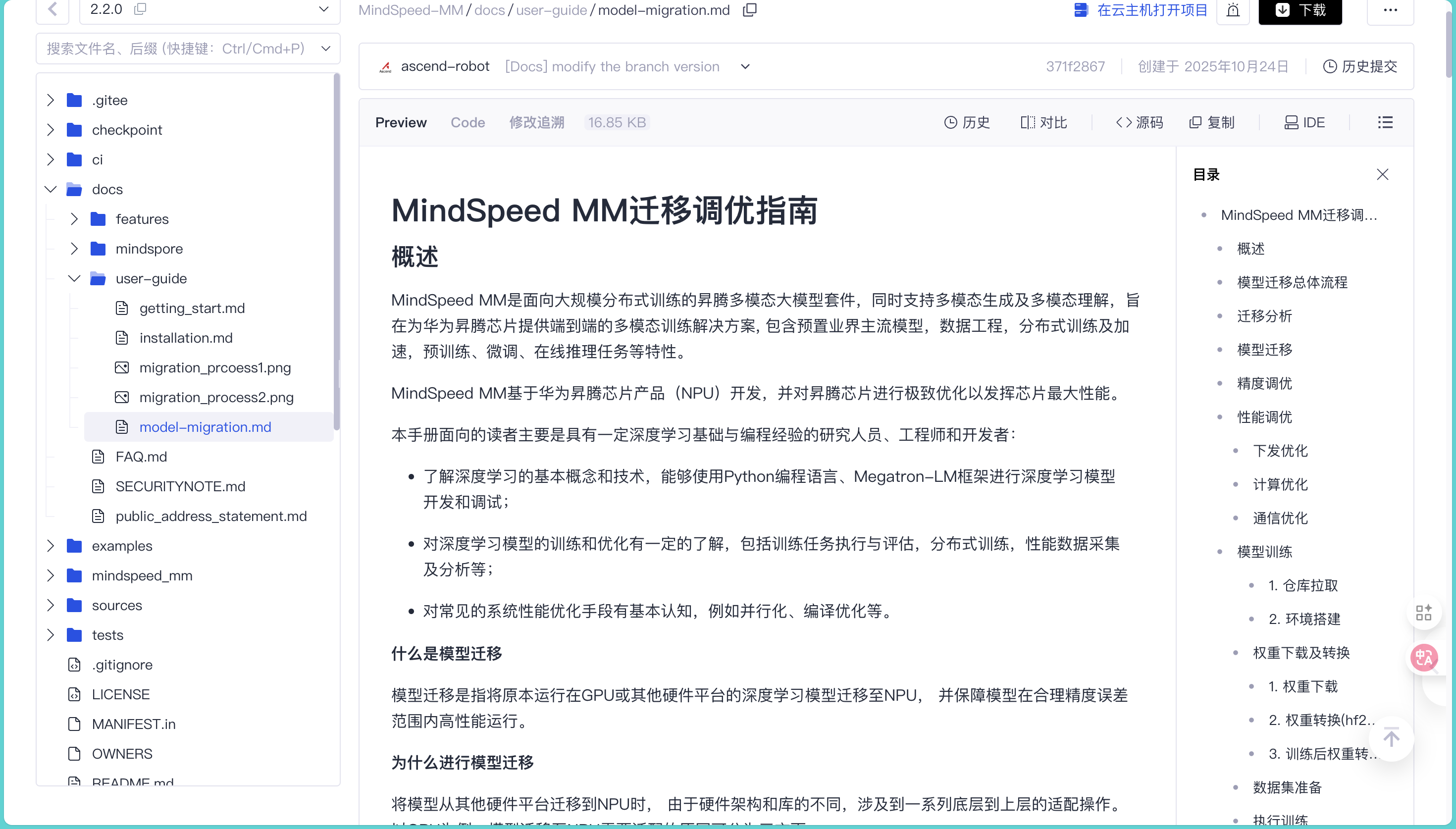
我按照论坛里的方案修改了训练脚本,增加了--distributed-timeout-minutes 45参数,重新启动训练后,watchdog超时问题彻底解决,Qwen2VL-7B的训练流程稳定跑通。
这就是昇腾社区论坛和官方文档的双重价值:论坛里有大量开发者遇到的真实案例和现成的排障方案,帮你跳过"踩坑-试错"的循环;官方文档则从底层原理和标准配置层面提供支撑,让你不仅能解决当下问题,还能理解问题背后的逻辑。
六、几点实用建议
1.版本匹配是硬性要求
昇腾生态的版本兼容性要求很严格。PyTorch、torch-npu、CANN、驱动必须按照官方适配表来,不要自作主张升级。论坛里至少一半的问题都是版本不匹配导致的。
2.先跑通再优化
不要一上来就想着怎么优化性能。先按照课程的流程把基本功能跑通,理解了整个pipeline的逻辑,再去做针对性优化。我一开始就想着改Tiling策略提升性能,结果连环境都没搭好。
3. 社区论坛:开发者的技术支持与经验宝库
社区论坛作为开发者交流平台,能够有效解决开发过程中遇到的技术难题,是开发者获取技术支持和经验分享的重要渠道。遇到技术难题时,优先在论坛检索相关内容,大概率能找到前人已经验证过的解决方案。如果需要发帖提问,务必完整附上环境配置信息、详细错误日志、可复现的代码片段,这样才能帮助其他开发者快速定位问题根源。
4.博客写作驱动知识深化
踩坑时可能只是"改了某个参数就好了",写博客时得解释清楚为什么要改、这个参数的作用机制、还有哪些类似的坑。这个过程让我对技术细节的理解深了一个层次。
总结
从报名课程到完整复现Qwen2.5-7B的训练流程,前前后后花了差不多一个月。中间踩了不少坑,但都在社区论坛找到了解决办法。
昇腾社区最打动我的不是什么"国产化"或"生态建设",而是实实在在的学习资源和互帮互助的氛围。课程给了系统化的学习路径,论坛帮我解决了无数个让人头疼的问题,技术博客让我看到了别人的实践经验。
如果你也在考虑学习昇腾开发,建议先从课程开始。反正是免费的,跟着课程把流程走一遍,至少能建立起完整的认知框架。然后再去本地环境复现,遇到问题就去论坛搜,基本上都能找到答案。