兄弟们,坐稳了,大的真要来了。
外媒《The Information》刚刚捅出一个猛料。
DeepSeek V4 定档春节,计划 2 月中旬发布。

而且,这次的目标很明确,显著提升了编程能力。
注意,这绝对不是一次常规的升级。
据多位参与内部测试的人士透露,在多个内部编程基准中。
DeepSeek V4 已经直接超越了当前全球范围内的主流模型。
虽然官方还没回应,但我觉得这事儿大概率是真的。
因为最近,DeepSeek 悄咪咪的把 DeepSeek R1 的论文更新了。
从原来的 22 页直接加厚到 86 页。

还有,最新版的 DeepSeek 手机 App,新增了语音输入。
一切迹象,都像极了在给新模型做预热。
真的要好好期待一下了。
新模型还在路上,但更新的论文还是非常精彩的。
我看完之后,先来跟大家分享三点。
1
训练出 R1 这样,一个能跟 OpenAI 的 o1 掰手腕的模型。
总共花了多少钱呢?
看这张表格。

你没看错,29.4 万美元。
相比之下,海外大模型训练,动不动就是千万美元,上亿美元。
29.4 万美元,在硅谷连一个资深工程师一年的工资都不够。
这事儿最打脸的,就是前 Scale AI 的 CEO,Meta 现任首席 AI 官,Alexandr Wang 了。
他经常说,必须要用昂贵的人工标注数据,天价的算力和顶级的芯片才能做出顶级 AI。
这回 DeepSeek 更新完的论文,相当于一份完全可复现的技术报告。
现在所有的证据都摆在这了。
还花钱看啥爽剧啊,还有比 DeepSeek 更燃的主角吗?
2
说真的,再次看到这,我还是起了点鸡皮疙瘩。

上图的红字是 AI 的思考过程,翻译过来的意思是。
等等,等等,等一下,这正是我要标记的一个顿悟时刻。
这就是强化学习的威力和魅力。
以前训练 AI 爹味十足,像教小孩儿一样,手把手一步一步教他步骤。
这次,DeepSeek 选择了放手,不教你怎么思考,只告诉你答案对不对。
答对了给颗糖,答错了就饿着。
结果在没有任何人教导的情况下,AI 的思考过程中涌现了人类才有的犹豫。
为了获得奖励,AI 居然进化出了自我博弈。
听着很抽象。
这就像你考试答题落笔之前,眉头紧锁,停顿的那几秒。
这声 Wait,是 AI 在一片混沌中,点燃的第一根火柴。
3
在论文的蒸馏部分,DeepSeek 回答了一个更具颠覆性的问题。
R1 身上的能力,能不能有效稳定的迁移到小模型上呢?
能,而且效果炸裂。
让 R1 当老师,生成高质量的思维链数据,然后通过监督微调 SFT,直接把这套内功心法传授给小模型。
这就是蒸馏。
好比武林盟主把自己毕生领悟的剑法写成了秘籍,直接扔给了小师弟们。
小师弟们不用再去江湖上挨打试错,不用再跑一遍强化学习的流程,直接照着练就行。
DeepSeek 系统性地实验了 1.5B、7B、8B、14B、32B、70B 等各种规模的小模型。
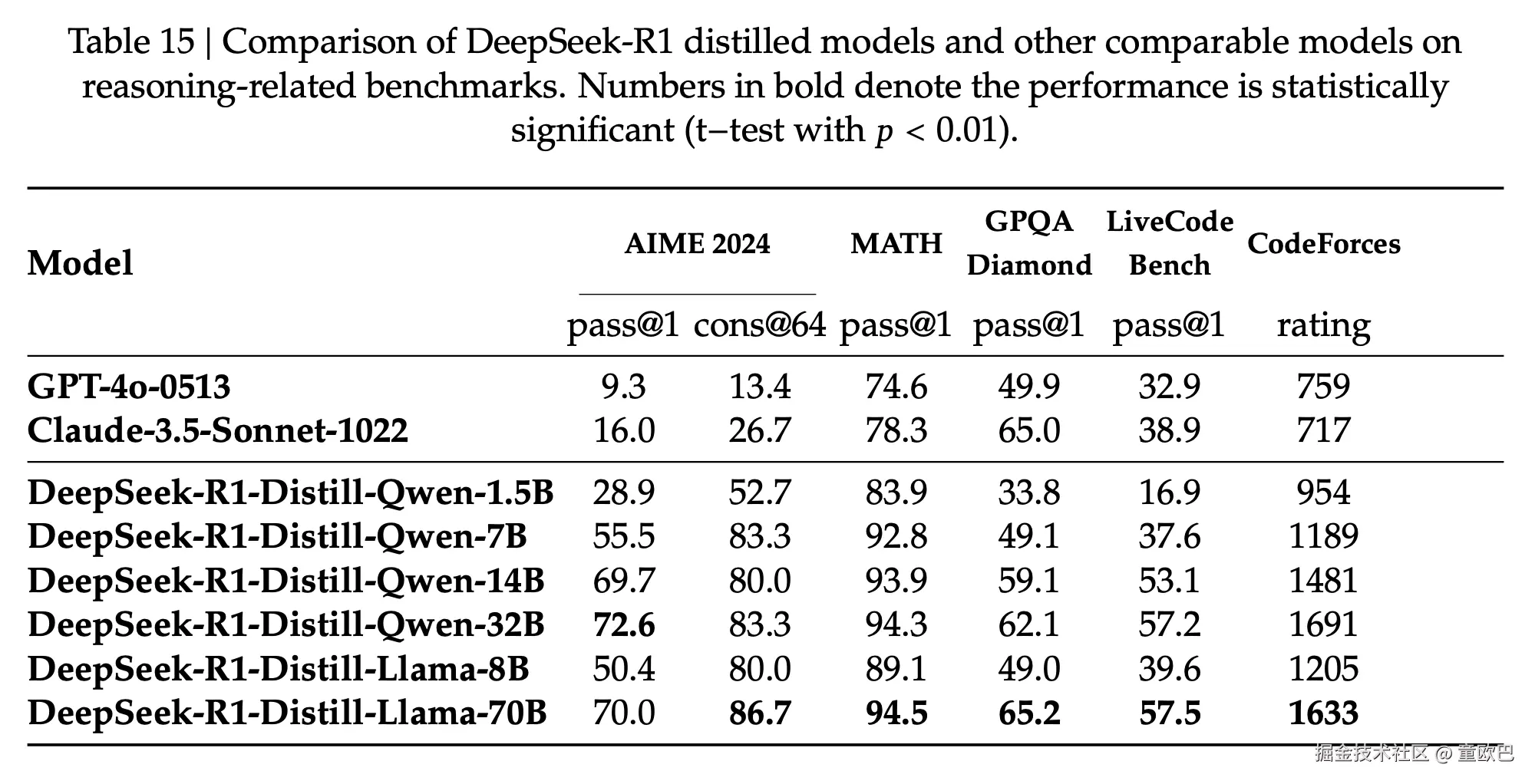
不管啥尺寸,蒸馏之后性能都得到了大幅提升。
顶级的智能,可以像水一样流动,以更低成本的无缝迁移到小模型身上。
听着有些魔幻,但这才是 DeepSeek 一直所追求的事情。
让智能像自来水一样,便宜且触手可及。
尾声
他们建起了高墙,挖深了护城河。
墙内本来 2 块钱的面包,卖到了 200 块。
有一天,DeepSeek 来到墙跟前,狠狠地踹了这堵墙一脚。
墙塌了。
大家往里一看,发面里面没有什么魔法,也没有什么神迹。
有的只是极致的数学,纯粹的逻辑,和一群充满好奇心的工程师。
DeepSeek 官网有句话,我真的特别特别喜欢。

探索未至之境。
是啊,我们要永远去探索前人尚未探索之地。
这才是人最应该做的事情,来牵引 AI 走向我们认可的方向。
敢问路在何方?
路,其实就在我们每个人的脚下。
❤️爱心三连击
1.如果你觉得欧巴的文章还合胃口,就点个赞支持下吧,你的赞是我最大的动力。
2.关注>>>公众号欧巴聊AI,AI 时代陪你一起成长。
3.点赞、评论、转发 === 催更!