文章目录
- 前言
- 介绍
- 知识点介绍
-
- 表结构字段设计
- 索引
-
- 介绍
- 字段数据类型与索引关系
- 向量索引解析
- 性能权衡
- 内存使用估算
-
- [IVF 索引内存使用量](#IVF 索引内存使用量)
- 基于图形的索引内存使用情况
- 搜索方面
-
- 基本ANN(向量)搜索【search方法】
- [增强 ANN(向量)搜索【包括过滤等】](#增强 ANN(向量)搜索【包括过滤等】)
- 混合搜索
- 版本差异记录
- 相关疑问
-
- [MilvusClientV2与MilvusServiceClient 有什么区别?](#MilvusClientV2与MilvusServiceClient 有什么区别?)
- 初始建立表可以建立多个向量字段?
- 创建完表后是否可以新增字段?
- 向量查询时是否需要和索引强一致的度量类型?
- 官方search查询的结果
- 资料获取

前言
博主介绍:✌目前全网粉丝4W+,csdn博客专家、Java领域优质创作者,博客之星、阿里云平台优质作者、专注于Java后端技术领域。
涵盖技术内容:Java后端、大数据、算法、分布式微服务、中间件、前端、运维等。
博主所有博客文件目录索引:博客目录索引(持续更新)
CSDN搜索:长路
视频平台:b站-Coder长路
介绍
官方文档:https://milvus.io/docs/zh/
知识点介绍
表结构字段设计
模式解释:https://milvus.io/docs/zh/schema.md
一个 Collection Schema 有一个主键、最多四个向量字段和几个标量字段。
索引
介绍
官方文档:https://milvus.io/docs/zh/index-explained.md
索引是建立在数据之上的附加结构。其内部结构取决于所使用的近似近邻搜索算法 。索引可以加快搜索速度,但在搜索过程中会产生额外的预处理时间、空间和 RAM。此外,使用索引通常会降低召回率(虽然影响可以忽略不计,但仍然很重要)。因此,本文将解释如何最大限度地减少使用索引的成本,同时最大限度地提高索引的效益。
字段数据类型与索引关系
| 字段数据类型 | 适用索引类型 |
|---|---|
| FLOAT_VECTORFLOAT16_VECTORbfloat16_vector****INT8_VECTOR | 平面IVF_FLAT IVF_SQ8IVF_PQ IVF_RABITQGPU_IVF_FLAT GPU_IVF_PQHNSWDISKANN |
| 二进制向量 | BIN_FLATBIN_IVF_FLATMINHASH_LSH |
| 稀疏浮点矢量 | 稀疏反转索引 |
| VARCHAR | 反转(推荐)BITMAPTrie |
| BOOL | **BITMAP(推荐)**反转 |
| INT8INT16INT32****INT64 | 反转****STL_SORT |
| FLOAT****DOUBLE | 反转 |
| 数组**(BOOL、INT8/16/32/64 和 VARCHAR 类型的元素)** | BITMAP(推荐) |
| ARRAY**(BOOL、INT8/16/32/64、FLOAT、DOUBLE 和 VARCHAR 类型的元素)** | 反转 |
| JSON | 反转 |
向量索引解析
数据结构
数据结构是索引的基础层。常见类型包括
- 反转文件(IVF)
IVF 系列索引类型允许 Milvus 通过基于中心点的分区将向量聚类到桶中。一般可以安全地假设,如果桶的中心点接近查询向量,那么桶中的所有向量都有可能接近查询向量。基于这个前提,Milvus 只扫描那些中心点靠近查询向量的桶中的向量 Embeddings,而不是检查整个数据集。这种策略既能降低计算成本,又能保持可接受的精确度。
这种索引数据结构非常适合需要快速吞吐量的大规模数据集。
- 基于图的结构
基于图的向量搜索数据结构,如分层导航小世界 (HNSW),构建了一个分层图,其中每个向量都连接到其最近的邻居。查询可以浏览这个层次结构,从粗略的上层开始,然后切换到下层,从而实现高效的对数时间搜索复杂性。
这种索引数据结构适用于高维空间和要求低延迟查询的场景。
量化
量化通过更粗略的表示来减少内存占用和计算成本:
- 标量量化 (如SQ8)使 Milvus 能够将每个向量维度压缩为单字节(8 位),与 32 位浮点数相比,内存使用量减少了 75%,同时保持了合理的精度。
- 乘积量化**(PQ**)使 Milvus 能够将向量分割成子向量,并使用基于编码本的聚类进行编码。这可以实现更高的压缩率(例如 4-32 倍),但代价是召回率略有降低,因此适用于内存受限的环境。
比如索引表格中的这几个:

精炼器
量化本身就是有损的。为了保持召回率,量化始终会产生比所需数量更多的前 K 个候选结果,这使得精炼器可以使用更高的精度从这些候选结果中进一步选择前 K 个结果,从而提高召回率。
例如,FP32 精炼器通过使用 FP32 精度而不是量化值重新计算距离,对量化返回的候选搜索结果进行操作符操作。
这对于需要在搜索效率和精度之间做出权衡的应用(如语义搜索或推荐系统)来说至关重要,因为在这些应用中,微小的距离变化都会对结果质量产生重大影响。
性能权衡
在评估性能时,平衡构建时间 、每秒查询次数(QPS)和召回率至关重要。一般规则如下:
- 就QPS 而言,基于图形的索引类型 通常优于IVF 变体。
- IVF 变体 尤其适用于topK 较大的情况**(例如,超过 2,000 个)**。
- 与SQ****相比,PQ通常能在相似的压缩率下提供更好的召回率,但后者的性能更快。
- 将硬盘用于部分索引(如DiskANN)有助于管理大型数据集,但也会带来潜在的 IOPS 瓶颈。
容量
容量通常涉及数据大小与可用 RAM 之间的关系。在处理容量问题时,请考虑以下几点:
- 如果有四分之一的原始数据适合存储在内存中,则应考虑使用延迟稳定的 DiskANN。
- 如果所有原始数据都适合在内存中存储,则应考虑基于内存的索引类型和 mmap。
- 您可以使用量化应用索引类型和 mmap 来换取最大容量的准确性。
召回率
召回率通常涉及过滤率,即搜索前过滤掉的数据。在处理召回问题时,应考虑以下几点:
- 如果过滤率小于 85%,则基于图的索引类型优于 IVF 变体。
- 如果过滤比在 85% 到 95% 之间,则使用 IVF 变体。
- 如果过滤率超过 98%,则使用 "蛮力"(FLAT)来获得最准确的搜索结果。
性能
搜索性能通常涉及 top-K,即搜索返回的记录数。在处理性能问题时,请考虑以下几点:
- 对于 Top-K 较小的搜索(如 2,000),需要较高的召回率,基于图的索引类型优于 IVF 变体。
- 对于 top-K 较大的搜索(与向量嵌入的总数相比),IVF 变体比基于图的索引类型是更好的选择。
- 对于 top-K 中等且过滤率较高的搜索,IVF 变体是更好的选择。
决策矩阵:选择最合适的索引类型
下表是一个决策矩阵,供您在选择合适的索引类型时参考。
| 方案 | 推荐索引 | 注释 |
|---|---|---|
| 原始数据适合内存 | HNSW、IVF + 精炼 | 使用 HNSW 实现低 **k**/ 高召回率。 |
| 磁盘、固态硬盘上的原始数据 | 磁盘ANN | 最适合对延迟敏感的查询。 |
| 磁盘上的原始数据,有限的 RAM | IVFPQ/SQ + mmap | 平衡内存和磁盘访问。 |
| 高过滤率(>95) | 强制(FLAT) | 避免微小候选集的索引开销。 |
大型 **k** (≥ 数据集的 1) |
IVF | 簇剪枝减少了计算量。 |
| 极高的召回率(>99) | 蛮力 (FLAT) + GPU | -- |
内存使用估算
IVF 索引内存使用量
举例:使用 IVF 变体索引的 100 万个 128 维向量所使用的内存明细。
下表列出了不同配置下的内存用量估算:
| 配置 | 内存估算 | 总内存 |
|---|---|---|
| IVF-PQ(无细化) | 1.0 MB + 2.0 MB + 8.0 MB | 11.0 MB |
| IVF-PQ + 10% 原始细化 | 1.0 MB + 2.0 MB + 8.0 MB + 51.2 MB | 62.2 MB |
| IVF-SQ8 (无细化) | 1.0 MB + 2.0 MB + 128 MB | 131.0 MB |
| IVF-FLAT(全原始向量) | 1.0 MB + 2.0 MB + 512 MB | 515.0 MB |
基于图形的索引内存使用情况
基于图的索引类型(如 HNSW)需要大量内存来存储图结构和原始向量嵌入。下面是使用 HNSW 索引类型索引的 100 万个 128 维向量所消耗内存的详细明细。
- 当您使用 HNSW 对 100 万 128 维向量嵌入进行索引时,使用的总内存为128 MB(图形)+ 512 MB(向量)= 640 MB。
- 与原始向量嵌入相比,这实现了 64 倍的压缩率,HNSWPQ 索引类型使用的总内存将为128 MB(图)+ 8 MB(压缩向量)= 136 MB。
搜索方面
基本ANN(向量)搜索【search方法】
基础参数介绍
官方文档:https://milvus.io/docs/zh/single-vector-search.md
java
// 下面参数来源:SearchReq
int topK:搜索请求中携带的参数limit 决定了搜索结果中包含的实体数量。该参数指定了单次搜索中返回实体的最大数量。【支持topK或者limit形式】
限制+偏移:topK字段+offset组合搜索
.topK(3)
.offset(10)
// 度量类型
IndexParam.MetricType metricType
INVALID,
L2,
IP,
COSINE,
HAMMING,
JACCARD,
MHJACCARD,
BM25;
// 向量集合,支持批次向量查询
List<BaseVector> data
// 指定输出字段,返回记录的字段信息值
List<String> outputFields;相似度:Milvus 根据搜索结果与查询向量的相似度得分从高到低排列搜索结果。相似度得分也称为与查询向量的距离,其值范围随使用的度量类型而变化。
度量类型:
| 度量类型 | 特征 | 距离范围 |
|---|---|---|
**L2** |
值越小表示相似度越高。 | [0, ∞) |
**IP** |
数值越大,表示相似度越高。 | -1, 1 |
**COSINE** |
数值越大,表示相似度越高。 | -1, 1 |
**JACCARD** |
值越小,表示相似度越高。 | 0, 1 |
**HAMMING** |
值越小,表示相似度越高。 | 0,dim(向量) 批量向量搜索 |
单向量搜索
单向量搜索:在 ANN 搜索中,单向量搜索指的是只涉及一个查询向量的搜索。根据预建索引和搜索请求中携带的度量类型,Milvus 将找到与查询向量最相似的前 K 个向量。
搜索请求携带单个查询向量,要求 Milvus 使用内积(IP)计算查询向量与 Collections 中向量的相似度,并返回三个最相似的向量。
java
FloatVec queryVector = new FloatVec(new float[]{0.3580376395471989f, -0.6023495712049978f, 0.18414012509913835f, -0.26286205330961354f, 0.9029438446296592f});
SearchReq searchReq = SearchReq.builder()
.collectionName("quick_setup")
.data(Collections.singletonList(queryVector))
.topK(3)
.build();
SearchResp searchResp = client.search(searchReq);
// Output
// TopK results:
// SearchResp.SearchResult(entity={}, score=0.95944905, id=5)
// SearchResp.SearchResult(entity={}, score=0.8689616, id=1)
// SearchResp.SearchResult(entity={}, score=0.866088, id=7)批向量搜索
**批向量搜索:**可以多向量批次去搜索
java
List<BaseVector> queryVectors = Arrays.asList(
new FloatVec(new float[]{0.041732933f, 0.013779674f, -0.027564144f, -0.013061441f, 0.009748648f}),
new FloatVec(new float[]{0.0039737443f, 0.003020432f, -0.0006188639f, 0.03913546f, -0.00089768134f})
);
SearchReq searchReq = SearchReq.builder()
.collectionName("quick_setup")
.data(queryVectors)
.topK(3)
.build();
SearchResp searchResp = client.search(searchReq);
// 返回的是两组数据分区ANN搜索
分区ANN搜索 :Collections 中创建了多个分区,您可以将搜索范围缩小到特定数量的分区。在这种情况下,您可以在搜索请求中包含目标分区名称,将搜索范围限制在指定的分区内。减少搜索所涉及的分区数量可以提高搜索性能。
java
SearchReq searchReq = SearchReq.builder()
.collectionName("quick_setup")
// 分区字段名
.partitionNames(Collections.singletonList("partitionA"))
.data(Collections.singletonList(queryVector))
.topK(3)
.build();增强 ANN(向量)搜索【包括过滤等】
导航梳理
AUTOINDEX 极大地平滑了 ANN 搜索的学习曲线。但是,随着 top-K 的增加,搜索结果可能并不总是正确的。通过缩小搜索范围、提高搜索结果的相关性和搜索结果的多样化,Milvus 实现了以下搜索增强功能。
1)过滤搜索 :可以在搜索请求中包含过滤条件,这样 Milvus 就会在进行 ANN 搜索前进行元数据过滤,将搜索范围从整个 Collections 缩小到只搜索符合指定过滤条件的实体。
2)**范围搜索:特定范围内限制返回实体的距离或得分,从而提高搜索结果的相关性。在 Milvus 中,范围搜索包括以与查询向量最相似的嵌入向量为中心**,画两个同心圆。搜索请求指定了两个圆的半径,Milvus 会返回所有属于外圆但不属于内圆的向量嵌入。
3)分组搜索:如果返回的实体在特定字段中持有相同的值,搜索结果可能无法代表向量空间中所有向量嵌入的分布情况。要使搜索结果多样化,可以考虑使用分组搜索。
4)混合搜索:一个 Collections 最多可以包含四个向量场,以保存使用不同嵌入模型生成的向量嵌入。通过这种方式,可以使用混合搜索对这些向量场的搜索结果进行 Rerankers,从而提高召回率。
过滤搜索(条件过滤)
过滤搜索根据应用过滤的阶段分为两种类型--标准过滤 和迭代过滤。
**标准过滤:**Collections 同时包含向量嵌入及其元数据,您可以在 ANN 搜索之前过滤元数据,以提高搜索结果的相关性。Milvus 收到携带过滤条件的搜索请求后,会将搜索范围限制在符合指定过滤条件的实体内。
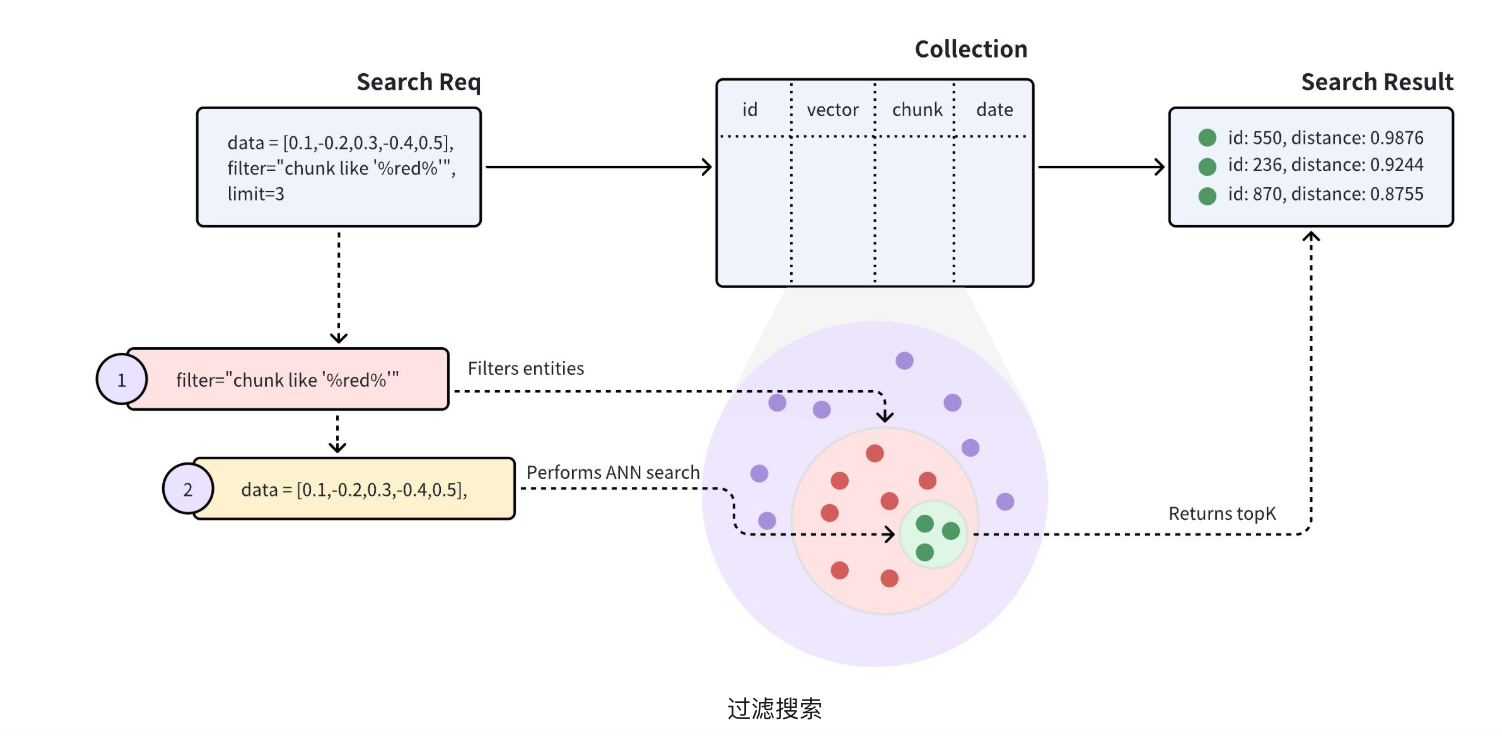
示范如下 :搜索请求携带**chunk like "%red%"** 作为过滤条件,表明 Milvus 应在**chunk** 字段中包含**red** 的所有实体内进行 ANN 搜索。具体来说,Milvus 会执行以下操作:
- 过滤符合搜索请求中过滤条件的实体。
- 在过滤后的实体中进行 ANN 搜索。
- 返回前 K 个实体。
迭代过滤:标准过滤过程能有效地将搜索范围缩小到很小的范围。但是,过于复杂的过滤表达式可能会导致非常高的搜索延迟。在这种情况下,迭代过滤可以作为一种替代方法,帮助减少标量过滤的工作量。
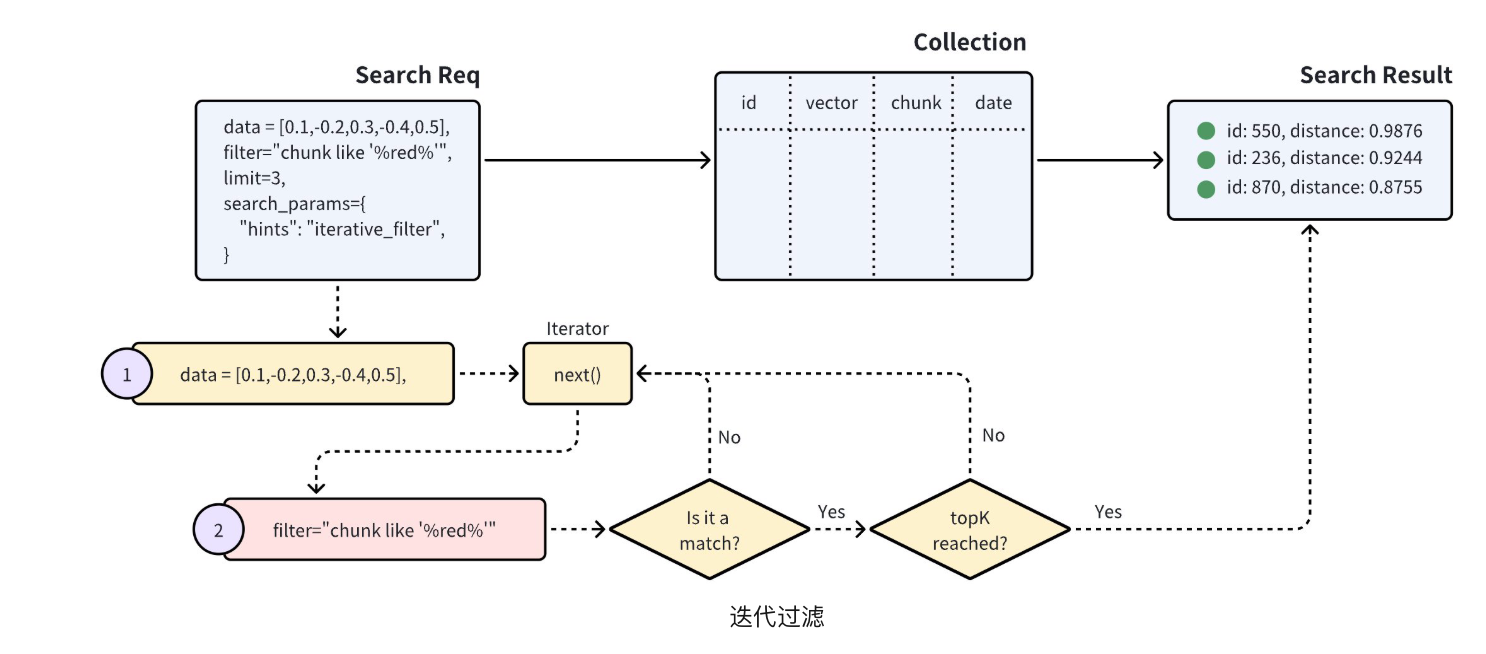
大数据量会有性能问题
过滤条件写法:
java
// 搜索请求中的过滤条件为color like "red%" and likes > 50 。它使用 and 操作符包含两个条件:第一个条件要求在color 字段中查找值以red 开头的实体,其他条件要求在likes 字段中查找值大于50 的实体。符合这些要求的实体只有两个。当 top-K 设置为3 时,Milvus 将计算这两个实体与查询向量的距离,并将它们作为搜索结果返回。
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
// 过滤表达式
.filter("color like \"red%\" and likes > 50")
.outputFields(Arrays.asList("color", "likes"))
.build();
// 使用迭代过滤器,就是补充了个searchParams字段
SearchReq searchReq = SearchReq.builder()
.collectionName("my_collection")
.data(Collections.singletonList(queryVector))
.topK(5)
.filter("color like \"red%\" and likes > 50")
.outputFields(Arrays.asList("color", "likes"))
.searchParams(new HashMap<>("hints", "iterative_filter"))
.build();过滤条件文档:https://milvus.io/docs/zh/boolean.md
标量字段:
sql
// 查找具有三原色(红色、绿色或蓝色)的实体
filter='color in ["red", "green", "blue"]'JSON 字段中引用键:
java
// 带有键price 和model 的 JSON 字段product ,并想查找具有特定模型且价格低于 1,850 的产品
filter='product["model"] == "JSN-087" AND product["price"] < 1850'过滤数组字段:
java
// 2000 年以来各观测站报告的平均气温记录,要查找 2009 年(第 10 次记录)气温超过 23°C 的观测站
filter='history_temperatures[10] > 23'过滤表达式模板文档:https://milvus.io/docs/zh/filtering-templating.md
过滤表达式优化:
json
要查找居住在 "北京"(北京)或 "上海"(上海)的 25 岁以上的个人,请使用以下模板表达式:
filter = "age > 25 AND city IN ['北京', '上海']"
为提高性能,可使用这种带参数的变体:
filter = "age > {age} AND city in {city}",
filter_params = {"age": 25, "city": ["北京", "上海"]}
这种方法可减少解析开销,提高查询速度。支持一些函数:
shell
# JSON data: {"tags": ["electronics", "sale", "new"]}
filter='json_contains(tags, "sale")'
# JSON data: {"tags": ["electronics", "sale", "new", "discount"]}
filter='json_contains_all(tags, ["electronics", "sale", "new"])'
# JSON data: {"tags": ["electronics", "sale", "new"]}
filter='json_contains_any(tags, ["electronics", "new", "clearance"])'混合搜索
官方文档:https://milvus.io/docs/zh/multi-vector-search.md
支持一个collection中创建多个向量,默认4个,可以修改配置参数,最多10个一个collection中
示范场景:
为了演示各种搜索向量字段的功能,我们将使用一个示例查询构建三个**AnnSearchRequest** 搜索请求。在此过程中,我们还将使用其预先计算的密集向量。搜索请求将针对以下向量场:
**text_dense**语义文本搜索,允许基于意义而非直接关键词匹配进行上下文理解和检索。**text_sparse**全文搜索或关键词匹配,侧重于文本中精确匹配的单词或短语。**image_dense**多模态文本到图片搜索,根据查询的语义内容检索相关产品图片。
示范举例:
java
float[] queryDense = new float[]{-0.0475336798f, 0.0521207601f, 0.0904406682f, ...};
float[] queryMultimodal = new float[]{0.0158298651f, 0.5264158340f, ...}
List<BaseVector> queryTexts = Collections.singletonList(new EmbeddedText("white headphones, quiet and comfortable");)
List<BaseVector> queryDenseVectors = Collections.singletonList(new FloatVec(queryDense));
List<BaseVector> queryMultimodalVectors = Collections.singletonList(new FloatVec(queryMultimodal));
List<AnnSearchReq> searchRequests = new ArrayList<>();
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_dense")
.vectors(queryDenseVectors)
.params("{\"nprobe\": 10}")
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("text_sparse")
.vectors(queryTexts)
.params("{\"drop_ratio_search\": 0.2}")
.topK(2)
.build());
searchRequests.add(AnnSearchReq.builder()
.vectorFieldName("image_dense")
.vectors(queryMultimodalVectors)
.params("{\"nprobe\": 10}")
.topK(2)
.build());参数**limit** 设置为 2 时,每个**AnnSearchRequest** 会返回 2 个搜索结果。在本示例中,创建了 3 个**AnnSearchRequest** 实例,总共产生了 6 个搜索结果。
默认milvus还支持重排:
- 加权排名:如果结果需要强调某个向量场,请使用该策略。WeightedRanker 可以为某些向量场赋予更大的权重,使其更加突出。
- RRFRanker(互易排名融合排名器):在不需要特别强调的情况下选择此策略。RRFRanker 能有效平衡每个向量场的重要性。
针对重排文档可查看:https://milvus.io/docs/zh/weighted-ranker.md
java
// RRFRanker(互易排名融合排名器)
BaseRanker reranker = new RRFRanker(100);混合查询的效果如下:
java
// 在为混合搜索指定limit=2 参数后,Milvus 将对三次搜索得到的六个结果进行 Rerankers 排序。最终,它们将只返回最相似的前两个结果。
HybridSearchReq hybridSearchReq = HybridSearchReq.builder()
.collectionName("my_collection")
.searchRequests(searchRequests)
.ranker(reranker)
.topK(2)
.build();
SearchResp searchResp = client.hybridSearch(hybridSearchReq);版本差异记录
2.6.0
体现在sdk包中,如果服务端版本比较低,sdk用的高,服务端会报错类似如下;

在2.6.0及之后MilvusClientV2开始支持addCollectionField:新增集合字段。
相关疑问
MilvusClientV2与MilvusServiceClient 有什么区别?
| 特性 | 新版客户端 (推荐) | 旧版客户端 (过时) |
|---|---|---|
| Maven 依赖 | io.milvus:milvus-sdk-java |
io.milvus:milvus-sdk-java |
| 包路径 | io.milvus.v2.client.** |
io.milvus.client.** |
| 核心类 | **MilvusClientV2** |
MilvusClient |
| 引入版本 | SDK 2.3.0+ (对应 Milvus 2.3.x+) | SDK 2.2.x 及以前 |
| 设计理念 | 更简洁、更现代、Fluent API | 更接近 gRPC 底层 API,略显冗长 |
| 连接方式 | 使用 ConnectConfig 构建配置 |
使用 ConnectParam 构建参数 |
| 推荐程度 | ✅ 强烈推荐,是未来的方向 | ⚠️ 已过时,新项目不应使用 |
推荐使用MilvusClientV2。
初始建立表可以建立多个向量字段?
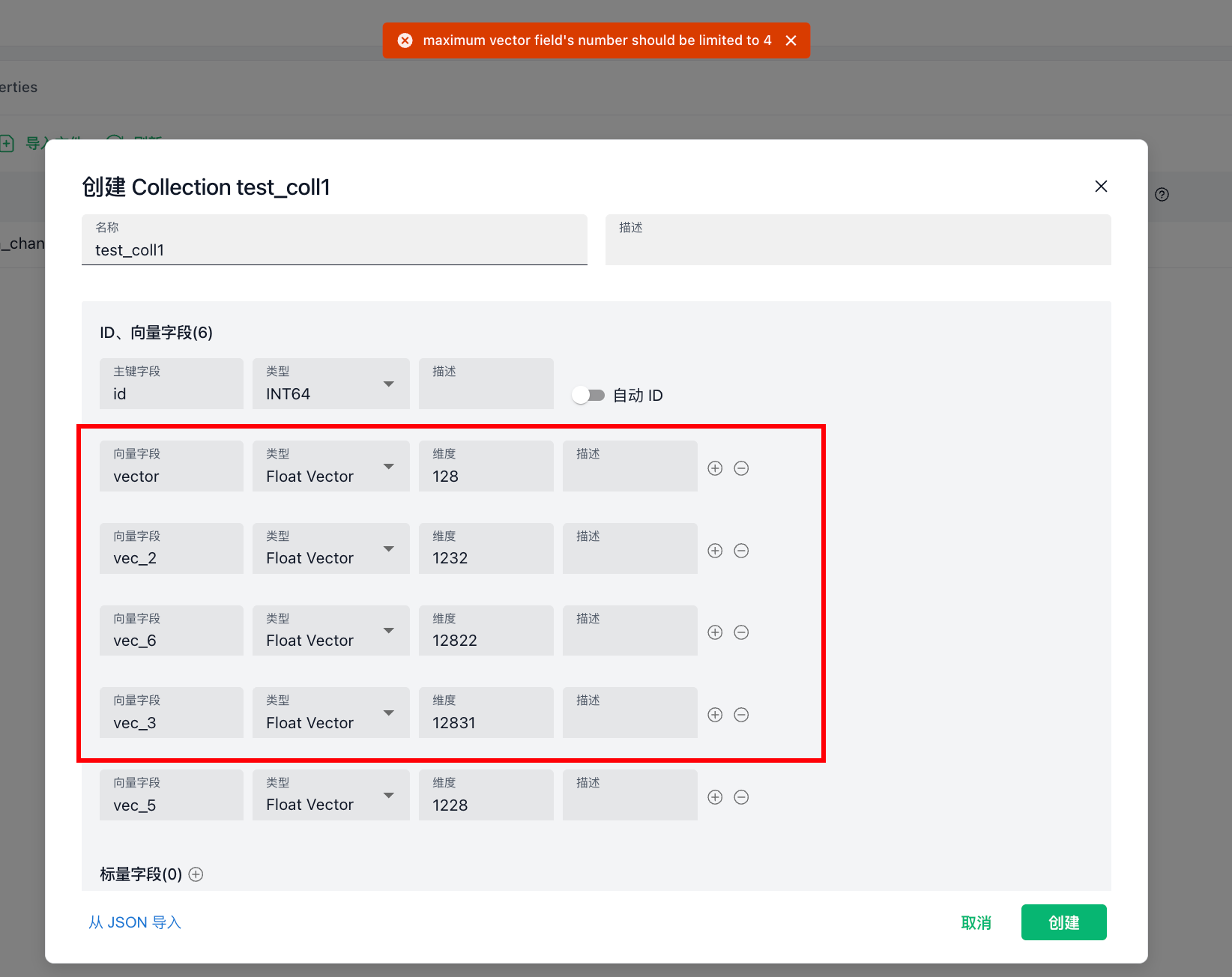
是的,官方介绍,可在建立表的时候最多加四个向量字段。
模式解释:https://milvus.io/docs/zh/schema.md
一个 Collection Schema 有一个主键、最多四个向量字段和几个标量字段。
在官方文档中介绍到可以修改配置项,来提高更多的向量?
- 创建具有多个向量场的 Collections:https://milvus.io/docs/zh/multi-vector-search.md【对于多向量混合搜索,我们应该在一个 Collection schema 中定义多个向量字段。默认情况下,每个 Collection 最多可容纳 4 个向量字段。不过,如果有必要,可以根据需要调整
**proxy.maxVectorFieldNum**,在一个 Collection 中最多包含 10 个向量字段。】
创建完表后是否可以新增字段?
以milvus 2.6.3版本为例子
**是否支持新增向量字段?**不可以,向量字段一开始建立完表之后无法新增
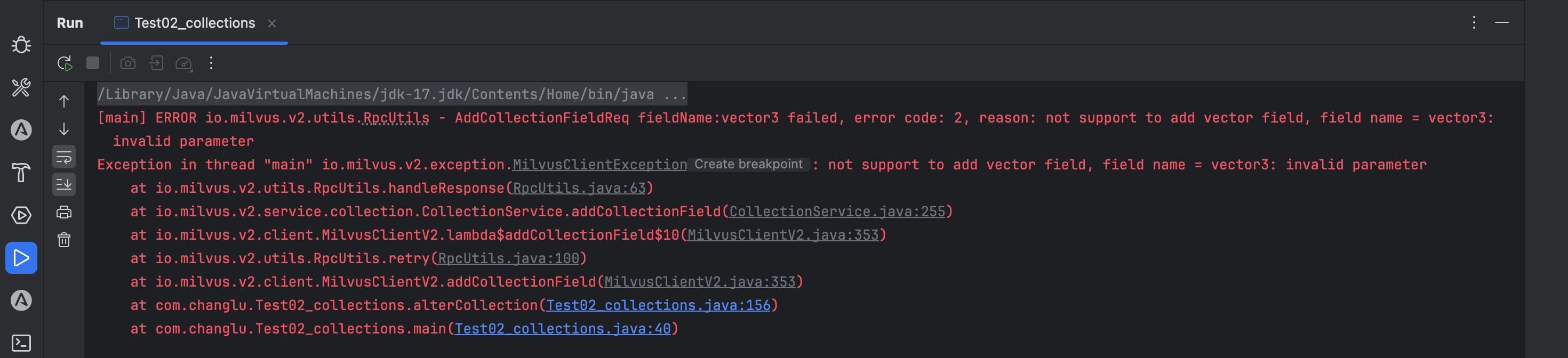
**新增其他标量字段?**可以,但是必须设置可为空
其他标量字段需要设置可以为空,否则会报错:

java
// 新增字段
AddCollectionFieldReq addCollectionFieldReq = AddCollectionFieldReq.builder()
.databaseName(database)
.collectionName(collectionName)
.fieldName("test_param")
.dataType(DataType.VarChar)
// 新增的字段必须加这个为空的
.isNullable(true)
.maxLength(65535).build();
MilvusClient.getInstance().addCollectionField(addCollectionFieldReq);向量查询时是否需要和索引强一致的度量类型?
关于建立表的注意点
建立表的强制点:
1、建立的表必须要强制手动loadCollection ,后续才能查询。【内存计算架构要求数据预先加载到内存,Miluvs是内存计算架构】
- 在 Milvus 2.3+ 的 release notes 中强调:"All search operations require explicit collection loading for better resource management."
java
// 注意最后要加载集合到内存
LoadCollectionReq loadCollectionReq = LoadCollectionReq.builder()
.databaseName(database)
.collectionName(collectionName)
.build();
instance.loadCollection(loadCollectionReq);2、加载到内存loadCollection前必须要给表建立索引与度量类型!
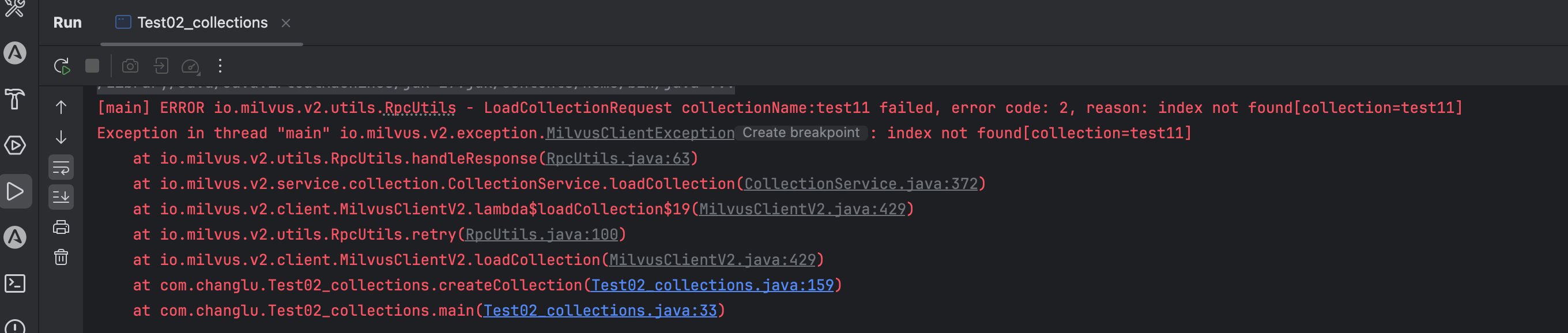
如果不设置索引就会报错,在loadCollection的时候**。**
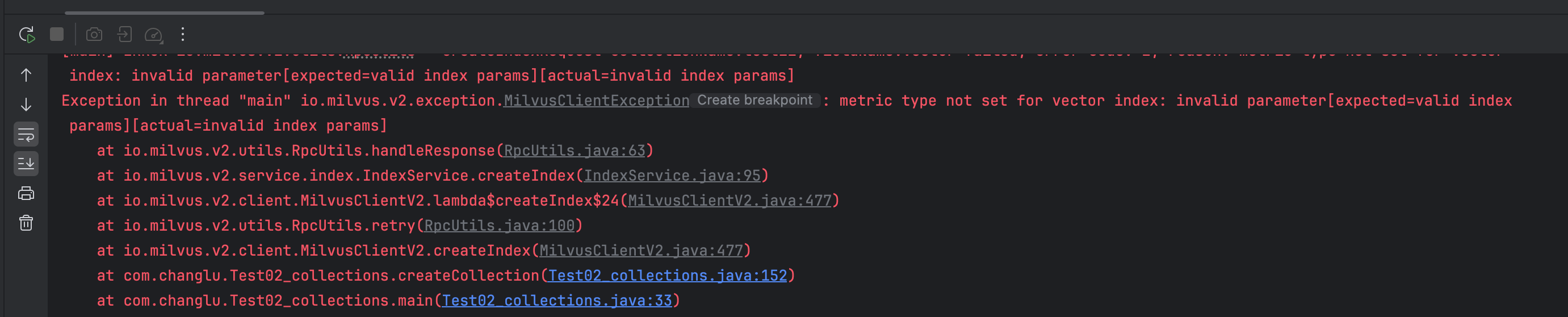
如果不建立度量就会报错,在loadCollection的时候**。**
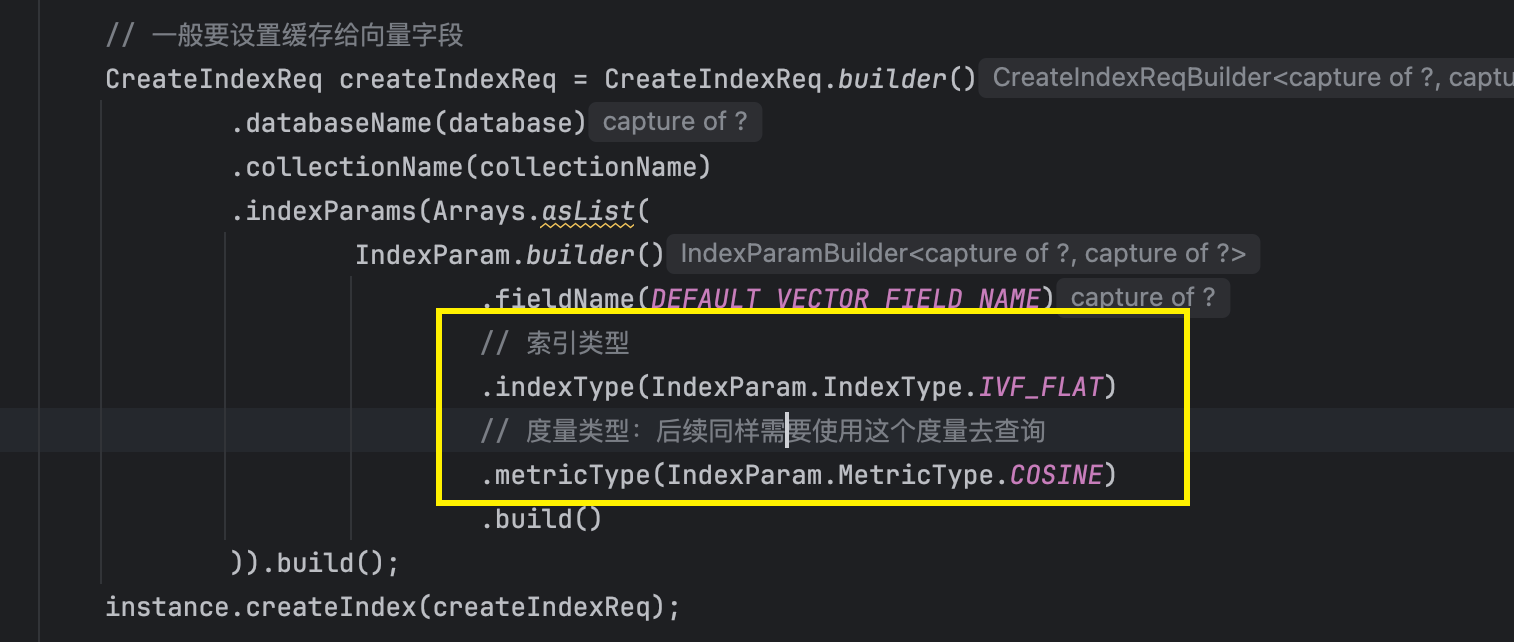
**下面是创建索引+度量:**初始的时候就指定好了
java
// 一般要设置缓存给向量字段
CreateIndexReq createIndexReq = CreateIndexReq.builder()
.databaseName(database)
.collectionName(collectionName)
.indexParams(Arrays.asList(
IndexParam.builder()
.fieldName(DEFAULT_VECTOR_FIELD_NAME)
// 索引类型
.indexType(IndexParam.IndexType.IVF_FLAT)
// 度量类型:后续同样需要使用这个度量去查询
.metricType(IndexParam.MetricType.COSINE)
.build()
)).build();
instance.createIndex(createIndexReq);索引方面
索引方面:
1)一旦向量索引创建后,那么就无法删除,亲测如下:
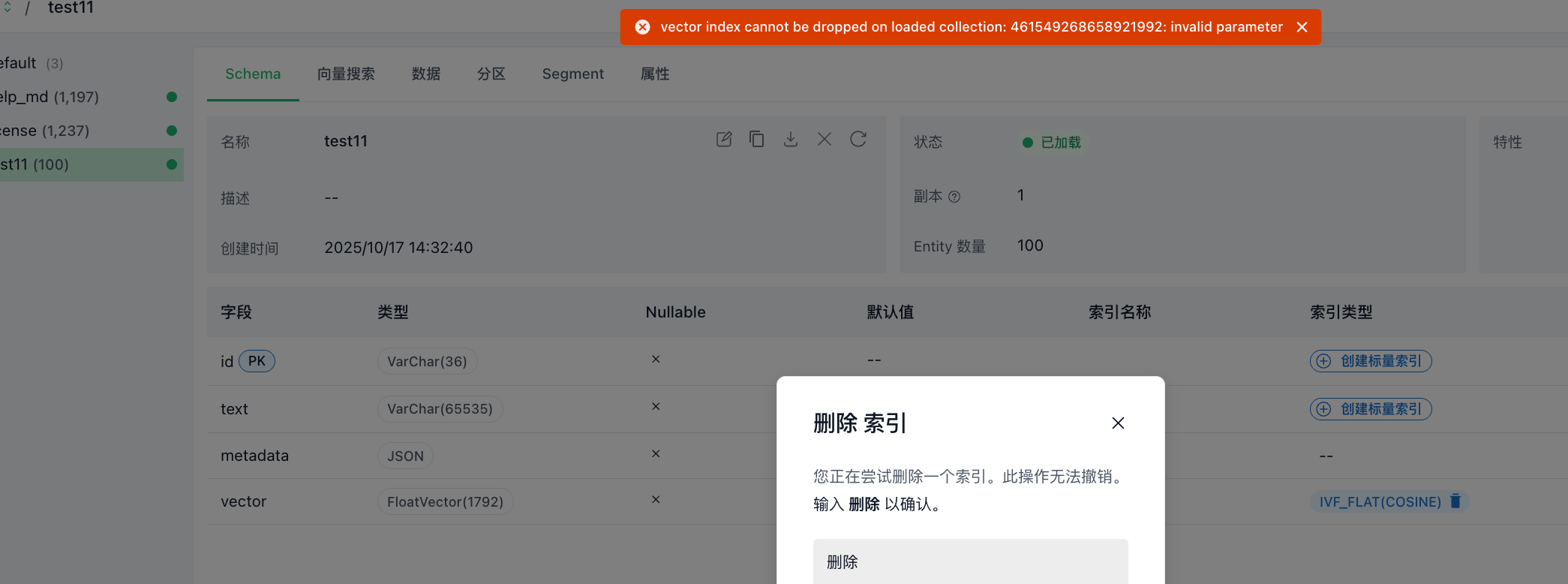
在一开始建立向量索引的时候,必须要选择索引+度量:
关于搜索和索引向量的关系:
搜索的时候选择的度量必须和对应表的度量一致,否则会查询报错!
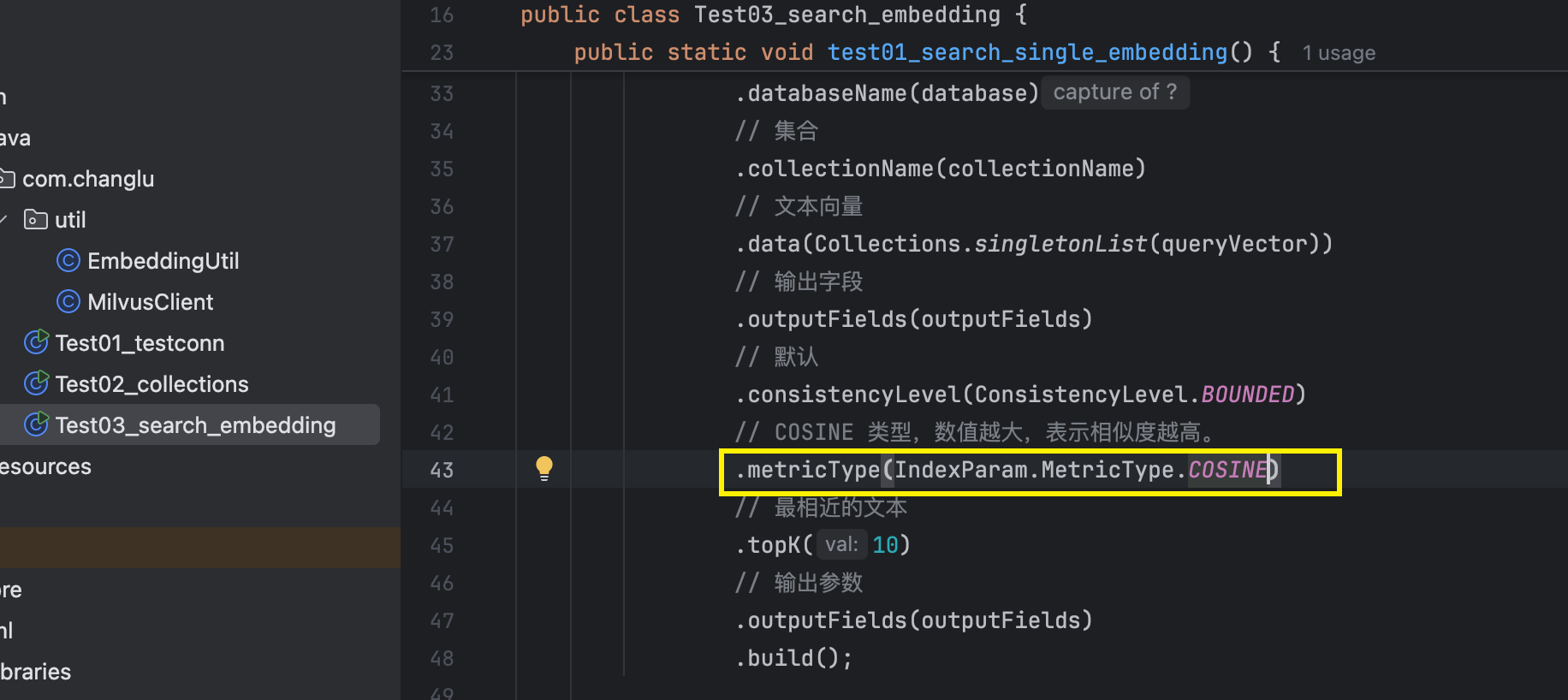
报错如下如果度量选择不一致的话:
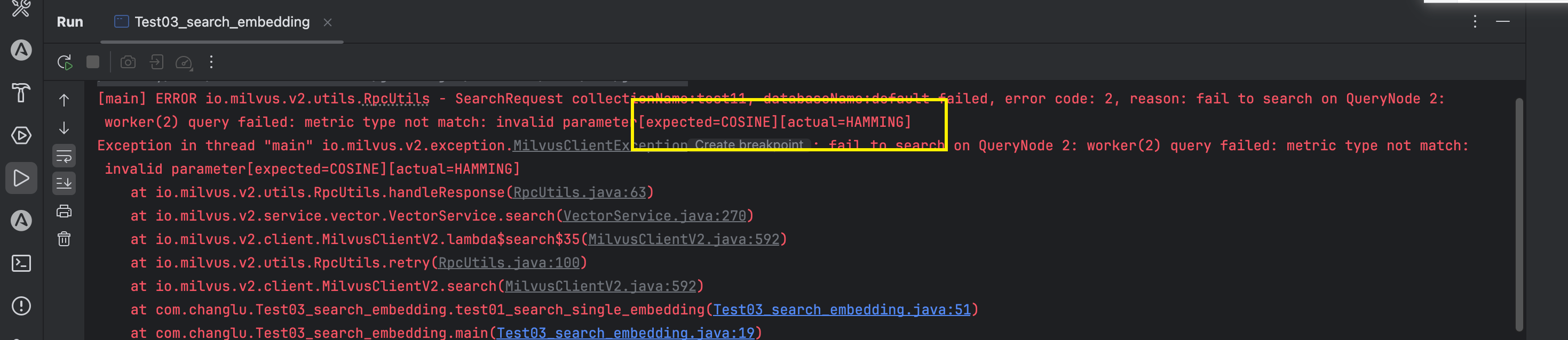
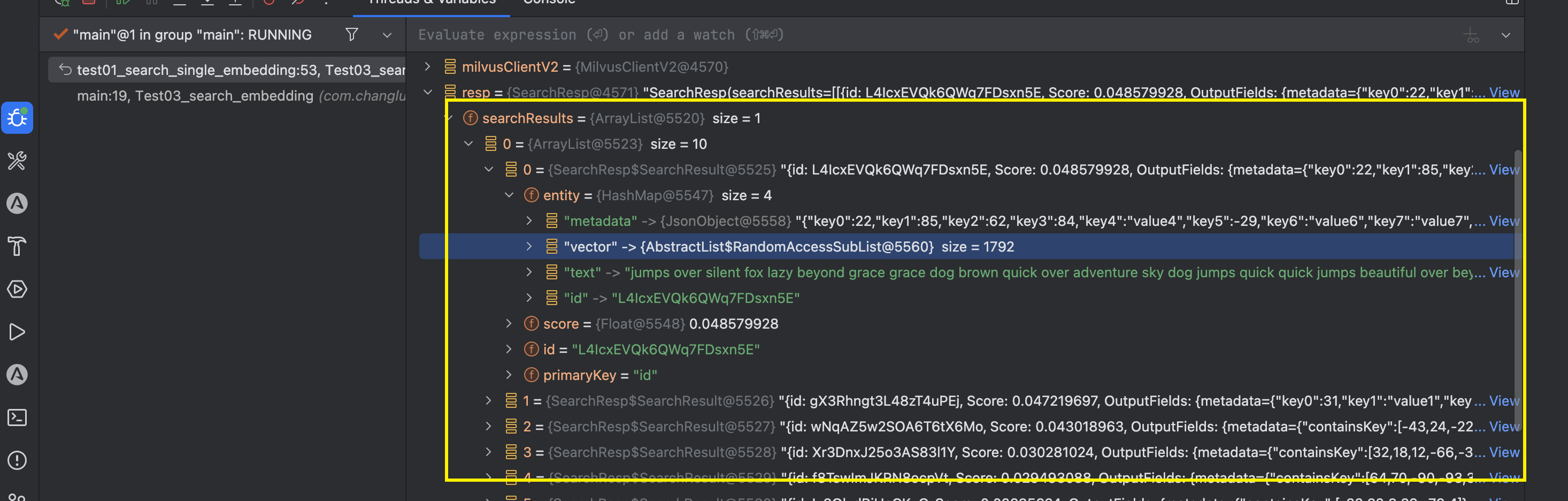
官方search查询的结果
entity是这样子的一组查询的结果:
资料获取
大家点赞、收藏、关注、评论啦~
精彩专栏推荐订阅:在下方专栏👇🏻
- 长路-文章目录汇总(算法、后端Java、前端、运维技术导航):博主所有博客导航索引汇总
- 开源项目Studio-Vue---校园工作室管理系统(含前后台,SpringBoot+Vue):博主个人独立项目,包含详细部署上线视频,已开源
- 学习与生活-专栏:可以了解博主的学习历程
- 算法专栏:算法收录
更多博客与资料可查看👇🏻获取联系方式👇🏻,🍅文末获取开发资源及更多资源博客获取🍅