自注意力机制 QKV 深度解析
Query - 查询
Key - 键
Value - 值
QKV是自注意力机制的核心三要素 ,本质是通过三次线性变换 将输入特征映射为三个向量,再通过 ,查询 - 键匹配" 计算注意力权重 ,最终对 "值向量" 加权融合,实现特征间全局关联的自适应建模。
|---------------|-----------------------------|----------------------------------------------|
| 向量 | 类比人工质检的动作 | 工业视觉中的特征对应 |
| Query(查询) | 盯住当前待检测的目标(如某个电容、某条划痕) | 输入特征图中当前位置的特征向量(如 CNN 输出的某个元件的形状 + 位置特征) |
| Key(键) | 板上所有可用于比对的参考目标(如所有电阻、电容、焊点) | 输入特征图中所有位置的特征向量(全局范围内的所有元件 / 缺陷特征) |
| Value(值) | 参考目标的核心特征(如元件的标准位置、尺寸) | 与 Key 一一对应的待加权融合的特征向量(最终用来生成全局关联特征) |
核心结论:
- Query 和 Key 的作用是计算 "注意力权重"(衡量当前特征与全局其他特征的关联度);
- Value 的作用是根据权重进行特征融合(关联度高的特征占比更大)。
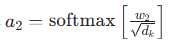 =自注意力机制中「生成注意力权重」的核心步骤,本质是对 Query 和 Key 的点积结果做缩放 + Softmax 归一化,最终得到衡量特征间关联度的权重矩阵。
=自注意力机制中「生成注意力权重」的核心步骤,本质是对 Query 和 Key 的点积结果做缩放 + Softmax 归一化,最终得到衡量特征间关联度的权重矩阵。
举例
|-------|-------|-------|-------|
| ## 权重 | C | E | F |
| C | X | X | X |
| E | X | X | X |
| F | X | X | X |
该公式的的完整展开为:
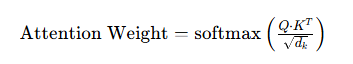
这个公式承担了自注意力机制中最关键的权重分配任务,分为两步执行,每一步都有明确的数学和工程意义。
1. 第一步:缩放操作 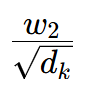
这里的缩放是防止 Softmax 饱和的核心手段,我们用数学推导解释必要性:



自注意力机制
NLP举例
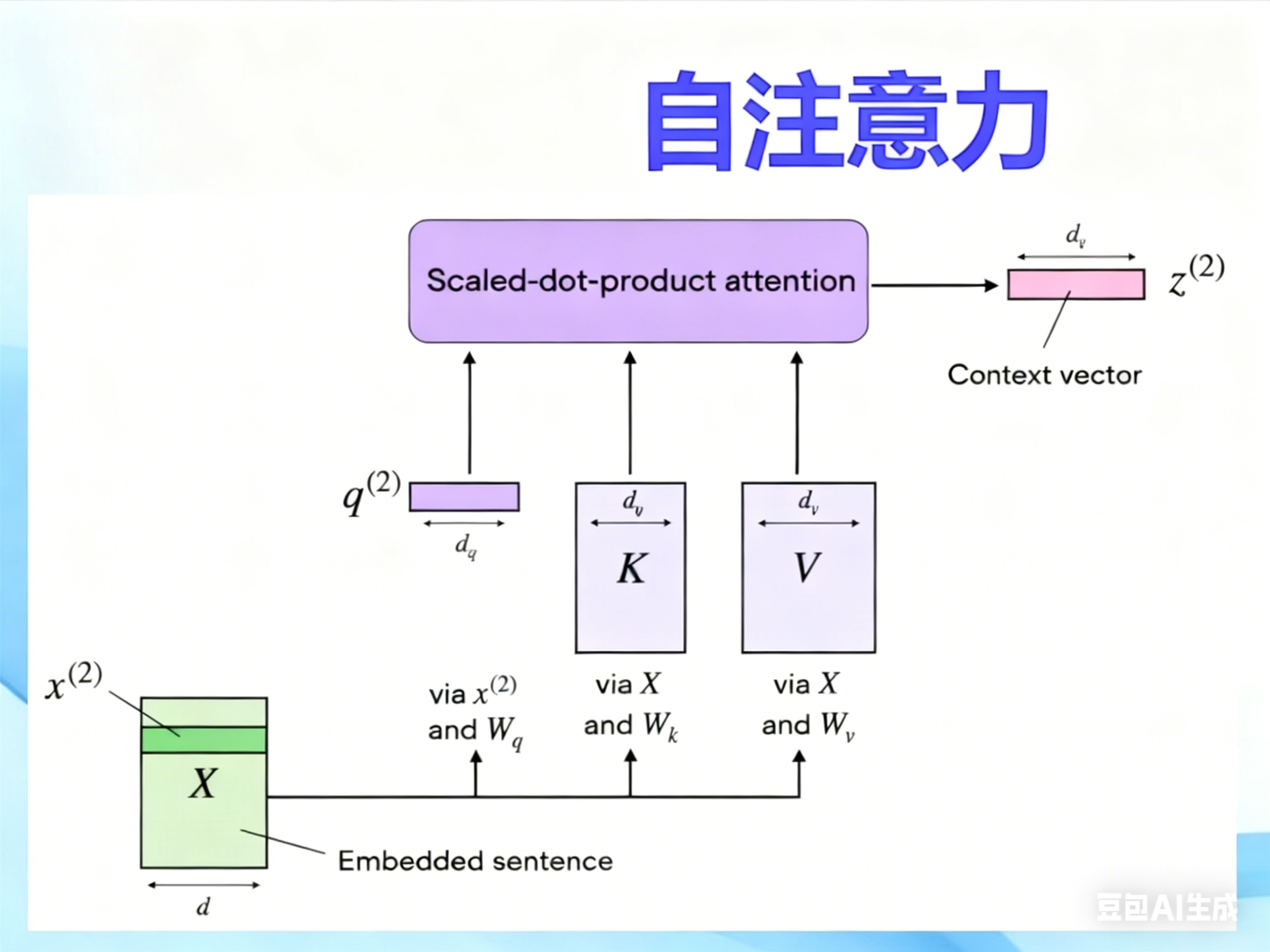 对输入的文本 分词->向量
对输入的文本 分词->向量


举例例如 C E F是三个四条信息的输入端 3x4 那么
Wq要求假设是输出2的那就结果是3x2的
Wk要求假设是输出2的那就结果是3x2的
Wq要求假设是输出4的那就结果是3x4的
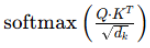 =Q*K*V=3x3*3x4=3x4
=Q*K*V=3x3*3x4=3x4