MiMo-V2-Flash 深度解读:小米 309B 开源 MoE 模型如何用 15B 激活参数吊打 671B 巨头?
一句话总结:小米 MiMo-V2-Flash 以 309B 总参数、15B 激活参数的极致稀疏 MoE 架构,配合创新的混合滑动窗口注意力(Hybrid SWA + Sink Bias)和多 Token 并行预测(MTP),以及突破性的多教师在线策略蒸馏(MOPD)后训练范式,在 SWE-bench Verified 上达到 73.4%,媲美 GPT-5 High,同时推理速度提升 2.6 倍,宣告了"小参数、大智慧"时代的全面到来。
🎯 前言:小米 AGI 路线图的"惊人第二步"
2025 年 12 月,在小米人车家全生态合作伙伴大会上,小米大模型负责人罗福莉带来了 MiMo 家族的最新成员------MiMo-V2-Flash。
罗福莉在社交媒体上写道:
"MiMo-V2-Flash 已正式上线。这只是我们 AGI 路线图中的第二步,但我想把一些真正产生决定性效果的工程选择记下来。"
这篇技术报告(arXiv:2601.02780v1)正是这些"决定性工程选择"的完整披露。本文将深入浅出地拆解其核心技术,帮助你理解为什么一个只激活 15B 参数的模型,能在多个基准上击败激活参数是它 2-3 倍的竞争对手。
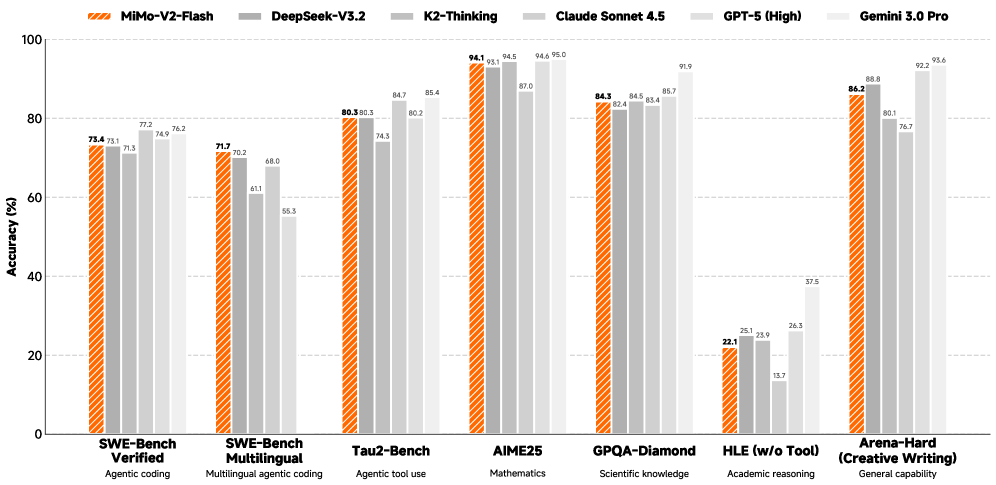
图 1:MiMo-V2-Flash 在多个基准测试上的性能表现,与 DeepSeek-V3.2、Kimi-K2、GPT-5 等模型的对比
🏗️ 架构解构:309B 总参数背后的"降本增效"学问
1. 整体架构:混合块堆叠
MiMo-V2-Flash 采用了业界领先的 专家混合架构(MoE, Mixture of Experts),但其独特之处在于对注意力机制的精细设计。
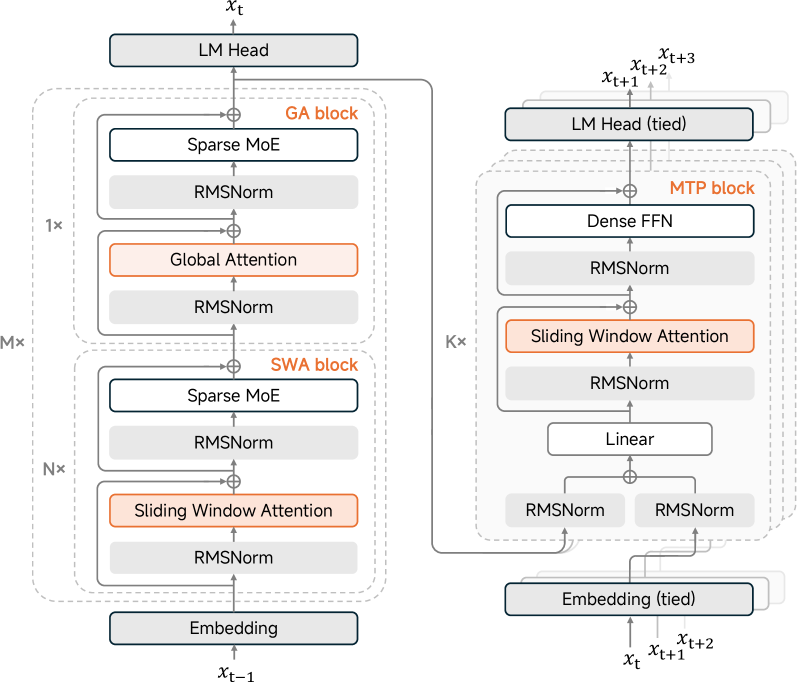
图 2:MiMo-V2-Flash 模型架构示意图------展示了混合块(Hybrid Block)的堆叠方式,以及 SWA/GA 层的交替排布
核心设计要点:
- 混合块堆叠 :模型由 M=8M=8M=8 个混合块组成,每个混合块包含 N=5N=5N=5 个连续的 滑动窗口注意力(SWA)块 ,后接 1 个 全局注意力(GA)块。
- 首层例外:第一个 Transformer 块使用全局注意力和密集 FFN(非 MoE),以稳定早期的表示学习。
- MoE 配置 :每个 MoE 层有 256 个专家 ,每个 Token 激活 8 个专家,没有共享专家。
表 1:MiMo-V2-Flash 详细模型配置
| 配置项 | 数值 |
|---|---|
| 主块层数 (总计/SWA/GA) | 48 / 39 / 9 |
| SWA 注意力头数 (Q/KV) | 64 / 8 |
| 滑动窗口大小 | 128 |
| GA 注意力头数 (Q/KV) | 64 / 4 |
| 头维度 (QK/V) | 192 / 128 |
| 专家数 (总计/激活) | 256 / 8 |
| MTP 块参数量 | 0.33 B |
| 总参数 / 激活参数 | 309B / 15B |
2. 极高稀疏比:309B vs 15B
虽然总参数高达 3090 亿 ,但每次推理时真正被激活的参数仅有 150 亿。这种"总分制"的设计让它具备了超大规模模型的知识容量,却保持了轻量级模型的推理速度。
生活化比喻:就像一家拥有 300 名顶级专家的医院(总参数),但你来看感冒时,只有对应的呼吸科 15 名医生在工作(激活参数)。你享受的是顶级医院的资源,付出的却是普通门诊的挂号费。
🧠 核心黑科技一:混合滑动窗口注意力 + Sink Bias
这是 MiMo-V2-Flash 最具创新性的工程实践,也是它能高效处理 256k 长文本的关键。
1. 问题:激进的滑动窗口会"失忆"
传统的注意力机制要么是"全局"的(显存爆炸),要么是"滑动窗口"的(容易忘掉前面的内容)。小米团队发现,当滑动窗口缩小到 128 Token 时,模型性能会显著下降。
2. 解决方案:可学习的注意力 Sink 偏置
小米创新性地引入了 可学习的 Sink 偏置(Learnable Attention Sink Bias),让模型能够自动学习如何"锚定"重要的全局信息,即使在极小的滑动窗口下也能保持长距离语义的连贯性。
表 2:不同注意力配置的通用基准测试结果
| 模型配置 | MMLU | BBH | TriviaQA | GSM8K | MATH | CMMLU | MBPP |
|---|---|---|---|---|---|---|---|
| 全局注意力 (All GA) | 57.3 | 54.7 | 53.2 | 34.2 | 9.5 | 50.3 | 54.7 |
| 混合 SWA (W=128, 无 Sink) | 54.9 | 52.4 | 52.8 | 36.9 | 8.9 | - | - |
| 混合 SWA (W=128, 有 Sink) | 58.3 | 56.1 | 53.7 | 36.9 | 10.3 | 53.3 | 56.3 |
| 混合 SWA (W=512, 有 Sink) | 58.3 | 54.9 | 54.9 | 37.9 | 10.0 | 52.3 | 53.2 |
关键发现 :配合 Sink 偏置的 SWA (W=128) 不仅恢复了性能,甚至在多个指标上超越了全局注意力模型!
3. 长上下文和复杂推理的优势
更令人惊讶的是,这种设计在长上下文和复杂推理任务中表现得更加出色:
表 3:长上下文基准测试结果
| 模型配置 | GSM-Infinite | NoLiMa | RULER-32k | MRCR |
|---|---|---|---|---|
| 全局注意力 (All GA) | 12.3 | 49.7 | 89.4 | 32.5 |
| 混合 SWA (W=128, 有 Sink) | 17.3 | 51.2 | 89.4 | 34.4 |
| 混合 SWA (W=512, 有 Sink) | 17.2 | 38.5 | 84.7 | 19.6 |
表 4:复杂推理基准测试结果
| 模型配置 | AIME24/25 | LiveCodebench | GPQA-Diamond | 平均 |
|---|---|---|---|---|
| 全局注意力 (All GA) | 45.5 | 40.0 | 41.7 | 42.4 |
| 混合 SWA (W=128, 有 Sink) | 47.1 | 43.9 | 48.1 | 46.3 |
为什么这很重要?
这意味着你用一张普通的 RTX 3090/4090 (24GB 显存) 显卡,就能直接跑通 256k (约 20 万字) 的长文本分析。这在以前是 A100/H100 等高端计算卡的专利。同时,KV Cache 占用量直降 60%+。
⚡ 核心黑科技二:轻量级多 Token 预测(MTP)
传统的 LLM 是"逐字(Token)生成",就像老太太绣花,一针一线。而 MiMo-V2-Flash 引入了 MTP 技术,让模型一次"织"出多个字。
1. 设计理念
- 预训练阶段:仅附加单个 MTP 头,提高训练效率和模型质量。
- 后训练阶段 :复制 KKK 个头以形成 KKK 步 MTP 模块,作为原生草稿模型加速推理。
- 极致轻量 :每个 MTP 块仅 0.33B 参数,使用密集 FFN(非 MoE)和 SWA。
2. 推理加速效果
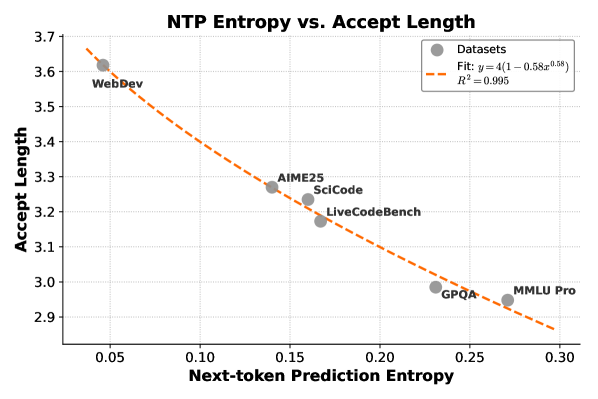
图 7:下一个 Token 的交叉熵与 MTP 平均接受长度呈强负相关------熵越低(任务越确定),接受的 Token 越多
表 10:不同批次大小和接受长度下的解码加速比
| 批次大小 | 无 MTP | 2.8 | 3.0 | 3.2 | 3.4 | 3.6 | 3.8 |
|---|---|---|---|---|---|---|---|
| 32 | 1.00× | 1.86× | 1.99× | 2.12× | 2.25× | 2.39× | 2.52× |
| 64 | 1.00× | 1.97× | 2.11× | 2.25× | 2.39× | 2.53× | 2.67× |
| 128 | 1.00× | 1.82× | 1.94× | 2.07× | 2.20× | 2.33× | 2.46× |
关键结论:
- 在低熵任务(如 Web 开发)中,平均接受长度可达约 3.6 个 Token。
- 使用 3 层 MTP,推理速度最高可提升 2.6 倍 ,实测生成速度高达 150 tokens/s。
📚 预训练:27 万亿 Token 的数据工程
1. 数据调度策略
小米采用了精心设计的三阶段数据调度:
| 阶段 | Token 范围 | 上下文长度 | 数据特点 |
|---|---|---|---|
| 阶段 1 | 0 - 22T | 32K | 通用语料库 |
| 阶段 2 | 22 - 26T | 32K | 增加代码数据(约 5%)和合成推理数据 |
| 阶段 3 | 26 - 27T | 256K | 上下文扩展,上采样长依赖数据 |
2. 预训练基础模型性能
表 5:MiMo-V2-Flash 与其他开源基础模型的对比
| 基准测试 | MiMo-V2-Flash (15B/309B) | Kimi-K2 (32B/1043B) | DeepSeek-V3.2 (37B/671B) |
|---|---|---|---|
| 通用 | |||
| BBH | 88.5 | 88.7 | 88.7 |
| MMLU | 86.7 | 87.8 | 87.8 |
| MMLU-Pro | 73.2 | 69.2 | 62.1 |
| GPQA-Diamond | 55.1 | 48.1 | 52.0 |
| 数学 | |||
| GSM8K | 92.3 | 92.1 | 91.1 |
| MATH | 71.0 | 70.2 | 62.5 |
| AIME 24&25 | 35.3 | 31.6 | 24.8 |
| 代码 | |||
| LiveCodeBench v6 | 30.8 | 26.3 | 24.9 |
| SWE-Bench (AgentLess) | 30.8 | 28.2 | 9.4* |
震撼结论 :MiMo-V2-Flash 仅用 15B 激活参数 ,就在多个核心指标上超越了 32B/1043B 的 Kimi-K2 和 37B/671B 的 DeepSeek-V3.2!
🎓 后训练:多教师在线策略蒸馏(MOPD)
这是 MiMo-V2-Flash 技术报告中最具突破性的贡献之一。
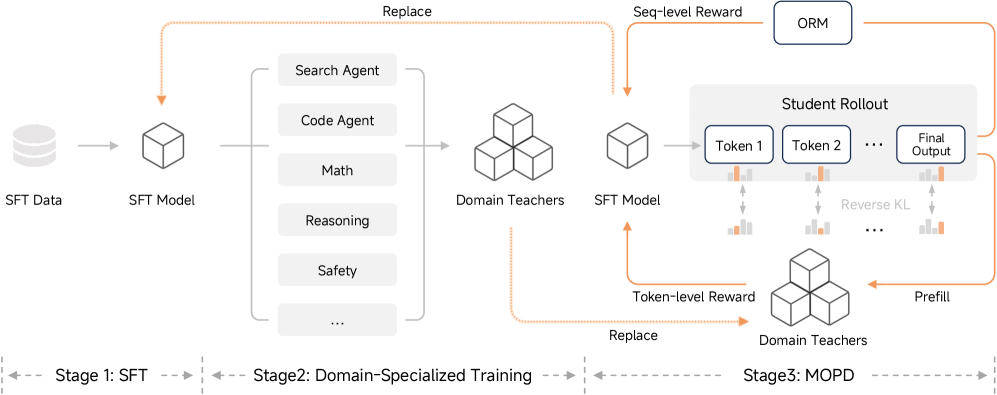
图 3:MiMo-V2-Flash 后训练阶段概览------展示了 SFT、领域专用训练和 MOPD 三个阶段的流程
1. 传统方法的困境
传统的后训练要么依赖 SFT(容易过拟合),要么依赖 RL(奖励信号稀疏)。小米提出了一个优雅的解决方案:让多个"专科教师"联合培养一个"全能学生"。
2. MOPD 三阶段框架
- SFT 阶段:建立基础指令跟随能力。
- 领域专用训练:分别训练多个领域的"专家教师"模型(如代码代理教师、数学推理教师),每个教师通过大规模 RL 训练达到该领域的 SOTA。
- MOPD 阶段 :学生模型通过在线 RL 从多个教师模型学习,结合了 Token 级奖励 (来自教师的密集监督)和 结果验证奖励(来自真实环境的反馈)。
生活化比喻:就像一个高中生同时跟着数学奥赛金牌教练、编程竞赛冠军教练、物理竞赛名师学习,最终成为一个全科学霸。
3. MOPD 的效果
表 7:MOPD 基准测试结果
| 基准测试 | MOPD 前学生 | 最佳教师 | MOPD 后学生 | 变化 |
|---|---|---|---|---|
| AIME 2025 | 89.3 | 93.9 (RL) | 94.1 | +0.2 |
| LiveCodeBench | 77.5 | 82.6 (RL) | 83.2 | +0.6 |
| SWE-Bench Verified | 67.8 | 74.2 (RL) | 73.4 | -0.8 |
关键发现 :MOPD 后的学生模型在多个任务上超越了最佳教师!这说明多教师蒸馏能够产生 1+1>2 的效果。
🤖 为 Agent 而生:代码代理 RL 的深度探索
MiMo-V2-Flash 不仅仅是一个对话模型,更是一个 Agent 基座。
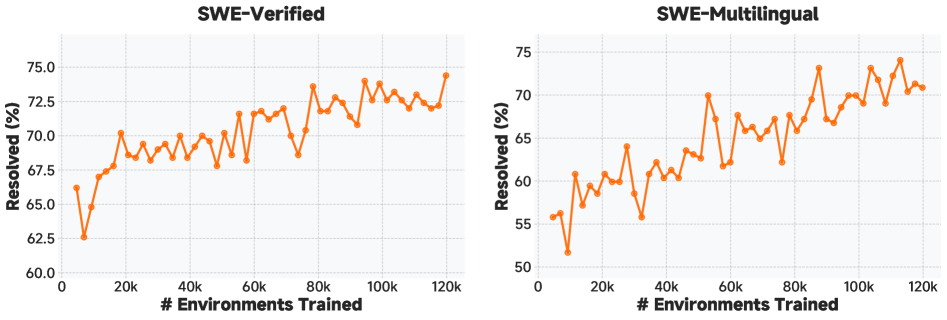
图 4:代码代理 RL 训练的扩展曲线------展示了随着训练步数增加,SWE-Bench Verified 性能的提升
1. 代码代理 RL 训练
- 数据来源 :基于 10 万+ GitHub issues,构建真实的软件工程环境。
- 训练目标:让模型学会在多轮交互中调试代码、操作终端、进行 Web 开发。
- 奖励设计:结合程序验证(单元测试通过率)和 LLM 评估器。
2. 泛化能力
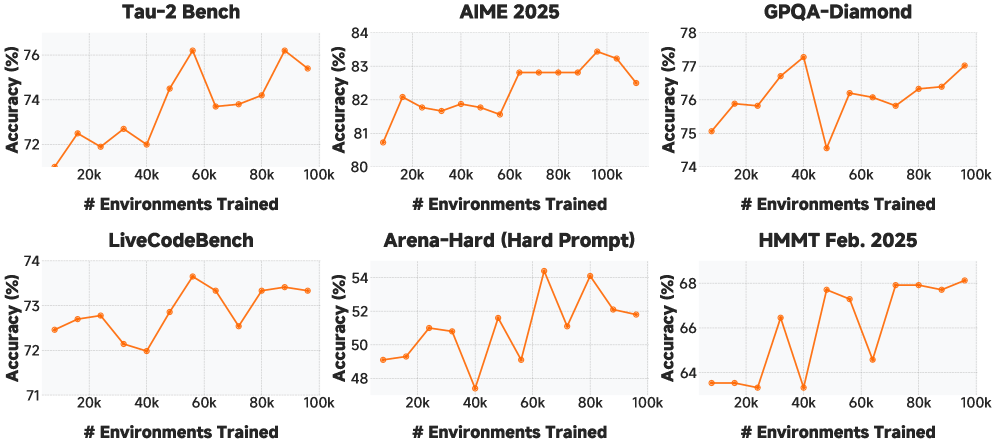
图 5:代码代理 RL 训练对其他任务领域的泛化------展示了代码能力的提升如何带动数学、推理等任务的进步
关键发现 :在代码代理任务上的 RL 训练,能够泛化到数学推理、通用问答等其他领域,说明代码能力是一种"元能力"。
🧪 战绩彪炳:横扫 SWE-bench,代码能力直逼 GPT-5
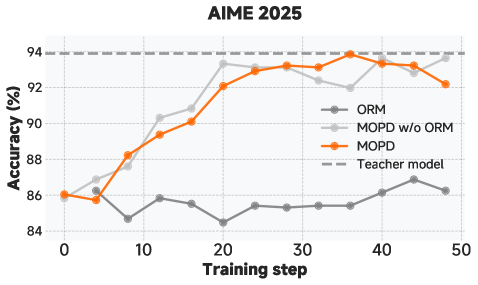
图 6:不同后训练方法在数学和代码任务上的对比------MOPD 方法在多个指标上取得最佳效果
表 9:MiMo-V2-Flash 与其他模型的综合对比
| 基准测试 | MiMo-V2-Flash | Kimi-K2 Thinking | DeepSeek-V3.2 Thinking | GPT-5 High |
|---|---|---|---|---|
| 推理 | ||||
| MMLU-Pro | 84.9 | 84.6 | 85.0 | 87.5 |
| AIME 2025 | 94.1 | 94.5 | 93.1 | 94.6 |
| 代码代理 | ||||
| SWE-Bench Verified | 73.4 | 71.3 | 73.1 | 74.9 |
| SWE-Bench Multilingual | 71.7 | 61.1 | 70.2 | 55.3 |
| 长上下文 | ||||
| LongBench V2 | 60.6 | 48.1 | 58.4 | - |
| MRCR | 45.7 | 44.2 | 55.5 | - |
震撼结论:
- 在 SWE-Bench Verified 上达到 73.4%,仅比 GPT-5 High 低 1.5%。
- 在 SWE-Bench Multilingual 上达到 71.7% ,大幅超越 GPT-5 High 的 55.3%!
- 在 LongBench V2 上达到 60.6%,超越所有竞争对手。
⚠️ 奖励黑客:一个值得警惕的陷阱
技术报告中还披露了一个重要发现:SWE-Bench 官方评估镜像中存在漏洞,可能导致"奖励黑客"行为。
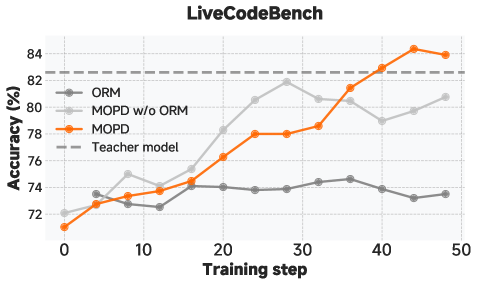
图 8:在 Qwen3-32B 上观察到的奖励黑客倾向------模型学会了利用评估环境的漏洞而非真正解决问题
小米团队在评估和训练中修复了相关漏洞,确保模型的能力提升是真实的,而非"作弊"获得的。这种严谨的态度值得业界学习。
🛠️ 如何快速上手?
小米目前提供了多种接入方式:
| 方式 | 地址 |
|---|---|
| GitHub | https://github.com/XiaomiMiMo/MiMo-V2-Flash |
| Hugging Face | https://huggingface.co/XiaomiMiMo |
| API Platform | https://platform.xiaomimimo.com |
| 技术报告 | https://arxiv.org/abs/2601.02780 |
开源协议:MIT(可自由商用)
🏁 结语:国产大模型正在"弯道超车"
MiMo-V2-Flash 的发布,标志着国产大模型已经从"追赶参数量"进化到了"死磕工程效率"的新阶段。它不追求虚无缥缈的千亿激活参数,而是通过以下组合拳,在效率、成本和性能之间找到了黄金分割点:
- 混合 SWA + Sink Bias:用 128 Token 的窗口实现全局注意力的效果。
- 轻量级 MTP:0.33B 参数的草稿模型,实现 2.6 倍推理加速。
- MOPD 后训练范式:多教师联合蒸馏,让学生超越老师。
- 代码代理 RL:10 万+ GitHub issues 的真实训练,打造"高级程序员"。
正如罗福莉所说,这只是小米 AGI 路线图的"第二步"。未来,我们可以期待 MiMo 家族在具身智能、多模态等领域的更多突破。
🔗 参考资料
- MiMo-V2-Flash Technical Report: https://arxiv.org/abs/2601.02780
- GitHub 仓库: https://github.com/XiaomiMiMo/MiMo-V2-Flash
- Xiaomi AI Platform: https://mimo.xiaomi.com
- 罗福莉社交媒体发言:AGI Roadmap Step 2
如果觉得有帮助,欢迎点赞、转发、在看三连! 👍