stable-diffusion-webui
- 二、模型推荐
-
- [1.Nova Anime XL 【二次元】](#1.Nova Anime XL 【二次元】)
-
- [1.1 绘画效果](#1.1 绘画效果)
- [1.2 绘画效果](#1.2 绘画效果)
- 一、文件夹介绍
缺少的数据可以留言我会及时补齐
缺少的数据可以留言我会及时补齐
缺少的数据可以留言我会及时补齐
二、模型推荐
1.Nova Anime XL 【二次元】
链接: Nova Anime XL - IL v15.0 | Illustrious Checkpoint | Civitai
模型类型:Checkpoint (大模型/底模)
它是一个主模型,不是 Lora,不需要挂载在别的模型上,而是直接选它来画图。
核心架构:SDXL (Stable Diffusion XL)
注意:这不是老旧的 SD 1.5 模型。
使用要求:SDXL 模型通常很大(6GB左右),画图时的推荐分辨率是 1024x1024(不同于 SD 1.5 的 512x512)。如果你的显卡显存低于 8GB,运行起来可能会比较吃力。
1.1 绘画效果
不知道为什么图片绘画完不显示
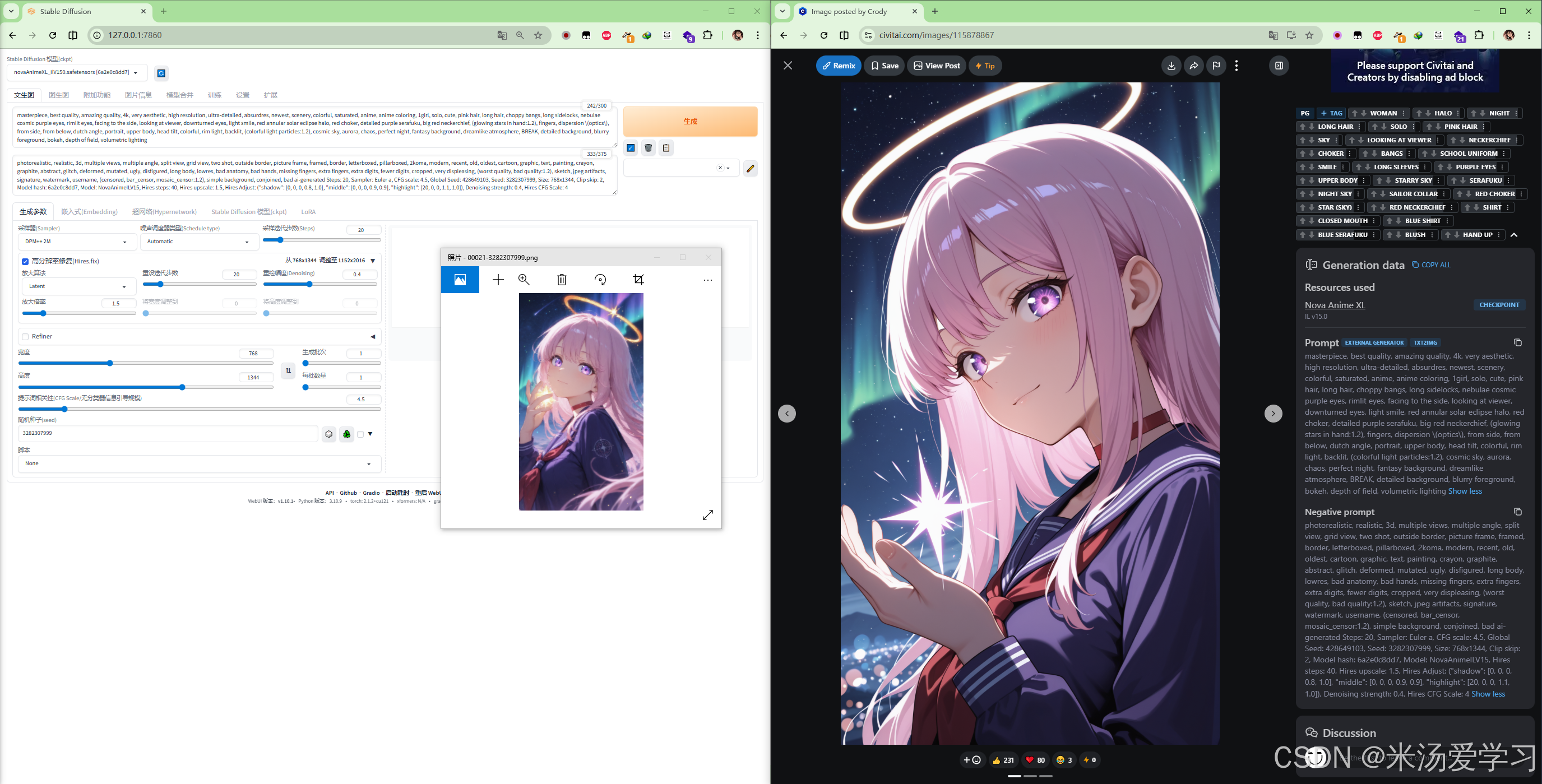
masterpiece, best quality, amazing quality, 4k, very aesthetic, high resolution, ultra-detailed, absurdres, newest, scenery, colorful, saturated, anime, anime coloring, 1girl, solo, cute, pink hair, long hair, choppy bangs, long sidelocks, nebulae cosmic purple eyes, rimlit eyes, facing to the side, looking at viewer, downturned eyes, light smile, red annular solar eclipse halo, red choker, detailed purple serafuku, big red neckerchief, (glowing stars in hand:1.2), fingers, dispersion \(optics\), from side, from below, dutch angle, portrait, upper body, head tilt, colorful, rim light, backlit, (colorful light particles:1.2), cosmic sky, aurora, chaos, perfect night, fantasy background, dreamlike atmosphere, BREAK, detailed background, blurry foreground, bokeh, depth of field, volumetric lighting
Negative prompt: photorealistic, realistic, 3d, multiple views, multiple angle, split view, grid view, two shot, outside border, picture frame, framed, border, letterboxed, pillarboxed, 2koma, modern, recent, old, oldest, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured, long body, lowres, bad anatomy, bad hands, missing fingers, extra fingers, extra digits, fewer digits, cropped, very displeasing, (worst quality, bad quality:1.2), sketch, jpeg artifacts, signature, watermark, username, (censored, bar_censor, mosaic_censor:1.2), simple background, conjoined, bad ai-generated
Steps: 20, Sampler: Euler a, CFG scale: 4.5, Global Seed: 428649103, Seed: 3282307999, Size: 768x1344, Clip skip: 2, Model hash: 6a2e0c8dd7, Model: NovaAnimeILV15, Hires steps: 20, Hires upscale: 1.5, Hires Adjust: ("shadow": [0, 0, 0, 0.8, 1.0], "middle": [0, 0, 0, 0.9, 0.9], "highlight": [20, 0, 0, 1.1, 1.0]), Denoising strength: 0.4, Hires CFG Scale: 41.2 绘画效果
自己本地画半天,不如直接给豆包绘画,甚至不用登录,哭死!!!

masterpiece, best quality, amazing quality, 4k, very aesthetic, high resolution, ultra-detailed, absurdres, newest, scenery, colorful, saturated, anime, anime coloring, high contrast, 1girl, solo, red halo, long white hair, hair between eyes, floating hair, red eyes, turning head, looking at viewer, white eyelashes, raised inner eyebrows, smile, parted lips, red angel wings, (black sundress:1.2), floating, (midair:1.2), knees up, hugging own legs, bent back, from side, dutch angle, portrait, upper body, close-up, night, starry sky, red full moon, dark, omnious, dappled moonlight, BREAK, backlighting, luminous particles, shimmering feathers, subtle lens flare, cinematic lighting, depth of field, bokeh, volumetric lighting, dreamy atmosphere
Negative prompt: photorealistic, realistic, 3d, white dress, arms behind back, devil wings, wide shot, very wide shot, full body, lens flare, sunset, multiple views, multiple angle, split view, grid view, two shot, outside border, picture frame, framed, border, letterboxed, pillarboxed, 2koma, modern, recent, old, oldest, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured, long body, lowres, bad anatomy, bad hands, missing fingers, extra fingers, extra digits, fewer digits, cropped, very displeasing, (worst quality, bad quality:1.2), sketch, jpeg artifacts, signature, watermark, username, (censored, bar_censor, mosaic_censor:1.2), simple background, conjoined, bad ai-generated
Steps: 20, Sampler: Euler a, CFG scale: 4.5, Global Seed: 718579124, Seed: 678217776, Size: 768x1344, Clip skip: 2, Model hash: 6a2e0c8dd7, Model: NovaAnimeILV15, Hires steps: 20, Hires upscale: 1.5, Denoising strength: 0.4, Hires CFG Scale: 4一、文件夹介绍
点击小数字跳转更加详细的介绍
| 文件夹 | 描述 |
|---|---|
| \ models \ Stable-diffusion \ ^[1](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | 大模型 / 底模 / Checkpoint |
| \ models \ Lora \ ^[2](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | 微调模型 / 插件 |
| \ outputs \ txt2img-images \ ^[3](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | Text to Image (文生图) - Images (单张图像) |
| \ outputs \ txt2img-grids \ ^[4](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | Text to Image (文生图) - Grids (宫格图/拼合图) |
| \ outputs \ img2img-images \ ^[5](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | Image to Image (图生图) - Images (单张图像) |
| \ outputs \ img2img-grids \ ^[6](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | Image to Image (图生图) - Grids (宫格图) |
| \ outputs \ extras-images \ ^[7](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | Extras (后期处理/附加功能) - Images |
| \ repositories \ ^[8](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | 核心依赖的源代码仓库 |
| \ repositories \ BLIP \ ^[9](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | 反推提示词,生成 Prompt |
| \ repositories \ generative-models \ ^[10](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | 跑最新、最强的 SDXL 模型 |
| \ repositories \ k-diffusion \ ^[11](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | 采样器 (Sampler) 仓库,决定画画的具体笔法 |
| \ repositories \ stable-diffusion-stability-ai \ ^[12](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | 跑老版本核心架构 (SD 1.5 / 2.0) |
| \ repositories \ stable-diffusion-webui-assets \ ^[13](#文件夹 描述 \ models \ Stable-diffusion \ 1 大模型 / 底模 / Checkpoint \ models \ Lora \ 2 微调模型 / 插件 \ outputs \ txt2img-images \ 3 Text to Image (文生图) - Images (单张图像) \ outputs \ txt2img-grids \ 4 Text to Image (文生图) - Grids (宫格图/拼合图) \ outputs \ img2img-images \ 5 Image to Image (图生图) - Images (单张图像) \ outputs \ img2img-grids \ 6 Image to Image (图生图) - Grids (宫格图) \ outputs \ extras-images \ 7 Extras (后期处理/附加功能) - Images \ repositories \ 8 核心依赖的源代码仓库 \ repositories \ BLIP \ 9 反推提示词,生成 Prompt \ repositories \ generative-models \ 10 跑最新、最强的 SDXL 模型 \ repositories \ k-diffusion \ 11 采样器 (Sampler) 仓库,决定画画的具体笔法 \ repositories \ stable-diffusion-stability-ai \ 12 跑老版本核心架构 (SD 1.5 / 2.0) \ repositories \ stable-diffusion-webui-assets \ 13 静态资源与离线支持,保证界面显示正常)^ | 静态资源与离线支持,保证界面显示正常 |
1.文件夹详细解释
-
\ models \ Stable-diffusion \ (大模型 / 底模 / Checkpoint)
意思:这里存放的是 Checkpoints(主模型/底模)。
作用:这是绘图的基础。它包含了大量的数据,决定了 AI 生成图片的主体画风和基础能力。没有这个模型,AI 无法生成任何图片。
比如:你想画二次元动漫图,你需要下载一个动漫风格的大模型(如 AnythingV5);你想画这就真人的照片,你需要下载一个写实风格的大模型(如 ChilloutMix 或 SDXL)。
文件特征-体积大:通常在 2GB 到 6GB 甚至更大。
文件特征-后缀名:.safetensors (推荐,更安全) 或 .ckpt。
如何使用:把下载好的大模型放入此文件夹。在 WebUI 网页界面的左上角下拉菜单中选择它。 ↩︎ -
\ models \ Lora \
意思:这里存放的是 LoRA (Low-Rank Adaptation) 模型。
作用:这是一个轻量级的微调插件,它必须挂载在"大模型"之上运行。它用来向 AI 灌输特定的概念。
比如:你用了一个通用的动漫大模型,但你想画"原神里的雷电将军",你就需要去下载一个"雷电将军"的 Lora 模型;或者你想让画面呈现"盲盒风格"、"水墨画风格",也可以通过加载对应的 Lora 来实现。
文件特征-体积小:通常在 10MB 到 300MB 之间。
文件特征-后缀名:绝大多数为 .safetensors。
如何使用:把下载好的 Lora 文件放入此文件夹。在 WebUI 界面中,点击生成按钮下方的"红色小卡片"图标(Extra Networks),选择 Lora 标签页点击使用。
或者在提示词(Prompt)中加入指令,例如:<lora:模型名字:0.8> (0.8代表权重,即影响力度)。 ↩︎
-
\ outputs \ txt2img-images \
含义:Text to Image (文生图) - Images (单张图像)。
作用:这里存放的是你在"文生图"模式下生成的每一张独立的原始图片。
特点:这是你最需要关注的文件夹;图片通常是全分辨率的(例如 512x512 或 1024x1024)。
文件结构:默认情况下,它会按日期(如 2023-10-27)自动建立子文件夹,当天的图都在当天的文件夹里。 ↩︎ -
\ outputs \ txt2img-grids \
含义:Text to Image (文生图) - Grids (宫格图/拼合图)。
作用:当你一次性生成多张图片(比如设置了 Batch size > 1 或 Batch count > 1)时,系统会自动把这一批次的所有图片拼合成一张大图,方便你在一张图里预览这一批次的所有结果。这张拼合的大图就放在这里。
特点:这是一张"索引图"或"目录图";如果你通常一次只生成一张图,这个文件夹可能看起来比较空,或者只有单张图的重复。
注意:很多老手为了节省硬盘空间,会在设置里把"Always save all generated image grids"(总是保存宫格图)关掉,因为有了单张图其实就不太需要这个拼合图了。 ↩︎ -
\ outputs \ img2img-images \
含义:Image to Image (图生图) - Images (单张图像)。
作用:存放你在"图生图"模式下生成的每一张独立图片。
场景:当你上传一张草图让 AI 细化,或者给照片换脸时,结果存在这里。 ↩︎ -
\ outputs \ img2img-grids \
含义:Image to Image (图生图) - Grids (宫格图)。
作用:存放"图生图"模式下的批量拼合预览图(同 txt2img-grids 原理一样)。 ↩︎ -
\ outputs \ extras-images \
含义:Extras (后期处理/附加功能) - Images。
作用:存放你在 Extras(后期处理) 选项卡中生成的图片。
场景:当你使用 WebUI 自带的"高清修复"、"图片放大(Upscale)"或"抠图"功能时,处理好的图片会保存在这里,而不是在 txt2img 文件夹里。 ↩︎ -
\ repositories8 \
简单来说,这里面存放的是 WebUI 运行所必须的、从 GitHub 上克隆下来的外部程序代码,是系统自动安装的底层依赖,删了 WebUI 就启动不了。下面详细介绍 ↩︎
-
\ repositories8 \ BLIP \
全称:Bootstrapping Language-Image Pre-training
功能:"看图说话"专家。
具体作用:当你使用 WebUI 的 "反推提示词" (Interrogate CLIP) 功能时,就是它在工作;你上传一张图片,点击按钮,BLIP 会分析图片内容,然后告诉你:"这是一张照片,里面有一个女孩,站在街道上,夕阳......",从而帮你生成 Prompt。 ↩︎ -
\ repositories8 \ generative-models \
功能:SDXL 模型架构支持。
具体作用:这是 Stability AI 推出的新一代代码库。它的主要任务是让 WebUI 能够运行 SDXL (Stable Diffusion XL) 系列的大模型。
如果你下载了 SDXL Base 1.0 或相关的微调大模型(通常 6GB+),就是靠这个文件夹里的代码来加载和运行的。 ↩︎
-
\ repositories8 \ k-diffusion \
全称:Karras Diffusion
功能:采样器 (Sampler) 仓库。
具体作用:你在 WebUI 界面左侧看到的那个长长的"采样方法"列表(例如 Euler a, DPM++ 2M Karras, Heun 等),这些算法的代码全部都在这里。它决定了噪点是如何一步步变成清晰图像的。没有它,AI 就不知道怎么"下笔"去画画。 ↩︎
-
\ repositories8 \ stable-diffusion-stability-ai \
功能:老版本核心架构 (SD 1.5 / 2.0)。
具体作用:这是 Stable Diffusion 最经典版本的代码库。目前市面上最流行的 SD 1.5 模型(如 ChilloutMix, Anything 等)以及 SD 2.0/2.1 模型,都是依靠这个文件夹里的代码来驱动的。
它是 WebUI 的"老地基"。 ↩︎
-
\ repositories8 \ stable-diffusion-webui-assets \
功能:静态资源与离线支持。
具体作用:这里存放的是 WebUI 自身需要的一些杂物,主要是字体文件(如 Roboto 字体)和其他静态资源。为什么要这个? 为了让你在没有网络的情况下,或者生成"XY 图表"添加文字标签时,系统能找到对应的字体文件,而不需要每次都去网上下载。 ↩︎