前言
了解了Agent和LLM的一些基础知识后,直接上python开始调API
代码实现
环境准备
先装好python,创建项目目录,安装必要库
bash
pip install openai python-dotenv配置API密钥
创建 .env 文件并添加API密钥:
env
OPENAI_API_KEY=your_openai_api_key获取 OpenAI API 密钥
打开OpenAI获取API密钥地址:platform.openai.com/api-keys
直接Google账号或者Microsoft账号登录OpenAI,然后完善一下基本资料,就能创建API密钥了
创建好以后,把key保存好,然后下一步,非常专业的操作,上来就付费,选择稍后再买
激活虚拟环境
bash
# Linux/Mac
. venv/bin/activate
# Windows
venv\Scripts\activate这一步是因为我用的 virtualenv 虚拟环境管理工具,系统全局 Python,直接使用即可
代码示例
官方Demo
创建 test_openai.py 文件,代码如下
python
from openai import OpenAI
client = OpenAI(
api_key="api-key" # 替换为你自己的API密钥
)
# 调用 OpenAI 的 responses.create 接口生成文本
# 参数说明:
# model="gpt-5-nano" - 指定使用的模型为 gpt-5-nano(轻量版)
# input="write a haiku about ai" - 输入提示词,要求写一首关于 AI 的俳句
# store=True - 将本次请求及结果存储到后台,用于后续分析或优化
response = client.responses.create(
model="gpt-5-nano",
input="请创作一首关于AI的短诗",
store=True,
)
print(response.output_text);在终端中使用 python test_openai.py 命令运行文件,即可看到输出结果,如下效果则说明调用成功了
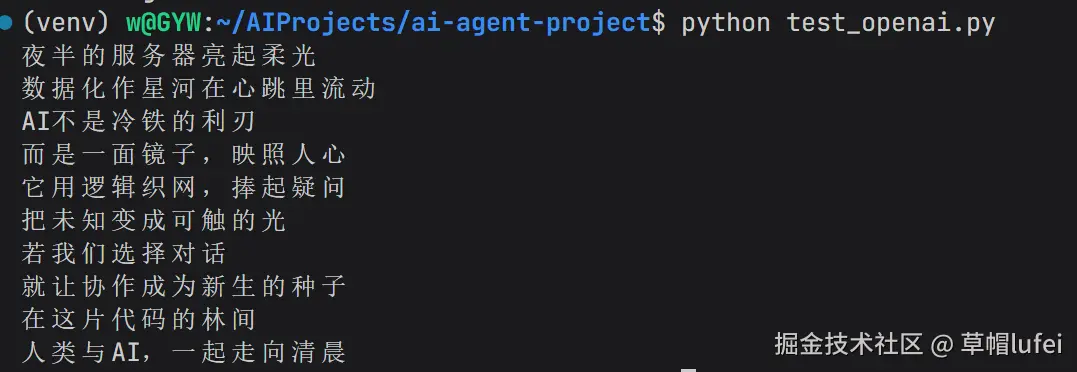
简单文本生成
将 test_openai.py 代码中的 api_key="api-key" 替换为 api_key=os.getenv("OPENAI_API_KEY"),并把 key 放到对应的 .env 文件中
python
import os
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量
load_dotenv()
# 初始化客户端
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
# 简单文本生成
response = client.chat.completions.create(
model="gpt-5-nano",
messages=[
{"role": "system", "content": "你是一个友好的助手。"},
{"role": "user", "content": "请解释什么是AI Agent。"}
]
)
print(response.choices[0].message.content)同级目录下创建 .env 文件,内容如下
env
OPENAI_API_KEY=your_openai_api_key
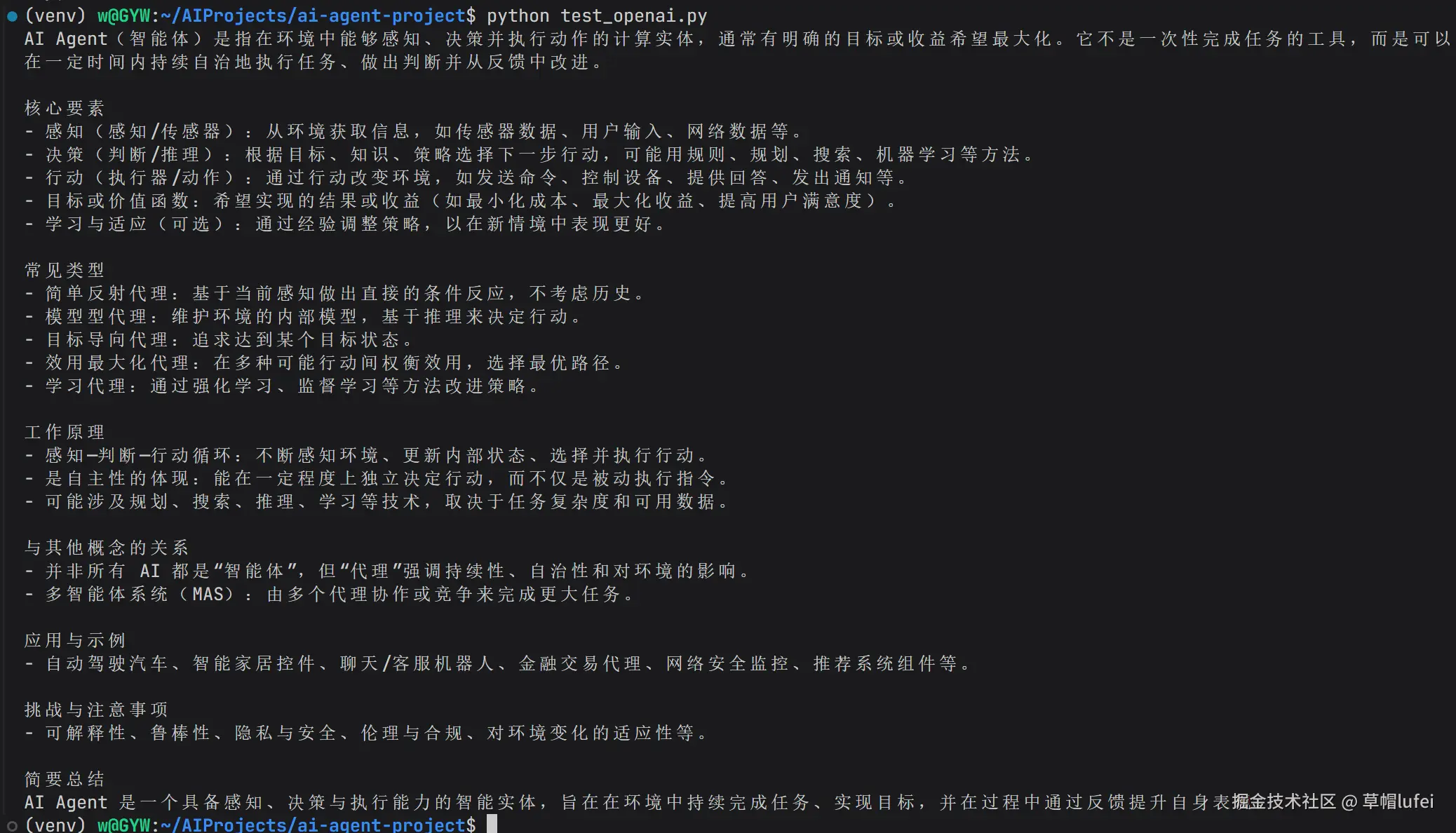
再次执行 test_openai.py 文件,即可看到输出结果,如下效果则说明调用成功了
上面通过调用 OpenAI 的 responses.create 接口生成文本已经知道了,下面看多轮对话的例子
多轮对话
多轮对话就是在一次对话中,用户和AI系统进行多次交互,就像我们日常用豆包之类的一样
还能定义角色,例如让 AI 专业导师,然后回答问题,代码示例如下
python
import os
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量
load_dotenv()
# 初始化客户端
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
messages = [
{"role": "system", "content": "你是一个专业的AI导师。"},
{"role": "user", "content": "什么是大语言模型?"},
{"role": "assistant", "content": "大语言模型是一种基于深度学习的人工智能模型,能够理解和生成人类语言..."},
{"role": "user", "content": "它和传统NLP模型有什么区别?"}
]
response = client.chat.completions.create(
model="gpt-5-nano",
messages=messages
)
print(response.choices[0].message.content)注意,message前三行是对话历史的一部分,用于构建多轮对话的上下文
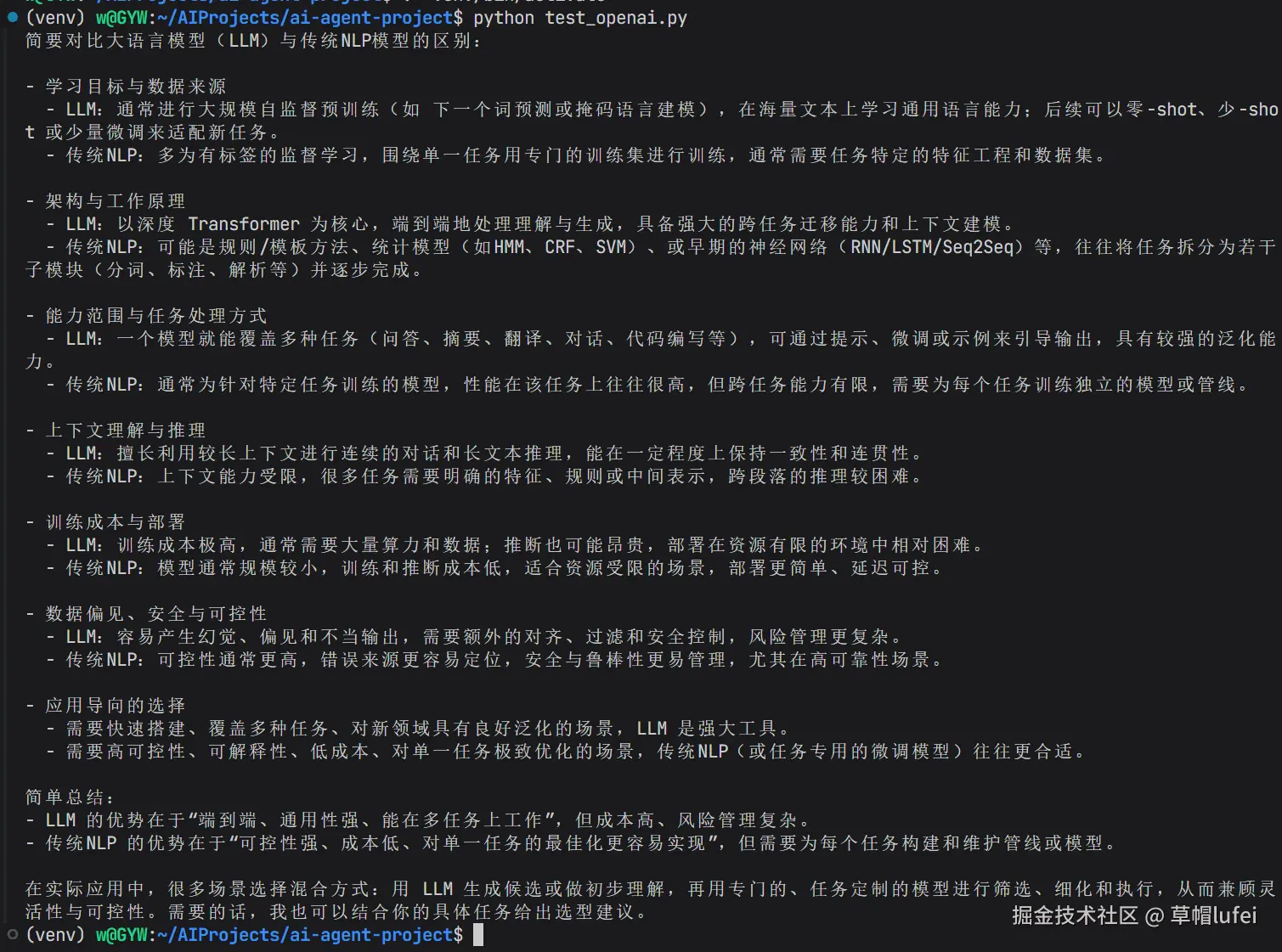
再次运行后,会看到AI提供了继续的回答
分析图片
下面是一个分析图片的例子,图片地址为接了一个图上传到图床,图中是一只柴犬狗
python
import os
from dotenv import load_dotenv
from openai import OpenAI
# 加载环境变量
load_dotenv()
# 初始化客户端
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY"))
from openai import OpenAI
client = OpenAI()
response = client.responses.create(
model="gpt-5-nano",
input=[
{
"role": "user",
"content": [
{
"type": "input_text",
"text": "这个图片中有什么?",
},
{
"type": "input_image",
"image_url": "https://raw.githubusercontent.com/gywgithub/image-bed/main/20260109204706397.png"
}
]
}
]
)
print(response.output_text)图片效果

看看执行代码后的输出,分析的挺好,我就知道这图里面有只柴犬

小结
运行了三个简单的例子后,了解了API的基本调用方法和流程,后面将会继续学习如何用工具扩展模型能力,以及流式响应等等
欢迎留言交流,如果觉得有帮助,可以
点个赞支持一下公众号:草帽lufei