
在上一篇Everything Claude Code 速查指南中,我涵盖了基础配置:技能(skills)和命令(commands)、钩子(hooks)、子代理(subagents)、MCPs、插件(plugins),以及构成高效 Claude Code 工作流骨干的配置模式。那是一份配置指南和基础设施。
这篇长篇指南深入探讨了将高效会话与浪费性会话区分开来的技术。如果你还没有读过简明指南,请先回去配置好你的设置。接下来的内容假设你已经配置好了技能、代理、钩子和 MCPs 并且它们已正常运行。
这里的主题包括:token 经济学、记忆持久化、验证模式、并行化策略,以及构建可复用工作流的复合效应。这些是我在超过10个月的日常使用中精炼出的模式,它们决定了你是在第一个小时内就被上下文腐烂(context rot)所困扰,还是能够维持数小时的高效会话。
简明和长篇文章中涵盖的所有内容都可在 GitHub 上获取:everything-claude-code
Context & Memory Management
上下文与记忆管理
对于跨会话共享记忆,最好的方法是使用一个技能或命令来总结并检查进度,然后保存到你的 .claude 文件夹中的 .tmp 文件,并在会话结束前持续追加内容。第二天它可以将其作为上下文来使用,从你上次中断的地方继续,为每个会话创建一个新文件,这样你就不会把旧的上下文污染到新的工作中。最终你会有一个很大的会话日志文件夹------只需将其备份到有意义的地方,或者修剪你不需要的会话对话。Claude 会创建一个总结当前状态的文件。查看它,如果需要可以要求修改,然后开始新的对话。对于新对话,只需提供文件路径。当你达到上下文限制并需要继续复杂工作时,这特别有用。这些文件应该包含------哪些方法有效(可验证且有证据)、哪些尝试过的方法没有效果、哪些方法尚未尝试以及还剩什么要做。
 会话存储示例 -> github.com/affaan-m/ev...
会话存储示例 -> github.com/affaan-m/ev...
策略性清除上下文:
一旦你的计划设定好并且上下文已清除(现在是 Claude Code 计划模式中的默认选项),你就可以从计划开始工作。当你积累了大量不再与执行相关的探索性上下文时,这很有用。对于策略性压缩,禁用自动压缩。在逻辑间隔处手动压缩,或创建一个技能为你执行此操作,或在某些定义的标准下提出建议。
Strategic Compact Skill(直接链接):
(嵌入以供快速参考)
bash
#!/bin/bash
# Strategic Compact Suggester
# Runs on PreToolUse to suggest manual compaction at logical intervals
#
# Why manual over auto-compact:
# - Auto-compact happens at arbitrary points, often mid-task
# - Strategic compacting preserves context through logical phases
# - Compact after exploration, before execution
# - Compact after completing a milestone, before starting next
COUNTER_FILE="/tmp/claude-tool-count-$$"
THRESHOLD=${COMPACT_THRESHOLD:-50}
# Initialize or increment counter
if [ -f "$COUNTER_FILE" ]; then
count=$(cat "$COUNTER_FILE")
count=$((count + 1))
echo "$count" > "$COUNTER_FILE"
else
echo "1" > "$COUNTER_FILE"
count=1
fi
# Suggest compact after threshold tool calls
if [ "$count" -eq "$THRESHOLD" ]; then
echo "[StrategicCompact] $THRESHOLD tool calls reached - consider /compact if transitioning phases" >&2
fi将它挂钩到 Edit/Write 操作的 PreToolUse 上------当你积累了足够多的上下文、压缩可能有帮助时,它会提醒你。
进阶:动态系统提示注入(Advanced: Dynamic System Prompt Injection)
我学到并正在试运行的一种模式是:不要只把所有东西放在 CLAUDE.md(用户范围)或 .claude/rules/(项目范围)中(这些每次会话都会加载),而是使用 CLI 标志来动态注入上下文。
bash
claude --system-prompt "$(cat memory.md)"这让你可以更精确地控制何时加载什么上下文。你可以根据当前工作内容在每个会话中注入不同的上下文。
为什么这比 @ 文件引用更重要: 当你使用 @memory.md 或将内容放在 .claude/rules/ 中时,Claude 通过 Read 工具在对话过程中读取它------它作为工具输出传入。当你使用 --system-prompt 时,内容在对话开始前被注入到实际的系统提示中。
区别在于指令层级(instruction hierarchy)。系统提示内容的权威性高于用户消息,用户消息的权威性高于工具结果。对于大多数日常工作来说,这种差异是微不足道的。但对于诸如严格的行为规则、项目特定的约束,或你绝对需要 Claude 优先考虑的上下文------系统提示注入确保它得到适当的权重。
实际配置:
一种有效的方法是将 .claude/rules/ 用于你的基线项目规则,然后为场景特定的上下文设置 CLI 别名,可以在它们之间切换:
bash
# Daily development
alias claude-dev='claude --system-prompt "$(cat ~/.claude/contexts/dev.md)"'
# PR review mode
alias claude-review='claude --system-prompt "$(cat ~/.claude/contexts/review.md)"'
# Research/exploration mode
alias claude-research='claude --system-prompt "$(cat ~/.claude/contexts/research.md)"'System Prompt Context Example Files(直接链接):
dev.md专注于实现review.md专注于代码质量/安全research.md专注于行动前的探索
同样,对于大多数情况,使用 .claude/rules/context1.md 和直接将 context1.md 附加到系统提示之间的区别是微乎其微的。CLI 方法更快(无需工具调用)、更可靠(系统级权威)且稍微更节省 token。但这是一个小优化,对许多人来说开销大于收益。
进阶:记忆持久化钩子(Advanced: Memory Persistence Hooks)
有一些钩子(hooks)是大多数人不知道的,或者知道但没有真正利用的,它们有助于记忆管理:
plaintext
SESSION 1 SESSION 2
───────── ─────────
[Start] [Start]
│ │
▼ ▼
┌──────────────┐ ┌──────────────┐
│ SessionStart │ ◄─── reads ─────── │ SessionStart │◄── loads previous
│ Hook │ nothing yet │ Hook │ context
└──────┬───────┘ └──────┬───────┘
│ │
▼ ▼
[Working] [Working]
│ (informed)
▼ │
┌──────────────┐ ▼
│ PreCompact │──► saves state [Continue...]
│ Hook │ before summary
└──────┬───────┘
│
▼
[Compacted]
│
▼
┌──────────────┐
│ Stop Hook │──► persists to ──────────►
│ (session-end)│ ~/.claude/sessions/
└──────────────┘- PreCompact Hook: 在上下文压缩发生之前,将重要状态保存到文件中
- SessionComplete Hook: 在会话结束时,将学习成果持久化到文件中
- SessionStart Hook: 在新会话开始时,自动加载之前的上下文
Memory Persistent Hooks(直接链接):
(嵌入以供快速参考)
json
{
"hooks": {
"PreCompact": [{
"matcher": "*",
"hooks": [{
"type": "command",
"command": "~/.claude/hooks/memory-persistence/pre-compact.sh"
}]
}],
"SessionStart": [{
"matcher": "*",
"hooks": [{
"type": "command",
"command": "~/.claude/hooks/memory-persistence/session-start.sh"
}]
}],
"Stop": [{
"matcher": "*",
"hooks": [{
"type": "command",
"command": "~/.claude/hooks/memory-persistence/session-end.sh"
}]
}]
}
}这些的作用:
pre-compact.sh:记录压缩事件,用压缩时间戳更新活动会话文件session-start.sh:检查最近的会话文件(最近7天),通知可用的上下文和已学习的技能session-end.sh:创建/更新每日会话文件模板,跟踪开始/结束时间
将这些串联起来,即可实现跨会话的持续记忆,无需手动干预。这建立在第一篇文章中的钩子类型(PreToolUse、PostToolUse、Stop)之上,但专门针对会话生命周期。
Continuous Learning / Memory
持续学习 / 记忆
我们之前讨论了以更新代码地图(codemaps)的形式进行持续记忆更新,但这也适用于其他方面,比如从错误中学习。如果你不得不多次重复提示,而 Claude 遇到了相同的问题或给了你以前听过的回答,那这部分就适用于你。很可能你需要发送第二个提示来"重新引导(resteer)"并校准 Claude 的方向。这适用于任何此类场景------这些模式必须被追加到技能中。
现在你可以通过简单地告诉 Claude 记住它或将其添加到你的规则中来自动完成此操作,或者你可以有一个技能来专门做这件事。
问题: 浪费 token,浪费上下文,浪费时间,你的皮质醇飙升,因为你沮丧地对 Claude 大喊不要做你在之前会话中已经告诉它不要做的事情。
解决方案: 当 Claude Code 发现一些非平凡的东西------调试技术、变通方法、某些项目特定的模式------它会将该知识保存为新技能。下次出现类似问题时,技能会自动加载。
Continuous Learning Skill(直接链接):
为什么我使用 Stop hook 而不是 UserPromptSubmit?UserPromptSubmit 在你发送的每条消息上都会运行------这会带来很大的开销,给每个提示增加延迟,坦率地说对这个目的来说是大材小用。Stop 在会话结束时只运行一次------轻量级,不会在会话期间拖慢你的速度,而且评估的是完整会话而非碎片化的内容。
安装:
bash
# Clone to skills folder
git clone https://github.com/affaan-m/everything-claude-code.git ~/.claude/skills/everything-claude-code
# Or just grab the continuous-learning skill
mkdir -p ~/.claude/skills/continuous-learning
curl -sL https://raw.githubusercontent.com/affaan-m/everything-claude-code/main/skills/continuous-learning/evaluate-session.sh > ~/.claude/skills/continuous-learning/evaluate-session.sh
chmod +x ~/.claude/skills/continuous-learning/evaluate-session.shHook Configuration(直接链接):
json
{
"hooks": {
"Stop": [
{
"matcher": "*",
"hooks": [
{
"type": "command",
"command": "~/.claude/skills/continuous-learning/evaluate-session.sh"
}
]
}
]
}
}这使用 Stop hook 在每个提示上运行一个激活脚本,评估会话中值得提取的知识。该技能也可以通过语义匹配激活,但钩子确保了一致的评估。
Stop hook 在你的会话结束时触发------脚本分析会话中值得提取的模式(错误解决方案、调试技术、变通方法、项目特定模式等),并将它们保存为 ~/.claude/skills/learned/ 中的可复用技能。
手动提取 - /learn:
你不必等到会话结束。仓库中还包含一个 /learn 命令,你可以在会话中途刚解决了一些非平凡的问题时运行它。它会提示你立即提取模式,起草一个技能文件,并在保存前征求确认。参见这里。
会话日志模式:
该技能期望会话日志保存在 .tmp 文件中。模式为:~/.claude/sessions/YYYY-MM-DD-topic.tmp------每个会话一个文件,包含当前状态、已完成项目、阻碍因素、关键决定和下次会话的上下文。示例会话文件在仓库的 examples/sessions/ 中。
其他自我改进的记忆模式:
来自 @RLanceMartin 的一种方法涉及反思会话日志以提炼用户偏好------本质上是建立一个记录什么有效、什么无效的"日记"。每次会话后,一个反思代理(reflection agent)提取哪些做得好、哪些失败了、你做了哪些修正。这些学习成果会更新一个记忆文件,在后续会话中加载。
来自 @alexhillman 的另一种方法是让系统每15分钟主动建议改进,而不是等你注意到模式。代理审查最近的交互,提出记忆更新建议,你批准或拒绝。随着时间推移,它会从你的批准模式中学习。
Token Optimization
Token 优化
我从价格敏感的消费者那里收到了很多问题,或者那些作为重度用户经常遇到限制问题的人。在 token 优化方面,有一些技巧可以使用。
主要策略:子代理架构
主要是优化你使用的工具和子代理架构,旨在将最便宜的、足以完成任务的模型委派出去以减少浪费。你有几个选项------可以尝试试错法并随着进展调整。一旦你了解了什么是什么,你就可以区分哪些委派给 Haiku、哪些委派给 Sonnet、哪些委派给 Opus。
基准测试方法(更深入):
另一种更深入的方法是,你可以让 Claude 设置一个基准测试,在一个有明确目标、任务和明确计划的仓库中。在每个 git worktree 中,让所有子代理都使用同一个模型。在任务完成时记录日志------理想情况下在你的计划和任务中记录。你必须至少使用每个子代理一次。
一旦完成一轮完整测试并且任务已从你的 Claude 计划中勾选完毕,停下来审核进度。你可以通过比较差异(diffs)、创建在所有 worktree 中统一的单元测试、集成测试和端到端测试来做到这一点。这将给你一个基于通过/失败案例的数值基准。如果所有 worktree 都全部通过,你需要添加更多的边界测试用例或增加测试的复杂度。这可能值得也可能不值得做,取决于这对你来说到底有多重要。
模型选择快速参考:
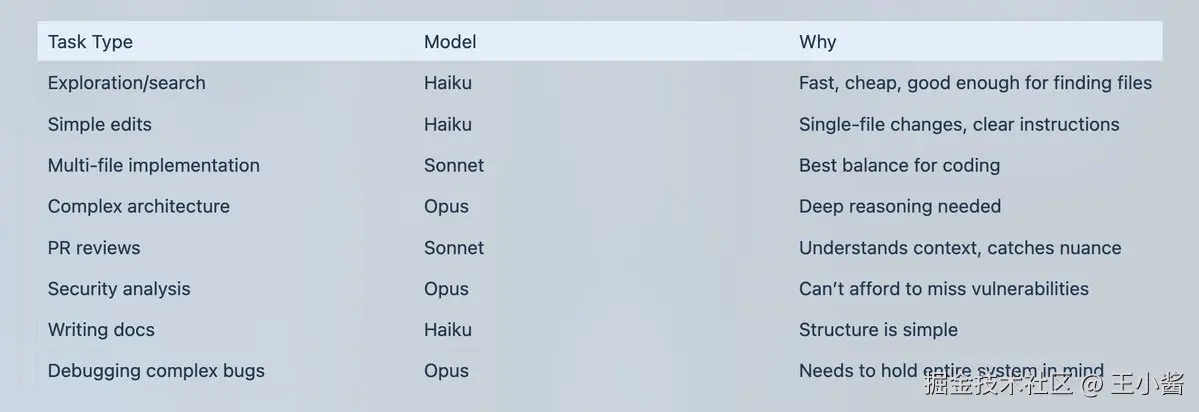
各种常见任务上子代理的假设配置及选择背后的推理
90% 的编码任务默认使用 Sonnet。当首次尝试失败、任务跨越5个以上文件、架构决策或安全关键代码时升级到 Opus。当任务是重复性的、指令非常清晰,或在多代理设置中作为"工人(worker)"使用时降级到 Haiku。坦率地说,Sonnet 4.5 目前处于一个尴尬的位置,每百万输入 token 3,每百万输出token15,与 Opus 相比成本节省约66.7%,绝对值来说这是不错的节省,但相对而言对大多数人来说微不足道。Haiku 和 Opus 组合最有意义,因为 Haiku 与 Opus 有5倍的成本差异,而与 Sonnet 只有1.67倍的价格差异。
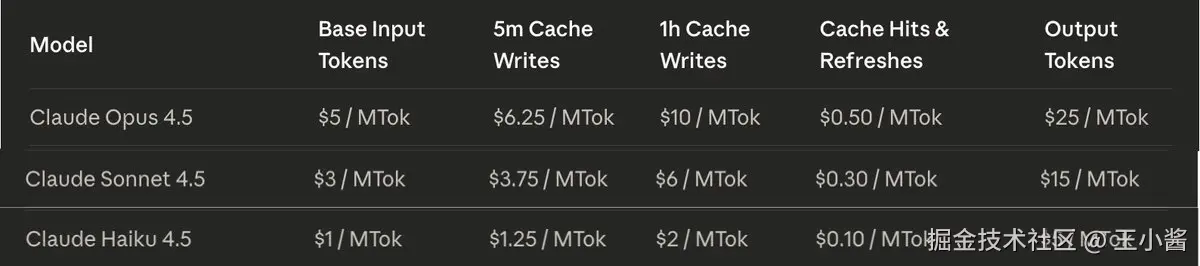
来源:platform.claude.com/docs/en/abo...
在你的代理定义中,指定模型:
yaml
---
name: quick-search
description: Fast file search
tools: Glob, Grep
model: haiku # Cheap and fast
---工具特定优化:
想想 Claude 最频繁调用的工具。例如,用 mgrep 替换 grep------在各种任务上,与传统 grep 或 ripgrep(Claude 默认使用的)相比,平均有效 token 减少约一半。
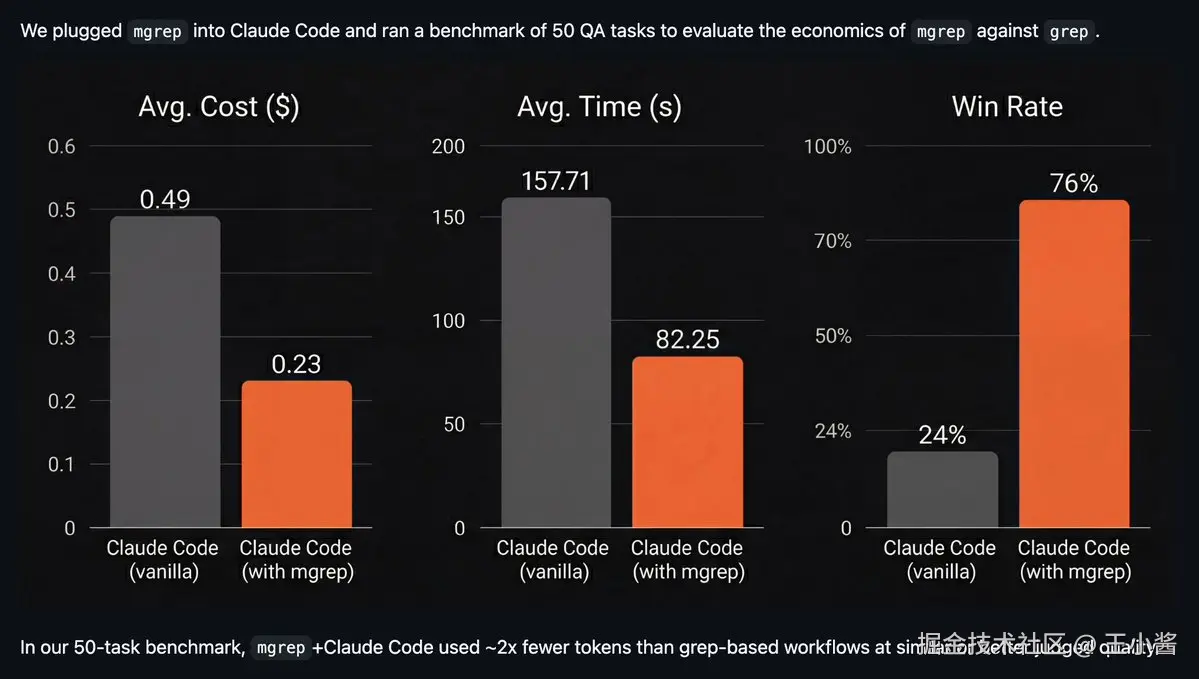
后台进程:
适用时,如果你不需要 Claude 处理整个输出并实时流式传输,请在 Claude 之外运行后台进程。这可以通过 tmux 轻松实现(参见简明指南和 Tmux Commands Reference(直接链接))。获取终端输出后,要么总结它,要么只复制你需要的部分。这将节省大量输入 token,这是大部分成本的来源------Opus 4.5 每百万 token 5,输出每百万token25。
模块化代码库的好处:
拥有更模块化的代码库,包含可复用的工具函数、函数、钩子等------主文件在数百行而非数千行------既有助于 token 优化成本,也有助于第一次就正确完成任务,两者是相关的。如果你必须多次提示 Claude,你就在大量消耗 token,尤其是当它反复读取非常长的文件时。你会注意到它需要进行大量工具调用才能读完文件。中间过程中,它会告诉你文件非常长,它将继续读取。在这个过程中的某个地方,Claude 可能会丢失一些信息。而且,停止和重新读取会消耗额外的 token。这可以通过拥有更模块化的代码库来避免。示例如下 ->
plaintext
root/
├── docs/ # Global documentation
├── scripts/ # CI/CD and build scripts
├── src/
│ ├── apps/ # Entry points (API, CLI, Workers)
│ │ ├── api-gateway/ # Routes requests to modules
│ │ └── cron-jobs/
│ │
│ ├── modules/ # The core of the system
│ │ ├── ordering/ # Self-contained "Ordering" module
│ │ │ ├── api/ # Public interface for other modules
│ │ │ ├── domain/ # Business logic & Entities (Pure)
│ │ │ ├── infrastructure/ # DB, External Clients, Repositories
│ │ │ ├── use-cases/ # Application logic (Orchestration)
│ │ │ └── tests/ # Unit and integration tests
│ │ │
│ │ ├── catalog/ # Self-contained "Catalog" module
│ │ │ ├── domain/
│ │ │ └── ...
│ │ │
│ │ └── identity/ # Self-contained "Auth/User" module
│ │ ├── domain/
│ │ └── ...
│ │
│ ├── shared/ # Code used by EVERY module
│ │ ├── kernel/ # Base classes (Entity, ValueObject)
│ │ ├── events/ # Global Event Bus definitions
│ │ └── utils/ # Deeply generic helpers
│ │
│ └── main.ts # Application bootstrap
├── tests/ # End-to-End (E2E) global tests
├── package.json
└── README.md精简代码库 = 更便宜的 Token:
这可能很明显,但你的代码库越精简,token 成本就越低。关键是要通过使用技能来持续清理代码库,利用技能和命令进行重构来识别死代码。另外在某些时候,我喜欢通读整个代码库,寻找那些让我觉得突出或看起来重复的东西,手动拼凑这些上下文,然后将其与重构技能和死代码技能一起输入给 Claude。
系统提示精简(进阶):
对于真正注重成本的人:Claude Code 的系统提示占用约18k token(200k 上下文的约9%)。这可以通过补丁减少到约10k token,节省约7,300 token(静态开销的41%)。如果你想走这条路,参见 YK 的 system-prompt-patches,我个人不这样做。
Verification Loops and Evals
验证循环与评估
评估和框架调优------取决于项目,你需要使用某种形式的可观测性和标准化。
可观测性方法:
一种方法是让 tmux 进程挂钩到追踪思维流和输出上,每当技能被触发时。另一种方法是使用 PostToolUse 钩子来记录 Claude 具体执行了什么以及确切的变更和输出是什么。
基准测试工作流:
将其与不使用技能地要求相同的事情进行比较,检查输出差异以进行相对性能基准测试:
plaintext
[Same Task]
│
┌────────────┴────────────┐
▼ ▼
┌───────────────┐ ┌───────────────┐
│ Worktree A │ │ Worktree B │
│ WITH skill │ │ WITHOUT skill │
└───────┬───────┘ └───────┬───────┘
│ │
▼ ▼
[Output A] [Output B]
│ │
└──────────┬──────────┘
▼
[git diff]
│
▼
┌────────────────┐
│ Compare logs, │
│ token usage, │
│ output quality │
└────────────────┘分叉对话,在其中一个中启动一个没有技能的新 worktree,最后查看差异,看看日志记录了什么。这与持续学习和记忆部分相关联。
评估模式类型:
更高级的评估和循环协议在这里登场。分为基于检查点的评估和基于强化学习任务的持续评估。
plaintext
CHECKPOINT-BASED CONTINUOUS
───────────────── ──────────
[Task 1] [Work]
│ │
▼ ▼
┌─────────┐ ┌─────────┐
│Checkpoint│◄── verify │ Timer/ │
│ #1 │ criteria │ Change │
└────┬────┘ └────┬────┘
│ pass? │
┌───┴───┐ ▼
│ │ ┌──────────┐
yes no ──► fix ──┐ │Run Tests │
│ │ │ │ + Lint │
▼ └────┘ │ └────┬─────┘
[Task 2] │ │
│ │ ┌────┴────┐
▼ │ │ │
┌─────────┐ │ pass fail
│Checkpoint│ │ │ │
│ #2 │ │ ▼ ▼
└────┬────┘ │ [Continue] [Stop & Fix]
│ │
... └────┘
Best for: Linear workflows Best for: Long sessions
with clear milestones exploratory refactoring基于检查点的评估:
- 在工作流中设置明确的检查点
- 在每个检查点根据定义的标准进行验证
- 如果验证失败,Claude 必须在继续之前修复
- 适合具有明确里程碑的线性工作流
持续评估:
- 每 N 分钟或在重大变更后运行
- 完整测试套件、构建状态、lint 检查
- 立即报告回归
- 在继续之前停下来修复
- 适合长时间运行的会话
决定因素是你工作的性质。基于检查点适用于具有明确阶段的功能实现。持续评估适用于探索性重构或维护,因为你没有明确的里程碑。
我会说,通过一些干预,验证方法足以避免大部分技术债务。让 Claude 在完成任务后通过运行技能和 PostToolUse 钩子来验证有助于此。持续更新代码地图也有帮助,因为它保持了变更日志以及代码地图如何随时间演变的记录,作为仓库本身之外的事实来源。通过严格的规则,Claude 会避免创建杂乱的随机 .md 文件、为相似代码创建重复文件,以及留下一片死代码的荒原。
基于代码的评分器(Code-Based Graders): 字符串匹配、二元测试、静态分析、结果验证。快速、便宜、客观,但对有效变体很脆弱。
基于模型的评分器(Model-Based Graders): 评分标准打分、自然语言断言、成对比较。灵活且能处理微妙之处,但非确定性且更昂贵。
人工评分器(Human Graders): 专家审查、众包判断、抽样检查。金标准质量,但昂贵且缓慢。
关键指标:
plaintext
pass@k: At least ONE of k attempts succeeds
┌─────────────────────────────────────┐
│ k=1: 70% k=3: 91% k=5: 97% │
│ Higher k = higher odds of success │
└─────────────────────────────────────┘
pass^k: ALL k attempts must succeed
┌─────────────────────────────────────┐
│ k=1: 70% k=3: 34% k=5: 17% │
│ Higher k = harder (consistency) │
└─────────────────────────────────────┘当你只需要它能工作且任何验证反馈就足够时,使用 pass@k 。当一致性至关重要且你需要接近确定性的输出一致性(在结果/质量/风格方面)时,使用 pass^k。
构建评估路线图(来自同一 Anthropic 指南):
- 尽早开始------从真实失败中提取20-50个简单任务
- 将用户报告的失败转化为测试用例
- 编写明确的任务------两个专家应达成相同结论
- 构建平衡的问题集------测试行为应该和不应该出现的情况
- 构建健壮的测试框架------每次试验从干净环境开始
- 评分代理产生的结果,而非它走过的路径
- 阅读许多试验的记录
- 监控饱和度------100%通过率意味着需要添加更多测试
Parallelization
并行化
在多 Claude 终端设置中分叉对话时,确保分叉中的操作范围和原始对话的操作范围都有明确定义。在代码变更方面尽量减少重叠。选择彼此正交的任务以防止干扰的可能性。
我的首选模式:
个人而言,我更喜欢主聊天用于处理代码变更,而我做的分叉是用于我对代码库及其当前状态的问题,或者做外部服务的研究,比如拉取文档、在 GitHub 上搜索适用的开源仓库来帮助任务,或其他有用的一般性研究。
关于任意终端数量:
Boris @bcherny(创建 Claude Code 的传奇人物)有一些关于并行化的建议,我对此有赞同也有不赞同的地方。他建议过类似在本地运行5个 Claude 实例和5个上游实例这样的事情。我建议不要设置这样的任意终端数量。增加一个终端和增加一个实例应该出于真正的必要性和目的。如果你可以用脚本来处理该任务,就用脚本。如果你可以留在主聊天中让 Claude 在 tmux 中启动一个实例并在单独的终端中流式传输,那就那样做。
引用推文:Boris Cherny @bcherny · 1月3日 回复 @bcherny 1/ 我在终端中并行运行5个 Claude。我给我的标签页编号1-5,并使用系统通知来知道何时 Claude 需要输入 code.claude.com/docs/en/ter...
你的目标真的应该是:用最小可行的并行化量完成尽可能多的工作。
对于大多数新手,我甚至建议在你熟练掌握单实例运行和管理一切之前远离并行化。我不是主张限制自己------我是说要小心。大多数时候,即使是我也只使用大约4个终端。我发现通常只需打开2或3个 Claude 实例就能完成大部分事情。
扩展实例时:
如果你要开始扩展你的实例,并且有多个 Claude 实例在相互重叠的代码上工作,使用 git worktrees 并为每个实例制定非常明确的计划是必不可少的。此外,为了在恢复会话时不会混淆或迷失哪个 git worktree 是做什么的(除了树的名称之外),使用 /rename <name here> 来命名你所有的聊天。
Git Worktrees 用于并行实例:
bash
# Create worktrees for parallel work
git worktree add ../project-feature-a feature-a
git worktree add ../project-feature-b feature-b
git worktree add ../project-refactor refactor-branch
# Each worktree gets its own Claude instance
cd ../project-feature-a && claude好处:
- 实例之间没有 git 冲突
- 每个都有干净的工作目录
- 容易比较输出
- 可以在不同方法之间对同一任务进行基准测试
级联方法(The Cascade Method):
当运行多个 Claude Code 实例时,使用"级联"模式来组织:
- 在右侧的新标签页中打开新任务
- 从左到右扫描,从最旧到最新
- 保持一致的方向流
- 根据需要检查特定任务
- 一次最多关注3-4个任务------超过这个数量,心理开销的增长速度会快于生产力
Groundwork
基础工作
从零开始时,实际的基础非常重要。这应该是显而易见的,但随着代码库的复杂性和规模增加,技术债务也会增加。管理它非常重要,如果你遵循一些规则,其实并不困难。除了为当前项目有效配置你的 Claude 之外(参见简明指南)。
双实例启动模式(The Two-Instance Kickoff Pattern):
对于我自己的工作流管理(不是必须的但很有帮助),我喜欢用2个打开的 Claude 实例来启动一个空仓库。
实例 1:脚手架代理(Scaffolding Agent)
- 负责搭建脚手架和基础工作
- 创建项目结构
- 配置设置(CLAUDE.md、规则、代理------简明指南中的所有内容)
- 建立约定
- 把骨架搭好
实例 2:深度研究代理(Deep Research Agent)
- 连接到你所有的服务、网络搜索等
- 创建详细的 PRD(产品需求文档)
- 创建架构 mermaid 图
- 用实际文档中的实际片段编译参考资料
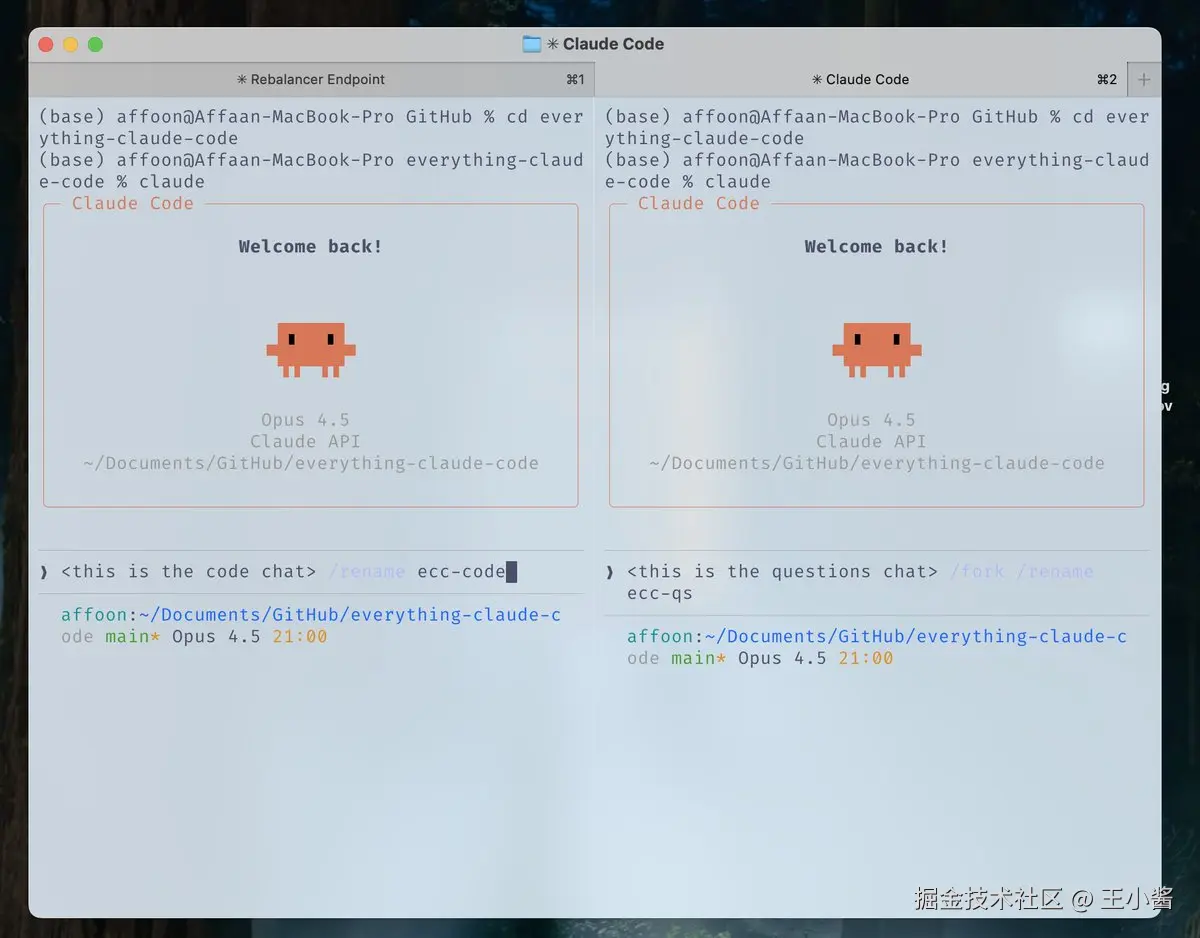
启动配置:左侧终端用于编码,右侧终端用于提问------使用 /rename 和 /fork。
最小化启动所需的内容就够了------这比每次都用 Context7 或喂链接让它抓取或使用 Firecrawl MCP 站点要快。当你已经深入某件事情且 Claude 明显语法出错或使用过时的函数或端点时,那些方法才派上用场。
llms.txt 模式:
如果可用的话,你可以在许多文档参考上通过在到达其文档页面后访问 /llms.txt 来找到一个 llms.txt 文件。这是一个示例:www.helius.dev/docs/llms.t...
这给你一个干净的、为 LLM 优化的文档版本,你可以直接提供给 Claude。
理念:构建可复用模式(Philosophy: Build Reusable Patterns)
来自 @omarsar0 的一个我完全认同的见解:"早期,我花时间构建可复用的工作流/模式。构建起来很繁琐,但随着模型和代理框架的改进,这产生了疯狂的复合效应。"
值得投资的方面:
- 子代理(简明指南)
- 技能(简明指南)
- 命令(简明指南)
- 计划模式
- MCP 工具(简明指南)
- 上下文工程模式
为什么会产生复合效应 (@omarsar0):"最棒的部分是所有这些工作流都可以转移到其他代理,如 Codex。"一旦构建完成,它们可以跨模型升级工作。投资于模式 > 投资于特定模型的技巧。
Best Practices for Agents & Sub-Agents
代理和子代理的最佳实践
在简明指南中,我列出了子代理结构------planner、architect、tdd-guide、code-reviewer 等。在这一部分,我们关注编排和执行层。
子代理上下文问题(The Sub-Agent Context Problem):
子代理的存在是为了通过返回摘要而非倾倒所有内容来节省上下文。但编排器(orchestrator)拥有子代理所缺乏的语义上下文。子代理只知道字面上的查询,不知道请求背后的目的/推理。摘要通常会遗漏关键细节。
来自 @PerceptualPeak 的类比:"你的老板让你去参加一个会议并要求你做个总结。你回来给他汇报情况。十次有九次,他会有后续问题。你的总结不会包含他需要的所有内容,因为你没有他拥有的隐含上下文。"
迭代检索模式(Iterative Retrieval Pattern):
plaintext
┌─────────────────┐
│ ORCHESTRATOR │
│ (has context) │
└────────┬────────┘
│ dispatch with query + objective
▼
┌─────────────────┐
│ SUB-AGENT │
│ (lacks context) │
└────────┬────────┘
│ returns summary
▼
┌─────────────────┐ ┌─────────────┐
│ EVALUATE │─no──►│ FOLLOW-UP │
│ Sufficient? │ │ QUESTIONS │
└────────┬────────┘ └──────┬──────┘
│ yes │ sub-agent
▼ │ fetches answers
[ACCEPT] │
◄──────────────────────┘
(max 3 cycles)要修复这个问题,让编排器:
- 评估每个子代理的返回结果
- 在接受之前询问后续问题
- 子代理回到源头,获取答案,返回
- 循环直到充分(最多3个循环以防止无限循环)
传递目标上下文,而不仅仅是查询。 当派遣子代理时,同时包含具体查询和更广泛的目标。这有助于子代理确定在其摘要中优先包含什么内容。
模式:带有顺序阶段的编排器(Pattern: Orchestrator with Sequential Phases)
markdown
Phase 1: RESEARCH (use Explore agent)
- Gather context
- Identify patterns
- Output: research-summary.md
Phase 2: PLAN (use planner agent)
- Read research-summary.md
- Create implementation plan
- Output: plan.md
Phase 3: IMPLEMENT (use tdd-guide agent)
- Read plan.md
- Write tests first
- Implement code
- Output: code changes
Phase 4: REVIEW (use code-reviewer agent)
- Review all changes
- Output: review-comments.md
Phase 5: VERIFY (use build-error-resolver if needed)
- Run tests
- Fix issues
- Output: done or loop back关键规则:
- 每个代理获得一个明确的输入并产生一个明确的输出
- 输出成为下一阶段的输入
- 永远不要跳过阶段------每个阶段都有价值
- 在代理之间使用
/clear保持上下文新鲜 - 将中间输出存储在文件中(不仅仅是记忆中)
代理抽象层级列表(Agent Abstraction Tierlist)(来自 @menhguin):
第1层:直接增益(容易使用)
- 子代理(Subagents) ------防止上下文腐烂和临时专业化的直接增益。只有多代理一半的用处,但复杂度低得多
- 元提示(Metaprompting) ------"我花3分钟来提示一个20分钟的任务。"直接增益------提高稳定性并对假设进行健全性检查
- 在开始时多问用户(Asking user more at the beginning) ------通常是增益,尽管你必须在计划模式中回答问题
第2层:高技能门槛(较难用好)
- 长时间运行的代理(Long-running agents) ------需要理解15分钟任务 vs 1.5小时 vs 4小时任务的形态和权衡。需要一些调整,而且显然是非常长的试错过程
- 并行多代理(Parallel multi-agent) ------方差非常高,仅在高度复杂或分段良好的任务上有用。"如果2个任务需要10分钟,而你花了任意时间在提示上,或者更糟糕的是合并变更,那就适得其反了"
- 基于角色的多代理(Role-based multi-agent) ------"模型演进太快,硬编码的启发式规则除非套利非常高否则没意义。"难以测试
- 计算机使用代理(Computer use agents) ------非常早期的范式,需要大量调教。"你在让模型做一年前它们绝对不应该做的事情"
要点:从第1层模式开始。只有在掌握了基础知识并有真正的需求时才升级到第2层。
Tips and Tricks
提示与技巧
一些 MCP 是可替代的,将释放你的上下文窗口
方法如下。
对于版本控制(GitHub)、数据库(Supabase)、部署(Vercel、Railway)等 MCP------这些平台中的大多数已经有健壮的 CLI,MCP 本质上只是对它们的包装。MCP 是一个不错的包装器,但它有成本。
要让 CLI 更像 MCP 一样工作,而实际上不使用 MCP(以及随之而来的上下文窗口缩减),考虑将功能捆绑到技能和命令中。剥离 MCP 暴露的使事情变得简单的工具,并将它们转化为命令。
示例:不要始终加载 GitHub MCP,而是创建一个 /gh-pr 命令来包装 gh pr create 并使用你偏好的选项。不要让 Supabase MCP 消耗上下文,而是创建直接使用 Supabase CLI 的技能。功能是一样的,便利性相似,但你的上下文窗口被释放出来用于实际工作。
这与我收到的一些其他问题相关。自从我发布原始文章以来的过去几天里,Boris 和 Claude Code 团队在记忆管理和优化方面取得了很大进展,主要是 MCP 的懒加载,使它们不再从一开始就消耗你的窗口。以前我会建议在可能的地方将 MCP 转换为技能,以两种方式之一卸载执行 MCP 的功能:在当时启用它(不太理想,因为你需要离开并恢复会话)或者拥有使用 MCP 的 CLI 类似物的技能(如果它们存在的话),让技能成为它的包装器------本质上让它充当伪 MCP。
通过懒加载,上下文窗口问题基本上已经解决。但 token 使用和成本并没有以同样的方式解决。CLI + 技能方法仍然是一种 token 优化方法,其效果可能与使用 MCP 相当或接近。此外,你可以通过 CLI 而不是在上下文中运行 MCP 操作,这显著减少了 token 使用,对于数据库查询或部署等繁重的 MCP 操作特别有用。