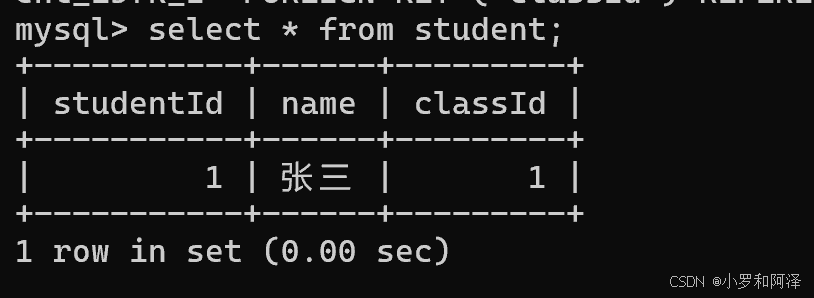
数据库操作

显示当前的数据库
show databases;
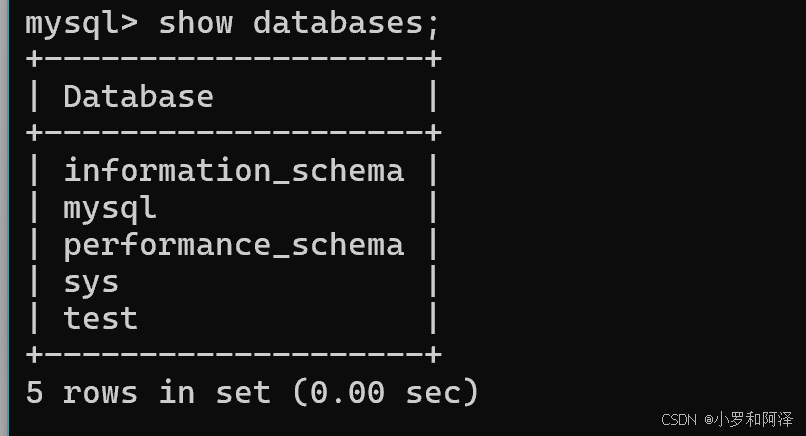 sql语句命令结尾 一定要是 ;(英文分号),如果输入 ;(中文分号)则会出现以下现象.
sql语句命令结尾 一定要是 ;(英文分号),如果输入 ;(中文分号)则会出现以下现象.
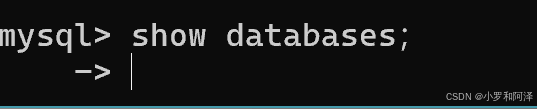
如果后续再输入英文分号,则会报错.
 初学时,大概率会出现许多问题,还请各位初学者仔细阅读报错提示,以便于找到出错位置,更正错误.
初学时,大概率会出现许多问题,还请各位初学者仔细阅读报错提示,以便于找到出错位置,更正错误.
创建数据库
create database 数据库名;
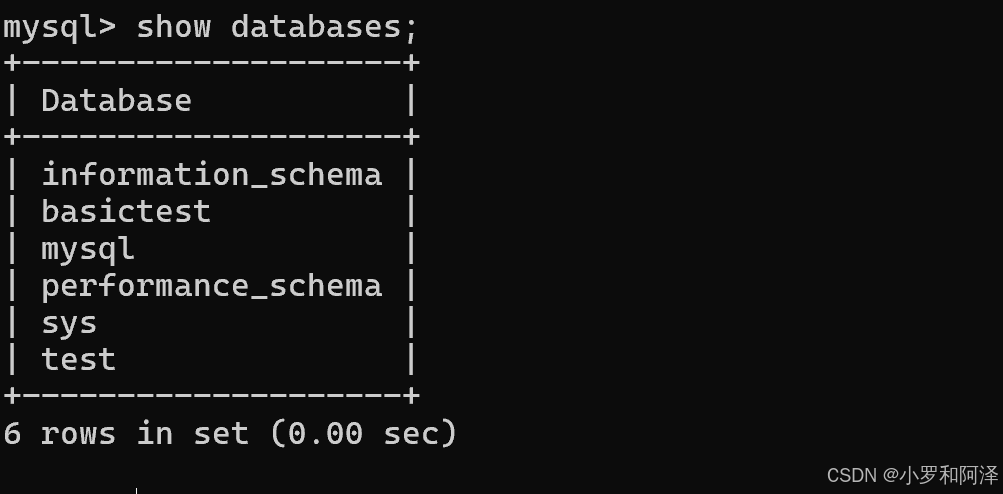
如果数据库创建成功,则会出现以下结果显示

此时也可以使用 show databases 语句 来检查 刚才的数据库是否创建成功.
 如果 创建的数据库已存在则会出现
如果 创建的数据库已存在则会出现
 因此数据库名称 在数据库服务器 上要保持唯一.
因此数据库名称 在数据库服务器 上要保持唯一.
注意事项:
1.创建数据库时,数据库的名字,不能和SQL中的"关键字"重复
2.创建数据库的名字,不能和已有的数据库名字重复
创建数据库时,往往还需要指定数据库的"字符集"
create database 数据库名 charset utf8;
如果不能正确指定字符集,后续保存中文字符时,可能会出现错误

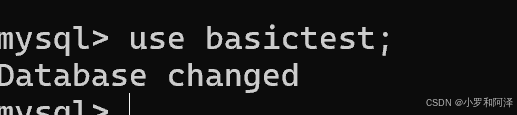
选中数据库
use 数据库名;
删除数据库
drop database 数据库名;

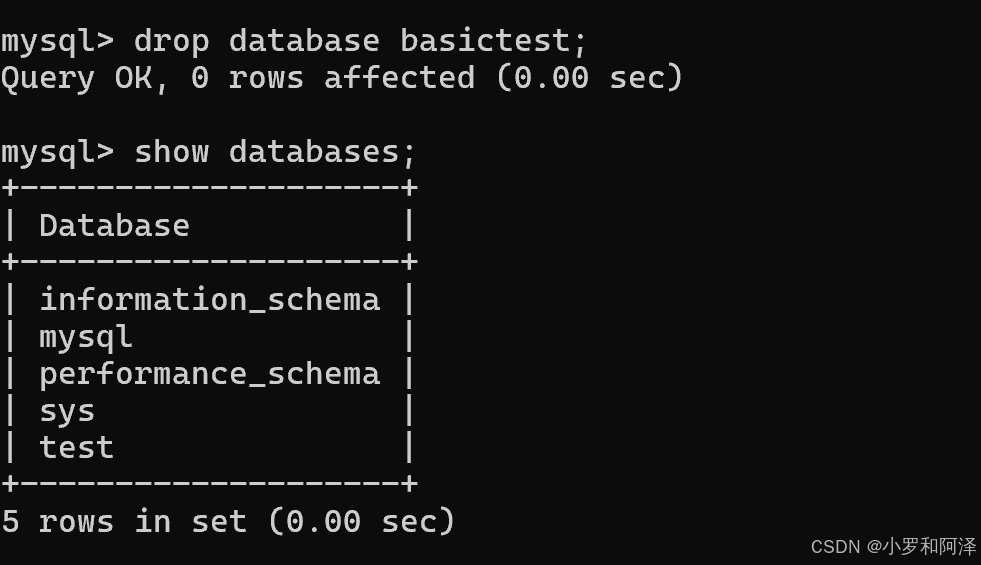
删除数据库之后,数据无法恢复,因此是一个非常危险的行为.
数据类型
数据表的操作
前提:已使用use选中数据库
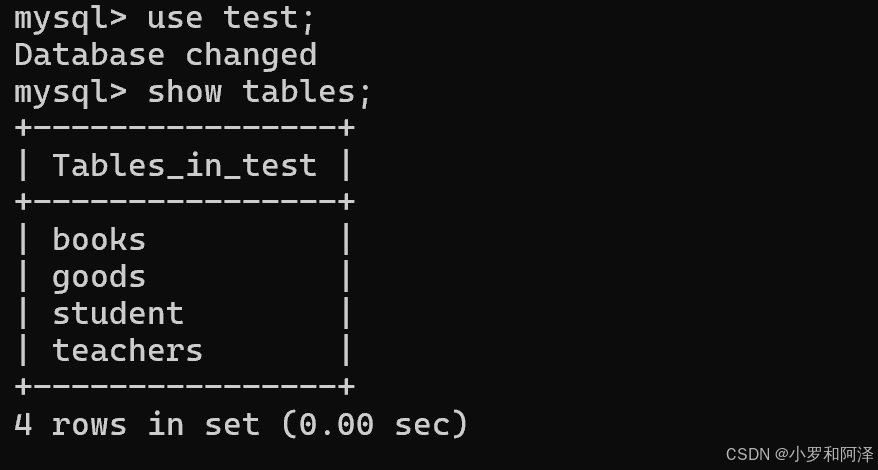
1.查看当前数据库中,有那哪些表
show tables;
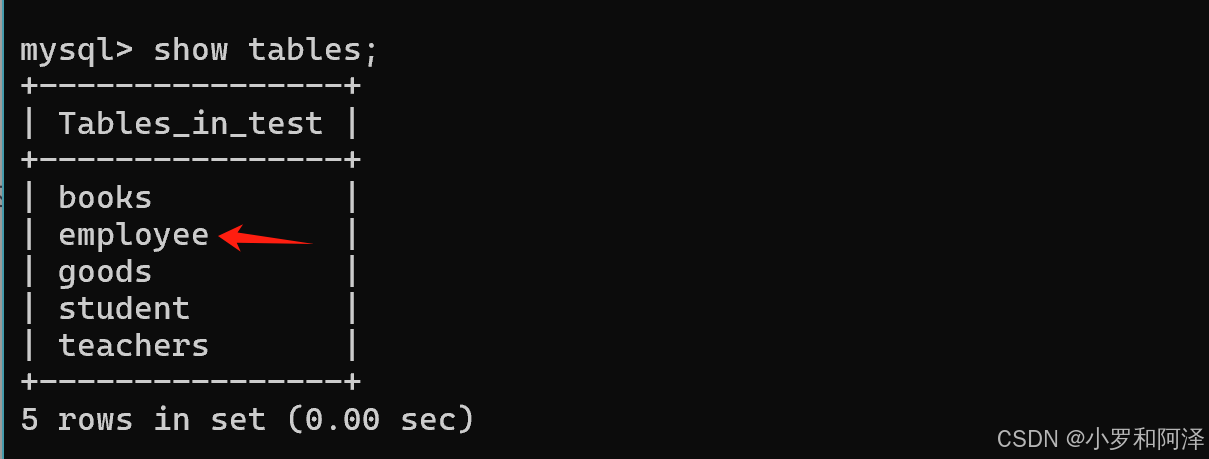
2.创建表
create table 表名(列名 类型,列名 类型,.......);

常用类型
int
bigint
double
decimal
varchar(最大字符长度)
datetime
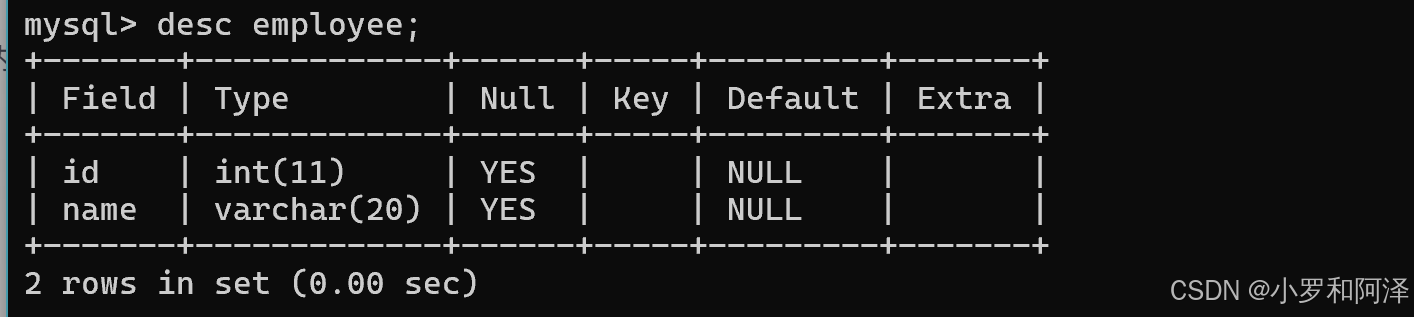
3.查看指定表的详细情况
desc 表名;
4.删除表
drop table 表名;


删表操作,也是一个非常危险的操作
表内容的操作(增删改查)
新增
insert into 表名 values (值,值,值...);

SQL中,表示字符串 可以使用 ' 也可以使用 '' ;
c/c++/Java,,' 表示字符。" 表示字符串
SQL/python/Js,没有字符类型,只有字符串
指定列插入
insert into 表名 (列名,列名) values (值,值,值...);

注意:这里的列的个数和类型,要与表结构匹配
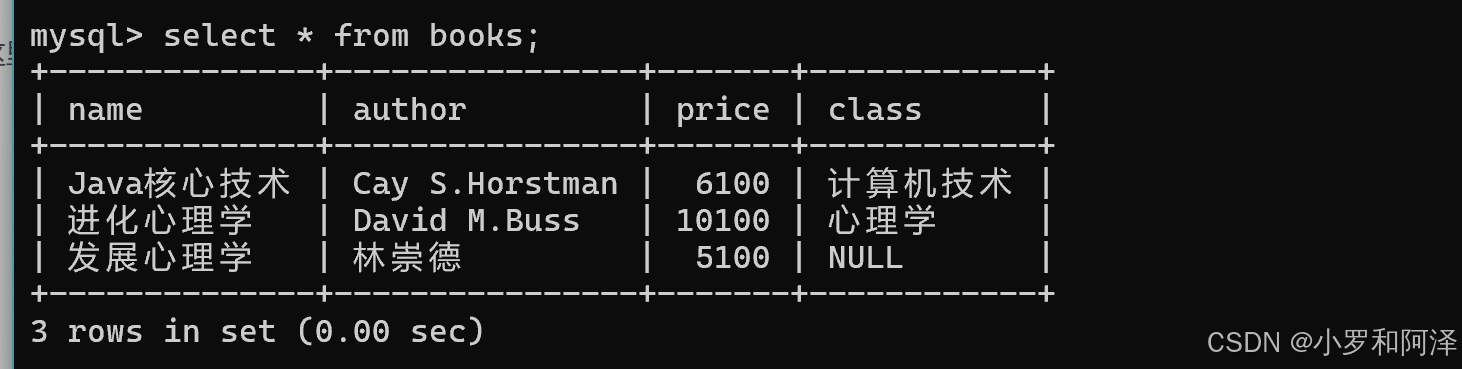
一次插入多行
insert into 表名 values (值,值...),(值,值...),(值,值...);

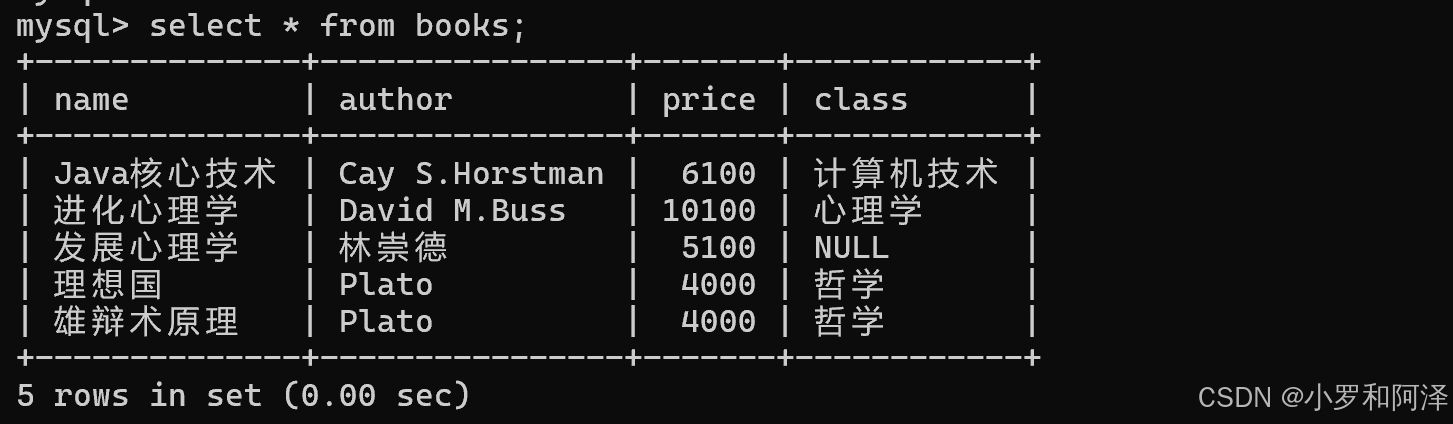
客户端-服务器 交互过程中,交互的次数越多,整体的开销就越大,花的时间越长
插入时间
例: insert into test into values ("2024-10-03 20:20:20");
插入当前时间 也可以使用SQL的库函数 now();
例: insert into test into values (now());'
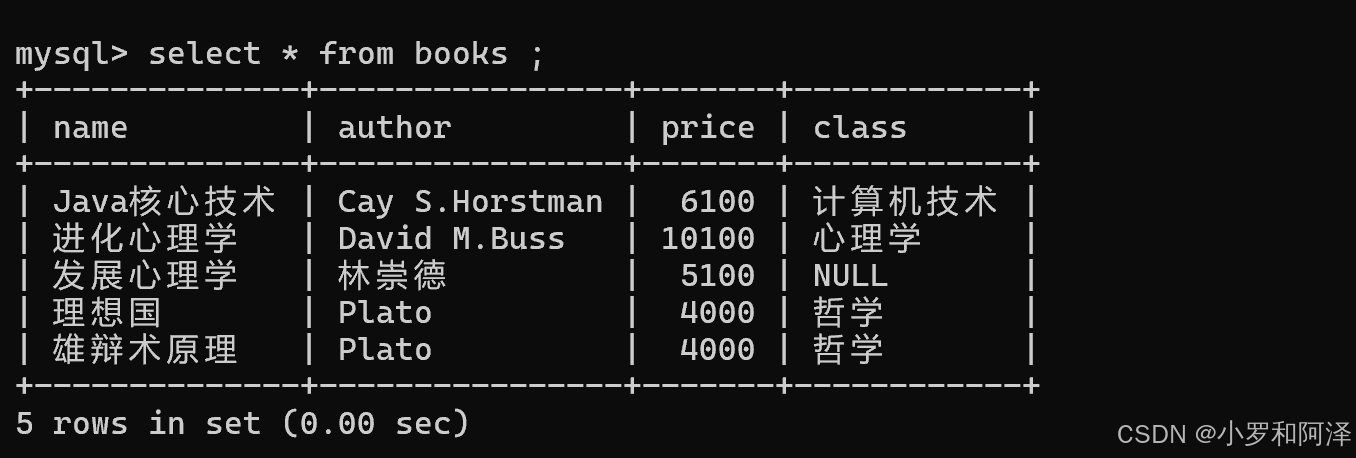
查询
所有select 查询操作 都是只针对临时表进行 计算/调整 ,并不影响整个硬盘上的数据
注:以下中 列名 的含义 也包括 * .
全列查询
查询出这个表中的所有的行和所有的列
select * from 表名
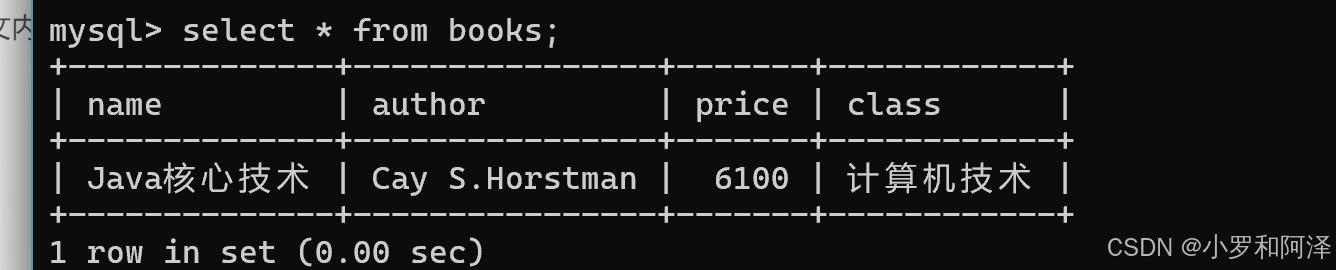
* 可以指代 所有的列
注意:select * 是一个很危险的操作
指定列查询
select 列名,列名... from 表名
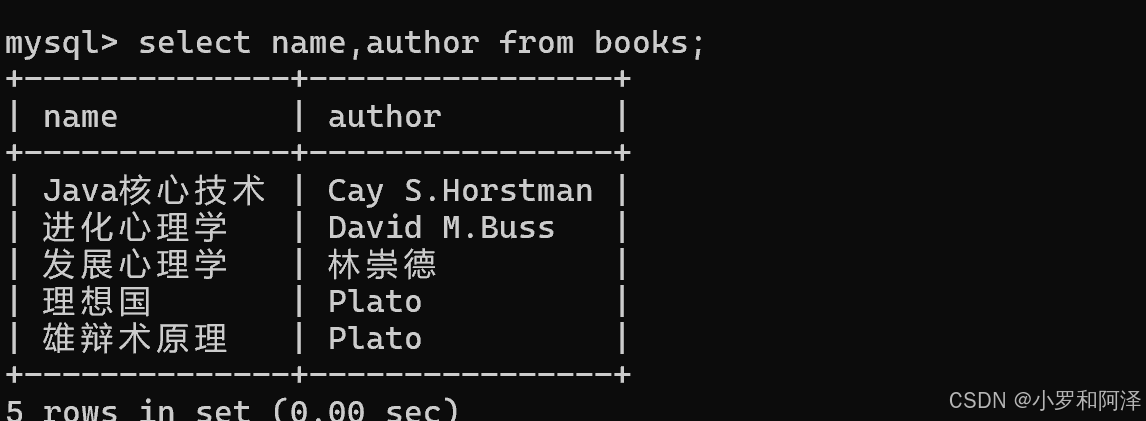
查询时 指定表达式(列之间进行运算)
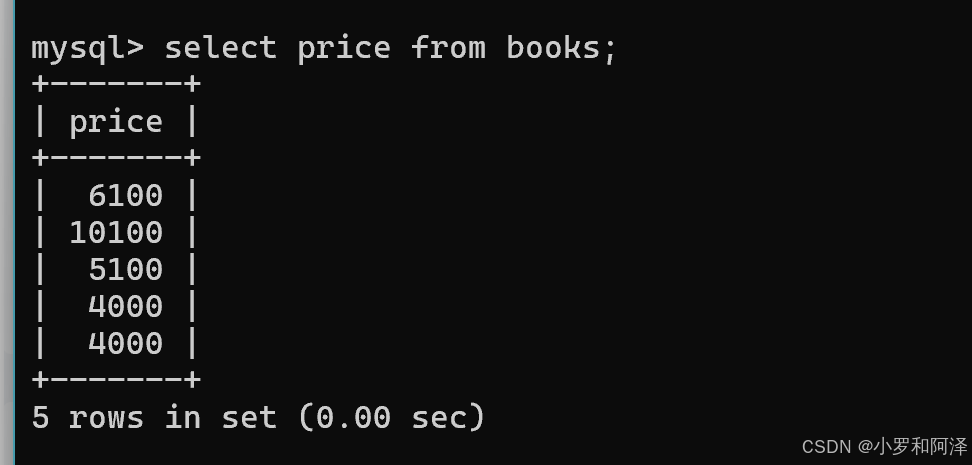
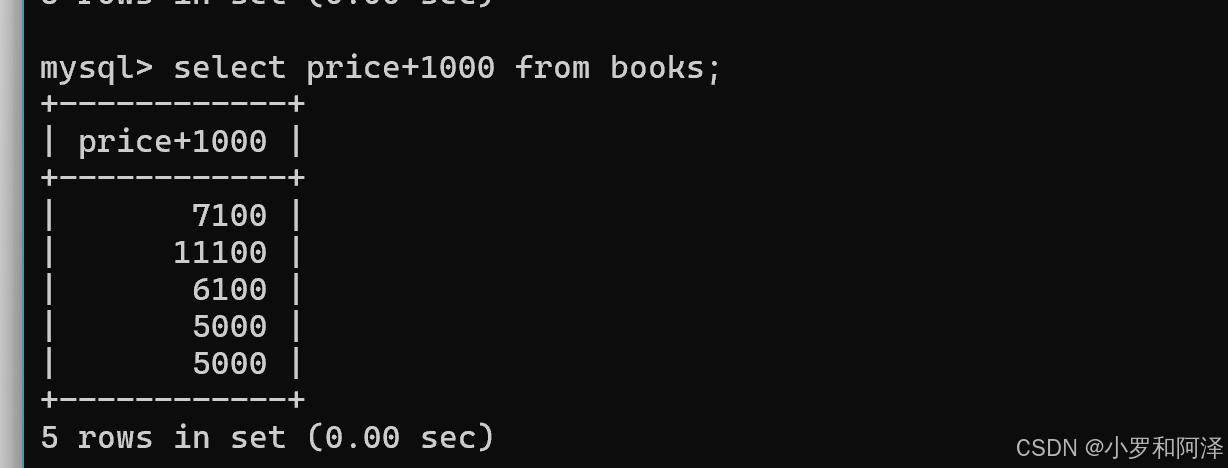
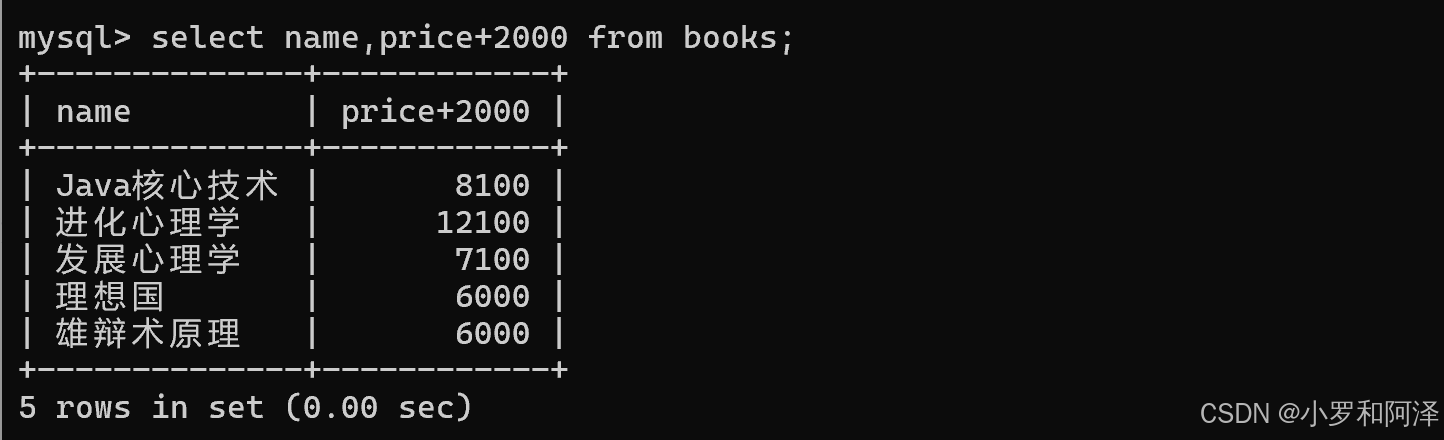
这样产生的结果,只是数据库查询过程中,生成的"临时表",数据库本体数据没有任何改变.
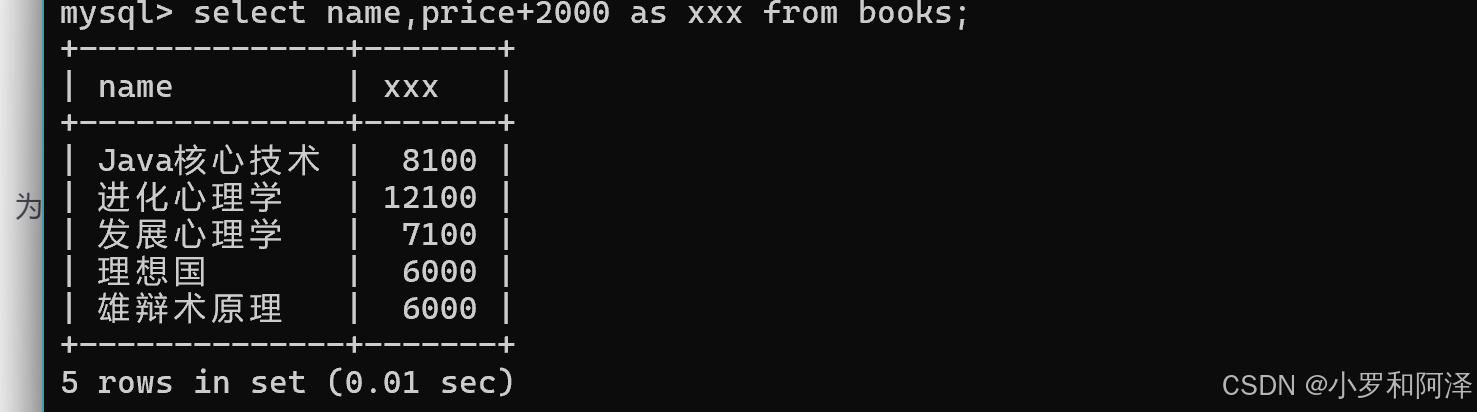
起别名
select 表达式 as 别名 from 表名;
去重查询
select distinct 列名 from 表名;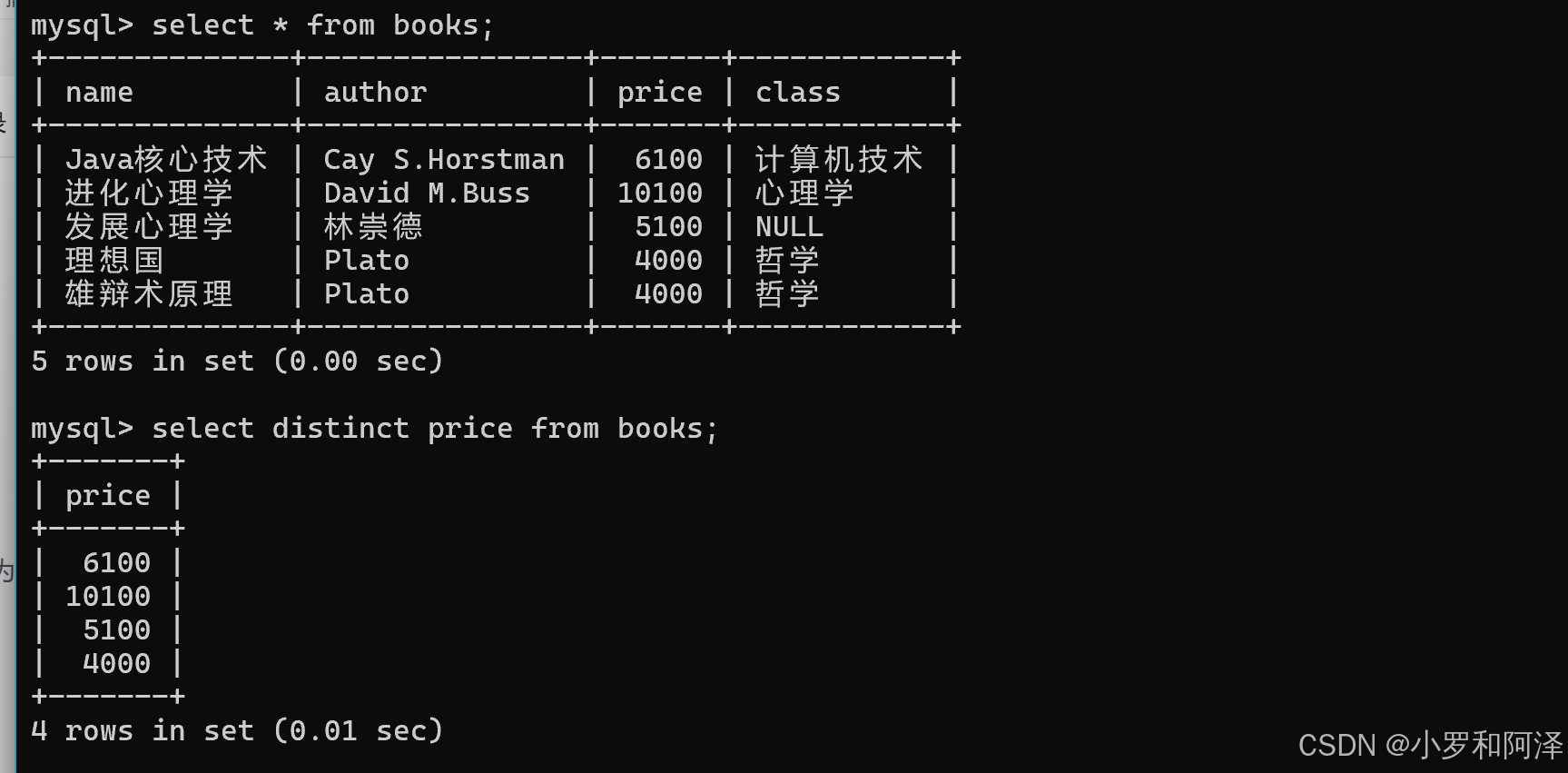
如果有两个或以上的列名,那么其中对应列中都有一一对应的重复,才能触发去重.
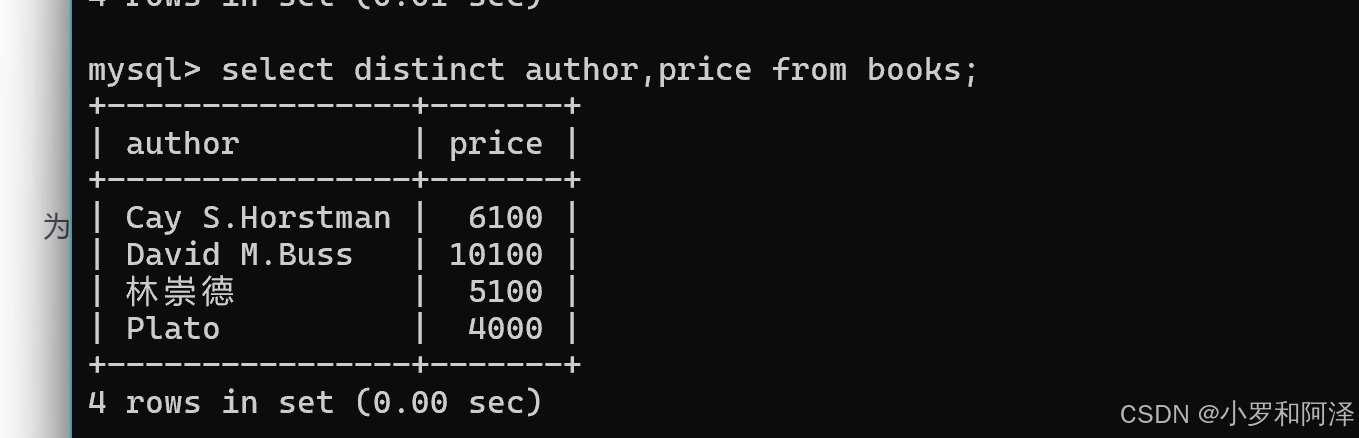
排序查询(默认升序)
select 列名 from 表名 order by 列名;
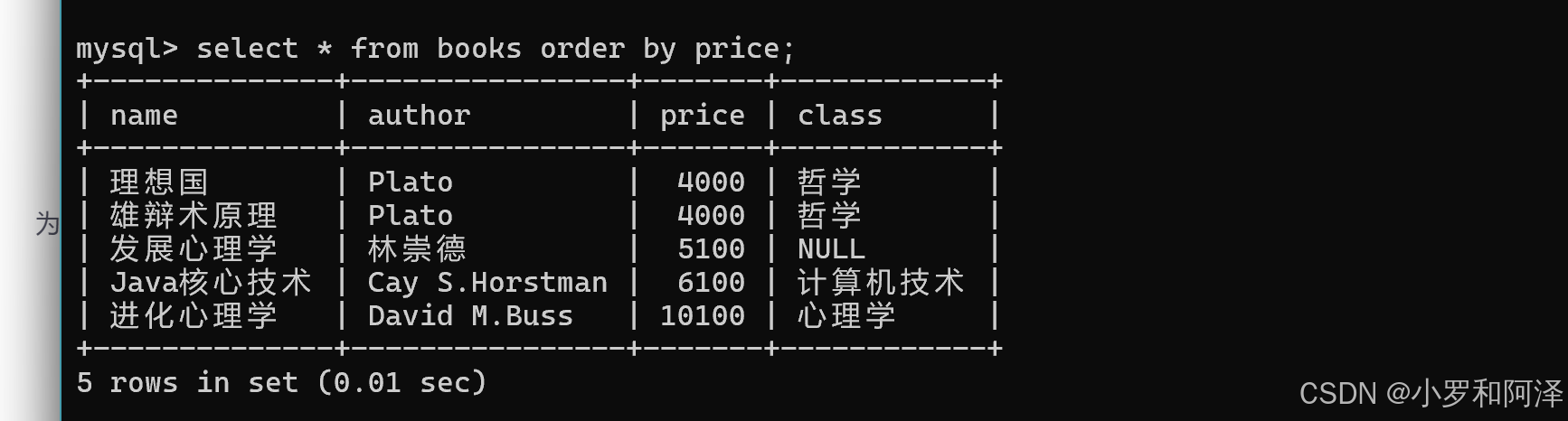
注意:数据库中如果不写order by,那么查询得到的结果顺序是随机的。
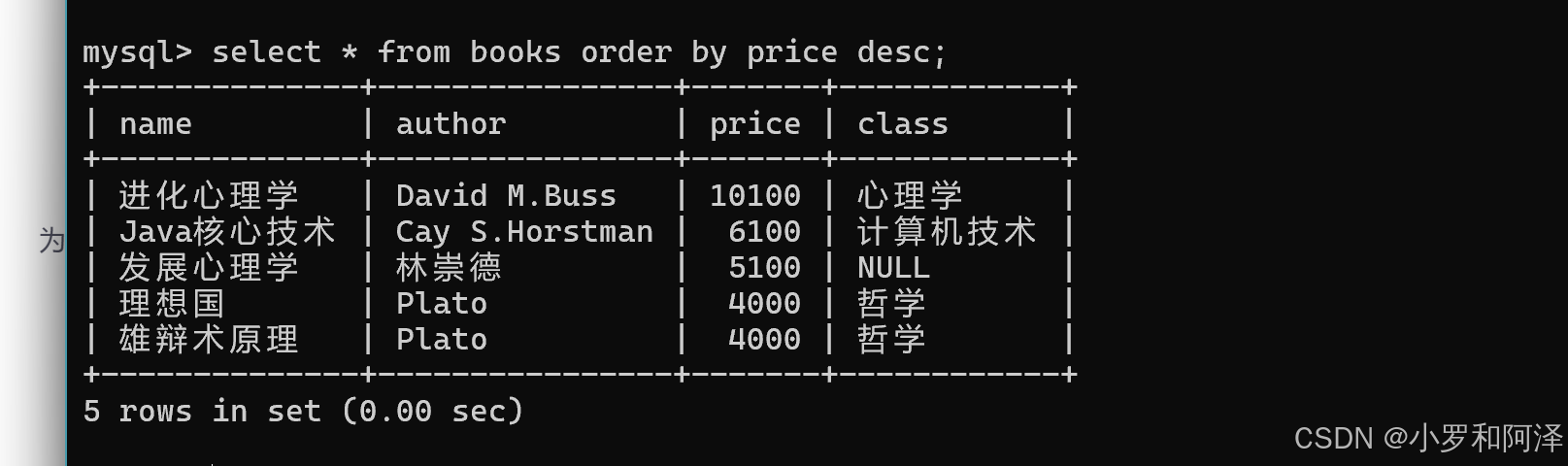
降序排序查询
在order by中对应的列名,加上desc 关键字.
select 列名 from 表名 order by 列名 desc;
条件查询
查询过程中,指定筛选条件,满足条件的记录就保留,不满足条件的就跳过
select 列名 from 表名 where 条件;
条件:
范围查询
between a and b

在编程中,大部分谈到的"区间"都是"前闭后开"区间[a,b).
但 SQL 的 between... and... 则是 闭区间 a,b.
in(a,b,c,.....)
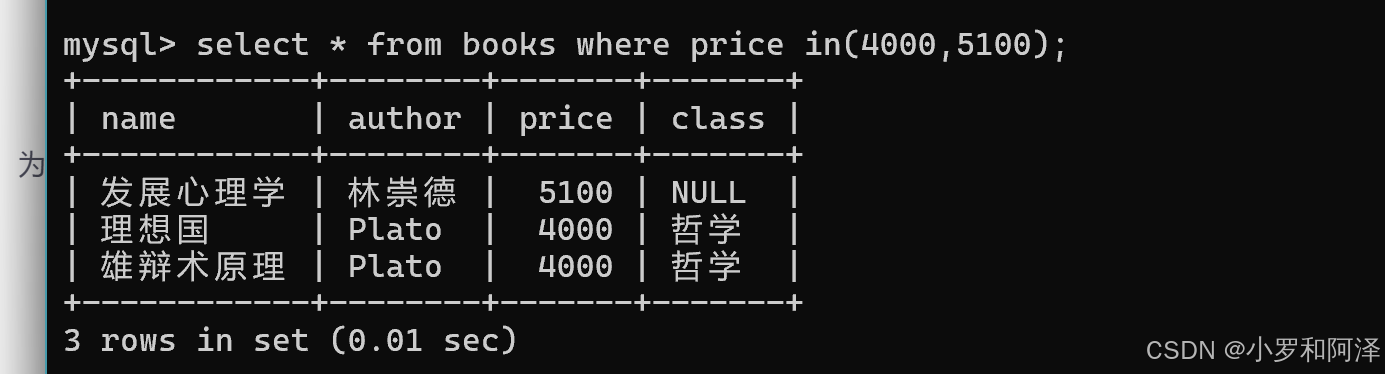
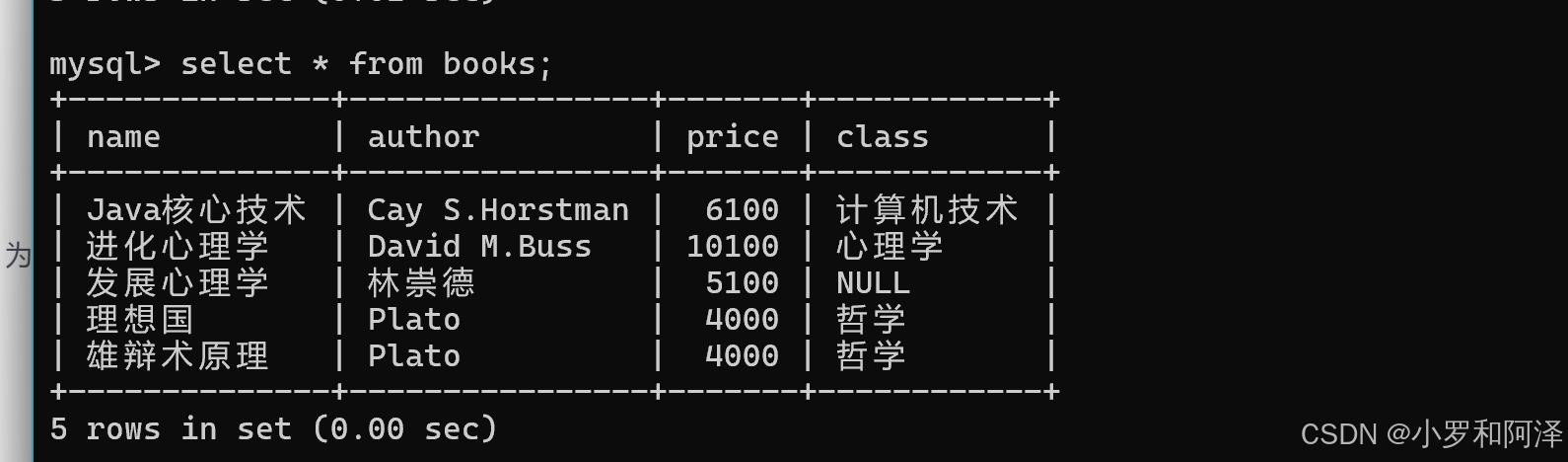
模糊查询
like
模糊匹配,%表示匹配任意数量字符,_表示匹配一个特点字符.
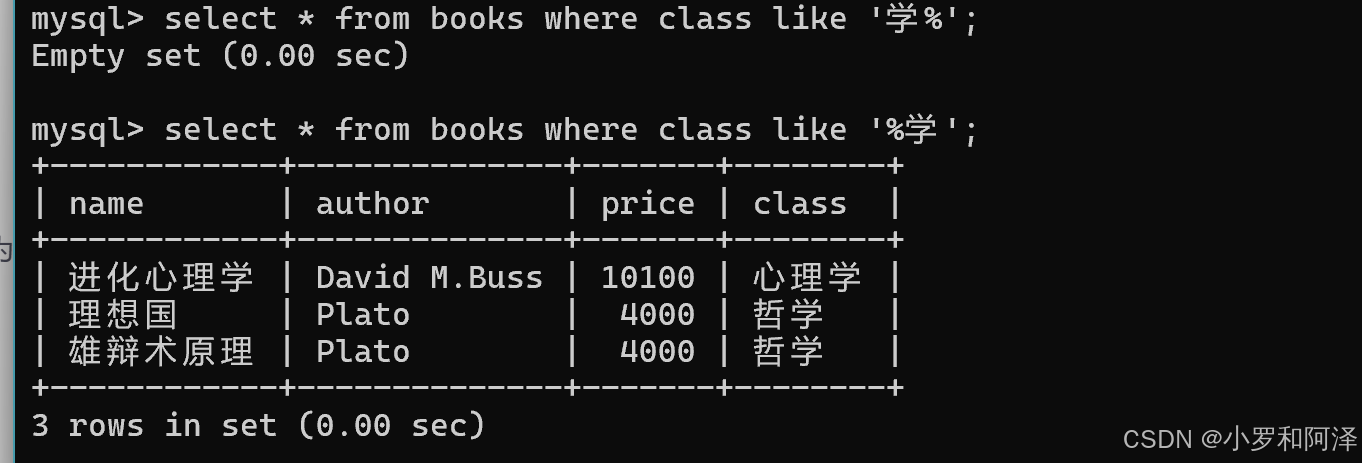
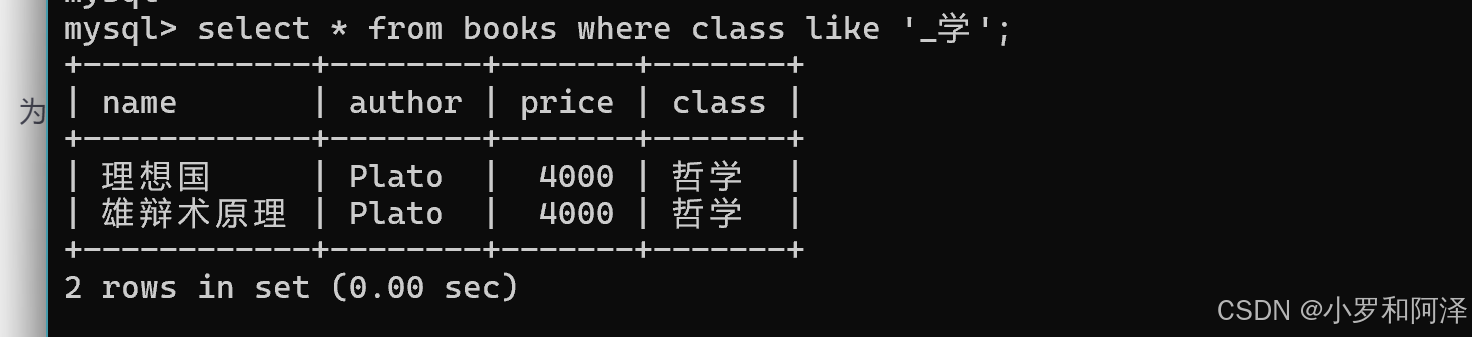
一般条件
and

or
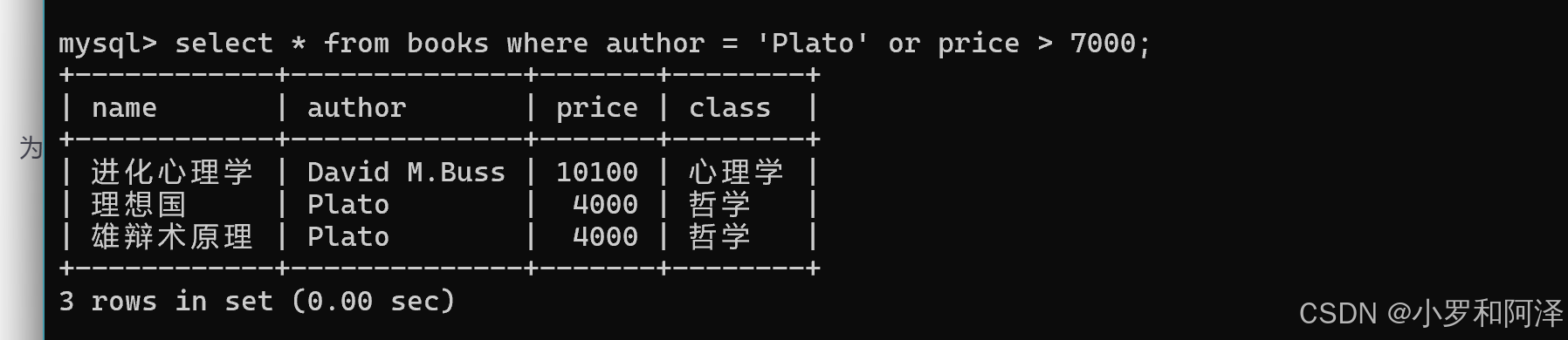
注:and 和 or 同时出现时 有需要优先执行的表达式要加 ( ) .
not
is null
is not null
>,>=
<,<=
=
注:不要使用null 和 = 直接使用
而是 <=> null 的方式,因此 只要含有null 的 列 要进行 = 比较的话 只能使用<=> 进行比较
SQL中 使用 = 表示比较相等.
null = null 的结果是null.
分页查询
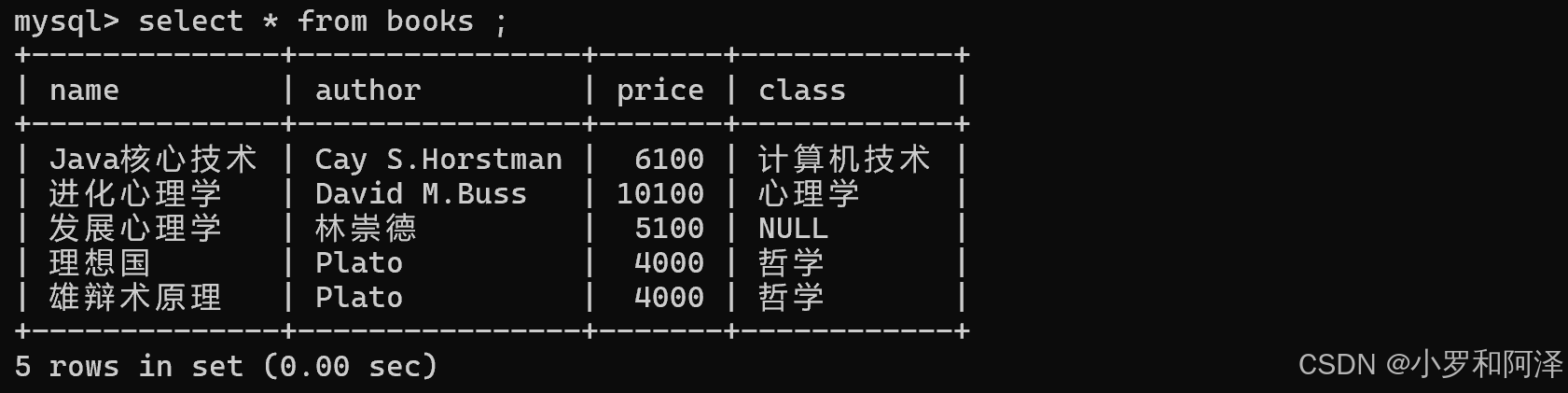
select 列名 from 表名 limit N; (限制查询N条记录)
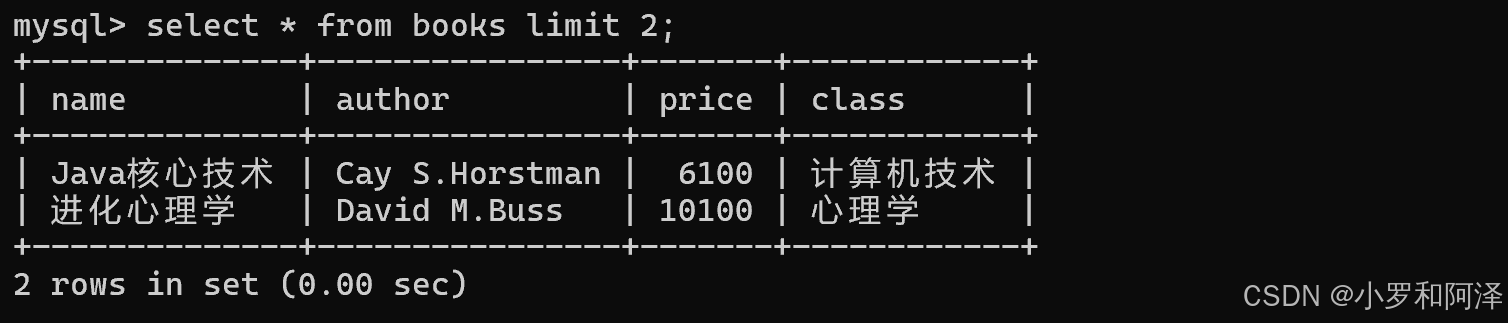
select 列名 from 表名 limit N offset M; (从M开始查N条数据)
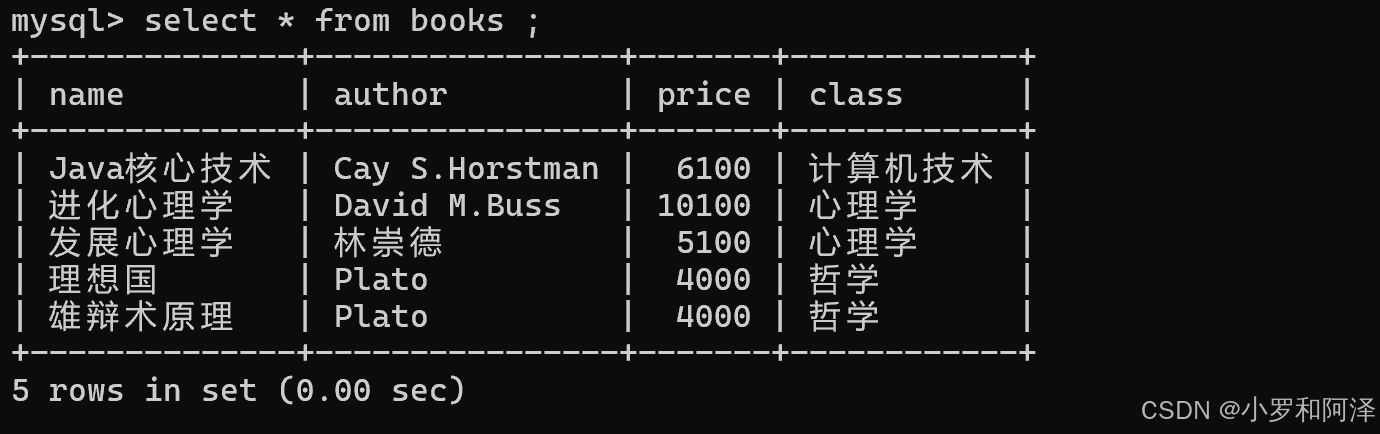
修改
update 表名 set 列名 = 值, 列名 = 值, ... where 条件/order by/limit;

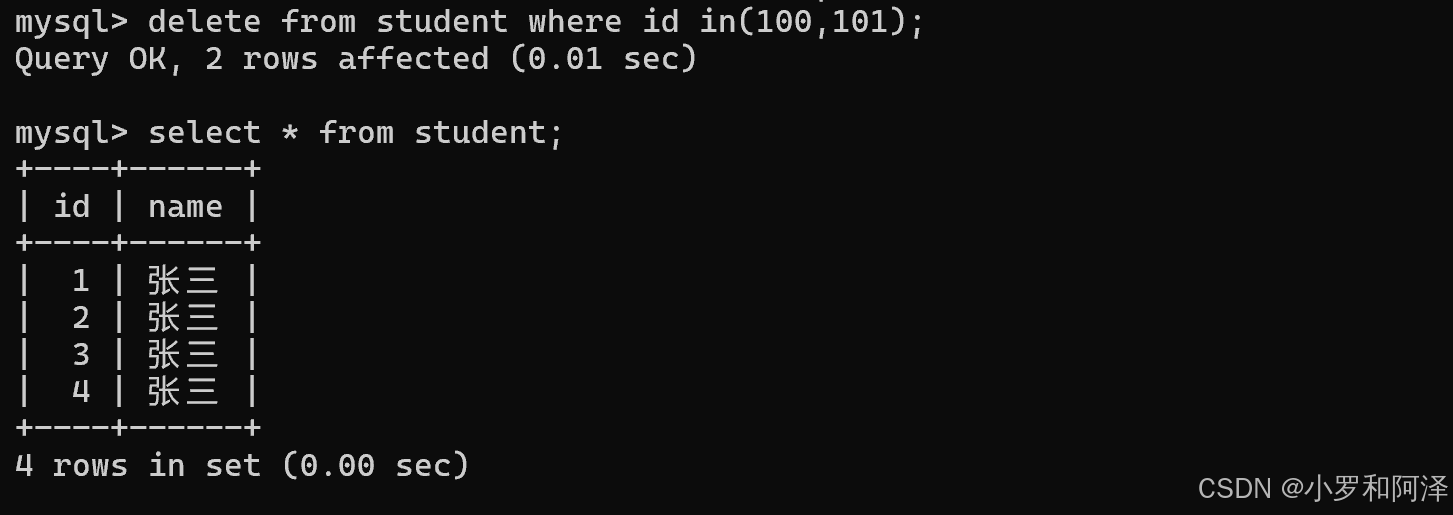
删除
delate from 表名 where 条件/order by/limit;

数据库进阶
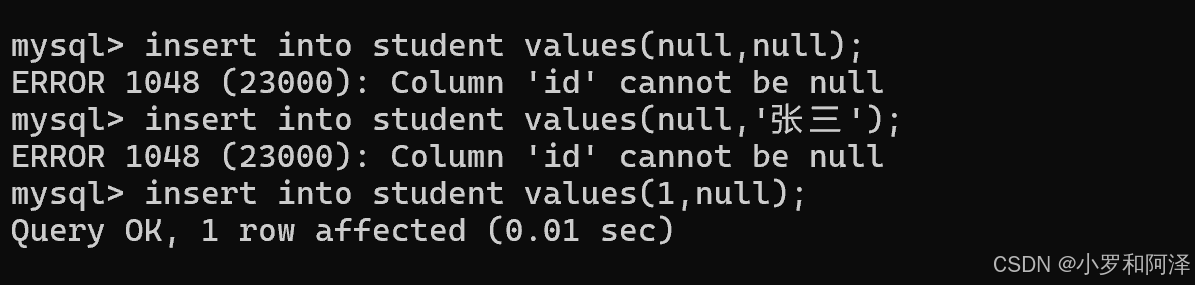
约束
not null (非空)指示某列不能存储 null 值

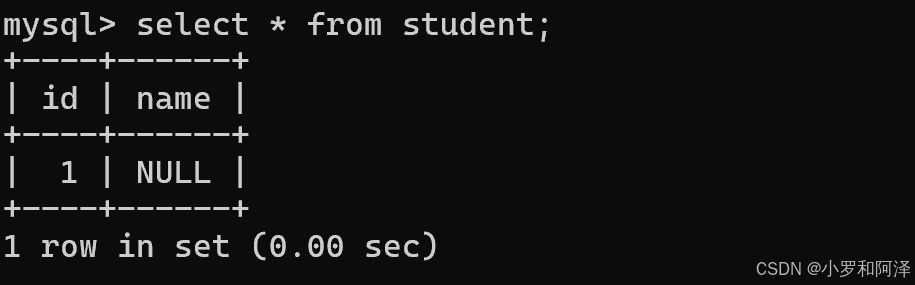
unique (唯一)保证某列的每行必须有唯一的值
先看不加unique时的情况
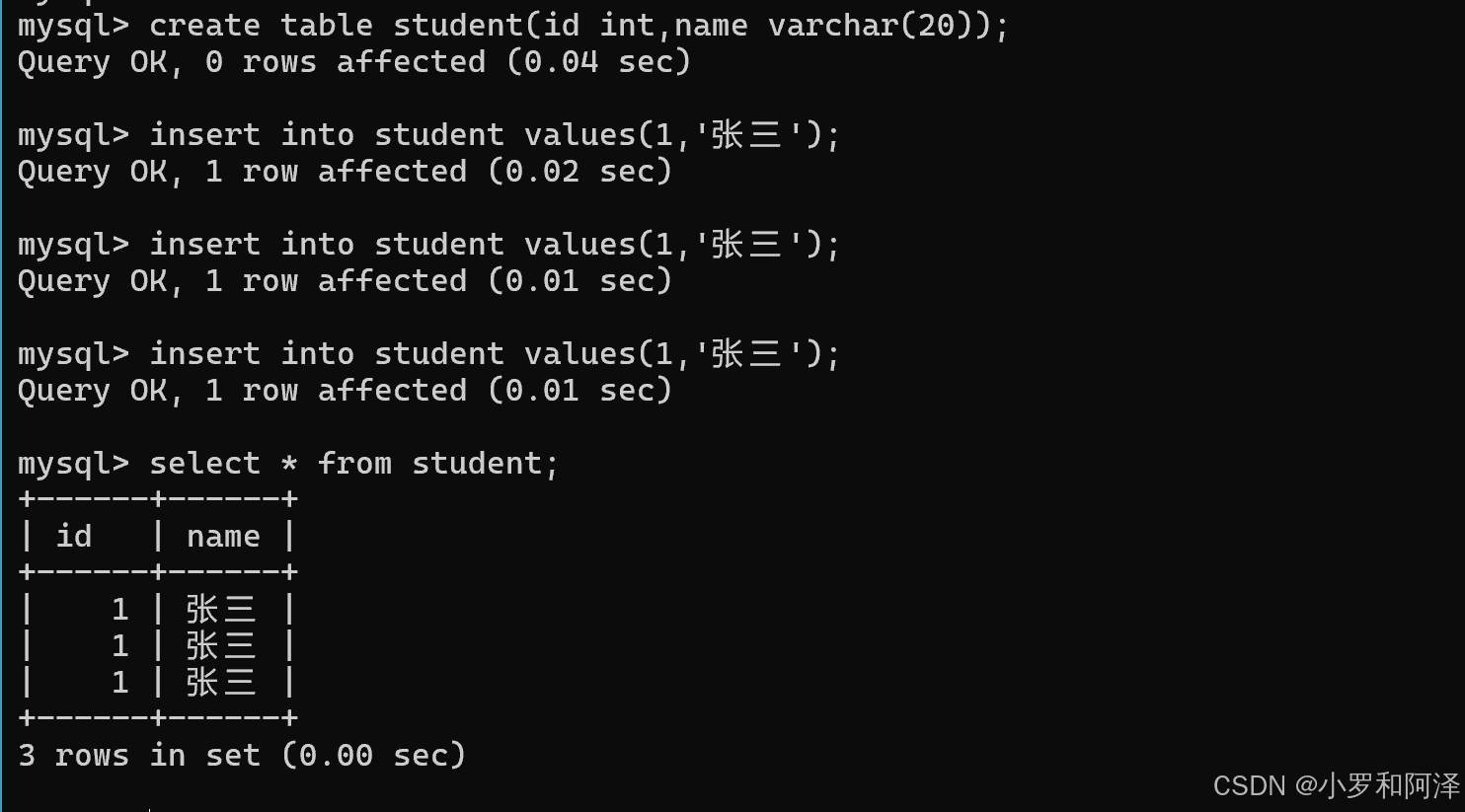
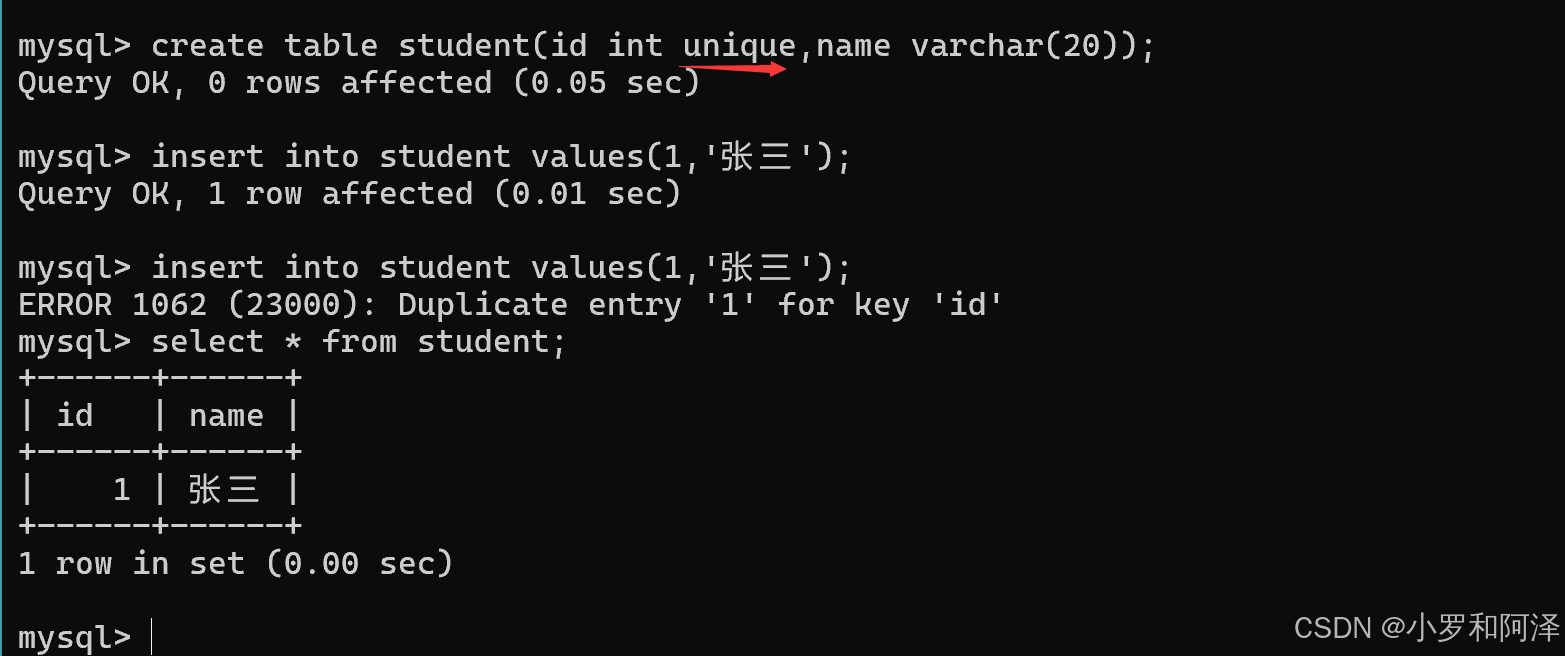
加入unique之后,相同操作语句,产生的结果
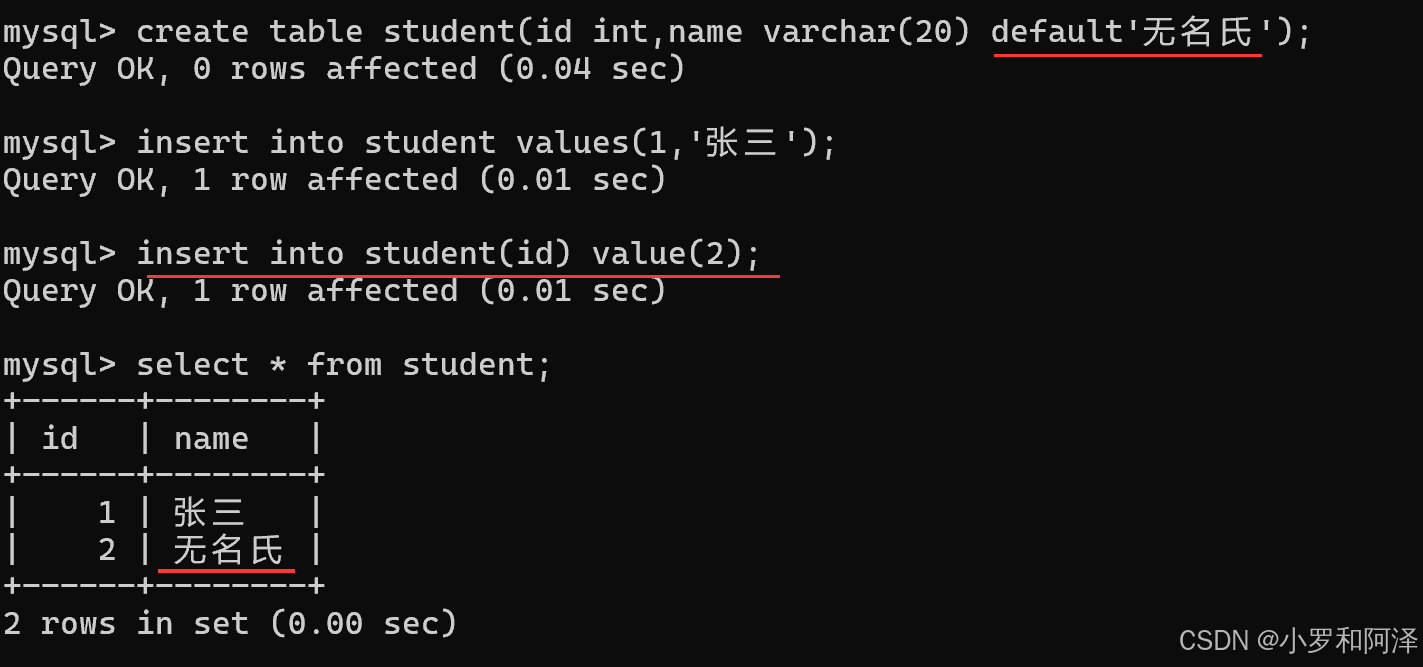
default (指定默认值)规定没有给列赋值时的默认值
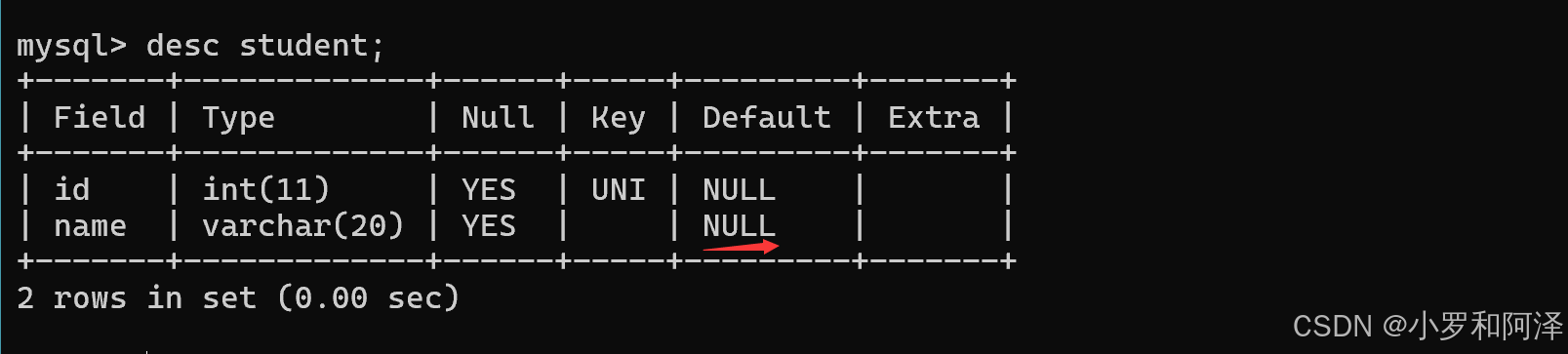
最初的默认值都是null.
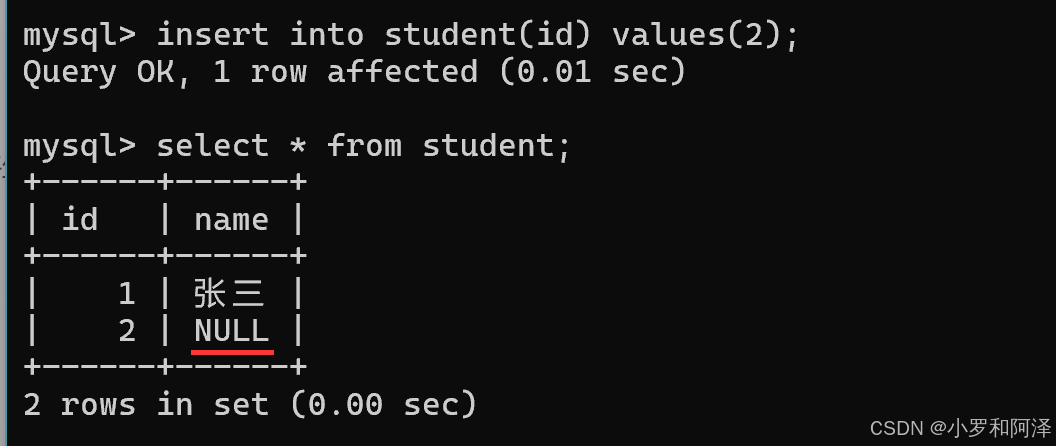
定义了默认值之后的结果
primary key (主键)
not null 和 unique 的结合,确保某列(或两个列多个列的结合)有唯一标识,有助于更容易快速地找到表中的一个特定的记录

当赋null值和重复赋值时,都报出了错误
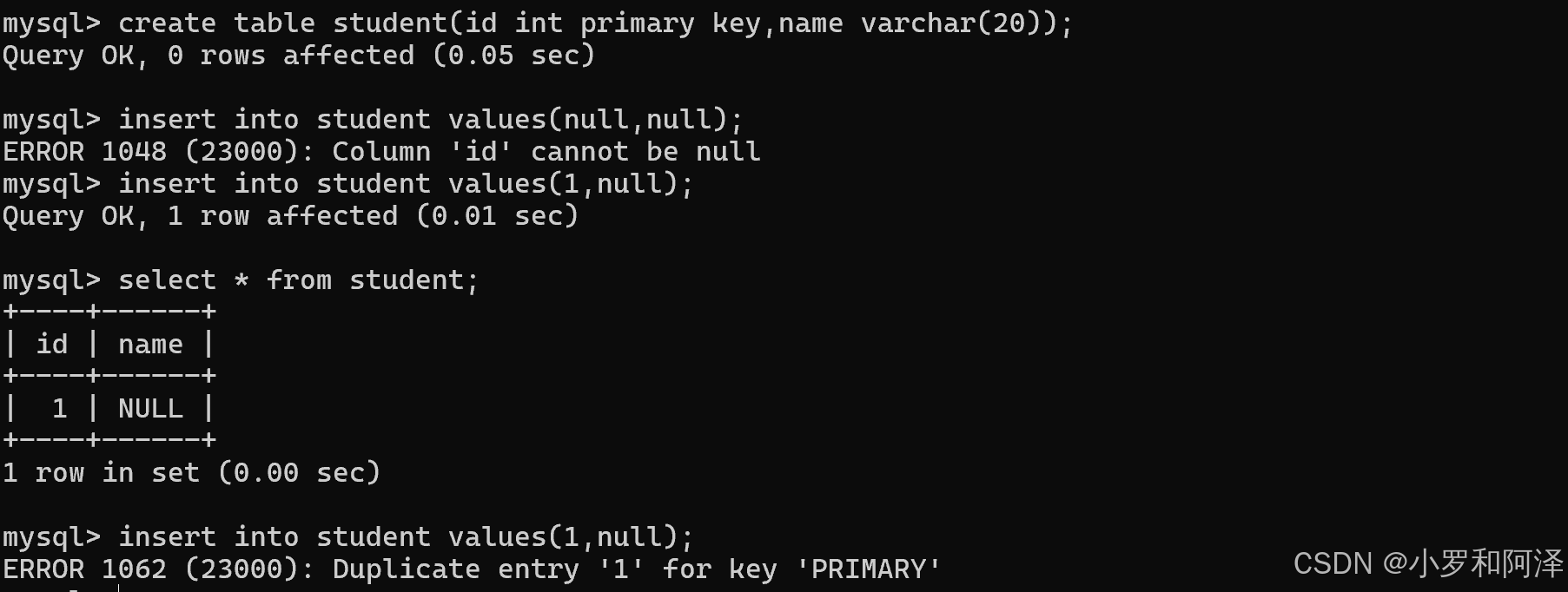
一个表中不允许同时出现多个主键

主键需要分配一个唯一的值,如何进行分配呢?
mysql 提供了一个 自动分配 主键值 的方式,"自增主键".
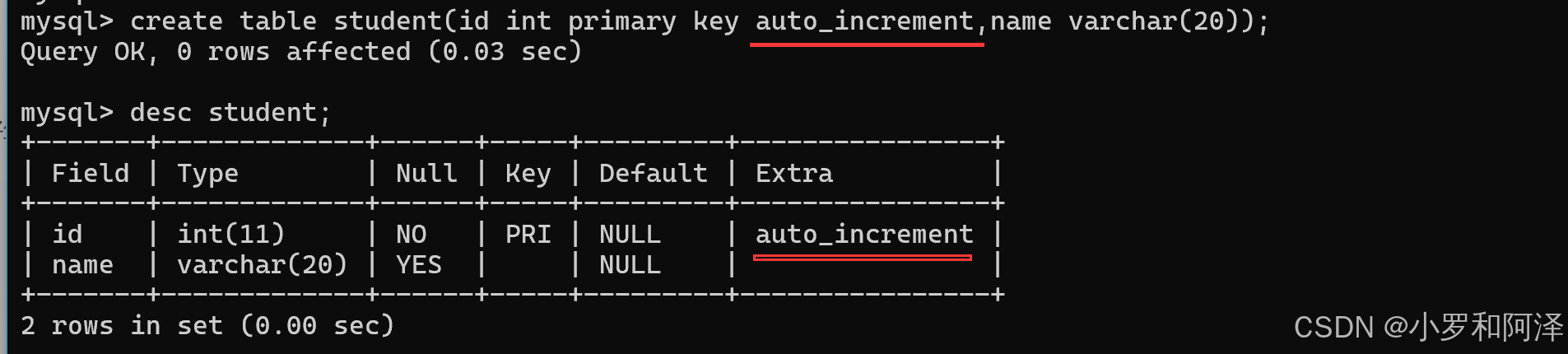
插入数据时,可以不指定id列的值,让数据库自动分配,就会按1,2,3,4.....的顺序自动分配.
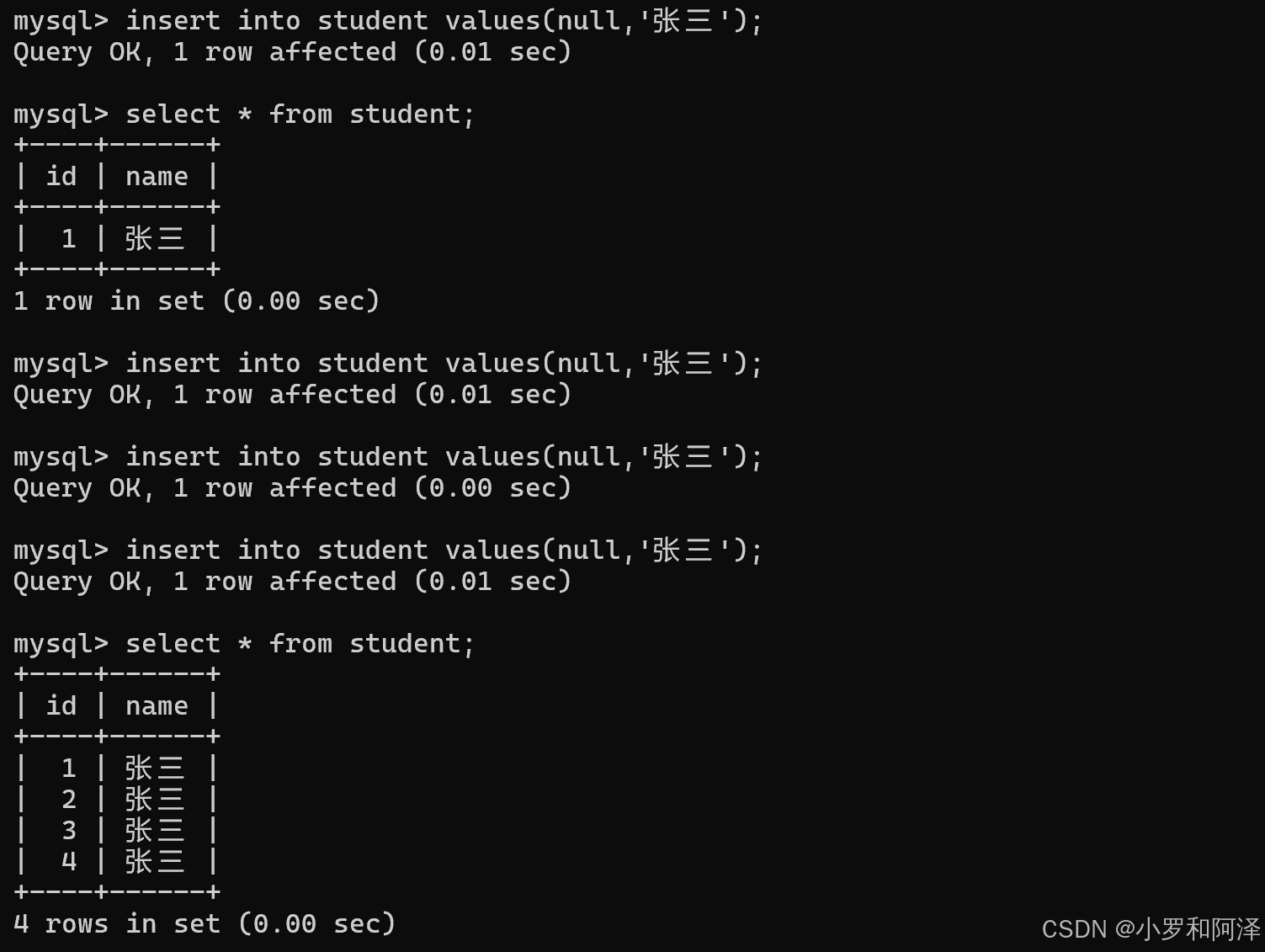
也可以手动指定其他数值
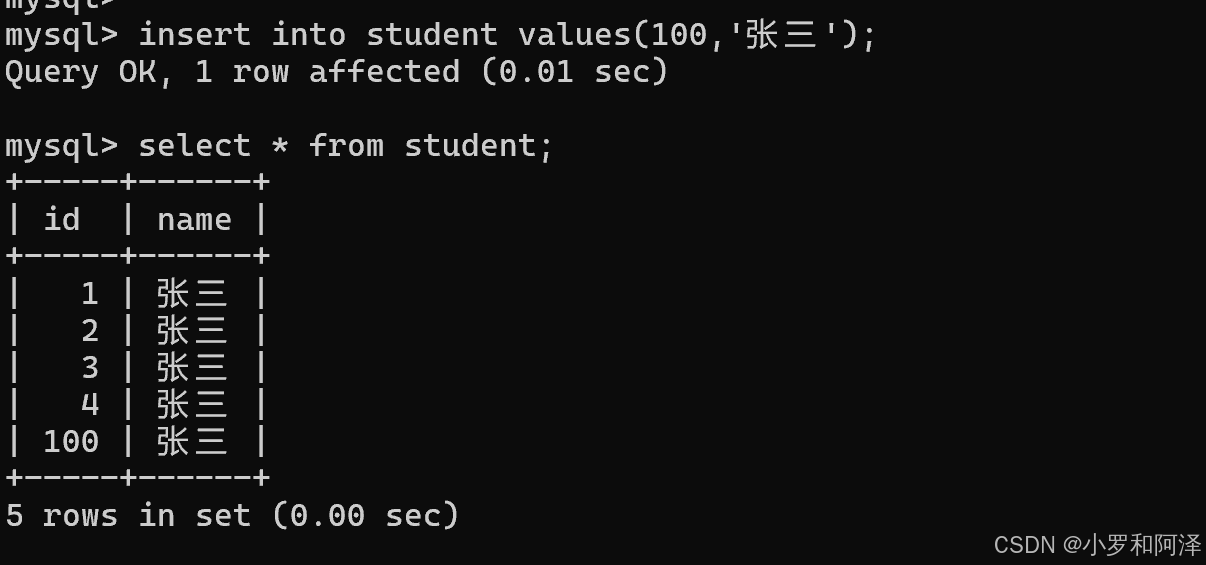
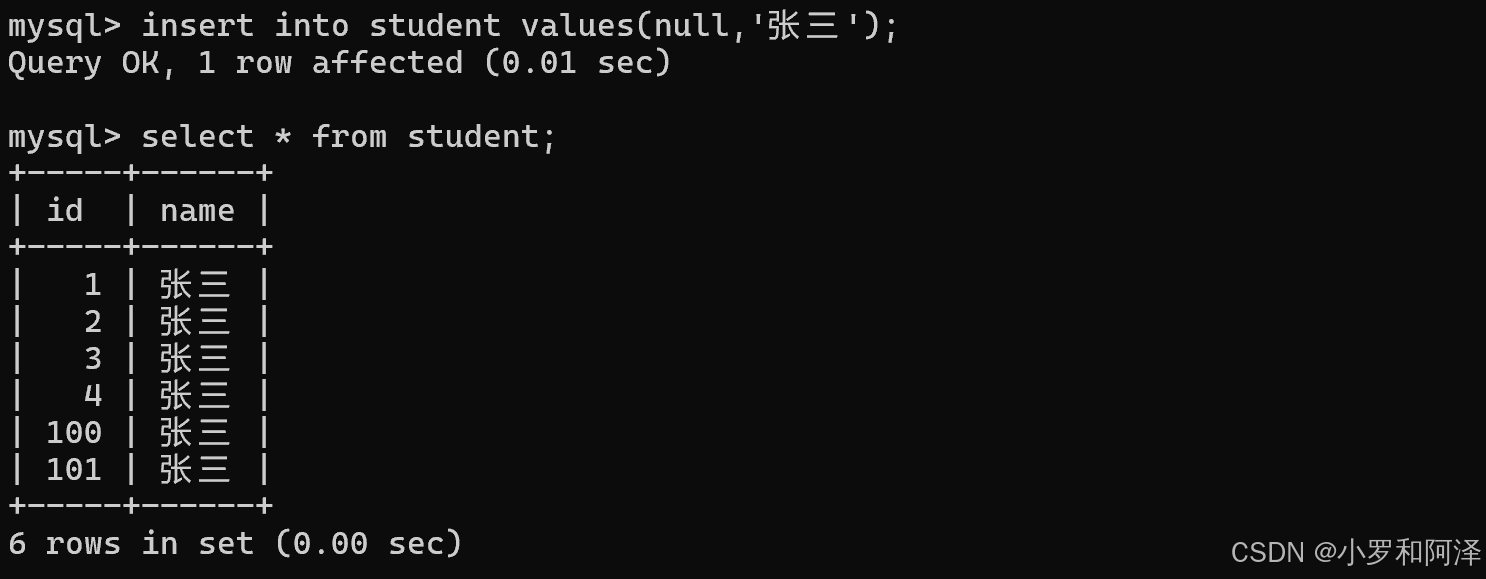
在mysql中,给每个表都记录了一个"自增主键的最大值",后续继续插入数据时,无论之前的最大值是否存在,都是根据之前保存的最大值,继续往后分配的.
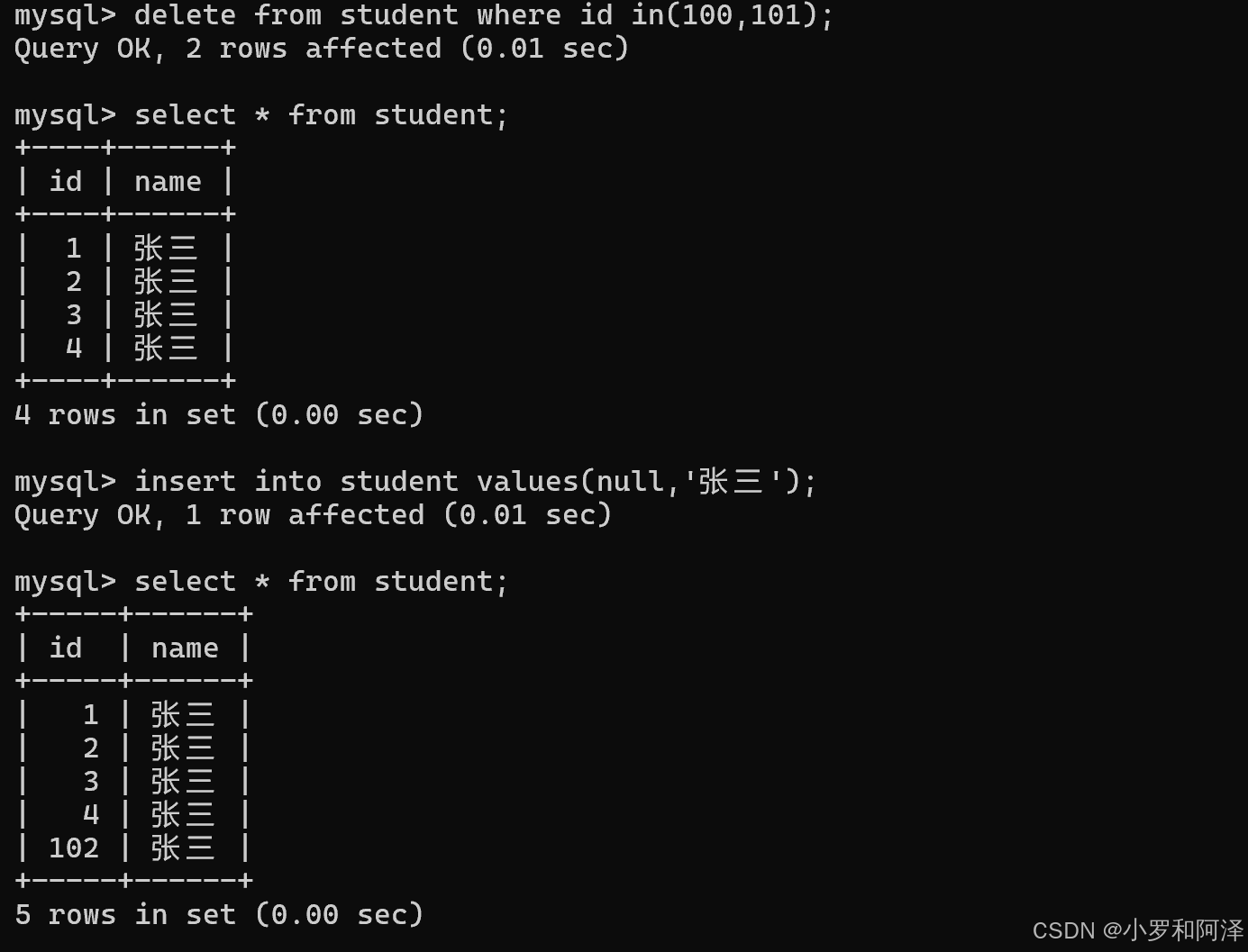
注:自增主键只能针对 像 int/bigint 的整数
foreign key (外键)保证一个表中的数据匹配另一个表中的值的参照完整性
涉及到两张表
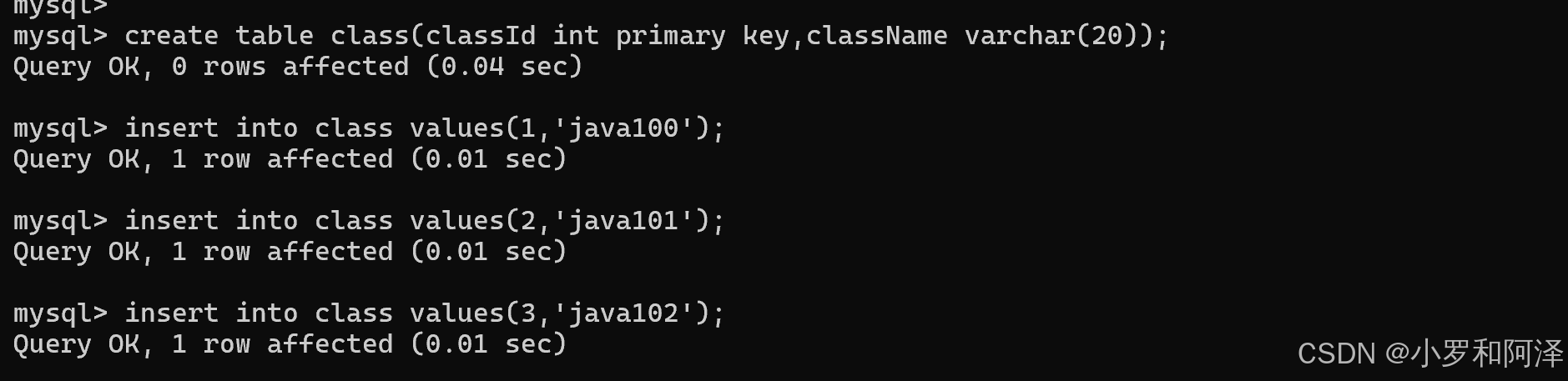

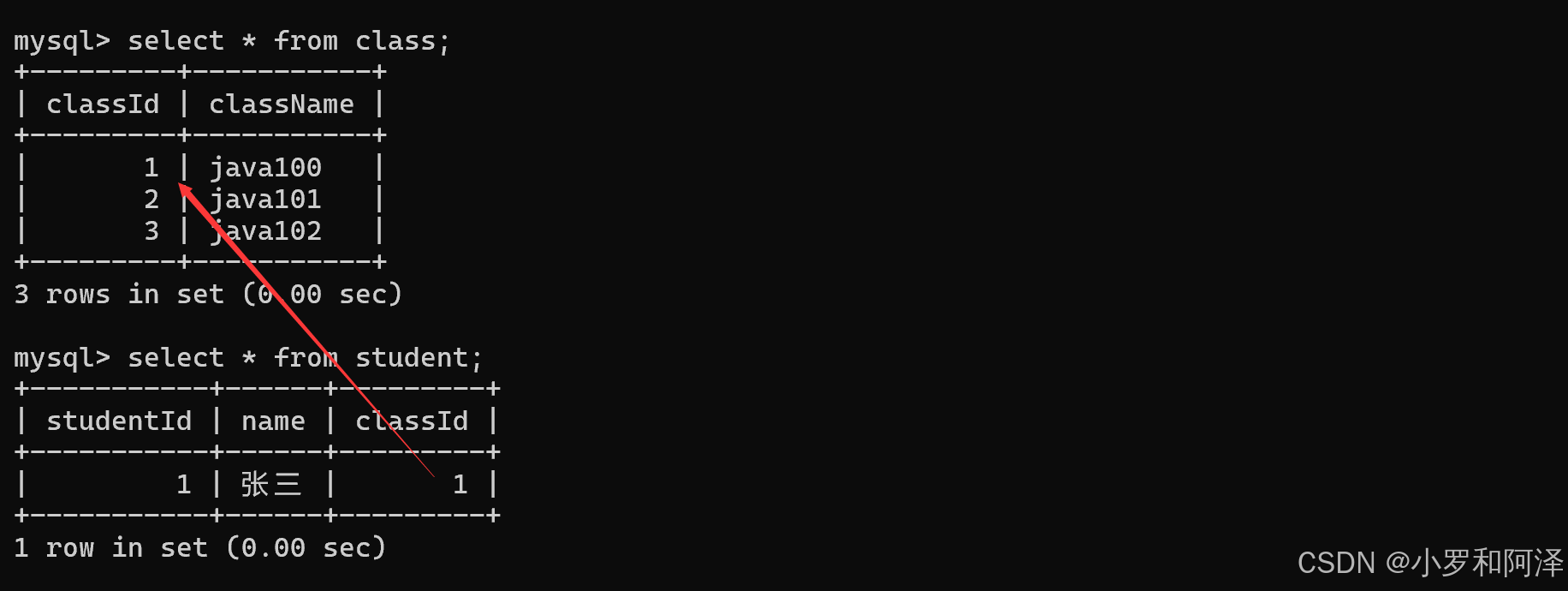
但如果没有 foreign key 约束,可以会出现意外
即以下情况:在第一张class表中的classId并没有100,但第二张student表却能插入classId为100的数据.
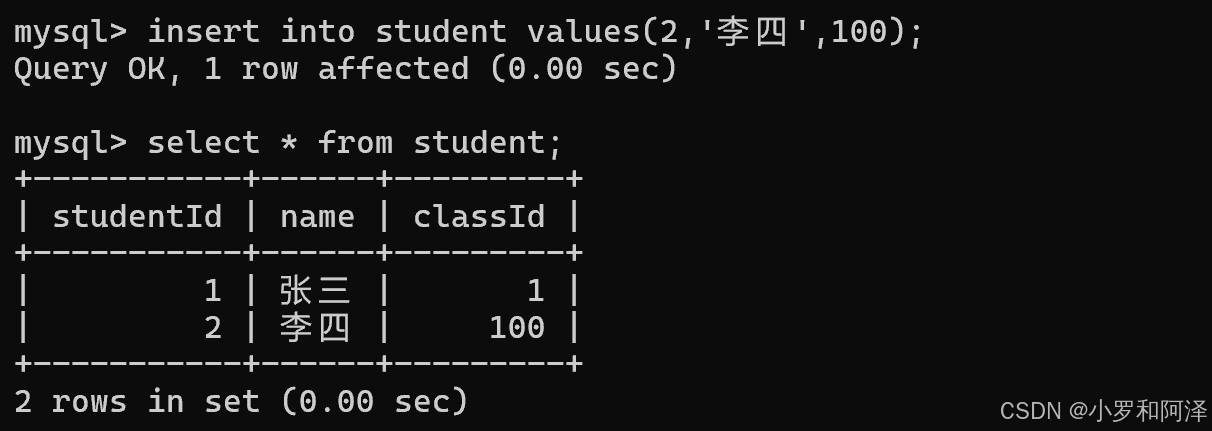

加入foreign key 之后,不属于 class 表中 classid 中的数据,不能被插入 student 表中.

check (检查)保证列中的值符合指定的条件
查询
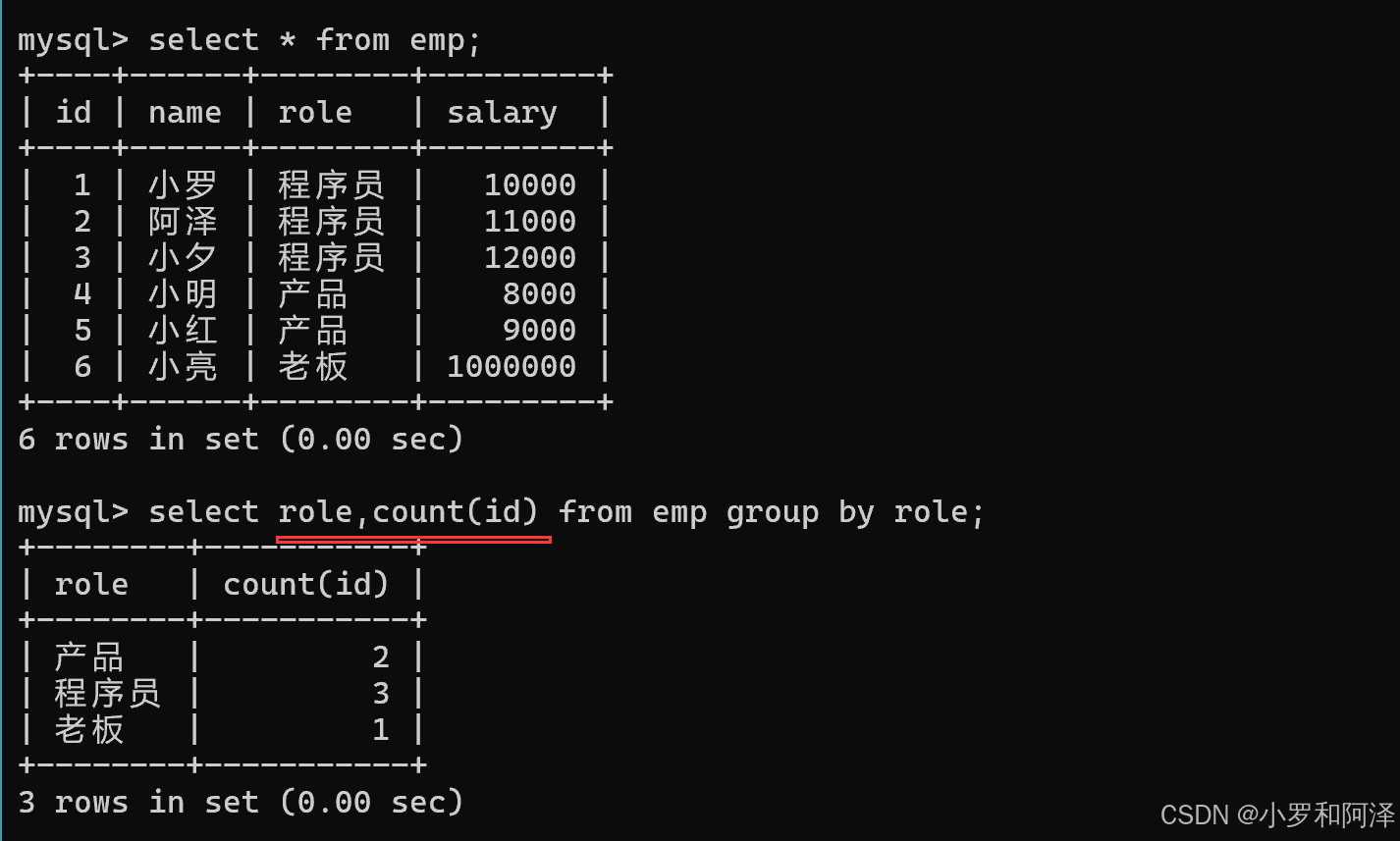
聚合查询
聚合函数
count()
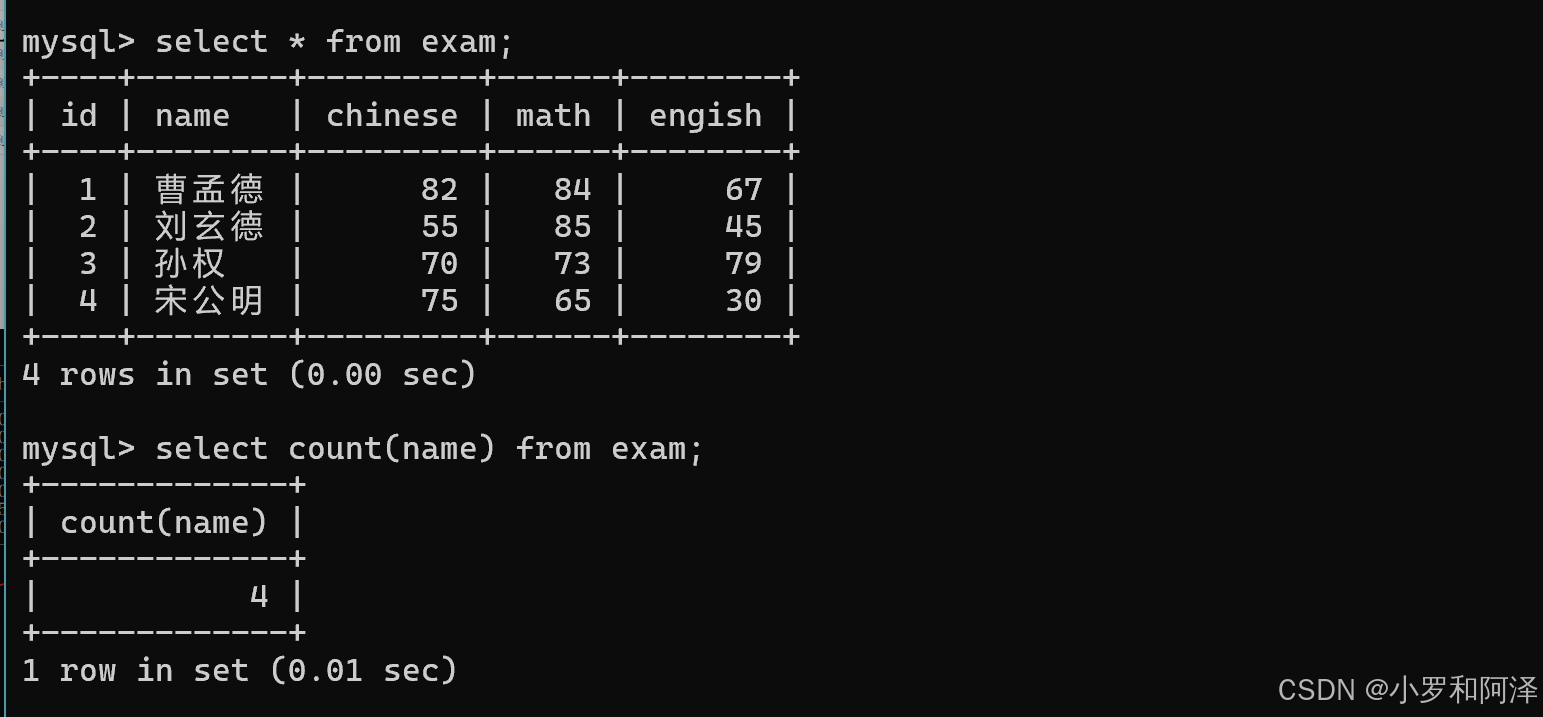
sum()
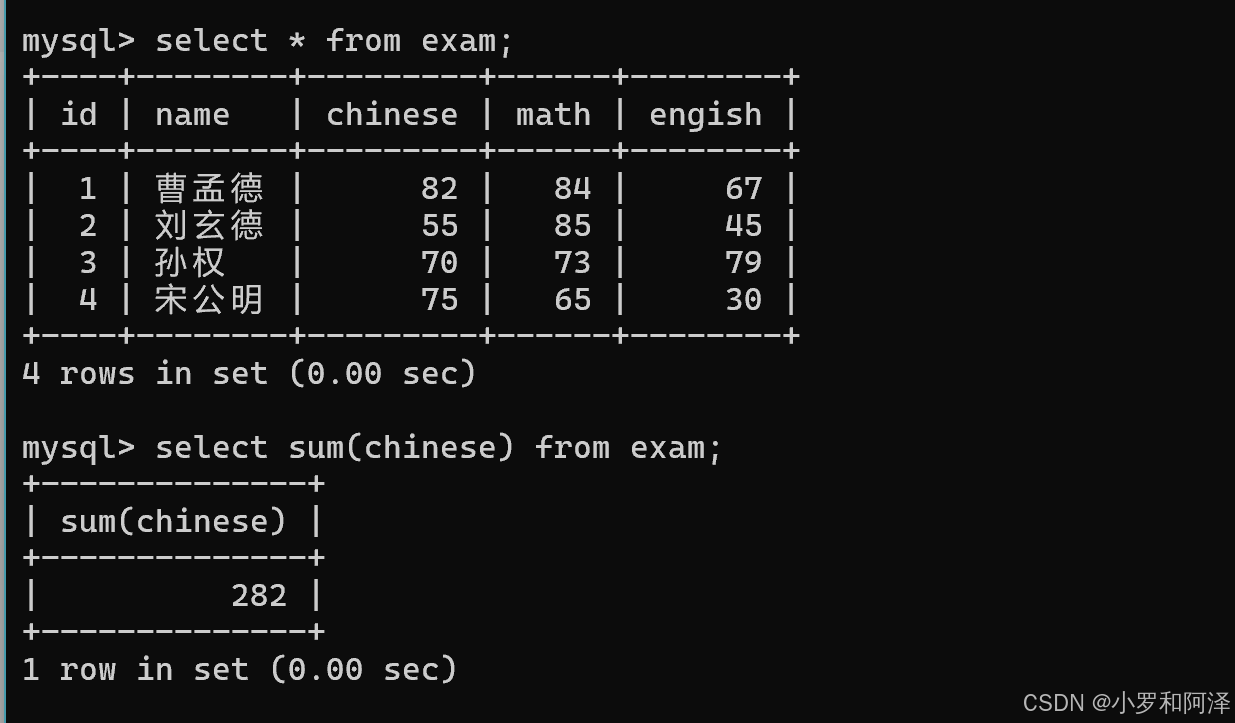
sum 函数 不可以用来求和字符串.
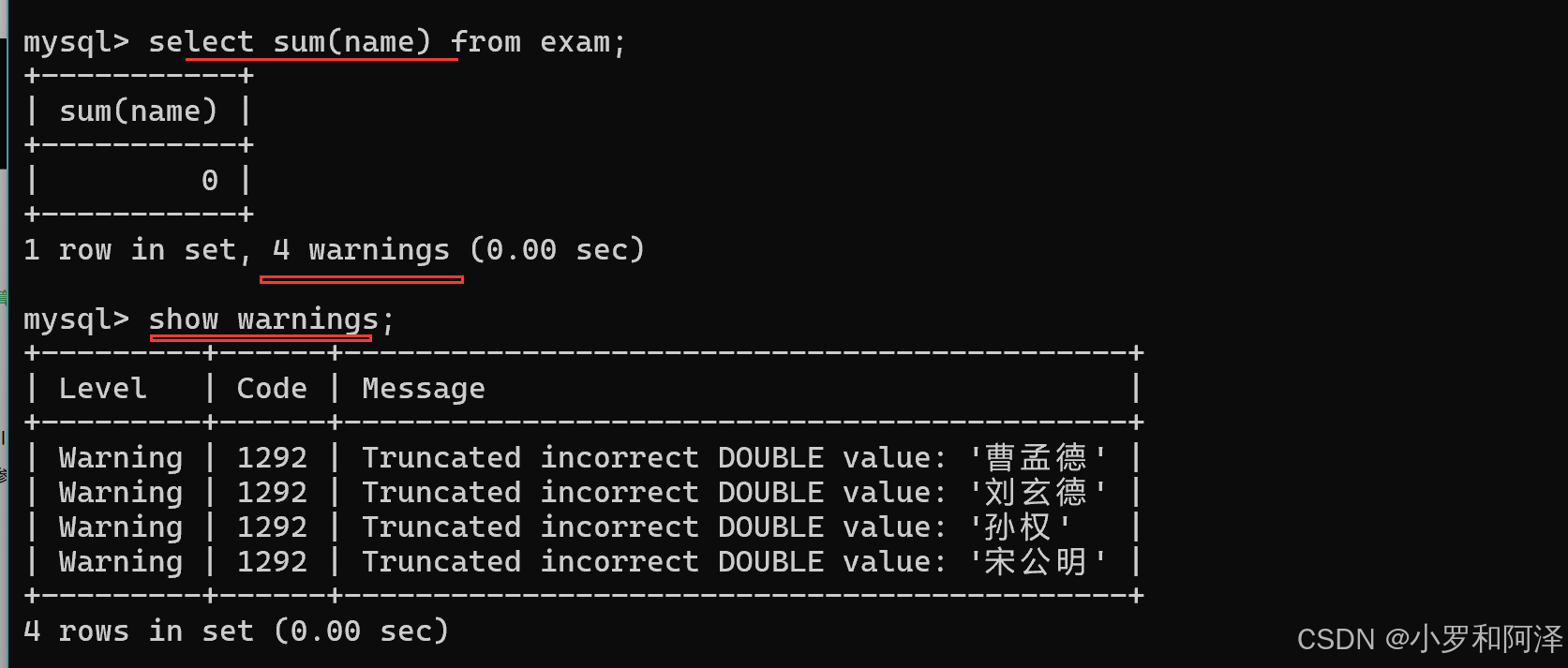
sum 函数 遇到 null 会直接跳过.
注:在之前的表达式计算中,如果有null参与,结果就会为null
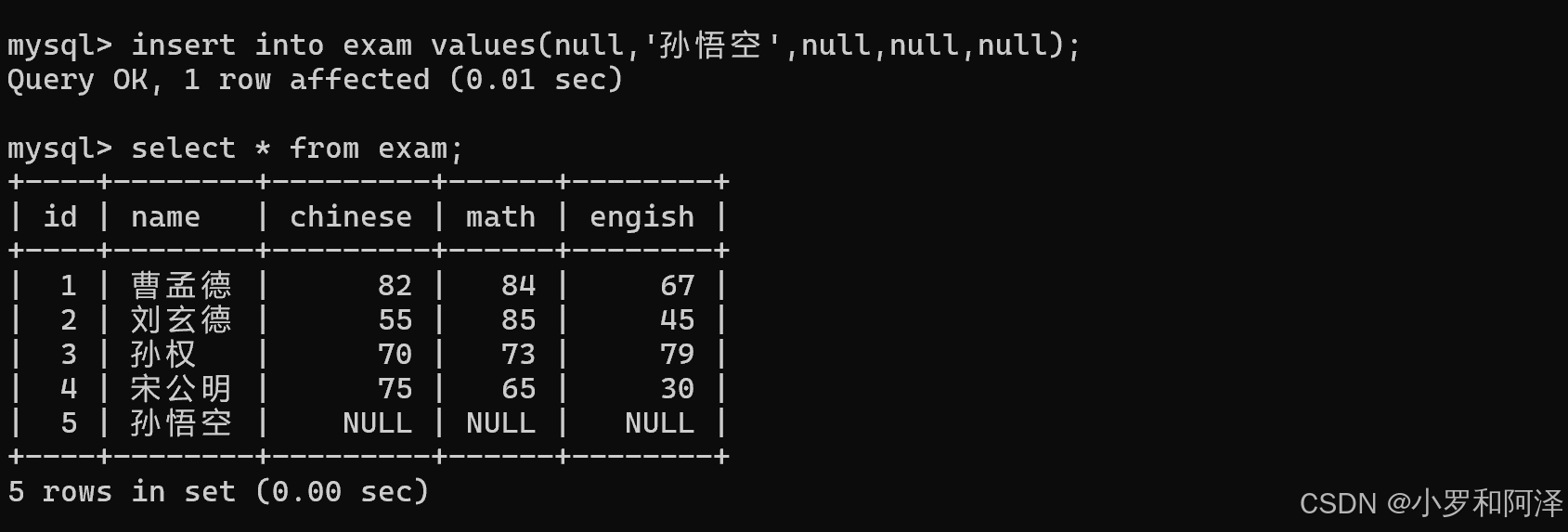
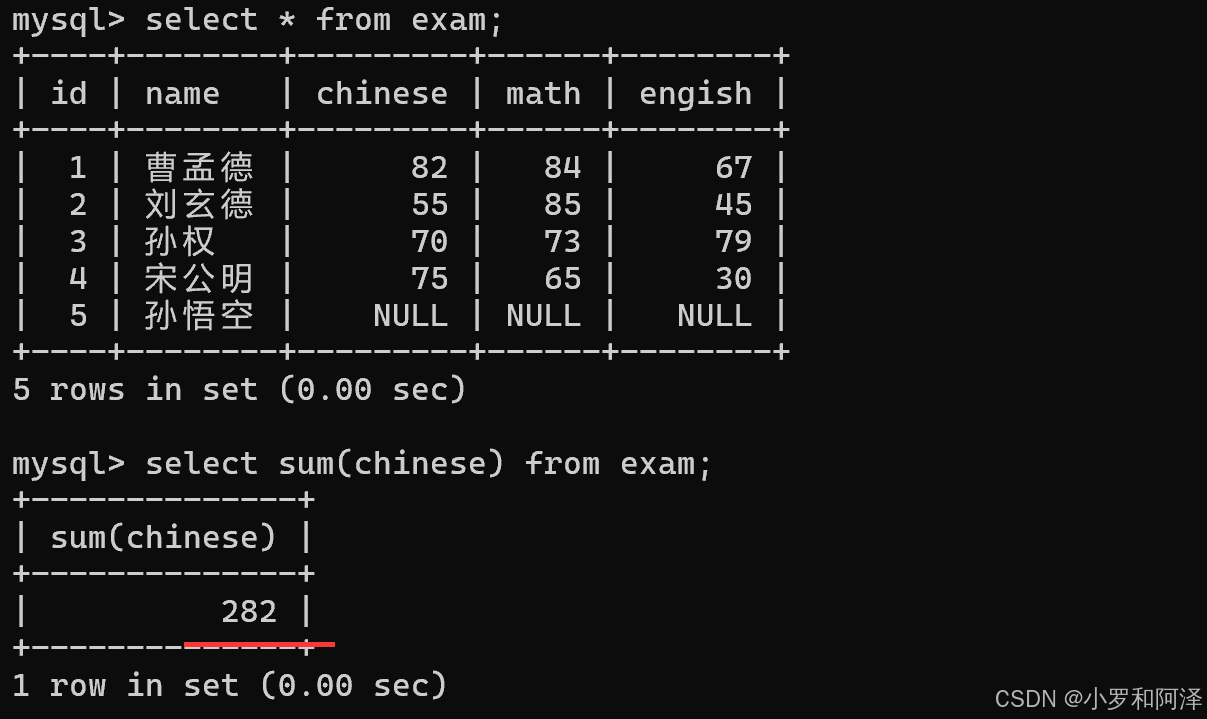
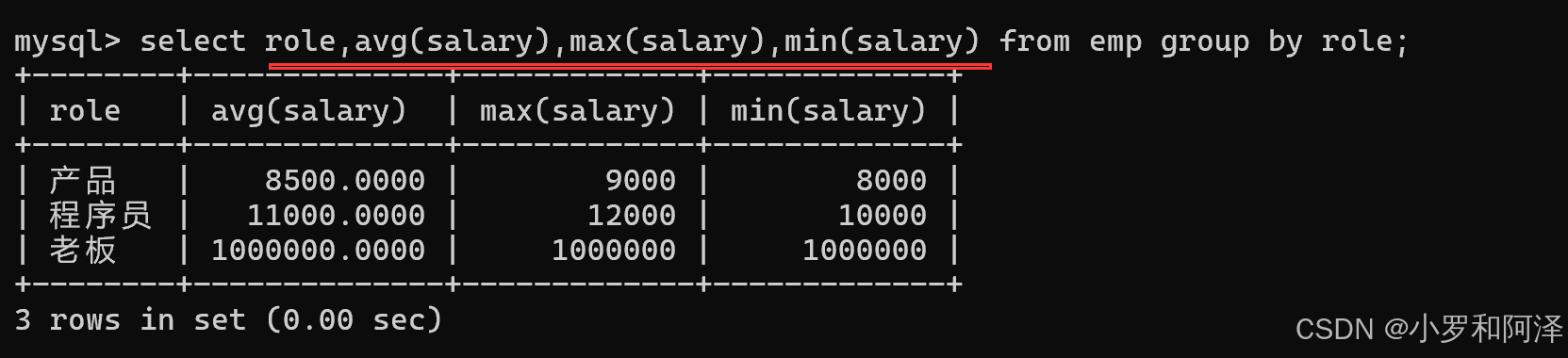
avg()
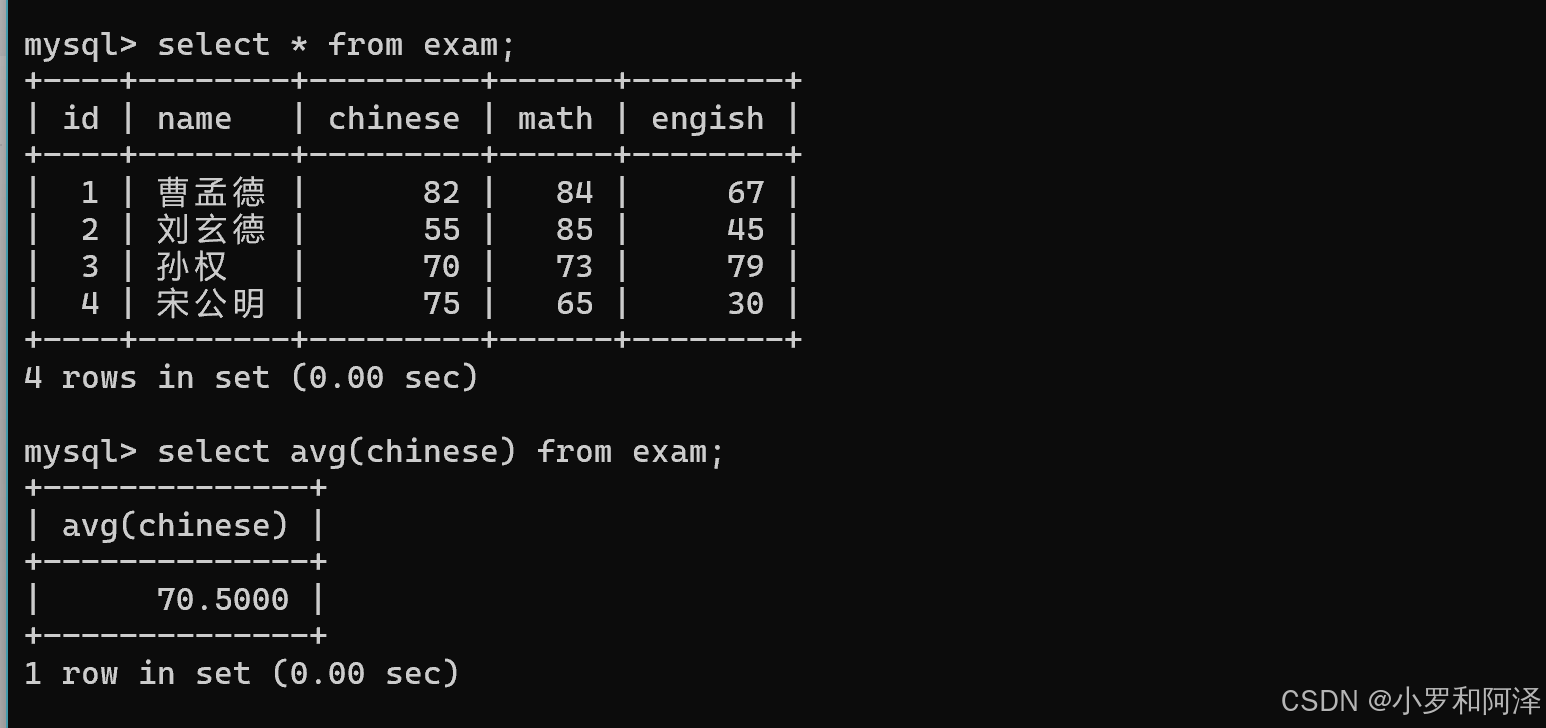
avg 函数 遇到 null 会直接跳过.
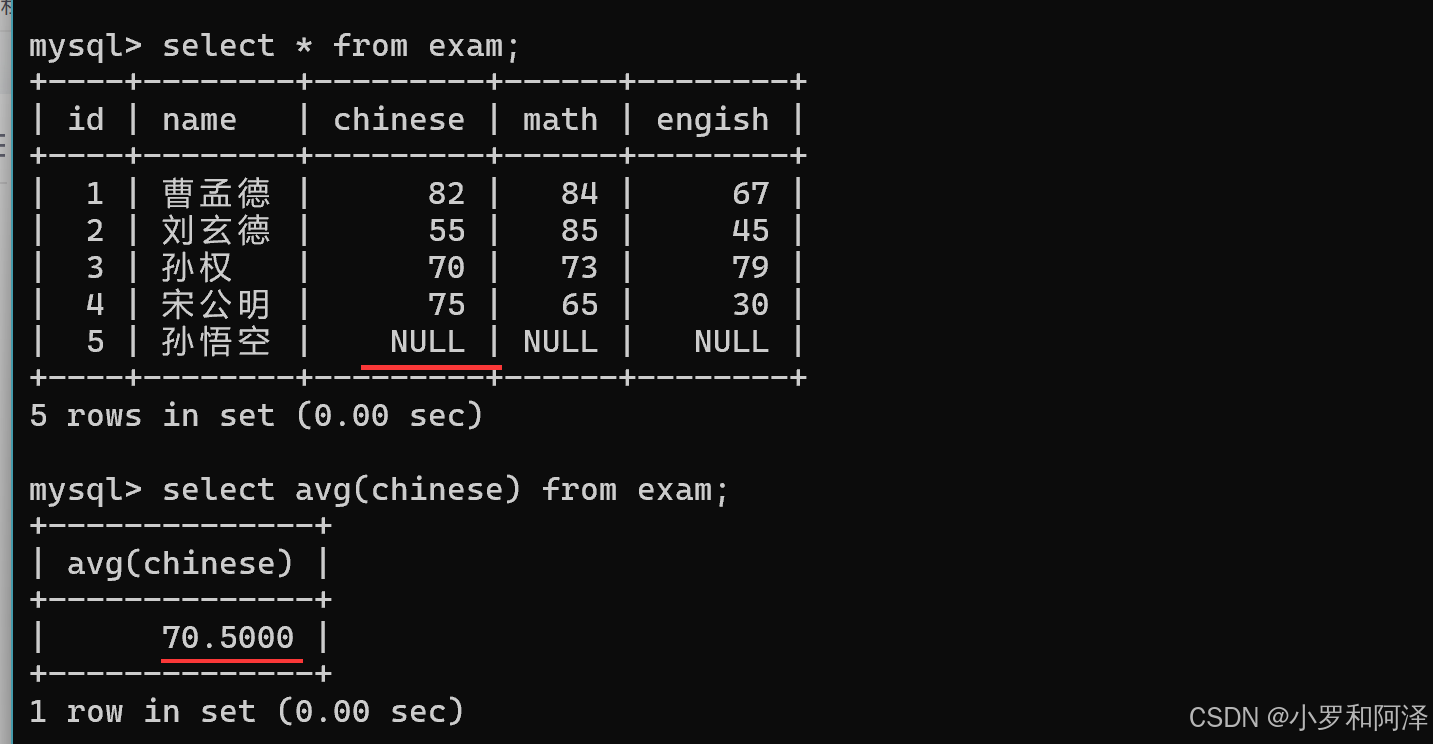
max()
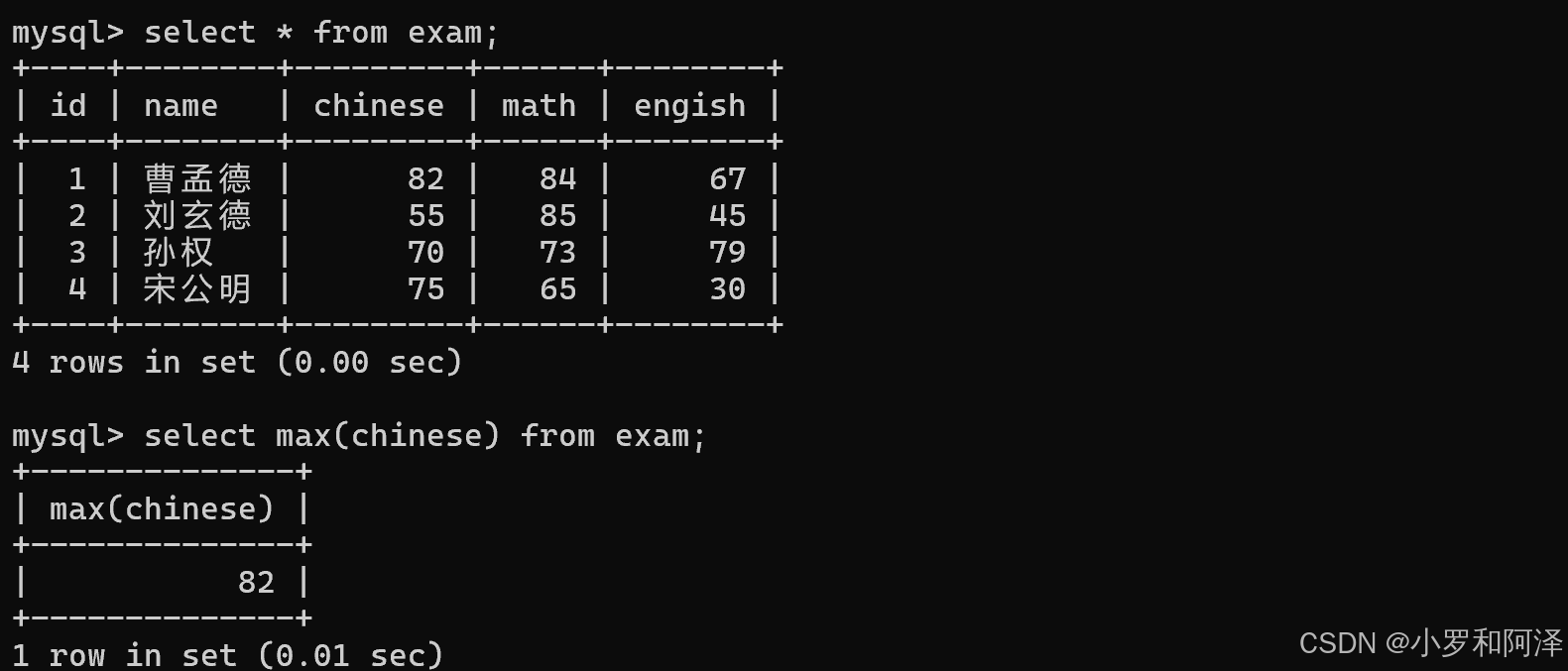
max 函数 遇到 null 会直接跳过.
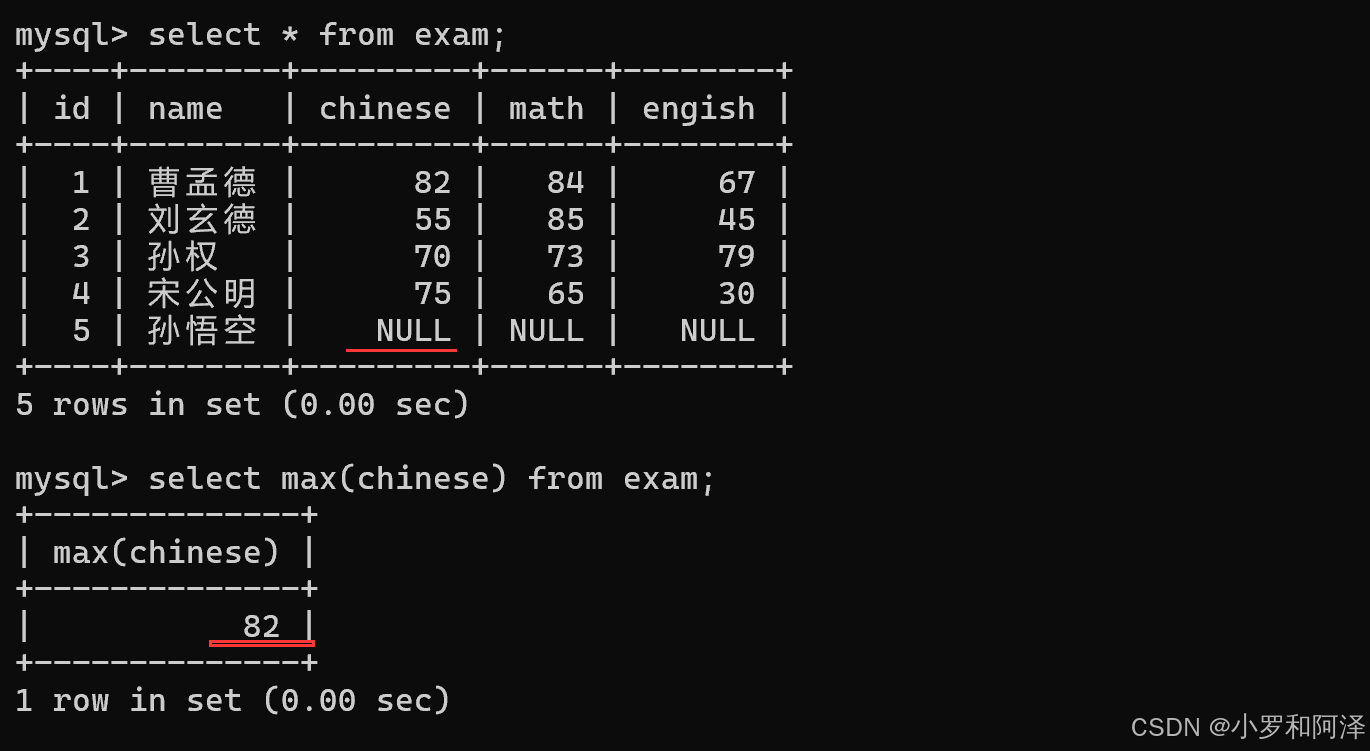
min()
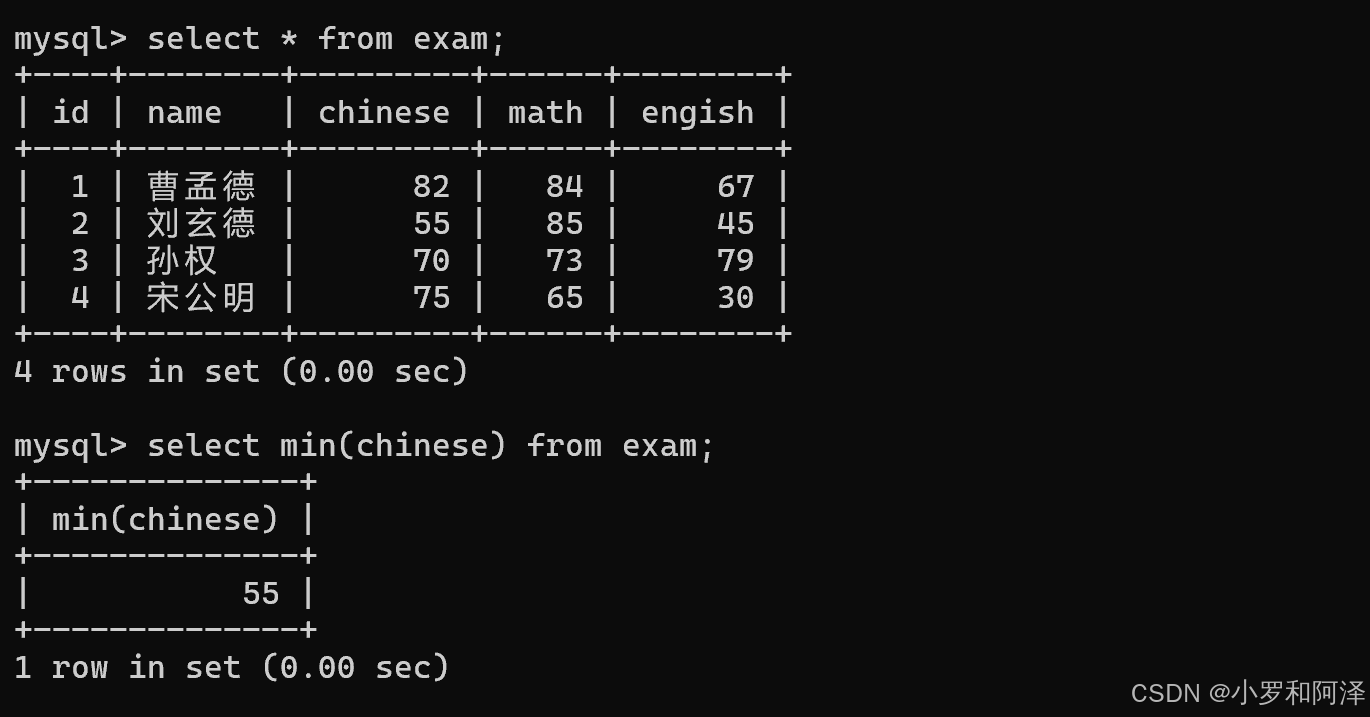
min 函数 遇到 null 会直接跳过.
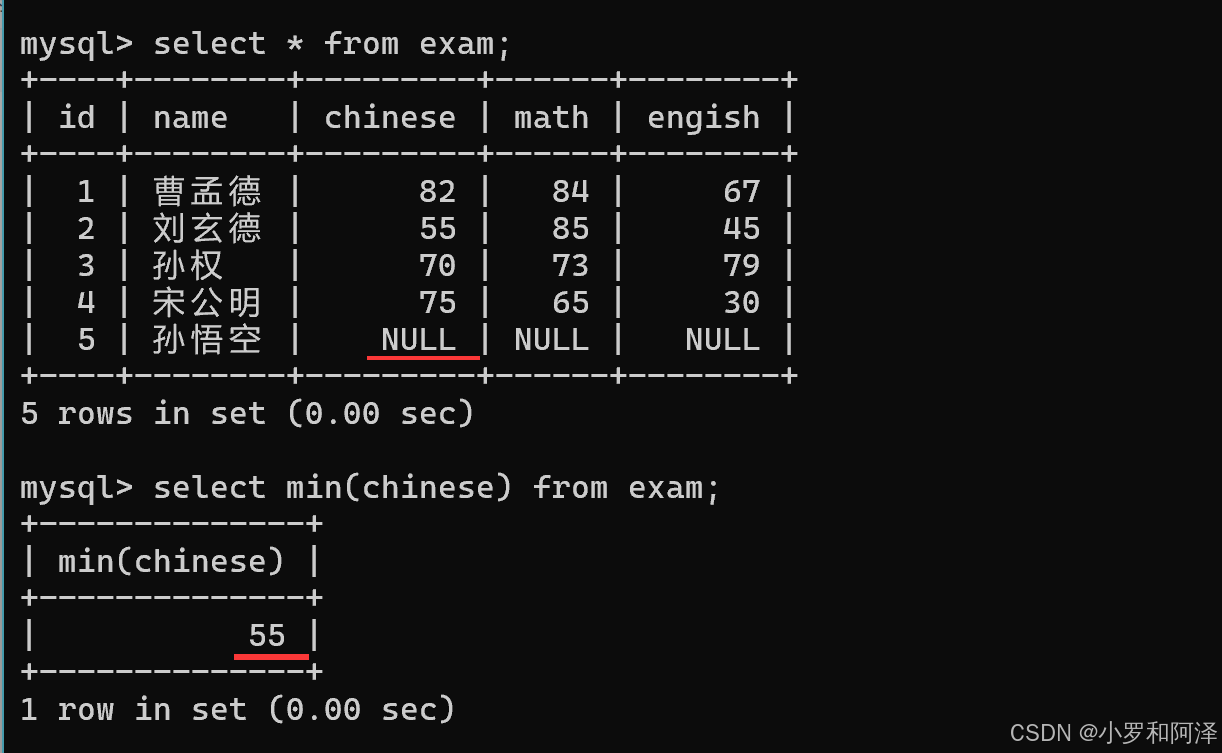
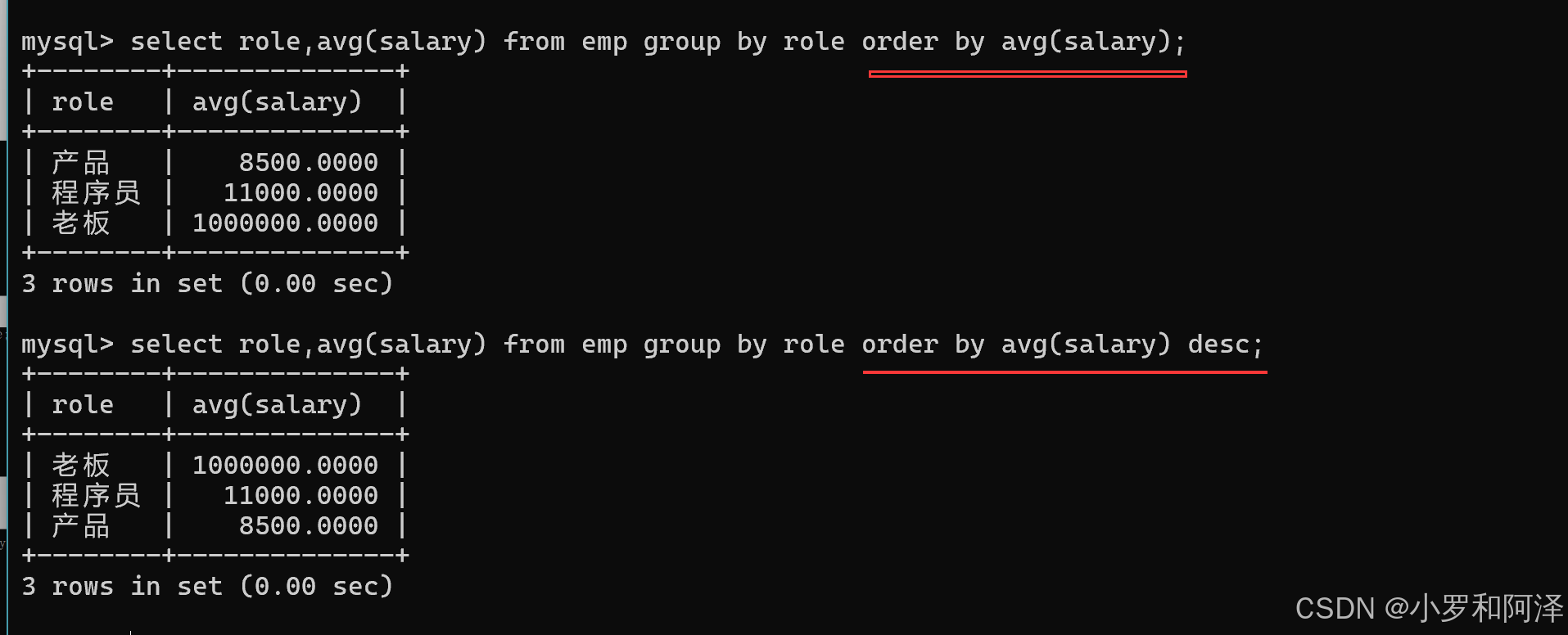
gourp by
在查询时,group by 大多数 是和 聚合函数 一起使用.
可以针对结果进行排序查询
group by 和 条件 一起使用
分组之前的条件 用 where 关键字.

分组之后的条件 用 having 关键字.

也可以同时使用

多表查询
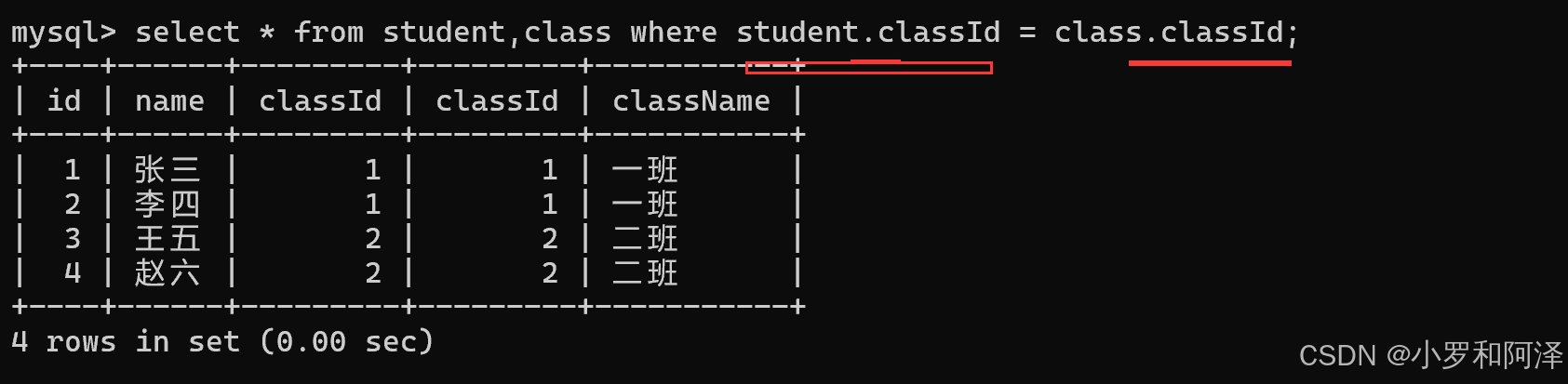
笛卡尔积
实际上就是把几张表中的数据,进行排列组合
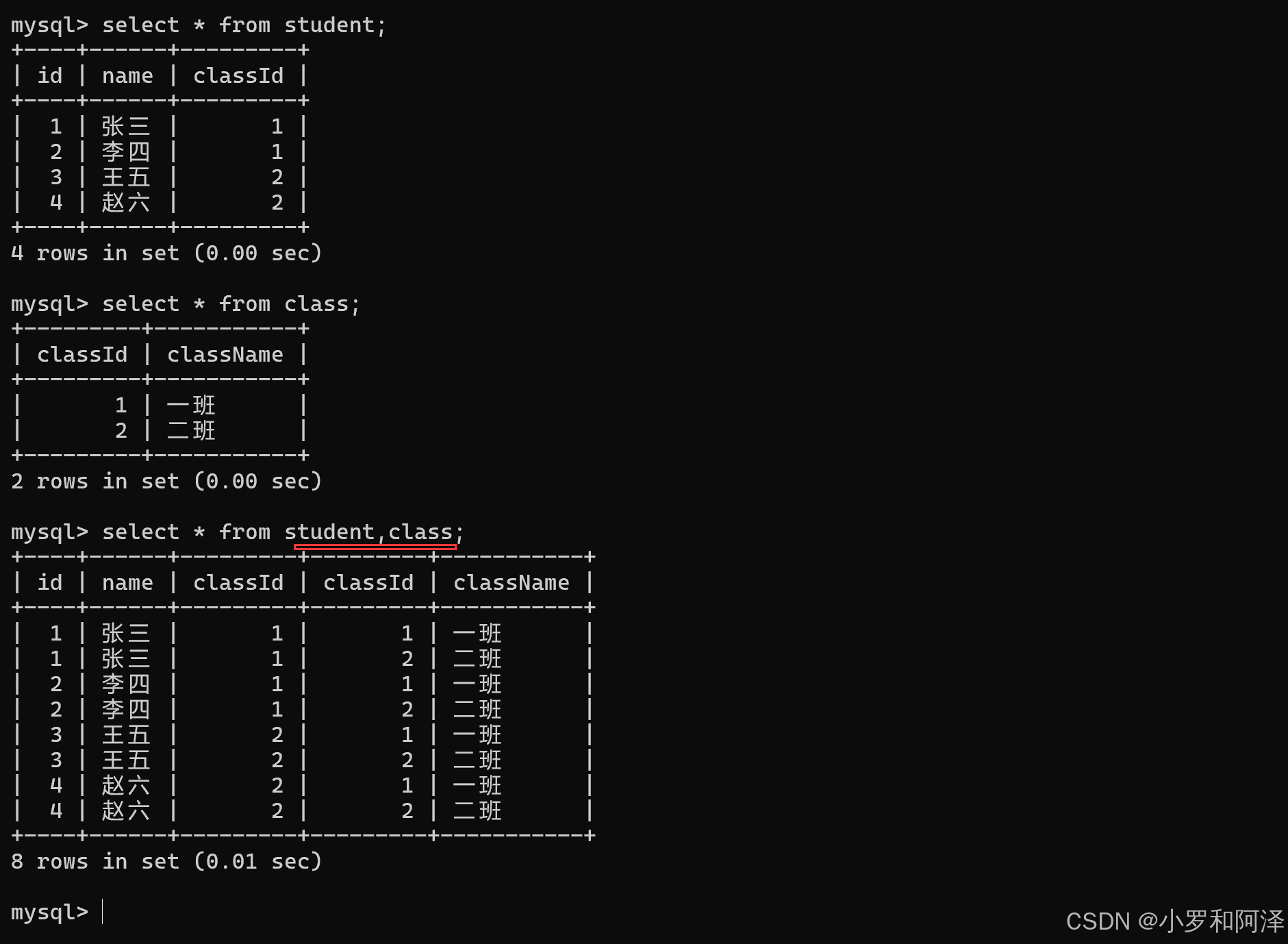
student.classId 中的 . 是 成员访问运算符,翻译为"的".
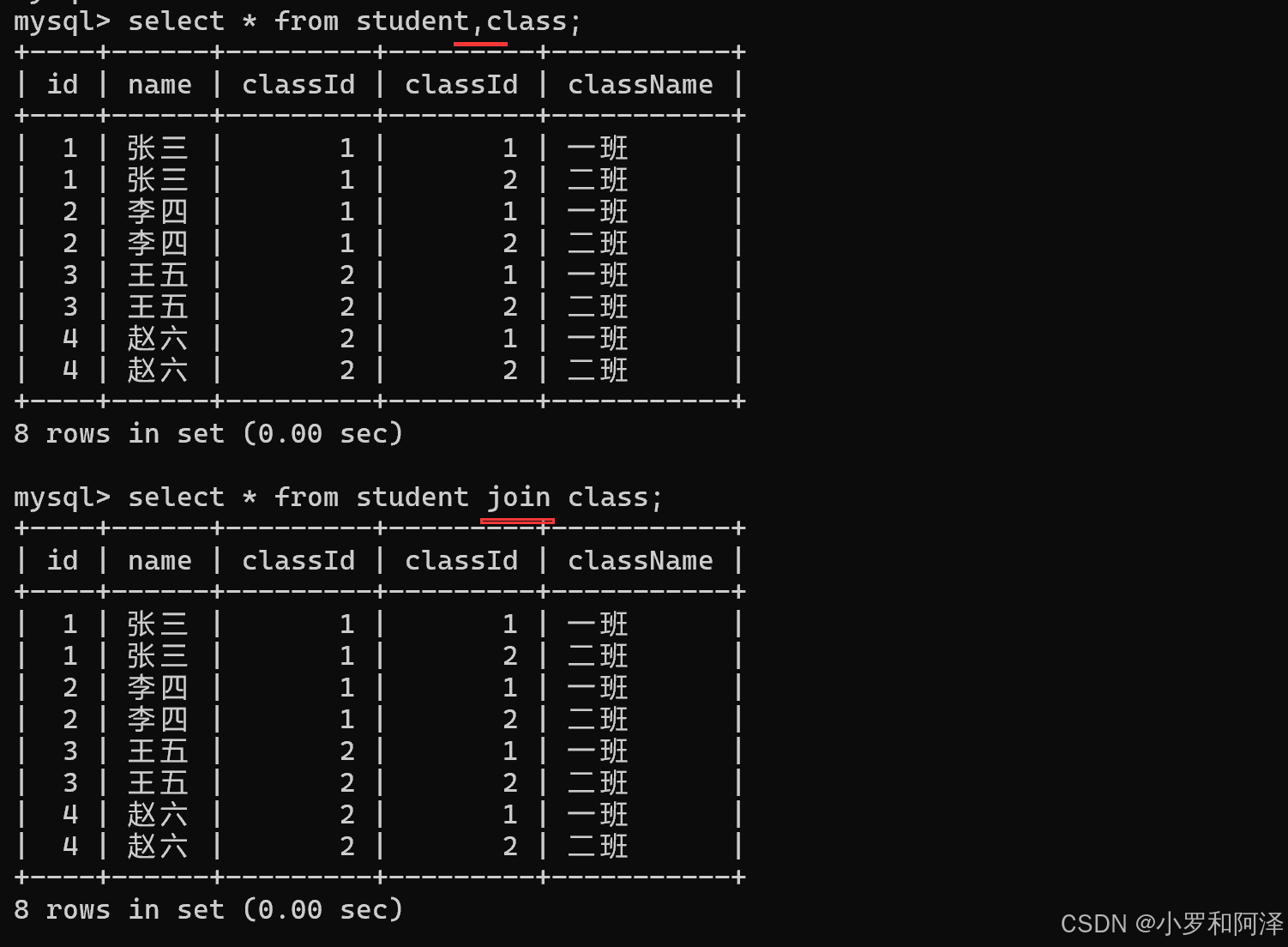
多表查询的另一种写法
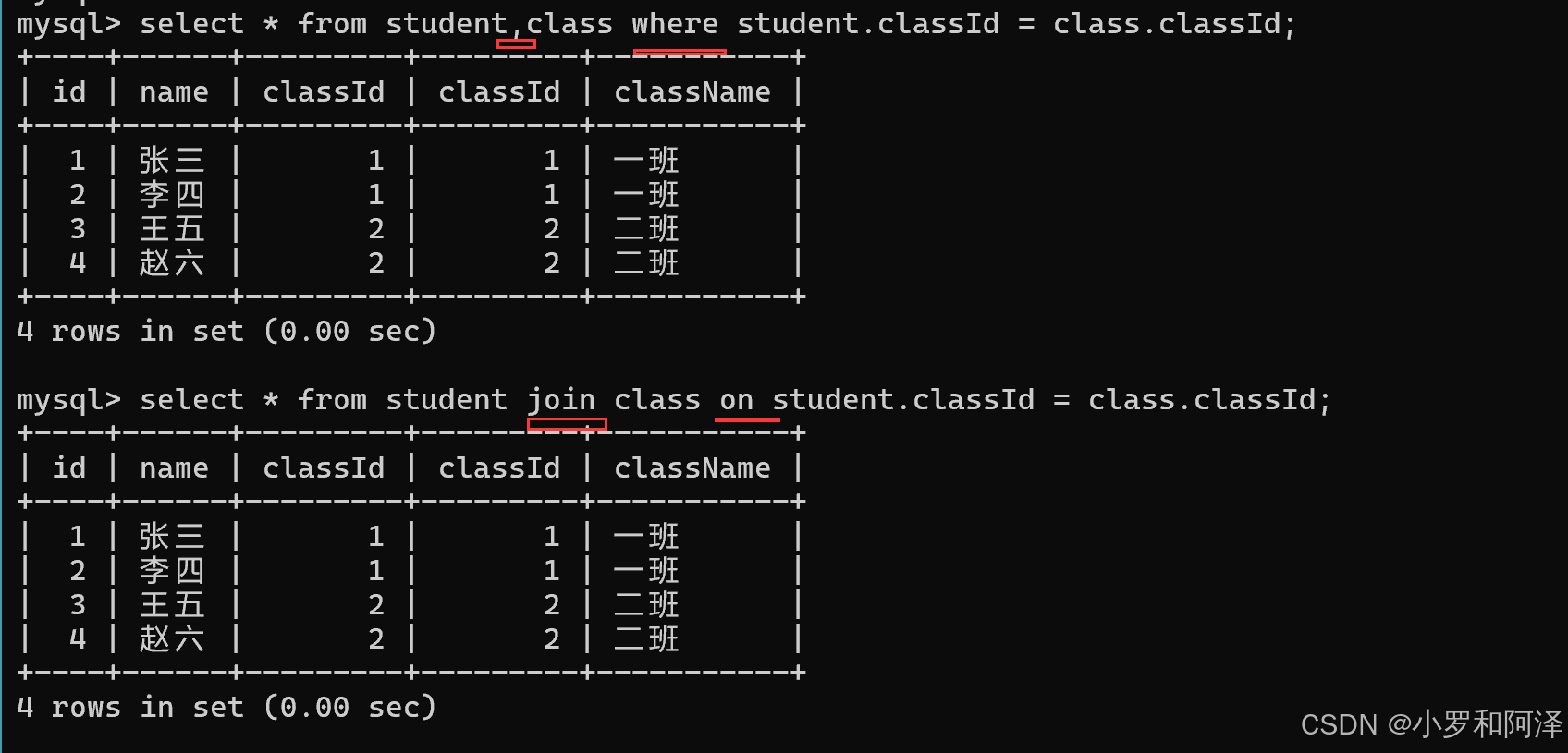
join on 写法
上一种 写法 可以简写为 " , where 写法".
合并查询
union 把多个select 查询结果 合并成一个
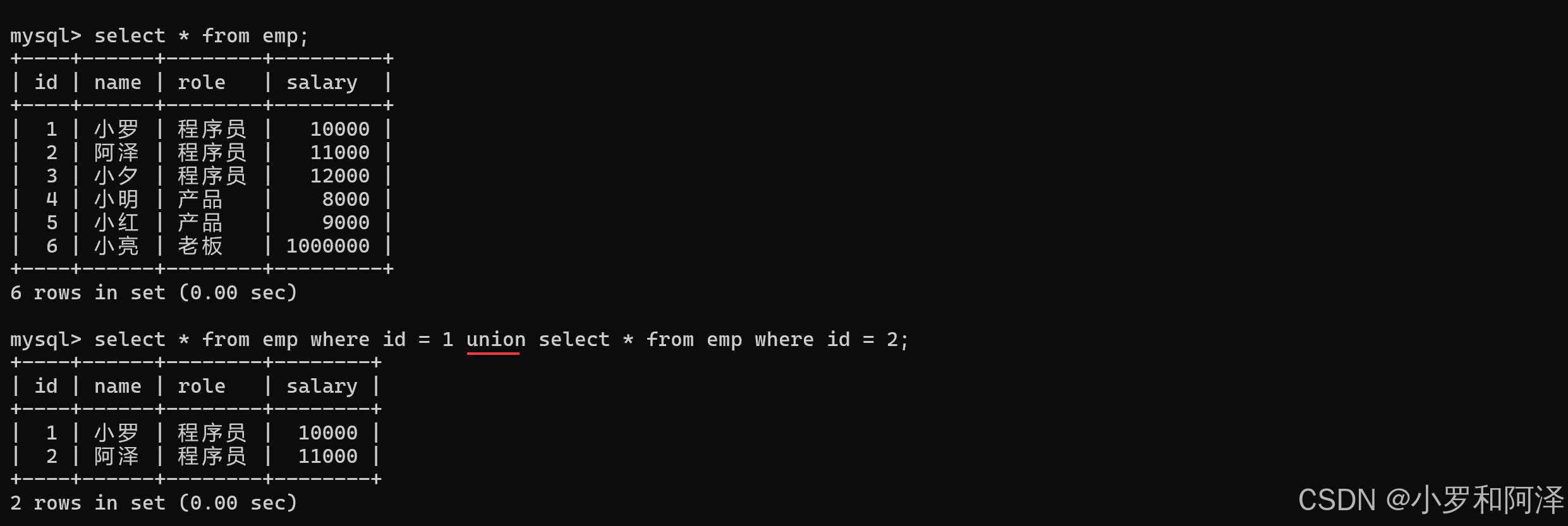
union 还可以 将 不同的表 的 查询结果整合到一起,前提是 两个表的列数相同
索引
查看索引
show index from 表名
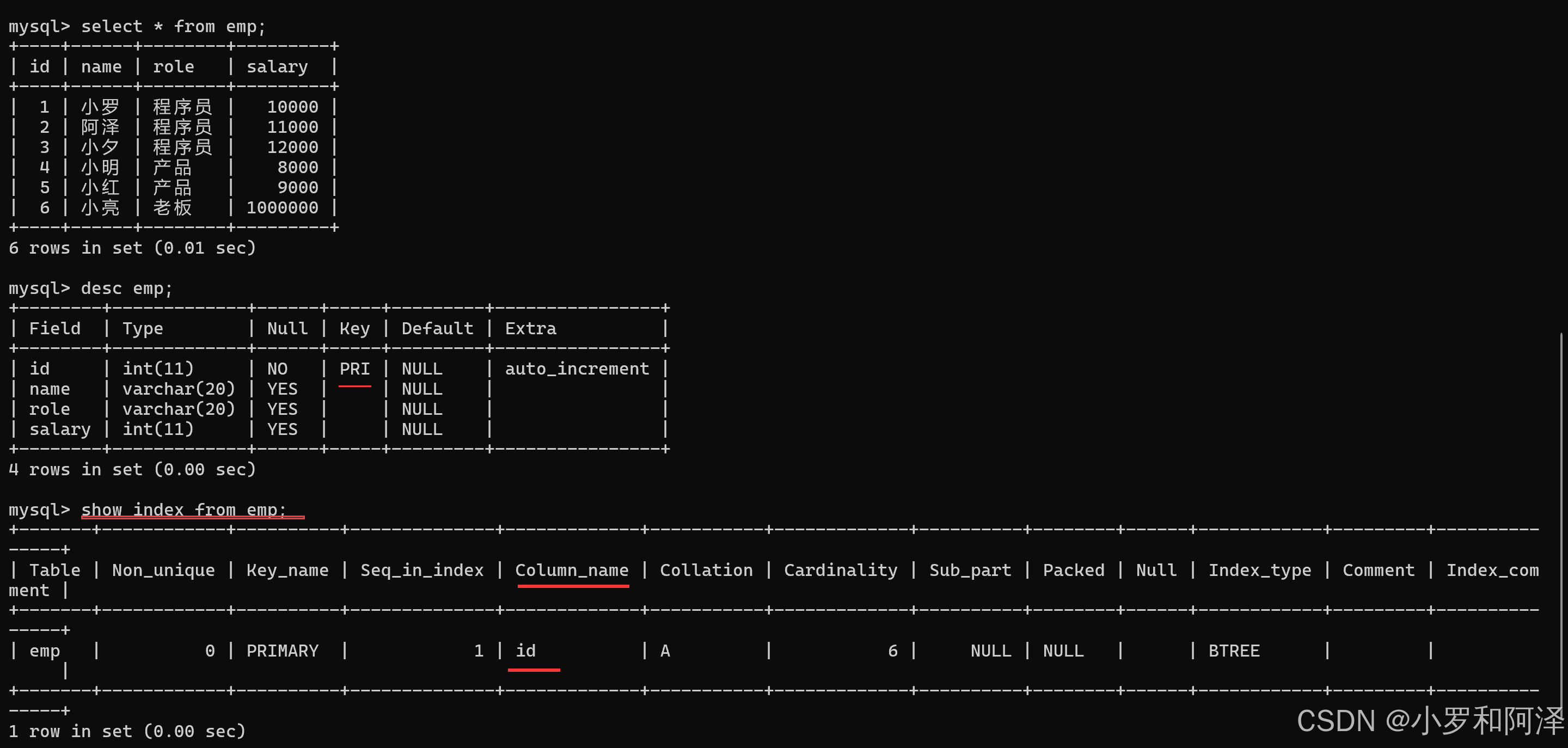
注:primary key、unique、foreign key 都会自动创建索引
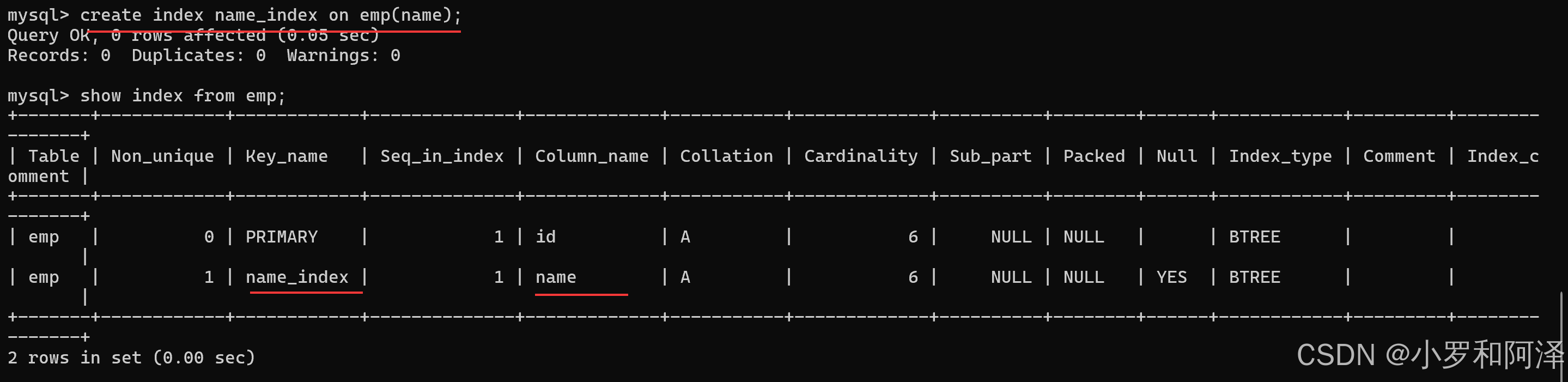
创建索引
create index 索引名 on 表名(列名)
删除索引
drop index 索引名 on 表名
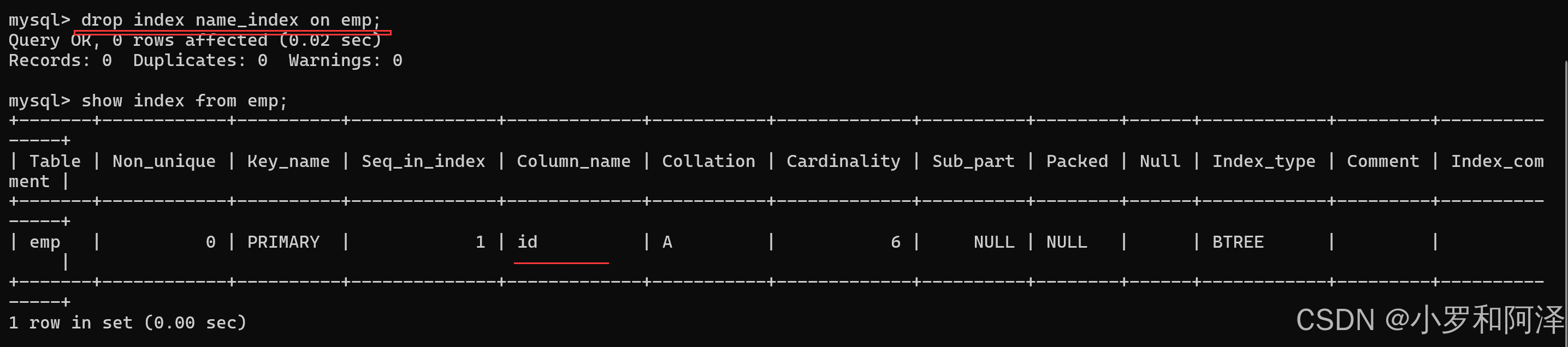
注:只能删除自己创建的索引,不能删除自动生成的索引
事务
事务是用来解决,一些特定场景的问题
这些特定场景需要进行完成的操作,需要多个sql配合完成.
列如:账户转账操作
(补一张图)
假设,账户A向账户B进行转账,而在同一时刻,发生改变的有两个地方,一个是账户A的账户金额数据,另一个是账户B的账户金额数据.
如果此处的操作是sql一句一句进行执行的,当执行A账户数据减少时完成过后,突然发生了电脑死机,或者停电的情况,那么A的账户数据改变了,但B的账户却没有发生改变,这里产生的损失是不可忽视的.
因此所谓事务,就相等于把多个要执行的sql,打包成一个"整体",这个"整体"在执行过程中,要么全部都执行,要么就执行了一部分,再使用回滚机制进行还原.
事务的ACID特点
可靠数据库所具有的四个特性:原子性,一致性,持久性,隔离性.
事务最核心的特性,就是原子性。
原子性
指事务是一个不可再分割的工作单位.事务中的操作要么全部执行,要么都不执行.
一致性
事务执行前和执行后,数据库中的数据,都是"合法状态",不会出现非法的临时结果.
持久性
事务执行完毕之后,就会修改硬盘上的数据,事务都是持久生效的.
隔离性
在并发执行时,当不同的事务同时操作时,每个事务各自都是独立的.
如果这些同时执行的事务,恰好是针对同一张表,进行一些增删改查操作,此时可能会引入一些问题.
脏读(读取未提交的数据)
有两个事务A和B并发执行,其中事务A在针对某个表的数据进行修改,A执行过程中,B也去读取这个表的数据,当B读完之后,A把表中的数据修改了.
这就导致,B读到的数据,就不是最终的"正确数据",而是读到了临时性的数据(脏数据).
不可重复读(前后多次读取,数据内容不一致)
此时,有三个事务,ABC
首先,事务A执行一个修改操作,A执行完毕时,提交数据,接下来事务B执行,事务B读取刚才A提交的数据,在B读取的过程中,事务C对刚才A修改的数据进行了修改
此时对应B来说,再读取数据时,读到的结果就和第一次读到的结果时不同的
此过程就叫"不可重复读"
幻读
有一个事务A在读取数据,读的过程中,另一个事务B,修改了一些其他数据,此时站在A的角度,多次读取的数据内容虽然一样,但"结果集"不同
这三个问题"脏读","不可重复读","幻读"和隔离性的关系
mysql中提供了四个隔离级别,可以通过配置文件来设置当前服务器的隔离级别是哪个级别
设置不同的隔离级别,就会使事务之间的并发执行的影响产生不同的差别,从而影响上述三个问题的情况
1)read uncommitted 读未提交
这种情况下,一个事务可以读取另一个事务未提交的数据,此时,就可能产生 脏读,不可重复读,幻读 三种问题.
此时,多种事务并发执行程度是最高的,执行速度也是最快的.
2)read committed 读已提交
这种情况下,一个事务只能读取另一个事务提交之后的数据,此时,可能会产生 不可重复读,幻读问题(脏读问题已解决~~)
此时,并发程度会降低,执行速度变慢,同时,事务之间的隔离性提高(事务之间的相互影响变小了,得到的数据更准确了~~)
3)repeatable read 可重复读(mysql默认)
这种情况下,无论其他事务是否修改并提交了数据,在这个事务中看到的数据值始终不受其他事务的影响
此时,可能产生幻读问题,解决了脏读和不可重复读问题
并发程度进一步降低,执行速度进一步变慢,事务之间的隔离性,进一步提高
4)serializable 串行化
此时,所有的事务都是在服务器上一个接一个执行的
此时,解决了脏读,不可重复读,幻读问题
并发程度最低,执行速度最慢,隔离性最高,数据最准确.
看到此处,我们可能会发出疑问,我们为什么不一直用最后一个串行化,这样所有数据都是最准确的?
对此,我们需要看具体情况,有时我们需要更快的场景,那么准确性需要稍微牺牲一下(比如说短视频的点赞数),但有时我们需要更准确的场景(账户转账).