客户环境
客户环境
生产环境是11.2.0.4
测试环境是11.2.0.1
测试环境sql执行很快,生产上要7秒左右。
生产环境是刚做数据迁移之后,并且运行一段时间。

统计信息收集方式对比
生产环境:dbms_stats.gather_table_stats
测试环境:analyze语句分析的。
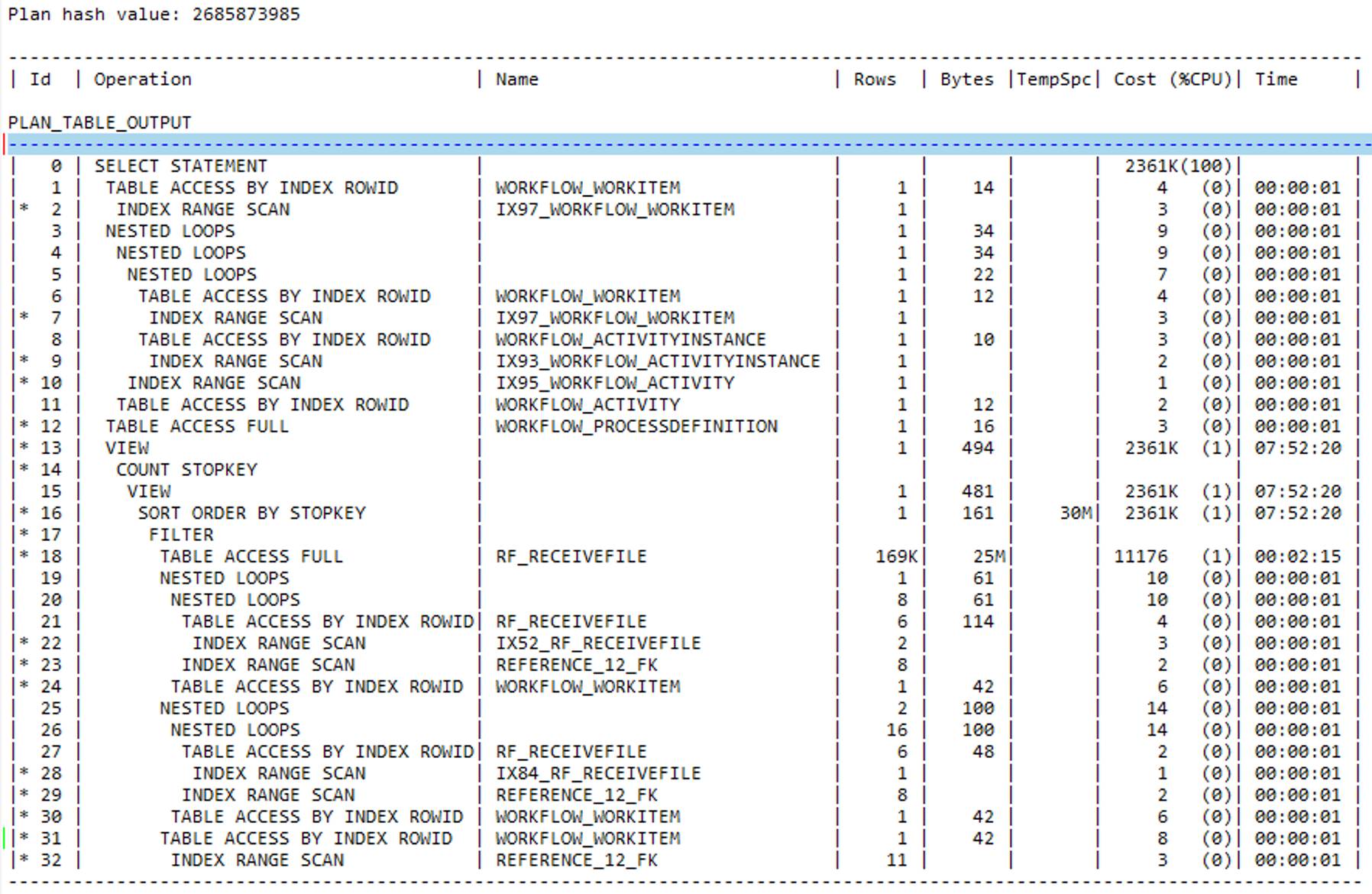
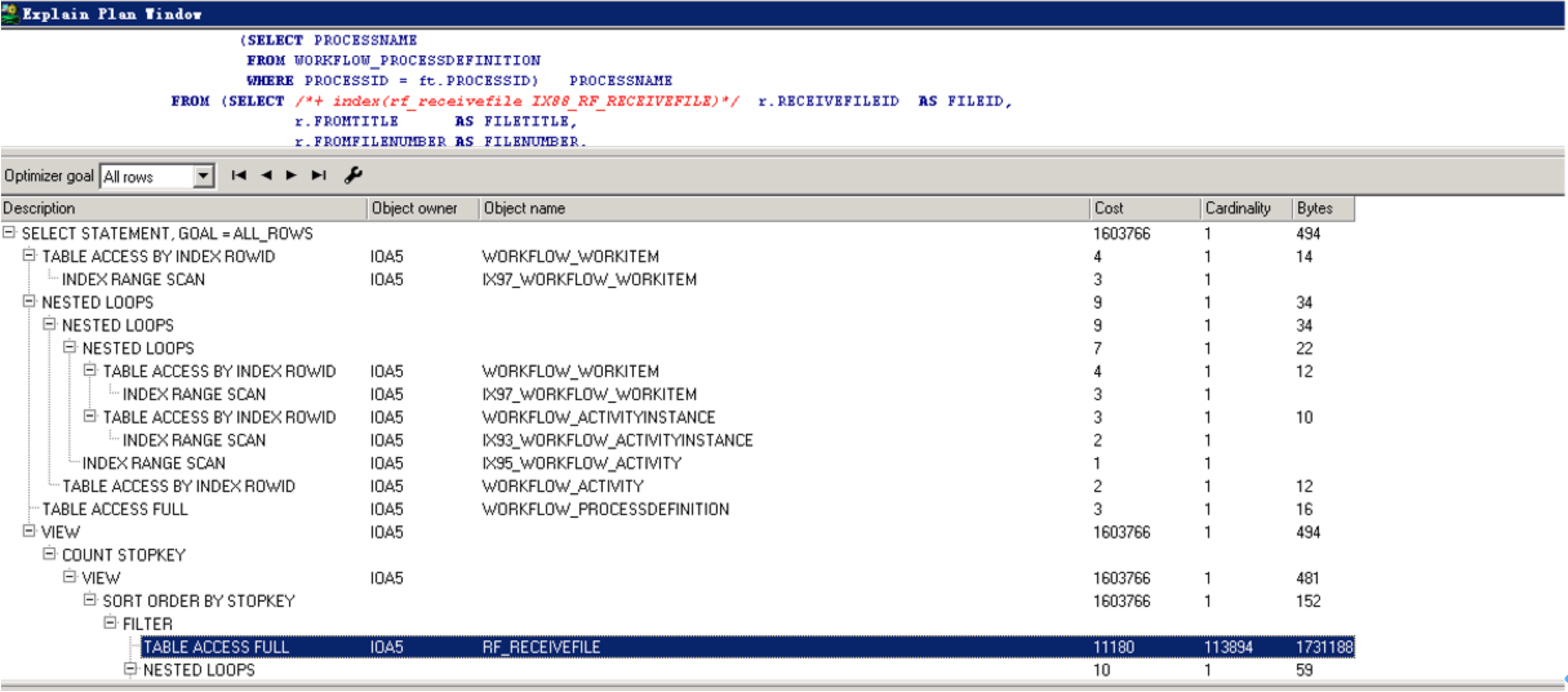
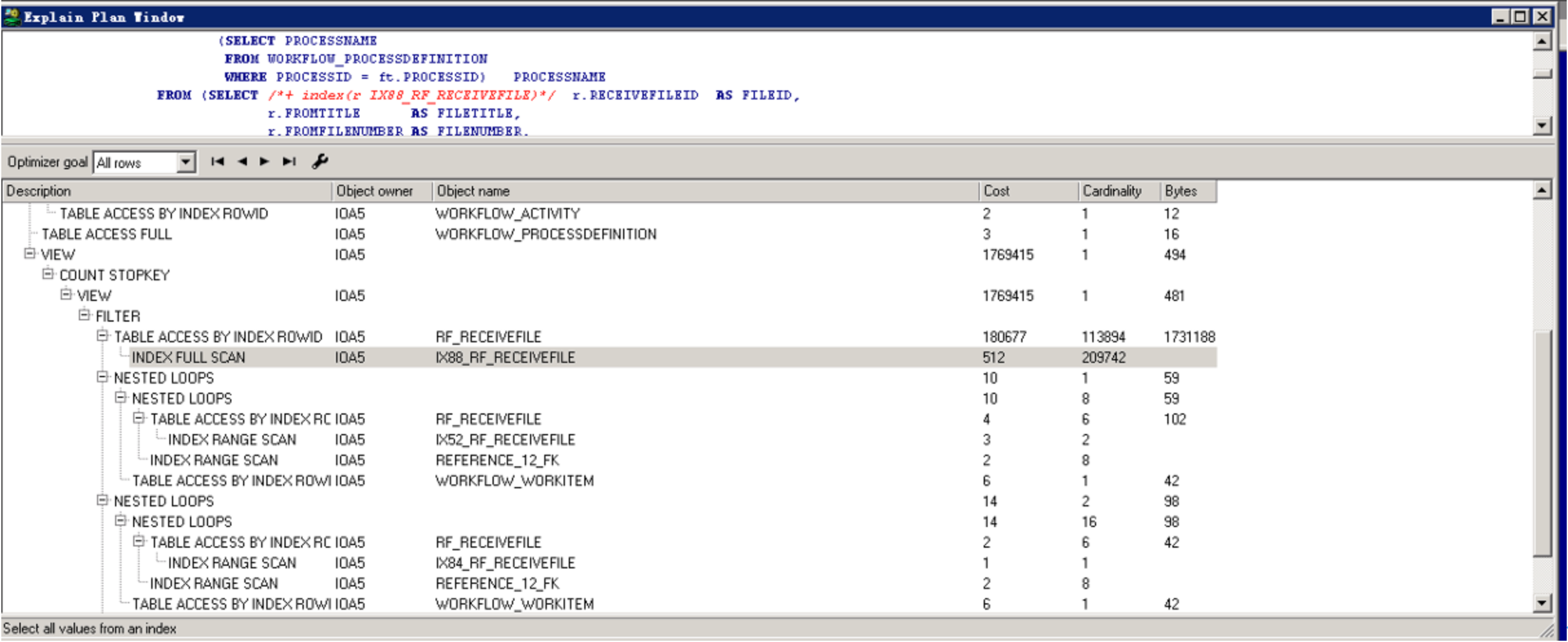
执行计划现象与说明
SORT ORDER BY STOPKEY(按列顺序对行进行排序。使用 ROWNUM 伪列限制返回的行数),一般常见于分页语句里面order by操作,减少排序操作将会大大降低成本。
对比两边的执行计划,发现IOA5.RF_RECEIVEFILE表测试环境上走索引,生产环境上面走的是全表扫描。
排查过程
排查过程
检查统计信息:
检查统计信息:
生产:

测试:

检查索引的状态:
检查索引的状态:
生产,测试:
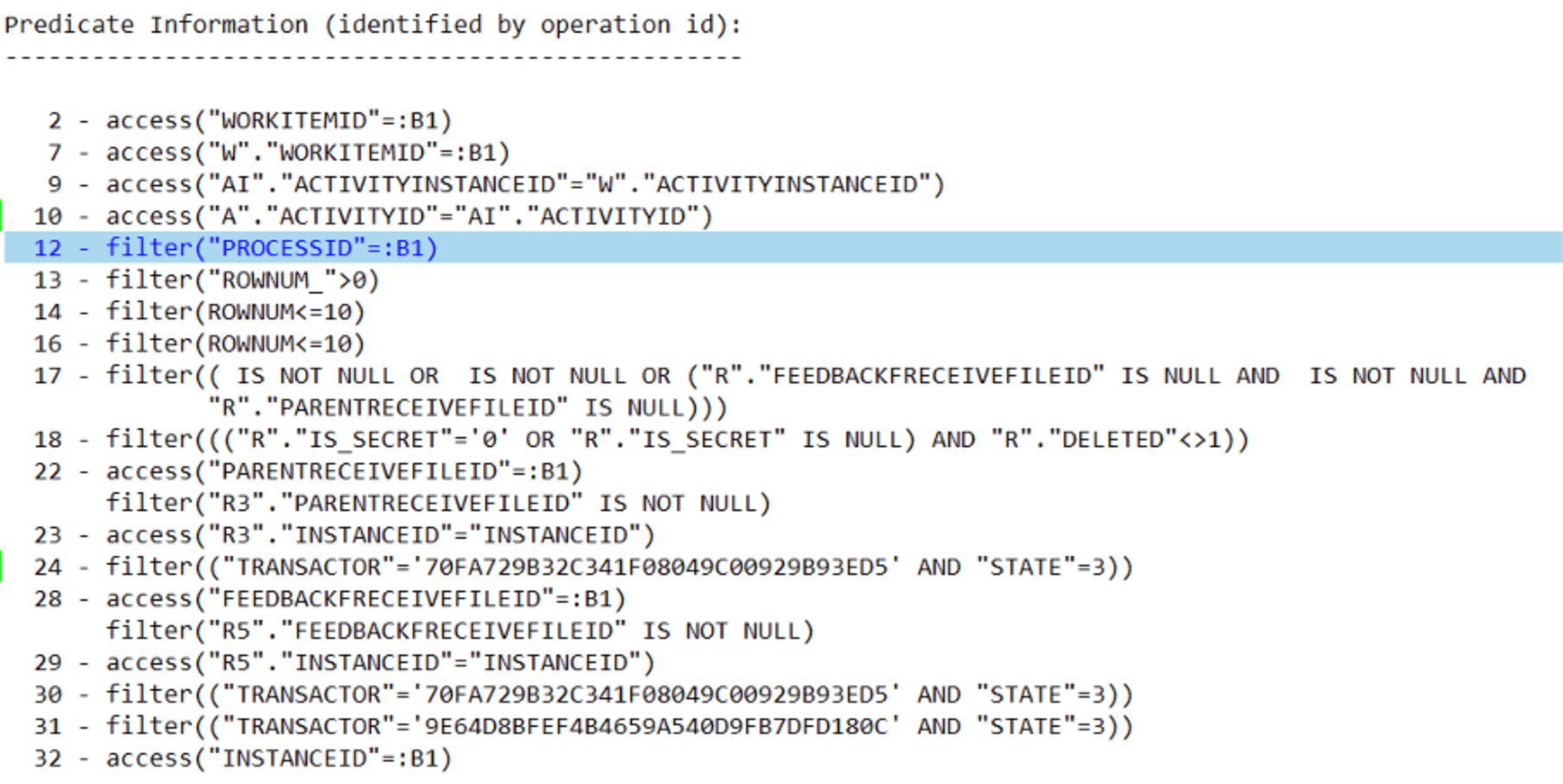
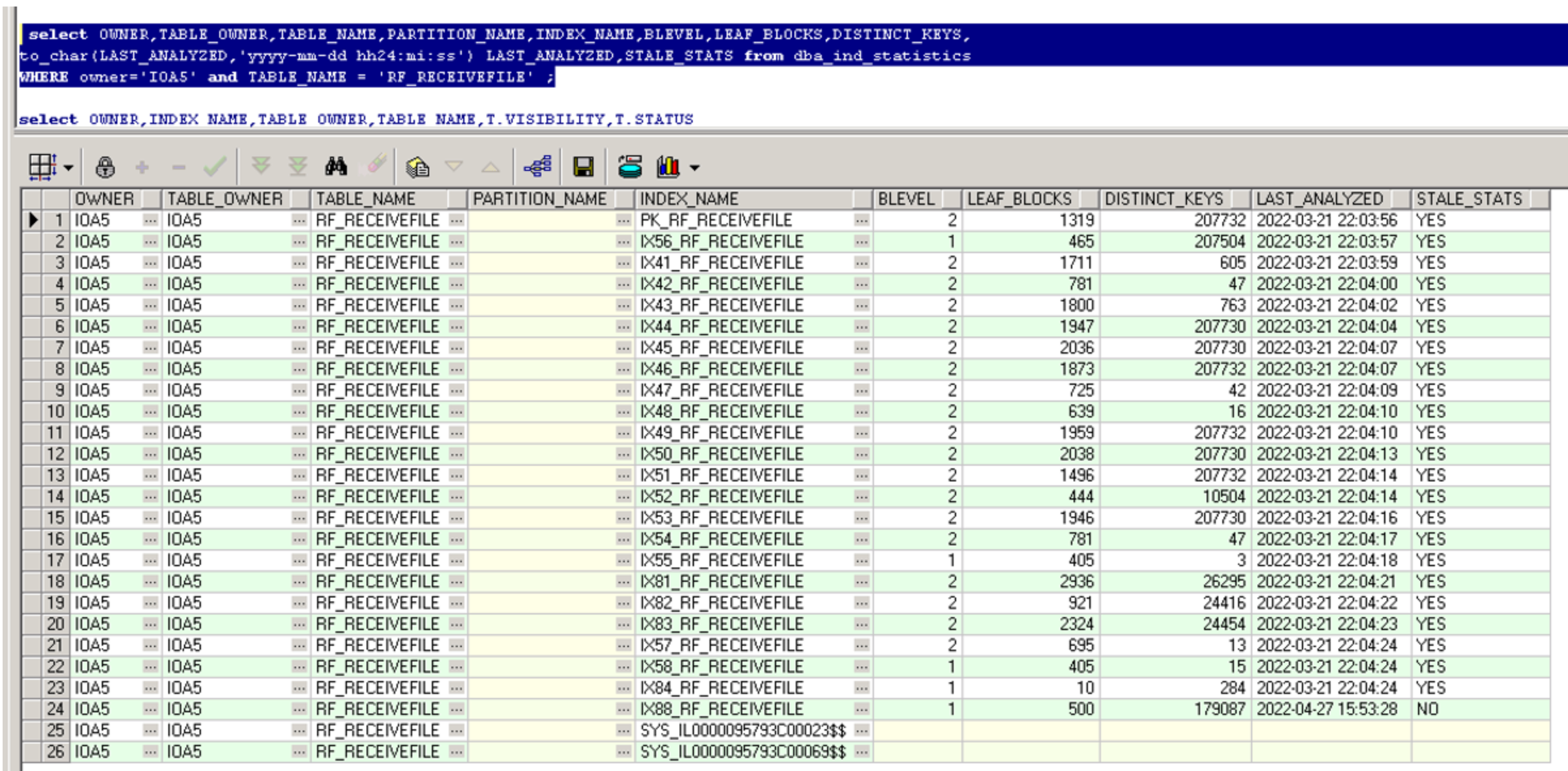
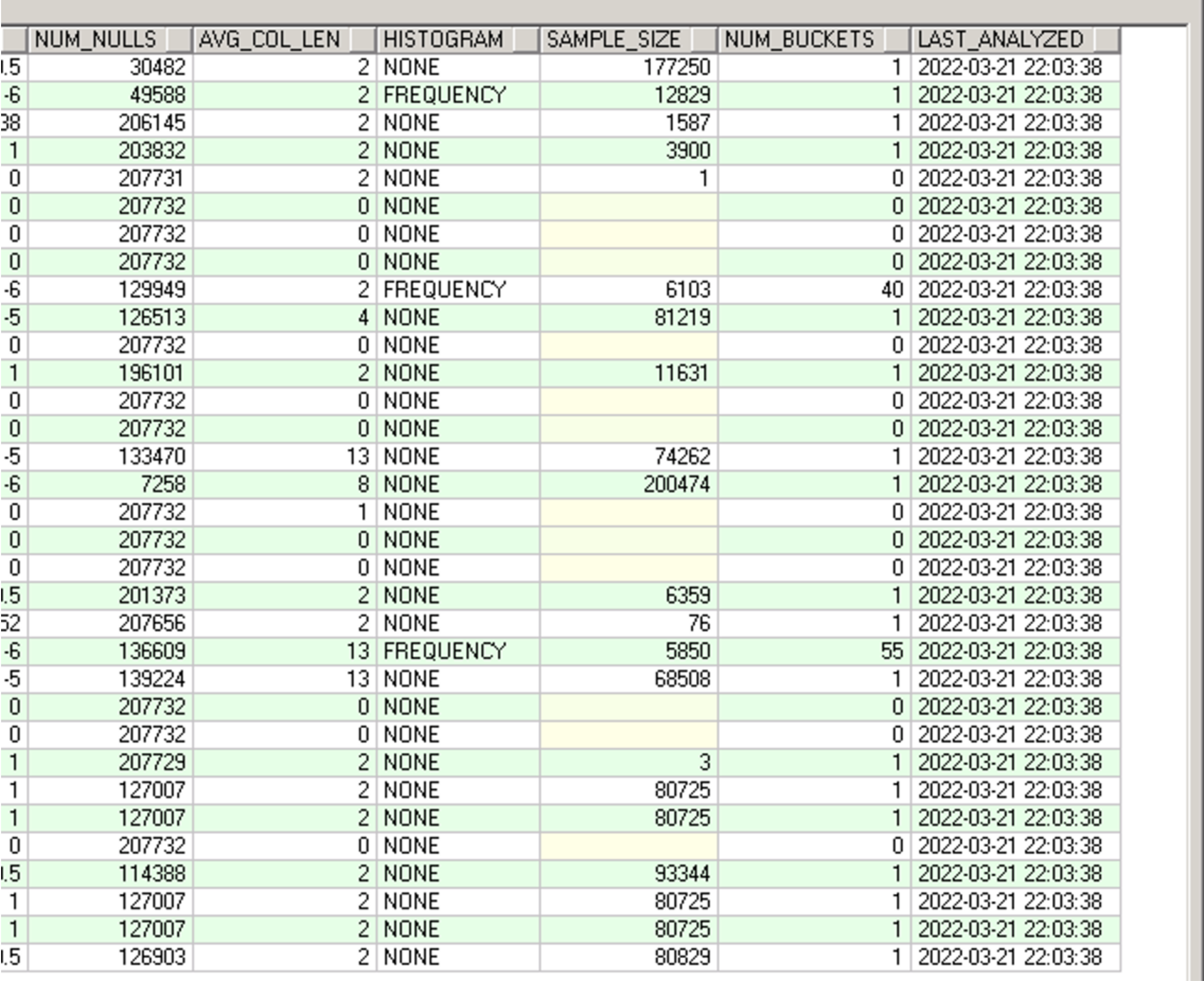
检查索引的统计信息:
检查索引的统计信息:
生产:
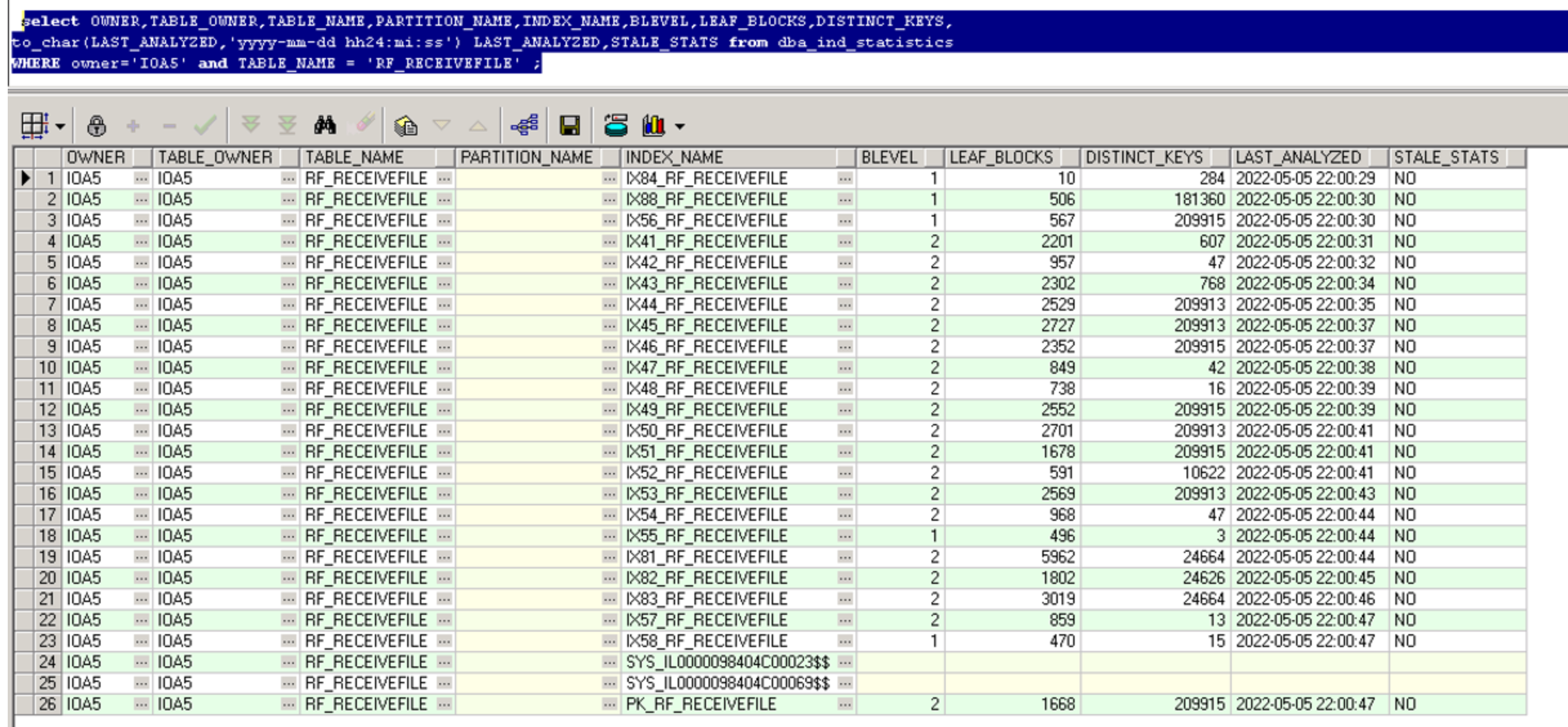
测试:
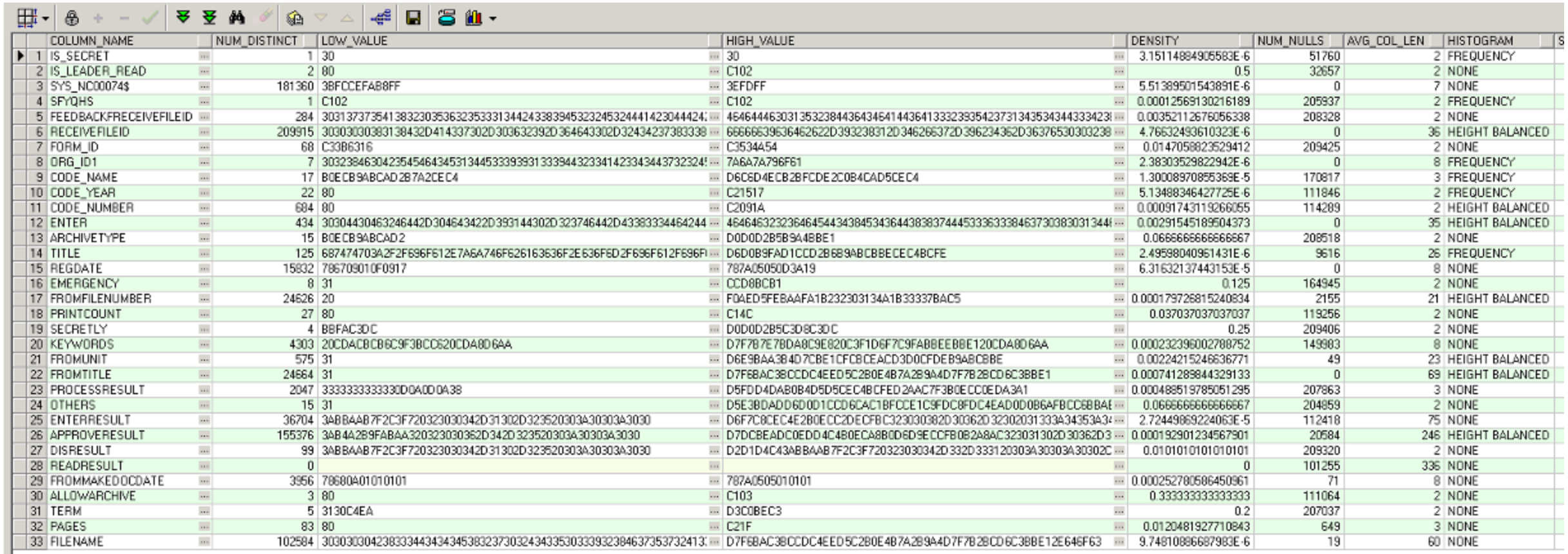
检查直方图信息:
检查直方图信息:
生产:
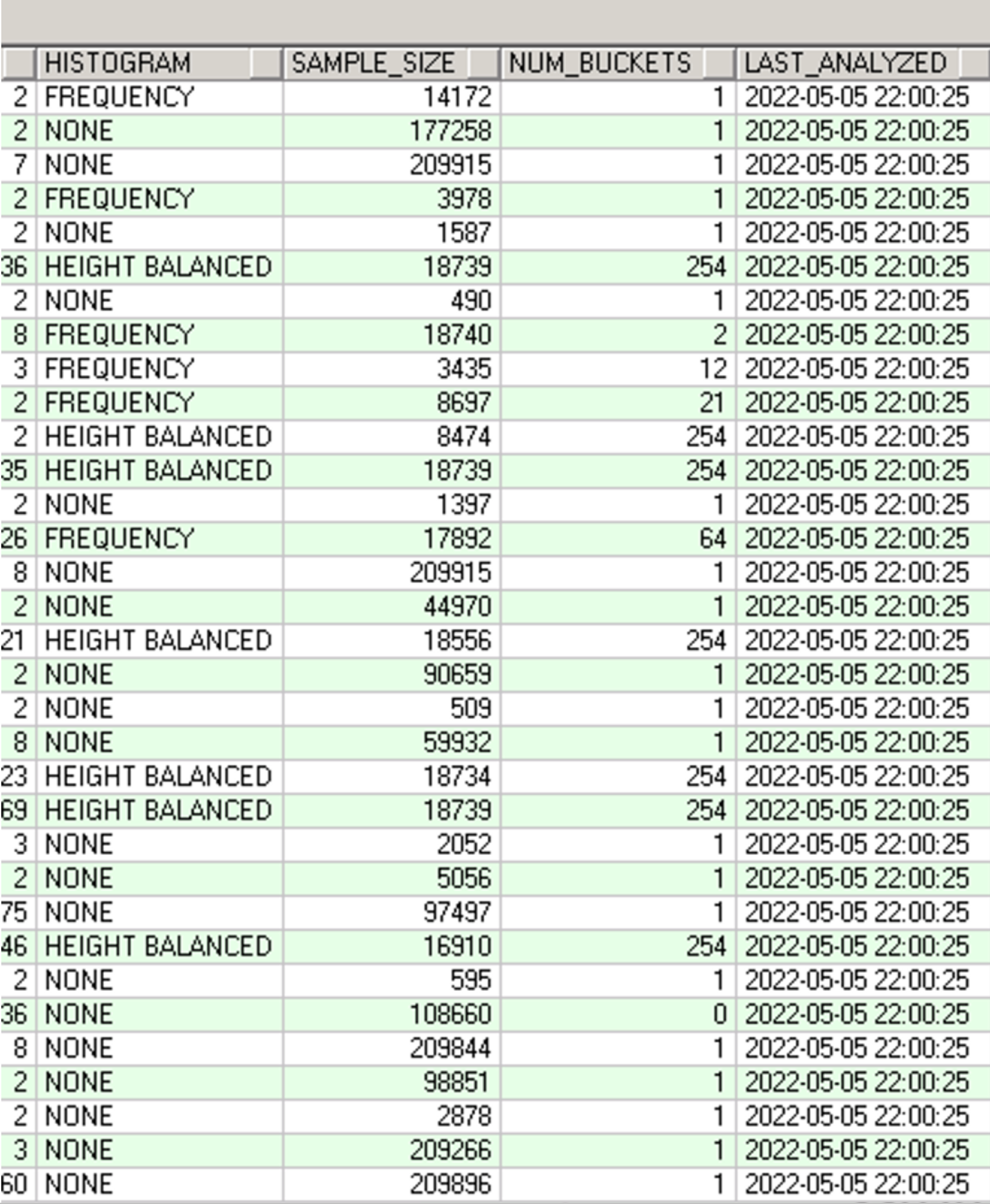
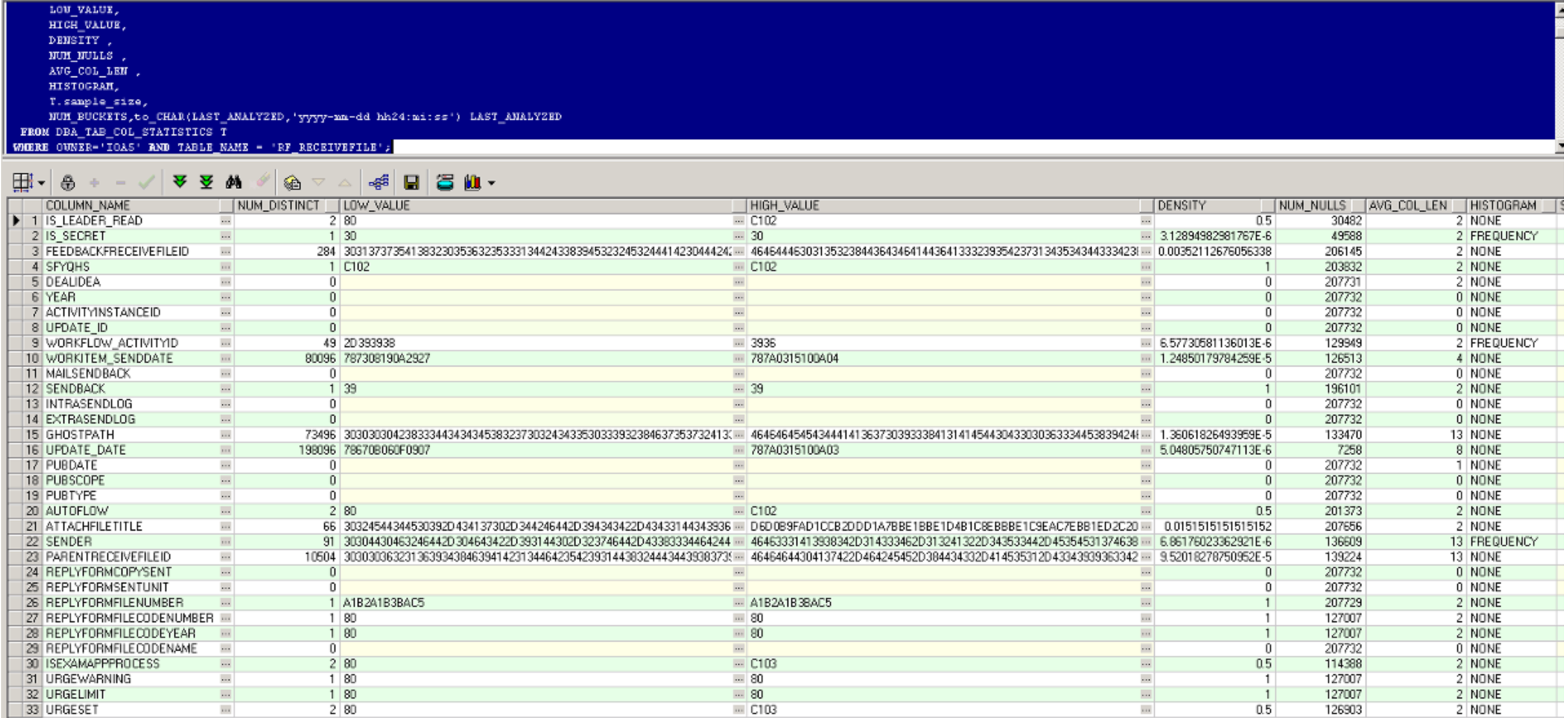
测试:
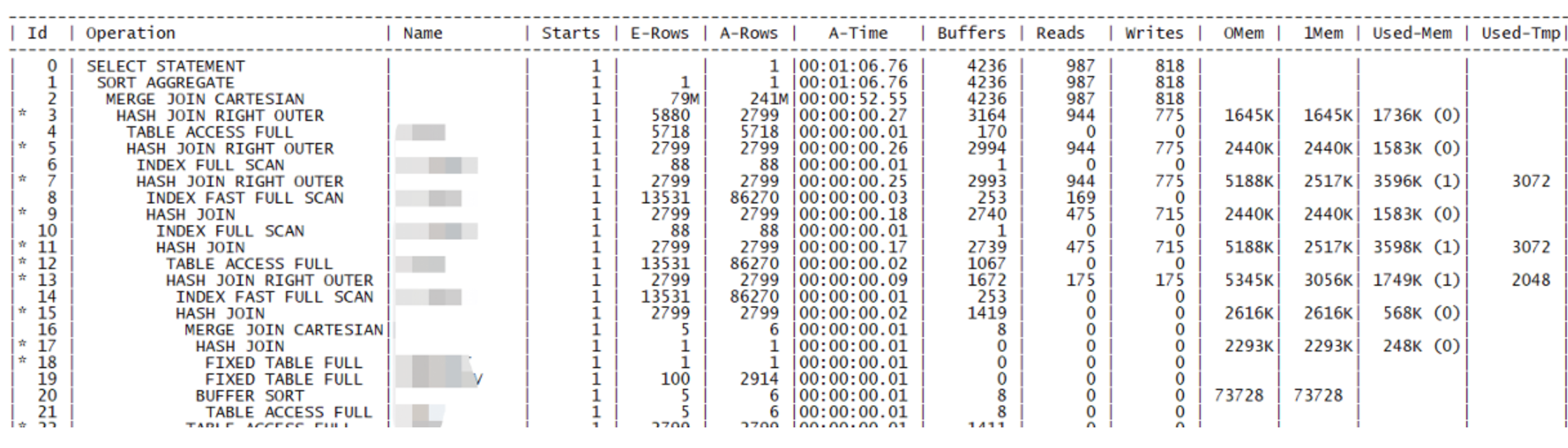
查看实际执行时间的方法
用这个方法可以看实际的执行时间:
sql
alter session set statistics_level=all;sql语句;
select * from table(dbms_xplan.display_cursor(null,null,'allstats last'));
收集统计信息差异
收集统计信息差异
生产用的是dbms_stats. gather_table_stats:
exec dbms_stats.gather_table_stats(
ownname=>' IOA5',
tabname=>' RF_RECEIVEFILE',
estimate_percent=>100,
cascade=>true
);测试用的是analyze语句:
analyze语句:
analyze table rf_receivefile compute statistics;
对比了一下收集后的统计信息,上面两种方式收集的统计信息结果稍微不一样的,对比结果如下:
相同:
采集比例是一致的,索引统计信息也是收集的,收集其他的统计信息数值基本一致
不同:
analyze不收集直方图信息
使用 DBMS_STATS 的示例
BEGIN
DBMS_STATS.gather_table_stats(
ownname => 'SCOTT',
tabname =>'T1',
estimate_percent=>100,
degree => 2,
method_opt => 'for all columns size auto',
no_invalidate => false,
cascade => TRUE
);
END;
/Auto:10g之后的默认选项。根据列使用的情况和数据分布情况进行直方图的创建。auto情况下要依据col_usage$基础表和数据的倾斜情况来判断。
解决方法与不走索引的常见情况
解决方法
不走索引的情况
1. 索引是invalid
2. 直方图信息的影响
3. 隐式转换
4. where条件是 <> != 使用不了索引
5. 复合索引前导列的问题例如:索引是key index (a,b,c)。可以支持a | a,b| a,c| a,b,c 组合进行查找,但不支持 b| c| b,c
6. null值会导致不用索引
7. like语句 %在前面也用不了索引
8. 索引是invisable
9. where语句中,对存在的索引列使用函数,索引并不是函数索引
select * from t1 where fun_objecdid(object_name)=2;
10. 数据列涉及计算的情况
select * from t1 where id+1=2;总结
这次问题,表面上是"同一条 SQL 在测试环境很快、在生产环境却很慢",实质原因却落在统计信息的差异上:测试环境使用 ANALYZE 收集统计信息,没有生成直方图;生产环境使用 DBMS_STATS 收集统计信息,并生成了直方图,结果导致优化器在生产环境里选择了全表扫描,而不是在测试环境中表现良好的索引路径,从而放大了性能差异。
从整个排查过程,其实可以得到几个比较有价值的经验:
第一,统计信息不只是"有"和"没有"的问题,更关键的是"怎么收"。同一张表,在是否生成直方图、method_opt 配置不同的情况下,优化器对选择率的估计会发生明显变化,进而影响执行计划,这也是为什么很多时候"测试一切正常,生产环境却经常出问题"。
第二,直方图是一把双刃剑。数据分布倾斜明显、过滤条件相对固定时,直方图可以帮助优化器做出更精准的判断;但在某些复杂 SQL 场景,尤其是分页、排序、多表关联并存的情况下,直方图有时会让优化器"过度相信"自己的估计,从而放弃原本更合适的索引路径,转而走全表扫描。
第三,在定位性能问题时,不能只看静态执行计划,更要结合实际执行统计。通过设置 statistics_level=all,再用 dbms_xplan.display_cursor 带 allstats last 的方式输出执行信息,对比估算行数和实际行数、估算成本和实际耗时,往往可以很快判断出问题是出在统计信息和选择率估计,还是出在 SQL 本身或硬件资源上。
第四,对于分页类 SQL,建议尽量采用相对稳定的分页写法和分页框架,把分页相关的过滤条件尽量明确写入 SQL 中(例如基于主键或时间范围的分页),减少对复杂排序加 STOPKEY 以及直方图估计的依赖,让执行计划更可预期、更稳定。
综合来看,这次生产环境不走索引、性能明显劣化的核心原因,很大概率就是直方图带来的选择率估计偏差,进而让生产环境走上了与测试环境完全不同的执行路径。对 DBA 来说,理解并善用统计信息和直方图,依然是日常 SQL 优化和性能排查中绕不过去的一课。