目录
AE对比VAE:
自编码器(Autoencoder):
目标:学习数据的有效压缩表示(降维,去噪)
核心结构:编码器->潜向量 z → 解码器
**输出:**输出是对输入的尽可能精确的复现。
损失函数:MSE
潜空间:不规则,难以生成
变分自编码器(VAE)
目标:学习数据的潜在概率分布,成为一个生成器
核心结构:编码器输出分布的参数(均值μ、方差σ²)→ 采样 z → 解码器。
输出:可以从潜空间随机采样生成新的数据
损失函数:重构损失+ 分布正则化损失(KL散度)
潜空间:连续,结构化,支持平滑插值
KL散度:
- -它衡量的是编码器输出的概率分布(由
μ和σ定义)与一个标准正态分布(均值为0,方差为1)之间的相似度。 - 作用 :它像一个正则化项 ,强迫编码器学习到的所有分布都向标准正态分布看齐。这带来了两个至关重要的特性:
- 连续性 (Continuity):由于所有数据的编码分布都被拉向中心(原点),不同数据(比如手写数字'1'和'7')的编码分布会在潜在空间中产生重叠。这意味着在'1'的区域和'7'的区域之间没有"断崖",而是平滑过渡的。如果你在这个过渡区域采样,解码器就能生成一个既像'1'又像'7'的图像。
- 规整性 (Regularity):潜在空间变得非常规整、结构化。大部分数据都被编码到了一个可控的、以原点为中心的区域内。
为什么要学习高斯隐空间:
如果我们只追求数据压缩和重构,普通自编码器就够了,为什么非要强迫隐空间(latent space)服从高斯分布呢?
简单来说,将隐空间规整为高斯分布的优越性在于:**它把一个混乱无序、充满"空洞"的编码空间,变成了一个连续、规整、且"可被探索"的地图,**使得这个空间中的每一个点都具有解码的意义。这使得"生成"成为可能。
优点:
- 泛化性能:解码器学会了将这个规整空间中的任意一个点
z映射回一个逼真的数据。它不仅学会了从训练数据采样到的z进行解码,还学会了对潜在空间中从未见过的点进行解码,并生成合理的结果。
VQ-VAE对比VAE:
VQ-VAE通过使用 codebook(码本)进行离散编码,相较于原始的 VAE 模型,潜在空间从连续变为了"离散化"和"结构化":
- 潜在空间是离散的 。编码器输出一个或多个向量,然后在 码本(Codebook) 中找到与这些向量最接近的"码字"(codeword)。最终的编码是这些码字在码本中的索引(index)。
- 解决"后验坍塌"(Posterior Collapse) 问题,即解码器(Decoder)可能学会忽略潜在编码
z,直接生成平均化的、模糊的输出。 - 降低数据保存开销
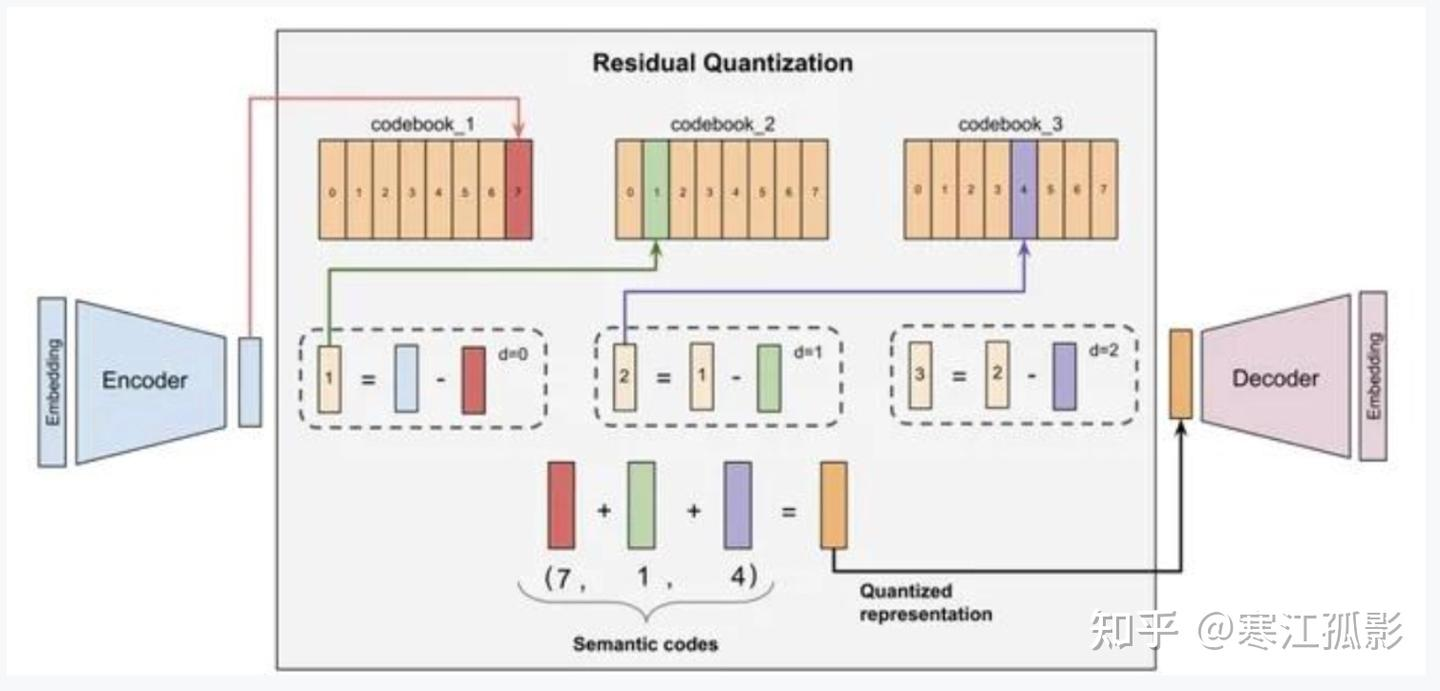
RQ-VAE对比VQ-VAE:
RQ-VAE(Residual Quantized Variational Autoencoder)变比VQ-VAE多了学习残差的过程,一个码本变为多个码本
-
码本小,组合多 :每一层只需要一个小型 码本(例如 1024 个向量)。但通过 8 层的组合,理论上可以表示
1024^8种不同的特征,这是一个天文数字。这意味着用极小的存储成本实现了极高的表示能力。 -
降低预测空间维度:将在一个大空间维度预测改为分层预测;
-
高质量的生成和重建 :分层量化的方式使得模型能够捕获从全局轮廓到局部细节的丰富信息,从而生成非常精细和高质量的图像。著名的 Parti 和 **Muse** 等文生图大模型都采用了 RQ-VAE 作为图像分词器。
-
解决了 VQ-VAE 的码本坍塌问题:在 VQ-VAE 中,码本中的很多向量可能永远不被使用(码本坍塌)。而在 RQ-VAE 中,由于每层码本负责不同粒度的信息,所有码本向量都被充分利用起来。
实现

训练过程:
L = 重构损失 + 码本损失 + 承诺损失

码本更新和encoder同时训练,如何保证能训练好?
- 双向对齐 :通过码本损失 和承诺损失,从两个方向拉近编码器输出空间和码本向量空间,迫使它们对齐。
- 稳定更新 :采用EMA等技巧,确保码本能够平滑、稳定地学习到编码器输出的核心分布。
技巧:
-
码本初始化 :码本向量初始值很重要。常用策略是从第一批数据编码器输出的
z_e中随机采样初始化,这样码本一开始就落在真实的数据分布区域内。 -
码本更新方式 :除了使用码本损失进行梯度下降,更稳定的一种方法是采用 指数移动平均(EMA) 。即,对编码到每个码本向量
e_i的所有z_e进行统计并更新:
N_i = 衰减率 * N_i + (1 - 衰减率) * 当前批次中分配到 e_i 的样本数
m_i = 衰减率 * m_i + (1 - 衰减率) * 当前批次中所有分配到 e_i 的 z_e 之和
e_i = m_i / N_i
这种方式能更平滑、更稳定地更新码本,尤其适用于批次小或码本使用分布不均匀时。
-
学习率策略 :通常,码本的学习率会设置得比编码器/解码器更高(例如10倍)。这是为了鼓励码本更快地适应编码器输出的分布,尤其是在训练初期。
-
解决"码本坍缩" :训练早期,可能只有少数码本向量被使用,大部分未被激活。除了承诺损失,有时会采用 "重启"策略 :当某个码本向量在很长一段时间(如一定步数)内未被使用,则将其重新初始化为一个当前正在被使用的编码器输出
z_e。
快手是如何利用其来做推荐的?
https://blog.csdn.net/yinyu19950811/article/details/151834292?spm=1001.2014.3001.5502
参考: